python_机器学习_监督学习模型_决策树
决策树模型练习:https://www.kaggle.com/c/GiveMeSomeCredit/overview
1. 监督学习--分类

机器学习肿分类和预测算法的评估:
a. 准确率
b.速度
c. 强壮行
d.可规模性
e. 可解释性
2. 什么是决策树/判定树(decision tree)?
https://scikit-learn.org/stable/modules/tree.html


3. 熵(entropy)概念:


变量的不确定越大,熵也就越大。
4. 决策树归纳算法(ID3)


5. 其他算法及优缺点

6. 决策树的应用


生成后的决策树
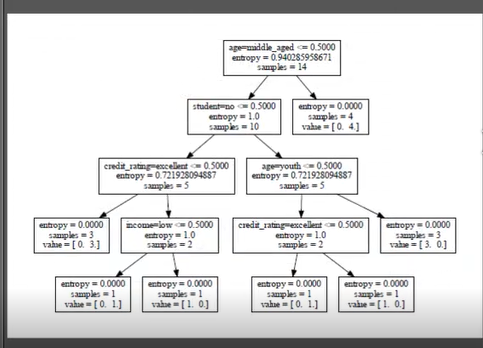
逻辑代码:
整理好的代码 --》
python3.6.3
Successfully installed joblib-0.13.2 numpy-1.16.4 scikit-learn-0.21.2 scipy-1.3.0
# -*- coding:utf-8 -*-
from sklearn.feature_extraction import DictVectorizer
import csv
from sklearn import preprocessing
from sklearn import tree # 要求是数值型的值
from sklearn.externals.six import StringIO
import pandas as pd """
注意: 决策树要求要数值型的值,不能是字符串类型的值
例如: no, yes这样的值是不允许的
需要转换成矩阵
====================================
age income student
youth high no
youth high no
middle_aged high no
senior medium no
senior low yes
==================================== 比如上面这种数据:
youth middle_aged senior high medium low ......
1 0 0 1 0 0
1 0 0 1 0 0
..... """ fileName = r"C:\Users\Administrator\Desktop\data.xlsx"
data = pd.read_excel(fileName)
# 删除id序列
del data["RID"]
# headers
headers = data.columns.values
# print(headers)
# ["RID", 'age'.....] # 样本量
# print(len(data)) # dict格式化单个样本
# print(dict(data.ix[1]))
# 单个样本最后一个数据
# print(data.ix[1][-1]) featureList = []
labelList = []
for row in range(len(data)):
rowData = data.ix[row]
labelList.append(rowData[-1])
featureList.append(dict(rowData)) # print(featureList) # [
# {"credit_rating": "fair", "age": "youth"},
# .... #作用,方便转换成矩阵。将数据转换成对象
# ]
# print(labelList)
# ['no', 'no', 'yes', 'yes', 'yes', 'no', 'yes', 'no', 'yes', 'yes', 'yes', 'yes', 'yes', 'no'] # =========<格式化数据,转换成decision tree需要的格式模型>============ vec = DictVectorizer()
dummyX = vec.fit_transform(featureList).toarray() print("dummyX:" + str(dummyX)) # 转换成矩阵的数据了二维
print(vec.get_feature_names()) print("labelList: " + str(labelList)) lb = preprocessing.LabelBinarizer()
dummyY = lb.fit_transform(labelList)
print("dummyY: " + str(dummyY)) # ===========《决策树建模分析》============= clf = tree.DecisionTreeClassifier(criterion="entropy")
clf = clf.fit(dummyX, dummyY)
print("clf: ", str(clf)) # # 存储决策树信息 # # Graphviz 将dot转换成pdf的命令: dot -T pdf iris.dot -o output.pdf
# # 可以查看decision tree 的形状了(看pdf的值)
# with open(r"C:\Users\Administrator\Desktop\code\mechine_learning\allElectronicInformationGainOri.dot", "w") as f:
# f = tree.export_graphviz(clf, feature_names = vec.get_feature_names(), out_file = f) # # 下面的代码属于预测的代码
# # 属于转化后的矩阵数值,其实就是进行复制修改
oneRowX = dummyX[2, :]
print("oneRowX: " + str(oneRowX)) newRowX = oneRowX # newRowX[0] = 1
# newRowX[2] = 1
print("newRowX: ", str(newRowX)) predictedY = clf.predict([newRowX])
# 预测 class_buys_labels的值
print("predictedY: " + str(predictedY))
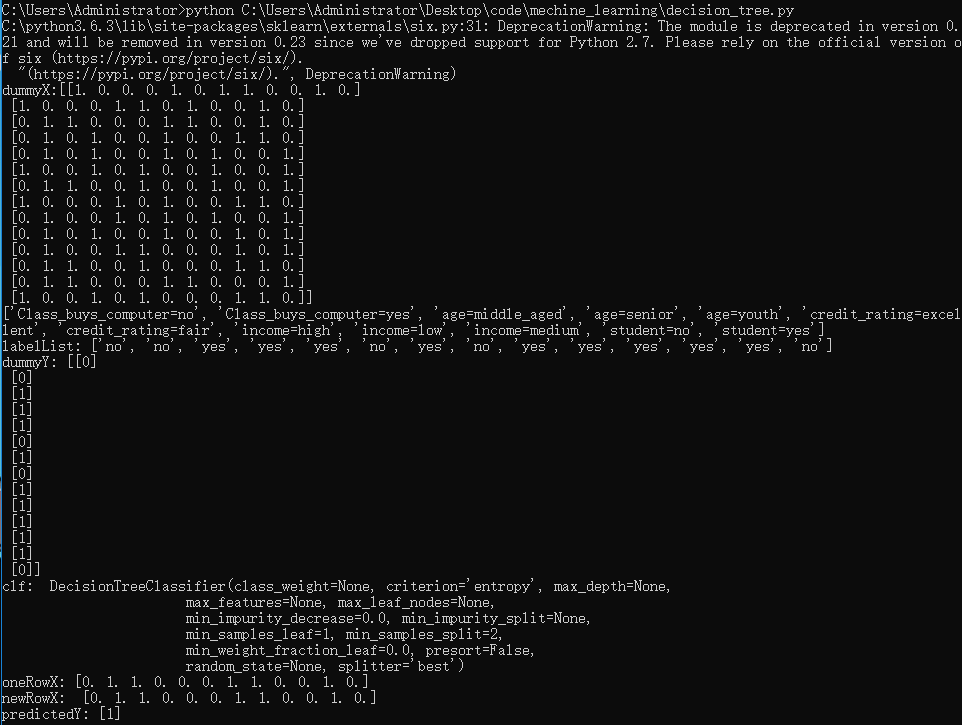
但这段代码不是特别通用,而且有bug, 需要修改,但基本逻辑是正确的
# -*- coding:utf-8 -*-
from sklearn.feature_extraction import DictVectorizer
import csv
from sklearn import preprocessing
from sklearn import tree # 要求是数值型的值
from sklearn.externals.six import StringIO """
注意: 决策树要求要数值型的值,不能是字符串类型的值
例如: no, yes这样的值是不允许的
需要转换成矩阵
====================================
age income student
youth high no
youth high no
middle_aged high no
senior medium no
senior low yes
==================================== 比如上面这种数据:
youth middle_aged senior high medium low ......
1 0 0 1 0 0
1 0 0 1 0 0
..... """ allElectronicsData = open(r"C:\Users\Administrator\Desktop\data.xlsx", 'r')
reader = csv.reader(allElectronicsData)
print(reader)
headers = next(reader) print(headers)
# ["RID", 'age'.....] featureList = []
labelList = []
for row in reader:
labelList.append(row[len(row) - 1])
rowDict = {}
for i in range(1, len(row) - 1):
rowDict[headers[i]] = row[i] featureList.append(rowDict) print(featureList)
# [
# {"credit_rating": "fair", "age": "youth"},
# .... #作用,方便转换成矩阵。将数据转换成对象
# ] vec = DictVectorizer()
dummyX = vec.fit_transform(featureList).toarray() print("dummyX:" + str(dummyX)) # 转换成矩阵的数据了二维
print(vec.get_feature_names()) print("labelList: " + str(labelList)) lb = preprocessing.LabelBinarizer()
dummyY = lb.fit_transform(labelList)
print("dummyY: " + str(dummyY)) clf = tree.DecisionTreeClassifier(criterion="entropy")
clf = clf.fit(dummyX, dummyY)
print("clf: ", str(clf)) # 存储决策树信息 # Graphviz 将dot转换成pdf的命令: dot -T pdf iris.dot -o output.pdf
# 可以查看decision tree 的形状了(看pdf的值)
with open(r"C:\Users\Administrator\Desktop\code\mechine_learning\allElectronicInformationGainOri.dot", "w") as f:
f = tree.export_graphviz(clf, feature_names = vec.get_feature_names(), out_file = f) # 下面的代码属于预测的代码
# 属于转化后的矩阵数值,其实就是进行复制修改
oneRowX = dummyX[0, :]
print("oneRowX: " + str(oneRowX)) newRowX = oneRowX newRowX[0] = 1
newRowX[2] = 0
print("newRowX: ", str(newRowX)) predictedY = clf.predicted(newRowX)
# 预测 class_buys_labels的值
predicted("predictedY: " + str(predictedY)) if __name__ == '__main__':
main()

python_机器学习_监督学习模型_决策树的更多相关文章
- [并发并行]_[线程模型]_[Pthread线程使用模型之三 客户端/服务端模型(Client/Server]
Pthread线程使用模型之三 客户端/服务端模型(Client/Server) 场景 1.在客户端/服务端模型时,客户端向服务端请求一些数据集的操作. 服务端执行执行操作独立的(多进程或跨网络)– ...
- [并发并行]_[线程模型]_[Pthread线程使用模型之二 工作组work crew]
Pthread线程使用模型之二工作组(Work crew) 场景 1.一些耗时的任务,比如分析多个类型的数据, 是独立的任务, 并不像 pipeline那样有序的依赖关系, 这时候pipeline就显 ...
- [并发并行]_[线程模型]_[Pthread线程使用模型之一管道Pipeline]
场景 1.经常在Windows, MacOSX 开发C多线程程序的时候, 经常需要和线程打交道, 如果开发人员的数量不多时, 同时掌握Win32和pthread线程 并不是容易的事情, 而且使用Win ...
- Java_太阳系_行星模型_小游戏练习_详细注释
//实现MyFrame--实现绘制窗口,和实现重写 重画窗口线程类 package cn.xiaocangtian.Test; import java.awt.Frame; import java.a ...
- 网络_OSI模型_数据包传输
2017年1月12日, 星期四 网络_OSI模型_数据包传输 1. 网络_源主机_局域网_交换机_路由器_目标主机 2. OSI7七层_TCP/IP精简 OSI 7层: 应用层 ...
- (转)看穿机器学习(W-GAN模型)的黑箱
本文转自:http://www.360doc.com/content/17/0212/11/35919193_628410589.shtml# 看穿机器学习(W-GAN模型)的黑箱 201 ...
- Spark机器学习6·聚类模型(spark-shell)
K-均值(K-mean)聚类 目的:最小化所有类簇中的方差之和 类簇内方差和(WCSS,within cluster sum of squared errors) fuzzy K-means 层次聚类 ...
- spark机器学习从0到1决策树(六)
一.概念 决策树及其集合是分类和回归的机器学习任务的流行方法. 决策树被广泛使用,因为它们易于解释,处理分类特征,扩展到多类分类设置,不需要特征缩放,并且能够捕获非线性和特征交互. 诸如随机森林和 ...
- Python 机器学习实战 —— 监督学习(上)
前言 近年来AI人工智能成为社会发展趋势,在IT行业引起一波热潮,有关机器学习.深度学习.神经网络等文章多不胜数.从智能家居.自动驾驶.无人机.智能机器人到人造卫星.安防军备,无论是国家级军事设备还是 ...
随机推荐
- C学习笔记(5)--- 指针第二部分,字符串,结构体。
1. 函数指针(function pointer): 函数指针是指向函数的指针变量. 通常我们说的指针变量是指向一个整型.字符型或数组等变量,而函数指针是指向函数. 函数指针可以像一般函数一样,用于调 ...
- 5. Vue - 小清单实例
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- pycharm 快速启动Django项目和python程序
Django 设置 *.py
- HTML简介 页面标记
HTML简介 HTML 1.0 : 1993年 HTML 2.0 : 1995年 HTML 3.2 : 1997年 HTML 4.01 : 1999年 HTML 5 : 2008年 XML:可扩展标 ...
- eclipse 错误日志地址
我们用eclipse插件的时候,有时插件会报错误,那么这些错误日志在哪儿放着呢? 这些错误日志的存放位置是:“你的workspace名称\.metadata\.log”,如果我们的eclipse报错了 ...
- 树莓派开机主动发送自己的局域网ip/外网ip到你的微信
开机时,树莓派主动发送自己的内网ip以及公网ip到你的微信上,这样就能方便地使用ssh或VNC. 操作步骤 下载目录下的 boot_getIP_send_Wechat.py 到你的 Raspberry ...
- ThreadPoolExecutor 线程池 简单解析
jdk1.8 ThreadPoolExecutor ThreadPoolExecutor实际就是java的线程池,开发常用的Executors.newxxxxx()来创建不同类型和作用的线程池,其底部 ...
- JDBC与Druid简单介绍及Druid与MyBatis连接数据库
序言 java程序与数据建立连接,首先要从jdbc说起,然后直接上阿里认为宇宙最好的数据库连接池druid,然后再说上层程序对象与数据源映射关联关系的orm-mybatis. JDBC介绍 JDBC( ...
- Elastic 使用索引生命周期管理实现热温冷架构
Elastic: 使用索引生命周期管理实现热温冷架构 索引生命周期管理 (ILM) 是在 Elasticsearch 6.6(公测版)首次引入并在 6.7 版正式推出的一项功能.ILM 是 Elast ...
- DLT645 1997 协议解析
源码下载 -> 提取码 QQ:505645074 DLT645.zip 工具 源码 规约解析 DL/T645-07: 数据帧格式: 注意事项: (1)前导字节-一般在传输帧信息前,都要有0~4 ...