ORM执行原生SQL语句、双下划线数据查询、ORM外键字段的创建、外键字段的相关操作、ORM跨表查询、基于对象的跨表查询、基于双下划线的跨表查询、进阶查询操作
今日内容
ORM执行SQL语句
有时候ROM的操作效率可能偏低 我们是可以自己编写sql的
方式1:
models.User.objects.raw('select * from app01_user;')
方式2:
from django.db import connection
cursor = connection.cursor()
cursor.execute('select name from app01_user;')
print(cursor.fetchall())
神奇的双下划线查询
只要是queryset对象就可以无限制的点queryset对象的方法
queryset.filter().values().filter().values_list().filter()...
大于 小于
__gt 大于
__lt 小于
大于等于 小于等于
__gte 大于等于
__lte 小于等于
或1 或2 或3
__in(1,2,3)
在1-10范围内
__range(1,10)
是否含有'j'
__contains='j' #区分大小写
__icontains='j' #不区分大小写
查询注册年份
register_time_year = 2022
'''针对django框架时区问题 是需要配置文件中修改的 后续bbs讲解'''
ORM外键字段的创建
mysql外键关系
一对多
外键字段建在多的一方
多对多
外键字段统一建在第三张表
一对一
任何一方都可以 但是建议建在查询频率高的表中
1.创建四张表
书籍表、出版社表、作者表、作者详情
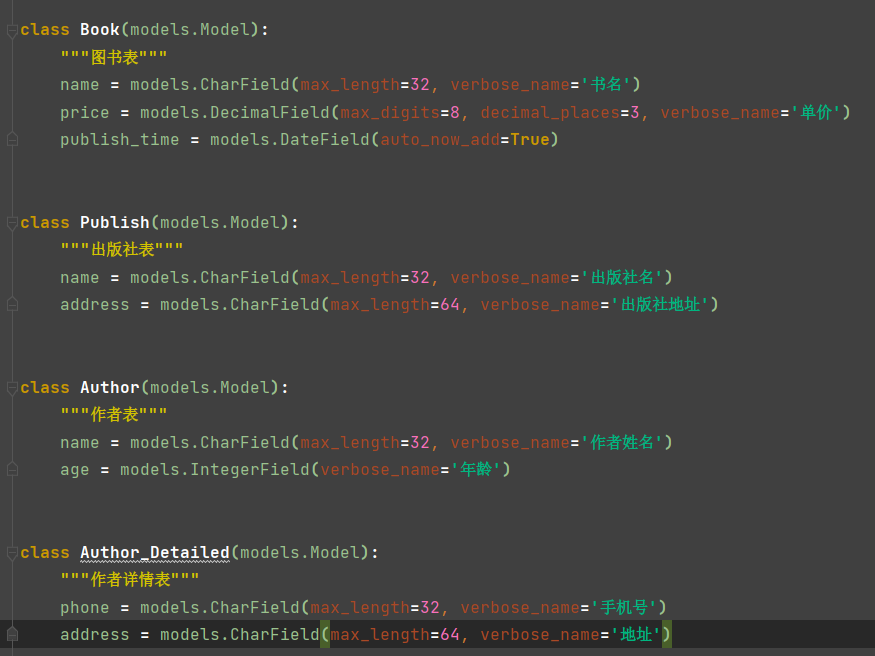
2.确定外键关系
一对多 ORM与MYSQL一致 外键字段建在多的一方
多对多 ORM比MYSQL有变化
1.外键字段可以直接建在某张表中(查询频率较高的)
内部会自动帮你创建第三张关系表
2.自己创建第三张关系表 并创建外键字段
详情后续讲解
一对一 OPM与MYSQL一致 外键字段建在查询较高的一方
3.ORM外键字段的创建
针对一对多和一对一同步到表中会自动加_id的后缀
publish = models.ForeignKey(to='Publish', on_delete=models.CASCADE)
注意:django1.x版本默认外键字段都是级联更新级联删除的 django2.x及以上版本需要自己声明
针对多对多 不会再表中有展示 而是创建第三张表
authors = models.ManyToMangField(to='Author')
外键字段相关操作
针对一对多添加关系
#插入数据可以直接写表中的实际字段
models.Book.objects.create(name='火浒传',price=6.66,publish_id=1)
#插入数据可以直接表中的类中字段名
publish_obj = models.Publish.objects.filter(pk=1).first()
#先获取到对象
models.Book.objects.create(name='四国演义',price=3.33,publish=publish_obj)
#将获取到的对象插入
'''一对一与一对多 一致'''
即可以传数字也可以传对象
针对多对多添加关系
book_obj = models.Book.objects.filter(pk=12).first()
#获取书籍对象
book_obj.authors.add(3)
book_obj.authors.add(3,2)
#在第三张表中给数据对象绑定作者 支持一个或多个 (作者主键)
book_obj =
models.Book.objects.filter(pk=1).first()
author_obj=
models.Author.objects.filter(pk=2).first()
author_obj2=
models.Author.objects.filter(pk=1).first()
book_obj.author.addd(author_obj2)
#(作者对象)
修改关系
book_obj =
models.Book.objects.filter(pk=10).first()
book_obj.authors.set((2,1))
book_obj.authors.set([2,])
#直接传外键 元组要加号
book_obj =
models.Book.objects.filter(pk=10).first()
author_obj=
models.Author.objects.filter(pk=1).first()
book_obj.authors.set((author_obj))
#直接传对象
删除关系
book_obj =
models.Book.objects.filter(pk=12).first()
book_obj.authors.remove(2)
#移除这本书和2的绑定关系
book_obj =
models.Book.objects.filter(pk=12).first()
author_obj=
models.Author.objects.filter(pk=1).first()
book_obj.authors.remove((author_obj))
#直接传数据
book_obj.authors.clear()#把这本书的关系全部清掉
add()\remove() 多个位置参数(数字 对象)
set() 可迭代对象(元组 列表)数字 对象
clear() 清空当前数据对象的关系
ORM跨表查询
mysql跨表查询
子查询
分布操作:
将一条sql语句用括号括起来当作另外一条sql语句的条件
联表操作
先整合多张表之后基于单表查询即可
inner join 内连接
left join 左连接
right join 右连接
正反向查询
正向查询
由外键字段所在的表数据查询关联的表数据
有外键字段 去查别人
反向查询
没有外键字段的表数据查询关联的表数据
没有外键 去查别人
ps:正反向核心就看外键在不在当前的数据表中
ORM跨表查询口诀
正向查询按外键字段
反向查询按表名小写
基于对象的跨表查询
正向查询
1.查询主键为7的书籍对应的出版社名称
book_obj= models.Book.objects.filter(pk=7).first()
print(book_obj.publish.name)
2.查询主键为10的书籍对应的作者
book_obj = models.Book.objects.filter(pk=10).first()
print(book_obj.authors.all().values('name'))
3.查询joyce的电话号码 author_obj=models.Author.objects.filter(name='joyce').first()
print(author_obj.author_detail.phone)
反向查询
1.查询月月出版社出版的书籍名称
publish_obj = models.Publish.objects.filter(name='月月出版社').first()
print(publish_obj.book_set.all().values())
2.查询kevin写过的书
author_obj = models.Author.objects.filter(name='kevin').first()
print(author_obj.book_set.all().values('name'))
3.查询电话号码是33333333333的作者姓名
Author_Detailed_obj = models.Author_Detailed.objects.filter(phone=33333333333).first()
print(Author_Detailed_obj.author.name)
基于上下划线的跨表查询
1.查询主键为7的书籍对应的出版社名称 book_obj=models.Book.objects.filter(pk=7).values('publish__name')
print(book_obj)
2.查询主键为10的书籍对应的作者 book_obj=models.Book.objects.filter(pk=10).values('authors__name')
print(book_obj)
3.查询joyce的电话号码
author_obj=
models.Author.objects.filter(name='joyce').values('author_detail__phone')
print(author_obj)
4.查询月月出版社出版的书籍名称 publish_obj=models.Publish.objects.filter(name='月月出版社').values('book__name')
print(publish_obj)
5.查询kevin写过的书
author_obj = models.Author.objects.filter(name='kevin').values('book__name')
print(author_obj)
6.查询电话号码是33333333333的作者姓名
Author_Detailed_obj = models.Author_Detailed.objects.filter(phone=33333333333).values('author__name')
print(Author_Detailed_obj)
进阶操作
s.Publish.objects.filter(book__pk=7).values('name')
print(res)
# 2.查询主键为10的书籍对应的作者
res = models.Author.objects.filter(book__pk=10).values('name')
print(res)
# 3.查询joyce的电话号码
res = models.Author_Detailed.objects.filter(author__name='joyce').values('phone')
print(res)
# 1.查询月月出版社出版的书籍名称
res = models.Book.objects.filter(publish__name='月月出版社').values('name')
print(res)
# 2.查询kevin写过的书
res = models.Book.objects.filter(authors__name='kevin').values('name')
print(res)
# 3.查询电话号码是33333333333的作者姓名
res = models.Author.objects.filter(author_detail__phone=33333333333).values('name')
print(res)
ORM执行原生SQL语句、双下划线数据查询、ORM外键字段的创建、外键字段的相关操作、ORM跨表查询、基于对象的跨表查询、基于双下划线的跨表查询、进阶查询操作的更多相关文章
- 12月15日内容总结——ORM执行原生SQL语句、双下划线数据查询、ORM外键字段的创建、外键字段的相关操作、ORM跨表查询、基于对象的跨表查询、基于双下划线的跨表查询、进阶查询操作
目录 一.ORM执行SQL语句 二.神奇的双下划线查询 三.ORM外键字段的创建 复习MySQL外键关系 外键字段的创建 1.创建基础表(书籍表.出版社表.作者表.作者详情) 2.确定外键关系 3.O ...
- Django之ORM执行原生sql语句
django中的ORM提供的操作功能有限,在模型提供的查询API不能满足实际工作需要时,可以在ORM中直接执行原生sql语句. Django 提供两种方法使用原生SQL进行查询:一种是使用raw()方 ...
- ORM执行原生SQL语句
# 1.connectionfrom django.db import connection, connections cursor = connection.cursor() # cursor = ...
- django系列5.4--ORM中执行原生SQL语句, Python脚本中调用django环境
ORM执行原生sql语句 在模型查询API不够用的情况下,我们还可以使用原始的SQL语句进行查询. Django 提供两种方法使用原始SQL进行查询:一种是使用raw()方法,进行原始SQL查询并返回 ...
- python 之 Django框架(orm单表查询、orm多表查询、聚合查询、分组查询、F查询、 Q查询、事务、Django ORM执行原生SQL)
12.329 orm单表查询 import os if __name__ == '__main__': # 指定当前py脚本需要加载的Django项目配置信息 os.environ.setdefaul ...
- orm分组,聚合查询,执行原生sql语句
from django.db.models import Avg from app01 import models annotate:(聚合查询) ret=models.Article.objects ...
- Django中的ORM相关操作:F查询,Q查询,事物,ORM执行原生SQL
一 F查询与Q查询: 1 . F查询: 在上面所有的例子中,我们构造的过滤器都只是将字段值与某个常量做比较.如果我们要对两个字段的值做比较,那该怎么做呢? Django 提供 F() 来做这样的 ...
- java:Hibernate框架3(使用Myeclipse逆向工程生成实体和配置信息,hql语句各种查询(使用hibernate执行原生SQL语句,占位符和命名参数,封装Vo查询多个属性,聚合函数,链接查询,命名查询),Criteria)
1.使用Myeclipse逆向工程生成实体和配置信息: 步骤1:配置MyEclipse Database Explorer: 步骤2:为项目添加hibernate的依赖: 此处打开后,点击next进入 ...
- Django的F查询和Q查询,事务,ORM执行原生SQL
F查询和Q查询,事务及其他 F查询和Q查询 F查询 在上面所有的例子中,我们构造的过滤器都只是将字段值与某个我们自己设定的常量做比较.如果我们要对两个字段的值做比较,那该怎么做呢? Django ...
随机推荐
- Vue学习之--------全局事件总线(2022/8/22)
文章目录 1.全局事件总线基础知识(GlobalEventBus) 2.图解过程 3.代码实例 3.1 main.js 3.1 App.vue 3.2 School.vue 3.3 Student.v ...
- HTML元素大全(1)
01.基础元素 <h1/2/3/4/5/6>标题 从大h1到小h6,块元素,有6级标题.是一种标题类语义标签,内置了字体.边距样式. 合理使用h标签,主要用于标题,不要为了加粗效果而随意使 ...
- DQL语句排序与分组
DQL语句排序与分组 一.DQL-排序 排序是计算机内经常进行的一种操作,其目的是将一组"无序"的记录序列调整为"有序"的记录序列.分内部排序和外部排序,若整个 ...
- SQL Server 读写分离配置的一些问题
1,新建发布服务器遇到此服务器上未安装复制组件 先执行以下sql use mastergoselect @@servername;select serverproperty('servername') ...
- 面试 个人摸底监测 考察JavaScript基础 (第三天)
01,如何开启JS严格模式?JS严格模式有什么特点? 两种方式 全局开启在js开头加上 'use strict' 局部开启,在作用域开头加上 function fn(){ 'use strict' } ...
- Kubeadm搭建kubernetes集群
Kubeadm搭建kubernetes集群 环境说明 | 角色 | ip | 操作系统 |组件 | | – | – | – | | master | 192.168.203.100 |centos8 ...
- OSI传输层TCP与UDP协议、应用层简介、socket模块介绍及代码优化、半连接池的概念
目录 传输层之TCP与UDP协议 应用层 socket模块 socket基本使用 代码优化 半连接池的概念 传输层之TCP与UDP协议 TCP与UDP都是用来规定通信方式的 通信的时候可以随心所欲的聊 ...
- linux sublime-text ctrl+shift+b 快捷键失效问题解决
解决办法 由于fcitx拦截了这个ctrl+shift+b 这个快捷键,所以取消即可 点击全局配置里面高级选项,然后找到ctrl+shift+b这个快捷键,点击后,按esc就可以将快捷键设置为空,不过 ...
- Docker使用Calico配置网络模式
一.Calico介绍 Calico是一种容器之间互通的网络方案,在虚拟化平台中,比如OpenStack.Docker等都需要实现workloads之间互连,但同时也需要对容器做隔离控制,就像在Inte ...
- day29 jQuery选择器 & jquery属性操作 & jquery DOM元素 操作与遍历
简介 jQuery,顾名思义,就是javascript和query(查询),即辅助javascript开发的库,本质就是一个js文件: jQuery是一个js函数库,是目前全球范围内最流行.用的最多的 ...