简答一波 HashMap 常见八股面试题 —— 算法系列(2)
请点赞,你的点赞对我意义重大,满足下我的虚荣心。
Hi,我是小彭。本文已收录到 GitHub · Android-NoteBook 中。这里有 Android 进阶成长知识体系,有志同道合的朋友,关注公众号 [彭旭锐] 跟我一起成长。
前言
HashMap 是我们熟悉的散列表实现,也是 “面试八股文” 的标准题库之一。今天,我给出一份 HashMap 高频面试题口述简答答案,希望对你刷题有帮助。如果能帮上忙请务必点赞加关注,这对我非常重要。
这篇文章是数据结构与算法系列文章第 2 篇,专栏文章列表:
一、数据结构基础:
- 1、线性表(ArrayList & LinkedList 实现)
- 2、散列表(HashMap 实现)(本文)
- 3、队列
- 4、栈
- 5、二叉树(高频面试题与解题框架)
- 6、图
二、算法思想:
- 1、回溯算法解题框架
- 2、二分查找解题框架
- 3、排序算法
- 4、贪心算法解题框架
- 5、动态规划解题框架
三、高级数据结构:
- 1、前缀和数组(区间查询问题)
- 2、线段树(区间查询问题)
- 3、树状数组(区间查询问题)
- 4、字典树
- 5、单调队列(下一个更大元素问题)
- 6、单调栈(滑动窗口最大值问题)
- 7、并查集(动态连通问题)
- 8、二叉堆(优先队列)
四、刷题题解:
1. 认识散列表
1.1 散列表的作用
散列算法是散列表的核心,也就做哈希算法或 Hash 算法,是一个意思。散列算法是一种将任意长度输入转换为固定长度输出的算法,输出的结果就是散列值。基于散列算法实现的散列表,可以实现快速查找元素的特性。
总结一下散列算法的主要性质:
| 性质 | 描述 |
|---|---|
| 1、单向性(基本性质) | 支持从输入生成散列值,不支持从散列值反推输入 |
| 2、高效性(基本性质) | 单次散列运算计算量低 |
| 3、一致性 | 相同输入重复计算,总是得到相同散列值 |
| 4、随机性 | 散列值在输出值域的分布尽量随机 |
| 5、输入敏感性 | 相似的数据,计算后的散列值差别很大 |
1.2 什么是散列冲突?
散列算法一定是一种压缩映射,因为输入值域非常大甚至无穷大,而散列值域为一个固定长度的值域。例如,MD5 的输出散列值为 128 位,SHA256 的输出散列值为 256 位,这就存在 2 个不同的输入产生相同输出的可能性,即散列冲突,或哈希冲突、Hash Collision。
这其实只要用鸽巢原理(又称:抽屉原理)就很好理解了,假设有 10 个鸽巢,现有 11 只鸽子,无论分配多么平均,也肯定有一个鸽巢里有两只甚至多只鸽子。举一个直接的例子,Java中的字符串 "Aa" 与 "BB" 的散列值就冲突了:
示例程序
String str1 = "Aa";
String str2 = "BB";
System.out.println(str1.hashCode()); 2112
System.out.println(str2.hashCode()); 2112 散列冲突
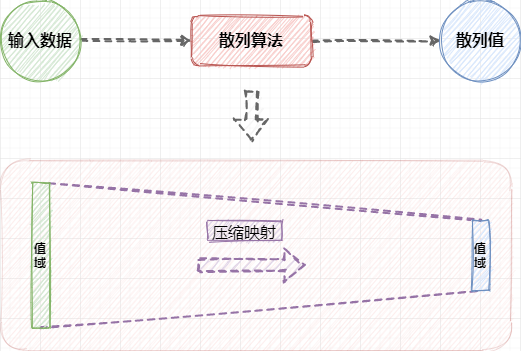
1.3 如何降低散列冲突概率
虽然散列冲突是无法完全避免的,但可以尽可能降低发生散列冲突的概率。例如:
- 1、优化散列算法,提高散列值随机性: 将散列值尽可能均匀分布到输出值域的范围内,避免出现 “堆积” 线程。否则,当大部分散列值都堆积在一小块区域上时,势必会增大冲突概率。例如,HashMap 保证容量为 2^n 次幂就是提高随机性的方法。
- 2、扩大输出值域(即扩容): 在散列值尽可能均匀分布的前提下,扩大输出值域可以直接降低冲突概率。例如,HashMap 在达到阈值时执行扩容,本质上是扩大了输出值域。
2. HashMap 设计思路
2.1 说一下 HashMap 的底层结构?
HashMap 的底层结构是一个 “数组 + 拉链” 的二维结构,在 Java 7 中使用的是数组 + 链表,而在 Java 8 中当链表长度大于 8 时会转换为红黑树。
那么为什么 HashMap 要采用这样的设计呢?我分为 3 点来回答:
- 第 1 点:HashMap 的定义是一个散列表,这是一种支持快速查找元素的数据结构,那么其背后就必然会使用到数组随机访问的特点。因此,HashMap 的一维结构就是一个数组,数组元素是一个包含 Key、Value 和 hashcode 的 Entry 节点。当我们需要访问集合元素时,其实就是先通过 key 计算 hashcode,再将 hashCode 对数组长度取余得到数组下标,最后通过下标去数组中找到对应的 Value;
- 第 2 点:从 Key 到数组下标的转换过程必然是一个压缩映射的过程,因为不同的 key 计算的 hashCode 可能相同,不同的 hashCode 取余得到的数组下标也可能相同,这就是哈希冲突。常规的哈希冲突解决方法有开放地址法和拉链法等,而 HashMap 采用的是拉链法来解决哈希冲突。
- 第 3 点:为什么 Java 8 要引入红黑树的设计呢?因为当冲突加剧的时候,在链表中寻找对应元素的时间复杂度是 O(n),n 是链表长度。而使用红黑树(近似平衡的二叉搜索树)的话,树形结构的复杂度一般跟树的高度有关,查找复杂度是 O(lgn),时间复杂度更低。
2.2 为什么 HashMap 采用拉链法而不是开放地址法?
我认为 Java 给予 HashMap 的定位是一个相对通用的散列表容器,它应该在面对各种输入的时候都表现稳定。而开发地址法相对来说容易出现数据堆积,在数据量较大时可能出现连续冲突的情况,性能不够稳定。
我们可以举个反例,在 Java 原生的数据结构中,也存在使用开放地址法的散列表 —— 就是 ThreadlLocal。因为项目中不会大量使用 ThreadLocal 线程局部存储,所以它是一个小规模数据场景,这里使用开发地址法是没问题的。
2.3 为什么 HashMap 用红黑树而不是平衡二叉树?
红黑树和平衡二叉树的区别在于它们的平衡强弱不同:
- 平衡二叉树追求的是一种完全平衡的状态,它的定义是任何结点的左右子树的高度差不会超过 1,这样的优势是树的结点是很平均分配的;
- 红黑树不追求这种完全平衡,而是追求一种弱平衡的状态,就是让整个树最长路径不会超过最短路径的 2 倍。这样的话,红黑树虽然牺牲了一部分查找的性能效率,但是能够换取一部分维持树平衡状态的成本。
而我们知道 HashMap 的设计定位应该是一个相对通用的散列表,那么它的设计者会希望这样一个数据结构应该具备更强大的稳定性,因此它才选择了红黑树。
3. HashMap 源码细节
3.1 HashMap 的初始容量
HashMap 的初始容量是 0,这是一种懒加载机制,直到第一次 put 操作才会初始化数组大小,默认大小是 16。
3.2 HashMap 扩容
扩容本质上是扩大了散列算法的输出值域,在散列值尽可能均匀分布的前提下,扩大输出值域可以直接降低冲突概率。当然,由于 HashMap 使用的是拉链法来解决散列冲突,扩容并不是必须的,但是不扩容的话会造成拉链的长度越来越长,导致散列表的时间复杂度会倾向于 O(n) 而不是 O(1)。
HashMap 扩容的触发时机出现在元素个数超过阈值(容量 * loadFactor)的时候时,会将集合的一维数组扩大一倍,然后重新计算每个元素的位置。
3.3 为什么 HashMap 的长度是 2^n 次幂?
这是为了尽量将集合元素均摊到数组的不同位置上。
- 我们知道 HashMap 在确定元素对应的数组下标时,是采用了 hashCode 对数组长度取余的运算,它其实等价于 hashCode 对数组长度 - 1 的与运算(h % length 等价于 h & (lenght -1),与运算效率更高,偶数才成立);
- 而 2^n 次幂对应的 length - 1 恰好全是 1(1000-1 = 111),这样就把影响下标的因素归结于 hashCode 本身,因而能够实现尽可能均摊。
3.4 HashMap 中 Key 的匹配判断
if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k))))
3.5 为什么经常使用 String 作为 HashMap 的 Key?
这个问题我认为有 2 个原因:
- 1、不可变类 String 可以避免修改后无法定位键值对: 假设 String 是可变类,当我们在 HashMap 中构建起一个以 String 为 Key 的键值对时,此时对 String 进行修改,那么通过修改后的 String 是无法匹配到刚才构建过的键值对的,因为修改后的 hashCode 可能是变化的。而不可变类可以规避这个问题。
- 2、String 能够满足 Java 对于 hashCode() 和 equals() 的通用约定: 既两个对象 equals() 相同,则 hashCode() 相同,如果 hashCode() 相同,则 equals() 不一定相同。这个约定是为了避免两个 equals() 相同的 Key 在 HashMap 中存储两个独立的键值对,引起矛盾。
4. HashMap 线程安全性
4.1 HashMap 线程不安全的原因
- 数据覆盖问题:如果两个线程并发执行 put 操作,并且两个数据的 hash 值冲突,就可能出现数据覆盖(线程 A 判断 hash 值位置为 null,还未写入数据时挂起,此时线程 B 正常插入数据。接着线程 A 获得时间片,由于线程 A 不会重新判断该位置是否为空,就会把刚才线程 B 写入的数据覆盖掉);
- 环形链表问题: 在 HashMap 触发扩容时,并且正好两个线程同时在操作同一个链表时,就可能引起指针混乱,形成环型链条(因为 JDK 1.7 版本采用头插法,在扩容时会翻转链表的顺序,而 JDK 1.8 采用尾插法,再扩容时会保持链表原本的顺序)。
4.2 HashMap 和 hashTable 的区别?
- 1、hashTable 对每个方法都增加了 synchronized;
- 2、hashTable 不允许 null 作为 Key;
4.3 ConcurrentHashMap 分段锁的原理
HashMap 出现并发问题的核心在于多个线程同时操作同一个链表,而 ConcurrentHashMap 在操作链表前会用 synchronized 对链表的首个元素加锁,从而避免并发问题。
参考资料
- 散列算法—— 维基百科
- 都说 HashMap 是线程不安全的,到底体现在哪儿? —— developer 著
- Java源码分析:HashMap 1.8 相对于1.7 到底更新了什么? —— Carson 著
- 《数据结构与算法之美》(第21、22章) —— 王争 讲,极客时间 出品
简答一波 HashMap 常见八股面试题 —— 算法系列(2)的更多相关文章
- mybatis返回list很智能很简答的,只需要配置resultmap进行类型转换,你dao方法直接写返回值list<对应的object>就行了啊
mybatis返回list很智能很简答的,只需要配置resultmap进行类型转换,你dao方法直接写返回值list<对应的object>就行了啊 dao方法 public List< ...
- linux系统运维面试题简答
1. 简述常用高可用技术 解答: Keepalived:Keepalived是一个保证集群高可用的服务软件,用来防止单点故障,使用VRRP协议实现.在master和backup之间通过mast ...
- 安装python包时遇到"error: Microsoft Visual C++ 9.0 is required"的简答
简答 在Windows下用pip安装Scrapy报如下错误, error: Microsoft Visual C++ 9.0 is required (Unable to find vcvarsall ...
- 【Python】安装python包时遇到"error: Microsoft Visual C++ 9.0 is required"的简答
简答 在Windows下用pip安装Scrapy报如下错误, error: Microsoft Visual C++ 9.0 is required (Unable to find vcvarsall ...
- Java 实现简答的单链表的功能
作者:林子木 博客网址:http://blog.csdn.net/wolinxuebin 參考网址:http://blog.csdn.net/sunsaigang/article/details/5 ...
- Docker理论简答
Docker理论简答: 1. 介绍对docker的认识(10分) Docker是容器,容器不是docker Dockers就是一个文件夹,它欺骗操作系统说自己是一个操作系统,然后把所需要 ...
- 安装python包时遇到"error: Microsoft Visual C++ 9.0 is required"的简答(Python2.7)
简答 在Windows下用pip安装Scrapy报如下错误, error: Microsoft Visual C++ 9.0 is required (Unable to find vcvarsall ...
- 【面试必备】常见Java面试题大综合
一.Java基础 1.Arrays.sort实现原理和Collections.sort实现原理答:Collections.sort方法底层会调用Arrays.sort方法,底层实现都是TimeSort ...
- 机器学习&数据挖掘笔记(常见面试之机器学习算法思想简单梳理)
机器学习&数据挖掘笔记_16(常见面试之机器学习算法思想简单梳理) 作者:tornadomeet 出处:http://www.cnblogs.com/tornadomeet 前言: 找工作时( ...
随机推荐
- Vue.js 3.x 双向绑定原理
什么是双向绑定? 废话不多说,我们先来看一个 v-model 基本的示例: <input type="text" v-model="search"> ...
- Oracle 19c单实例部署
目录 Oracle 19c单实例部署: 1.配置yum: 2.安装rpm包: 3.设置hostname: 4.配置hostname解析: 5.配置时钟同步服务(ntp): 6.检查及配置内核参数: 7 ...
- socket模块和黏包问题
socket套接字简介 编写cs架构的程序 实现数据交互 OSI七层相当复杂 socket套接字是一门技术 socket模块>>>:提供了快捷方式 不需要自己处理每一层 " ...
- 【PyHacker编写指南】打造URL批量采集器
这节课是巡安似海PyHacker编写指南的<打造URL批量采集器> 喜欢用Python写脚本的小伙伴可以跟着一起写一写呀. 编写环境:Python2.x 00x1: 需要用到的模块如下: ...
- spring 事务传播(Propagation)
propagation 一共有以下几种选项: 1. REQUIRED(默认): 使用当前的事务,如果当前没有事务,则自己新建一个事务,子方法必须运行在一个事务中:如果当前存在事务,则加入这个事务,成为 ...
- scanf需要多输入一行是什么问题
有大佬知道用scanf输入,执行程序要多输入一行才能运行一般是什么问题呢 scanf的问题,其中多了\n. scanf如果加入\n,会导致需要多输入一次数据. 错误实例:
- Nginx禁止使用IP访问
在nginx的访问日志中,会出现只显示IP,而不出现域名的情况,在经过尝试之后,是因为没有设置禁止IP访问导致的. 下面就是在配置文件中设置禁止IP访问,来实现日志文件中$host显示域名. vim ...
- 声学感知刻度(mel scale、Bark scale、ERB)与声学特征提取(MFCC、BFCC、GFCC)
梅尔刻度 梅尔刻度(Mel scale)是一种由听众判断不同频率 音高(pitch)彼此相等的感知刻度,表示人耳对等距音高(pitch)变化的感知.mel 刻度和正常频率(Hz)之间的参考点是将1 k ...
- 6月6日,HTTP/3 正式发布了!
经过了多年的努力,在 6 月 6 号,IETF (互联网工程任务小组) 正式发布了 HTTP/3 的 RFC, 这是超文本传输协议(HTTP)的第三个主要版本,完整的 RFC 超过了 20000 字, ...
- 在 4GB 物理内存的机器上,申请 8G 内存会怎么样?
作者:小林coding 计算机八股文刷题网站:https://xiaolincoding.com/ 大家好,我是小林. 看到读者在群里讨论这些面试题: 其中,第一个问题「在 4GB 物理内存的机器上, ...