SpringCloud Sleuth链路追踪
1、概要
一般的,一个分布式服务跟踪系统,主要有三部分:
- 数据收集
- 数据存储
- 数据展示
然而这三个部分其实不都是由SpringCloud Sleuth(下面我简称为Sleuth)完成的,Sleuth负责数据的收集,而数据的存储和数据的展示由Zipkin完成
首先我们需要搞清楚,链路追踪功能由Sleuth(数据收集),Zipkin(数据存储、数据展示)这两个组件组合完成的。
下面我们对它们分别介绍
2、Sleuth
①产生原因
在微服务框架中,一个客户端的请求在后端系统中会经过多个不同的服务节点调用来协同产生最后的请求结果,每一个前端请求都会产生一个复杂的服务调用链路,链路中的任何一环出现高延迟或错误都会导致请求的失败
Springcloud考虑到这个问题,Sleuth即为长链路调用的链路跟踪监控组件
②简介
SpringCloud Sleuth官网:Spring Cloud Sleuth
这是SpringCloud Sleuth的概念图:
trace:一次完整的请求,从服务开始到执行完成
span:在一次trace中,每调用一个服务就会记录调用的信息和响应时间,这就是一个span
下图中,Trace全为X表示一次调用,其中每个服务调用都有一个span,不同服务调用span不同。
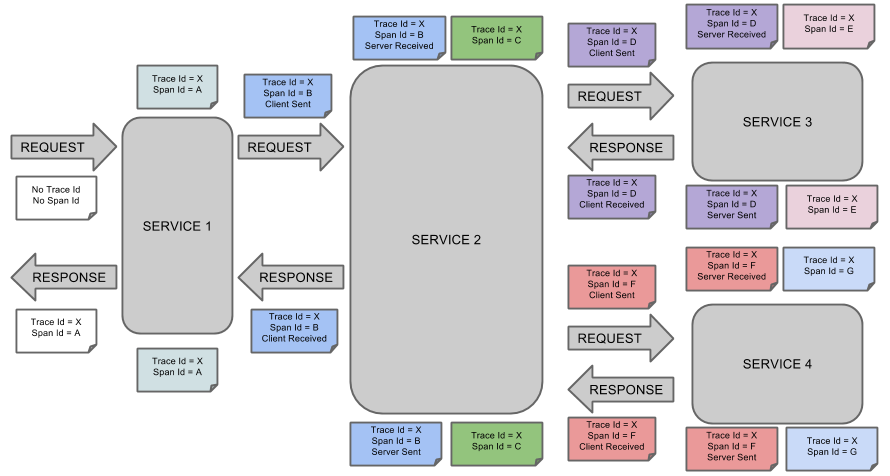
可见sleuth能够通过trace和span,追踪到一次调用经过了哪些服务,每个服务的耗费时间
3、Zipkin
①简介
Zipkin是一个开源的追踪系统,它负责收集,存储数据并展示给用户
这里说Zipkin的收集不同于Sleuth的收集,Sleuth是通过监控来实现信息的收集,而Zipkin的收集是将Sleuth采集的数据进行接收。
官网也表达的很清楚:
本文中,Sleuth负责数据的收集,Zipkin负责存储和展示
Zipkin提供了不同的数据存储方式:
- Merory(内存存储)
- Mysql(关系型数据库)
- Cassandra(非关系型数据库ps本人还没有接触过)
- Elasticsearch
4、搭建
①安装zipkin
下载地址:
运行:
java -jar zipkin-server-2.12.9-exec.jar
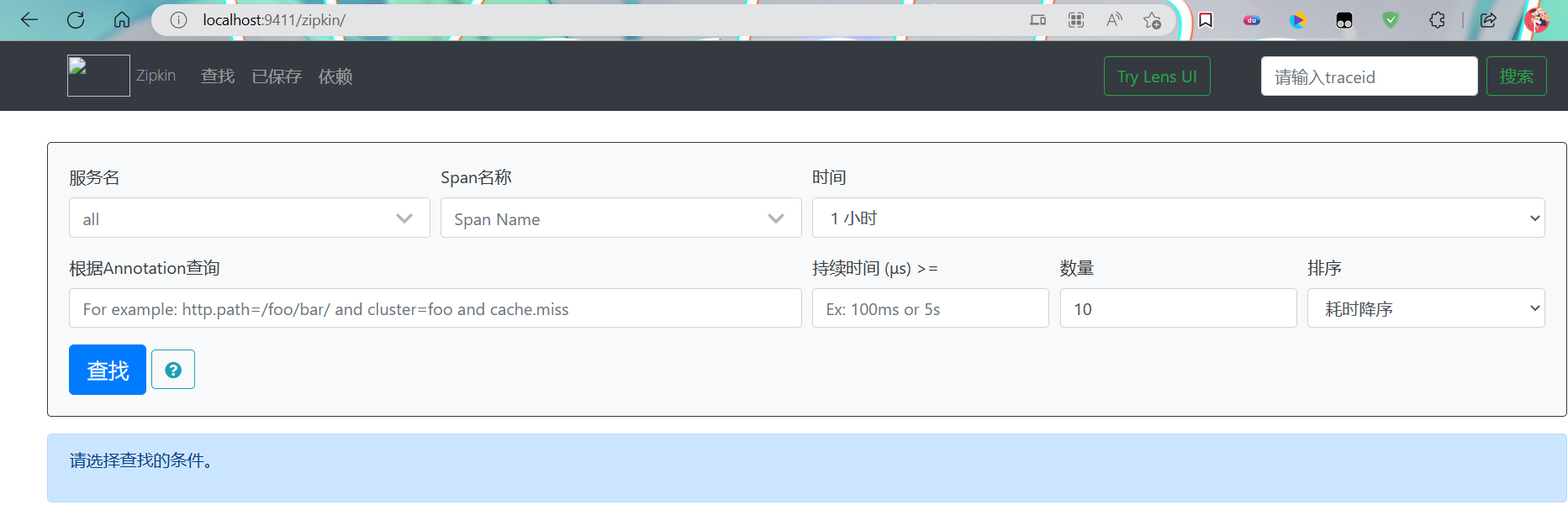
进入控制台:
http://localhost:9411/zipkin/
②Provider
在之前的工程cloud-provider-payment8001上进行修改
添加依赖:
<!--包含了sleuth+zipkin-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-zipkin</artifactId>
</dependency>
添加配置:
spring:
zipkin:
base-url: http://localhost:9411 #zipkin Server的地址
sleuth:
sampler:
probability: 1 #采样率值介于0到1之间,1则表示全部采集(一般不为1,不然高并发性能会有影响)
在Controller中添加方法:
@GetMapping("/payment/zipkin")
public String paymentZipkin(){
return "paymentZipkin...";
}
③Consumer
在之前的工程cloud-consumer-order80(服务消费者)上进行更改
添加依赖:
<!--包含了sleuth+zipkin-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-zipkin</artifactId>
</dependency>
添加配置:
spring:
zipkin:
base-url: http://localhost:9411 #zipkin Server的地址
sleuth:
sampler:
probability: 1 #采样率值介于0到1之间,1则表示全部采集(一般不为1,不然高并发性能会有影响)
在Controller中添加方法:
@GetMapping("/consumer/payment/zipkin")
public String paymentZipkin(){
String result = restTemplate.getForObject("http://localhost:8001" + "/payment/zipkin", String.class);
return result;
}
④测试
前面已经启动了zipkin Server了
启动Eureka注册中心7001,Order80,Payment8001
调用Order接口,Order接口调用了Payment的接口:
http://localhost/consumer/payment/zipkin
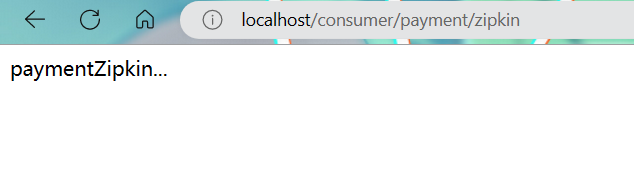
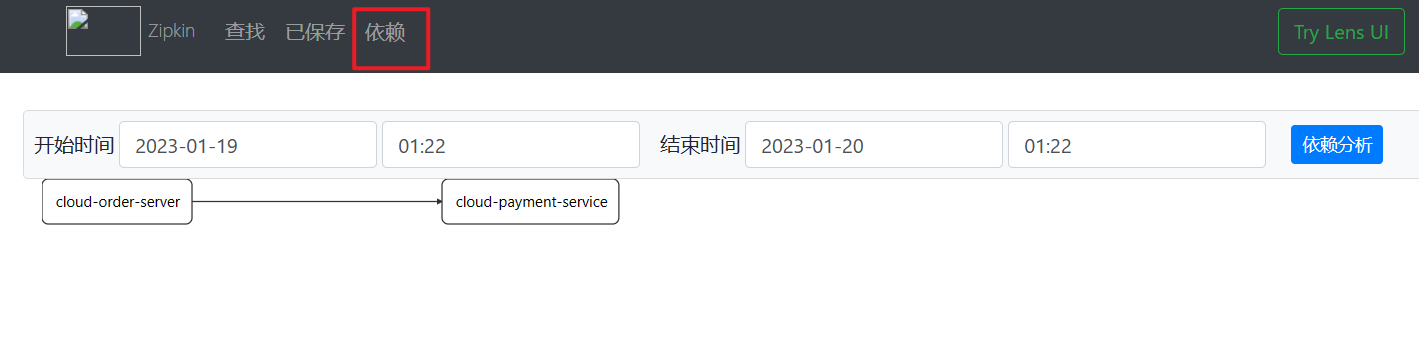
进入Zipkin面板查看:
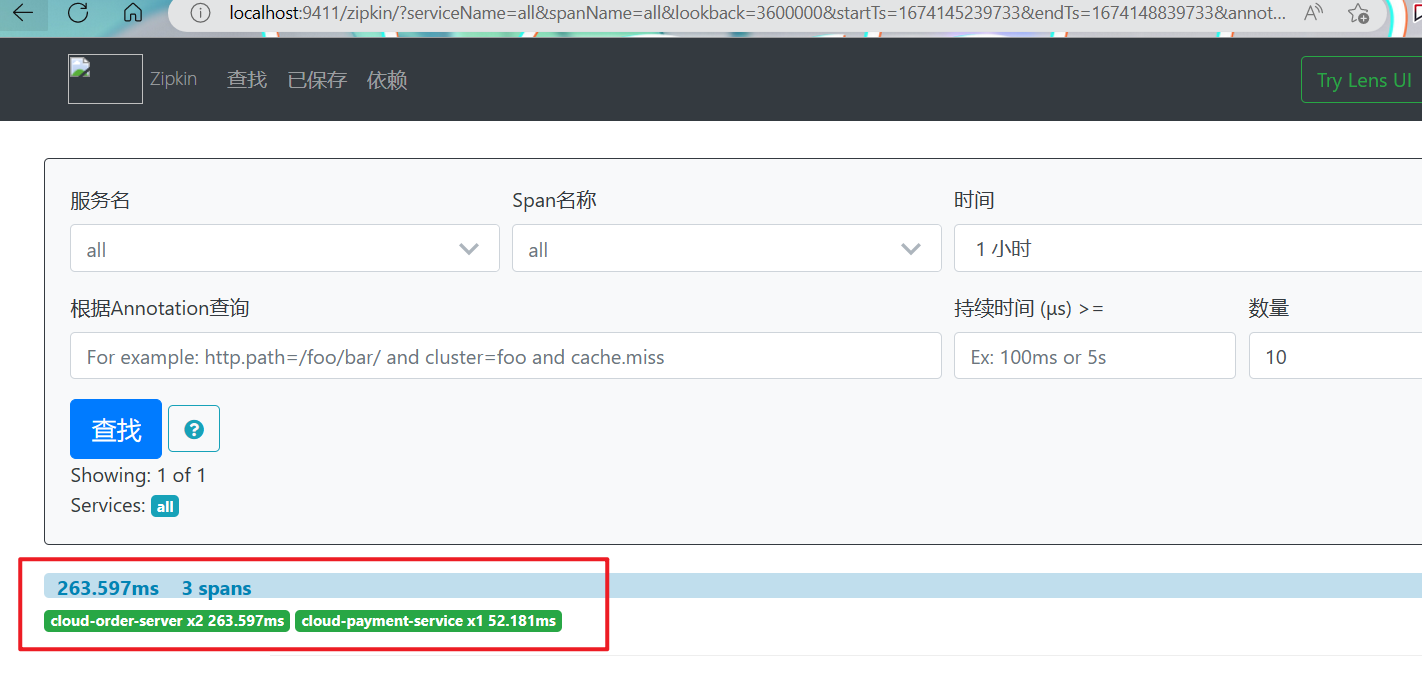
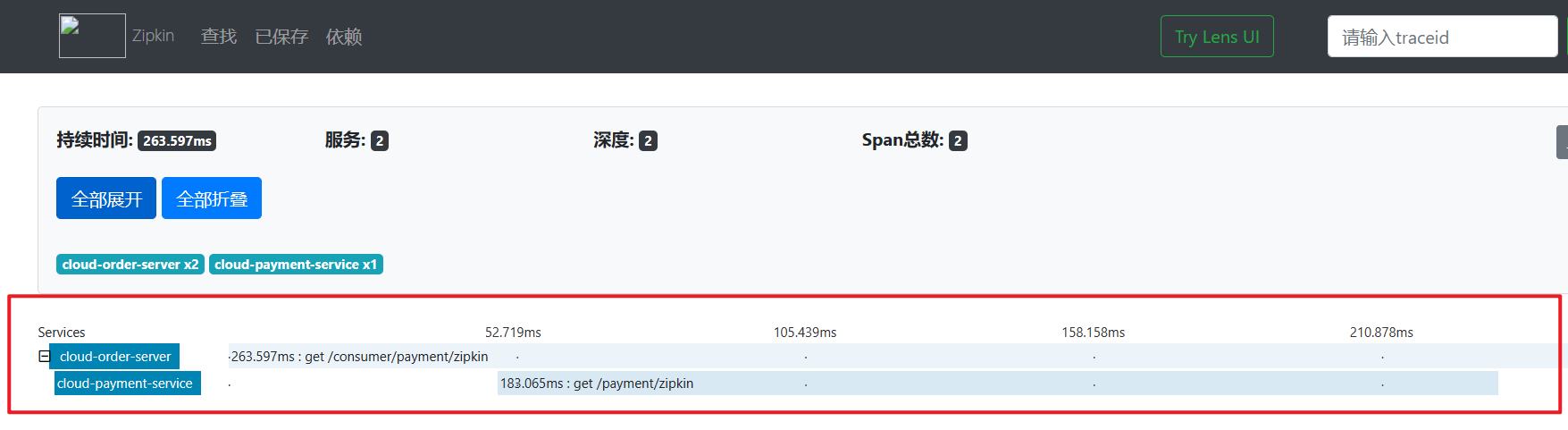
查看服务依赖:
SpringCloud Sleuth链路追踪的更多相关文章
- Spring Cloud 系列之 Sleuth 链路追踪(二)
本篇文章为系列文章,未读第一集的同学请猛戳这里:Spring Cloud 系列之 Sleuth 链路追踪(一) 本篇文章讲解 Sleuth 基于 Zipkin 存储链路追踪数据至 MySQL,Elas ...
- Spring Cloud 系列之 Sleuth 链路追踪(三)
本篇文章为系列文章,未读前几集的同学请猛戳这里: Spring Cloud 系列之 Sleuth 链路追踪(一) Spring Cloud 系列之 Sleuth 链路追踪(二) 本篇文章讲解 Sleu ...
- Spring-Cloud之Sleuth链路追踪-8
一.Spring Cloud Sleuth 是Spring Cloud 的一个组件,它的主要功能是在分布式系统中提供服务链路追踪的解决方案. 二.为什么需要Spring Cloud Sleuth? 微 ...
- SpringCloud之链路追踪整合Sleuth(十三)
前言 SpringCloud 是微服务中的翘楚,最佳的落地方案. 在一个完整的微服务架构项目中,服务之间的调用是很复杂的,当其中某一个服务出现了问题或者访问超时,很 难直接确定是由哪个服务引起的,所以 ...
- SpringCloud(七)之SpringCloud的链路追踪组件Sleuth实战,以及 zipkin 的部署和使用
一.前言 Spring Cloud Sleuth 主要功能就是在分布式系统中提供追踪解决方案 ,并且兼容了zipkin,提供了REST API接口来辅助我们查询跟踪数据以实现对分布式系统的监控程序 . ...
- Zipkin+Sleuth 链路追踪整合
1.Zipkin 是一个开放源代码分布式的跟踪系统 它可以帮助收集服务的时间数据,以解决微服务架构中的延迟问题,包括数据的收集.存储.查找和展现 每个服务向zipkin报告计时数据,zipkin会根据 ...
- Spring Cloud 系列之 Sleuth 链路追踪(一)
随着微服务架构的流行,服务按照不同的维度进行拆分,一次请求往往需要涉及到多个服务.互联网应用构建在不同的软件模块集上,这些软件模块,有可能是由不同的团队开发.可能使用不同的编程语言来实现.有可能布在了 ...
- 十一、springcloud之链路追踪Sleuth
一.背景 随着微服务的数量增长,一个业务接口涉及到多个微服务的交互,在出错的情况下怎么能够快速的定位错误 二.简介 Spring Cloud Sleuth 主要功能就是在分布式系统中提供追踪解决方案, ...
- 学习一下 SpringCloud (五)-- 配置中心 Config、消息总线 Bus、链路追踪 Sleuth、配置中心 Nacos
(1) 相关博文地址: 学习一下 SpringCloud (一)-- 从单体架构到微服务架构.代码拆分(maven 聚合): https://www.cnblogs.com/l-y-h/p/14105 ...
- 分布式链路追踪系统Sleuth和ZipKin
1.微服务下的链路追踪讲解和重要性 简介:讲解什么是分布式链路追踪系统,及使用好处 进行日志埋点,各微服务追踪. 2.SpringCloud的链路追踪组件Sleuth 1.官方文档 http://cl ...
随机推荐
- HTTPS详解二
前言 在上篇文章中,我已经为大家介绍了 HTTPS 的详细原理和通信流程,但总感觉少了点什么,应该是少了对安全层的针对性介绍,那么这篇文章就算是对HTTPS 详解一的补充吧.还记得这张图吧. HTTP ...
- .NET 6使用ImageSharp给图片添加水印
.NET 6 中,使用System.Drawing操作图片,生成解决方案或打包的时候,会有警告,意思是System.Drawing仅在 'windows' 上受支持.微软官方的解释是: Syste ...
- 【数据库】Postgresql/PG-编写函数实现字段对应加备注
〇.资料链接 一.背景 构建分区表时,删除了表的字段备注信息 1.查询语句 select c.relname 表名, cast ( obj_description (relfilenode, 'pg_ ...
- 【Java SE】Day04 IDEA、方法*
一.IDEA 1.快捷键 Ctrl+Alt+L/Ctrl+Alt+Shift+4:格式化代码 Alt+Insert:自动生成代码 修改快捷键:File->Settings->keymap- ...
- 【面试题总结】JVM02:JVM参数调优、类加载机制
四.JVM参数调优 1.调优工具 (1)jvisualvm:jdk提供的性能分析工具,可以监控java进程,对dump文件分析:查看应用程序的详细信息,针对不同插件,实现监控GC过程.内存.进程.线程 ...
- [数据结构]哈希拉链法化解冲突+ASL计算
看这篇就好(自用,别骂我) 摘自博客园 存疑:学校考试空节点算不算查找次数???
- xshell+Xftp下载
1.XShell免费官方网站下载地址:https://www.netsarang.com/zh/all-downloads/ 但是官网的地址贼慢,用以下方法下载 2.可以用这个下(写着中文官网):ht ...
- MySQL字符编码、存储引擎、严格模式、字段类型之浮点 字符串 枚举与集合 日期类型
目录 字符编码与配置文件 数据路储存引擎 创建表的完整语法 字段类型之整型 严格模式 字段类型之浮点型 字段类型之字符串类型 数字的含义 字段类型之枚举与集合 字段类型之日期类型 字符编码与配置文件 ...
- md5-有道翻译
网站 aHR0cHMlM0EvL2ZhbnlpLnlvdWRhby5jb20v 测试发现三个值是变化的 一.第一种方法 initiator一步一步找,在t.translate中找到以下内容 这里可以看 ...
- 学习.NET MAUI Blazor(二)、MAUI是个啥
随着.NET 7的发布,MAUI也正式发布了.那么MAUI是个啥?我们先来看看官方解释: .NET 多平台应用 UI (.NET MAUI) 是一个跨平台框架,用于使用 C# 和 XAML 创建本机移 ...