单页面(如react,vue)网站的服务器渲染 SSR 之 SEO 大杀器 Rendertron
单页面网站,比如vue、recat框架的网站,一般都是直接从服务器推送index.html,再根据自身路由通过js在客户端浏览器渲染出完整的html页面。
但是搜索引擎的爬虫可没有这么智能(实际上google就有这么智能,拿到js文件自动帮你渲染好,但身在CN,将就下百度这个阿斗吧),为了SEO,要想爬虫爬到你的网站的内容,就得先由服务器把页面渲染好后再发送给爬虫,这就尴尬了,传统的服务器渲染是多页面的,一个请求对应一个页面,但SPA不是啊,本来就一个单页面,你叫我写各种路由对应渲染好了再给你??当然也不是不可以,以下就是几种方案:
react自带的renderToString
react自带的renderToString 和 renderToStaticMarkup 就可以用来将组件(Virtual DOM)输出成 HTML 字符串,看起来不错,但是要自己配参数啊,webpack不会怎么办,原本路由写在一起怎么办,redux要改动怎么办,如果这些你都ok的话,react自带的方案也是一种不错的选择,这里就不多说了,网上相关帖子很多。
nextjs
还有一种方案,就更尴尬了,叫nextjs框架(nextjs是react的,vue的叫nuxtjs),这种框架写出来直接就是多页面的,也就是用react的语法和规则,写出多页面网站来,每个页面的入口名字就是路由名字,服务器也是nextjs自带的,短短几行就能把单个网页渲染好并推送出去,是不是看起来棒棒的?!
那为啥说尴尬呢?就是因为他虽说跟react很像,但还是一个新框架,你不得不花时间学一下nextjs;他的路由对应页面文件,这种路由看似简单明了,但是一点都不自由;nextjs是多页面的,好不容易进化到单页面,你让我再回到中世纪?原罪啊!所以如果你已经写好了一个单页面网站,要改成nextjs框架的话,我只能说呵呵了,这返工返的……
rendertron
我们的主角要出场了!rendertron的由来我不多说了,当初诞生就是为了做SEO的。先说说原理,听完你就知道是个好东西了。
Rendertron是nodejs框架下的产物,是google-chrome旗下的的配套产品。首先,服务器上装有个google-chrome,rendertron把他打开,然后在服务器(官方推荐express)中增加中间件,先判断UA(user-agent)里面有没有带有类似Baiduspider(百度爬虫)等字样,如果没有,就像正常的单页面服务器那样,把原始html推送出去,由客户端浏览器完成js、css渲染的工作;如果带有指定UA头字样,就先把网页推送给本地服务器那个google-chrome,等他渲染好对应页面后,把渲染好的html结果推送出去。不就是为了SEO么,你爬虫来了我再渲染给你总行了吧,其余的我还是做我的单页面,呵呵哒。
下面上一张图,说明原理。(原理跟rendora的差不多,下图的rendora你把他换成rendertron就好了)
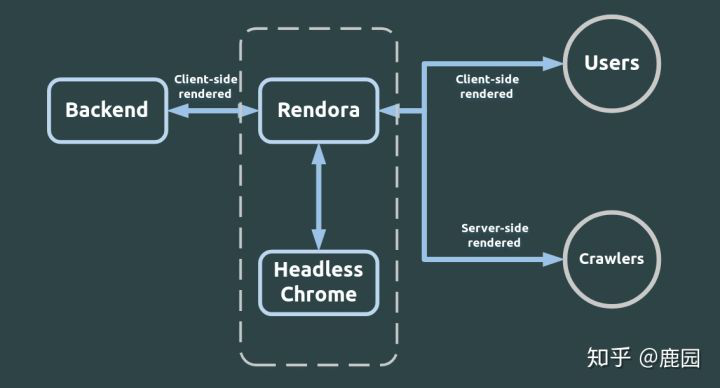
好了,现在讲讲怎么用,官网有用法,我给个链接rendertron官网。但是这里我讲一下具体怎么用的一种无脑方案,你照做就可以了,另外官网demo还有不少的坑和bug,我也挑出来和大家分享一下。
安装Chromeheadless
先在你的服务器上安装Chromeheadless,这是服务器上的无头chrome浏览器,如果你的服务器上已经有这个,那恭喜你了,因为安装过程的坑实在是太多太多了。网上关于安装Chromeheadless的教学贴很多,在此我贴几个。
先在你的服务器上安装Chromeheadless,这是服务器上的无头chrome浏览器,如果你的服务器上已经有这个,那恭喜你了,因为安装过程的坑实在是太多太多了。网上关于安装Chromeheadless的教学贴很多,在此我贴几个:
- 在ubuntu服务器上使用Chrome Headless
- linux 安装 Headless Chrome - bambooleaf - CSDN博客
- Chromeheadless安装与使用 - 探索技术世界 - CSDN博客
安装过程中你会遇到很多坑,不过不要紧,把error复制粘贴一下放百度,还是有很多解决方案的,毕竟Chromeheadless不是什么小众的东西。
安装rendertron
直接命令行输入
npm install -g rendertron
回车,就装好了。就这么简单?呵呵,有greatWall,安装过程中必需的某个东东下载不了,这时候要用代理,会的同学当然ok,但是不会的同学就没办法了,我自己一台大陆一台海外,大陆的装不了就改海外服务器了。
还有一个方案,也是官方给出的:
git clone https://github.com/GoogleChrome/rendertron.git
cd rendertron
npm install
npm run build
运行:
npm run start
能用第一种安装方案的推荐用第一种。
在你的express服务器程序中引入中间件rendertron-middleware
进入项目目录,命令行输入并回车
npm install --save express rendertron-middleware
在你的express服务器程序的代码中加入几行:
const express = require('express');const rendertron = require('rendertron-middleware');
const app = express();
app.use(rendertron.makeMiddleware({
proxyUrl: 'http://localhost:3000/render',}));
app.use(express.static('files'));app.listen(8080);
重点是插入的
app.use(rendertron.makeMiddleware({
proxyUrl: 'http://localhost:3000/render',}));
其中rendertron.makeMiddleware有好几个参数,github上说有proxyUrl、userAgentPattern、excludeUrlPattern、injectShadyDom、timeout,也就是有类似以下的设置。
app.use(rendertron.makeMiddleware({
proxyUrl: 'http://localhost:3000/render',
userAgentPattern:****,
excludeUrlPattern:****,
injectShadyDom:true or false, //这个参数一般不用设,用的时候这行删掉就好了 timeout:11000,//这个timeout超时参数亲测已经无效了,尴尬,用的时候也去掉这行就好}));
下面重点讲讲以上的userAgentPattern和excludeUrlPattern参数的含义和怎么设置。
userAgentPattern是用来写清楚哪些UA头需要服务器渲染,除此之外的请求都直接单页面推送。比如说:
const botUserAgents = [
'Baiduspider',
'bingbot',
'Embedly',
'facebookexternalhit',
'LinkedInBot',
'outbrain',
'pinterest',
'quora link preview',
'rogerbot',
'showyoubot',
'Slackbot',
'TelegramBot',
'Twitterbot',
'vkShare',
'W3C_Validator',
'WhatsApp',];//略n行代码app.use(rendertron.makeMiddleware({
//其他参数 userAgentPattern: new RegExp(botUserAgents.join('|'), 'i'),}));
把你要的爬虫UA头都写到一个数组里,然后用new RegExp()正则一下
excludeUrlPattern是指哪些文件格式需要在chromeheadless中被完全加载,用法如下
const staticFileExtensions = [
'ai', 'avi', 'css', 'dat', 'dmg', 'doc', 'doc', 'exe', 'flv',
'gif', 'ico', 'iso', 'jpeg', 'jpg', 'js', 'less', 'm4a', 'm4v',
'mov', 'mp3', 'mp4', 'mpeg', 'mpg', 'pdf', 'png', 'ppt', 'psd',
'rar', 'rss', 'svg', 'swf', 'tif', 'torrent', 'ttf', 'txt', 'wav',
'wmv', 'woff', 'xls', 'xml', 'zip',];//略n行代码app.use(rendertron.makeMiddleware({
//其他参数 userAgentPattern: new RegExp(\\.(${staticFileExtensions.join('|')})$, 'i'),}));
把你需要加载的文件后缀都写到一个数组里,然后用new RegExp()正则一下
至于proxyUrl参数的用法,如果rendertron+chromeheadless在本地服务器,那就写'http://localhost:3000/render'(rendertron启动后默认开启3000端口),如果是在别的服务器,那就写http://www.xxxx.com/render或者http://106.xx.xx.xxx:xxxx/render。
proxyUrl参数设置的就是遇到爬虫UA头后、转到rendertron用本地服务器上的chromeheadless浏览器渲染的地址。
好了,express服务器改写好后,正常启动他,然后再启动rendertron,方法也很简单,直接命令行输入rendertron就行了。
下面测试一下,命令行输入curl -A “baiduspider” http://你需要测试的网址(就是访问你的server程序对应的那个网址,即改写前的那个原来的网址),然后就能看到通过chromeheadless渲染好的html代码,大功告成!
rendertron的改进
有没有发现你每次curl以后都需要10s左右后才能返回数据,这种响应时间怎么可能用在SEO上呢??!!所以要改进一下咯。
在rendertron的github上有写到,可以在rendertron的根目录写一个config.json,里面可以设置datastoreCache(是否适用缓存,默认false),timeout(渲染超时,过了这个时间还没有渲染结束就硬性返回已渲染好的html,默认10000ms,即10s),port(端口,默认3000),width和height(渲染用的浏览器屏幕宽高,默认1000,这个在rendertron的另一个功能‘截图’上可以用到)。
然后你很天真的设置了config.json文件,把timeout改成3000ms——这差不多已经是搜索引擎认为你是优质网站所要求的响应时间的上限了。再一次curl,什么!!还是10s!!这个怎么搞哦!!
又一次大写的尴尬!下面来公布答案吧~rendertron的码源里面已经没有引用config.json里面的timeout参数了,这个参数没法通过外部设置,呵呵哒,坑。
好了,下面说解决方法。找到rendertron根目录,里面有个build文件夹,里面有个renderer.js文件,打开后,搜索timeout,一共有两处,后面都跟了10000这个值,把它改成你需要的2000或者之类的(单位ms),然后再次重新启动rendertron,在命令行输入
curl -A “baiduspider” http://你需要测试的网址(就是访问你的server程序对应的那个网址,即改写前的那个原来的网址)
可以发现只需要2s就有html代码返回了,搞定!
注:以上问题是针对npm install -g rendertron方式安装的rendertron,其他方式安装后是否有以上问题不一定。
如果你的渲染程序会崩,那就pm2 start rendertron。pm2真的挺好用,不熟悉的同学百度下就好了,满满的资料。
单页面(如react,vue)网站的服务器渲染 SSR 之 SEO 大杀器 Rendertron的更多相关文章
- 从单页应用(SPA)到服务器渲染(SSR)
从单页应用(SPA)到服务器渲染(SSR) 情景回顾 在学习Vue开发一个电商网站的管理后台时,使用到了一个组件 vue-quill-editor 主要是一个快捷的一个富文本编辑器 在使用这个组件的组 ...
- .htaccess A网站单页面301到B网站单页面
.htaccess 301问题 A网站 a.com/a.html 301到 B网站 b.com/b.html RewriteRule ^a.com/a.html$ http://www.b. ...
- 创建一个vue单页面应用
最最开始是要安装cli3 1.npm install -g @vue/cli 2.npm install -g @vue/cli-service-global 然后是创建单页面应用si ...
- 前端单页面富应用(SPA)的实现
一. 什么是单页面富应用? 单页面应用:Single Page Application 概念:Web应用即使不刷新也在不同的页面间切换,解决浏览器前进.后退等机制被破坏等问题.并且页面访问会被浏览器保 ...
- Cloud Test 单页面即时监测功能上线!
什么是即时监测? 即时监测,顾名思义是指输入 URL 后能够立即进行监测并展示结果,无需注册. 如下图,在输入框内输入需要监测的 URL,点击免费监测,即可展示网页监测结果: 图中我们可以看到页面各个 ...
- Nginx配置Web项目(多页面应用,单页面应用)
目前前端项目 可分两种: 多页面应用,单页面应用. 单页面应用 入口是一个html文件,页面路由由js控制,动态往html页面插入DOM. 多页面应用 是由多个html文件组成,浏览器访问的是对应服务 ...
- vue,react,angular本地配置nginx 环境单页面应用
一.起因:项目使用VUE,和react.构建单页面应用.在nginx的环境下只有一个index.html入口.这时候默认能够访问到vue,和react 路由 配置中的首页.内部连接也能够跳转但是不能给 ...
- Vue系列(1):单页面应用程序
前言:关于页面上的知识点,如有侵权,请看 这里 . 关键词:SPA.单个 HTML 文件.全靠 JS 操作.Virtual DOM.hash/history api 路由跳转.ajax 响应.按需加载 ...
- 处理 Vue 单页面应用 SEO 的另一种思路
vue-meta-info 官方地址: monkeyWangs/vue-meta-info (设置vue 单页面meta info信息,如果需要单页面SEO,可以和 prerender-spa-plu ...
随机推荐
- Spring Boot:实现MyBatis动态创建表
综合概述 在有些应用场景中,我们会有需要动态创建和操作表的需求.比如因为单表数据存储量太大而采取分表存储的情况,又或者是按日期生成日志表存储系统日志等等.这个时候就需要我们动态的生成和操作数据库表了. ...
- Laravel --- Laravel 5.3 发送邮件配置
版本:laravel 5.3 发送邮箱:QQ邮箱 根据官网以及别人的教程配置邮件发送,并且对配置过程中遇到的坑进行填补,做一总结,留待参考. 一.开启stmp 进入QQ邮箱,设置-服务,开启smtp. ...
- Java虚拟机详解(一)------简介
本系列博客我们将以当前默认的主流虚拟机HotSpot 为例,详细介绍 Java虚拟机.以 JDK1.7 为主,同时介绍与 JDK1.8 的不同之处,通过Oracle官网以及各种文献进行整理,并加以验证 ...
- Spring_One
Spring_01 Spring概述 Spring是分层的Java2E应用full-stack轻量级开源框架,,以IoC(Inverse Of Control:反转控制)和AOP(Aspect Ori ...
- Kali Linux Web渗透测试手册(第二版) - 1.1 - Firefox浏览器下安装一些常用的插件
一.配置KALI Linux和渗透测试环境 在这一章,我们将覆盖以下内容: l 在Windows和Linux上安装VirtualBox l 创建一个Kali Linux虚拟机 l 更新和升级Ka ...
- 【JVM】02垃圾回收机制
垃圾回收 垃圾回收策略https://blog.csdn.net/u010425776/article/details/51189318 程序计数器.Java虚拟机栈.本地方法栈都是线程私有的,也就是 ...
- 浅说——数位DP
老子听懂了!!!!! 好感动!!! 不说多了:Keywords: 数位DP,二进制,异或. “在信息学竞赛中,有一类与数位有关的区间统计问题.这类问题往往具有比较浓厚的数学味道,无法暴力求解,需要在数 ...
- POJ 1741:Tree(树上点分治)
题目链接 题意 给一棵边带权树,问两点之间的距离小于等于K的点对有多少个. 思路 <分治算法在树的路径问题中的应用> 图片转载于http://www.cnblogs.com/Paul-Gu ...
- ConnectionPool实现redis在python中的连接
这篇文章主要介绍了Python与Redis的连接教程,Redis是一个高性能的基于内存的数据库,需要的朋友可以参考下 今天在写zabbix storm job监控脚本的时候用到了python的re ...
- C# 实现最小化托盘功能
winform程序实现最小化托盘显示 1.创建新的解决方案,解决方案名称和路径自定义 2.在解决方案下面新建一个窗体,从左边工具箱,将NotifyIcon拖过去窗体,该控件的作用是:运行程序期间在Wi ...