Spark第一周
Why Scala
在数据集不是很大的时候,开发人员可以使用python、R、MATLAB等语言在单机上处理数据集。但是在大数据时代,数据集少说都是TB、PB级别,此时便需要分布式地处理。相较于上述语言,Scala有着现成的框架即Spark能分布式地处理问题,Scala中有着丰富的Spark API,开发时只需要进行函数的编写就能轻松解决各种需求。虽然其他语言也有Spark的API,比如python的pySpark,但是逊色于Spark对Scala的支持,毕竟Spark是用Scala开发出来的。
Spark和Hadoop
Spark和Hadoop是Apache下的两个不同开源项目,但是有着很强的关联性。简单理解,Spark是一个能在Hadoop生态圈中使用的计算框架,Hadoop本身也有计算框架MapReduce。Spark对比Hadoop中的MapReduce有以下优势:
- Spark is more expressive(实现方式). Spark's APIs are modeled after Scala's collections, which mean distributed computations in Spark are like immutable lists in Scala. You can use higher-order functions like map, flatMap, filter, and reduce, to build up rich pipelines of computation that are distributed in a very concise way. Whereas Hadoop on the other hand is much more rigid(不灵活). It forces map then reduce computations without all of these cool combinators, like flatMap and filter, and it requires a lot more boilerplate to build up interesting computation pipelines.
- The second reason is performance(性能). By now, I'm sure you've heard of Spark as being super fast. After all, Spark's tagline is Lightning-Fast Cluster Computing. Performance brings something very important to the table that we haven't had until Spark came along which is interactivity. Now it's possible to query your very large distributed data set interactively(交互式). So that's a really big deal. And also Spark is so much faster that Hadoop in some cases that jobs that would take tens of minutes to run, now only take a few seconds. This allows data scientists to interactively explore and experiment with their data, which in turn allows for data scientists to discover richer insights from their data faster. MapReduce job results need to be stored in HDFS before they can be used by another job.
- And finally, Spark is good for data science. It's much better for data science than Hadoop and it's not just due to performance reasons. Iteration is required by most algorithms in the data scientist's toolbox. That is, most analysis tasks require multiple passes over the same set of data. And while iteration is indeed possible in Hadoop with really quite a lot of effort, you have a bunch of boilerplate that you have to do and a required external libraries and frameworks that just degenerate a bunch of extra map reduce phases in order to simulate iteration. It's really, on the other hand, the downright simple to do in Spark. There's no boilerplate required whatsoever, you just write what feels like a normal program, which includes a few passes over the same dataset. You just have basically, something that looks like a for loop and say hey, until this condition is met iterate. Which is night and day when compared with Hadoop, because it's almost not possible in Hadoop.
Why Spark is causing such a shift in handling data
Spark对于数据的实时处理被人津津乐道,那么这个分布式计算框架为什么能如此优秀?
对于一个分布式计算框架,有两个问题始终难以回避:
- Partial failure(某些节点崩溃,难以工作): crash failures of a subset of the machines involved in distributed computation
- Latency(延迟): certain opeartions have a much higher latency than other operations due to the network communication
在实际开发中,Latency是难以规避的。虽然Spark是很优秀的框架,但是如何编写出更好的代码尽量降低Latency也是开发人员的工作。
一些延迟时间:
 

- 蓝色:与内存读写有关
- 橙色:与磁盘读写有关
- 紫色:与网络传输有关
在继承Hadoop对于节点崩溃的容错性的同时,Spark在处理时效上有了巨大突破。原因在于
如果计算不涉及与其他节点进行数据交换,Spark可以在内存中一次性完成这些操作,也就是中间结果无须落盘(MR则需要存到HDFS先),减少了磁盘IO的操作。
RDD(resilient distributed dataset)
在scala-REPL中敲出下列代码可以查看Spark根目录中的LICENSE有几行,并且可以打印其中有几行包含“BSD”。
// sc是Spark Context类
scala> val licLines = sc.textFile("/Users/shayue/env/spark/spark-2.4.2-bin-hadoop2.7/LICENSE")
licLines: org.apache.spark.rdd.RDD[String] = /Users/shayue/env/spark/spark-2.4.2-bin-hadoop2.7/LICENSE MapPartitionsRDD[1] at textFile at <console>:24
scala> val lineCnt = licLines.count
[Stage 0:>
lineCnt: Long = 518
scala> val bsdLines = licLines.filter(line => line.contains("BSD"))
bsdLines: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[2] at filter at <console>:25
scala> bsdLines.count
res1: Long = 3
scala> bsdLines.foreach(bsdLine => println(bsdLine))
BSD 2-Clause
BSD 3-Clause
is distributed under the 3-Clause BSD license.
// 简化写法
scala> bsdLines.foreach(println)
BSD 2-Clause
BSD 3-Clause
is distributed under the 3-Clause BSD license.
这里代码中用到的filter和contains在scala的一些collection中也有。不过,licLines和bsdLines并不是scala的collection结构。它们时分布式的collection结构,在Spark中被称为RDDs。
RDD的特性如下:
- Immutable (read-only) ,只读类型
- Resilient (fault-tolerant) ,高容错性
- Distributed (dataset spread out to more than one node),分布式
RDDs能执行很多数据转化操作,但结束后总是产生一个新的RDD实例。一旦创建,RDD永远不会改变,这也是上面提到的Immutable特性。因为Mutable会增加框架的复杂性,除此之外,immutable collections使得Spark更具有容错性。
一个RDD实例是分布在各台机器上的总和,但是Spark仅仅暴露一个接口给用户,使得用户感觉就像在单机上操作。RDDs使得将一个任务部署到多个机器上执行变得简单了。
其他分布式计算框架通过将数据复制到多台机器来保持容错,一旦节点出现故障就可以从正常的节点复制恢复。RDD的机制不同的,它们会记录如何在某个工作节点上生成一些数据的方式,称为RDD运算图(RDD lineage),如果哪个工作节点发生故障,则只需根据记录重新生成数据即可。
下面以上述代码为例:
- 加载文本文件的过程生成了licLines RDD
- 对licLines使用
filter方法,生成新的bsdLines RDD - 步骤1和步骤2一起构成了一个
RDD运算图(RDD lineage)。它记录了如何从头到尾创建bsdLines RDD。也就是说,即使某个节点当掉,可以根据RDD lineage重新生成必要的数据。
基本的RDD操作
分为两种方式:
- Transformations(转换): 比如
filter,map,可以发现transformations操作一般会通过原RDD进行更改,进而产生新的RDD实例 - Actions(执行): 比如
count,foreach,进行action操作主要是希望得到一些关于RDD实例性质的结果。
值得注意的是:
Spark的Transformations操作是Lazily的,即仅在执行某些Actions操作以输出一些想要的结果时,Transformations操作才会进行。
在RDD上触发action操作后,Spark会检查RDD lineage,并使用该信息构建需要执行的graph of operations(操作图)以计算操作。它告诉Spark需要执行哪些transformations,以及将以何种顺序执行。
“操作图”可以理解为在一些RDDs上接了许多带箭头的线,每条线代表一个transformation,只有最后点击Actions时,这些线上才会有数据流动。
Transformations实践
map
// sc.parallelize是一个创建RDD的方式,用本地的scala collect创建。makeRDD也可;(10 to 50 by 10)是生成Scala Range类型写法
// scala> List(10 to 50 by 10)
// res6: List[scala.collection.immutable.Range] = List(Range 10 to 50 by 10)
scala> val numbers = sc.parallelize(10 to 50 by 10)
numbers: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[3] at parallelize at <console>:24
scala> numbers.foreach(println)
20
30
40
50
10
// map操作,计算平方
scala> val numberSquared = numbers.map(num => num * num)
numberSquared: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[4] at map at <console>:25
scala> numberSquared.foreach(println)
100
1600
400
900
2500
// 对于平方数,转成string,再反转
scala> val reversed = numberSquared.map(num => num.toString.reverse)
reversed: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[5] at map at <console>:25
scala> reversed.foreach(println)
001
004
009
0061
0052
// 上述方式的简写
scala> val alsoReversed = numberSquared.map(_.toString.reverse)
alsoReversed: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[6] at map at <console>:25
distinct and flatMap
- .collect方法能获得RDDs实例中的scala collection类型
- .distinct获得不同的元素
- .flatMap对于
def flatMap[U](f: (T) => TraversableOnce[U]): RDD[U]
代码:
scala> val lines = sc.textFile("/Users/shayue/client-ids.log")
lines: org.apache.spark.rdd.RDD[String] = /Users/shayue/client-ids.log MapPartitionsRDD[1] at textFile at <console>:24
scala> val idsStr = lines.flatMap(_.split(","))
idsStr: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[2] at flatMap at <console>:25
scala> idsStr.collect
res0: Array[String] = Array(15, 16, 20, 20, 77, 80, 94, 94, 98, 16, 31, 31, 15, 20)
scala> idsStr.first
res2: String = 15
scala> val idsInt = idsStr.map(_.toInt)
idsInt: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[3] at map at <console>:25
// idsInt.collect是Array[Int]
scala> idsInt.collect
res4: Array[Int] = Array(15, 16, 20, 20, 77, 80, 94, 94, 98, 16, 31, 31, 15, 20)
scala> idsInt.distinct
res5: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[6] at distinct at <console>:26
// res5指代idsInt.distinct生成的RDD实例
scala> res5
res6: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[6] at distinct at <console>:26
// 仅包含不同元素
scala> res5.collect
res8: Array[Int] = Array(16, 80, 98, 20, 94, 15, 77, 31)
// 由Array[String]到String,并且加上特定格式“;”
scala> idsStr.collect.mkString(";")
res9: String = 15;16;20;20;77;80;94;94;98;16;31;31;15;20
sample\takeSample\take
def sample(withReplacement: Boolean, fraction: Double, seed: Long = Utils.random.nextLong): RDD[T]
用于对一个RDD实例中的元素取样,Boolean是True的话就是有放回的取样;False就是无放回
统计量
mean\sum\histogram\variance\stdv
PPT 总结:赖得手打了
常用Transformations:
 

常用Actions:
 

其他:
 

Why Spark is good for Data Analysis
先来回顾一下Spark的特性:
- Transformtions is Lazy
- Actions is Eager
数据处理中做的最多的事情是迭代:
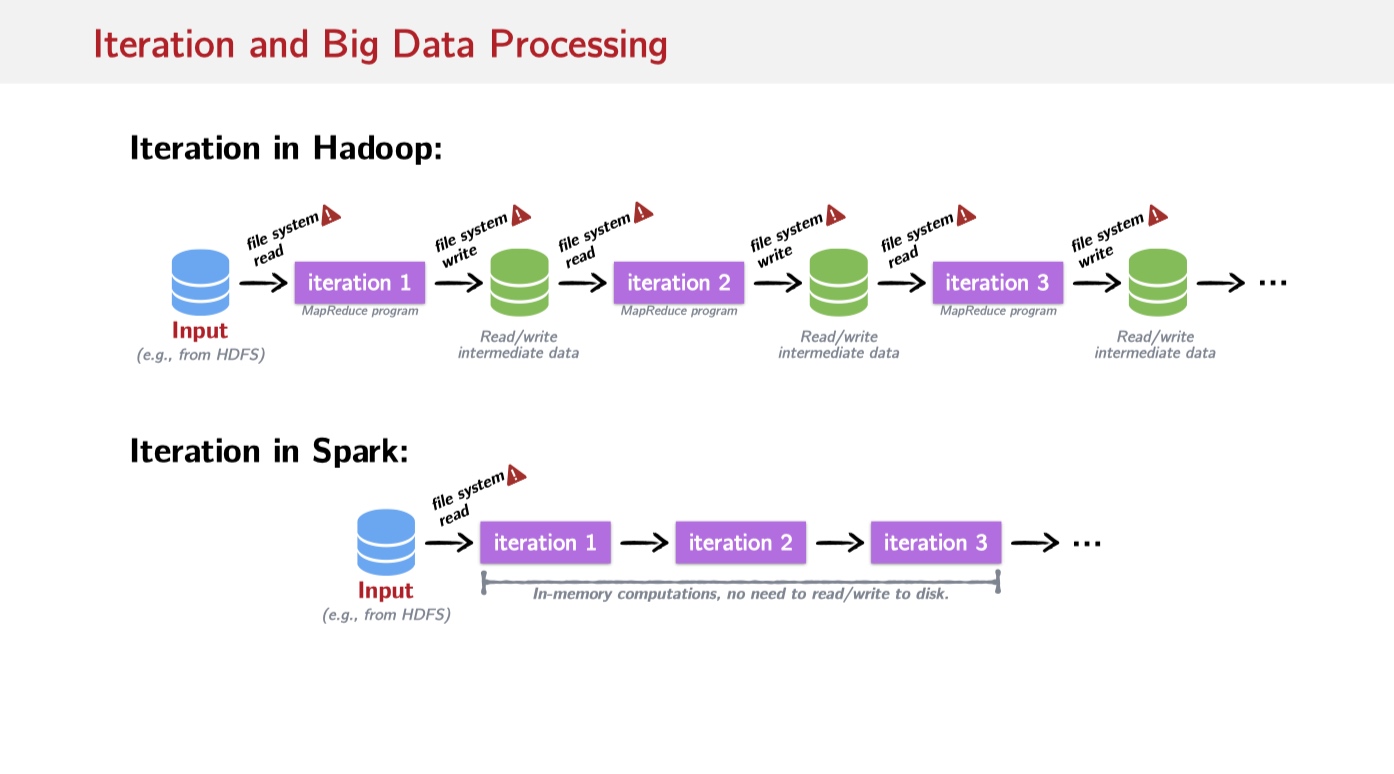 

从上图看来,不像Hadoop需要重复地将数据写回File System中,Spark有能力直接在内存中读取数据进行迭代。
Spark allows us to control what is cached in memory. What we do is just simply call persist() or cache() on RDDs.
举例:
 

倘若不在第二行生成logsWithErrors时加上.persist()。由于filter()和contains()是Lazy的,在第4行执行Actions操作count时,需要重新执行.filter(_.contains("ERROR"))这个操作;但是加上.persist()就可以不用重复计算。
当然,既然是将数据保存在内存中,那显然很吃内存的容量。Spark有以下如下几种方式,配置保存在内存中的数据格式。
 

RDDs和collection的区别
- Lazy和Eager
- Spark更加聪明,比如:
 

取完10个元素之后,Spark便停止工作了;又或者:
 

collction中要先走完map再走filter再走count,RDDs中一次遍历时这些操作同时进行。
Spark第一周的更多相关文章
- 第一周 总结笔记 / 斯坦福-Machine Learning-Andrew Ng
课程主页:https://www.coursera.org/learn/machine-learning/home/welcome 收集再多的资料也没用,关键是要自己理解总结,做笔记就是一个归纳总结的 ...
- Surprise团队第一周项目总结
Surprise团队第一周项目总结 团队项目 基本内容 五子棋(Gobang)的开发与应用 利用Android Studio设计一款五子棋游戏,并丰富其内涵 预期目标 实现人人模式:2个用户可以在同一 ...
- 20145213《Java程序设计》第一周学习总结
20145213<Java程序设计>第一周学习总结 教材学习内容总结 期待了一个寒假,终于见识到了神秘的娄老师和他的Java课.虽说算不上金风玉露一相逢,没有胜却人间无数也是情理之中,但娄 ...
- 20145206邹京儒《Java程序设计》第一周学习总结
20145206 <Java程序设计>第1周学习总结 教材学习内容总结 1.三大平台:Java SE.Java EE与Java ME.Java SE是各应用平台的基础,分为四个主要的部分: ...
- 20145304 刘钦令 Java程序设计第一周学习总结
20145304<Java程序设计>第1周学习总结 教材学习内容总结 1995年5月23日,是公认的Java的诞生日,Java正式由Oak改名为Java. Java的三大平台是:Java ...
- 20145330孙文馨 《Java程序设计》第一周学习总结
20145330孙文馨 <Java程序设计>第一周学习总结 教材学习内容总结 刚开始拿到这么厚一本书说没有压力是不可能的,开始从头看觉得很陌生进入不了状态,就稍微会有一点焦虑的感觉.于是就 ...
- 20145337《JAVA程序设计》第一周学习总结
# 20145337 <Java程序设计>第1周学习总结 ## 教材学习内容总结 第一章 -Java最早是Sun公司撰写Star7应用程序的程序语言 -根据应用领域不同,有Java SE. ...
- Linux内核设计第一周 ——从汇编语言出发理解计算机工作原理
Linux内核设计第一周 ——从汇编语言出发理解计算机工作原理 作者:宋宸宁(20135315) 一.实验过程 图1 编写songchenning5315.c文件 图2 将c文件汇编成32位机器语言 ...
- 20135328信息安全系统设计基础第一周学习总结(Linux应用)
学习计时:共xxx小时 读书: 代码: 作业: 博客: 一.学习目标 1. 能够独立安装Linux操作系统 2. 能够熟练使用Linux系统的基本命令 3. 熟练使用Linux中用户管理命令/ ...
随机推荐
- File handling in Delphi Object Pascal(处理record类型)
With new users purchasing Delphi every single day, it’s not uncommon for me to meet users that are n ...
- [转载] ASP.NET MVC (一)——深入理解ASP.NET MVC
个人认为写得比较透彻得Asp.net mvc 文章,所以转载过来,原文链接在最后: ASP.NET vs MVC vs WebForms 许多ASP.NET开发人员开始接触MVC认为MVC与ASP.N ...
- c# log4net 配置使用
新增配置文件log4net.config,内容如下 <?xml version="1.0" encoding="utf-8" ?> <conf ...
- 推荐一些C#相关的网站、资源和书籍 (转载自http://blog.csdn.net/chinacsharper/article/details/17514923)
一.网站 1.http://msdn.microsoft.com/zh-CN/ 微软的官方网站,C#程序员必去的地方.那里有API开发文档,还有各种代码.资源下载. 2.http://social.m ...
- c++用参数返回堆上的空间
<高质量c++和c编程>7.4 指针参数是如何传递内存的一节中写道 void GetMemory(char *p, int num) { p = (char *)malloc(sizeof ...
- Linux基础(二)
网卡的启动与关闭 ipup ens33 启动网卡 ifdown 关闭网卡 普通用户没有该权限 root用户,管理员,普通用户的权限 root 至高无上的 root用户所在的组是root组 管理员 ...
- nice-validator表单验证插件的简单使用
前言 前端表单校验是过滤无效数据.假数据.有毒数据的第一步,是数据安全的第一道关卡,虽然我们不能100%相信客户端提交的数据(真正的校验还得在服务端进行),但设置前端表单校验也是至关重要的,自己写逻辑 ...
- JavaScript 一元正号运算符
本文适合JavaScript初学者. 一元正号介绍 一元正号运算符(+)位于其操作数前面,计算其操作数的数值,如果操作数不是一个数值,会尝试将其转换成一个数值. 尽管一元负号也能转换非数值类型,但是一 ...
- Solr配置文件 schema.xml
1 添加自己的分词器(mmseg4j) 意思是textCommplex 这个类型,用的是 com.chenlb.mmseg4j.solr.MMSegTokenizerFactory 这个分词器,词库是 ...
- 2018.8.19 2018暑假集训之maxnum
昨天去做志愿服务去了没写成Q_Q 今天再来一道 先放题面描述 设有n个正整数(n<=20),将它们联成一排,组成一个最大的多位数 设有n个正整数(n<=20),将它们联成一排,组成一个最大 ...