Python登录豆瓣并爬取影评

上一篇我们讲过Cookie相关的知识,了解到Cookie是为了交互式web而诞生的,它主要用于以下三个方面:
- 会话状态管理(如用户登录状态、购物车、游戏分数或其它需要记录的信息)
- 个性化设置(如用户自定义设置、主题等)
- 浏览器行为跟踪(如跟踪分析用户行为等)
我们今天就用requests库来登录豆瓣然后爬取影评为例子,
用代码讲解下Cookie的会话状态管理(登录)功能。
此教程仅用于学习,不得商业获利!如有侵害任何公司利益,请告知删除!
一、需求背景
之前猪哥带大家爬取了优酷的弹幕并生成词云图片,发现优酷弹幕的质量并不高,有很多介词和一些无效词,比如:哈哈、啊啊、这些、那些。。。而豆瓣口碑一直不错,有些书或者电影的推荐都很不错,所以我们今天来爬取下豆瓣的影评,然后生成词云,看看效果如何吧!
二、功能描述
我们使用requests库登录豆瓣,然后爬取影评,最后生成词云!
为什么我们之前的案例(京东、优酷等)中不需要登录,而今天爬取豆瓣需要登录呢?那是因为豆瓣在没有登录状态情况下只允许你查看前200条影评,之后就需要登录才能查看,这也算是一种反扒手段!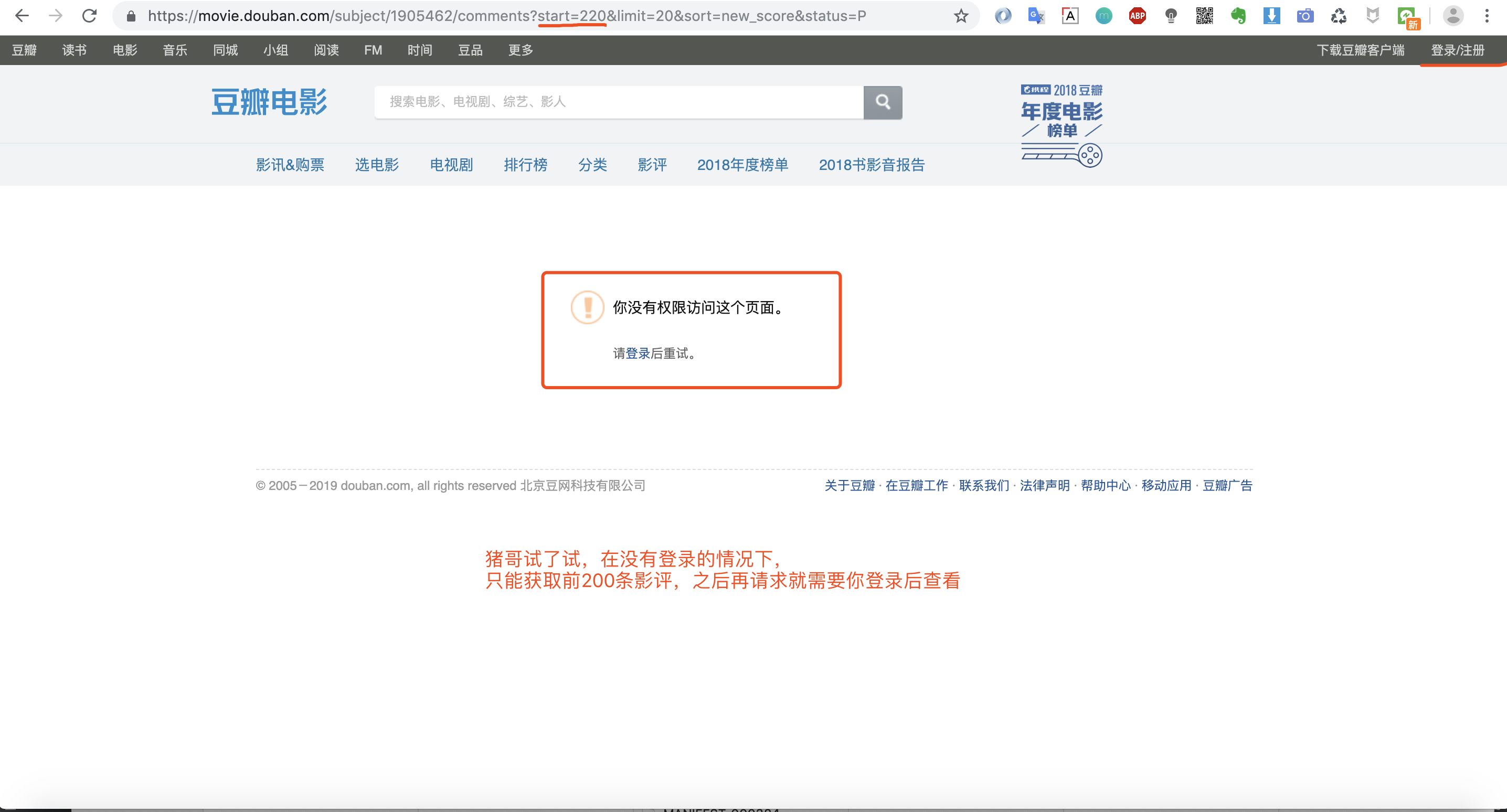
三、技术方案
我们看下简单的技术方案,大致可以分为三部分:
- 分析豆瓣的登录接口并用requests库实现登录并保存cookie
- 分析豆瓣影评接口实现批量抓取数据
- 使用词云做影评数据分析
方案确定之后我们就开始实际操作吧!
四、登录豆瓣
做爬虫前我们都是先从浏览器开始,使用调试窗口查看url。
1.分析豆瓣登录接口
打开登录页面,然后调出调试窗口,输入用户名和密码,点击登录。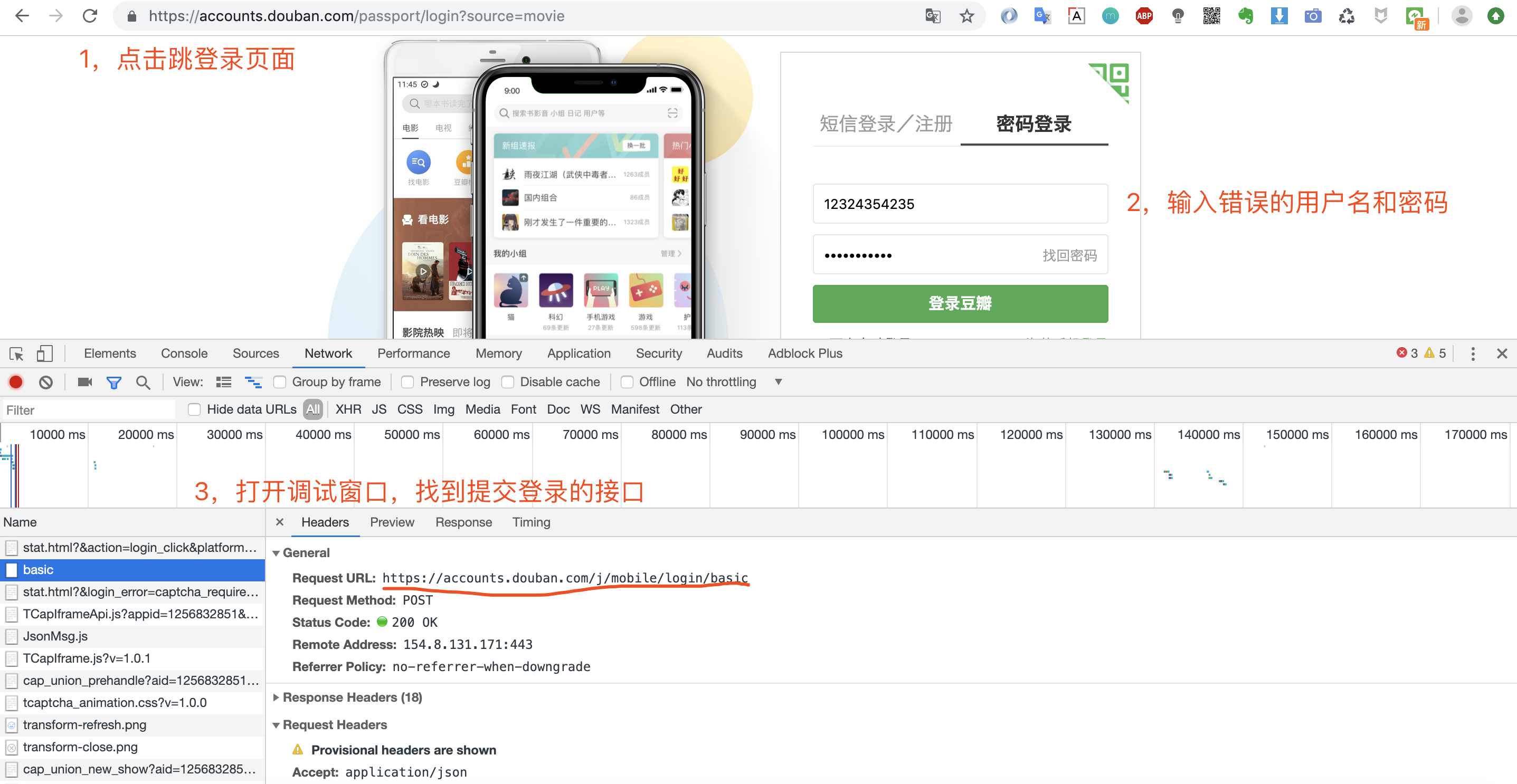
这里猪哥建议输入错误的密码,这样就不会因为页面跳转而捕捉不到请求!上面我们便获取到登录请求的URL:https://accounts.douban.com/j/mobile/login/basic
因为是一个POST请求,所以我们还需要看看请求登录时携带的参数,我们将调试窗口往下拉查看Form Data。
2.代码实现登录豆瓣
得到登录请求URL和参数后,我们就可以来用requests库来写一个登录功能!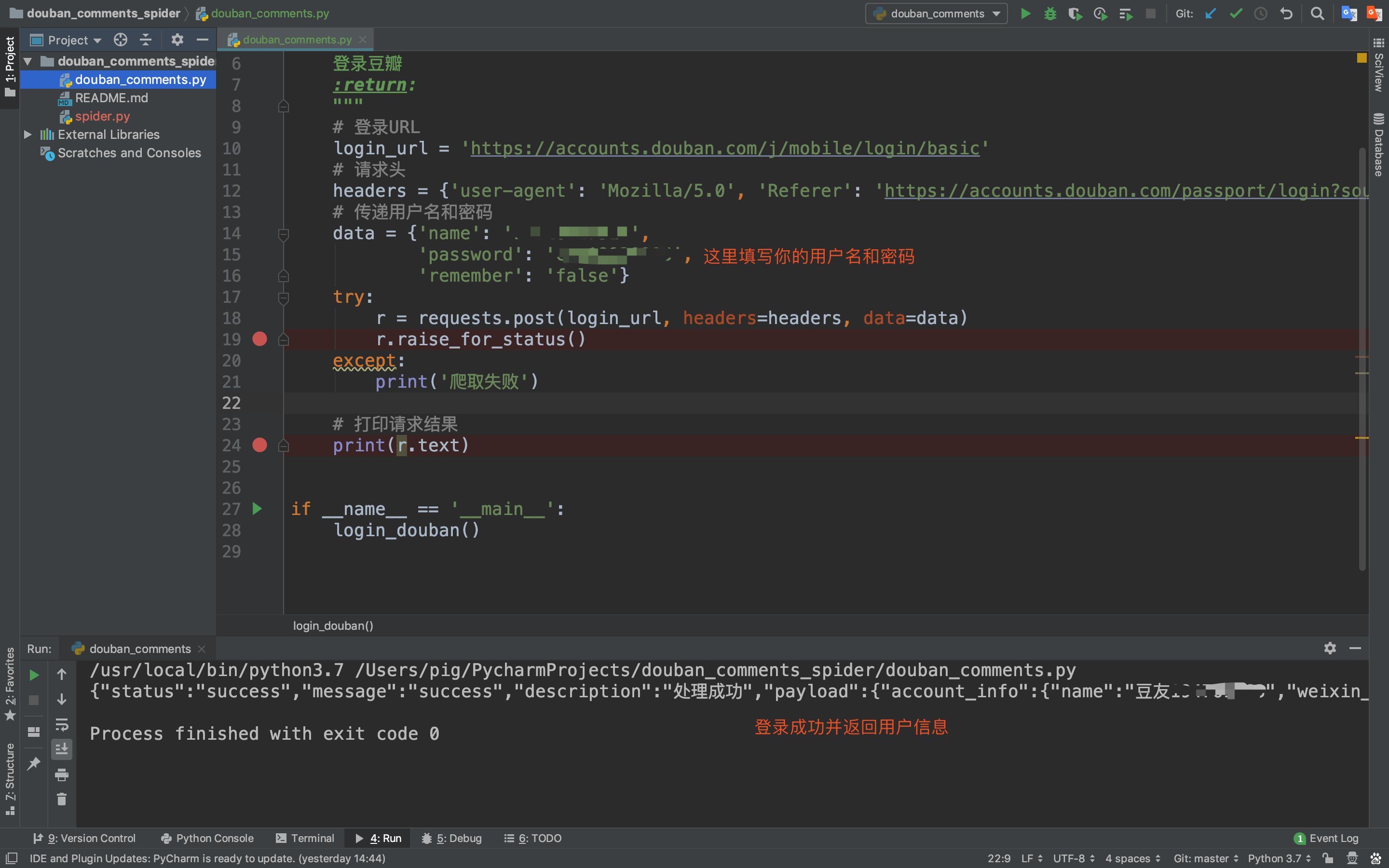
3.保存会话状态
上期我们在爬取优酷弹幕的时候我们是复制浏览器中的Cookie到请求头中这来来保存会话状态,但是我们如何让代码自动保存Cookie呢?
也许你见过或者使用过urllib库,它用来保存Cookie的方式如下:
cookie = http.cookiejar.CookieJar()
handler = urllib.request.HttpCookieProcessor(cookie)
opener = urllib.request.build_opener(handler)
opener(url)
但是前面我们介绍requests库的时候就说过:
requests库是一个基于urllib/3的第三方网络库,它的特点是功能强大,API优雅。由上图我们可以看到,对于http客户端python官方文档也推荐我们使用requests库,实际工作中requests库也是使用的比较多的库。
所以今天我们来看看requests库是如何优雅的帮我们自动保存Cookie的?我们来对代码做一点微调,使之能自动保存Cookie维持会话状态!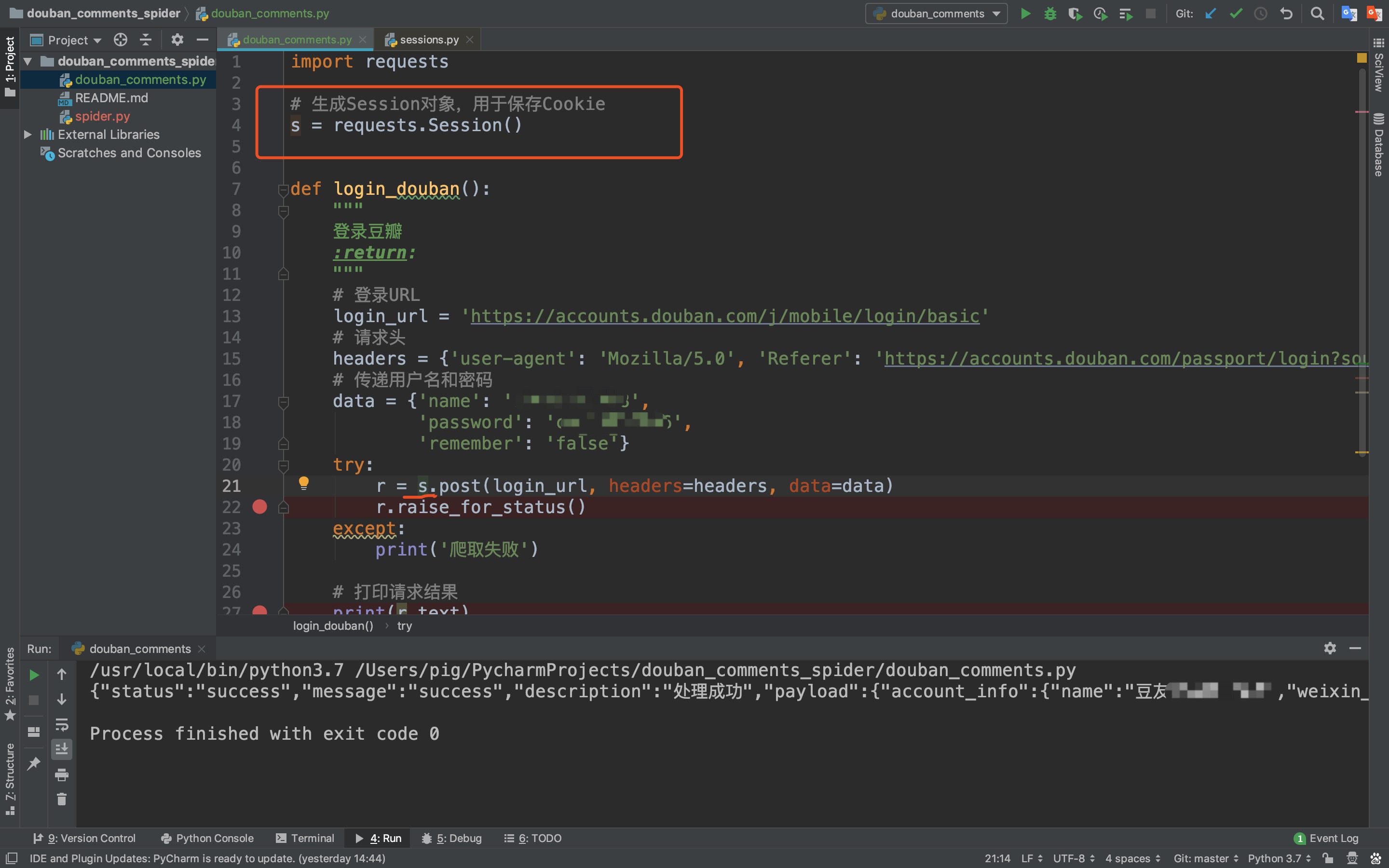
上述代码中,我们做了两处改动:
- 在最上面增加一行
s = requests.Session(),生成Session对象用来保存Cookie - 发起请求不再是原来的requests对象,而是变成了Session对象
我们可以看到发起请求的对象变成了session对象,它和原来的requests对象发起请求方式一样,只不过它每次请求会自动带上Cookie,所以后面我们都用Session对象来发起请求!
4.这个Session对象是我们常说的session吗?
讲到这里也许有同学会问:requests.Session对象是不是我们常说的session呢?
答案当然不是,我们常说的session是保存在服务端的,而requests.Session对象只是一个用于保存Cookie的对象而已,我们可以看看它的源码介绍
所以大家千万不要将requests.Session对象与session技术搞混了!
五、爬取影评
我们实现了登录和保存会话状态之后,就可以开始干正事啦!
1.分析豆瓣影评接口
首先在豆瓣中找到自己想要分析的电影,这里猪哥选择一部美国电影《荒野生存》,因为这部电影是猪哥心中之最,没有之一!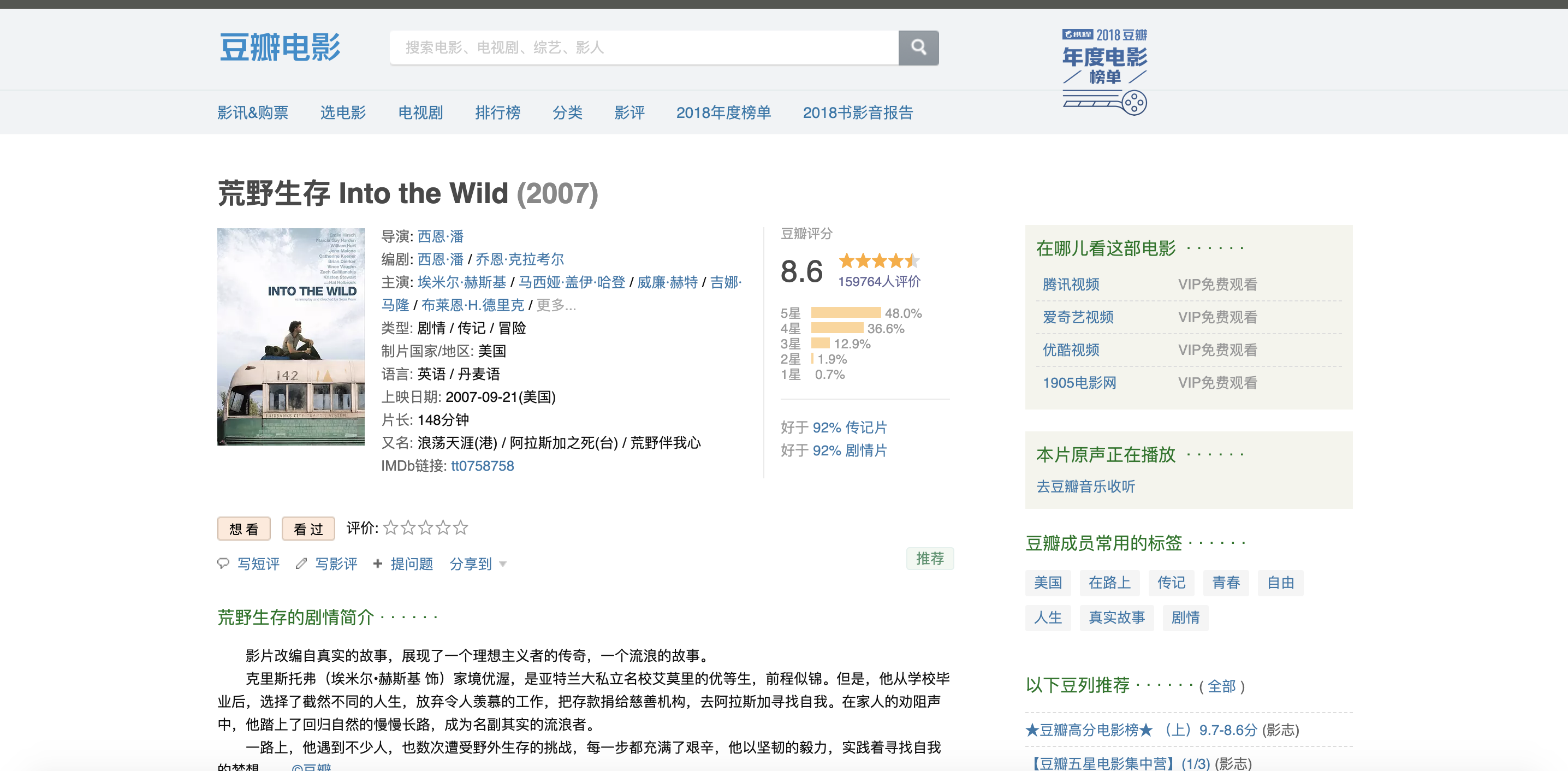
然后下拉找到影评,调出调试窗口,找到加载影评的URL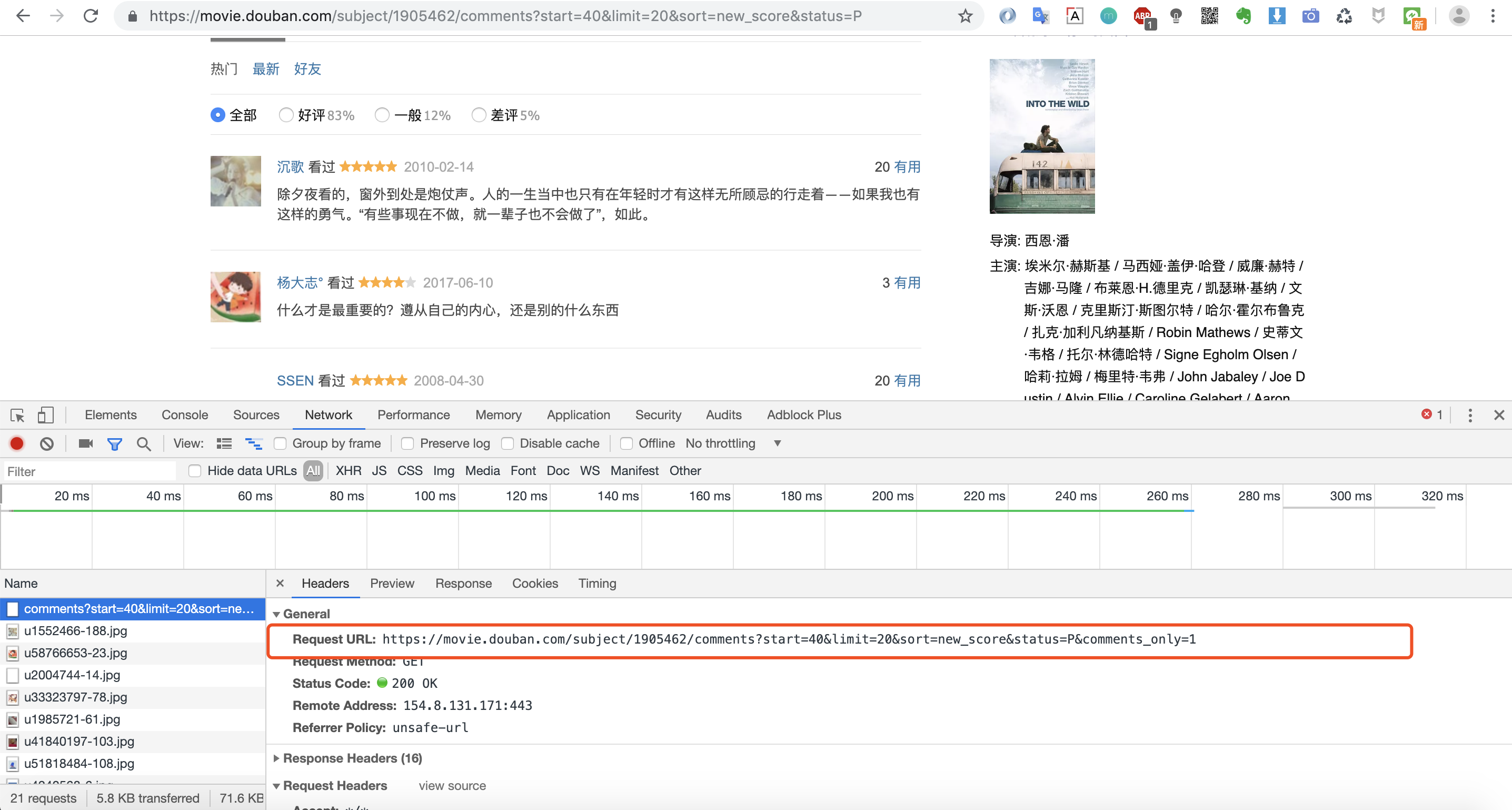
2.爬取一条影评数据
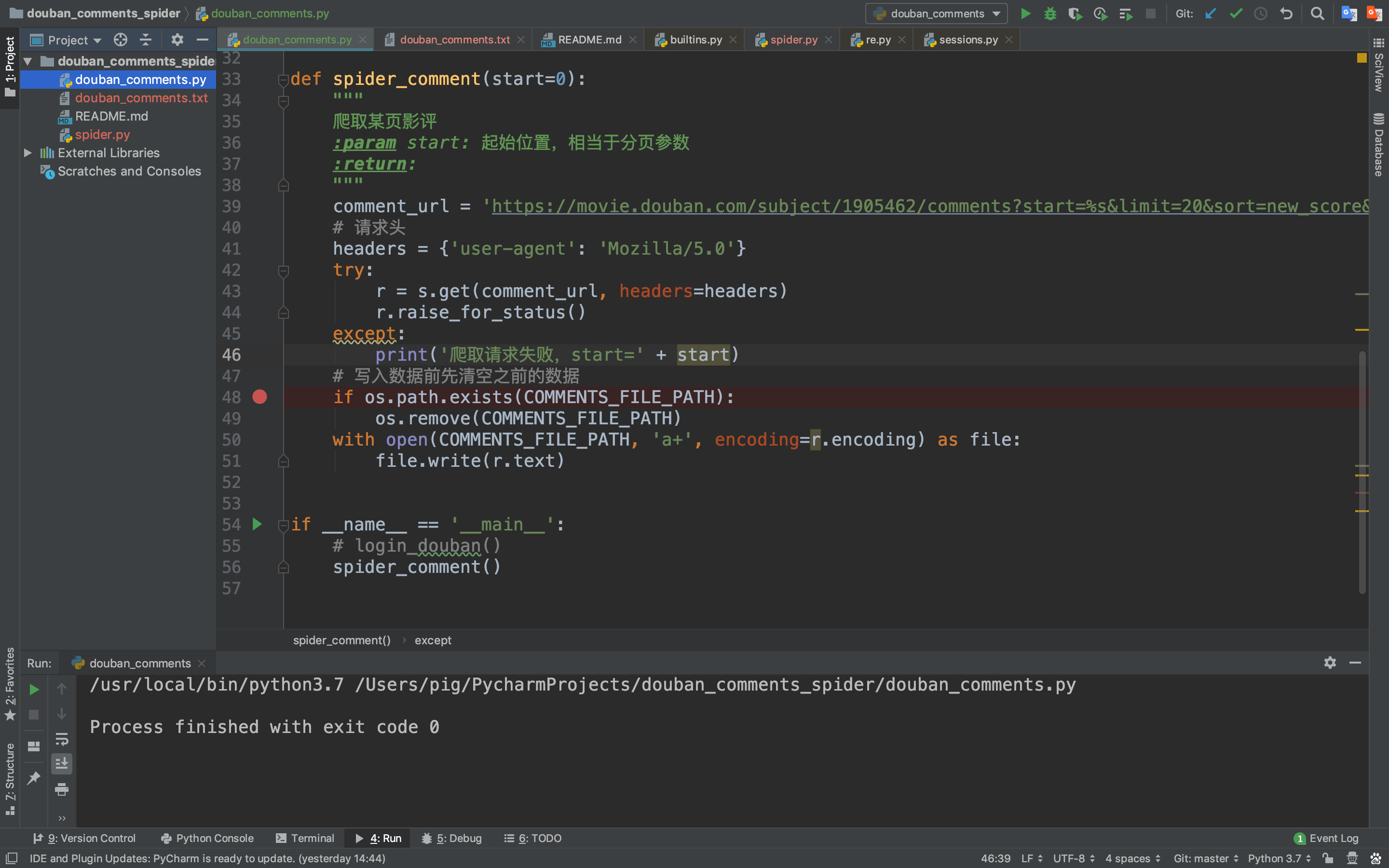
但是爬取下来的是一个HTML网页数据,我们需要将影评数据提取出来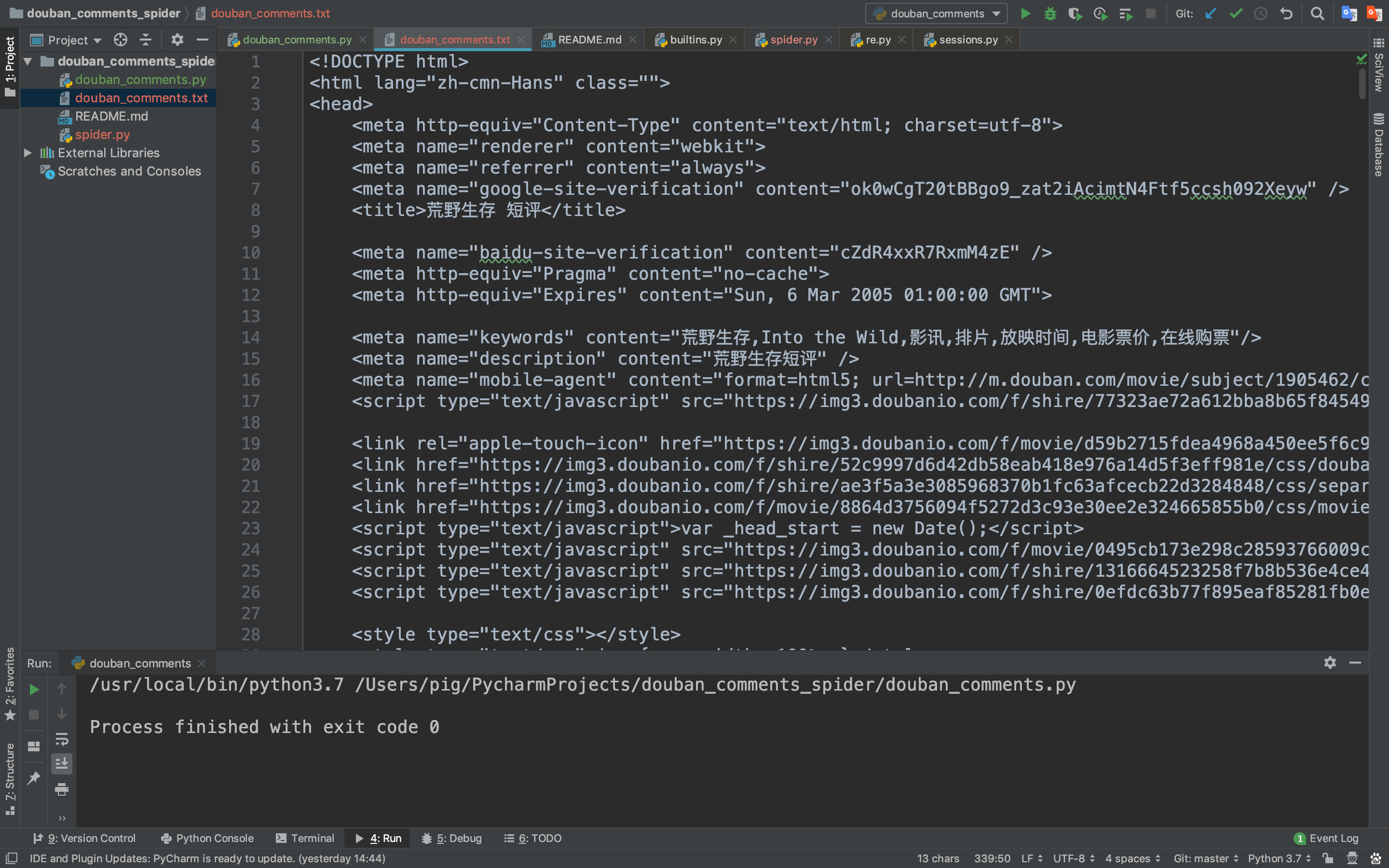
3.影评内容提取
上图中我们可以看到爬取返回的是html,而影评数据便是嵌套在html标签中,如何提取影评内容呢?
这里我们使用正则表达式来匹配想要的标签内容,当然也有更高级的提取方法,比如使用某些库(比如bs4、xpath等)去解析html提取内容,而且使用库效率也比较高,但这是我们后面的内容,我们今天就用正则来匹配!
我们先来分析下返回html 的网页结构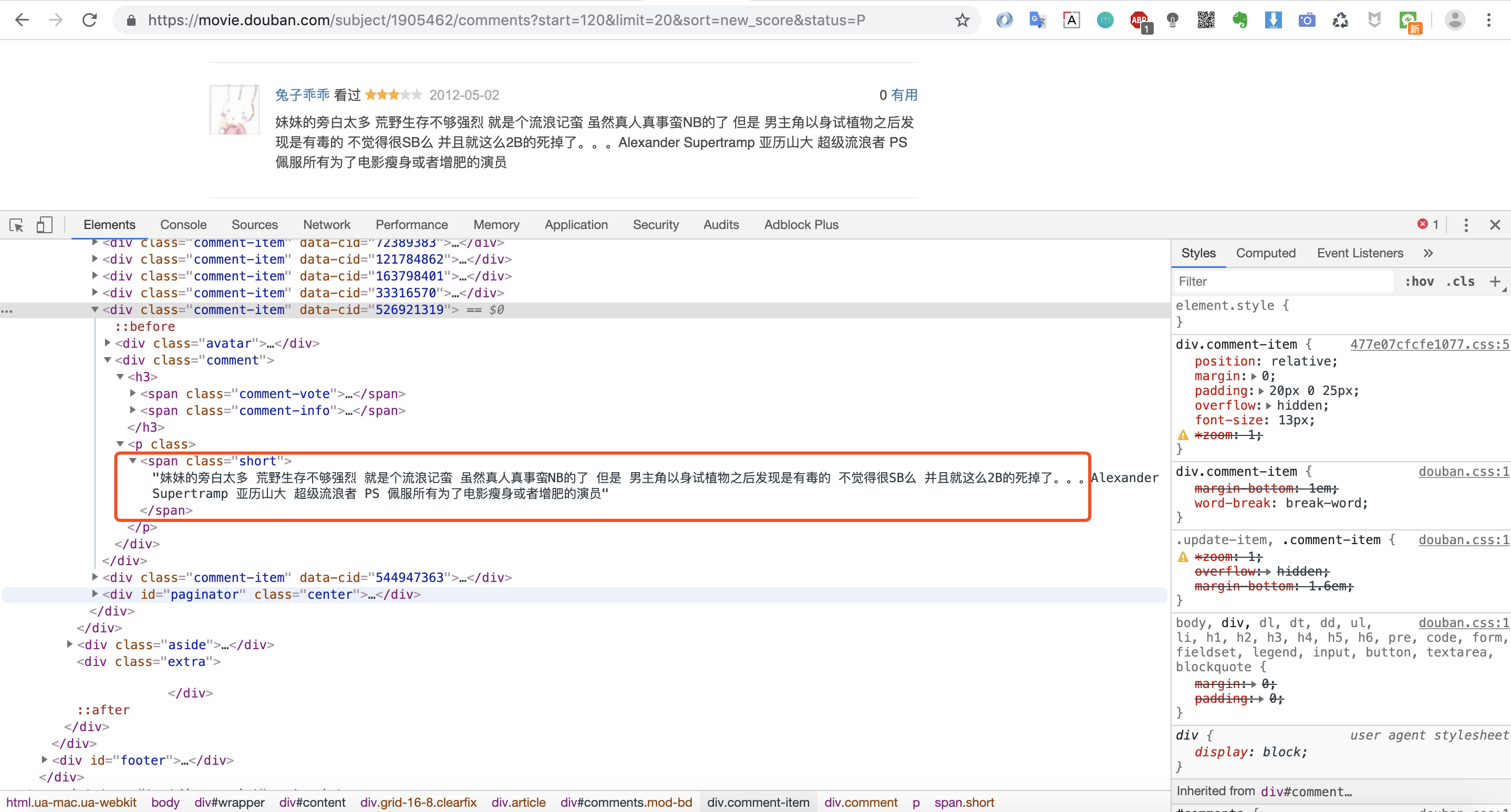
我们发现影评内容都是在<span class="short"></span>这个标签里,那我们 就可以写正则来匹配这个标签里的内容啦!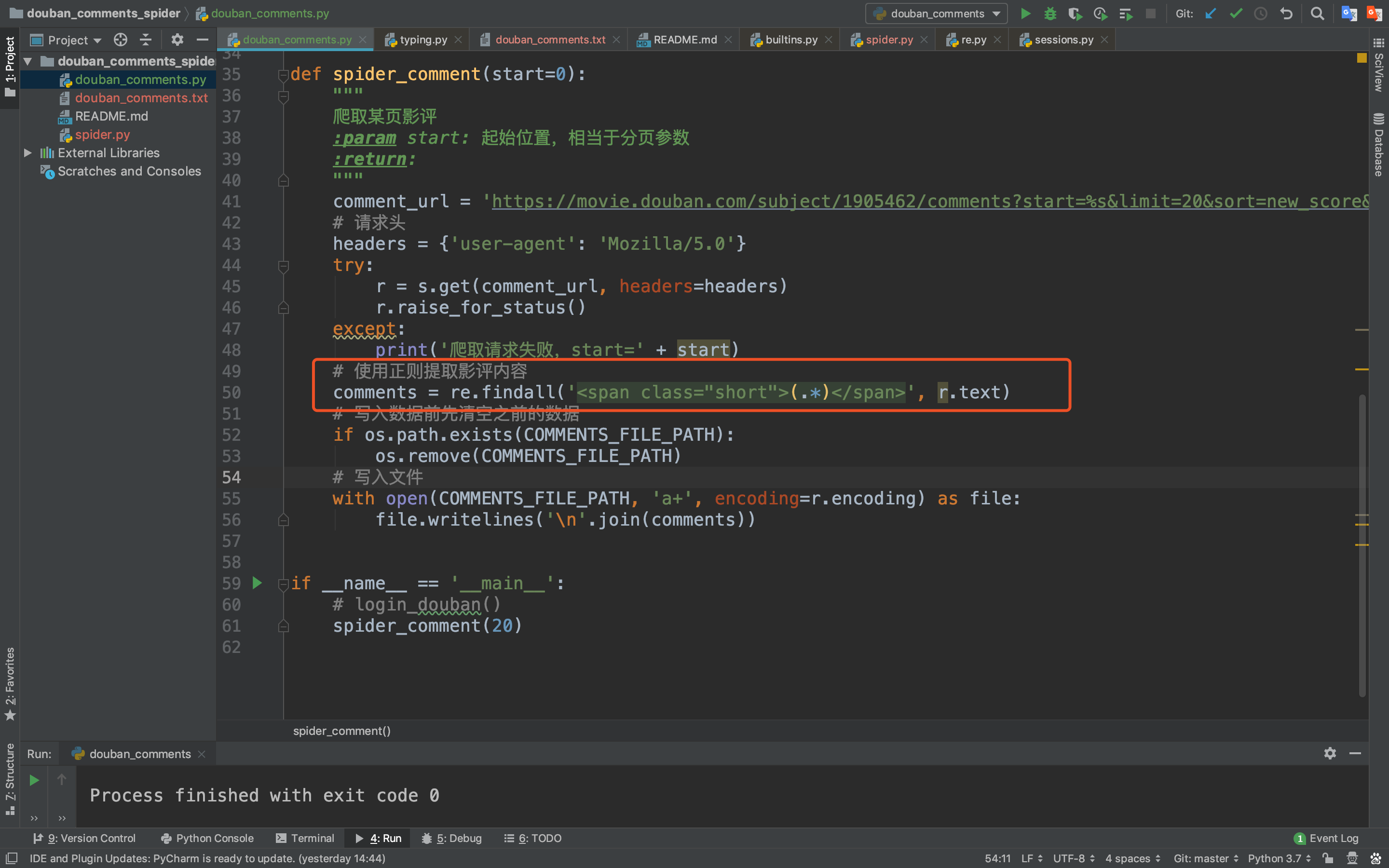
检查下提取的内容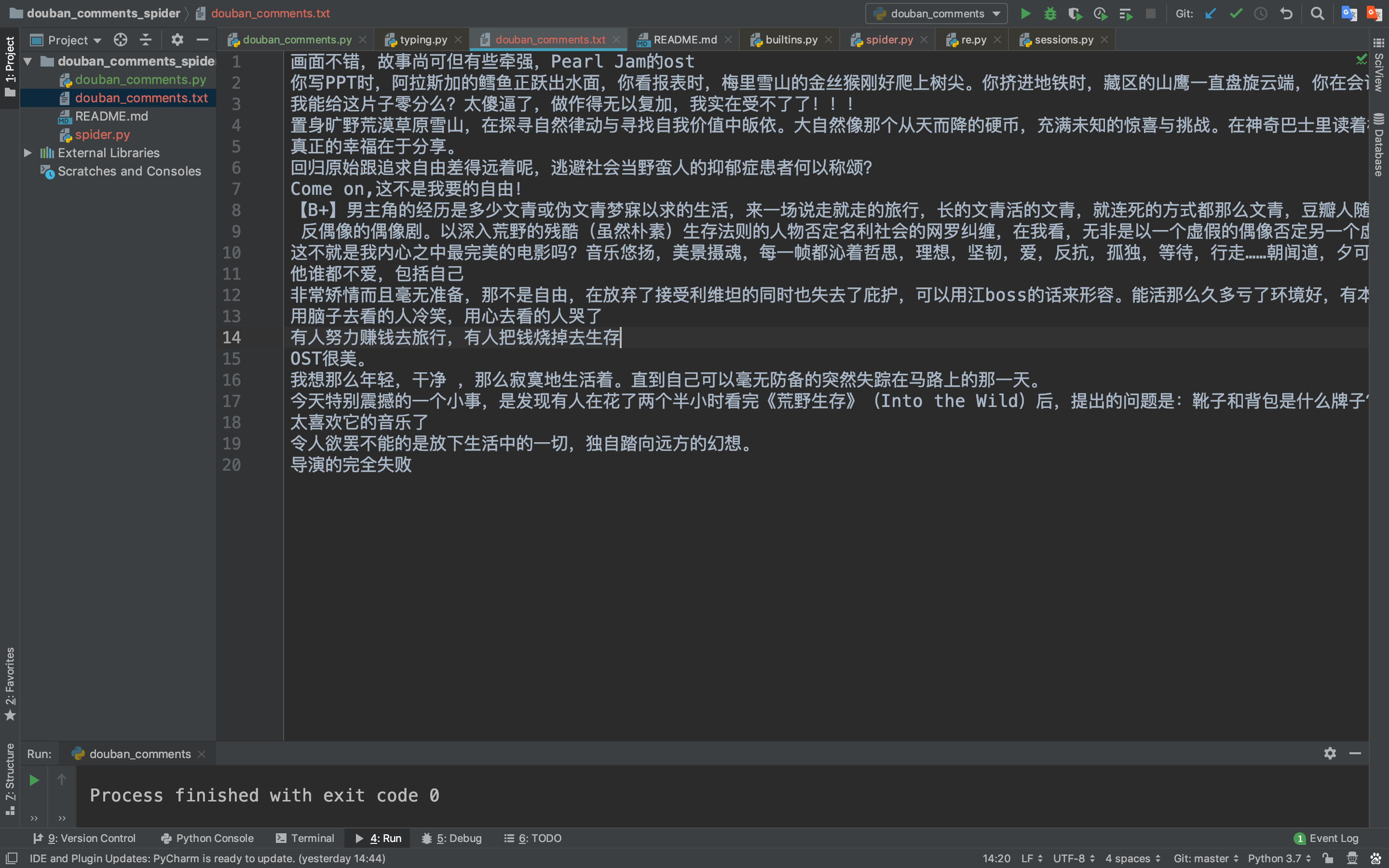
4.批量爬取
我们爬取、提取、保存完一条数据之后,我们来批量爬取一下。根据前面几次爬取的经验,我们知道批量爬取的关键在于找到分页参数,我们可以很快发现URL中有一个start参数便是控制分页的参数。
这里只爬取了25页就爬完,我们可以去浏览器中验证一下,是不是真的只有25页,猪哥验证过确实只有25页!
六、分析影评
数据抓取下来之后,我们就来使用词云分析一下这部电影吧!
基于使用词云分析的案例前面已经讲过两个了,所以猪哥只会简单的讲解一下!
1.使用结巴分词
因为我们下载的影评是一段一段的文字,而我们做的词云是统计单词出现的次数,所以需要先分词!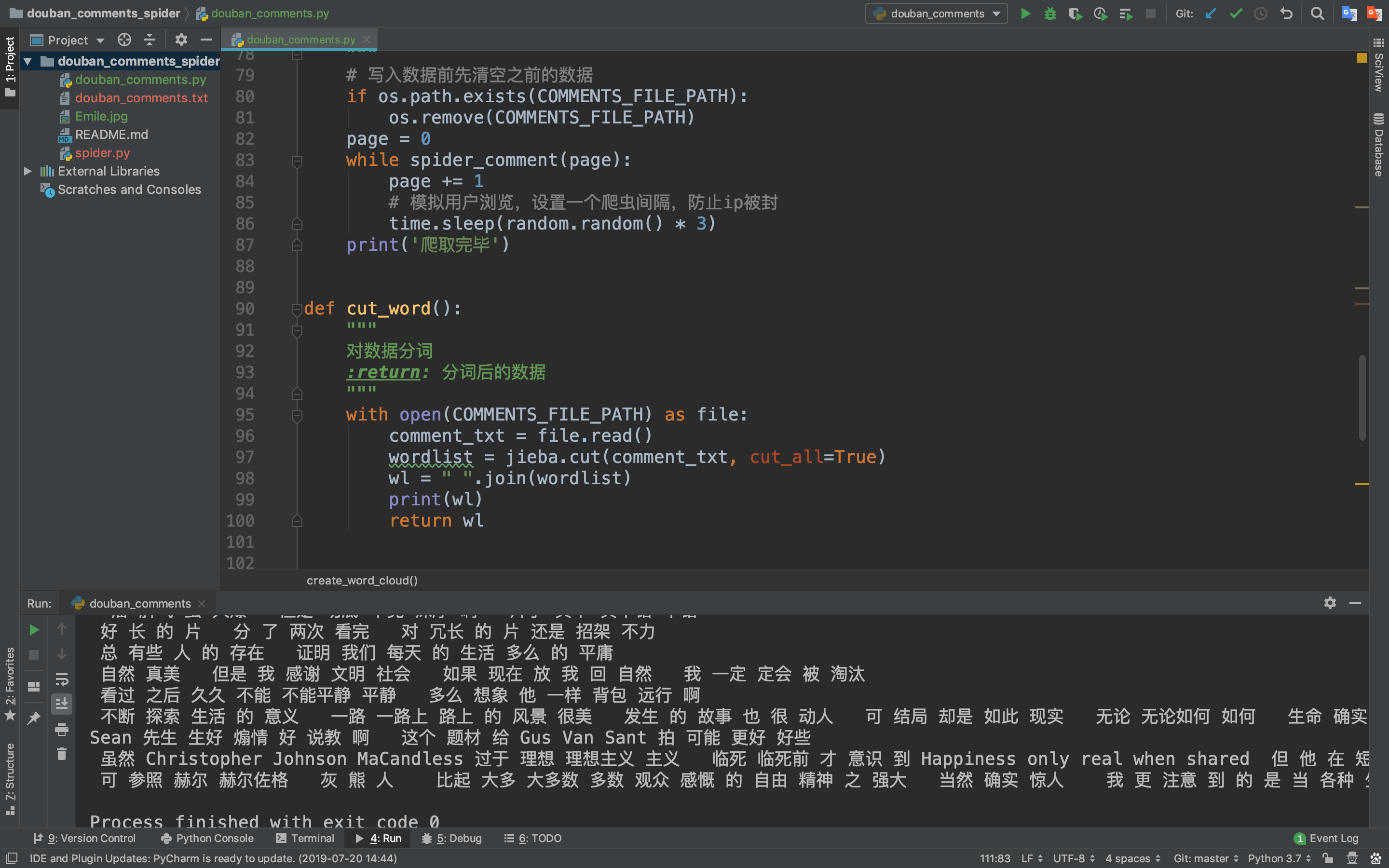
2.使用词云分析
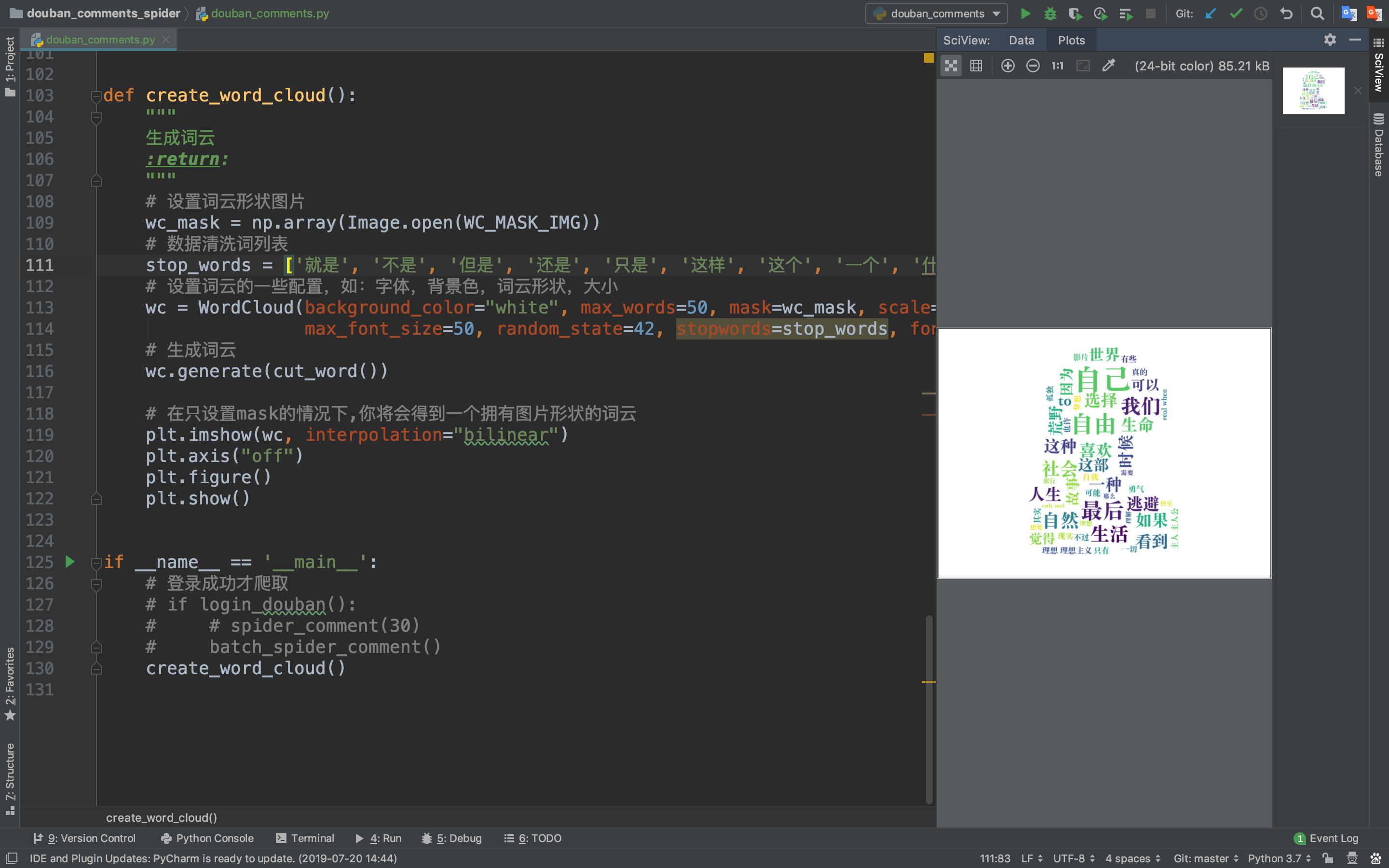
最终成果:
从这些词中我们可以知道这是关于一部关于追寻自我与现实生活的电影,猪哥裂墙推荐!!!
七、总结
今天我们以爬取豆瓣为例子,学到了不少的东西,来总结一下:
- 学习如何使用requests库发起POST请求
- 学习了如何使用requests库登录网站
- 学习了如何使用requests库的Session对象保持会话状态
- 学习了如何使用正则表达式提取网页标签中的内容
鉴于篇幅有限,爬虫过程中遇到的很多细节和技巧并没有完全写出来,所以希望大家能自己动手实践,当然也可以加入到猪哥的Python新手交流群中和大家一起学习,遇到问题也可以在群里提问!加群请加猪哥微信:it-pig66,好友申请格式:加群-xxx!
源码地址:https://github.com/pig6/douban_comments_spider
Python登录豆瓣并爬取影评的更多相关文章
- Scrapy 通过登录的方式爬取豆瓣影评数据
Scrapy 通过登录的方式爬取豆瓣影评数据 爬虫 Scrapy 豆瓣 Fly 由于需要爬取影评数据在来做分析,就选择了豆瓣影评来抓取数据,工具使用的是Scrapy工具来实现.scrapy工具使用起来 ...
- Python爬虫实例:爬取豆瓣Top250
入门第一个爬虫一般都是爬这个,实在是太简单.用了 requests 和 bs4 库. 1.检查网页元素,提取所需要的信息并保存.这个用 bs4 就可以,前面的文章中已经有详细的用法阐述. 2.找到下一 ...
- Python爬虫教程-17-ajax爬取实例(豆瓣电影)
Python爬虫教程-17-ajax爬取实例(豆瓣电影) ajax: 简单的说,就是一段js代码,通过这段代码,可以让页面发送异步的请求,或者向服务器发送一个东西,即和服务器进行交互 对于ajax: ...
- Python爬虫实例:爬取B站《工作细胞》短评——异步加载信息的爬取
很多网页的信息都是通过异步加载的,本文就举例讨论下此类网页的抓取. <工作细胞>最近比较火,bilibili 上目前的短评已经有17000多条. 先看分析下页面 右边 li 标签中的就是短 ...
- Python爬虫实例:爬取猫眼电影——破解字体反爬
字体反爬 字体反爬也就是自定义字体反爬,通过调用自定义的字体文件来渲染网页中的文字,而网页中的文字不再是文字,而是相应的字体编码,通过复制或者简单的采集是无法采集到编码后的文字内容的. 现在貌似不少网 ...
- 【转载】教你分分钟学会用python爬虫框架Scrapy爬取心目中的女神
原文:教你分分钟学会用python爬虫框架Scrapy爬取心目中的女神 本博文将带领你从入门到精通爬虫框架Scrapy,最终具备爬取任何网页的数据的能力.本文以校花网为例进行爬取,校花网:http:/ ...
- python爬虫-基础入门-爬取整个网站《3》
python爬虫-基础入门-爬取整个网站<3> 描述: 前两章粗略的讲述了python2.python3爬取整个网站,这章节简单的记录一下python2.python3的区别 python ...
- python爬虫-基础入门-爬取整个网站《2》
python爬虫-基础入门-爬取整个网站<2> 描述: 开场白已在<python爬虫-基础入门-爬取整个网站<1>>中描述过了,这里不在描述,只附上 python3 ...
- python爬虫-基础入门-爬取整个网站《1》
python爬虫-基础入门-爬取整个网站<1> 描述: 使用环境:python2.7.15 ,开发工具:pycharm,现爬取一个网站页面(http://www.baidu.com)所有数 ...
随机推荐
- webform的图片防盗链
最近用到域的问题,不是同一主机的请求将不允许请求此页面. 这其实和图片防盗链的本质是一样的. 通过两个属性:由于当时用的aspx视图引擎,所以需要通过HttpContext.Current才能拿到ht ...
- Linux ADF(Atomic Display Framework)浅析---概述
概述 因为工作关系,最近有涉及到ADF(Atomic Display Framework)相关的内容,部分内容来自互联网 ADF(Atomic Display Framework)是Google新增的 ...
- Delphi For Linux Compiler
Embarcadero is about to release a new Delphi compiler for the Linux platform. Here are some of the k ...
- 使用pjax实现类似github无刷新更改页面url
pjax=pushState+ajax,相信用过github的同学都知道,github部分页面采用了pjax这个项目来实现ajax无刷新加载的同时改变页面url.一起来学习一下这个插件吧. 我们都知道 ...
- 基于python实现的三方组件----Celery
一.基于python实现的三方组件----Celery 1.作用 用于异步周期任务的处理 2.Celery的组成 (1)任务 app (2)记录任务的缓存(通常用redis或rabbitMQ) 任务记 ...
- pycharm安装及配置全过程
首先要准备两个文件,一是pycharm-community,二是python-3.7.2-amd. PyCharm 的下载地址:http://www.jetbrains.com/pycharm/dow ...
- 【转】 远程连接mysql
转自:http://www.linuxidc.com/Linux/2013-05/84813.htm 1.确认能ping通 2.确认端口能telnet通.如果user表的host值是localhost ...
- 跟我学SpringCloud | 第一篇:介绍
首先讲一下我为什么要写这一系列的文章,现在网上大量的springcloud相关的文章,使用的springboot和springcloud的版本都相对比较老,很多还是在使用springboot1.x的版 ...
- Java学习笔记——三层架构
Layer: UI层: user interface 用户接口层 Biz层: service business login layer 业务逻辑层 DAO层: Date Access Obje ...
- python 基本数据类型之列表
#列表是可变类型,可以增删改查#字符串不可变类型,不能修改,只能生成新的值. #1.追加 # user_list = ['李泉','刘一','刘康','豆豆','小龙'] # user_list.ap ...