算法与数据结构基础 - 字典树(Trie)
Trie基础
Trie字典树又叫前缀树(prefix tree),用以较快速地进行单词或前缀查询,Trie节点结构如下:
//208. Implement Trie (Prefix Tree)
class TrieNode{
public:
TrieNode* children[]; //或用链表、map表示子节点
bool isWord; //标识该节点是否为单词结尾
TrieNode(){
memset(children,,sizeof(children));
isWord=false;
}
};
插入单词的方法如下:
void insert(string word) {
TrieNode* p=root;
for(auto w:word){
if(p->children[w-'a']==NULL) p->children[w-'a']=new TrieNode;
p=p->children[w-'a'];
}
p->isWord=true;
}
假如有单词序列 ["a", "to", "tea", "ted", "ten", "i", "in", "inn"],则完成插入后有如下结构:
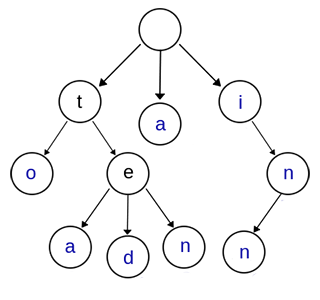
Trie的root节点不包含字符,以上蓝色节点表示isWord标记为true。在建好的Trie结构里查找单词或单词前缀的方法如下:
/** Returns if the word is in the trie. */
bool search(string word) {
TrieNode* p=root;
for(auto w:word){
if(p->children[w-'a']==NULL) return false;
p=p->children[w-'a'];
}
return p->isWord;
}
/** Returns if there is any word in the trie that starts with the given prefix. */
bool startsWith(string prefix) {
TrieNode* p=root;
for(auto w:prefix){
if(p->children[w-'a']==NULL) return false;
p=p->children[w-'a'];
}
return true;
}
相关LeetCode题:
208. Implement Trie (Prefix Tree) 题解
Trie与Hash table比较
同样用于快速查找,经常会拿Hash table和Trie相互比较。从以上Trie的构建和查找代码可知,构建Trie的时间复杂度和文本长度线性相关、查找时间复杂度和单词长度线性相关;对Trie空间复杂度来说,如果数据按前缀聚拢,那么有利于减少Trie的存储空间。
对Hash table而言,虽然查找过程是O(1),但另需考虑hash函数本身的时间消耗;另对于字符串prefix查找问题,并不能直接用Hash table解决,要么做一些提前功夫,将各个prefix也提前存入Hash table。
相关LeetCode题:
648. Replace Words Trie题解 HashTable题解
Trie的应用
Trie除了可以用于字符串检索、前缀匹配外,还可以用于词频统计、字符串排序、搜索自动补全等场景。
相关LeetCode题:
642. Design Search Autocomplete System 题解
算法与数据结构基础 - 字典树(Trie)的更多相关文章
- 字典树(Trie)详解
详解字典树(Trie) 本篇随笔简单讲解一下信息学奥林匹克竞赛中的较为常用的数据结构--字典树.字典树也叫Trie树.前缀树.顾名思义,它是一种针对字符串进行维护的数据结构.并且,它的用途超级广泛.建 ...
- 『字典树 trie』
字典树 (trie) 字典树,又名\(trie\)树,是一种用于实现字符串快速检索的树形数据结构.核心思想为利用若干字符串的公共前缀来节约储存空间以及实现快速检索. \(trie\)树可以在\(O(( ...
- [POJ] #1002# 487-3279 : 桶排序/字典树(Trie树)/快速排序
一. 题目 487-3279 Time Limit: 2000MS Memory Limit: 65536K Total Submissions: 274040 Accepted: 48891 ...
- 算法与数据结构基础 - 广度优先搜索(BFS)
BFS基础 广度优先搜索(Breadth First Search)用于按离始节点距离.由近到远渐次访问图的节点,可视化BFS 通常使用队列(queue)结构模拟BFS过程,关于queue见:算法与数 ...
- 算法与数据结构基础 - 二叉树(Binary Tree)
二叉树基础 满足这样性质的树称为二叉树:空树或节点最多有两个子树,称为左子树.右子树, 左右子树节点同样最多有两个子树. 二叉树是递归定义的,因而常用递归/DFS的思想处理二叉树相关问题,例如Leet ...
- 算法与数据结构基础 - 图(Graph)
图基础 图(Graph)应用广泛,程序中可用邻接表和邻接矩阵表示图.依据不同维度,图可以分为有向图/无向图.有权图/无权图.连通图/非连通图.循环图/非循环图,有向图中的顶点具有入度/出度的概念. 面 ...
- 算法与数据结构基础 - 深度优先搜索(DFS)
DFS基础 深度优先搜索(Depth First Search)是一种搜索思路,相比广度优先搜索(BFS),DFS对每一个分枝路径深入到不能再深入为止,其应用于树/图的遍历.嵌套关系处理.回溯等,可以 ...
- 字典树trie学习
字典树trie的思想就是利用节点来记录单词,这样重复的单词可以很快速统计,单词也可以快速的索引.缺点是内存消耗大 http://blog.csdn.net/chenleixing/article/de ...
- 算法与数据结构基础 - 堆(Heap)和优先级队列(Priority queue)
堆基础 堆(Heap)是具有这样性质的数据结构:1/完全二叉树 2/所有节点的值大于等于(或小于等于)子节点的值: 图片来源:这里 堆可以用数组存储,插入.删除会触发节点shift_down.shif ...
随机推荐
- POJ 2987:Firing(最大权闭合图)
http://poj.org/problem?id=2987 题意:有公司要裁员,每裁一个人可以得到收益(有正有负),而且如果裁掉的这个人有党羽的话,必须将这个人的所有党羽都裁除,问最少的裁员人数是多 ...
- HDU 4763:Theme Section(KMP)
http://acm.hdu.edu.cn/showproblem.php?pid=4763 Theme Section Problem Description It's time for mus ...
- 【Aizu - 0118】Property Distribution
-->Property Distribution 原文是日语,算了算了,直接上我大中华母语吧 Descriptions: 在H * W的矩形果园里有苹果.梨.蜜柑三种果树, 相邻(上下左右)的 ...
- 从零开始实现放置游戏(十)——实现战斗挂机(1)hessian服务端搭建
前面实现RMS系统时,我们让其直接访问底层数据库.后面我们在idlewow-game模块实现游戏逻辑时,将不再直接访问底层数据,而是通过hessian服务暴露接口给表现层. 本章,我们先把hessia ...
- c++指针经典题目分析
首先看一下题目,下列程序会在那一行崩溃,程序如下: #include<iostream> using namespace std; struct S{ int i; int *p; }; ...
- Kafka Eagle V1.3.4更新预览
1.概述 Kafka Eagle是一款开源的Kafka集群监控系统,源代码托管在Github.目前Kafka Eagle已更新到V1.3.4版本,域名已经统一更新为http://www.kafka-e ...
- c++学习书籍推荐《C++设计新思维》下载
百度云及其他网盘下载地址:点我 译序by 侯捷 i 译序by 於春景 iii 目录 v 序言by scott meyers xi 序言by john vlissides xv 前言 xvii 致谢 x ...
- Elasticsearch(一)开启外网访问
1. 设置Elasticsearch对外访问的Host 修改Elasticsearch配置文件 elasticsearch.yml : network.host: 128.24.108.84 //在 ...
- Java基础之回味finally
平时大家try…catch…finally语句用的不少,知道finally块一定会在try…catch..执行结束时执行,但是具体是在什么时候执行呢,今天我们一起来看下. public static ...
- Perm排列计数(新博客试水,写的不好,各路大神见谅)
B. Perm 排列计数 内存限制:512 MiB 时间限制:1000 ms 标准输入输出 题目描述 称一个1,2,...,N的排列P1,P2...,Pn是Magic的,当且仅当2<=i&l ...