推荐系统[八]算法实践总结V1:淘宝逛逛and阿里飞猪个性化推荐:召回算法实践总结【冷启动召回、复购召回、用户行为召回等算法实战】
0.前言:召回排序流程策略算法简介
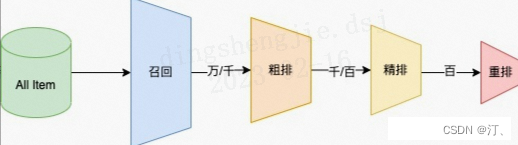
推荐可分为以下四个流程,分别是召回、粗排、精排以及重排:
- 召回是源头,在某种意义上决定着整个推荐的天花板;
- 粗排是初筛,一般不会上复杂模型;
- 精排是整个推荐环节的重中之重,在特征和模型上都会做的比较复杂;
- 重排,一般是做打散或满足业务运营的特定强插需求,同样不会使用复杂模型;
召回层:召回解决的是从海量候选item中召回千级别的item问题
- 统计类,热度,LBS;
- 协同过滤类,UserCF、ItemCF;
- U2T2I,如基于user tag召回;
- I2I类,如Embedding(Word2Vec、FastText),GraphEmbedding(Node2Vec、DeepWalk、EGES);
- U2I类,如DSSM、YouTube DNN、Sentence Bert;
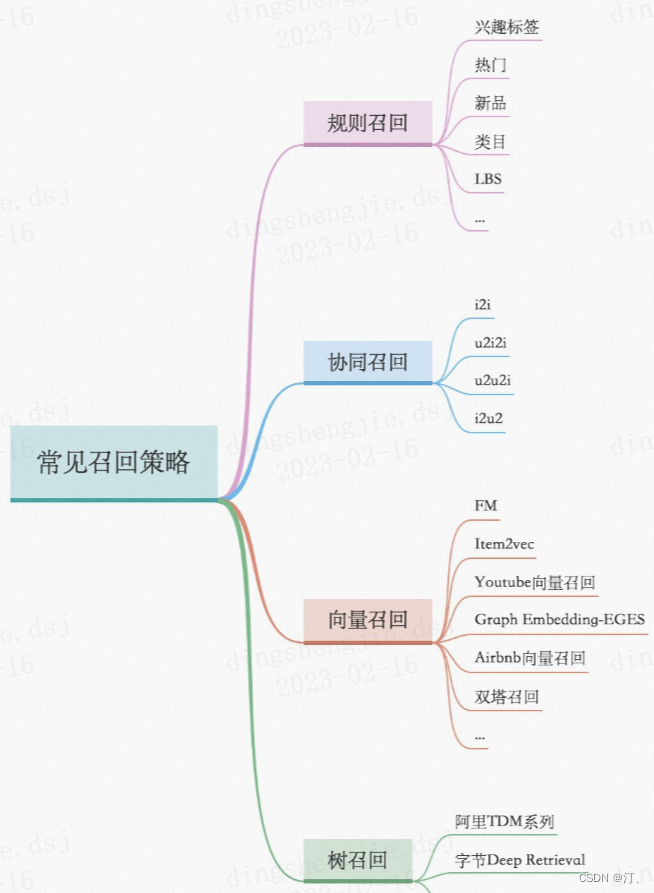
模型类:模型类的模式是将用户和item分别映射到一个向量空间,然后用向量召回,这类有itemcf,usercf,embedding(word2vec),Graph embedding(node2vec等),DNN(如DSSM双塔召回,YouTubeDNN等),RNN(预测下一个点击的item得到用户emb和item emb);向量检索可以用Annoy(基于LSH),Faiss(基于矢量量化)。此外还见过用逻辑回归搞个预估模型,把权重大的交叉特征拿出来构建索引做召回
排序策略,learning to rank 流程三大模式(pointwise、pairwise、listwise),主要是特征工程和CTR模型预估;
- 粗排层:本质上跟精排类似,只是特征和模型复杂度上会精简,此外也有将精排模型通过蒸馏得到简化版模型来做粗排
- 常见的特征挖掘(user、item、context,以及相互交叉);
- 精排层:精排解决的是从千级别item到几十这个级别的问题
- CTR预估:lr,gbdt,fm及其变种(fm是一个工程团队不太强又对算法精度有一定要求时比较好的选择),widedeep,deepfm,NCF各种交叉,DIN,BERT,RNN
- 多目标:MOE,MMOE,MTL(多任务学习)
- 打分公式融合: 随机搜索,CEM(性价比比较高的方法),在线贝叶斯优化(高斯过程),带模型CEM,强化学习等
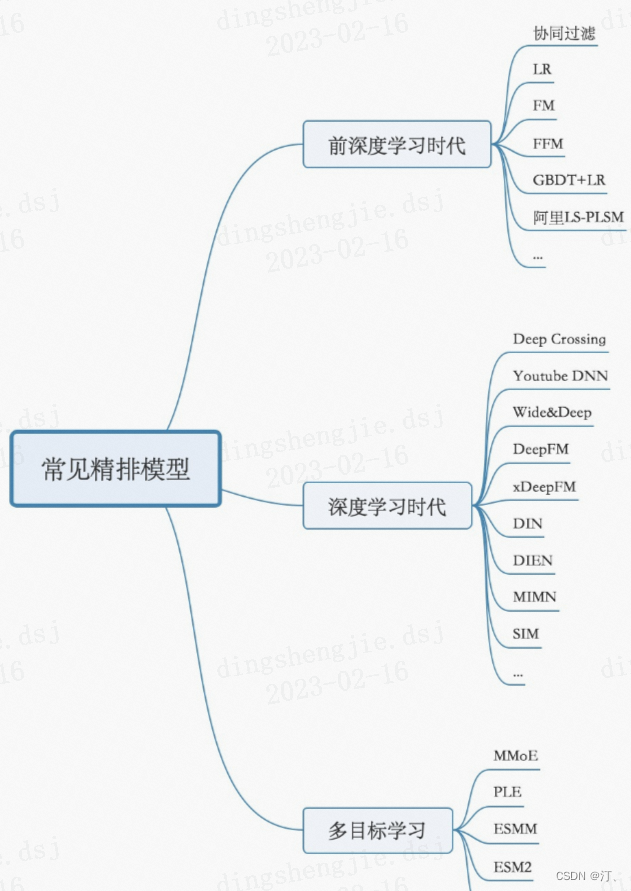
- 粗排层:本质上跟精排类似,只是特征和模型复杂度上会精简,此外也有将精排模型通过蒸馏得到简化版模型来做粗排
重排层:重排层解决的是展示列表总体最优,模型有 MMR,DPP,RNN系列(参考阿里的globalrerank系列)
展示层:
- 推荐理由:统计规则、行为规则、抽取式(一般从评论和内容中抽取)、生成式;排序可以用汤普森采样(简单有效),融合到精排模型排等等
- 首图优选:CNN抽特征,汤普森采样
探索与利用:随机策略(简单有效),汤普森采样,bandit,强化学习(Q-Learning、DQN)等
产品层:交互式推荐、分tab、多种类型物料融合
1.淘宝逛逛召回算法实践总结
内容化这几年越来越成为电商的重点,用户来到网购的时候越来越不局限在只有明确需求的时候,而更多的是没有明确需求的时候,就像是逛街一样。逛逛就是在这样的背景下诞生的内容化产品,打造出有用、有趣、潮流、奇妙、新鲜的内容,为消费者提供全新的内容消费体验。在这个场景下的内容召回有很多问题需要探索,其中主要的特点和挑战有:
强时效性:内容推荐场景下的内容新旧汰换非常快,新内容的用户行为少,很难用用户历史行为去描述新内容,而用户行为正是老内容投放主要的依赖。所以当不能依靠用户行为数据来建模内容之间关系的时候,我们必须要找到其他可以表征内容的方法。
多兴趣表征:多兴趣表征,特别是多峰召回是这几年比较主流的一个趋势。但是目前多峰模型中峰的数量是固定的,当用户行为高度集中的时候,强制的将用户行为拆分成多向量,又会影响单个向量的表达能力。如何去平衡不同用户行为特点,特别是收敛和发散的兴趣分布,就成了此类任务的挑战。
在设计优化方向的时候,我们重点考虑上面描述问题的解法(召回本身也需要兼顾精准性和多样性,所以单一召回模型显然无法满足这些要求,我们的思路是开发多个互补的召回模型)。详细的介绍在后面的章节以及对应的后续文章中展开:
跨域联合召回:除了单纯把多域的信息平等输入到模型中,如何更好利用跨域之间的信息交互就变的尤为重要。目前有很多优秀的工作在讨论这样的问题,比如通过用户语义,通过差异学习和辅助loss等。我们提出了基于异构序列融合的多兴趣深度召回模型CMDM(a cross-domain multi-interest deep matching network),以及双序列融合网络Contextual Gate DAN 2种模型结构来解决这个问题。
语义&图谱&多模态:解决时效性,最主要的问题就是怎么去建模新内容,最自然的就是content-based的思想。content-based的关键是真正理解内容本身,而content-based里主要的输入信息就是语义,图像,视频等多模态信息。目前有许多工作在讨论这样的问题,比如通过认知的方式来解决,多模态表征学习,结合bert和高阶张量等方式等等。在语义召回上,我们不仅仅满足于语义信息的融入,还通过Auxiliary Sequence Mask Learning去对行为序列进行高阶语义层面的提纯。更进一步,我们利用内容图谱信息来推荐,并且引入了个性化动态图谱的概念。对于新老内容上表达能力的差异问题,我们通过multi-view learning的思想去将id特征和多模态特征做融合。
泛多峰:为了解决多峰强制将兴趣拆分的问题,我们考虑到单峰和多峰的各自特点,特别是在泛化和多样性上各自有不同的建模能力。基于此,我们提出了泛多峰的概念。
1.1 跨域联合召回
1.1.1 基于异构序列融合的多兴趣深度召回
在单一推荐场景下,深度召回模型只需要考虑用户在当前场景下的消费行为,通过序列建模技术提取用户兴趣进而与目标商品或内容进行匹配建模。而在本推荐场景下,深度召回模型需要同时考虑用户内容消费行为和商品消费行为,进行跨场景建模。为此,我们提出了CMDM多兴趣召回模型架构,能够对用户的跨场景异构行为序列进行融合建模。在CMDM中,我们设计了用于异构序列建模的层级注意力模块,通过层级注意力模块提取的多个用户兴趣向量与目标内容向量进行匹配建模。
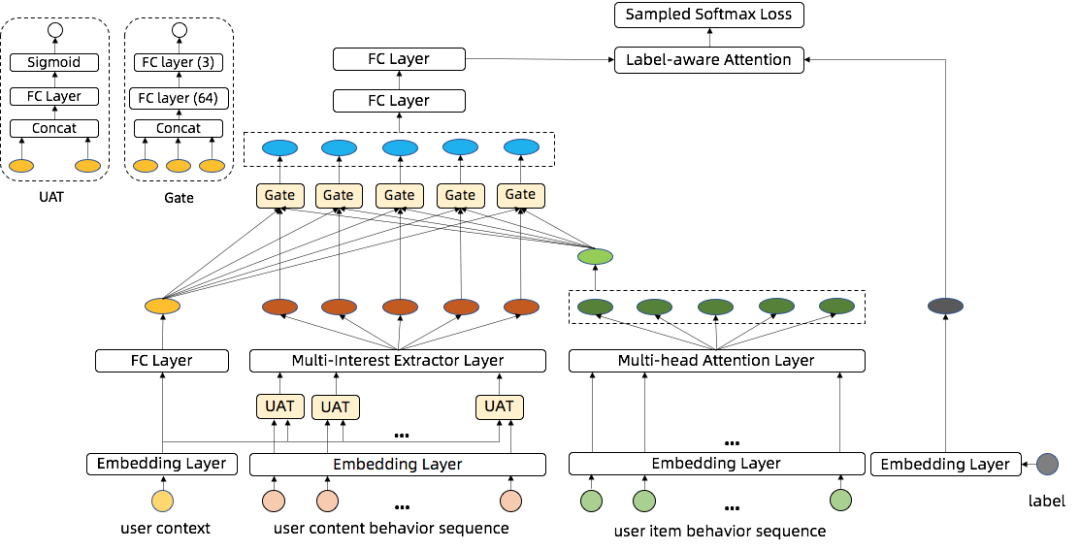
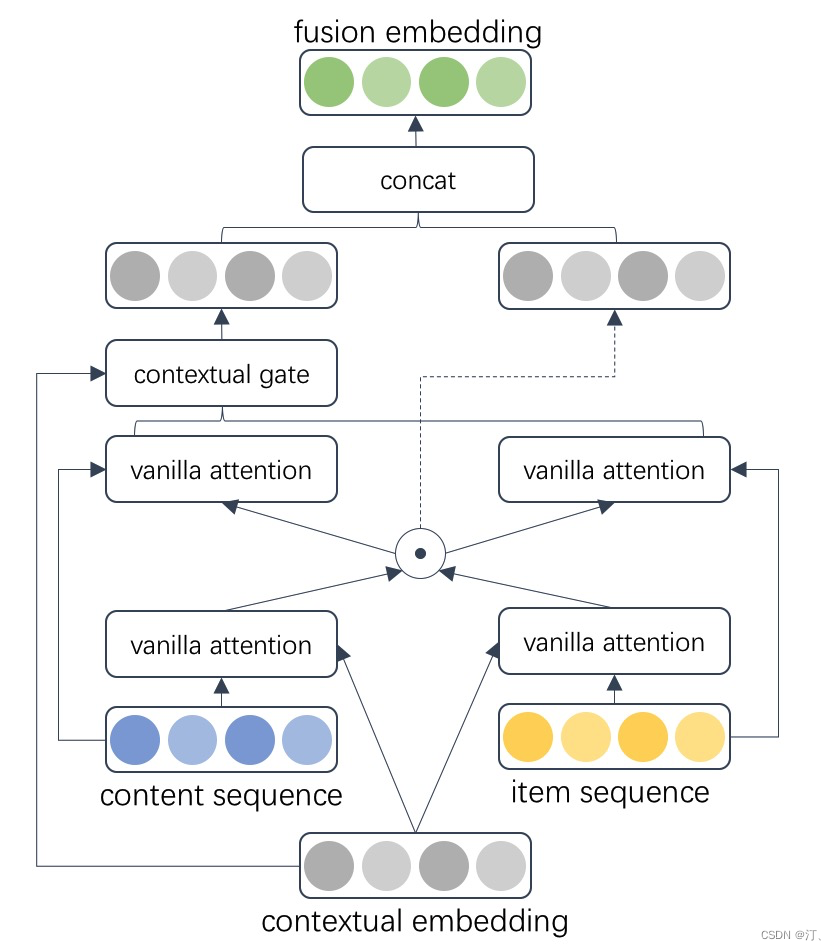
1.1.2 双序列融合网络Contextual Gate DAN
除了通过层次注意力的方式,异构序列中还有个特点就是在时间上更接近交叉并存的状态。为了学习到两个序列之间的信息交叉,充分融合商品点击序列和内容点击序列,我们从自然语言处理的VQA任务中得到启发。VQA是用自然语言回答给定图像的问题的任务,常用做法是在图片上应用视觉注意力,在文本上应用文本注意力,再分别将图片、文字多模态向量输入到一个联合的学习空间,通过融合映射到共享语义空间。而DAN结构是VQA任务中一个十分有效的模型结构,DAN通过设计模块化网络,允许视觉和文本注意力在协作期间相互引导并共享语义信息。我们对DAN结构进行了改进,设计了Contextual Gate DAN 双序列融合网络:
1.2 语义&图谱&多模态
1.2.1 多模态语义召回
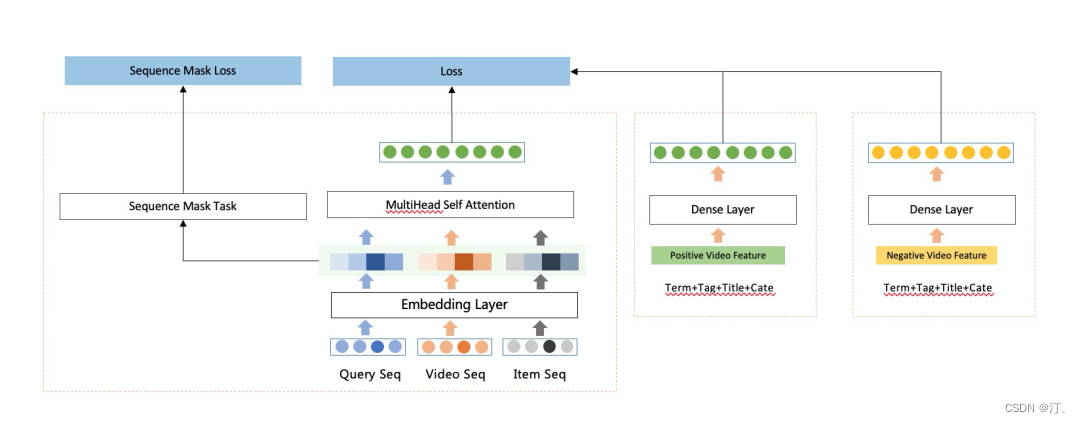
在内容推荐场景内,存在大量新内容需要冷启动,我们主要通过语义和多模态2种方式。相对于搜索任务,语义匹配是一个从单点到多点,解空间更大更广的问题。首先是用户行为的不确定性,内容推荐场景下用户决策空间更大更广,从而导致用户对推荐系统的反馈信号本身就存在较大的不确定性;再就是语义空间表达的对齐问题,这里的对齐包含两个方面,第一个方面是单个序列里的内容表达的语义标签提取方式差别大(比如cpv、分词、语义标签、多模态表征等等),另外一个方面是多序列(内容和商品等)之间的语义空间对齐问题。多模态的召回方式融合了文本,图像,音频等大量模式跨域信息,由于与内容互动解耦,在缓解内容冷启动上具有一定的优势。多模态召回主要是通过理解内容多模态表征,先后进行了collaborative filtering、聚类中心召回、个性化多模态表征相关的探索工作,在多样性方面取得了一定的效果,深度语义召回方面针对用户行为去噪和更好的表达语义信息角度出发,迭代了cate-aware和query-aware和序列mask 自监督任务的模型。
1.2.2 行为稀疏场景下的图模型实践
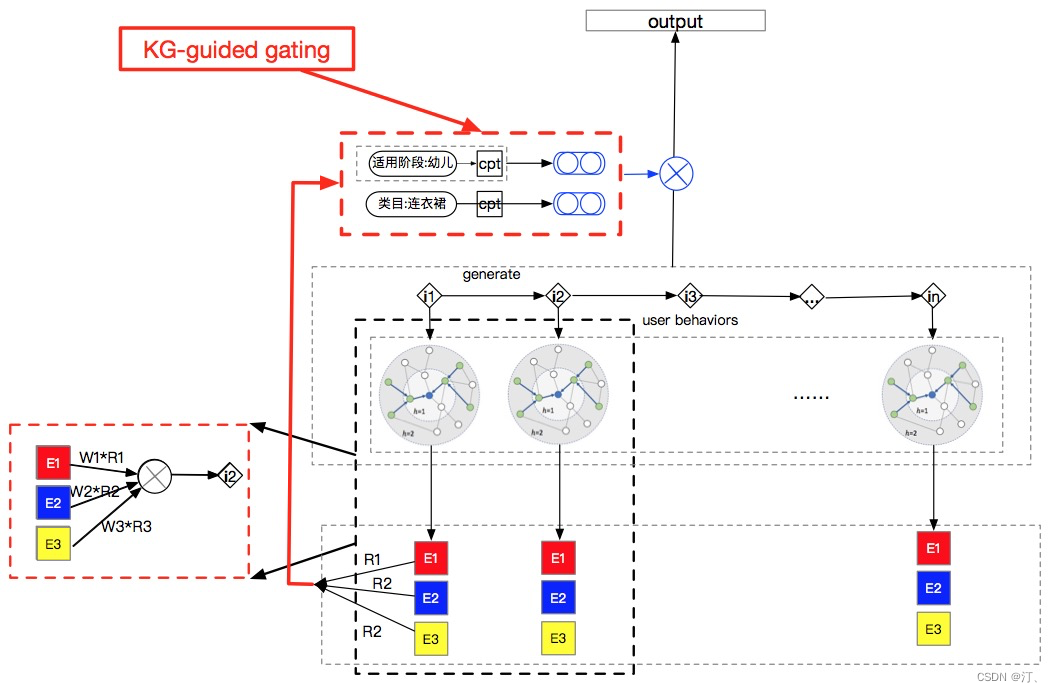
更进一步,我们利用内容图谱信息来推荐。知识图谱构建的出发点就是对用户的深度认知,能够帮助系统以用户需求出发构建概念,从而可以帮助理解用户行为背后的语义和逻辑。这样可以将用户的每次点击行为,都用图谱的形式极大的丰富,图谱带来的可解释的能力还可以大大加快模型的收敛速度。知识图谱有个特点,就是其中的信息是相对固定的,或者说是静态的,因为知识图谱基本是由先验信息构成的。但是从各个用户的角度,知识图谱的数据中的链接重要度并不相同。比如一个电影,有的用户是因为主演看的,有的用户是因为导演看的,那么这个电影连接的主演边和导演边的权重就因人而异了。我们提出了一种新的方法来融合用户动态信息和静态图谱数据。每个行为都用图谱扩展,这样行为序列变成行为图谱序列, 并且加入KnowledgeGraph-guided gating的自适应的生成式门控图注意力,去影响知识图谱融入到模型中的点边的权重。
1.2.3 融合多模态信息的跨模态召回
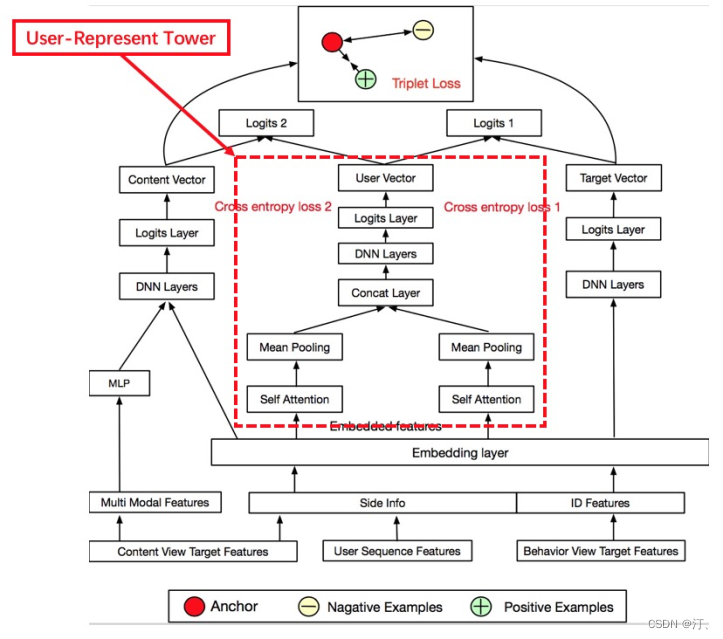
针对新内容冷启动的问题,我们提出了跨模态召回模型来兼顾content-based和behaviour-based的召回各自的优点。在跨模态召回模型构建前,我们首先引入了多模态meta信息为主的“语义” deep collaborative filtering召回,两者的显著差别主要在target side的特征组成中相较与behaviour-based的特征,多模态特征构建的模型去除了影响较大的内容id类的特征,将这些特征更换为了来自多模态预训练技术得到的多模态表征输入。除了上面的变化,我们还加入了triplet loss的部分使得embedding空间更具有区分度,效率指标也有了较大幅度的提升。
1.3 用户多兴趣表征(多模型簇联合学习):泛多峰
多峰召回模型通过对用户侧产生多个表征不同“兴趣”的向量进行多个向量的召回,是对于单峰的一个拓展,将单个用户的表达扩展成了多个兴趣表达, 更精确地刻画了用户, 从而取得更好的效果。我们通过对于单峰模型及多峰模型的观察发现,用户行为高度集中的序列单峰模型的线上效率相对于多峰模型会更有优势,而那些用户序列类目丰富度较高的则多峰模型的效率明显占优。所以这里提出了泛多峰u2i模型的概念,尝试将多峰模型容易拟合行为序列类目丰富度较高的用户,而单峰模型则更容易拟合行为序列类目丰富度较为集中的用户的优势进行结合。使得单一模型能够通过产生不同算法簇的多个不同表征的向量在不同簇的内容向量中进行召回,从而具备这两种召回范式的优点。
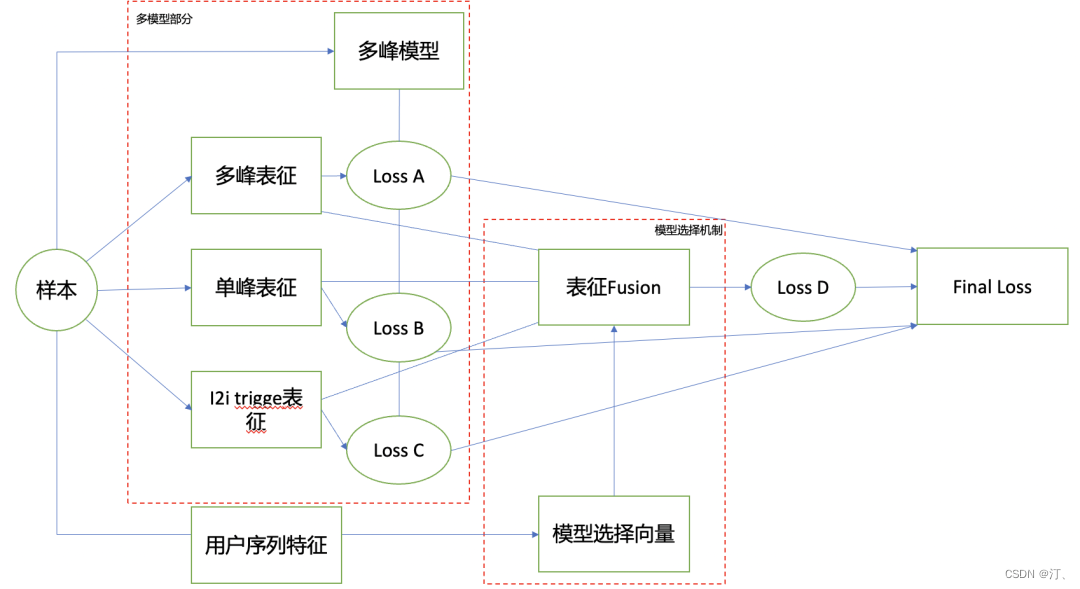
1.4 提升优化:
▐ 认知推荐
我们正在尝试,将图谱用于user embedding投影,投影的平面空间就是语义空间,这样做到可控多维度语义可解释embedding。另外,对于召回,采样方式对模型效果影响非常大,结合知识图谱来进行graph-based Learning to sample的优化,对于正负样本的选取更加做到关联可控,加快迭代速度,提升效果。
▐ 兴趣破圈
在内容化推荐领域,仅仅相似度提高的优化,会导致用户没有新鲜感,对平台粘性变低。如何帮助用户探索他更多的兴趣,是现在内容化推荐亟待解决的另一个问题。一种做法是兴趣近邻,从已有兴趣出发,慢慢通过兴趣之间的相似,扩展用户未知的领域,可以参考MIND,CLR一些思路。另一种做法是对兴趣构建推理引擎,在对已有兴趣推理过程建模之后,加入扰动来探索用户可能新的兴趣。
2.阿里飞猪个性化推荐:召回篇
常见的有基于user profile的召回,基于协同过滤的召回,还有最近比较流程的基于embedding向量相似度的topN召回等等。方法大家都知道,但具体问题具体分析,对应到旅行场景中这些方法都面临着种种挑战。例如:旅行用户需求周期长,行为稀疏导致训练不足;行为兴趣点发散导致效果相关性较差;冷启动用户多导致整体召回不足,并且热门现象严重;同时,具备旅行特色的召回如何满足,例如:针对有明确行程的用户如何精准召回,差旅用户的周期性复购需求如何识别并召回等。
本次分享将介绍在飞猪旅行场景下,是如何针对这些问题进行优化并提升效果的。主要内容包括:⻜猪旅行场景召回问题、冷启动用户的召回、行程的表达与召回、基于用户行为的召回、周期性复购的召回。
2.1 飞猪旅行场景召回问题
推荐系统流程
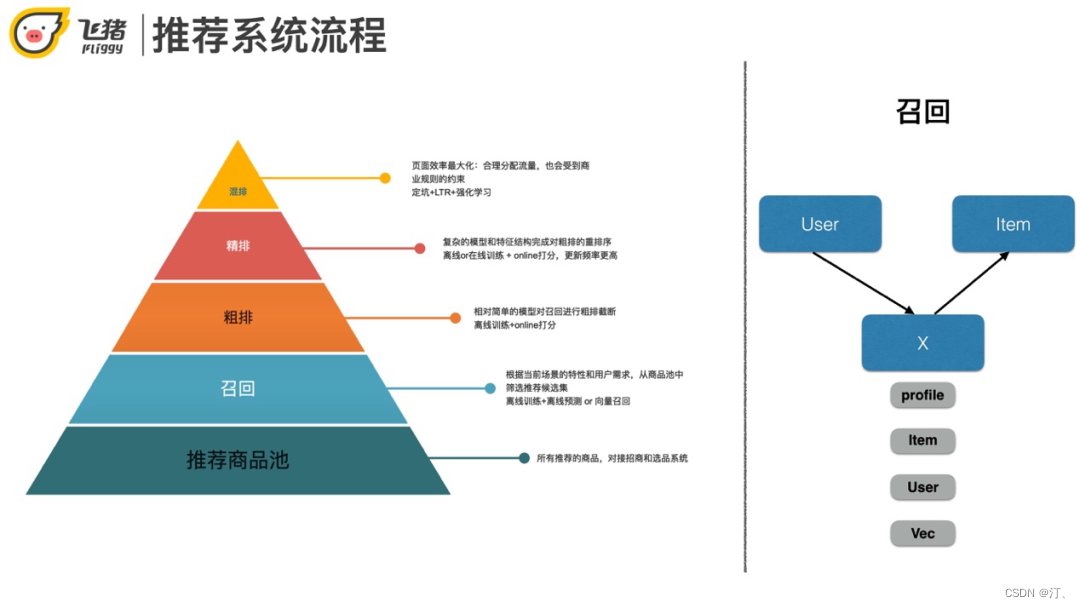
首先介绍推荐的整体流程。整体上分为5个阶段。从全量的商品池开始,之后依此是召回阶段,粗排/精排阶段,最后的混排模块根据业务实际情况而定,并不是大多数推荐系统必须的。粗排和精排在另外一次分享中已经介绍过了,本次分享主要介绍一下飞猪推荐系统的召回问题,召回可以说决定了推荐系统效果的上限。
下面说一下召回和粗排/精排的区别。从召回到粗排再到精排模块,商品的数据量是递减的,模型的复杂度会增高。具体会体现在输入特征数量和模型复杂度的增加,更新往往也会更频繁。对应的训练和上线的方式也会不同,拿召回来讲,出于性能的考虑,往往采用离线训练+打分或者离线训练得到向量表达+向量检索的方式,而排序阶段为了更好的准确率和线上指标,更多的是离线训练+实时打分,甚至在线学习的方式。
召回的本质其实就是将用户和商品从不同维度关联起来。常见的方法比如content-base匹配,或者item/user based的协同过滤,还有最近比较流行的向量化召回。向量化召回常用做法是用深度学习将用户和商品都表达成向量,然后基于内积或欧式距离通过向量检索的方式找到和用户最匹配的商品。
2.1.1 飞猪推荐场景
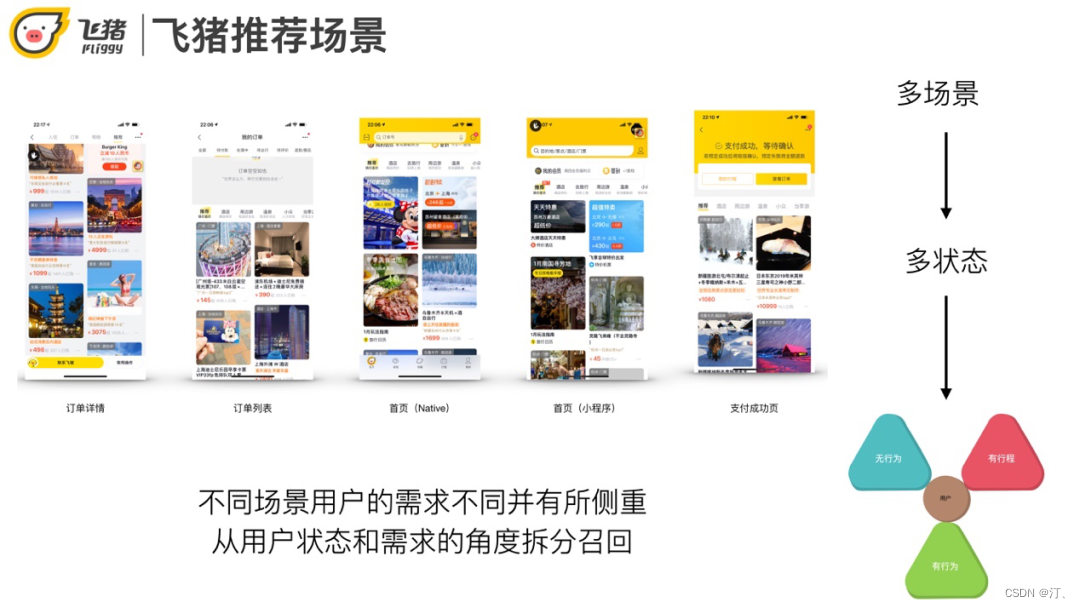
飞猪的推荐页面有很多,比如首页,支付成功页,订单列表页,订单详情页都有猜你喜欢。不同页面对应了不同的场景,用户在不同场景下需求不同,也有一定的交叉。比如首页偏重逛/种草,但支付完成后推荐一些与订单相关的商品会更好。
我们大致可以把用户分为三类:无行为、有行为,还有一种是飞猪场景下特殊的一类"有行程"。
2.1.2 主要问题
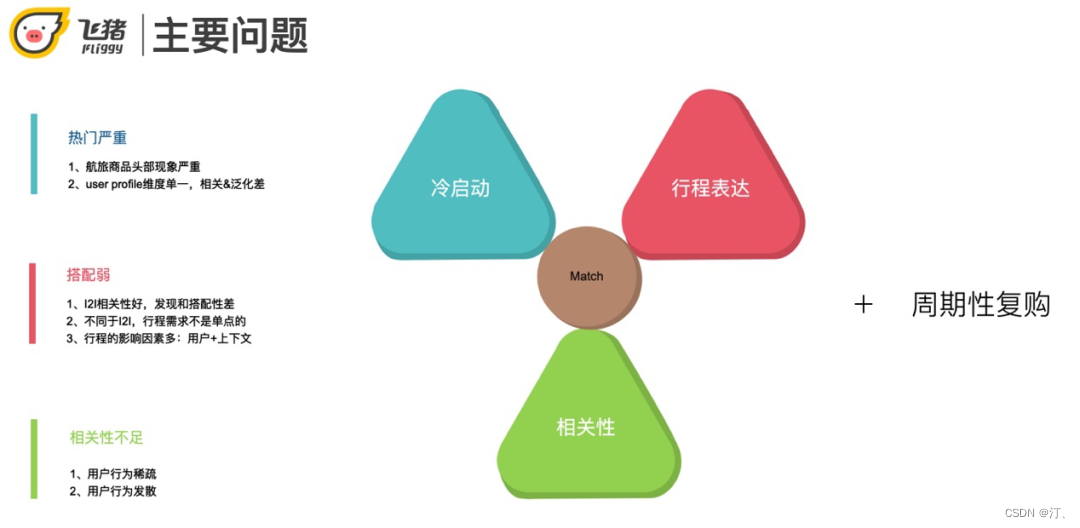
本次分享的主要内容就是针对这三类用户在推荐过程中存在的问题+周期性复购场景 ( 出差/回家 ) 的解决。
航旅场景下的召回存在以下问题:
冷启动:航旅商品的热门现象严重,user profile缺乏。
相关性vs搭配性:航旅场景下要求搭配性比较高,传统的I2I只偏重相关性。但用户的行程需求不是单点的,比如买了飞机票还要看住宿。行程受上下文影响比较多,比如季节、用户近期行为等。
相关性不足:航旅用户的行为稀疏又发散,目前的召回结果噪音较多。
下面会对我们在优化过程中碰到的相关问题一一介绍。我们知道,召回处于推荐链路的底端,对召回常规的离线评估方式有预测用户未来点击的TopN准确率或者用户未来点击的商品在召回队列中平均位置等等。但是在工业系统中,为了召回的多样性和准确率,都是存在多路召回的,离线指标的提高并不代表线上效果的提升,一种常见的评估某路召回效果的方式就是对比同类召回通道的线上点击率,这种评估更能真实反映线上的召回效果,基于篇幅的考虑,后面的介绍主要展示了线上召回通道点击率的提升效果。
2.2 冷启动用户召回
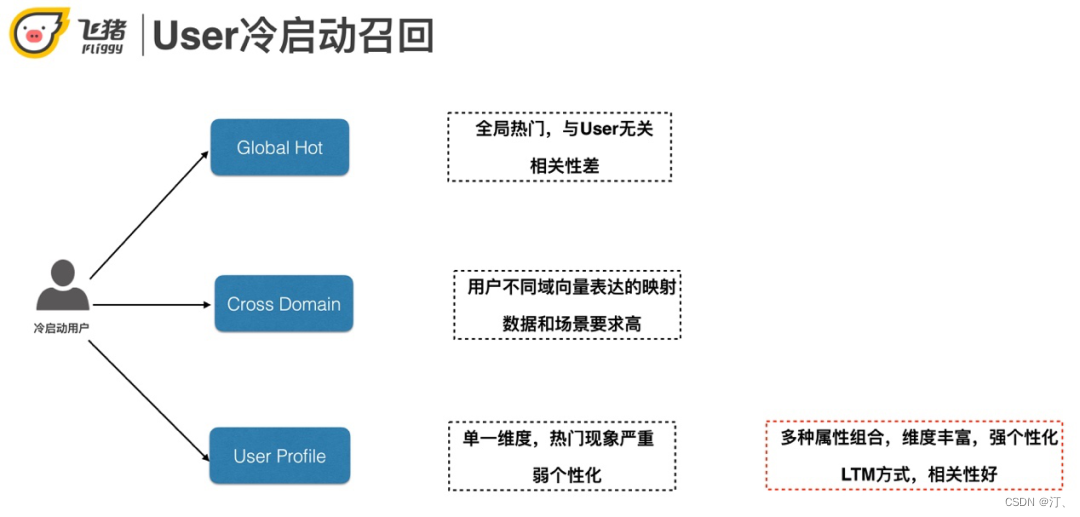
2.2.1 User冷启动召回
用户冷启动召回主要有以下几种方案:Global Hot、Cross Domain、基于用户属性的召回。
全局热门:缺点是和user无关,相关性差。
Cross domain:一种做法是基于不同域 ( 例如飞猪和淘宝 ) 共同用户的行为将不同域的用户映射到同一个向量空间,然后借助其他域的丰富行为提升本域冷启动用户的召回效果。
基于用户属性:单一属性的缺点是热门现象严重,个性化不足。我们采用了基于多属性组合的方法。
2.2.2 UserAttr2I
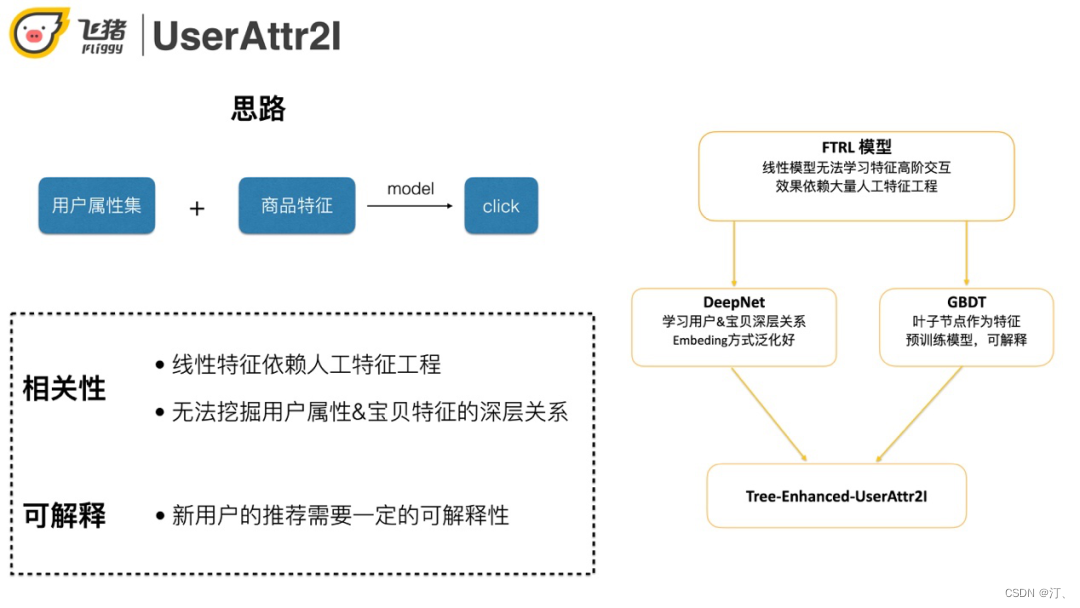
在这里介绍我们的方案UserAttr2I,使用类似排序模型的方法,输入用户+商品的属性,预测用户是否会点击一个商品。
开始用线性FTRL模型,效果不是很好。原因是线性模型无法学习高阶特征,并且解释性比较差。针对这两个问题,通过DeepNet提高泛化性,同时用GBDT来做特征筛选。

下面对比双塔结构和深度特征交叉两种方案,优缺点如图所示。最终选择了第二种,原因是目标用户是冷启动,能用到的特征比较少。如果放弃挖掘用户和宝贝之间的关系会导致相关性比较差。模型结构如下:
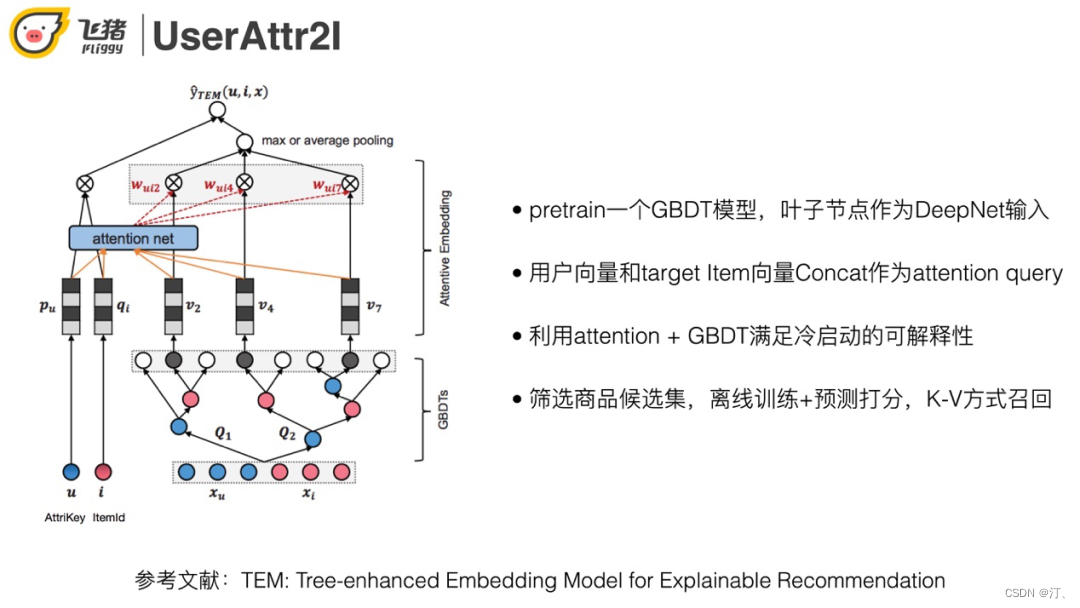
通过attention操作以及GBDT的叶子节点即可满足冷启动的可解释性。
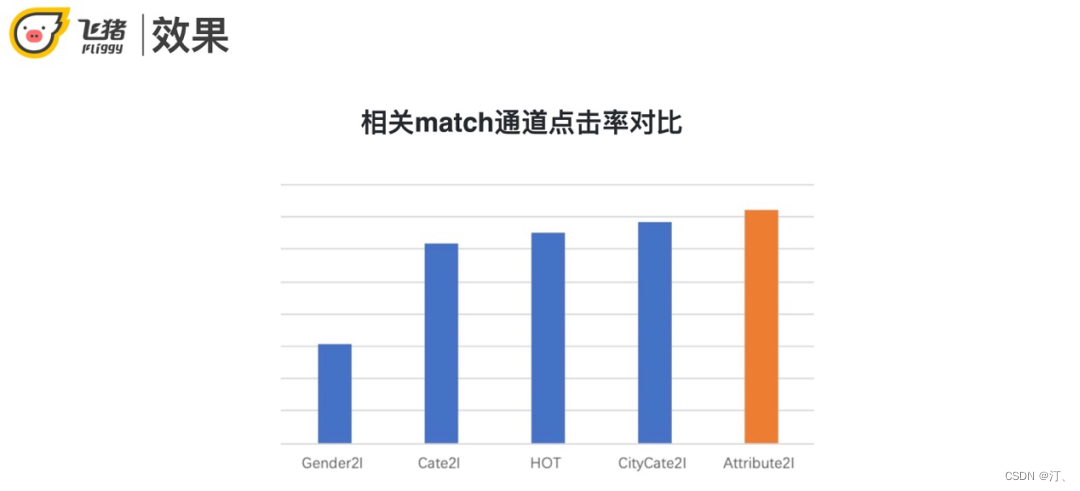
对比其他冷启动的召回方式,Attribute2I的点击率最高。
2.3 行程的表达与召回
2.3.1 Order2I
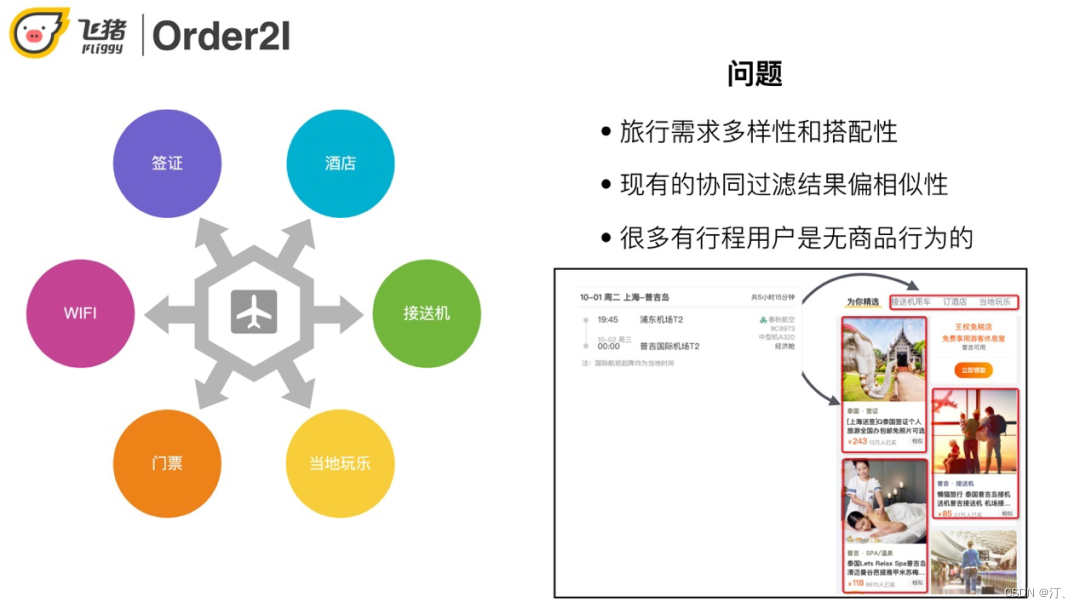
在飞猪场景下用户有类似如下的需求:买了去某地的机票,用户很可能需要与之搭配的签证/wifi/酒店等等,而协同过滤通常只能推出同类型商品,比如门票推门票,酒店推酒店。另外飞猪不像淘宝用户可能会经常逛,有比较丰富的历史行为信息可以供我们去分析和计算,飞猪用户通常是"买完即走"。

通过数据分析我们发现订单附近的行为数据和订单有较高搭配关系,我们通过Graph Embedding的方式学习订单和宝贝的Embed,以此来学习搭配关系。
难点有以下几个:
如何挖掘反映搭配关系的数据集合
搭配的限制性比较强,如果仅仅基于用户行为构建图,由于用户行为噪音多,会造成较多badcase
如果完全基于随机游走学习Embed,最后的召回结果相关性差,因此需要行业知识的约束
数据稀疏,覆盖商品少,冷启动效果差
解决方案:
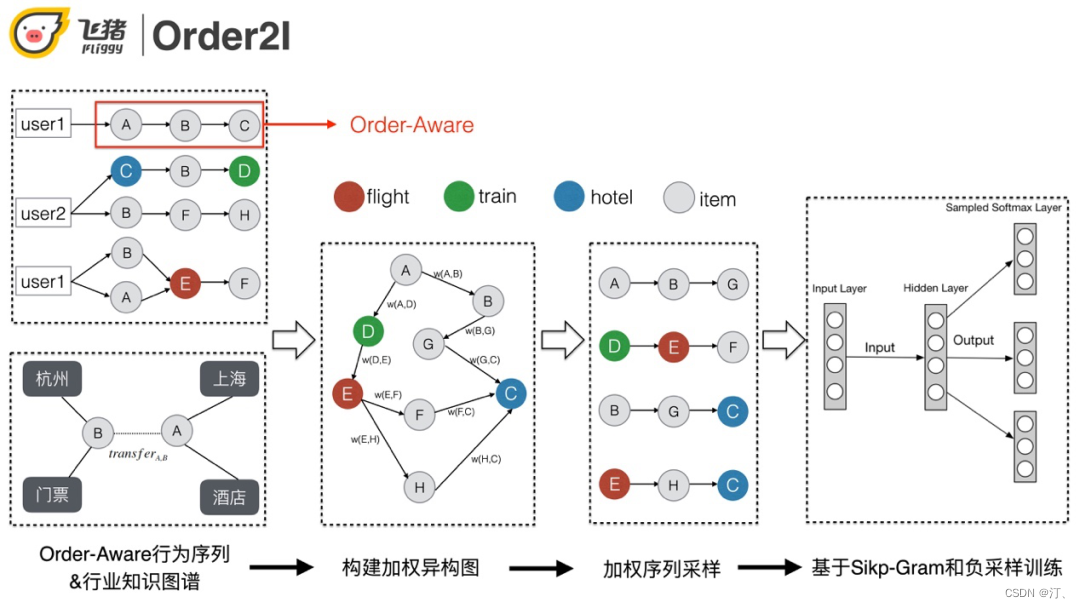
利用航旅知识图谱以及用户的行为序列进行加权异构图的构建 ( 机票/火车票节点利用业务线+出发地+目的地唯一标示、宝贝&酒店利用其id唯一标示 )。之后的流程和传统的Graph Embedding类似。
具体过程:
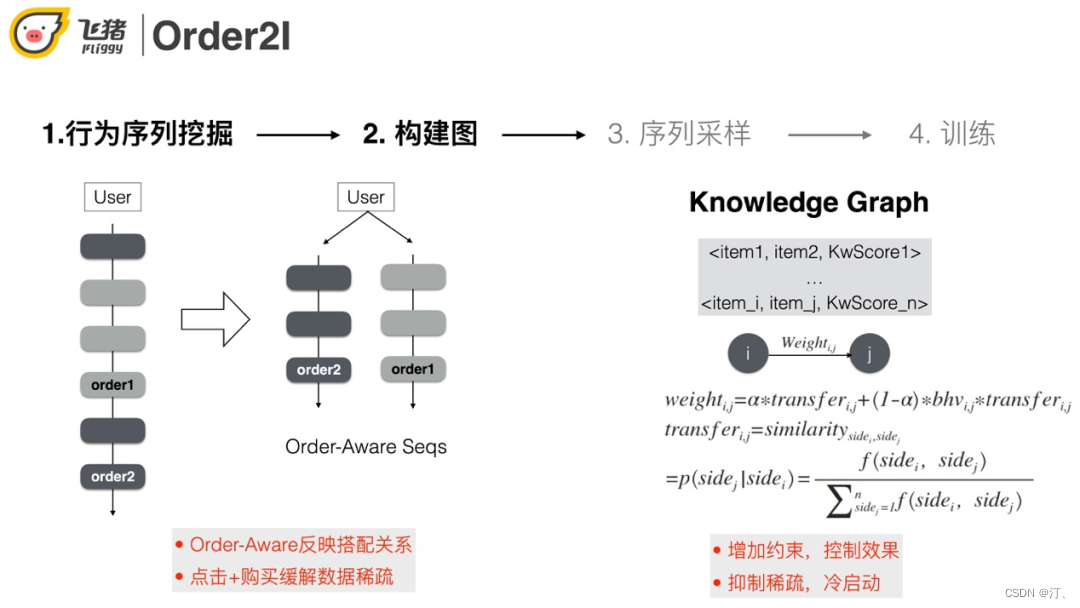
① 以订单粒度对用户的行为做拆分和聚合,同时加入点击行为缓解稀疏问题。
② 边的权重的计算同时考虑知识图谱和用户行为,这种做法一方面可以增加约束控制效果,另一方面也可以抑制稀疏,解决冷启动的问题。
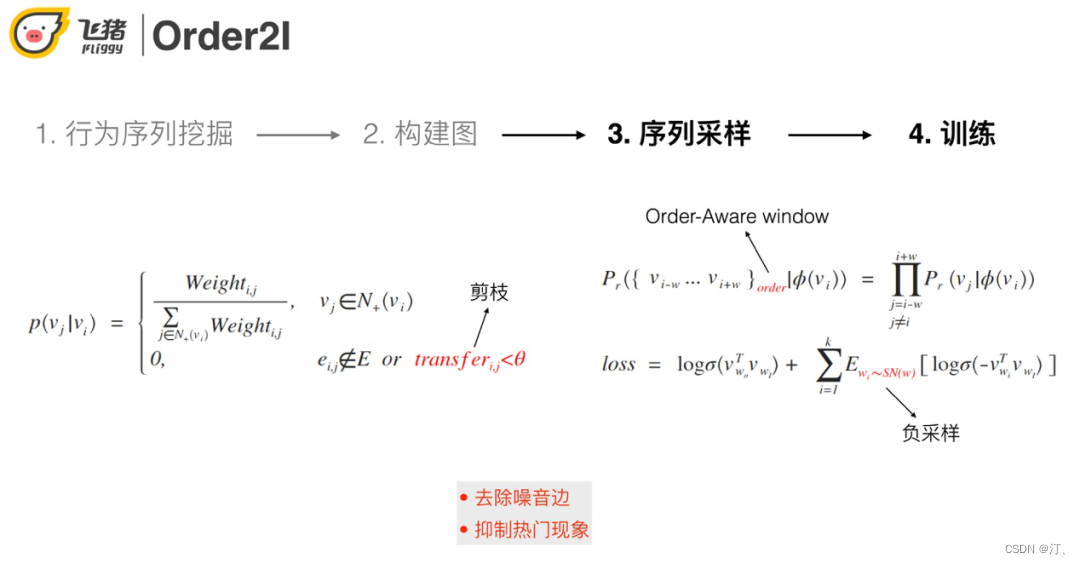
③ 序列采样过程中会基于转移概率进行剪枝操作,用来抑制噪声和缓解热门问题。
④ skip-gram+负采样训练。

这里有一个具体的case,用户订了一张去曼谷的机票,order2I召回了曼谷的一些自助餐,落地签,热门景点等,体现了较好的搭配性。整体的指标上order2I的点击率也明显高于其他方式。
2.3.2 journey2I
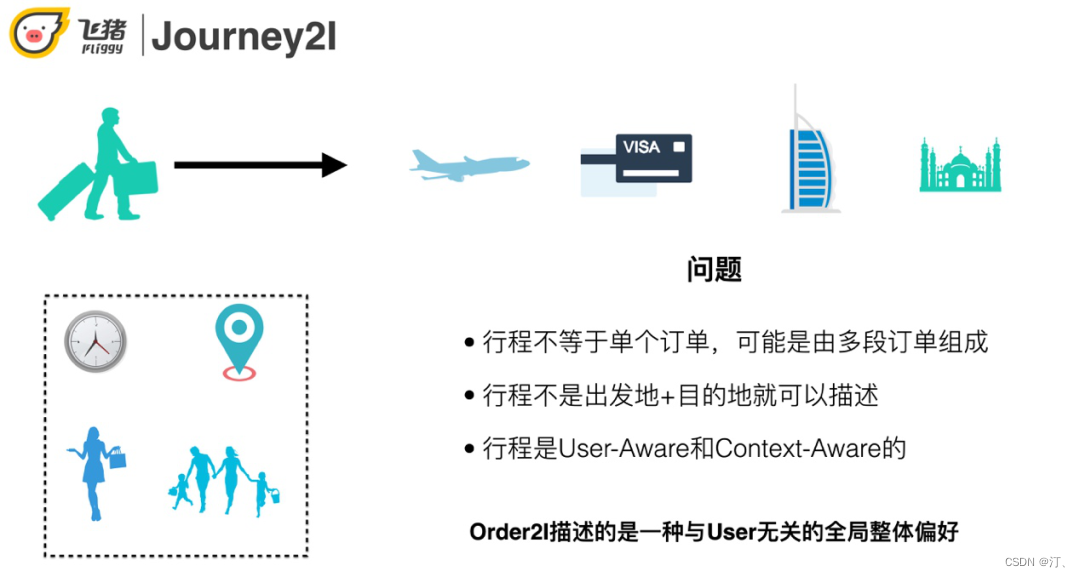
Order2I将订单进行向量化表达,从而进行召回。但是它还有一些问题:用户的某次行程可能由多个订单组成,甚至有的订单只是中转的作用,Graph Embedding还是基于单个订单进行搭配的推荐;用户的某次行程不是一个出发地+目的地就能描述的,它不仅与行程本身属性 ( 例如出发/到达时间,目的地,行程意图等 ) 相关,还与用户的属性和偏好 ( 例如年龄,是否是亲子用户 ) 相关。因此行程既是User-Aware又是Context-Aware的。而Order2I学习的还是一种全局的整体偏好,与用户无关,不够个性化。因此我们尝试在行程的粒度做召回,综合考虑用户属性、行程意图、上下文等因素,更个性化的召回与用户这次行程以及用户自身强相关的的宝贝。

以行程为粒度,对多个订单做聚合,并且增加行程相关的特征。融入用户的基础属性特征和历史行为序列。丰富行程特征并引入attention机制。采用双塔模型离线存储商品向量,在线做向量化召回。模型结构如下:

模型左边主要是利用行程特征对订单序列以及用户的历史行为序列进行attention操作,用于识别关键订单以及用户关键行为。在此基础上融合行程特征和用户属性特征学习用户该段行程的Embed。模型右边是商品特征,经过多层MLP之后学习到的宝贝Embed。两边做内积运算,利用交叉熵损失进行优化,这样保证召回的结果不仅与行程相关还与用户行为相关。
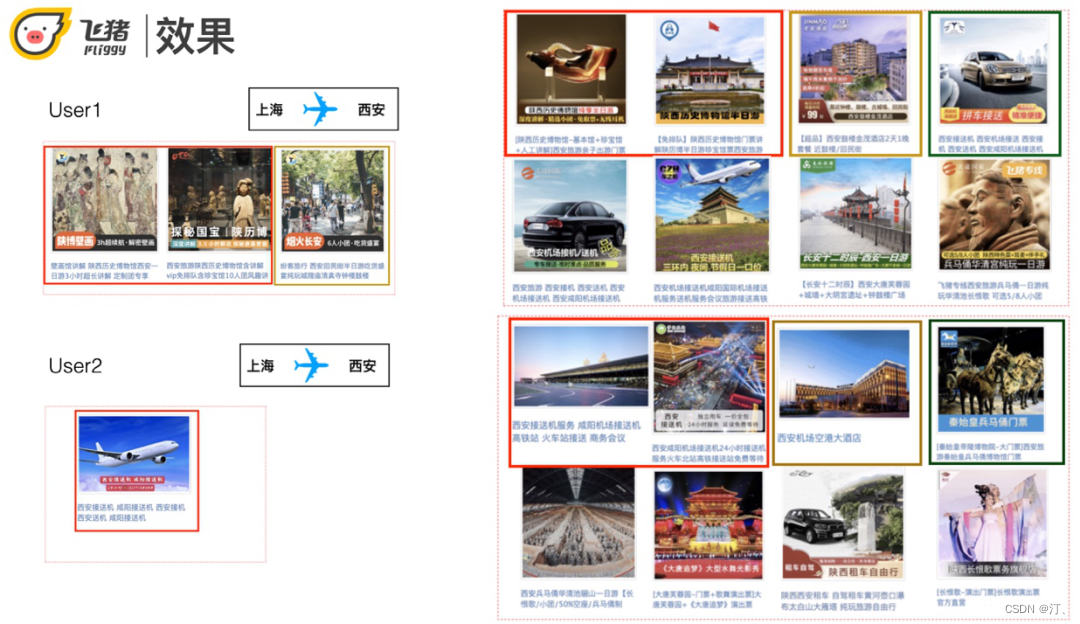
两个同样是上海到西安的用户。用户1点击了历史博物馆和小吃,不仅召回了与机票搭配的接送机,还召回了与行为行为相关的小吃街附近的酒店以及历史博物馆相关的宝贝。
用户2点击了一个接送机,除了召回接送机还召回了机场附近的酒店和热门的POI景点门票。可以看出基于用户的不同行为,召回结果不仅满足搭配关系还与用户行为强相关。
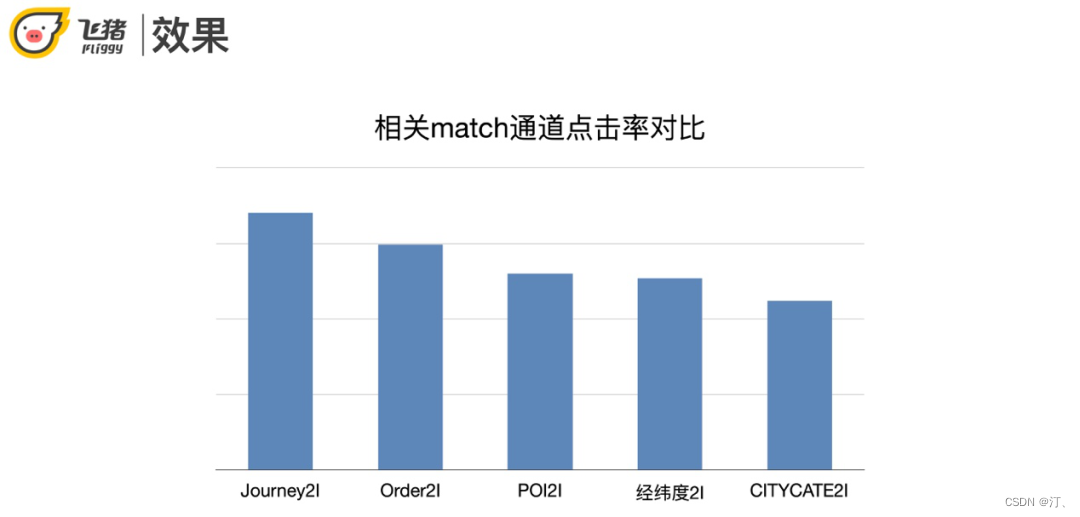
从指标来看Journey2I相对Order2I有进一步明显的提升。
2.4 基于用户行为的召回
2.4.1 Session-Based I2I
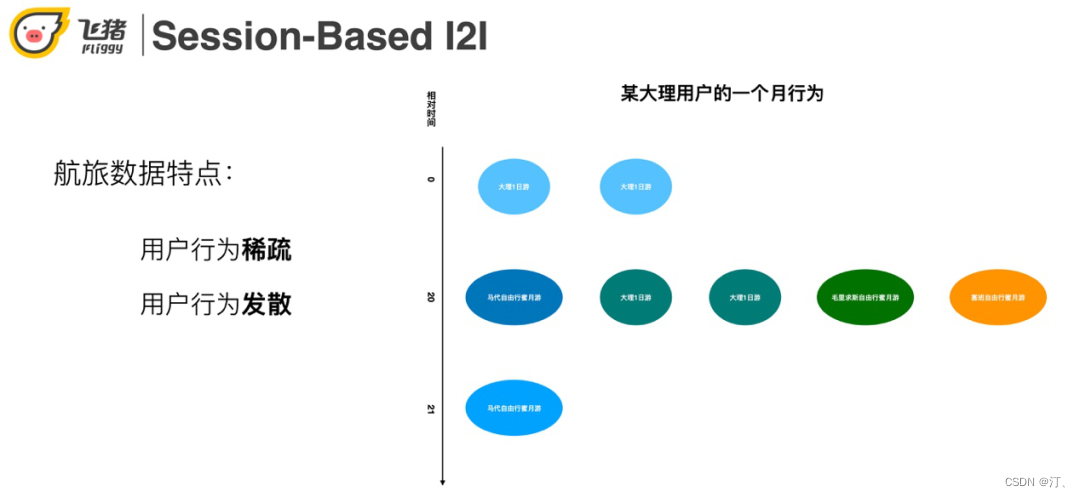
航旅用户的行为有稀疏和发散的特点。利用右图一个具体的用户实例来说明这两个特点:用户在第一天点击了两个大理一日游,第20天点击了一些马尔代夫蜜月相关的商品,第21天又点击了大理的一日游。稀疏性体现在一个月只来了3次,点击了8个宝贝。发散性体现在用户大理一日游和出国蜜月游两个topic感兴趣。
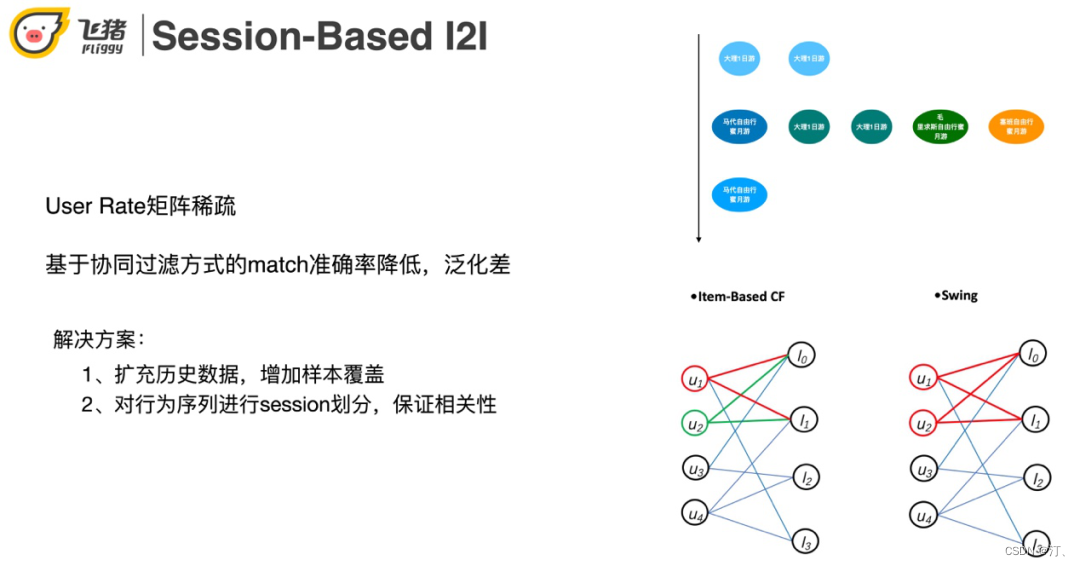
在用户有行为的情况下进行召回,我们常采用的方法是基于User-Rate矩阵的协同过滤方法 ( 如ItemCF,Swing。ItemCF认为同时点击两个商品的用户越多则这两个商品越相似。Swing是在阿里多个业务被验证过非常有效的一种召回方式,它认为user-item-user的结构比itemCF的单边结构更稳定 ),但是由于航旅用户行为稀疏,基于User-Rate矩阵召回结果的准确率比较低,泛化性差。针对这两个问题我们可以通过扩充历史数据来增加样本覆盖。航旅场景因为用户点击数据比较稀疏,需要比电商 ( 淘宝 ) 扩充更多 ( 时间更长 ) 的数据才够。这又带来了兴趣点转移多的问题。在这里我们采用对行为序列进行session划分,保证相关性。
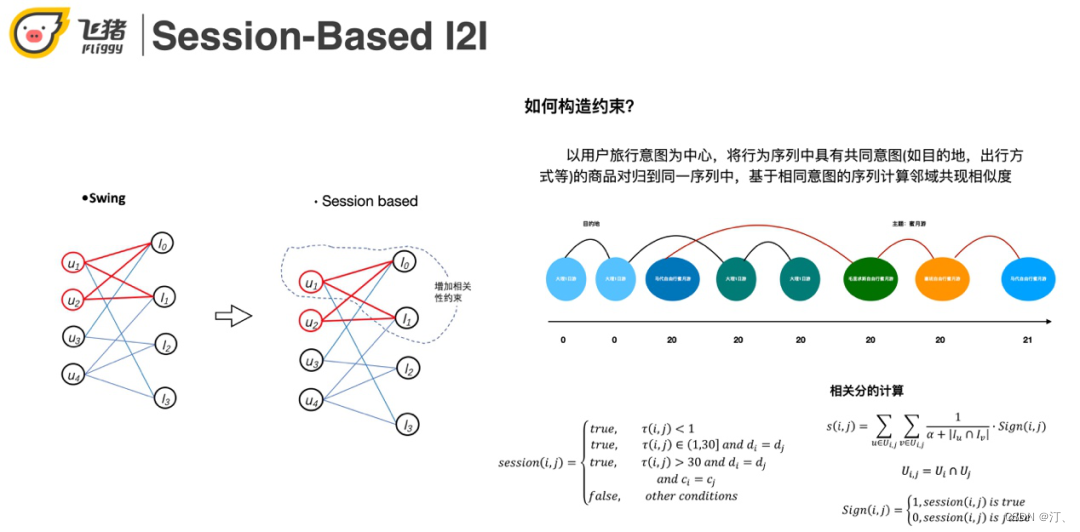
这里以swing为例讲解一下构造约束的方式。我们以用户的行为意图为中心,将表示共同意图的商品聚合在一个序列中,如上图对用户行为序列的切分。
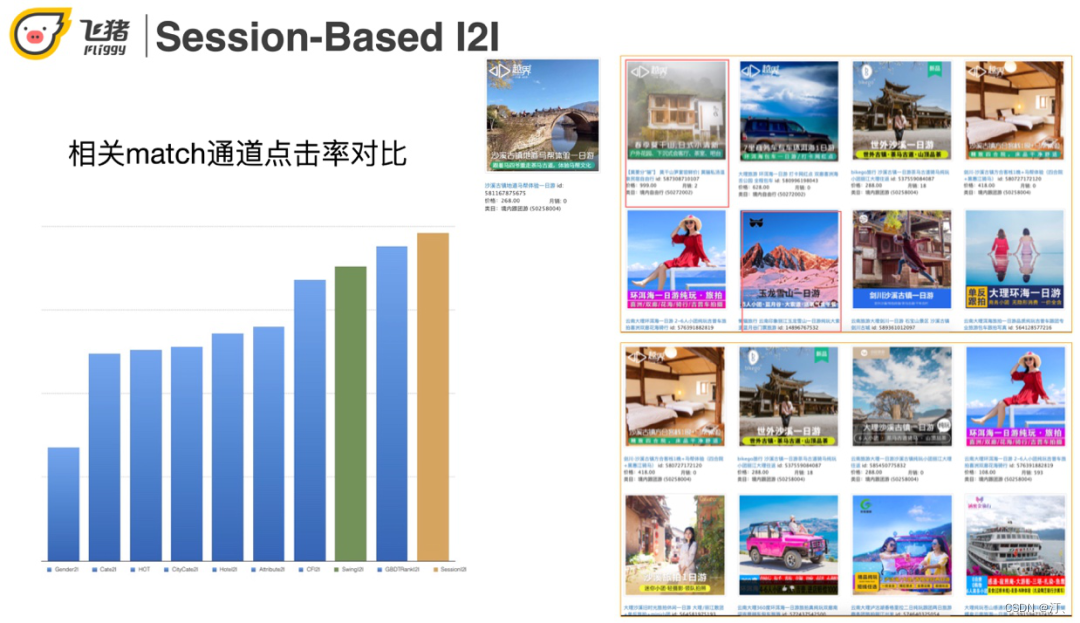
在这个case中,上面是传统swing的召回结果,下面是基于session的召回结果。当trigger是沙溪古镇一日游的时候,上面有一个杭州莫干山和玉龙雪山一日游,这两个不相关结果的出现是因为它们是热门商品,也称哈利波特效应。下面的召回结果就都是和沙溪古镇相关的了。从指标来看,session-based召回比swing和itemCF都高。
2.4.2 Meta-Path Graph Embedding

基于I2I相关矩阵的优点是相关性好,缺点是覆盖率比较低。而Embed的方式虽然新颖性好但是相关性差。右边的case是Embed的召回结果,上海迪士尼乐园召回了一个珠海长隆的企鹅酒店和香港迪士尼。我们期望的应该是在上海具有亲子属性,或者在上海迪士尼附近的景点。
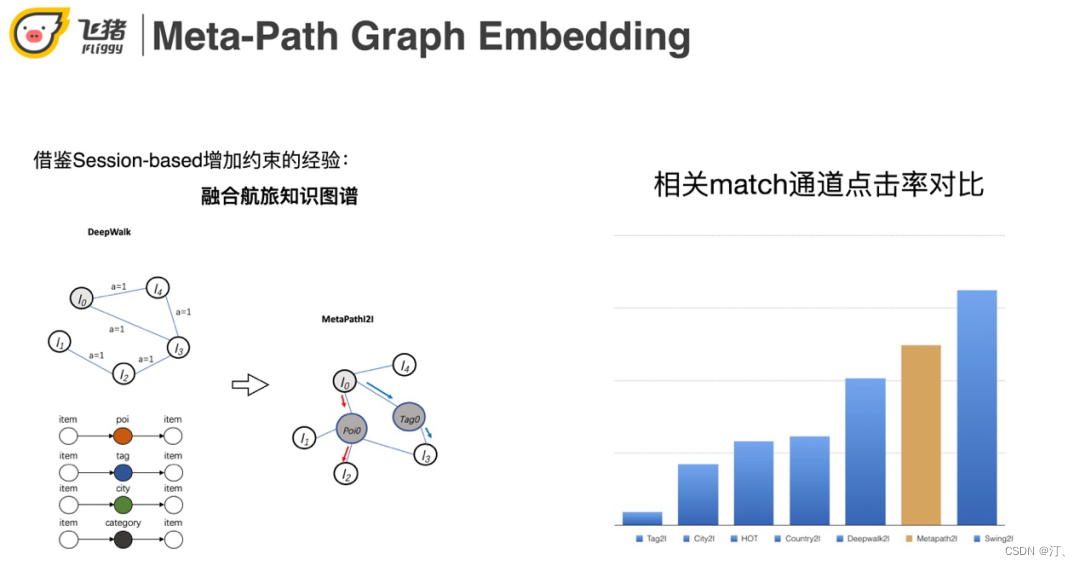
解决Embed相关性低的方式借鉴了session-based召回的经验,将航旅知识图谱融合,构建航旅特定的Meta-Path。效果上看meta-path的效果是比deepwalk更好。
2.5周期性复购的召回
复购场景的需求来自于:飞猪有大量的差旅和回家用户,该部分用户的行为有固定模式,会在特定的时间进行酒店和交通的购买,那么该如何满足这部分用户的需求?
2.5.1 Rebuy2I
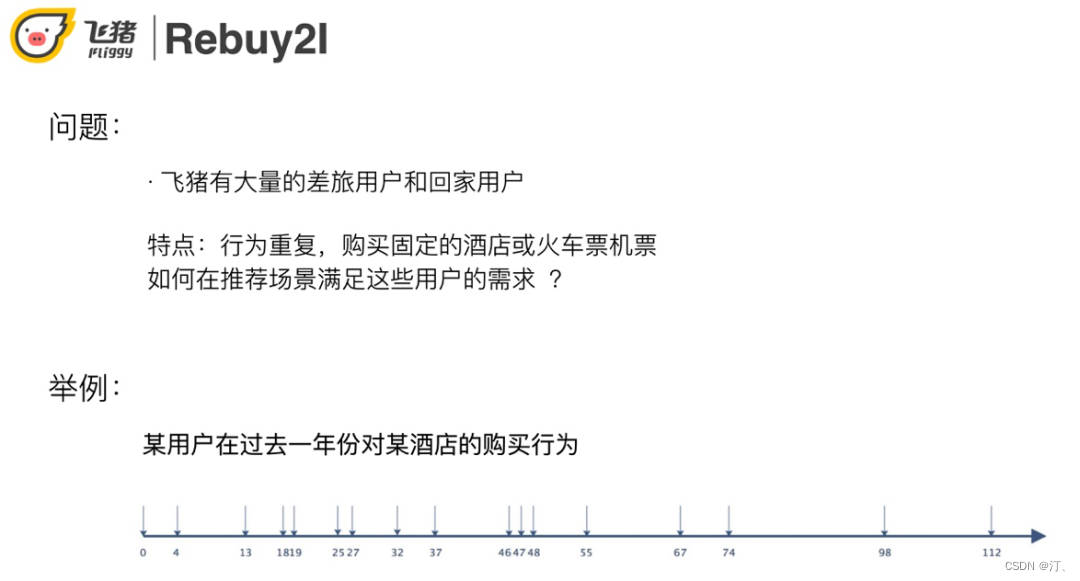
我们的目标是在正确的时间点来给用户推出合适的复购商品,下面以酒店为例具体讲解 ( 其他的品类原理类似 )。

输入用户在飞猪的酒店历史购买数据,输出是用户在某个时间点对某个酒店的复购概率。当有多个可复购酒店时,按照概率降序排序。

常见做法有以下几种:
利用酒店本身的复购概率
基于用户购买历史的Retarget
利用Poission-Gamma分布的统计建模

首先取用户对酒店的购买历史,利用矩估计/参数估计计算酒店的购买频次 ( 参数α和β )。接下来就可以调整每个用户的购买概率,k是购买次数,t是第一次购买距离最近一次购买的时间间隔。最后代入Possion分布计算复购概率,加入用户的平均购买周期来缓解刚刚完成购买的酒店复购概率最大的问题。
从左图可以看出在购买一段时间以后,复购概率达到最大值,之后递减。实际使用中复购单独作为一路召回,效果比前面提到的retarget和热门召回更好。
2.6 总结

最后总结一下做好召回的几个思路:
首先要基于业务场景,来发掘用户需求,发现自有场景的特点。接下来通过case和数据分析来发现问题,通过理解模型结构或者特征背后的动机进行针对性的改进。最后在召回和排序之间找到边界,效果和性能之间做好trade-off。
2.7 Q&A
Q:Journey2i的双塔模型如何负采样,正负比例如何控制?
A:关于召回的负采样是一个非常值得研究的问题。我们也做了很多尝试,例如我们曾经尝试过按照排序的套路用曝光样本做负样本,但是效果很差。然后也进行了全局负采样,效果要明显好于曝光的方式,但是负样本如何采也值得一提,采得太随机,你的负样本容易太easy,模型的auc可能虚高,因此也要新增一些hard的样本,在journey2i中就是那些属于本次行程相关城市目的地的商品,但是用户不太可能购买的商品,具体的方式这里不展开介绍了。Facebook在KDD2020中有篇论文也对召回的采样问题做了详细的介绍,推荐阅读。关于正负比例,我们的经验是没有绝对的答案,需要在优化过程中摸索,不过一般只要抽样方式ok,正负比例的变化不会对最终结果有太大的影响。
Q:Journey2I无法考虑交互特征,是否会有影响?
A:肯定会有影响。理论上讲,没有Journey和target item的交互特征,auc和准确率肯定会打折扣,但是需要针对具体问题具体分析,做召回的优化和排序有个很明显的不同就是需要在性能、准确率、多样性上做trade-off。
Q:meta-path,session-base解决问题和出发点是什么?
A:session-base解决的是扩充稀疏的数据后会带来兴趣发散的问题。举个极端的例子,有个用户每个月都出差,去到不同的地点。召回结果就会混合多个地点。Meta-path解决的是相关性低的问题。
推荐系统[八]算法实践总结V1:淘宝逛逛and阿里飞猪个性化推荐:召回算法实践总结【冷启动召回、复购召回、用户行为召回等算法实战】的更多相关文章
- 计蒜客 淘宝的推荐系统【DP】
题目链接:https://nanti.jisuanke.com/t/26984 ...
- no.2淘宝架构背后——零售业务中台架构设计探讨及实践读后感
2017年8月12日,袋鼠云首席架构师正风在“网易博学实践日:大数据与人工智能技术大会”进行<淘宝架构演进背后——零售业务中台架构设计探讨及实践>演讲分享.传统零售行业如何选择应对新经济模 ...
- (转)从P1到P7——我在淘宝这7年
(一) 2011-12-08 [原文链接] 今天有同事恭喜我,我才知道自己在淘宝已经七周年了.很多人第一句话就是七年痒不痒,老实说,也曾经痒过,但往往都是一痒而过,又投入到水深火热的工作中去.回家之后 ...
- 从P1到P7——我在淘宝这7年(转)
作者: 赵超 发布时间: 2012-02-25 14:47 阅读: 114607 次 推荐: 153 [收藏] (一) 2011-12-08 [原文链接] 今天有同事恭喜我,我才知道自己在淘 ...
- 从P1到P7——我在淘宝这7年 - 子柳撰写
http://kb.cnblogs.com/page/132752/来自博客园的整理版本,作者是子柳,博客地址:http://blog.sina.com.cn/calvinzhaoc (一) 2011 ...
- Python模拟登录淘宝
最近想爬取淘宝的一些商品,但是发现如果要使用搜索等一些功能时基本都需要登录,所以就想出一篇模拟登录淘宝的文章!看了下网上有很多关于模拟登录淘宝,但是基本都是使用scrapy.pyppeteer.sel ...
- selenium五十行代码自动化爬取淘宝
先看一下代码,真的只是五十行: # coding=gbk from selenium import webdriver import time options = webdriver.ChromeOp ...
- 淘宝天猫网站停止支持IE6、IE7浏览器,你还在用xp吗?
2016年4月14日,是科比正式告别篮球的最后一场球赛.大家都在忙着各种纪念和怀念着看科比打球的青葱岁月.不过已经完美谢幕.而我们今天要说的是微软的IE6.IE7浏览器.淘宝网和天猫商城正式停止支持I ...
- 淘宝技术发展(Java时代:脱胎换骨)
我的师父黄裳@岳旭强曾经说过,“好的架构图充满美感”,一个架构好不好,从审美的角度就能看得出来.后来我看了很多系统的架构,发现这个言论基本成立.那么反观淘宝前面的两个版本的架构,你看哪个比较美? 显然 ...
- 淘宝IP地址库API接口(PHP)通过ip获取地址信息
淘宝IP地址库网址:http://ip.taobao.com/ 提供的服务包括: 1. 根据用户提供的IP地址,快速查询出该IP地址所在的地理信息和地理相关的信息,包括国家.省.市和运营商. 2. 用 ...
随机推荐
- Spring Security(7)
您好,我是湘王,这是我的博客园,欢迎您来,欢迎您再来- 有时某些业务或者功能,需要在用户请求到来之前就进行一些判断或执行某些动作,就像在Servlet中的FilterChain过滤器所做的那样,Spr ...
- 3.7:基于Weka的K-means聚类的算法示例
〇.目标 1.使用Weka平台,并在该平台使用数据导入.可视化等基本操作: 2.对K-means算法的不同初始k值进行比较,对比结果得出结论. 一.打开Weka3.8并导入数据 二.导入数据 三.Si ...
- docker入门(利用docker部署web应用)
第一章 什么是docker1.1 docker的发展史2010年几个年轻人成立了一个做PAAS平台的公司dotCloud.起初公司发展的不错,不但拿到过一些融资,还获得了美国著名孵化器YCombina ...
- 进击的K8S:Kubernetes基础概念
Kubernetes简介 Kubernetes简称K8S(因为k和s中间有8个字母),是一个开源的容器集群管理平台,基于Go语言编写. 使用K8S,将简化分布式系统上的容器应用部署,使得开发人员可以专 ...
- 一文带你入木三分地理解字符串KMP算法(next指针解法)
1. KMP算法简介 温馨提示:在通篇阅读完并理解后再看简介效果更佳 以下简介由百度百科提供https://baike.baidu.com/item/KMP%E7%AE%97%E6%B3%95/109 ...
- jQuery事件与动态效果
目录 一:阻止后续事件执行 1.推荐使用阻止事件 2.未使用 阻止后续事件执行 3.使用阻止后续事件执行 二:阻止事件冒泡 1.什么是事件冒泡? 2.未阻止事件冒泡 3.阻止事件冒泡 4.2.阻止冒泡 ...
- 微服务组件-----Spring Cloud Alibaba 注册中心Nacos的CP架构Raft协议分析
前言 本篇幅是继 注册中心Nacos源码分析 的下半部分. 意义 [1]虽说大部分我们采用注册中心的时候考虑的都是AP架构,为什么呢?因为性能相对于CP架构来说更高,需要等待的时间更少[相对于CP架 ...
- 跟光磊学Java-Windows版Java8开发环境搭建
Java语言核心技术 如果想要开发Java程序/Java项目之前,必须要安装和配置JDK,这里的JDK表示Java8\JDK8,不过下载软件的时候,强烈推荐大家一定要去软件的官网下载,因为官网提供的软 ...
- LFU 的设计与实现
LFU 的设计与实现 作者:Grey 原文地址: 博客园:LFU 的设计与实现 CSDN:LFU 的设计与实现 题目描述 LFU(least frequently used).即最不经常使用页置换算法 ...
- 学习ASP.NET Core Blazor编程系列二十——文件上传(完)
学习ASP.NET Core Blazor编程系列文章之目录 学习ASP.NET Core Blazor编程系列一--综述 学习ASP.NET Core Blazor编程系列二--第一个Blazor应 ...