算法导论--最小生成树(Kruskal和Prim算法)
转载出处:勿在浮沙筑高台http://blog.csdn.net/luoshixian099/article/details/51908175
关于图的几个概念定义:
连通图:在无向图中,若任意两个顶点vivi与vjvj都有路径相通,则称该无向图为连通图。
强连通图:在有向图中,若任意两个顶点vivi与vjvj都有路径相通,则称该有向图为强连通图。
连通网:在连通图中,若图的边具有一定的意义,每一条边都对应着一个数,称为权;权代表着连接连个顶点的代价,称这种连通图叫做连通网。
生成树:一个连通图的生成树是指一个连通子图,它含有图中全部n个顶点,但只有足以构成一棵树的n-1条边。一颗有n个顶点的生成树有且仅有n-1条边,如果生成树中再添加一条边,则必定成环。
最小生成树:在连通网的所有生成树中,所有边的代价和最小的生成树,称为最小生成树。
下面介绍两种求最小生成树算法
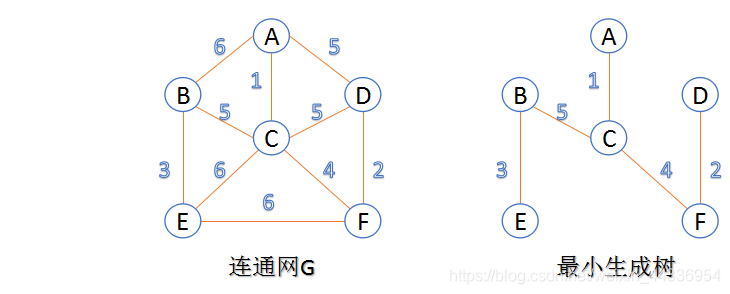
1.Kruskal算法
此算法可以称为“加边法”,初始最小生成树边数为0,每迭代一次就选择一条满足条件的最小代价边,加入到最小生成树的边集合里。
- 把图中的所有边按代价从小到大排序;
- 把图中的n个顶点看成独立的n棵树组成的森林;
- 按权值从小到大选择边,所选的边连接的两个顶点ui,viui,vi,应属于两颗不同的树,则成为最小生成树的一条边,并将这两颗树合并作为一颗树。
- 重复(3),直到所有顶点都在一颗树内或者有n-1条边为止。
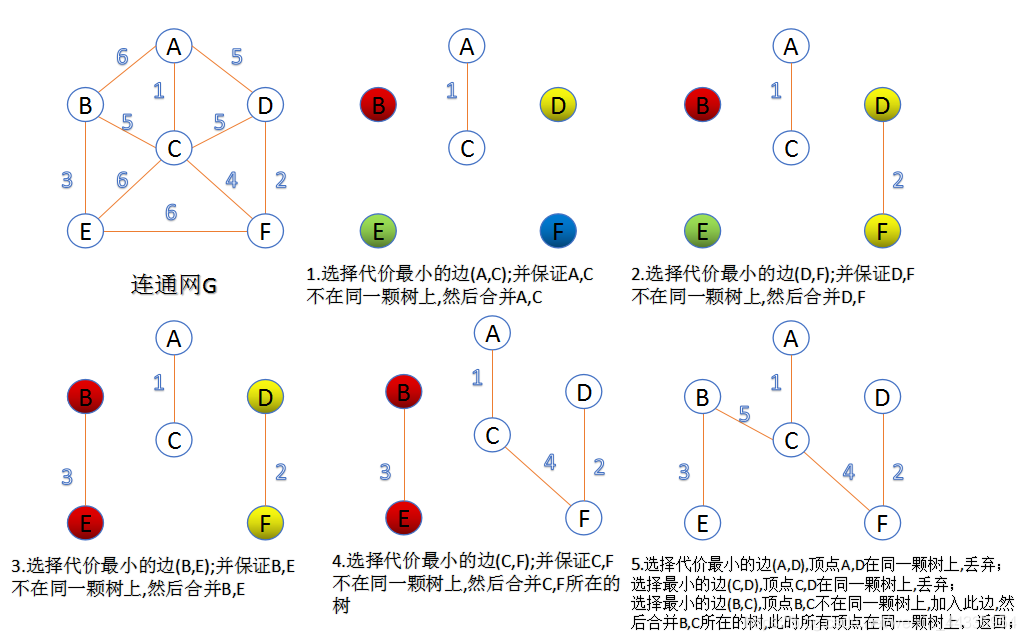
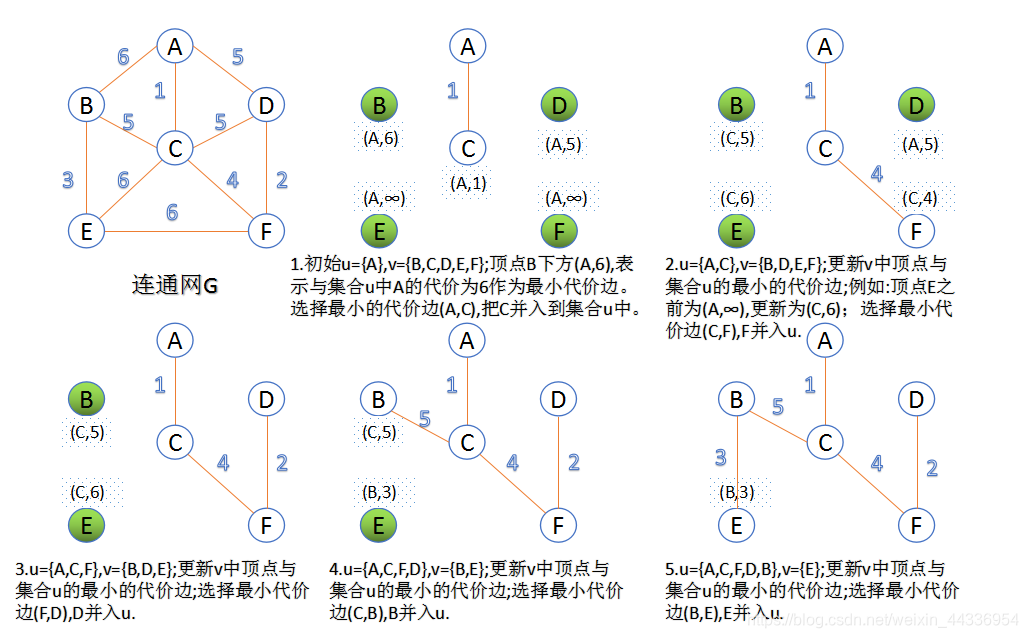
2.Prim算法
此算法可以称为“加点法”,每次迭代选择代价最小的边对应的点,加入到最小生成树中。算法从某一个顶点s开始,逐渐长大覆盖整个连通网的所有顶点。

由于不断向集合u中加点,所以最小代价边必须同步更新;需要建立一个辅助数组closedge,用来维护集合v中每个顶点与集合u中最小代价边信息,:
struct
{
char vertexData //表示u中顶点信息
UINT lowestcost //最小代价
}closedge[vexCounts]
3.完整代码
/************************************************************************
CSDN 勿在浮沙筑高台 http://blog.csdn.net/luoshixian099算法导论--最小生成树(Prim、Kruskal)2016年7月14日
************************************************************************/
#include <iostream>
#include <vector>
#include <queue>
#include <algorithm>
using namespace std;
#define INFINITE 0xFFFFFFFF
#define VertexData unsigned int //顶点数据
#define UINT unsigned int
#define vexCounts 6 //顶点数量
char vextex[] = { 'A', 'B', 'C', 'D', 'E', 'F' };
struct node
{
VertexData data;
unsigned int lowestcost;
}closedge[vexCounts]; //Prim算法中的辅助信息
typedef struct
{
VertexData u;
VertexData v;
unsigned int cost; //边的代价
}Arc; //原始图的边信息
void AdjMatrix(unsigned int adjMat[][vexCounts]) //邻接矩阵表示法
{
for (int i = 0; i < vexCounts; i++) //初始化邻接矩阵
for (int j = 0; j < vexCounts; j++)
{
adjMat[i][j] = INFINITE;
}
adjMat[0][1] = 6; adjMat[0][2] = 1; adjMat[0][3] = 5;
adjMat[1][0] = 6; adjMat[1][2] = 5; adjMat[1][4] = 3;
adjMat[2][0] = 1; adjMat[2][1] = 5; adjMat[2][3] = 5; adjMat[2][4] = 6; adjMat[2][5] = 4;
adjMat[3][0] = 5; adjMat[3][2] = 5; adjMat[3][5] = 2;
adjMat[4][1] = 3; adjMat[4][2] = 6; adjMat[4][5] = 6;
adjMat[5][2] = 4; adjMat[5][3] = 2; adjMat[5][4] = 6;
}
int Minmum(struct node * closedge) //返回最小代价边
{
unsigned int min = INFINITE;
int index = -1;
for (int i = 0; i < vexCounts;i++)
{
if (closedge[i].lowestcost < min && closedge[i].lowestcost !=0)
{
min = closedge[i].lowestcost;
index = i;
}
}
return index;
}
void MiniSpanTree_Prim(unsigned int adjMat[][vexCounts], VertexData s)
{
for (int i = 0; i < vexCounts;i++)
{
closedge[i].lowestcost = INFINITE;
}
closedge[s].data = s; //从顶点s开始
closedge[s].lowestcost = 0;
for (int i = 0; i < vexCounts;i++) //初始化辅助数组
{
if (i != s)
{
closedge[i].data = s;
closedge[i].lowestcost = adjMat[s][i];
}
}
for (int e = 1; e <= vexCounts -1; e++) //n-1条边时退出
{
int k = Minmum(closedge); //选择最小代价边
cout << vextex[closedge[k].data] << "--" << vextex[k] << endl;//加入到最小生成树
closedge[k].lowestcost = 0; //代价置为0
for (int i = 0; i < vexCounts;i++) //更新v中顶点最小代价边信息
{
if ( adjMat[k][i] < closedge[i].lowestcost)
{
closedge[i].data = k;
closedge[i].lowestcost = adjMat[k][i];
}
}
}
}
void ReadArc(unsigned int adjMat[][vexCounts],vector<Arc> &vertexArc) //保存图的边代价信息
{
Arc * temp = NULL;
for (unsigned int i = 0; i < vexCounts;i++)
{
for (unsigned int j = 0; j < i; j++)
{
if (adjMat[i][j]!=INFINITE)
{
temp = new Arc;
temp->u = i;
temp->v = j;
temp->cost = adjMat[i][j];
vertexArc.push_back(*temp);
}
}
}
}
bool compare(Arc A, Arc B)
{
return A.cost < B.cost ? true : false;
}
bool FindTree(VertexData u, VertexData v,vector<vector<VertexData> > &Tree)
{
unsigned int index_u = INFINITE;
unsigned int index_v = INFINITE;
for (unsigned int i = 0; i < Tree.size();i++) //检查u,v分别属于哪颗树
{
if (find(Tree[i].begin(), Tree[i].end(), u) != Tree[i].end())
index_u = i;
if (find(Tree[i].begin(), Tree[i].end(), v) != Tree[i].end())
index_v = i;
}
if (index_u != index_v) //u,v不在一颗树上,合并两颗树
{
for (unsigned int i = 0; i < Tree[index_v].size();i++)
{
Tree[index_u].push_back(Tree[index_v][i]);
}
Tree[index_v].clear();
return true;
}
return false;
}
void MiniSpanTree_Kruskal(unsigned int adjMat[][vexCounts])
{
vector<Arc> vertexArc;
ReadArc(adjMat, vertexArc);//读取边信息
sort(vertexArc.begin(), vertexArc.end(), compare);//边按从小到大排序
vector<vector<VertexData> > Tree(vexCounts); //6棵独立树
for (unsigned int i = 0; i < vexCounts; i++)
{
Tree[i].push_back(i); //初始化6棵独立树的信息
}
for (unsigned int i = 0; i < vertexArc.size(); i++)//依次从小到大取最小代价边
{
VertexData u = vertexArc[i].u;
VertexData v = vertexArc[i].v;
if (FindTree(u, v, Tree))//检查此边的两个顶点是否在一颗树内
{
cout << vextex[u] << "---" << vextex[v] << endl;//把此边加入到最小生成树中
}
}
}
int main()
{
unsigned int adjMat[vexCounts][vexCounts] = { 0 };
AdjMatrix(adjMat); //邻接矩阵
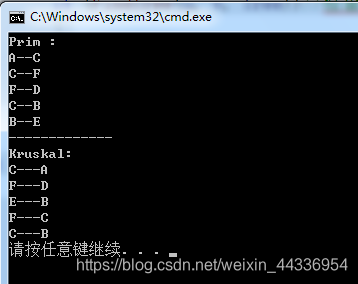
cout << "Prim :" << endl;
MiniSpanTree_Prim(adjMat,0); //Prim算法,从顶点0开始.
cout << "-------------" << endl << "Kruskal:" << endl;
MiniSpanTree_Kruskal(adjMat);//Kruskal算法
return 0;
}
Reference:
数据结构–耿国华
算法导论–第三版
算法导论--最小生成树(Kruskal和Prim算法)的更多相关文章
- 最小生成树——Kruskal与Prim算法
最小生成树——Kruskal与Prim算法 序: 首先: 啥是最小生成树??? 咳咳... 如图: 在一个有n个点的无向连通图中,选取n-1条边使得这个图变成一棵树.这就叫“生成树”.(如下图) 每个 ...
- 最小生成树--Prim算法,基于优先队列的Prim算法,Kruskal算法,Boruvka算法,“等价类”UnionFind
最小支撑树树--Prim算法,基于优先队列的Prim算法,Kruskal算法,Boruvka算法,“等价类”UnionFind 最小支撑树树 前几节中介绍的算法都是针对无权图的,本节将介绍带权图的最小 ...
- 关于最小生成树 Kruskal 和 Prim 的简述(图论)
模版题为[poj 1287]Networking. 题意我就不说了,我就想简单讲一下Kruskal和Prim算法.卡Kruskal的题似乎几乎为0.(●-`o´-)ノ 假设有一个N个点的连通图,有M条 ...
- Kruskal和Prim算法求最小生成树
Kruskal算法求最小生成树 测试数据: 5 6 0 1 5 0 2 3 1 2 4 2 4 2 2 3 1 1 4 1 输出: 2 3 1 1 4 1 2 4 2 0 2 3 思路:在保证不产生回 ...
- 最小生成树(Kruskal和Prim算法)
关于图的几个概念定义: 关于图的几个概念定义: 连通图:在无向图中,若任意两个顶点vi与vj都有路径相通,则称该无向图为连通图. 强连通图:在有向图中,若任意两个顶点vi与vj都有路 ...
- 最小生成树的kruskal、prim算法
kruskal算法和prim算法 都说 kruskal是加边法,prim是加点法 这篇解释也不错:这篇 1.kruskal算法 因为是加边法,所以这个方法比较合适稀疏图.要码这个需要先懂并查集.因为我 ...
- 1.1.2最小生成树(Kruskal和Prim算法)
部分内容摘自 勿在浮沙筑高台 http://blog.csdn.net/luoshixian099/article/details/51908175 关于图的几个概念定义: 连通图:在无向图中,若任意 ...
- 算法设计和分析(Prim算法构建最小生成树)
问题: 给定无向图G(N,M)表明图G有N个顶点,M条边,通过Prim算法构造一个最小生成树 分析: 算法流程: 构造好的最小生成树就是step6 运行代码: #include<cstdio&g ...
- 【算法导论C++代码】Strassen算法
简单方阵矩乘法 SQUARE-MATRIX-MULTIPLY(A,B) n = A.rows let C be a new n*n natrix to n to n cij = to n cij=ci ...
随机推荐
- MASMPlus汇编之简单窗体
.386 .model flat,stdcall option casemap:none ;include 定义 include windows.inc include gdi32.inc i ...
- mysql索引创建&查看&删除
1.索引作用 在索引列上,除了上面提到的有序查找之外,数据库利用各种各样的快速定位技术,能够大大提高查询效率.特别是当数据量非常大,查询涉及多个表时,使用索引往往能使查询速度加快成千上万倍. 例如,有 ...
- Oracle序列使用:建立、删除、使用
Oracle序列使用:建立.删除 在开始讲解Oracle序列使用方法之前,先加一点关于Oracle client sqlplus的使用,就是如果执行多行语句的话一定要加“/”才能表示结束,并执行!本篇 ...
- 转换GMT秒数为日期时间格式-Delphi源码
转换GMT秒数为日期时间格式-Delphi源码.收藏最近在写PE分析工具的时候,需要转换TimeDateStamp字段值为日期时间格式,这是Delphi的源码. //把GMT时间的秒数转换成日期时间格 ...
- Linux 桌面玩家指南:19. 深入理解 JavaScript,及其开发调试工具
特别说明:要在我的随笔后写评论的小伙伴们请注意了,我的博客开启了 MathJax 数学公式支持,MathJax 使用$标记数学公式的开始和结束.如果某条评论中出现了两个$,MathJax 会将两个$之 ...
- Kafka Topic的详细信息 捎带主要的安装步骤
1. 安装步骤 Kafka伪分布式安装的思路跟Zookeeper的伪分布式安装思路完全一样,不过比Zookeeper稍微简单些(不需要创建myid文件), 主要是针对每个Kafka服务器配置一个单独的 ...
- 很多程序员都没搞明白的时间与时区知识 - 24时区/GMT/UTC/DST/CST/ISO8601
全球24个时区的划分 相较于两地时间表,可以显示世界各时区时间和地名的世界时区表(World Time),就显得精密与复杂多了,通常世界时区表的表盘上会标示着全球24个时区的城市名称,但究竟 ...
- 如何使用VS Code编写Spring Boot (第二弹)
本篇文章是续<如何使用VS Code编写Spring Boot> 之后,结合自己.net经验捣鼓的小demo,一个简单的CRUD,对于习惯了VS操作模式的.net人员非常方便,强大的智能提 ...
- Web框架之Django重要组件(Django中间件、csrf跨站请求伪造)
Web框架之Django_09 重要组件(Django中间件.csrf跨站请求伪造) 摘要 Django中间件 csrf跨站请求伪造 一.Django中间件: 什么是中间件? 官方的说法:中间件是 ...
- Spring Boot2(四):使用Spring Boot多数据源实现读写分离
前言 实际业务场景中,不可能只有一个库,所以就有了分库分表,多数据源的出现.实现了读写分离,主库负责增改删,从库负责查询.这篇文章将实现Spring Boot如何实现多数据源,动态数据源切换,读写分离 ...