Spark Streaming实时计算
spark批处理模式:
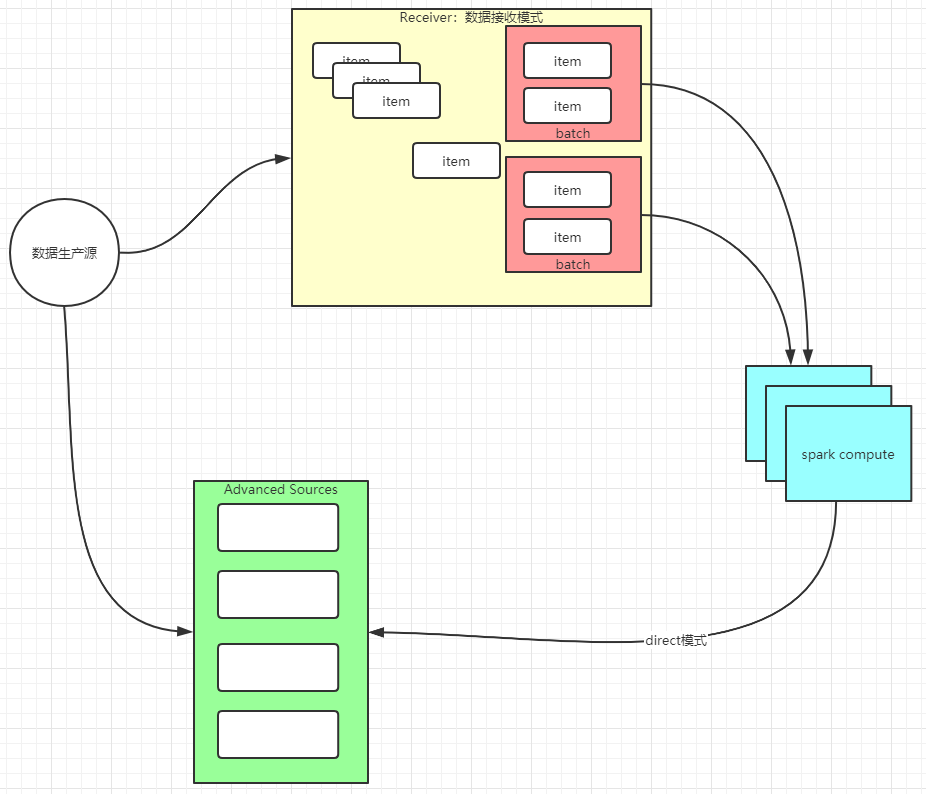
receiver模式:接收数据流,负责数据的存储维护,缺点:数据维护复杂(可靠性,数据积压等),占用计算资源(core,memory被挤占)
direct模式:数据源由三方组件完成,spark只负责数据拉取计算,充分利用资源计算
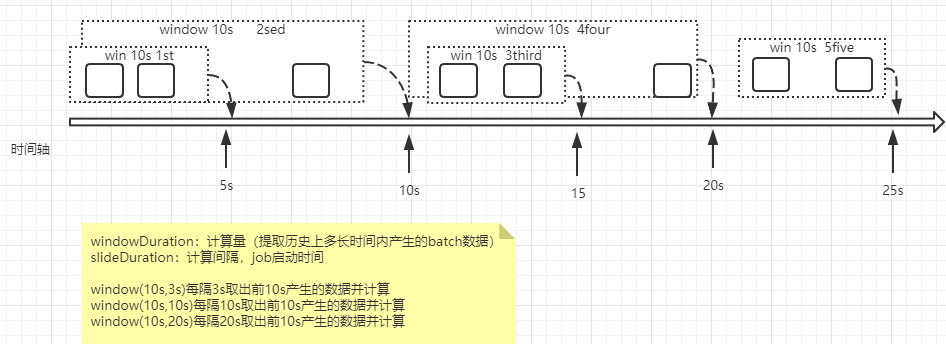
window计算:
def windowApi(): Unit = {
val conf: SparkConf = new SparkConf().setAppName("sparkstream").setMaster("local[2]")
val sc = new SparkContext(conf)
val ssc = new StreamingContext(sc, Duration(1000))
ssc.sparkContext.setLogLevel("ERROR")
val resource: ReceiverInputDStream[String] = ssc.socketTextStream("localhost",8889)
val format: DStream[(String, Int)] = resource.map(_.split(" ")).map(x=>(x(0),1))
//统计每次看到的10s的历史记录
//windowDuration窗口一次最多批次量,slideDuration滑动间隔(job启动间隔),最好等于winduration
val res: DStream[(String, Int)] = format.reduceByKeyAndWindow(_+_,Duration(10000),Duration(1000))//每一秒计算最后10s内的数据
res.print()
ssc.start()
ssc.awaitTermination()
}
window处理流程:
执行流程:
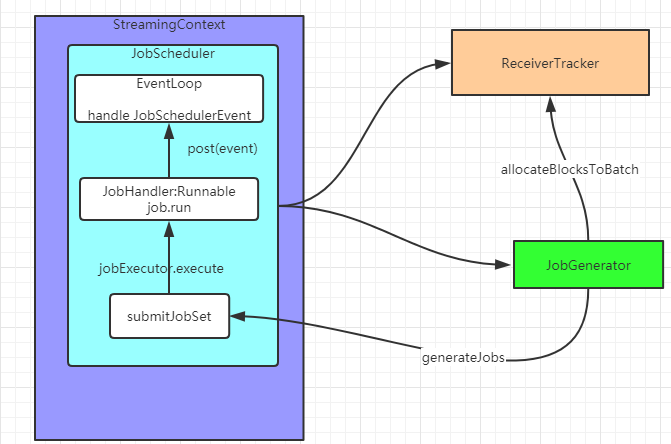
说明:Receiver模式下,接收器创建数据块,每间隔blockInterval 时间产生新的数据块,块的个数N = batchInterval/blockInterval。这些数据块由当前executor的BlockManager发送到其它executor的BlockManager,driver追踪块的位置为下一步计算准备
1,JobScheduler通过EventLoop消息处理机制处理job事件(jobStart,jobCompletion,jobError对job进行标记)使用ThreadPoolExecutor为每个job维护一个thread执行job.run
2,JobGenerator负责job生成,执行checkpoint,清理DStream产生的元数据,触发receiverTracker为下一批次数据建立block块的标记
stream合并与转换:
每个DStream对应一种处理,对于数据源有多种特征需要多个DStream分别处理,最后将结果在一起处理,val joinedStream = windowedStream1.join(windowedStream2)
val conf: SparkConf = new SparkConf().setAppName("sparkstream").setMaster("local[2]")
val sc = new SparkContext(conf)
val ssc = new StreamingContext(sc, Duration(1000))
ssc.sparkContext.setLogLevel("ERROR")
val resource: ReceiverInputDStream[String] = ssc.socketTextStream("localhost",8889)
val format: DStream[(String, Int)] = resource.map(_.split(" ")).map(x=>(x(0),1))
//transform 加工转换处理
val res: DStream[(String, Int)] = format.transform( //返回值是RDD
(rdd ) =>{
val rddres: RDD[(String, Int)] = rdd.map(x => (x._1, x._2 * 10))//做转换
rddres
}
)
//末端处理
format.foreachRDD( //StreamingContext 有一个独立的线程执行while(true)下面的代码是放到执行线程去执行
(rdd)=>{
rdd.foreachPartition { partitionOfRecords =>
// val connection = createNewConnection()
// to redis or mysql
// partitionOfRecords.foreach(record => connection.send(record))
// connection.close()
}
}
)
Caching / Persistence
在使用window统计时(reduceByWindow ,reduceByKeyAndWindow,updateStateByKey)Dstream会自动调用persist将结果缓存到内存(data serialized)
Checkpointing 保存两种类型数据存储
Metadata:driver端需要的数据
Configuration: application配置信息conf
DStream operations: 定义的Dstream操作集合
Incomplete batches:在队列内还没计算完成的bactch数据
Data checkpointing:已经计算完成的状态数据
设置checkpoint
val ssc = new StreamingContext(...)
ssc.checkpoint(checkpointDirectory)
dstream.checkpoint(checkpointInterval).
...... // Get StreamingContext from checkpoint data or create a new one
val context = StreamingContext.getOrCreate(checkpointDirectory, functionToCreateContext _)
context.
checkpoint依赖外存储,随着batch处理间隔的变短,会使吞吐量显著降低,因此存储间隔要合理设置,系统默认最少10s调用一次,官方建议5s-10s
Spark Streaming实时计算的更多相关文章
- Spark Streaming实时计算框架介绍
随着大数据的发展,人们对大数据的处理要求也越来越高,原有的批处理框架MapReduce适合离线计算,却无法满足实时性要求较高的业务,如实时推荐.用户行为分析等. Spark Streaming是建立在 ...
- 【Streaming】30分钟概览Spark Streaming 实时计算
本文主要介绍四个问题: 什么是Spark Streaming实时计算? Spark实时计算原理流程是什么? Spark 2.X下一代实时计算框架Structured Streaming Spark S ...
- Spark练习之通过Spark Streaming实时计算wordcount程序
Spark练习之通过Spark Streaming实时计算wordcount程序 Java版本 Scala版本 pom.xml Java版本 import org.apache.spark.Spark ...
- 【转】Spark Streaming 实时计算在甜橙金融监控系统中的应用及优化
系统架构介绍 整个实时监控系统的架构是先由 Flume 收集服务器产生的日志 Log 和前端埋点数据, 然后实时把这些信息发送到 Kafka 分布式发布订阅消息系统,接着由 Spark Streami ...
- spark streaming 实时计算
spark streaming 开发实例 本文将分以下几部分 spark 开发环境配置 如何创建spark项目 编写streaming代码示例 如何调试 环境配置: spark 原生语言是scala, ...
- 大数据开发实战:Spark Streaming流计算开发
1.背景介绍 Storm以及离线数据平台的MapReduce和Hive构成了Hadoop生态对实时和离线数据处理的一套完整处理解决方案.除了此套解决方案之外,还有一种非常流行的而且完整的离线和 实时数 ...
- 50、Spark Streaming实时wordcount程序开发
一.java版本 package cn.spark.study.streaming; import java.util.Arrays; import org.apache.spark.SparkCon ...
- Dream_Spark-----Spark 定制版:005~贯通Spark Streaming流计算框架的运行源码
Spark 定制版:005~贯通Spark Streaming流计算框架的运行源码 本讲内容: a. 在线动态计算分类最热门商品案例回顾与演示 b. 基于案例贯通Spark Streaming的运 ...
- 【慕课网实战】Spark Streaming实时流处理项目实战笔记八之铭文升级版
铭文一级: Spark Streaming is an extension of the core Spark API that enables scalable, high-throughput, ...
- 【慕课网实战】Spark Streaming实时流处理项目实战笔记二之铭文升级版
铭文一级: 第二章:初识实时流处理 需求:统计主站每个(指定)课程访问的客户端.地域信息分布 地域:ip转换 Spark SQL项目实战 客户端:useragent获取 Hadoop基础课程 ==&g ...
随机推荐
- Selenium4+Python3系列(十三) - 与docker中的jenkins持续集成
前言 文章更新到这一篇时,其实我还是很开心的,因为这也正是这系列教程的最后一篇文章,也算是完成了一个阶段性的小目标,也很感谢那些愿意看我文章与我交流学习的同学,感谢有你们的支持和陪伴. Jenkins ...
- 教你铁威马NAS中如何进行阵列升级
磁盘阵列 (RAID) 是磁盘阵列的管理工具.当TNAS 中安装的硬盘多于1个时,组建适当的磁盘阵列能提高硬盘的存储效率,提高数据的安全性. 磁盘阵列升级,比如,将原来是RAID 0 或者RAID 1 ...
- java中的递归机制
本文主要讲述java中的递归机制. 示例1,递归代码如下: public class Recursion01 { public static void main(String[] args) { T ...
- Jmeter 之 switch 控制器
switch 控制器作用: switch 控制器起到了分流作用,具体应用在并发时,一部分用户执行某个场景,一部分用户执行另外一种场景,就像吞吐量控制器进行分流操作 switch 控制器字段介绍: 实例 ...
- 重学c#系列—— 反射的基本理解[三十三]
前言 在上一章中介绍了什么是反射: https://www.cnblogs.com/aoximin/p/16440966.html 正文 上一节讲述反射的基本原理和为什么要用反射,还用反射的优缺点这些 ...
- (已转)Linux基础第七章 线程
前言 之前讨论了进程,了解一个进程能做一件事情,如果想同时处理多件事情,那么需要多个进程,但是进程间很不方便的一点是,进程间的数据交换似乎没有那么方便.Linux提供线程功能,能在一个进程中,处理多任 ...
- 1_使用swiper数组对象循环图片遇到的问题
今天在练习微信小程序的swiper组件时,想用列表循环出图片,发现图片一直没出来,控制台也没有报错,后来仔细一看,原来是语法格式写错了. 以下是我列表循环踩过的坑: 一:微信小程序的列表循环和vue的 ...
- java基础篇——异常
异常的三种类型 1.检查型异常:通常是由用户错误或者问题引起,是程序员无法预见的,例如用户要打开一个不存在的文件... 2.运行时异常:最有可能被程序员忽略的异常,可以在编译时被忽略,例如无限递归调用 ...
- 如何理解scanf(“%d %d”,a,b)==2和scanf(“%d”,a)=1【摘抄笔记ψ(._. )>】
scanf 函数有一个返回值,0表示接受输入失败,1表示接受输入成功. while(scanf("%d",&x)==1) 的意思就是: 当接收输入变量x的值成功的时候,继续 ...
- 让Apache Beam在GCP Cloud Dataflow上跑起来
简介 在文章<Apache Beam入门及Java SDK开发初体验>中大概讲了Apapche Beam的简单概念和本地运行,本文将讲解如何把代码运行在GCP Cloud Dataflow ...