CodeForces 构造题专项解题报告
CodeForces 构造题专项解题报告
\(\newcommand \m \mathbf\)\(\newcommand \oper \operatorname\)
\(\text{By DaiRuiChen007}\)
来源:CodeForces *constructive algorithms
推荐阅读:
- 11. [1672F] - Array Shuffling & Checker for Array Shuffling
- 41. [1526D] - Kill Anton
1. [1772F] - Copy of a Copy of a Copy
- Rating:2000
- Status:Solve
- Evaluate:Easy
注意到如下的观察:
观察:
对于每个可修改位置 \((i,j)\),如果 \((i,j)\) 被修改后,与 \((i,j)\) 相邻的四个格子将不能被修改
因此每个 \((i,j)\) 最多被修改一次
所以对于每个图片 \(p_i\),维护对应的可修改位置集合 \(\m S_i\),按 \(|\m S_i|\) 从大到小排序即可得到每个图片生成的顺序
由于上面的观察我们能够推知每个位置的修改是没有后效性的,也就是修改位置的顺序没有影响,因此每次修改的位置就是相邻两张图片中不同的那些位置,直接枚举即可
时间复杂度 \(\Theta(nmk)\)
2. [1763C] - Another Array Problem
- Rating:2000
- Status:Hint + Data
- Evaluate:Medium
注意到如下的观察:
观察:
对于任意一个 \(i\in(2,n]\) 的 \(i\),存在一种方法将子序列 \([1,i]\) 全部赋值成 \(a_i\)
首先连续操作 \([1,2]\):\((a_1,a_2) \to(|a_1-a_2|,|a_1-a_2|)\to(0,0)\)
然后操作 \([1,i]\),此时整个子序列都会变成 \(a_i\)
运用上面的方法,对于 \(n\ge 4\) 的情形我们可以将序列 \(\max\) 推平到整个序列上,因此此时答案为 \(n\times \max\{a_i\}\)
- \(n=1\) 的情况:显然,答案为 \(a_1\)
- \(n=2\) 的情况:有意义的操作至多一次,因此答案为 \(\max(a_1+a_2,2\times|a_1-a_2|)\)
- \(n=3\) 的情况:如果 \(a_2\) 不是严格最大值,答案为 \(n\times \max\{a_i\}\),否则显然先操作 \(a_2\) 和 \(a_1,a_3\) 中较小的一个得到 \(\{a'_i\}\),然后我们可以将答案推平为 \(n\times a'_1\) 或 \(n\times a'_3\),最终答案为 \(\max\{a_1+a_2+a_3,3\times a'_1,3\times a'_2\}\)
时间复杂度 \(\Theta(n)\)
3. [1736D] - Equal Binary Subsequences
- Rating:2200
- Status:No Solve
- Evaluate:Hard
显然:0 和 1 出现的次数如果是奇数那么一定无解
对于剩下的情况,注意到如下的观察:
观察:
我们定义第 \(2i-1\) 位和第 \(2i\) 位的字符构成一个“字符组”(\(i\in[1,n]\)),那么通过一次轮转操作,我们一定能使得原串中只含有字符组
00和11,下述操作方法:以字符串
000110111001为例:我们可以将其每两位进行划分得到 \(6\) 个字符组:00 | 01 | 10 | 11 | 10 | 01显然对于字符组
00和11没有操作的必要,而对于字符组10和字符组01,我们对于每个字符组取出其中一个字符,并且满足我们取出的字符串是0和1交替的,由于需要取出字符的字符组中同时包含0和1,所以一定存在这样的取出方案对于上面举的例子,我们对第 \(2\) 个字符组取出第 \(3\) 位
0,对第 \(3\) 个字符组取出第 \(5\) 位1,对第 \(5\) 个字符组取出第 \(10\) 位0,对第 \(6\) 个字符组取出第12位1,最终得到取出的子序列0101对取出的子序列右移一位,由于
0和1出现的次数都是偶数,所以字符组01和字符组10的数量总和应该也为偶数,因此得到的子序列长度也是偶数,右移一位后恰好得到原序列取反,如例子中右移得到子序列1010把取出的子序列放回去,那么被取出
0的字符组有一个1没被操作,又获得了一个1,那么我们就得到了字符组11,同理,被取出1的字符组会变成字符组00,如例子中得到了序列00 | 11 | 00 | 11 | 11 | 00
根据观察中的构造方法,我们可以对于每个字符串通过右移使字符串仅由字符组 00 和 11 构成的,那么对于每个字符组,给 \(S^p\) 和 \(S^q\) 各一个字符即可
时间复杂度 \(\Theta(n)\)
4. [1734E] - Rectangular Congruence
- Rating:2100
- Status:Solve
- Evaluate:Easy
注:数值计算均在 \(\bmod n\) 意义下进行,数组下标范围为 \([0,n)\)
首先考虑对 \(a_{r_1,c_1}+a_{r_2,c_2}\ne a_{r_1,c_2}+a_{r2,c_1}\) 进行变形:得到 \(a_{r_1,c_1}-a_{r_2,c_1}\ne a_{r_2,c_1}-a_{r2,c_2}\)
那么对于 \(a\) 中的任意两行 \(r_1,r_2\),我们将其对位相减得到 \(d_i=a_{r_1,i}-a_{r_2,i}\),简记为 \(a_{r_1}-a_{r_2}=d\)
那么由题目的限制我们知道 \(d_i\) 两两不同,因此原限制等价于对于任意 \(r_1,r_2\),\(d\) 都是 \(0\sim n-1\) 的一个排列
考虑一种构造:对于所有 \(i\in[1,n)\):\(a_{i}-a_{i-1}=\{0,1,2,\cdots,n-1\}\)
此时:对于任意 \(r_1,r_2\),都满足 \(a_{r_1}-a_{r_2}=\{d\times0,d\times1,d\times2,\cdots,d\times(n-1)\}\),其中 \(d=|r_1-r_2|\)
由于 \(n\) 是质数,因此我们知道对于任意 \(k\ne 0\),\(\{0\times k,1\times k,2\times k,\cdots,(n-1)\times k\}\) 依然是一个 \(0\sim n-1\) 的排列,所以这种构造是合法的
此时第 \(i\) 列是一个公差为 \(i\) 的等差序列,从 \(a_{i,i}\) 出发依次赋值即可
时间复杂度 \(\Theta(n^2)\)
5. [1730D] - Prefixes and Suffixes
- Rating:2200
- Status:Hint
- Evaluate:Hard
先对 \(T\) 进行翻转,每次操作会变成:翻转 \(S[1\sim k],T[1\sim k]\),然后交换 \(S[1\sim k],T[1\sim k]\)
根据上面的转化,有一个显然的观察:一对同位置的 \((S_i,T_i)\) 在经过若干次操作后依然会在同一个位置上
根据上面的观察得到:只要确定 \(S\),\(T\) 也随之确定
因此对于最终的状态 \((S^\star,T^\star)\) 我们可以用一个长度为 \(n\) 的排列 \(\{p_i\}\) 和一个长度为 \(n\) 的 01 串 \(\{b_i\}\) 表示,具体规则如下:
对于 \((S^\star_i,T^\star_i)\):
- 如果 \(b_i=0\),那么 \((S^\star_i,T^\star_i)=(S_{p_i},T_{p_i})\)
- 如果 \(b_i\ne 0\),那么 \((S^\star_i,T^\star_i)=(T_{p_i},S_{p_i})\)
注意到有如下观察:
观察:
对于任意的一个状态表示 \((\{p_i\},\{b_i\})\),都存在一种合法的操作序列使我们能够得到一个合法的终态 \((S^\star,T^\star)\) 恰好能够用 \((\{p_i\},\{b_i\})\) 表示
对于每一次操作,我们会使 \(\{p_i\}\) 的前 \(k\) 位翻转,\(\{b_i\}\) 的前 \(k\) 位逐位取反后翻转
事实上,我们只需要证明存在一种操作使得我们能从任意一个状态 \((\{p'_i\},\{b'_i\})\) 开始,经过若干次操作使得 \(p'_n=p_n\) 和 \(b'_n=b_n\),剩下的步骤由数学归纳法即可得到
不妨假设在 \(\{p'_i\}\) 中 \(p_n\) 对应 \(p'_k\),那么通过操作 \([1,k]\) 和 \([1,n]\) 就可以把 \(p'_k\) 移动到 \(p'_n\) 上,此时 \(b'_n\) 会变成 \(b'_k\oplus 1\),如果我们需要保证 \(b'_k\) 不变,那么在操作 \([1,n]\) 之前先操作一次 \([1,1]\) 就可以使得 \(b'_k\) 移动到 \(b'_n\) 并且保持值不变
因此,我们得到了原题的操作等价于任意重排 \((S_i,T_i)\) 并且任意交换 \((S_i,T_i)\)
由于我们翻转了原序列,那么我们等价于让 \(S+T\) 变成一个回文串
考虑一组相对下标 \((i,n-i+1)\),我们需要使 \(S_i=T_{n-i+1},T_i=S_{n-i+1}\),因此对于两个相等的无序对 \(\{S_x,T_x\}\) 和 \(\{S_y,T_y\}\),我们可以把他们分别放到位置 \(i\) 和位置 \(n-i+1\) 上,使他们满足条件,可以证明这是使 \(S+T\) 回文的充要条件
因此我们维护每个无序字符对 \(\{\alpha,\beta\}\) 出现的次数,如果所有的 \(\{\alpha,\beta\}\) 出现的次数都是偶数那么满足条件
不过对于 \(n\) 为奇数的情况,我们需要恰好一对 \(\{\alpha,\alpha\}\) 是出现过奇数次,因此我们可以采用 map 来统计
时间复杂度 \(\Theta(n+\alpha^2(S)\log \alpha(S))\),\(\alpha(S)\) 为 \(S\) 的字符集大小
6. [1726D] - Edge Split
- Rating:2000
- Status:Solve
- Evaluate:Easy
定义 \(\m G_R=(\m V,\m E_R)\),即所有红边构成的图,\(\m G_B=(\m V,\m E_B)\),即所有蓝边构成的图
注意到有如下观察:
观察:
理论上 \(c_1+c_2\) 的最小值应该是 \(2\times n-m\),当且仅当 \(\m G_R\) 和 \(\m G_B\) 都是森林
考虑一个逐个加边的过程,最开始答案应该是 \(2\times n\),当我们加入一条边 \((u,v)\),加入后 \(c_1+c_2\) 会减少 \(1\) 当且仅当在与其同色的图中 \((u,v)\) 连接了两个不同的连通块,这是根据 \(c_1+c_2\) 的定义得来的
但我们又知道在一个森林中的每条边都是连接两个不同连通块的,因此每条边都对答案有 \(1\) 的贡献,故当且仅当 \(\m G_R\) 和 \(\m G_B\) 中都是森林(即无环)时 \(c_1+c_2\) 取得最小值 \(2\times n-m\)
注意到 \(m\le n+2\),这是一个非常好的性质,考虑如何利用
在得到这个观察之后,我们有一个非常显然的想法:由于原图联通,所以让 \(\m G_R\) 为原图的一棵生成树,而此时 \(\m G_B\) 中至多只有 \(3\) 条边
那么选择怎样的 \(\m G_R\) 才能保证 \(\m G_B\) 也是森林呢?由于原图中没有重边,因此当且仅当 \(\m G_B\) 为一个三元环的时候 \(\m G_R\) 不合法
注意到这样的 \(\m G_B\) 实际上不多,因此我们可以先随便确定一棵 \(\m G_R\),如果 \(\m G_B\) 是一个三元环,我们把 \(\m G_B\) 中的任意一条边放进 \(\m G_R\),然后在生成的环上随意断掉一条原来的树边即可
不妨设我们向 \(\m G_R\) 中加入一条边 \((u,v)\),我们只需要找到一条在路径 \(u\to v\) 上的边即可
对于这个问题,我们有如下的观察:
观察:
在一条路径 \(u\to v\) 中,假设 \(u\) 为深度较大的点,那么 \(u\) 到其父亲的边一定在路径 \(u\to v\) 中
证明很简单,假设 \(u\) 是一个任意的点,考虑什么时候 \(u\) 到其父亲的边不在路径 \(u\to v\) 中,显然,如果 \(u\ne \oper{lca}(u,v)\),那么 \(u\) 到其父亲的边一定在路径中,而如果 \(u=\oper{lca}(u,v)\),那么显然深度较大的点会变成 \(v\),即此时我们必然不可能选择 \(u\) 到其父亲的边,而是选择了 \(v\) 到其父亲的边
所以我们只需要随便取一棵 \(\m G_R\) 然后 dfs 预处理一下就可以了
时间复杂度 \(\Theta(m\alpha(n))\),\(\alpha(n)\) 为反阿克曼函数
7. [1704E] - Count Seconds
- Rating:2200
- Status:Hint+Data
- Evaluate:Medium
首先考虑一个最简单的想法,统计每个点会收到多少流量,最后答案为汇点接受的流量
但是这个想法无法处理部分 \(a_i=0\) 的情况,这个时候某个点可能会在若干秒后获得流量然后开始工作
不过也不是所有存在 \(a_i=0\) 的情况都不能这么统计,如果对于某个 \(a_i=0\) 的点所有的祖先都为 \(0\) 那么意味着这些点不会再获得流量,那么这样的情况称为“平凡的”零权点,这样的点对的统计答案没有影响
注意到如下的观察:
观察:
在至少 \(n\) 秒后就不存在非“平凡”的零权点
证明如下,考虑非“平凡”的零权点的生成,每个非“平凡”的零权点可以理解为祖先有流量正在运输,还没有抵达当前节点的点
那么注意到一个祖先的流量到当前点的延迟时间为这两个点的距离
由于 DAG 上最长链长度是 \(\le n\) 的,因此在 \(n\) 轮之后每个 \(a_i>0\) 的祖先都开始向当前节点运输流量
而且由于每个祖先运输流量的时间是连续的,因此当 \(a_i=0\) 时其祖先一定没有流量还在运输
根据上面的观察,我们可以先预处理出原图的拓扑序,然后模拟 \(n\) 轮后的答案,再用一次统计计算出最终的结果
时间复杂度 \(\Theta(nm)\)
8. [1684E] - MEX vs DIFF
- Rating:2100
- Status:Solve
- Evaluate:Medium
注意到有如下的观察:
观察:
最优方案一定是每次修改 \(a_i\) 为当前序列的 \(\oper{mex}\)
显然如果修改的 \(a_i<\oper{mex}\),那么其对答案的贡献至多是 \(0\),显然,做这样的一次操作肯定是不优的
假如修改 \(a_i\) 且 \(a_i>\oper{mex}\),那么一定会把 \(a_i\) 修改成另一个 \(a_j\) 的值,那么每种情况对答案的贡献为:
\(a_i\gets x\) \(cnt_{a_i}>1\) \(cnt_{a_i}=1\) \(x=\oper {mex}\) \(\oper{mex}\gets\oper{mex}+\delta+1,\oper{diff}\gets\oper{diff}+1\),贡献为 \(\delta\) \(\oper{mex}\gets\oper{mex}+\delta+1,\oper{diff}\gets\oper{diff}\),贡献为 \(\delta+1\) \(x=a_j\) \(\oper{mex}\gets\oper{mex},\oper{diff}\gets \oper{diff}\),贡献为 \(0\) \(\oper{mex}\gets\oper{mex},\oper{diff}\gets \oper{diff-1}\),贡献为 \(1\) 其中 \(\delta\) 为序列 \(a\) 中从 \(\oper{mex}+1\) 开始最多的连续自然数的数量,显然 \(\delta\ge 0\)
那么我们发现把每次 \(a_i\) 赋成 \(\oper{mex}\) 一定不弱于把 \(a_i\) 赋成某个其他的 \(a_j\) 的值
那么根据上面的分析,我们应该每次修改一个 \(>\oper{mex}\),而且注意我们修改的每一个 \(a_i\) 都应该大于最终的
\(\oper{mex}\),否则 \(a_i\) 对答案的贡献也是 \(\le 0\) 的
那么为了求出 \(\oper{mex}\),我们可以运用二分:二分 \(\oper{mex}=t\),计算需要多少次修改,与还剩下可修改的数的个数以及 \(k\) 进行对比即可
再求出了 \(\oper{mex}\) 之后,我们把所有可以修改的数拿出来,显然我们要从 \(cnt\) 小的到 \(cnt\) 大的贪心选数修改,因为这样我们可以修改尽可能多的 \(cnt=1\) 的数从而获得更多的 \(\delta+1\)
显然可以用一个小根堆维护这个过程,注意如果小根堆已经删空了,说明此时所有数 \(<\oper{mex}\),那么直接输出 0
时间复杂度 \(\Theta(n\log n)\)
9. [1682D] - Circular Spanning Tree
- Rating:2000
- Status:Solve
- Evaluate:Easy
先判定无解的情况:若所有点的度数都为偶数或者又奇数个点的度数也为奇数时,该问题无解
那么对于剩下的情况,度数为奇数的点都恰好有偶数个
我们可以先构造一条 \(1\to 2\to\cdots\to n\) 的链,然后比较度数,可以证明与目标系数不同的点也是偶数个
我们考虑把这些点按顺序把相邻的点配对,然后构造一种方法使得一对需要改变度数的 \((i,j)\) 的度数都改变奇偶性,且不影响其他点的度数
考虑令 \(\deg_i\gets \deg_i+1,\deg_j\gets \deg_j-1\),假如我们断掉 \((j,j+1)\),连接上 \((i,j+1)\) 就可以满足此构造要求
对于 \(j=n\) 的情况,假设与 \(i\) 相连且小于 \(i\) 的点为 \(x\) 我们就断掉 \((i,x)\) 替换成 \((n,x)\) 即可,由于我们的构造过程保证了对于每一个没被考虑到的的 \(i\) 这样的 \(x\) 总是存在的
10. [CF1674E] - Breaking the Wall
- Rating:2000
- Status:Hint+Data
- Evaluate:Easy
考虑两个变成非正整数的位置 \(a_i,a_j\),根据 \(|i-j|\) 的关系可以分为以下三类
- \(|i-j|=1\)
此时我们一次操作可以对于 \(a_i+a_j\) 产生 \(3\) 的贡献,因此此时的答案为 \(\left\lfloor\dfrac{a_i+a_j}3\right\rfloor\),不过当 \(\max(a_i,a_j)\ge 2\times \min(a_i,a_j)\) 时,不可能每次操作都产生 \(3\) 的贡献,而此时答案应该是 \(\left\lfloor\dfrac{\max(a_i,a_j)}2\right\rfloor\)
- \(|i-j|=2\)
无论是在 \(i,j\) 中间操作还是对着 \(i\) 或 \(j\) 操作,对 \(a_i+a_j\) 的贡献总是 \(2\),因此此时的答案为 \(\left\lfloor\dfrac{a_i+a_j}2\right\rfloor\)
- \(|i-j|>2\)
一次操作只可能对 \(a_i\) 或 \(a_j\) 中的一个产生 \(1\) 的贡献,此时的答案为 \(\left\lfloor\dfrac{a_i}2\right\rfloor+\left\lfloor\dfrac{a_j}2\right\rfloor\)
因此对于这三种情况分别处理后取最小代价即可
时间复杂度 \(\Theta(n)\)
11. [1672F] - Array Shuffling & Checker for Array Shuffling
- Rating:2000 & 2800
- Status:No Solve
- Evaluate:Hard
先考虑如何计算一个 \(\{a_i\}\) 的排列 \(\{b_i\}\) 的权值:对于个 \(i\),建立有向边 \(a_i\to b_i\),得到一张有向图 \(\m G\)
定义 \(\oper{cyc}(\m G)\) 表示 \(\m G\) 的最大环拆分的大小,即把 \(\m G\) 拆成尽可能多的环使得每条边都恰好在一个环中时拆分成环的数量
注意到如下的观察:
观察一:
\(\{b_i\}\) 的权值等于 \(n-\oper{cyc}(\m G)\)
证明如下:
注意到交换 \((b_i,b_j)\) 等价于交换 \(a_i\to b_i\) 和 \(a_i\to b_j\) 的终点,我们的目标就是使得 \(\m G\) 中产生 \(n\) 个环
而一次操作可以根据 \(b_i,b_j\) 在 \(\oper{cyc(\m G)}\) 对应的分解中分成是否在同一个环中的两种情况
由上图可得,只要 \(b_i,b_j\) 在同一个环中,无论如何 \(\m G\) 中的环数会 \(+1\),而如果 \(b_i,b_j\) 不在同一个环中,那么 \(\m G\) 中的环数一定会 \(-1\)
因此对于任意的大小为 \(k\) 的环分解,至少需要操作 \(n-k\) 次,而不断操作两个相邻的 \(b_i,b_j\) 给了我们一种操作 \(n-k\) 次的方法
综上所述,将 \(\{b_i\}\) 还原至少需要 \(n-\oper{cyc}(\m G)\) 次操作
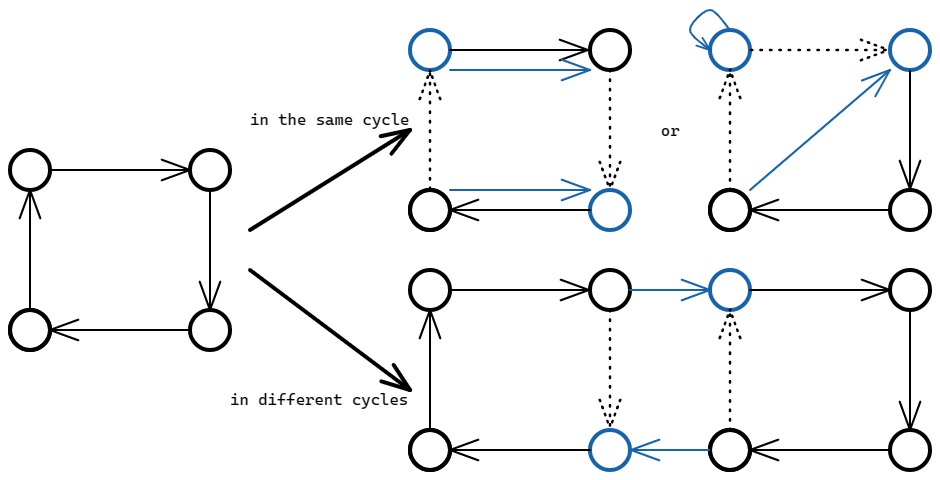
那么原问题就转化为了最小化 \(\oper{cyc}(\m G)\) 的问题
记 \(cnt_x\) 为 \(x\) 在 \(\{a_i\}\) 中的出现次数
注意到如下的观察:
观察二:
对于所有 \(\m G\) 和正整数 \(x\in [1,n]\),\(\oper{cyc}(\m G)\ge cnt_{x}\)
事实上 \(cnt_x\) 等于 \(\m G\) 中 \(x\) 的入度和出度,那么原命题可以等价于证明:
对于每个 \(\m G\) 的最大环拆分,不存在一个环经过某个 \(x\) 两次
而根据最大环拆分的定义,经过 \(x\) 两次的环会在最大环拆分中拆成两个环,因此原命题得证
我们假设 \(\{a_i\}\) 中的众数 \(m\) 出现了 \(c\) 次,根据观察二,那么答案 \(\ge n-c\)
猜测答案 \(=n-c\),即我们需要构造一个 \(\m G\) 使得 \(\oper{cyc}(\m G)=c\)
考虑什么时候 \(\oper{cyc}(\m G)=c\),注意到如下的观察:
观察三:
\(\oper{cyc}(\m G)=c \iff \oper{cycle}(\m G-\m G_m)=0\) 其中 \(\oper{cycle}\) 定义为图中的环的数量,\(\oper{cycle}(\m G-\m G_m)=0\) 即在 \(\m G\) 中删除 \(m\) 和所有与 \(m\) 相邻的边得到的新图 \(\m G-\m G_m\) 中不存在环
证明如下:
- 证 \(\oper{cyc}(\m G)=c \implies \oper{cycle}(\m G-\m G_m)=0\):
考虑逆否命题 $\oper{cycle}(\m G-\m G_m)>0\implies \oper{cyc}(\m G)>c $
那么考虑 \(\oper{cycle}(\m G-\m G_m)\) 中的一个环 \(\m C\):在子图 \(\m G-\m C\) 中,最大的度(等价于众数的出现个数)依然是 \(c\),根据观察二,得到 \(\oper{cyc}(\m G-\m C)\ge c\)
所以 \(\oper{cyc}(\m G)=\oper{cyc}(\m G-\m C)+1\ge c+1>c\)
2. 证 \(\oper{cycle}(\m G-\m G_m)=0\implies \oper{cyc}(\m G)=c\)考虑逆否命题 \(\oper{cyc}(\m G)>c \implies \oper{cycle}(\m G-\m G_m)>0\)
由于抽屉原理,在 \(\oper{cyc}(\m G)\) 个环中必然至少有一个不经过 \(m\),那么这个环的存在会使得 \(\oper{cycle}(\m G-\m G_m)>0\)
因此我们能够解决 F2:对 \(\m G-\m G_m\) 进行拓扑排序,如果存在环说明不是最优解,否则是最优解
时间复杂度 \(\Theta(n)\)
接下来继续解决 F1:
构造出一个 \(\m G\) 使得 \(\m G\) 存在一个大小为 \(c\) 的环剖分是简单的:考虑第 \(i\) 个环中包含所有 \(cnt_x\ge i\) 的 \(x\),这样每个 \(x\) 会出现在 \(cnt_x\) 个环中
那么接下来就是确定每个环的方向使得 \(\m G-\m G_m\) 是一个 DAG
有这样的一个想法,在值域 \([1,n]\) 上构造一个偏序关系 \(\succeq\) 满足:
- 对于任意 \(i,j\in [1,n]\),\((i,j)\) 在 \(\succeq\) 的定义域中
- 对于所有 \(k\in [1,n],k\ne m\),\(m\succ k\) 成立,即 \(m=\max_\succeq\{1,2,3,\cdots,n\}\)
那么对于每个环,我们将每个点按 \(\succeq\) 的顺序排序,然后从大到小连边,最小的一定会连到 \(m\) 处
此时如果删去 \(m\),剩下的所有边的方向与 \(\succeq\) 的方向相同,那么这样的图一定是 DAG
此处取偏序关系 \(\succeq\) 等价于按 \(cnt_x\) 为第一关键字,\(x\) 为第二关键字从大到小排序,\(m\) 为最大的众数
时间复杂度 \(\Theta(n\log n)\)
12. [1672E] - notepad.exe
- Rating:2200
- Status:No Solve
- Evaluate:Hard
对于一个 \(h\in[1,n]\),我们定义 \(w(h)\) 为 \(\min\{w|h(w)=h\}\),不难发现求出 \(w(1)\sim w(n)\) 即可解决原问题
首先可以二分出 \(w(1)\),即 \(\sum_{i=1}^nl_i+(n-1)\) 的值,记 \(w(1)=L\),花费次数为 \(\log_2L<30\)
注意到如下的观察:
观察:
对于所有 \(h\in(1,n]\),\(h\times w(h)\ge L-h+1\)
注意到 \(h\times w(h)\) 即显示器大小,考虑最优的情况,\(h\) 行字符每行后面都没有多余的空白,即每行字符串的长度都恰好为 \(w(h)\),此时显示其大小 \(h\times w(h)=\sum_{i=1}^nl_i+(n-h)=L-h+1\)
我们又知道对于每一个 \(h\in(1,n]\),可能影响答案的 \(h\times w(h)\) 一定是 \(\le L\) 的,否则一定不优于 \(h=1\) 的情况
因此对于每个 \(h\in(1,n]\),如果 \(h\) 可能影响答案,那么 \(h\times w(h)\in[L-h+1,L]\),注意到这个区间长度为 \(h\),又因为 \(h\mid h\times w(h)\),所以这样的 \(h\) 对应的 \(w(h)\) 都有 \(w(h)=\left\lfloor\dfrac Lh\right\rfloor\)
因此我们可以在 \(n-1\) 次询问内求每个 \(h\in(1,n]\) 的答案,与 \(L\) 取 \(\min\) 就可以得到答案,询问次数 \(n+\log_2 L\)
时间复杂度 \(\Theta(n)\)
13. [1670E] - Hemose on the Tree
- Rating:2200
- Status:No Solve
- Evaluate:Hard
诈骗题,注意到如下观察:
观察:
对于任意的一棵树,\(\text{MaxDis}\ge n\)
考虑反证法,假如每个距离都 \(<n\),那么我们考虑 \(n\) 个 \(\ge n\) 的权值和 \(n-1\) 条边
根据抽屉原理,至少有一条边的权值 \(\ge n\),那么由于我们的假设,不妨设这条边为 \((f_u,u)\),其中 \(f_u\) 表示 \(u\) 的父亲,且 \(w(f_u,u)=x\ge n\)
那么由于 \(dis(f_u)<n\),那么 \(dis(f_u,u)=dis(f_u)\oplus x\),由于 \(dis(f_u)<n=2^p\),因此 \(dis(f_u)\) 的第 \(p\) 位一定是 \(0\),而 \(x\ge n\) 因此 \(x\) 的第 \(p\) 位一定是 \(1\),异或后得到 \(dis(f_u,u)\) 的第 \(p\) 位上是 \(1\),则 \(dis(f_u,u)\ge 2^p=n\),与假设矛盾,故原命题得证
根据观察,答案至少为 \(n\),结合样例,大胆猜测答案恰好为 \(n\)
注意到对于所有 \(k\in[1,2\times n-1],k\ne n\),\(k\) 与 \(k\oplus n\) 成对出现时具有非常良好的性质,即 \(k\oplus(k\oplus n)=n\)
因此考虑除了根以外,每一对 \(\{w(u),w(u,f_u)\}\) 都是 \(\{k,k\oplus n\}\),而 \(w(root)=n\) 那么此时到每个节点的 \(dis\) 都应该是 \(0\) 或 \(n\),所以根据 \(f_u\) 等于 \(0\) 还是 \(n\) 判断 \(w(u,f_u)\) 取 \(>n\) 的还是 \(<n\) 的那个权值
根据上面的分析,我们知道对于任意指定的树根,都存在 \(\text{MaxDis}=n\) 的赋权方法,因此随便选一个树根然后 dfs 一遍整棵树就可以得到答案
时间复杂度 \(\Theta(n)\)
14. [1666J] - Job Lookup
- Rating:2100
- Status:Solve
- Evaluate:Easy
记 \(dp_{l,r}\) 表示区间 \([l,r]\) 中所有点贡献之和的最小值,我们枚举 \(dp_{l,r}\) 中的根 \(k\),则 \([l,k)\) 为 \(k\) 的左子树,\((k,r]\) 为 \(k\) 的右子树
一个显然的想法是把 \(d_{i,j}\) 拆分到每条边上统计,每条边对答案产生多少贡献那么每次合并两棵子树的时候产生的新贡献为:左子树内每个点到左子树外每个点的通话数加上右子树内每个点到右子树外每个点的通话数
假设我们记 \(C_{\m {I_1},\m {I_2}}\) 为 \(x\in \m {I_1},y\in\m{I_2}\) 的 \(c_{x,y}\) 的和,其中 \(\m{I_1},\m{I_2}\) 为两个区间,可以通过二维前缀和快速查询,那么状态转移方程如下:
\]
构造方案时记录每个 \([l,r]\) 转移时最优的 \(k\),递归计算 \([l,k)\) 和 \((k,r]\) 子树的形态即可
时间复杂度 \(\Theta(n^3)\)
15. [1666I] - Interactive Treasure Hunt
- Rating:2200
- Status:Solve
- Evaluate:Medium
注意到对于第一次询问 SCAN r c,由于我们不知道 \(r,r_1,r_2\) 和 \(c,c_1,c_2\) 之间的大小关系,因此这个东西不太好入手,考虑如何去掉绝对值
注意到在 \((r,c)\) 为矩形的四个角的时候,我们能同时拆掉两个绝对值,因此从四个角入手
执行这四个查询操作能够得到的对 \((r_1,r_2,c_1,c_2)\) 的限制方程,我们能够联想到通过解方程组来证明这样的 \((r_1,r_2,c_1,c_2)\) 是唯一的
我们可以得到联立这四个方程得到的方程组对应的行列式应该形如下面的形式:
r_1\\
r_2\\
c_1\\
c_2
\end{bmatrix}
\times
\begin{bmatrix}
1&1&1&1\\
1&1&-1&-1\\
-1&-1&1&1\\
-1&-1&-1&-1
\end{bmatrix}
=
\begin{bmatrix}
v_1\\
v_2\\
v_3\\
v_4
\end{bmatrix}
\]
不过我们发现这样询问四个角的做法是错误的,原因是系数矩阵中有线性相关的行向量,因此我们需要重新选取恰当的四个询问点
注意到询问左上角和右上角得到的两个向量是线性无关的,因此保留询问左上角和右上角的过程可以保留下来
设询问左上角得到回答 \(v_1\),询问右上角得到回答 \(v_2\) 得到的方程组应该为:
(r_1+r_2)+(c_1+c_2)&=v_1+4\\
(r_1+r_2)-(c_1+c_2)&=v_2-2m+2
\end{cases}
\]
那么我们把 \(r_1+r_2\) 和 \(c_1+c_2\) 看成两个整体,我们能够解得这两个整体的值
此时我们还剩下两个向量没确定,显然在剩下的两个方程中,\(r_1,r_2\) 系数不同和 \(c_1,c_2\) 系数不同至少有一个要成立
假设 \(r_1,r_2\) 系数不同那么我们询问的列 \(r\) 应该满足 \(\min(r_1,r_2)\le r\le \max(r_1,r_2)\),我们发现 \(\left\lfloor\dfrac{r_1+r_2}2\right\rfloor\) 恰好满足条件,我们在这一行中任取一列询问即可得到第三个方程
类似计算第三个方程的过程,我们在第 \(\left\lfloor\dfrac{c_1+c_2}2\right\rfloor\) 列中任取一行询问可以得到第四个方程
最后,我们联立这四个方程能够解出 \(r_1,r_2,c_1,c_2\),由于 \(n\) 和 \(m\) 很小,暴力枚举也可以通过
不过注意到我们实际上不能得到 \(r_1,r_2\) 之间和 \(c_1,c_2\) 之间的实际大小关系,这意味着我们将无法分辨 \(\{(r_1,c_1),(r_2,c_2)\}\) 和 \(\{(r_1,c_2),(r_2,c_1)\}\) 中哪一个点对才是真正的答案
不过我们注意到目前只用了 \(4\) 次操作,除去提交答案的 \(2\) 次操作还剩 \(1\) 次操作,因此可以先操作 DIG r1 c1,通过返回的结果是 \(1\) 还是 \(0\) 分辨到底是哪两个点对,总的操作次数在 \(6\) 和 \(7\) 之间
时间复杂度 \(\Theta(n^2m^2)\)
16. [1665D] - GCD Guess
- Rating:2000
- Status:Solve
- Evaluate:Medium
注意到 \(\gcd(x+a,x+b)=\gcd(x+a,|a-b|)\),因此有一个朴素的想法,由于 \(2\times3\times5\times7\times11\times13\times17\times19\times23\times29\ge 10^9\),所以求出 \(x\bmod 2\sim x\bmod29\) 的值用 CRT 求解即可
不过我们每次询问一个 \(\gcd(x+r,p)\) 只能判断 \(x\equiv -r\pmod p\) 是否成立,因此在最坏情况下我们需要依次检查在模每个质数的情况下的每个余数,显然会超过 \(30\) 次的限制
因此我们考虑如何压缩状态,比如对于 \(p\) 和 \(q\),我们询问 \(\gcd(x+r,p\times q)\),可以同时得到 \(x\equiv -r\pmod p\) 和 \(x\equiv -r\pmod q\) 是否成立,那么如果我们把多个质数乘在一起,在确定最大的质数的余数时我们能够同时计算出较小的一些质数的余数
所以直接将 \(10\) 个质数乘在一起,然后枚举 \(29\) 次,每次用 CRT 算出应该询问多少,使得对于每个模数每次都能排除一种可能的余数,这样的操作次数为 \(29\) 次
假设我们选用的所有质数乘积为 \(P\),那么可能出现的最大的一对询问为 \((P,2\times P)\),这就需要我们保证 \(P\le 10^9\),不过显然 \(2\) 乘到 \(29\) 超过了这个限制,因此我们需要在这个模数集合中去掉一些数使得 \(P\le 10^9\)
但是如果 \(P\le 10^9\),即使我们求出了合法的 \(r\) 我们有可能将无法确定哪个 \(r+kP\) 是答案
显然,存在一种方法使得 \(5\times 10^8 \le P\le 10^9\),那么这个时候 \(k\in\{0,1\}\)
注意到我们只询问了 \(29\) 次,而剩下的一次可以随意取这些模数这之外的一个质数 \(t\),询问 \(\gcd(x+(-r\bmod t),t)\),此时如果 \(\gcd\) 为 \(t\) 说明答案为 \(r\),否则答案为 \(r+P\)
给一组合法的构造:\(P=3\times 7\times 11\times 13\times 17\times19\times23\times29\approx6.5\times 10^8,t=5\)
这样我们就可以在恰好 \(30\) 次操作之后求出答案
时间复杂度 \(\Theta(1)\)
17. [1659E] - AND MEX Walk
- Rating:2000
- Status:Hint
- Evaluate:Medium
注意到如下的观察:
对于任意的节点对 \((u,v)\),其答案只有可能是 \(0,1,2\) 中的一个
对于任意的路径 \(u\to v\) 记 \(s_i=w_1\&w_2\&\cdots\&w_i\) 注意到 \(s_1\supseteq s_2\supseteq\cdots\),那么显然 \(u\to v\) 中不可能同时出现 \(1\) 和 \(2\) 故对于任何一条路径其 \(\oper{mex}\le 2\)
所以我们只需要解决两个问题:
- 是否存在一条路径 \(u\to v\) 使得 \(\{s_i\}\) 中不出现 \(0\)
- 是否存在一条路径 \(u\to v\) 使得 \(\{s_i\}\) 中不出现 \(1\)
先解决第一个问题:
显然,假如 \(\{s_i\}\) 中没有 \(0\),那么一定有至少一个二进制位 \(k\) 一直保持为 \(1\),即我们经过所有的边权 \(w_i\) 的第 \(k\) 位都是 \(1\)
因此我们可以对于每个 \(k\in[0,30)\) 维护一个图 \(\m G_k\),把所有满足 \(w\) 的第 \(k\) 为 \(1\) 的边加入 \(\m G_k\) 中,如果在某个 \(\m G_k\) 中 \((u,v)\) 联通,那么说明存在路径 \(u\to v\) 使得第 \(k\) 位一直保持为 \(1\),答案为 \(0\),如果不存在这样的 \(k\),那么答案至少为 \(1\),我们再去解决第二个问题
考虑第二个问题:
由于此时所有路径 \(u\to v\) 都包含 \(0\),因此只要解决这个问题就能确定答案是 \(1\) 还是 \(2\) 了
考虑 \(\{s_i\}\) 中的第 \(0\) 位,有如下两种情况:
- \(\{s_i\}\) 的第 \(0\) 位一直是 \(0\),此时对于所有 \(2\mid w\) 的边加入一张新图中并维护 \((u,v)\) 连通性即可
- 在 \(s_{i}\to s_{i+1}\) 时 \(s_i\) 的第 \(0\) 位从 \(1\) 变成 \(0\),且 \(s_{i}\) 中除第 \(0\) 位外至少有一个位置值为 \(1\),类似问题一对于所有 \(k\in(0,30)\) 的 \(k\),将所有第 \(k\) 位和第 \(0\) 位都为 \(1\) 的边加入一个图 \(\m G'_k\) 中,而对于 \(\m G'_k\) 中的一个连通块,如果原图中存在一条 \(2\mid w\) 的边连接其中的一个点,那么这个连通块里的所有点都可以通过经过这条边得到一个合法的 \(s_{i+1}\)
因此对于每个问题我们维护 \(n\log w\) 个并查集即可
时间复杂度 \(\Theta((m+q)\alpha(n)\log w)\)
18. [1656E] - Equal Tree Sums
- Rating:2200
- Status:No Solve
- Evaluate:Hard
不妨记节点 \(root\) 为根,记 \(A=\sum_{i=1}^na_i\)
对于每个节点 \(u\),假设其度数为 \(d_u\),子树权值和为 \(s_u\),且去掉 \(u\) 之后会形成的连通块权值和为 \(v_u\)
那么对于所有 \(u\),我们有 \(d_u\times v_u+a_u=A\),对于每个不为根的 \(u\) 运用 \(v_u=(d_u-1)\times s_u\) 稍作变形得到 \(v_u=(d_u-1)\times s_u+a_u=A-s_u=A-v_{son(u)}\)
因此对于每个 \(u\ne root\),我们有 \(v_u+v_{son(u)}=A\),一个自然的想法是先假设 \(A=0\),此时对于每个 \(u\ne root\),\(v_{son(u)}=-v_u\)
我们对于一个叶子 \(l\),考虑 \(a_l\) 的值,假设 \(v_l=a_l=1\),那么 \(l\) 的父亲 \(f\) 的权值为 \(-d_f\),而 \(v_f=-1\),而 \(f\) 的父亲 \(g\) 又有 \(a_g=d_g,v_g=1\)
根据这样的观察,我们可以大胆假设 \(a_i=d_i\times(-1)^{d}\),可以证明这样构造的总是合法的,且满足 \(v_i=[i\ne root]\times(-1)^{d_i}\):
对于叶子结点,显然有 \(d_i=1,v_i=a_i\),这是成立的
接下来我们按照深度序进行归纳:对于任意一个节点 \(u\),设其所有儿子 \(p\) 都满足 \(v_p=(-1)^{d}\)
- 如果 \(u\ne root\),那么 \(v_u=(d_u-1)\times(-1)^{d_u+1}+d_u\times(-1)^{d_u}=(-1)^{d_u}\)
- 如果 \(u=root\),那么 \(v_u=d_u\times(-1)^{d_u+1}+d_u\times(-1)^{d_u}=0\)
那么从任意一个点作为根 dfs 一遍整棵树即可
时间复杂度 \(\Theta(n)\)
19. [1646D] - Weight the Tree
- Rating:2000
- Status:Hint
- Evaluate:Medium
注意到如下的观察:
观察:
对于任意 \(n\ge 3\),树上不会有任何两个相邻的好节点
假设树上有一条边 \((u,v)\),由于 \(n\ge 3\),因此至少有一个点的度数 \(\ge 2\),设 \(\deg(u)\ge 2\)
此时若 \(u\) 和 \(v\) 均为好节点,由于 \(w_u=w_v+\sum_{(v',u)} w_{v'}\),而由于 \(w_i\in\mathbb {Z^+}\),所以 \(w_u>w_v\),同理由于 \(v\) 是好节点,所以 \(w_v\ge w_u\),故矛盾
特别地,若 \(n=2\) 则 \(u,v\) 度数均为 \(1\),所以 \(w_u=w_v\) 时可以选择两个好节点相邻
简单讨论剩下的情况:
- 若 \(u\) 不为好节点,那么 \(w_u\) 为任意正整数,由于我们要最小化答案,因此不妨令 \(w_u=1\)
- 若 \(u\) 为好节点,那么 \(u\) 相邻的所有点都不是好节点,其权值都为 \(1\),因此 \(w_u=\deg(u)\)
可以证明这样的方案是最优的,注意到只要确定所有非好节点的权值就可以确定所有的节点的权值,假如某个非好节点权值改变使得 \(w_u\gets w_u+1\),那么所有与 \(u\) 相邻的好节点的权值也要 \(+1\),因此令 \(w_u\) 尽可能小,显然选择 \(1\) 最优
剩下确定每个点是不是好节点的过程可以考虑使用 dp,令 \(dp_{u,1/0}\) 表示以 \(u\) 为根的子树中选择或没选择 \(u\) 作为好节点时的好节点个数的最大值,由于两个好节点不能相邻,那么这个过程就变成了很经典的树上选点问题,可以写出转移方程:
dp_{u,0}&=\sum_{v\in son(u)} \max(dp_{v,0},dp_{v,1})\\
dp_{u,1}&=1+\sum_{v\in son(u)} dp_{v,0}
\end{cases}
\]
而最小化权值只需要在比较两个方案优劣的时候作为比较的第二关键字顺便转移一下即可
构造方案时按照转移顺序计算每个节点是由子节点的 \(0\) 状态还是 \(1\) 状态转移过来,递归构造即可
时间复杂度 \(\Theta(n)\)
20. [1641B] - Repetitions Decoding
- Rating:2000
- Status:No Solve
- Evaluate:Hard
显然,如果有元素出现次数为奇数,则必定无解
考虑如何用题目中的操作复制一个序列 1 2 3 4,显然每次在序列中间插入下一个数可以得到序列 1 2 3 4 4 3 2 1
考虑 \(a_1\) 和谁匹配,显然我们应该找到第一个和 \(a_1\) 值相等的数 \(a_i\),然后在 \(a_i\) 的后面复制 \(a_{2}\sim a_{i-1}\),此时我们可以消掉 \(a_1\sim a_i\),并且留下序列 \(a_{i-1}\sim a_2\),注意到每次这样的操作会让原序列未匹配数减少 \(2\),而每次这样的操作需要至多 \(n\) 轮复制,那么这样的复制总次数大概在 \(\dfrac {n^2}2\) 左右,因此可以通过本题
代码实现用 vector 每次调用 reverse 函数和 erase 函数即可
时间复杂度 \(\Theta(n^2)\)
21. [1638D] - Big Brush
- Rating:2000
- Status:Solve
- Evaluate:Easy
考虑从结果入手,每次选择一个 \(2\times2\) 的同色方格清空,最后倒序操作即可
由于每个位置只会被最后一个操作覆盖,那么倒序操作时已经被操作的格子可以重复操作
因此每次选择一个合法的同色方格清空一定没有后效性,注意到每个格子至多被清空一次,所以操作次数一定在 \(n\times m\) 以内
不过如果暴力找操作位置是 \(\Theta(nm)\) 的,重复 \(n\times m\) 次会超时
注意到清空一个方格后,只有可能影响与其相交的 \(9\) 个方格,使得这些方格可以被操作,因此做一遍 BFS 即可
如果 BFS 结束后还有位置没被清空则输出无解
时间复杂度 \(\Theta(nm)\)
22. [1635E] - Cars
- Rating:2200
- Status:Solve
- Evaluate:Easy
注意到确定位置的过程是和每个点的方向有关的,因此考虑先确定方向
注意到如果 \((u,v)\) 出现在限制中,那么无论是相遇还是不相遇,都能保证 \(u\) 和 \(v\) 方向不同,因此把 \(\{ori_i\}\) 看成 \(n\) 个 01 变量解一遍 2-SAT 即可得到每个点的方向
注意到这里的 2-SAT 只存在 \(ori_u\oplus ori_v=1\) 的限制,可以用扩域并查集求解,具体过程和用 tarjan 解 2-SAT 比较类似,令 \(i\) 表示 \(ori_i=0\),\(i+n\) 表示 \(ori_i=1\):
- 合并所有 \(u+n,v\) 和 \(u,v+n\)
- 如果存在 \(u,u+n\) 在同一个块内,则该 2-SAT 无解
- 讨论每个块的 01 情况,用一个标记维护每个块是否确定了 01 情况,对于每个 \(u\),有如下三种情况:
- 如果 \(u\) 和 \(u+n\) 所在的块都未被标记,则令 \(ori_u=0\),并标记 \(u\) 所在块
- 如果 \(u\) 所在的块被标记,则 \(ori_u=0\)
- 如果 \(u+n\) 所在的块被标记,则 \(ori_u=1\)
这样我们能够确定一组合法的 \(\{ori_i\}\),那么此时再对于 \((u,v)\) 讨论能够得到每对 \(x_u,x_v\) 的相对大小关系
因此我们可以建立一个差分约束系统,注意到这个系统的所有边权都是 \(-1\) 的,因此只需要对其进行拓扑排序即可,\(x_u\) 即为 \(u\) 的拓扑序,如果差分系统中有环,那么该差分系统一定无解
不过我们需要保证对于任何一组合法的 \(\{ori_i\}\),如果其对应的差分系统无解,则原问题无解
我们只能通过每次对一个块内所有节点取反来修改 \(\{ori_i\}\),注意到如果差分系统中存在一个环,那么这个环中的节点一定是在一个块内的,假如我们对这个块内所有节点的 \(ori_i\) 取反,等价于对这个差分系统里这些节点之间的边取反,显然这样的操作是不可能消掉差分系统里的环的
因此只要求解出随意一组合法的 \(\{ori_i\}\) 都不会对答案产生影响
时间复杂度 \(\Theta(m\alpha(n))\)
23. [1634D] - Finding Zero
- Rating:2000
- Status:Solve
- Evaluate:Medium
同样的序列交互找特殊位置的问题,感觉上和 1762D 有点相似,那么考虑能否借鉴这道题的思路来求解
在 1762D 中,我们每次用 \(2\) 个询问来在 \(3\) 个元素中排除掉 \(1\) 个必然不为 \(0\) 的元素,并且实时维护可能为答案的 \((x,y)\),那么在这个题目中,显然每次不能选 \(3\) 个元素进行排除,考虑每次在 \(4\) 个元素中排除 \(2\) 个元素
那么由于操作限制为 \(2n-2\),因此对于每次排除可以进行 \(4\) 个询问,所以我们可以求出对于其中任意三个元素进行询问得到的答案
此时考虑进行排除的四个数 \(a,b,c,d\),不妨设 \(a<b<c< d\),显然只有 \(a\) 可能为 \(0\) 那么对于任何一个操作,我们能够得到:
- \(\max(a,b,c)-\min(a,b,c)=c-a\)
- \(\max(a,b,d)-\min(a,b,d)=d-a\)
- \(\max(a,c,d)-\min(a,c,d)=d-a\)
- \(\max(b,c,d)-\min(b,c,d)=d-b\)
观察到结果中有两个 \(d-a\),而且我们知道 \(d-a>c-a\) 且 \(d-a>d-b\),因此四个结果中的最大值出现过两次,找到这两次对应的询问,而在两次询问中都出现的 \(2\) 个元素即为 \(a,d\),那么排除掉剩下的 \(2\) 个即可
不过由于题目不保证非 \(0\) 的 \(a_i\) 两两不等,因此我们实际上要考虑 \(a\le b\le c\le d\),注意到只有 \(a=0\) 时排除操作有意义,所以实际上 \(a<b\) 依然成立,因此 \(d-a>d-b\),又因为在剩下的 \(3\) 个三元组 \((a,b,c),(a,b,d),(a,c,d)\) 中任取 \(2\) 个的交都包含 \(a\),因此这个解决方案是可行的
不过由于我们每次排除 \(2\) 个元素,假如 \(2\nmid n\),那么有一个数会没有被考察过,我们可以在剩下的数中任取一个拿进来一起排除即可
计算一下操作次数:
- \(2\mid n\) 时:操作次数为 \(4\times\dfrac{n-2}2=2n-4\)
- \(2\nmid n\) 时:操作次数为 \(4\times\left(1+\dfrac{n-3}2\right)=2n-2\)
因此这个策略是可以通过本题的
时间复杂度 \(\Theta(n)\)
24. [1624F] - Interacdive Problem
- Rating:2000
- Status:Solve
- Evaluate:Easy
假设每次询问操作不会改变 \(x\) 的值,而是返回 \(\left\lfloor\dfrac {x+c}n\right\rfloor\) 的值
显然,对于一个询问 + c,返回 \(0\) 当且仅当 \(x+c<n\),而返回 \(1\) 当且仅当 \(x+c\ge n\),考虑二分出最小的 \(c\) 使答案为 \(1\),那么 \(x=n-c\),由于 \(c\in[1,n)\),所以需要操作次数为 \(\log_2n\le 10\) 次
接下来考虑这道题,假设初始 \(x\) 值为 \(x_0\),设当前所有操作的 \(c\) 之和为 \(S\),那么假如我们仍然想比较 \(x+c\) 和 \(n\) 的大小,那么设上一次操作的答案为 \(k\),则我们需要找到一个 \(q\) 使得 \(x+S+q\ge (k+1)\times n\iff x+c\ge n\),移项比较可得 \(q=c-(S-k\times n)=(c-S)\bmod n\),因此每次询问 \((c-S)\bmod n\) 继续采用原来的二分策略即可
时间复杂度 \(\Theta(\log n)\)
25. [1621D] - The Winter Hike
- Rating:2000
- Status:Hint
- Evaluate:Medium
显然右下部分所有积雪必定清空,而我们注意到如下的观察:
观察:
对于任何一种操作方案,至少会经过右上部分的四个顶点或左下部分的四个顶点之一
假如我们操作左上部分,的第 \(1\) 行、第 \(n\) 行、第 \(1\) 列、第 \(n\) 列中的任何一个,左上部分的 \(4\) 个端点中必有一个接触到这 \(8\) 个顶点之一
而且我们发现这 \(8\) 个顶点都是可以直接到达右下部分的,如下图所示:
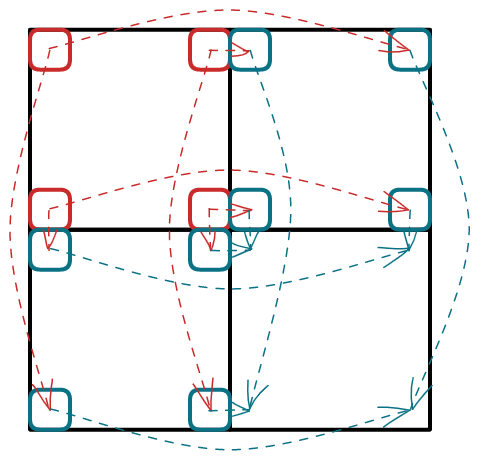
其中红色的边为每个学生走到积雪上的可能路径,而蓝色的边表示从这 \(8\) 个特殊格子最终走到右下部分的路径
因此我们只需要这 \(8\) 个格子中 \(c\) 值的 \(\min\) 加上右下部分 \(c\) 值的和即可
时间复杂度 \(\Theta(n^2)\)
26. [1620D] - Exact Change
- Rating:2000
- Status:Data
- Evaluate:Easy
设 \(v=\max_{i=1}^n\{a_i\}\)
有一个显然的策略:选 \(\left\lfloor\dfrac v3\right\rfloor\) 个 \(3\),然后选 \(1\) 和 \(2\) 补余数,如果所有 \(a_i\) 中没有 \(\bmod 3=1\) 的就不选 \(1\),同理如果 \(a_i\) 中没有 \(\bmod 3=2\) 的就不选 \(2\)
可以证明当 \(1,2\) 中选了 \(\le 1\) 个时,答案不会更优,而如果 \(1,2\) 都选了
- 如果 \(v\bmod 3=0\),显然可以将一个 \(3\) 去掉,用 \(1+2\) 取代 \(3\)
- 如果 \(v\bmod 3=1\),去掉一个 \(3\) 和一个 \(1\),加入一个 \(2\),用 \(2+2\) 取代 \(1+3\),不过需要特别注意的是如果 \(a_i\) 中出现了 \(v-1\) 或 \(1\) 是不能这么更换的
- 如果 \(v\bmod 3=2\) 没有更优的策略
因此根据上面的规则简单模拟即可
时间复杂度 \(\Theta(n)\)
27. [1619F] - Let's Play the Hat?
- Rating:2000
- Status:Solve
- Evaluate:Easy
考虑一个显然的贪心:按 \(b_i\) 从小到大对 \(i\) 排序,并且把 \(b_i\) 较小的人优先放到大桌子上
事实上这个贪心的正确性很好证明:
对于任意 \(k\),这样的贪心总是满足 \(\max\{b_i\}-\min\{b_i\}\le 1\)
对 \(k\) 采用归纳法:容易证明 \(k=0\) 时 \(\max\{b_i\}-\min\{b_i\}=0\le 1\),因此我们只需要考虑对于一个满足的限制的 \(\{b_i\}\) 操作即可
记此时 \(\{b_i\}\) 中 \(b_i=\min\{b_i\}\) 的有 \(k\) 个,而大桌子能坐的总人数为 \(t\),有以下三种情况:
- \(t<k\):此时一部分 \(\min\{b_i\}\) 变成 \(\min\{b_i\}+1=\max\{b_i\}\),此时 \(\min\{b_i\}\) 和 \(\max\{b_i\}\) 都不变
- \(t=k\):此时所有 \(\min\{b_i\}\)都 变成 \(\min\{b_i\}+1=\max\{b_i\}\),此时 \(\min\{b_i\}\gets\min\{b_i\}+1\),\(\max\{b_i\}\) 不变
- \(t>k\):此时所有 \(\min\{b_i\}\) 变成 \(\min\{b_i\}+1=\max\{b_i\}\),此时一部分 \(\max\{b_i\}\) 变成 \(\max\{b_i\}+1\),此时 \(\min\{b_i\}\gets\min\{b_i\}+1\),\(\max\{b_i\}\gets\max\{b_i\}+1\)
显然以上三种情况都不会增加 \(\max\{b_i\}-\min\{b_i\}\) 的大小,因此这个贪心是正确的
可以考虑用排序或者优先队列维护
时间复杂度 \(\Theta(nk\log n)\)
28. [1605D] - Treelabeling
- Rating:2100
- Status:Hint
- Evaluate:Medium
记 \(\oper{bit}(x)\) 表示 \(x\) 二进制下的最高位
考虑 \(u\oplus v\le \min(u,v)\) 的等价条件,发现 \(u\oplus v\le \min(u,v)\iff \oper{bit}(u)=bit(v)\),证明如下:
- 证明 \(\oper{bit}(u)=\oper{bit}(v)\implies u\oplus v\le \min(u,v)\)
考虑 \(u\oplus v\) 的第 \(\oper{bit}(u)\) 位,显然为 \(1\oplus1=0\),因此 \(\oper{bit}(u\oplus v)<\oper{bit}(u)=\oper{bit}(v)\),所以 \(u\oplus v\le\min(u,v)\)
- 证明 \(u\oplus v\le \min(u,v)\implies \oper{bit}(u)=bit(v)\)
不妨设 \(u\ge v\),考虑其逆否命题 \(\oper{bit}(u)>\oper{bit}(v)\implies u\oplus v>\min(u,v)\)
考虑 \(u\oplus v\) 的第 \(\oper{bit}(u)\) 位,显然为 \(1\oplus0=1\),因此 \(\oper{bit}(u\oplus v)=\oper{bit}(u)>\oper{bit}(v)\),所以 \(u\oplus v>\min(u,v)=v\)
设 \(\oper{bit}(n)=k\),我们可以根据 \(\oper{bit}\) 值把 \(1\sim n\) 分为 \(k+1\) 类
注意到如下的观察:
观察:
总存在一种染色方案使得无论从哪个点出发,Sushi 都无法进行任何一次移动
考虑对图黑白染色,我们只需要保证对于 \(k+1\) 个类,不存在一个类中同时包含黑色点和白色点上的数
那么我们需要把这 \(k+1\) 个类划分到黑色或者白色里面去
注意到前 \(k\) 个 \(\oper{bit}\) 类的大小恰好是 \(2^0\sim 2^{k-1}\),因此可以表示出 \(1\sim 2^k-1\) 之间的所有数
由于我们可以证明黑色点集和白色点集中较小的一个的大小一定 \(<2^k\),因此我们可以用前 \(k\) 类权值表示其中一个点集,剩下的表示另外一个点集即可
按照上面所述的构造求解即可,时间复杂度 \(\Theta(n)\)
29. [1593D] - Changing Brackets
- Rating:2200
- Status:No Solve
- Evaluate:Hard
由于题目数据进行了保证,以下的讨论均在 \(|S|\) 为偶数的前提下进行
记 \(\oper{cost}(S)\) 表示按题目要求使得 \(S\) 变成有一个合法括号序列的最小代价
注意到 [ 和],( 和 ) 没有区别,因为它们可以在不花费代价的情况下互相转化
所以我们只需要防止形如 ([)] 的情况出现即可
观察一个合法的序列,我们发现任意一对匹配的 [] 中间都有一个合法的括号序列,而这个括号序列的长度一定是偶数
因此每一对匹配的 [ 和 ],这两个字符在原串的下标一定是一奇一偶的
假设在串 \(S\) 中,奇数位置上的中括号有 \(c_1\) 个,偶数位置上的中括号有 \(c_2\) 个,注意到如下观察:
观察:
对于任意 \(S\),\(\oper{cost}(S)=0\iff c_1=c_2\)
考虑对 \(\min(c_1,c_2)\) 归纳:
当 \(\min(c_1,c_2)=0\) 的时候,若 \(c_1=c_2=0\),那么显然 \(S\) 可以通过把前一半小括号变成
(,后一半小括号变成)来满足题目要求如果 \(\max(c_1,c_2)>0\),此时可以证明任意两个中括号间的字符数量都是奇数,因此这中间不存在任何一对可以配对的中括号
由于在一个合法的括号匹配序列中,任取一段匹配的子串删去仍然是一个合法的括号匹配
那么当 \(c_1,c_2\ne0\) 我们必然可以找到一对相邻的,分别处于奇偶位置上的中括号,我们取出这两个中括号和其中间的所有字符构成的子串
容易发现其中间恰好有偶数个小括号,而有且仅有两侧的中括号,显然这个子串可以在 \(0\) 的代价内处理成一个匹配括号序列,因此将这个序列从 \(S\) 中删去,容易发现 \(\min(c_1,c_2)\gets\min(c_1,c_2)-1\),那么根据归纳假设即得证
因此我们能够大胆猜想,对于任意 \(S\),\(\oper{cost}(S)=|c_1-c_2|\)
证明:
- \(\oper{cost}(S)\ge |c_1-c_2|\)
考虑对每个代价为 \(1\) 的操作,显然可以通过枚举分讨证明一次修改只会对 \(c_1-c_2\) 产生 \(\pm 1\) 的贡献,所以想要使得 \(c_1-c_2=0\),至少需要 \(|c_1-c_2|\) 次代价为 \(1\) 的操作
- \(\oper{cost}(S)\le |c_1-c_2|\)
显然每次将 \(c_1,c_2\) 中较大的那个数对应的那些下标中选一个操作成小括号即可得到一个代价为 \(|c_1-c_2|\) 的操作方案,所以 \(\oper{cost}(S)\le |c_1-c_2|\)
因此结合两个方向的不等号得到 \(\oper{cost}(S)=|c_1-c_2|\)
因此每次计算一个子段的答案只需要预处理出 \(c_1\) 和 \(c_2\) 的前缀和即可 \(\Theta(1)\) 处理每次询问
时间复杂度 \(\Theta(n+q)\)
30. [1583E] - Moment of Bloom
- Rating:2200
- Status:No Solve
- Evaluate:Hard
考虑一个点周围的边覆盖次数的综合,对于一条 \(a\to b\) 的路径,其在路径中间的贡献为 \(2\),而在路径两边的贡献为 \(1\)
因此我们记录 \(d_v\) 为 \(v\) 在 \(q\) 对 \((a_i,b_i)\) 中出现的次数并考虑 \(d_v\bmod 2\) 的值,显然如果 \(d_v\bmod 2=1\) 无解
考虑所有 \(d_v\) 均为偶数的情况,注意到如下观察:
观察:
在保证所有 \(d_v\) 都是偶数的情况下,任取一棵原图的生成树,对于所有 \((a_i,b_i)\) 取 \(a_i\to b_i\) 的树上简单路径,此时构造满足题目要求
对树的大小进行归纳:
考虑树的任意一个叶子 \(u\),由于 \(2\mid d_u\),注意到此时根据构造有 \(w(u,fa_u)=d_u\equiv0\pmod 2\),因此我们可以删去 \(u\) 到其父亲的边
所以此时我们把从 \(u\) 出发的 \(d_u\) 条路径扔到 \(fa_u\) 上,即令 \(d_{fa_u}\gets d_{fa_u}+d_u\),此时由于 \(2\mid d_{fa_u},2|d_{u}\),因此新的 \(d_{fa_u}\) 仍然是偶数
然后我们在树中删除节点 \(u\) 和边 \((u,fa_u)\),此时得到的新树的一个合法的解也对应原树的一个合法的解,然后在新树上运用归纳假设即可证明原命题
所以求出图中的一棵生成树然后对于每个询问用朴素算法求 LCA 并且输出路径即可
时间复杂度 \(\Theta(nq)\)
31. [1567D] - Expression Evaluation Error
- Rating:2000
- Status:Solve
- Evaluate:Easy
考虑对 \(\{a_i\}\) 在 \(10\) 进制下求和的过程,假如我们在 \(10\) 进制下产生了一个从 \(k\to k+1\) 的进位,那么在 \(11\) 进制下我们就把一个 \(11^{k+1}\) 变成了 \(10\) 个 \(11^k\),相当于损失了一个 \(11^k\),因此我们应该尽可能减少进位
首先考虑对 \(S\) 的每个位拆成若干个 \(10^k\),每个 1 数码给到一个不同的 \(a_i\) 上,这样可以尽可能覆盖更多的 \(a_i\),如果此时我们覆盖的 \(a_i\) 仍然不足 \(n\) 个,那就从 \(10^1\) 开始,从小到大对于每个 \(k\) 拆成 \(10\) 个 \(10^{k-1}\) 分给若干还是 \(0\) 的 \(a_i\),如果某个时刻 \(>0\) 的 \(a_i\) 的数量超过 \(n\) 就终止
对于每次分拆找 \(k\) 的过程,注意到这样的过程至多执行 \(n\) 次,因此可以直接每次对所有数码对应的 \(k\) 重新排序,然后找到最小的非 \(0\) 的 \(k\)
时间复杂度 \(\Theta(n^2\log n)\)
32. [1566E] - Buds Re-hanging
- Rating:2000
- Status:No Solve
- Evaluate:Hard
首先注意到,每一次把一个 bud 节点放到一个叶子上,会使得叶子结点的总数 \(-1\),因此考虑尽可能多地提取出 bud 节点
假如我们已经把所有的 bud 节点都提取出来了,那么接下来考虑按照提取的顺序依次加入剩下的节点构成的剩余树上
假设我们有 \(k\) 个 bud 节点,对于剩下的 \(n-k\) 个节点显然除了根就都是叶子,一次添加能够减少 \(1\) 个叶子,因此的答案为 \(n-2\times k-1\),特别地,如果删去所有 bud 节点,而剩下的点只有一个根的话,第一次添加并不会减少一个叶子,而此时答案为 \(n-2\times k\)
而在求所有 bud 节点的时候,我们记录下每个点是否为 bud 节点,如果一个节点所有儿子中有一个不是 bud 节点,那么这个节点一定是 bud 节点,否则则不是 bud 节点,因此我们把“是不是 bud 节点”作为 dfs 的返回值即可
时间复杂度 \(\Theta(n)\)
33. [1560F2]- Nearest Beautiful Number (hard version)
- Rating:2100
- Status:Solve
- Evaluate:Easy
考虑直接进行 dp,记 \(dp_{i,\m S}\) 表示当前填第 \(i\) 位,用过的数码构成集合 \(\m S\) 时,第 \(i\sim 0\) 位所取得的的最小数值,然后状压 \(\m S\) 再套一个 dfs 解数位 dp 的板子即可,搜索的时候要记住从理论最高位(第 \(9\) 位)开始搜索并且记录一下当前是否在前导零状态下即可
由于其取得最小数值一定要先让高位尽可能小,因此查到一组解可以直接 break
时间复杂度 \(\Theta(2^{10}\cdot\log_{10}n)\)
34. [1558C] - Bottom-Tier Reversals
- Rating:2000
- Status:Hint
- Evaluate:Medium
首先,我们注意到对于每次操作,每个值所在下标的奇偶性并不会改变,因此我们得到了一个有解的必要条件:对于任意 \(i\),有 \(a_i\equiv i\pmod 2\)
在剩下的情况中,由于总限制是 \(\tfrac 52n\),因此我们考虑对于两个数一起打包归位,每次归位两个数花费 \(5\) 次操作,我们考虑如下的操作步骤:
- 在 \(5\) 次操作内将 \(n\) 和 \(n-1\) 归位
- 递归求解剩下的 \(n-2\) 个数
这样只要保证在求解 剩下的 \(n-2\) 个数的时候不会影响后面的 \(2\) 个数即可
注意到我们有如下的 \(5\) 步构造:
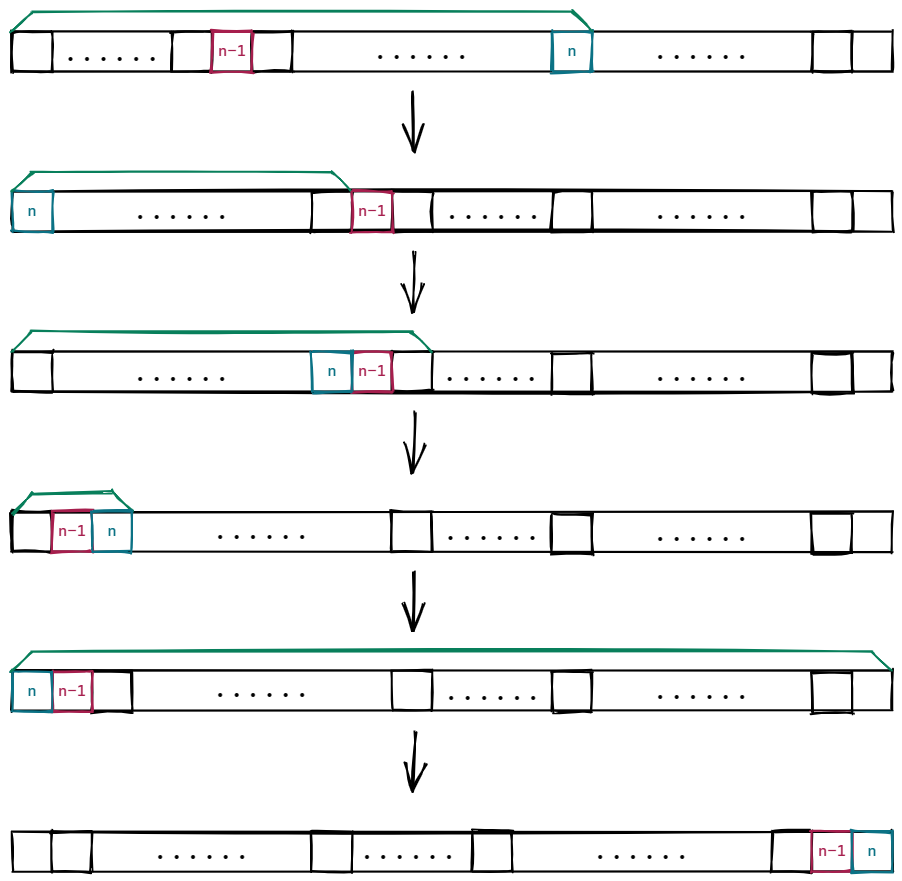
因此按照这个构造我们能够在 \(5\) 次内复原 \(2\) 个数,那么复原整个序列的 \(n\) 个数的操作次数应该也在 \(\tfrac52n\) 以下
每次操作暴力找到 \(n\) 和 \(n-1\) 所在的位置即可
时间复杂度 \(\Theta(n^2)\)
35. [1553E] - Permutation Shift
- Rating:2100
- Status:Hint
- Evaluate:Medium
通过交换元素使一个排列 \(\{p_i\}\) 复原是一个十分经典的问题,只需要对所有的 \(i\) 向 \(p_i\) 连边得到一张有向图 \(\m G\),记 \(\oper{cyc}(\m G)\) 表示 \(\m G\) 中环的个数,那么复原 \(\{p_i\}\) 的代价为 \(n-\oper{cyc}(\m G)\)
由于我们发现对 \(1\sim n\) 右移 \(k\) 位后匹配等价于使 \(\{p_i\}\) 左移 \(k\) 位后匹配,因此我们只需要对于每个 \(k\) 验证一下 \(\{p_i\}\) 左移 \(k\) 位后能否在 \(m\) 的代价以内复原为 \(1\sim n\)
注意到每次检查一个 \(k\) 的复杂度是 \(\Theta(n)\),如果检查每一个 \(k\) 一定会超时,不过我们注意到如下的观察:
观察:
对于任意的 \(n,m\),合法的 \(k\) 的数量不超过 \(\left\lfloor\dfrac{n}{n-2\times m}\right\rfloor\) 个
对于一个排列 \(\{p_i\}\),每次操作至多使 \(2\) 个 \(p_i,p_j\) 复位,因此在原本的 \(\{p_i\}\) 中至多只有 \(2\times m\) 个 \(i\) 失配,所以满足 \(p_i=i\) 的至少 \(n-2\times m\) 个
回到原问题上,对于某个位置 \(i\),有且仅有一个 \(k\) 使得 \(\{p_i\}\) 左移 \(k\) 位后得到 \(p_i=i\),因此对于所有 \(k\),匹配的 \(p_i\) 的数量总和为 \(n\)
通过抽屉原理,我们得到:合法的 \(k\) 的数量不超过 \(\left\lfloor\dfrac{n}{n-2\times m}\right\rfloor\)
根据观察,又因为数据范围中保证 \(m\le\tfrac13n\),因此合法 \(k\) 的个数不超过 \(3\)
所以我们只需要对于每个 \(k\) 计算已经有多少个 \(i\) 匹配成功,然后对于匹配成功的超过 \(n-2\times m\) 的 \(k\) 暴力验证即可
时间复杂度 \(\Theta(n)\)
36. [1552E] - Colors and Intervals
- Rating:2300
- Status:Hint
- Evaluate:Medium
记 \(p_{i,j}\) 表示第 \(i\) 个颜色在原序列中第 \(j\) 次出现的下标
注意到每个点至多被覆盖 \(\left\lceil\dfrac n{k-1}\right\rceil\) 这个条件很特殊,考虑从这里入手
首先,根据贪心观察知道,对于每个颜色 \(i\),对应的区间 \([a_i,b_i]\) 中应该没有颜色为 \(i\) 的其他位置,不然缩短区间长度不会更劣,所以每个 \([a_i,b_i]\) 都应该是颜色 \(i\) 在原序列出现的 \(k\) 个位置中相邻的某两个,即某个 \([p_{i,j},p_{i,j+1}]\)
对于一个给定的 \(j\) 不妨统称对于所有 \(i\),区间 \([p_{i,j},p_{i,j+1}]\) 都叫做“第 \(j\) 段”颜色段
所以对于每个颜色 \(i\),我们把其可以选择的区间数缩小到了 \(k-1\) 个
此时我们可以这样想:由于每个颜色有 \(k-1\) 个区间可以选,因此我们可以把 \(n\) 个颜色分别划分到 \(\left\lceil\dfrac n{k-1}\right\rceil\) 个序列里,且这样的每个序列包含的颜色段恰好是第 \(1\sim k-1\) 段各一个
假如每个序列中的颜色段互不相交,则对于每个序列,每个位置至多被覆盖一次,此时的构造方案是满足要求的
注意到每次生成一个序列不好做,那么考虑从一次取出所有选择了第 \(j\) 段的颜色,再把这些颜色塞进不同的序列里面
因此我们要做的就是对于每个 \(1\sim k-1\) 的 \(j\),在还没被选的颜色中,选 \(\left\lceil\dfrac n{k-1}\right\rceil\) 个颜色,而对于这些颜色都选择其对应的第 \(j\) 段,假如这样的每个这样的第 \(j\) 段都不与所有选过的其他段相交的话,那么这样的构造满足要求
考虑在解“选出尽可能多的不相交线段”这一问题的方法,我们在处理第 \(j\) 段的时候,对于每个颜色 \(i\),按照 \(p_{i,j+1}\) 的值从小到大排序,选出其中值最小的若干个
事实上这个做法是正确的:
证明:
采用反证法:假设这样选择后存在两个区间 \([p_{i_1,j_1},p_{i_1,j_1+1}]\) 和 \([p_{i_2,j_2},p_{i_2,j_2+1}]\) 相交,其中 \(j_1\ne j_2\)
那么不妨假设 \(j_1<j_2\)
由于颜色 \(i_2\) 并没有被选做第 \(j_1\) 段,那么我们知道 \(p_{i_1,j_1+1}<p_{i_2,j_1+1}\)
由于 \(j_1<j_2\),所以 \(j_2\ge j_1+1\),所以 \(p_{i_2,j_2}\ge p_{i_2,j_1+1}>p_{i_1,j_1+1}\),因此这样相交的区间不存在,所以原命题得证
因此对于每个 \(j\),进行一次排序即可
时间复杂度 \(\Theta(kn\log n)\)
37. [1551D] - Domino (easy version) & (hard version)
- Rating:1700 & 2000
- Status:Data
- Evaluate:Easy
显然考虑把 \(k\) 个横着的都聚拢到最上面,那么每一列在除去横着的骨牌的数量后,剩下的高度应该是偶数,只有这样才能用竖着的骨牌填满这一列
由于题目已经保证了 \(2\mid nm\),因此我们可以按 \(n\bmod 2,m\bmod 2\) 的值分成以下三类情况:
- \(n\bmod 2=0,m\bmod 2=1\)
此时最右边一列用竖着的骨牌填满,假如竖着的骨牌不足 \(\dfrac n2\) 个则无解
剩下的列考虑用 \(2\) 个横着的骨牌组成一个 \(2\times 2\) 的“方块”,这样每个“方块”填进去不会影响每一列剩下的高度的奇偶性,因此如果 \(2\mid k\) 时我们可以构造一种合法的方案,同样我们也可以证明 \(2\nmid k\) 时无解
- \(n\bmod2=1,m\bmod 2=0\)
显然先把一行用横着的骨牌填满,假如横着的骨牌不足 \(\dfrac m2\) 则无解
剩下的一样考虑构造方块,类似上一种情况,当且仅当剩下的的骨牌数为偶数时有解
- \(n\bmod2=0,m\bmod2=0\)
此时直接构造方块,有解当且仅当 \(2\mid k\)
根据上面的分析,我们能够得到判定条件和构造方案,模拟即可
时间复杂度分别为 \(\Theta(1)\) 和 \(\Theta(nm)\)
38. [1543D] - RPD and Rap Sheet (easy version) & (hard version)
- Rating:1700 & 2200
- Status:Solve
- Evaluate:Easy
先从 easy version 入手考虑:
先假设每次操作完不改变 \(x\) 值,显然由于询问次数有 \(n\) 次,因此每次我们询问 \(0\sim n-1\) 即可
那么在改变 \(x\) 值的情况下,我们对于第 \(i\) 次询问,只要询问在 \(x\) 最初为 \(i\) 的情况下经过若干次修改后得到的值即可
注意到每次询问 \(q\) 实际上就是让 \(x\) 变成 \(x\oplus q\),因此维护所有询问的 \(q\) 的异或和即可
时间复杂度 \(\Theta(n)\)
接下来考虑 \(k>2\) 的情况,类似上面的操作,我们依然考虑维护 \(x\) 最初为 \(i\) 时经过若干次修改后的值
定义 \(x\ominus_ky\) 为在 \(k\) 进制下对 \(x\) 和 \(y\) 做不退位减法得到的值
我们可以证明运算 \(\oplus_k\) 和 \(\ominus_k\) 均满足交换律结合律,并且有 \(0\ominus_k(0\ominus_kz)=z\)
每当我们询问 \(q\),\(x\) 会变成 \(q\ominus_kx\)
假设第 \(i\) 次询问的数为 \(q_i\),那么 \(x\) 的变化为:\(x\to (q_0\ominus_kx)\to(q_1\ominus_k q_0\oplus x)\to(q_2\ominus_k q_1\oplus_k q_0\ominus_k x)\to\cdots\)
因此我们分别维护前面的 \(q_i\ominus_kq_{i-1}\oplus_kq_{i-2}\ominus\cdots\) 和 \(x\) 的符号,每次询问 \(i\) 的时候令 \(x=i\) 并把两部分合并起来即可
时间复杂度 \(\Theta(n\log_kn)\)
39. [1537F] - Figure Fixing
- Rating:2200
- Status:Hint
- Evaluate:Medium
显然我们可以把原问题转化成下面的形式:
对于每条边 \(i\),指定一个整数权值 \(w_i\),使得对于每个节点 \(u\),所有与 \(u\) 相邻的边的权值和为 \(t_i-v_i\)
此时假如我们把每个 \(w_i\) 看成未知数,我们能够得到 \(n\) 个 \(m\) 元一次方程,而我们只需要判断这个方程组有没有一组整数解即可
先判定原方程是否有解,那么我们考虑一组系数 \(\{x_1,x_2,\cdots,x_n\}\) 使得节点 \(i\) 对应的方程 \(\times x_i\) 后全部相加使得 \(w_1\sim w_m\) 的系数全部为 \(0\),此时我们判断 \(\sum_{i=1}^n x_i\times(t_i-v_i)\) 是否为 \(0\) 即可得知该方程有没有解
由于每个 \(w_i\) 只在其两个端点 \(u,v\) 处出现,因此如果想让 \(w_i\) 最终系数为 \(0\),那么一定有 \(x_u+x_v=0\),因此任意相邻的两个节点符号相反,绝对值相同,显然只有这个图能被黑白染色时,即该图是二分图时有解
对整个图进行黑白染色,黑点系数为 \(1\),白点系数为 \(-1\) 即可判定是否有一组合法的 \(\{x_i\}\),然后我们用这组 \(\{x_i\}\) 去检查 \(\sum_{i=1}^n x_i\times(t_i-v_i)\) 是否为 \(0\) 即可判定方程有没有解
接下来考虑判定原方程是否有一组整数解,同样考虑一组系数 \(\{x_i\}\) 使得最终 \(w_1\sim w_n\) 都是某个 \(k\) 的倍数,而此时我们继续判断 \(\sum_{i=1}^n x_i\times(t_i-v_i)\) 是 \(k\) 的倍数即可,同样,此时对于任意一条边 \((u,v)\) 都有 \(x_u+x_v\equiv 0\pmod k\) 假设指定了某个点的系数为 \(x\bmod k\),那么每个点的系数就依次为 \(x\bmod k,(k-x)\bmod k\),为了保证判定有效,我们需要保证 \(\gcd(x,k)=1\),否则对于 \(x,k\) 同时约去其 \(\gcd\) 依然不会改变判定结果
但这样的判定只能在二分图上进行,且判定结果与上面的判定是等价的
对于非二分图,我们只能考虑 \(x\equiv k-x\pmod k\) 的情况,即 \(k=2,x=1\),此时我们能对于非二分图也进行这样的判断,我们构造 \(\{x_i\}=\{1,1,1,\cdots,1\}\),判断所有式子的和是否为 \(2\) 的倍数即可
因此总结一下:
- 对于二分图,判断其左部点的 \(t_i-v_i\) 的和与右部点 \(t_i-v_i\) 的和是否相等
- 对于非二分图,判断其所有点的 \(t_i-v_i\) 的和是否为偶数
对整张图进行黑白染色并分类按照判定条件判断即可
时间复杂度 \(\Theta(n)\)
40. [1530E] - Minimax
- Rating:2100
- Status:Hint+Data
- Evaluate:Medium
记 \(S[l,r]\) 表示 \(S\) 中第 \(l\) 个字符到第 \(r\) 个字符构成的子串
假设我们对字符串里的字符从小到大重新标号为 \(\texttt a,\texttt b,\texttt c,\texttt d,\texttt e,\cdots\)
对 \(S\) 进行分类讨论,记 \(\alpha(S)\) 为 \(S\) 中不同字符的数量:
\(\alpha(S)=1\):
显然,此时所有 \(f(T)=|S|-1\),直接输出原字符串 \(S\) 即可
\(\alpha(S)>1\):
假如 \(S\) 中存在仅出现一次的字符 \(\texttt{x}\):
此时 \(f(T)\) 最小值为 \(0\),排列成 \(\texttt {xaaabbccccc}\cdots\) 的形式即可
假如 \(S\) 中不存在仅出现一次的字符 \(\texttt{x}\):
猜测对于任意 \(S\),\(f(T)\) 最小值总是 \(1\),注意到无论哪个字符开头都不影响,因此强制把 \(\texttt a\) 放到开头
记 \(S\) 中标号为 \(\texttt a\) 的字符的个数为 \(A\)
可以以 \(\texttt{aa}\) 开头:
此时 \(T\) 第三个字符如果还是 \(\texttt a\),那么此时 \(T[1,2]=T[2,3]\),不满足 \(f(T)=1\) 的限制
因此 \(T\) 开头必须是 \(\texttt{aab}\),而剩下串中只要不出现 \(\texttt{aa}\) 即可,这要求 \(A\le \left\lfloor\tfrac n2\right\rfloor+1\)
因此此时的 \(T\) 应该形如 \(\texttt{aababacadaddefff}\cdots\),即后面每两个字符之间插入一个 \(\texttt{a}\)
只能以 \(\texttt{ab}\) 开头:
此时应该有 \(A>\left\lfloor\tfrac n2\right\rfloor+1\)
能以 \(\texttt{aba}\) 开头:
只需使 \(T\) 中没有 \(\texttt{ab}\),因此把所有 \(\texttt a\) 都放在第 \(\texttt b\) 后面,当 \(\alpha(S)>2\) 时,我们用一个 \(\texttt c\) 接在 \(\texttt a\) 后面即可
此时 \(T\) 形如 \(\texttt{abaaaaacbbccccd}\cdots\)
只能以 \(\texttt{abb}\) 开头:
此时应该有 \(\alpha(S)=2\),而不能出现 \(\texttt{ab}\),所以把所有 \(\texttt b\) 堆在一起即可
此时 \(T\) 形如 \(\texttt{abbbbbbaaaa}\cdots\)
先对 \(S\) 排序然后分类讨论逐种情况解决即可
时间复杂度 \(\Theta(n\log n)\),其中 \(n=|S|\)
41. [1526D] - Kill Anton
- Rating:2200
- Status:No Solve
- Evaluate:Hard
记 \(S-S_i\) 为 \(S\) 中删除 \(S_i\) 后得到的字符串,记 \(|S|=n\)
首先考虑在给定了 \(S\) 和 \(T\) 的情况下如何计算 \(T\) 到 \(S\) 的距离,记为 \(\oper{dist}(S,T)\),注意到如下的观察:
观察一:
\(\oper{dist}\) 满足对于任意字符串 \(A,B,C\) 满足 \(|A|=|B|=|C|\) 均有 \(\oper{dist}(A,C)\le\oper{dist}(A,B)+\oper{dist}(B,C)\)
证明很简单,考虑 \(\oper{dist}(A,C)\) 的实际意义,即 \(A\gets C\) 的最少操作次数,而 \(\oper{dist}(A,B)+\oper{dist}(B,C)\) 则表示了 \(A\gets B\gets C\) 的一种操作方案,其代价为 \(\oper{dist}(A,B)+\oper{dist}(B,C)\)
由于 \(\oper{dist}(A,C)\) 需要满足其操作数最小,因此对于任意一种合法的 \(A\gets C\) 操作方案,\(\oper{dist}(A,C)\) 应该不大于其操作数,而 \(A\gets B\gets C\) 的方案显然也是一种 \(A\gets C\) 的合法操作方案,所以得到 \(\oper{dist}(A,C)\le\oper{dist}(A,B)+\oper{dist}(B,C)\)
注意到如下的观察:
观察二:
对于 \(S\) 的最后一个字符 \(c\),设 \(c\) 在 \(T\) 中最后一次出现是在位置 \(x\) 上,那么 \(\oper{dist}(S,T)=(n-x)+\oper{dist}(S-S_n,T-T_x)\)
考虑在计算两个排列的距离的方法,每次复原最后一个字符,然后解决前面长度 \(n-1\) 的子串
对于此处,我们也可以从后到前依次复位,不过每次把哪个 \(c\) 放到 \(T_n\) 上是我们需要解决的问题
考虑贪心,每次选取最后的一个 \(c\) 放到 \(T_n\) 上,此时代价为 \((n-x)\),而剩下的字符串复位的代价就是 \(\oper{dist}(S-S_n,T-T_x)\)
现在我们要证明这个贪心的正确性,那么不妨考虑一个下标 \(x_1\) 满足 \(x_1<x\) 且 \(T_{x_1}=c\)
那么我们只需证明 \((n-x)+\oper{dist}(S-S_n,T-T_x)\le(n-x_1)+\oper{dist}(S-S_n,T-T_{x_1})\),事实上这等价于证明 \(\oper{dist}(S-S_n,T-T_x)\le (x-x_1)+\oper{dist}(S-S_n,T-T_{x_1})\)
而我们又注意到 \(x-x_1=\oper{dist}(T-T_x,T-T_{x_1})\),因此根据观察一,原命题得证
为了维护 \(\oper{dist}(S,T)\),我们对每个位置 \(i\) 维护 \(T_i\) 是否已经匹配,然后倒序考虑每个 \(x\),\(x\) 移动到匹配位置的代价事实上就等于 \((x,n]\) 中未匹配的位置数量,显然这个用一棵树状数组可以在 \(\Theta(n\log n)\) 的时间内解决
事实上,考察上面计算 \(\oper{dist}(S,T)\) 的过程,假如我们记录下每个 \(x\) 何时候被匹配,记为 \(c_i\),事实上 \(\oper{dist}(S,T)\) 与序列 \(\{c_i\}\) 的逆序对数是相等的
不过在这题中,\(T\) 的可能性太多了,逐一验证的复杂度显然会超时,考虑剪枝
而我们注意到如下的观察:
观察三:
最大化 \(\oper{dist}(S,T)\) 的 \(T\) 中相同的字符一定连续
考虑任意一个 \(T\),计算 \(\{c_i\}\),考虑两个字符相同的位置 \(T_i\) 和 \(T_j\),为了简化讨论,我们假设 \(i<j\) 且 \(T_{i+1}\sim T_{j-1}\) 中没有与 \(T_i,T_j\) 相等的字符,显然根据 \(\{c_i\}\) 的定义有 \(c_i<c_j\)
此时我们只需要证明总存在一种方式使 \(T_i,T_j\) 相邻且不减少 \(\{c_i\}\) 的逆序对数
由于要让这两个相邻,一种显然的方法就是循环移位,而根据移动的字符分成如下两种情况:
- 让 \(T_{i+1}\sim T_{j-1}\) 的字符全部向后移动 \(1\) 位,并把 \(T_j\) 移动到 \(T_{i+1}\) 上
- 让 \(T_{i+1}\sim T_{j-1}\) 的字符全部向前移动 \(1\) 位,并把 \(T_i\) 移动到 \(T_{j-1}\) 上
考虑区间 \((i,j)\) 中的每一个 \(k\),考虑修改后 \(k\) 对答案的贡献
- 对于第一种方式,若 \(c_k<c_j\),那么逆序对数 \(+1\),如果 \(c_j<c_k\),那么逆序对数 \(-1\)
- 对于第二种方式,若 \(c_i<c_k\),那么逆序对数 \(-1\),如果 \(c_k<c_i\),那么逆序对数 \(+1\)
记 \(\oper{cnt^\uparrow}(x)\) 表示 \(c_{i+1}\sim c_{j-1}\) 中 \(>x\) 的数的个数,而 \(\oper{cnt^\downarrow}(x)\) 表示 \(c_{i+1}\sim c_{j-1}\) 中 \(<x\) 的数的个数
根据上面的分析,我们得到第一种方式对逆序对数的贡献为 \(\oper{cnt^\downarrow}(c_j)-\oper{cnt^\uparrow}(c_j)\),第二种方式对逆序对数的贡献为 \(\oper{cnt^\uparrow}(c_i)-\oper{cnt^\downarrow}(c_i)\)
假如 \(\oper{cnt^\downarrow}(c_j)-\oper{cnt^\uparrow}(c_j)\ge0\),那么直接选择第一种操作就可以使得 \(T_i,T_j\) 相邻且 \(\{c_i\}\) 逆序对数量不减
假如 \(\oper{cnt^\downarrow}(c_j)-\oper{cnt^\uparrow}(c_j)<0\),即 \(\oper{cnt^\downarrow}(c_j)<\oper{cnt^\uparrow}(c_j)\)
由于 \(c_i<c_j\),我们知道 \(\oper{cnt^\uparrow}(c_i)\ge \oper{cnt^\uparrow}(c_j),\oper{cnt^\downarrow}(c_i)\le\oper{cnt^\downarrow}(c_j)\),与 \(\oper{cnt^\downarrow}(c_j)<\oper{cnt^\uparrow}(c_j)\) 联立得到:\(\oper{cnt^\downarrow}(c_i)\le\oper{cnt^\downarrow}(c_j)<\oper{cnt^\uparrow}(c_j)\le\oper{cnt^\uparrow}(c_i)\)
因此此时 \(\oper{cnt^\uparrow}(c_i)>\oper{cnt^\downarrow}(c_i)\),所以第二种操作的代价 \(\oper{cnt^\uparrow}(c_i)-\oper{cnt^\downarrow}(c_i)>0\) ,此时选择第二种操作可以使得 \(T_i,T_j\) 相邻且 \(\{c_i\}\) 逆序对数量不减
根据上面的分析,我们知道对于任何一对字符相同的 \(T_i,T_j\),若 \(T_{i+1}\sim T_{j-1}\) 中没有与其相同的字符,总存在一种方式使得 \(T_i,T_j\) 相邻并且 \(\oper{dist}(S,T)\) 不减少
根据上面的观察,我们只需要枚举 \(\texttt{a},\texttt{t},\texttt{o},\texttt{n}\) 的先后顺序即可
时间复杂度 \(\Theta(\alpha(S)!\times n\log n)\),其中 \(\alpha(S)\) 表示 \(S\) 的字符集大小(\(\alpha(S)\le 4\))
42. [1521C] - Nastia and a Hidden Permutation
- Rating:2000
- Status:Solve
- Evaluate:Easy
首先考虑通过指定 \(x\) 为极大值或极小值来确定内层的 \(\min,\max\) 运算的结果
假设在第一种操作中,我们令 \(x=n-1\),那么询问 ? 1 i j n-1 的结果会变成 \(\max(\min(n-1,p_i),p_j)\),在大部分情况下,这个式子的值为 \(\max(p_i,p_j)\),而假如我们已经知道了其中 \(p_i\) 的值,那么当 \(p_j>p_i\),我们能确定 \(p_j\) 的值,而当 \(p_i=1\) 时,我们就能靠这个操作还原整个排列 \(\{p_i\}\)
那么原问题转化成找到 \(1\) 在 \(\{p_i\}\) 里的位置
接下来我们应该考虑采用第二种操作,我们令 \(x=1\),那么询问 ? 2 i j 1 的结果会变成 \(\min(p_i,\max(2,p_j))\),讨论一下 \(1\) 所在的位置对答案带来的影响:
- \(p_i=1\) 时,原式答案为 \(1\)
- \(p_j=1\) 时,原式答案为 \(2\)
注意到此时我们剩下的操作数大约为 \(\dfrac n2+30\) 次,因此考虑每次询问相邻的两个数的答案,比如询问 \((1,2),(3,4),(5,6),\cdots,(n-1,n)\),如果某次返回的答案 \(>2\),说明这两个数中没有 \(1\)
而我们记录下所有让返回答案 \(\le 2\) 的 \((i,j)\),不过注意到 \(p_i\) 或 \(p_j\) 为 \(2\) 时,返回答案也为 \(2\),所以我们接下来要进行一些操作来甄别究竟是那种情况
考虑交换 \((i,j)\),询问 ? 2 j i 1,那么对于每对可能的 \((i,j)\),如果询问 \((i,j)\) 的答案为 \(1\),那么 \(p_i=1\),如果询问 \((j,i)\) 的答案为 \(1\),那么 \(p_j=1\),否则 \(p_i,p_j\) 中只有 \(2\) 没有 \(1\)
所以我们再对于每个可能的 \((i,j)\) 花费一次询问即可,可以证明这样的 \((i,j)\) 数量极少,再确定 \(p_i=1\) 的具体 \(i\) 值这一步骤的花费极小,肯定不到 \(30\) 次,因此这个策略能够通过本题
43. [1520F] - Guess the K-th Zero (easy version) & (hard version)
- Rating:1600 & 2200
- Status:Hint+Data
- Evaluate:Medium
简单版本是非常容易解决的,直接在原序列上进行二分,每次检查 \(1\sim x\) 中 \(0\) 的个数是否超过 \(k\) 即可,询问次数 \(\log_2 n\) 次
时间复杂度 \(\Theta(\log n)\)
接下来考虑困难版本,最显然的做法是复制容易版本 \(t\) 次,每次直接对每次询问都进行二分,询问次数 \(t\log_2n\) 次,超过了题目中的限制
考虑优化,假设每次猜到 \(x\) 后不会修改 \(a_x\) 的值,那么我们可以进行记忆化,即对重复的询问直接返回答案
而每次修改 \(a_x\) 的值也可以类似解决,假设我们维护 \(b_x\) 表示 \(a_1\sim a_x\) 的和,那么每种操作对 \(\{b_i\}\) 的贡献如下:
- 修改 \(a_x\) 为 \(1\),对于所有 \(i\in[x,n]\),使 \(b_i\gets b_i+1\)
- 询问
? 1 x的答案为 \(p\),使 \(b_i\gets p\)
因此我们要维护 \(\{b_i\}\) 支持单点查值,单点覆盖和区间加,显然用线段树或树状数组随便维护一下即可
计算一下记忆化后的询问次数,我们可以把二分的过程转成在线段树上逐步向下的过程,那么询问次数就是在一棵动态开点线段树中插入 \(t\) 个位置后,动态开点线段树的大小,因此答案为 \(\sum_{i=0}^{\left\lceil\log_2n\right\rceil}\min(2^i,t)\),在 \(n=2\times 10^5,t=10^4\) 时,询问次数为 \(1+2+4+\cdots+8192+10^4+10^4+10^4+10^4=56383\) 次,可以通过本题
时间复杂度 \(\Theta(t\log^2 n)\)
44. [1513E] - Cost Equilibrium
- Rating:2300
- Status:Hint+Data
- Evaluate:Medium
记 \(c_x\) 表示 \(x\) 在 \(a_1\sim a_n\) 中出现的次数,\(w\) 为 \(a_1\sim a_n\) 中的最大值
首先求出 \(a_1\sim a_n\) 的平均值,记为 \(\bar a\),若 \(\bar a\notin \mathbb Z\) 则无解
考虑将每个 \(a_i\) 当成 \(i\) 拥有的流量,对于每个 \(a_i\) 比较其与 \(\bar a\) 的大小关系有如下三种情况:
- \(a_i>\bar a\),每次操作一定是流出流量,共有 \(a_i-\bar a\) 的流量要流出,将点 \(i\) 放入源点点集 \(\mathbf S\)
- \(a_i=\bar a\),即 \(a_i\) 已经饱和,不需要进行任何操作,将点 \(i\) 放入自由点点集 \(\m F\)
- \(a_i<\bar a\),每次操作一定是流入流量,共有 \(\bar a-a_i\) 的流量要流入,将点 \(i\) 放入汇点点集 \(\m T\)
若 \(|\m S|=0\) 或 \(|\m T|=0\),此时 \(|\m F|=n\),总共只有 \(1\) 中可能的排列
对于每次操作,看成从某个源点 \(S_i\) 向某个汇点 \(T_j\) 流了 \(1\) 的流量,代价为 \(|S_i-T_j|\),并复制这样的流 \(x\) 次
考虑对于给定的 \(\{a_i\}\),判断其是否满足题目限制,对于一种合法的方案,如果存在两个流 \(S_{i_1}\to T_{j_1},S_{i_2}\to T_{j_2}\) 满足 \(S_{i_1}<T_{j_1}<S_{i_2}<T_{j_2}\) 或 \(S_{i_1}>T_{j_1}>S_{i_2}>T_{j_2}\),那么交换两个流的终点变成流 \(S_{i_1}\to T_{j_2},S_{i_2}\to T_{j_1}\) 时总花费改变
所以根据上面的分析,当 \(|\m S|\ge 2\) 且 \(|\m T|\ge 2\) 时,在任意合法的 \(\{b_i\}\) 中,所有的源点在都在所有的汇点的左侧或右侧
而 \(|\m S|=1\) 或 \(|\m T|=1\) 时,任意排列 \(\{a_i\}\) 均可,此时答案为 \(\binom{n}{c_0,c_1,c_2,\cdots,c_w}\)
当 \(|\m S|\ge 2\) 且 \(|\m T|\ge 2\) 时,我们先选择 \(\m F\) 中点的位置,然后确定 \(\m S\) 和 \(\m T\) 内部点集的排列数,最后确定是 \(\m S\) 在 \(\m T\) 左边还是右边,答案为:
\]
因此处理出 \({c_i}\) 和阶乘以及阶乘逆元即可计算
时间复杂度 \(\Theta(n\log n)\)
45. [1513D] - GCD and MST
- Rating:2000
- Status:Hint
- Evaluate:Medium
容易把第一种连边条件转化为 \(a_i\sim a_j\) 都是某个 \(a_x\) 的倍数,考虑 Kruskal 生成树,对于所有点权 \(<p\) 的点从小到大枚举,每次对于一个 \(a_x\),扩展出其左边有多少个连续的 \(a_x\) 的倍数和其右边有多少个连续的 \(a_x\) 的倍数,求出有 \(a_x\) 这一约数的极大的区间 \([l_x,r_x]\),那么对于所有 \(i\in [l_x,r_x]\),对于每条可能的边 \((i,x)\) 有并查集判断一下即可,每次这样的操作能够联通区间 \([l_x,r_x]\)
此时生成森林一定是若干个连续的区间构成一棵树,把剩下的边用 \(p\) 的代价都连接起来就可以
但是这种做法对于每个 \(x\) 在最坏情况下都需要遍历整个区间,复杂度退化为 \(\Theta(n^2)\)
考虑优化,注意到如下的观察:
观察:
当遇到一个 \(i\) 使 \((i,x)\) 构成环后,再往后的 \(i\) 一样会生成环,在这个地方直接
break掉即可我们只需要证明,每次
break后区间 \([l_x,r_x]\) 已经是联通的考虑数学归纳法,当前所有区间 \([l_x,r_x]\) 已经考虑完毕并联通,考虑下一个区间 \([l_{x'},r_{x'}]\),只需要证明 \(x'\) 不会越过这个区间去连接,即不存在 \(x'\to i'\) 满足 \(i'<l_x\le r_x<x'\) 或 \(i'>r_x\ge l_x>x'\),注意到这种 \(x\in[l_{x'},r_{x'}]\) 只会在 \(x'=x\) 时发生,此时有 \([l_{x'},r_{x'}]=[l_x,r_x]\),因此这样的 \((x',i')\) 不存在,故原命题得证
这样每个点至多同时作为某个区间的左端点和右端点,访问次数不会超过 \(2\)
时间复杂度 \(\Theta(n\log n)\)
46. [1495C] - Garden of the Sun
- Rating:2300
- Status:No Solve
- Evaluate:Hard
首先考虑的思路应该是对于奇数行都全部变成 X,偶数行就自动和上下的奇数行连接,但是这样可能会形成多个环
一个比较自然的思路是按行号 \(\bmod 3\) 来讨论,对于第 \(3i+1\) 行全部变成 X,这样第 \(3i+2\) 行和 \(3i+3\) 行就会分别与第 \(3i+1\) 行和第 \(3(i+1)+1\) 行相连,那么我们只需要找到一种合适的方式连接 \(3i+1\) 行和 \(3(i+1)+1\) 行
注意到任意一个 X 周围 \(8\) 个位置都是 .,因此对于某个在 \((3i+2,j)\) 上的 X,\((3i+3,j-1)\) 和 \((3i+3,j+1)\) 都是 .,因此我们直接把 \((3i+3,j)\) 变成 X,能连通第 \(3i+1\) 行和 \(3(i+1)+1\) 行而不产生环,对于某个坐标为 \((3i+3,j)\) 的 X 也一样,把 \((3i+2,j)\) 变成 X 即可
假如不存在这样的 \(j\),那么第 \(3i+2\) 和 \(3i+3\) 行应该全都是 .,那么任取同一列的两个位置变成 X 即可
注意一个需要特判的边界情况:若 \(n\bmod 3=0\),那么第 \(n\) 行的每个 X 都是独立的,其间两两都不联通,因此对于每个为 X 的 \((n,j)\),把 \((n-1,j)\) 变成 X 即可
时间复杂度 \(\Theta(nm)\)
47. [1494D] - Dogeforces
- Rating:2300
- Status:Data
- Evaluate:Medium
看到父亲的权值大于儿子的权值,首先想到 Kruskal 重构树
显然两个点 LCA 处的权值就是合并这两个点所在连通块时的那条边的边权,因此我们把所有 \(a_{i,j}\) 当成一条连接 \(i,j\),边权为 \(a_{i,j}\) 的边,求出 Kruskal 重构树即为所求的答案
但是这题略有不同,这题要求父亲的权值严格大于儿子的权值,因此我们要进行一定的分类讨论,假设当前我们需要新建一条边,连接 \(u,v\) 权值为 \(w\),记 \(val_i\) 表示节点 \(i\) 的权值,根据 Kruskal 生成树的算法流程我们知道 \(val_u\le w,val_v\le w\),根据两个不等号是否取等分成如下四类情况:
\(val_u<w,val_v<w\)
最基本的情况,用 Kruskal 重构树原本的处理方案,新建一个节点 \(x\),\(val_x=w\),设 \(u,v\) 为 \(w\) 的儿子即可
\(val_u=w,val_v<w\)
此时假如我们新建 \(x\),那么 \(val_x=w=val_u\) 不满足题目限制,发现直接把 \(v\) 设为 \(u\) 的儿子即可
\(val_u<w,val_v=w\)
同上一种情况,设 \(u\) 为 \(v\) 的儿子
\(val_u=w,val_v=w\)
非常有趣的情况,我们应该要把 \(u,v\) 合并成一个节点,因此我们想象成把 \(v\) 删掉,把所有 \(v\) 的儿子变成 \(u\) 的儿子,并查集上直接设 \(v\) 这一块的祖先为 \(u\),并不需要对于每个节点修改,只要保证后面查询这一块的祖先查不到 \(v\) 即可,最后输出节点编号的时候需要做一次离散化
时间复杂度 \(\Theta(n^2\log n)\)
48. [1493C] - K-beautiful Strings
- Rating:2000
- Status:Hint
- Evaluate:Medium
字符串下标从 \(0\) 开始,记 \(S[l\cdots r]\) 表示字符 \(S_l\sim S_r\) 构成的子串
观察到 \(k\nmid n\) 时满足条件的字符串一定不存在,而对于 \(k\mid n\) 的情况字符串 \(\texttt{zzzzz}\cdots\) 一定满足条件
若 \(S\) 已经满足条件,直接输出 \(S\) 即可
为了让字典序尽量小,我们可以从大到小枚举 \(\oper{lcp}(S,T)\) 的长度(\(\oper{lcp}(S,T)\) 表示 \(S,T\) 的最长公共前缀)
对于每个前缀 \(S[0\cdots i-1]\),我们可以维护每个字符出现的次数,由于每次只减少一个字符,因此单次更新是 \(\Theta(1)\) 的
接下来我们枚举 \(T_i\) 的值,显然 \(T_i>S_i\) 因此从 \(S_i+1\) 枚举到 \(\texttt z\),这个时候我们就确定了 \(T[0\cdots i]\) 的值,而 \(T[i+1\cdots n-1]\) 中的每个位置就都可以随便填了
根据题意能够计算出 \(T[i+1\cdots n-1]\) 中每个字符出现次数 \(\bmod k\) 的余数,因此我们能得到最少需要多少个字符才能让每种字符的出现次数都是 \(k\) 的倍数,而剩下的位置全填 \(\texttt{a}\),然后从小到大排列字符,如果爆长度了返回无解
记 \(\alpha(S)\) 表示 \(S\) 的字符集大小,我们判断 \(T[i+1\cdots n-1]\) 是否有解是 \(\Theta(\alpha (S))\) 的,而对于每个前缀,有 \(\alpha(S)\) 个可能的 \(T[0\cdots i]\) 需要判断 \(T[i+1\cdots n-1]\) 是否有解,因此判断解的总复杂度为 \(\Theta(n\alpha^2(S))\)
虽然构造一个 \(T[i+1\cdots n-1]\) 的复杂度是 \(\Theta(n)\) 的,但是只有有解的时候会进行构造,因此得到合法的 \(T[i+1\cdots n-1]\) 只会进行一次
综上所述,总时间复杂度为 \(\Theta(n\alpha^2(S))\)
49. [1486E] - Paired Payment
- Rating:2200
- Status:Solve
- Evaluate:Easy
注意到 \(w\) 很小,考虑对 \(w\) 构造分层图
对于每次移动 \(x\to u\to y\),记两次的权值分别为 \(w_1,w_2\),那么我们把每次移动都看成 \(x\to (u,w_1)\to y\),其中 \((v,w)\) 表示 \(v\) 作为中转点,且到达 \(v\) 的上一条边边权为 \(w\)
因此对于每个边 \((u,v,w)\),考虑 \(u\to v\) 是从起点到中转点还是从中转点到终点,那么我们连 \(u\to (v,w)\) 边权为 \(0\),对于每个 \(w'\),连 \((u,w')\to v\),边权为 \((w+w')^2\),同理处理 \(u\gets v\) 即可
此时在这张图上求一遍最短路即可
时间复杂度 \(\Theta(mw(\log m+\log w))\)
50. [1485D] - Multiples and Power Differences
- Rating:2200
- Status:Hint
- Evaluate:Medium
假设 \(k\in \mathbb{N}\) 而不是 \(\mathbb {N^+}\),那么我们首先想到令所有 \(k=0\),注意到由于 \(\oper{lcm}(1,2,3,\cdots,16)=720720<10^6\),因此我们把所有 \(b_{i,j}\) 都设成 \(720720\) 即可让任意两个相邻方格差为 \(0^4\)
不过本题要求 \(k\in\mathbb{N^+}\),这个时候我们就要处理相邻的方格之间的关系,考虑对整个网格进行黑白间隔染色,我们还在刚刚全部都是 \(720720\) 的矩阵上修改,我们可以保持白格不变,黑色的 \((i,j)\) 让 \(b_{i,j}\gets b_{i,j}+a_{i,j}^4\),容易证明这样相邻的两个元素之差为黑色元素的值的四次方,满足题意
由于 \(a_{i,j}\le 16\) 所以 \(b_{i,j}\le720720+16^4=786256< 10^6\) 满足题目限制
时间复杂度 \(\Theta(nm)\)
CodeForces 构造题专项解题报告的更多相关文章
- Codeforces Round 665 赛后解题报告(暂A-D)
Codeforces Round 665 赛后解题报告 A. Distance and Axis 我们设 \(B\) 点 坐标为 \(x(x\leq n)\).由题意我们知道 \[\mid(n-x)- ...
- Codeforces Round 662 赛后解题报告(A-E2)
Codeforces Round 662 赛后解题报告 梦幻开局到1400+的悲惨故事 A. Rainbow Dash, Fluttershy and Chess Coloring 这个题很简单,我们 ...
- 2016 第七届蓝桥杯 c/c++ B组省赛真题及解题报告
2016 第七届蓝桥杯 c/c++ B组省赛真题及解题报告 勘误1:第6题第4个 if最后一个条件粗心写错了,答案应为1580. 条件应为abs(a[3]-a[7])!=1,宝宝心理苦啊.!感谢zzh ...
- 无聊的活动/缘生意转(2018 Nova OJ新年欢乐赛B题)解题报告
题目2(下面的太抓 我重新写了个背景 其他都一样) 无聊的活动 JLZ老师不情愿的参加了古风社一年一度的活动,他实在不觉得一群学生跳舞有什么好看,更不明白坐在身后的学生为什么这么兴奋(看小姐姐),于是 ...
- codeforces 483C.Diverse Permutation 解题报告
题目链接:http://codeforces.com/problemset/problem/483/C 题目意思:给出 n 和 k,要求输出一个含有 n 个数的排列 p1, p2, ...,pn,使得 ...
- codeforces 468A. 24 Game 解题报告
题目链接:http://codeforces.com/problemset/problem/468/A 题目意思:给出一个数n,利用 1 - n 这 n 个数,每个数只能用一次,能否通过3种运算: + ...
- [置顶] 刘汝佳《训练指南》动态规划::Beginner (25题)解题报告汇总
本文出自 http://blog.csdn.net/shuangde800 刘汝佳<算法竞赛入门经典-训练指南>的动态规划部分的习题Beginner 打开 这个专题一共有25题,刷完 ...
- Codeforces Round #277.5 解题报告
又熬夜刷了cf,今天比正常多一题.比赛还没完但我知道F过不了了,一个半小时贡献给F还是没过--应该也没人Hack.写写解题报告吧= =. 解题报告例如以下: A题:选择排序直接搞,由于不要求最优交换次 ...
- CodeForce---Educational Codeforces Round 3 USB Flash Drives (水题)解题报告
对于这题明显是用贪心算法来解决问题: 下面贴出笔者的代码: #include<cstdio> #include<iostream> #include<algorithm& ...
随机推荐
- 服务器之Apollo单机部署(快速安装)
部署Apollo apollo单机部署(快速安装) Apollo官网:https://www.apolloconfig.com/#/zh/deployment/quick-start-docker 官 ...
- Redis Cluster 原理说的头头是道,这些配置不懂就是纸上谈兵
Redis Cluster 原理说的头头是道,这些配置不懂就是纸上谈兵 Redis Cluster 集群相关配置,使用集群方式的你必须重视和知晓.别嘴上原理说的头头是道,而集群有哪些配置?如何配置让集 ...
- C# 8.0 添加和增强的功能【基础篇】
.NET Core 3.x和.NET Standard 2.1支持C# 8.0. 一.Readonly 成员 可将 readonly 修饰符应用于结构的成员,来限制成员为不可修改状态.这比在C# 7. ...
- Linux--多线程(三)
生产者消费者模型 概念: 生产者消费者模式就是通过一个容器来解决生产者和消费者的强耦合问题.生产者和消费者彼此之间不直接通讯,而通过一个来进行通讯,所以生产者生产完数据之后不用等待消费者处理,直接扔给 ...
- 从BeanFactory源码看Bean的生命周期
下图是我搜索"Spring Bean生命周期"找到的图片,来自文章--Spring Bean的生命周期 下面,我们从AbstractAutowireCapableBeanFacto ...
- 自动化利器 Ansible - 从了解到应用
本文说明 本系列使用 ansible 2.9.27 版本来说明和汇总相关信息. # cat /etc/system-release Red Hat Enterprise Linux Server re ...
- 2022!影响百万用户金融信用评分,Equifax被告上法庭,罪魁祸首——『数据漂移』!⛵
作者:韩信子@ShowMeAI 数据分析实战系列:https://www.showmeai.tech/tutorials/40 机器学习实战系列:https://www.showmeai.tech/t ...
- __init__、__all__
在python中 引用模块包的时候,要先进入此模块的__init__.py中畅游一遍,因此,我们多次需要一个语句的时候,就可以将这些语句写入到__init__.py中: 在使用*号的时候我们可以用__ ...
- C温故补缺(十一):文件读写
文件读写 打开文件 fopen( ) 函数来创建一个新的文件或者打开一个已有的文件 FILE *fopen( const char *filename, const char *mode ); fil ...
- integer 拆箱装箱以及范围
//装箱是将一个原始数据类型赋值给相应封装类的变量.而拆箱则是将一个封装类的变量赋值给相应原始数据类型的变量. int i1 = 1; int i2 = 1; Integer integer1 = n ...