Postgresql架构体系解析
一、PostgreSQL物理架构
postgresql的物理架构非常简单,它由共享内存、一系列后台进程和数据文件组成。
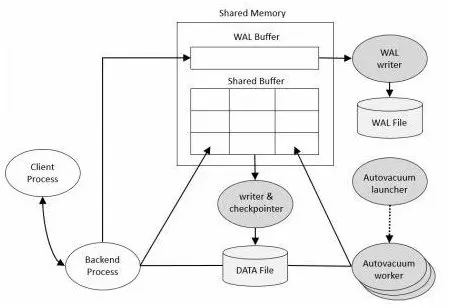
二、Shared Memory
共享内存是服务器服务器为数据库缓存和事务日志缓存预留的内存缓存空间。其中最重要的组成部分是Shared Buffer和WAL Buffer。
- Shared Buffer:是数据页缓冲区。Shared Buffer的目的是减少磁盘IO,大部分oltp工作负载都是随机IO,因此从磁盘获取非常慢。为了解决这个问题,postgre将数据缓存在RAM中,来提高性能。对于shared_buffers,没有一个特定的推荐值。但是一般来说,对于专用DB服务器,shared_buffers的值应该大约是系统总RAM的25%。
WAL Buffer:是预写日志(wal)缓冲区。在备份和恢复的场景下,WAL Buffer和WAL文件是极其重要的。如果要调优的系统有大量并发连接,那么wal_buffers的值越高,性能越好。
三、PostgreSQL 进程类型
PostgreSQL有四种进程类型
- Postmaster (Daemon) Process(主后台驻留进程)
- Background Process(后台进程)
- Backend Process(后端进程)
- Client Process(客户端进程)
- Postmaster Process:PostgreSQL启动时第一个启动的进程。启动时,他会执行恢复、初始化共享内存的运行后台进程操作。运行期间,当有客户端发起链接请求时,它还负责创建后端进程。
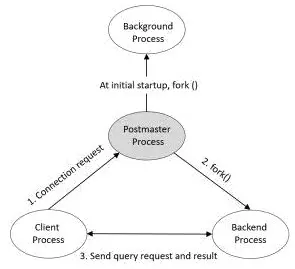
如果通过pstree命令查看进程之间的关系,你会发现Postmaster进程是其他所有进程的父进程。

- Background Process
| 进程 | 作用 |
|---|---|
| logger | 将错误信息写到log日志中 |
| checkpointer | 当检查点出现时,将脏内存块写到数据文件 |
| writer | 周期性的将脏内存块写入文件 |
| wal writer | 将WAL缓存写入WAL文件 |
| Autovacuum launcher | 当自动vacuum被启用时,用来派生autovacuum工作进程。autovacuum进程的作用是在需要时自动对膨胀表执行vacuum操作。 |
| archiver | 在归档模式下时,复制WAL文件到特定的路径下。 |
| stats collector | 用来收集数据库统计信息,例如会话执行信息统计(使用pg_stat_activity视图)和表使用信息统计(pg_stat_all_tables视图) |
- Backend Process
最大后台链接数通过max_connections参数设定,默认值为100。后端进程用于处理前端用户请求并返回结果。查询运行时需要一些内存结构,就是所谓的本地内存(local memory)。本地内存涉及的主要参数有:
- work_mem:用于排序、位图索引、哈希链接和合并链接操作。默认值为4MB。
- maintenance_work_mem:用于vacuum和创建索引操作。默认值为64MB。
- temp_buffers:用于临时表。默认值为8MB。
- Client Process
客户端进程需要和后端进程配合使用,处理每一个客户链接。通常情况下,Postmaster进程会派生一个子进程用来处理用户连接。
四、数据库结构
数据库相关概念:
- PostgreSQL由一系列数据库组成。一套PostgreSQL程序称之为一个数据库群集。
- 当initdb()命令执行后,template0 , template1 , 和postgres数据库被创建。
- template0和template1数据库是创建用户数据库时使用的模版数据库,他们包含系统元数据表。
- initdb()刚完成后,template0和template1数据库中的表是一样的。但是template1数据库可以根据用户需要创建对象。
- 用户数据库是通过克隆template1数据库来创建的;
表空间相关概念:
- initdb()后马上创建pg_default和pg_global表空间。
- 建表时如果没有指定特定的表空间,表默认被存在pg_default表空间中。
- 用于管理整个数据库集群的表默认被存储在pg_global表空间中。
- pg_default表空间的物理位置为$PGDATA\base目录。
- pg_global表空间的物理位置为$PGDATA\global目录。
- 一个表空间可以被多个数据库同时使用。此时,每一个数据库都会在表空间路径下创建为一个新的子路径。
- 创建一个用户表空间会在$PGDATA\pg_tblspc目录下面创建一个软连接,连接到表空间制定的目录位置。
表相关概念:
- 每个表有三个数据文件。
- 一个文件用于存储数据,文件名是表的OID。
- 一个文件用于管理表的空闲空间,文件名是OID_fsm。
- 一个文件用于管理表的块是否可见,文件名是OID_vm。
- 索引没有_vm文件,只有OID和OID_fsm两个文件
Postgresql架构体系解析的更多相关文章
- 「译」JUnit 5 系列:架构体系
原文地址:http://blog.codefx.org/design/architecture/junit-5-architecture/ 原文日期:29, Mar, 2016 译文首发:Linesh ...
- 分布式系统的那些事儿(六) - SOA架构体系
有十来天没发文了,实在抱歉!最近忙着录视频,同时也做了个开源的后台管理系统LeeCX,目前比较简单,但是后续会把各类技术完善.具体可以点击“原文链接”. 那么今天继续说分布式系统的那些事. 我们现在动 ...
- Atitit.vod 视频播放系统 影吧系统的架构图 架构体系 解决方案
Atitit.vod 视频播放系统 影吧系统的架构图 架构体系 解决方案 1. 运行平台:跨平台 android ios pc mobile 1.1. -------------前端 界面------ ...
- Netty-Channel架构体系源码解读
全文围绕下图,Netty-Channel的简化版架构体系图展开,从顶层Channel接口开始入手,往下递进,闲言少叙,直接开撸 概述: 从图中可以看到,从顶级接口Channel开始,在接口中定义了一套 ...
- 阿里巴巴飞天大数据架构体系与Hadoop生态系统
很多人问阿里的飞天大数据平台.云梯2.MaxCompute.实时计算到底是什么,和自建Hadoop平台有什么区别. 先说Hadoop 什么是Hadoop? Hadoop是一个开源.高可靠.可扩展的分布 ...
- 基于golang分布式爬虫系统的架构体系v1.0
基于golang分布式爬虫系统的架构体系v1.0 一.什么是分布式系统 分布式系统是一个硬件或软件组件分布在不同的网络计算机上,彼此之间仅仅通过消息传递进行通信和协调的系统.简单来说就是一群独立计算机 ...
- WCF技术剖析之二十五: 元数据(Metadata)架构体系全景展现[元数据描述篇]
原文:WCF技术剖析之二十五: 元数据(Metadata)架构体系全景展现[元数据描述篇] 在[WS标准篇]中我花了很大的篇幅介绍了WS-MEX以及与它相关的WS规范:WS-Policy.WS-Tra ...
- 基于EF+WCF的通用三层架构及解析
分享基于EF+WCF的通用三层架构及解析 本项目结合EF 4.3及WCF实现了经典三层架构,各层面向接口,WCF实现SOA,Repository封装调用,在此基础上实现了WCFContext,动态服务 ...
- 手机CPU架构体系分类及各大厂商
手机cpu相关知识,这对于开发Android应用程序适应各个机型有一定的辅助作用 . 手机cpu架构体系分类 指令集可分为复杂指令集(CISC)和精简指令集(RISC)两部分,代表架构分别是x86.A ...
- HBase伪分布式安装(HDFS)+ZooKeeper安装+HBase数据操作+HBase架构体系
HBase1.2.2伪分布式安装(HDFS)+ZooKeeper-3.4.8安装配置+HBase表和数据操作+HBase的架构体系+单例安装,记录了在Ubuntu下对HBase1.2.2的实践操作,H ...
随机推荐
- 【每日一题】【DFS】【BFS】【队列】2021年12月5日-199. 二叉树的右视图
解答: /** * Definition for a binary tree node. * public class TreeNode { * int val; * TreeNode left; * ...
- Mysql-delete语句
` 点击查看代码 删除2天之前的所有数据 delete From lkt_files_record where DATE(add_time) <= DATE(DATE_SUB(NOW(),INT ...
- 同步异步、mutiprocessing创建进程process模块及进程对象的多种方法、消息队列Queue
目录 同步异步 阻塞与非阻塞 综合使用 创建进程的多种方式之multiprocess.process模块 进程间数据隔离 进程的join方法 IPC机制 生产者 消费者模型 进程对象的多种方法 守护进 ...
- python之yaml文件读取封装
import os import yaml from yamlinclude import YamlIncludeConstructor YamlIncludeConstructor.add_to_l ...
- 百倍加速IO读写!快使用Parquet和Feather格式!⛵
作者:韩信子@ShowMeAI 数据分析实战系列:https://www.showmeai.tech/tutorials/40 本文地址:https://www.showmeai.tech/artic ...
- JavaScript:操作符:逗号运算符
逗号运算符,是极少见的运算符,我们看一下代码理解一下逗号运算符的功能: 先说结论,逗号运算符的优先级非常低,比赋值运算符=还要低: 同时,逗号隔开的几个表达式,都会各自进行计算,但是整体表达式只会返回 ...
- java下载网络文件的N种方式
java下载网络文件的N种方式 通过java api下载网络文件的方法有很多,主要方式有以下几种: 1.使用 common-io库下载文件,需要引入commons-io-2.6.jar public ...
- [C#]C++/CLI中interior_ptr和pin_ptr的区别
interior_ptr 当垃圾回收器移动对象时,Interior pointer能随之移动,并始终指向该对象. 但是如果把这个指针返回给外部函数,那么当垃圾回收时(垃圾回收期间会压缩对象,),对象地 ...
- pip19.2.3升级到20.3.3版本升级失败问题
2021-01-06 macOS版本:11.1 安装pip: sudo easy_install pip 话不多说,直接上问题 一行命令搞定 终端:sudo pip install --upg ...
- Blazor Pdf Reader PDF阅读器 组件 更新
Blazor Pdf Reader PDF阅读器 组件 https://www.nuget.org/packages/BootstrapBlazor.PdfReader#readme-body-tab ...