pgsql查询优化之模糊查询
前言
一直以来,对于搜索时模糊匹配的优化一直是个让人头疼的问题,好在强大pgsql提供了优化方案,下面就来简单谈一谈如何通过索引来优化模糊匹配
案例
我们有一张千万级数据的检查报告表,需要通过检查报告来模糊搜索某个条件,我们先创建如下索引:
CREATE INDEX lab_report_report_name_index ON lab_report USING btree (report_name);
然后搜个简单的模糊匹配条件如 LIKE "血常规%",可以发现查询计划生成如下,索引并没有被使用上,这是因为传统的btree索引并不支持模糊匹配
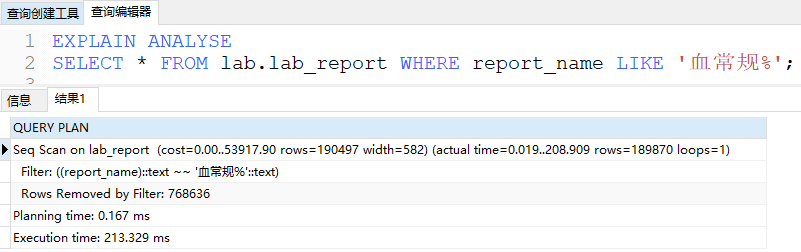
查阅文档后发现,pgsql可以在Btree索引上指定操作符:text_pattern_ops、varchar_pattern_ops和 bpchar_pattern_ops,它们分别对应字段类型text、varchar和 char,官方解释为“它们与默认操作符类的区别是值的比较是严格按照字符进行而不是根据区域相关的排序规则。这使得这些操作符类适合于当一个数据库没有使用标准“C”区域时被使用在涉及模式匹配表达式(LIKE或POSIX正则表达式)的查询中。”, 有些抽象,我们先试试看。创建如下索引并查询刚才的条件 LIKE"血常规%":(参考pgsql的文档 https://www.postgresql.org/docs/10/indexes-opclass.html)
CREATE INDEX lab_report_report_name_index ON lab.lab_report (report_name varchar_pattern_ops);

发现确实可以走索引扫描 ,执行时间也从213ms优化到125ms,但是,如果搜索LIKE "%血常规%"就又会走全表扫描了! 这里我们引入本篇博客的主角"pg_trgm"和"pg_bigm"。
创建这两个索引前分别需要引入如下两个扩展包 :
CREATE EXTENSION pg_trgm;
CREATE EXTENSION pg_bigm;
这两个索引的区别是:“pg_tigm”为pgsql官方提供的索引,"pg_tigm"为日本开发者提供。下面是详细的对比:(参考pg_bigm的文档 http://pgbigm.osdn.jp/pg_bigm_en-1-2.html)
Comparison with pg_trgm
The pg_trgm contrib module which provides full text search capability using 3-gram (trigram) model is included in PostgreSQL. The pg_bigm was developed based on the pg_trgm. They have the following differences:
| Functionalities and Features | pg_trgm | pg_bigm |
|---|---|---|
| Phrase matching method for full text search | 3-gram | 2-gram |
| Available index | GIN and GiST | GIN only |
| Available text search operators | LIKE (~~), ILIKE (~~*), ~, ~* | LIKE only |
| Full text search for non-alphabetic language (e.g., Japanese) |
Not supported (*1) | Supported |
| Full text search with 1-2 characters keyword | Slow (*2) | Fast |
| Similarity search | Supported | Supported (version 1.1 or later) |
| Maximum indexed column size | 238,609,291 Bytes (~228MB) | 107,374,180 Bytes (~102MB) |
- (*1) You can use full text search for non-alphabetic language by commenting out KEEPONLYALNUM macro variable in contrib/pg_trgm/pg_trgm.h and rebuilding pg_trgm module. But pg_bigm provides faster non-alphabetic search than such a modified pg_trgm.
- (*2) Because, in this search, only sequential scan or index full scan (not normal index scan) can run.
pg_bigm 1.1 or later can coexist with pg_trgm in the same database, but pg_bigm 1.0 cannot.
如无特殊要求推荐使用"pg_bigm",我们测试一下效果:
CREATE INDEX lab_report_report_name_index ON lab_report USING gin (report_name public.gin_bigm_ops);
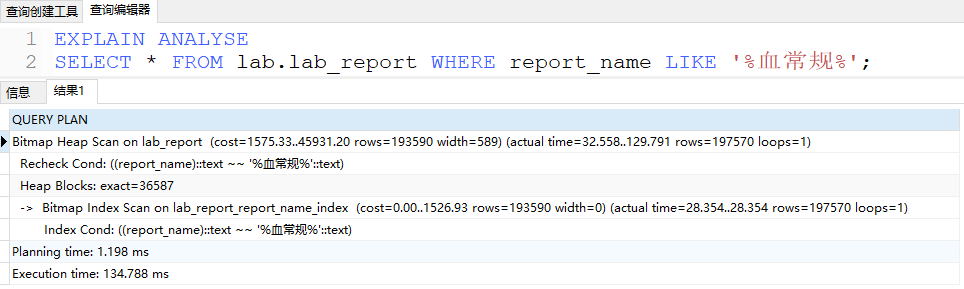
可以使用位图索引扫描,对于本次案例,使用pg_trgm效果同pg_bigm。
以上
本文只是简单的介绍许多细节并未做深入的分析,欢迎留言指教或者讨论
pgsql查询优化之模糊查询的更多相关文章
- oracle数据库使用hint来让模糊查询走索引
在没有创建数据直方图之前,查询优化器是cbo,可能不会选择代价最低(效率最高)的方式查询. 先创建表 --日语假名表 CREATE TABLE JAPANESE_SOUNDMARK ( ID INTE ...
- Oracle 模糊查询 优化
模糊查询是数据库查询中经常用到的,一般常用的格式如下: (1)字段 like '%关键字%' 字段包含"关键字"的记录 即使在目标字段建立索引也不会走索引,速度最慢 (2 ...
- Mybatis框架的模糊查询(多种写法)、删除、添加(四)
学习Mybatis这么多天,那么我给大家分享一下我的学习成果.从最基础的开始配置. 一.创建一个web项目,看一下项目架构 二.说道项目就会想到需要什么jar 三.就是准备大配置链接Orcl数据库 & ...
- js—模糊查询
首先要明白什么是模糊查询(废话又来了),就是根据关键字把列表中符合关键字的一项或某项罗列出来,也就是要检查列表的每一项中是否含有关键字,因此抽象一下就是一个字符串中是否含有某个字符或者字符串. 以下例 ...
- mybatis : trim标签, “等于==”经验, CDATA标签 ,模糊查询CONCAT,LIKE
一.My Batis trim标签有点类似于replace效果. trim 属性, prefix:前缀覆盖并增加其内容 suffix:后缀覆盖并增加其内容 prefixOverrides:前缀判断的条 ...
- combobox实现模糊查询自动填充
利用winform设计软件界面时,经常用到combobox控件,但有时需要绑定数据表中的数据,更进一步,需要实现对数据表中数据的模糊查询功能.本文就讲讲述如何用C#实现combobox下拉列表的模糊查 ...
- [转]ORACLE中Like与Instr模糊查询性能大比拼
instr(title,'手册')>0 相当于 title like '%手册%' instr(title,'手册')=1 相当于 title like '手册%' instr(titl ...
- 关系数据库SQL之基本数据查询:子查询、分组查询、模糊查询
前言 上一篇关系数据库常用SQL语句语法大全主要是关系型数据库大体结构,本文细说一下关系型数据库查询的SQL语法. 语法回顾 SELECT [ALL|DISTINCT] <目标列表达式>[ ...
- StackExchange.Redis加载Lua脚本进行模糊查询的批量删除和修改
前言 使用StackExchange.Redis没有直接相关的方法进行模糊查询的批量删除和修改操作,虽然可以通过Scan相关的方法进行模糊查询,例如:HashScan("hashkey&qu ...
随机推荐
- 搭建svn服务器&服务器客户端使用笔记
参考借鉴文章:http://www.cnblogs.com/vijayfly/p/5711962.html 之前尝试着用git管理公司代码,但被一个问题困惑了很久无法解决,那就是git该如何只pull ...
- UWP开发:获取用户当前所在的网络环境(WiFi、移动网络、LAN…)
原文:UWP开发:获取用户当前所在的网络环境(WiFi.移动网络.LAN-) UWP开发:获取用户当前所在的网络环境: 在uwp开发中,有时候,我们需要判断用户所在的网络,是WiFi,还是移动网络,给 ...
- Visual studio调试Web发生未能正常启动IIS express
今天调试web时,不知道怎么搞的,昨天还好好的,结果今天怎么也没法调试了.VS里报的错误是进程号为**的未能正常启动,看了下调试时IIS压根就没启动起来,没关系,看看事件管理器里发生了什么 找到个最关 ...
- MinGW 编译 libsndfile-1.0.25(只要有 MSYS,./configure make make install 就行了)
最近做的一个项目需要读写 wav 文件.在网上找到 libsndfile 刚好满足我的需要.但是编译的时候遇到了点小麻烦,这里记录一下编译的过程,免得下次再编译时忘记了. 因为是在编译完成若干天后写的 ...
- Oracle emca on linux
http://blog.csdn.net/haibusuanyun/article/details/16338591 bash-3.2$ lsnrctl status LSNRCTL for Lin ...
- CREATE CSS3是一款在线集成众多CSS3功能的生成器,可以在线生成常用的CSS3效果
CREATE CSS3是一款在线集成众多CSS3功能的生成器,可以在线生成常用的CSS3效果 CREATE CSS3 彩蛋爆料直击现场 CREATE CSS3是一款在线集成众多CSS3功能的生成器,可 ...
- 用CMake 构建Qt 项目
译:用CMake构建Qt项目作者: Johan Thelin 译者:赖敬文原链接:http://developer.qt.nokia.com/quarterly/view/using_cmake_t ...
- 【Linux】Linux下设备网卡以及硬件管理等
这是Linux下网络硬件管理的基础知识,虽然平时用到的可能比软件的少一点,但是作为基础命令,还是需要记住,以免用时又得查询. 本文参考官方文档:https://wiki.ubuntu.com.cn/% ...
- Google C++测试框架系列高级篇:第二章 让GTest学习打印自定义对象
上一篇:更多关于断言的知识 原始链接:Teaching Google Test How to Print Your Values 词汇表 版本号:v_0.1 让GTest学习打印自定义对象 当一个断言 ...
- python中的内置函数(bytearray)
返回一个新的字节数组.bytearray类是range 0 < = x < 256的一个可变序列.它有大多数可变序列的常用方法,在可变序列类型中描述,以及大多数字节类型的方法,参见字节和B ...