【论文笔记】Federated Learning for Wireless Communications: Motivation, Opportunities, and Challenges(综述)
Federated Learning for Wireless Communications: Motivation, Opportunities, and Challenges
| Authors | Solmaz Niknam, Harpreet S. Dhillon, Jeffrey H. Reed |
|---|---|
| Keywords | |
| Abstract | 本文介绍了FL的总体思路,讨论了在5G网络中可能的应用,描述了无线通信环境中的关键技术挑战与关于未来研究的开放性问题。 |
| Publication | DATA SCIENCE AND ARTIFICIAL INTELLIGENCE FOR COMMUNICATIONS 2020 |
| DOI | 10.1109/MCOM.001.1900461 |
1 INTRODUCTION
对于无线通信,采用ML进行系统设计和分析尤其具有吸引力,因为传统模型驱动的方法不够丰富以应对现代无线网络不断增长的复杂度与异构性。单独利用数据分析(例如被使用在模型驱动的通信系统设计中)的一种替代选择是使用大量数据学习模型,以期实现一个无线系统设计的完整的范式转换。
在无线网络环境下,数据分散在数以十亿计的设备上,传统的集中式ML方案已经不适合于这种情况,因为对数据隐私的要求已经不太可能将隐私数据集中到一起。
分散式ML将数据一直保留在设备本地,在本地做训练,只需要传输一些感兴趣的特征而非原始数据流,大大减少了网络带宽与电量的消耗。并且促进该方法发展的另一个动力在于它能够很好地应对延迟敏感应用的实时事务。
联邦学习(Federated Learning)是一个新兴的分散式方法,尤其针对上述挑战,包括隐私与资源限制。
2 前言与总览
尽管FL的做法本来就比直接分享原始数据对隐私保护得更好,但是由于本地学习者通过传输加密后的模型到聚合器加入了一个额外的保护层(layer),一些模型可能仍然会泄露隐藏信息。
作为安全多方计算的一类,一种安全的聚合算法被用于聚合加密的模型,它无需对上传的加密模型进行解密就可以完成模型聚合[7]。FL概念的一种描述如下图所示。
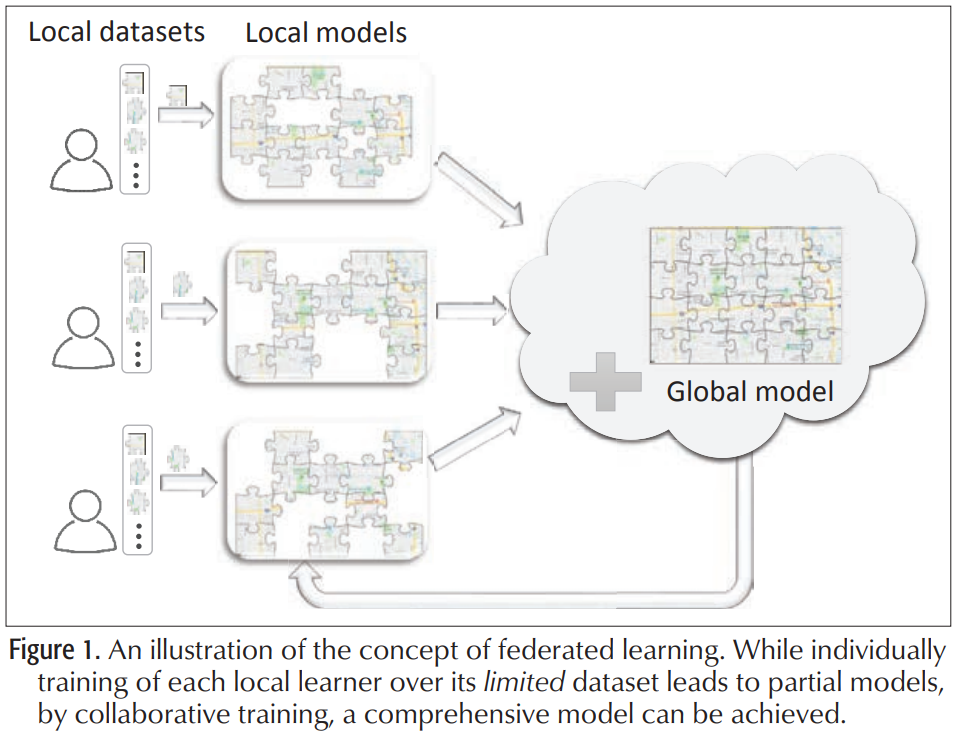
许多重要的方面使得FL区别于现存的分布式学习(Distributed Learning)方案,其中一个就是:分布式学习方案都是各学习者的数据都服从IID的随机变量的实现;FL环境下,不同的学习者可能会观察过程的不同部分(它们之间可能有重叠),因此生成的数据不能代表所有数据的分布,本地学习者的数据是Non-IID的。例如,可以考虑为自动驾驶构建高分辨率(HD)地图的任务,其中自动驾驶车辆仅收集与它们所经过路线相关的位置和传感信息,或者在手写数字识别任务中,本地学习者具有不同数字的样本。
其次,数据集的大小不平衡。例如,在HD地图示例中,由于不同的自动驾驶车辆所经过的环境不同,在不同的自动驾驶车辆上收集的数据集可能大小不同。最后,数据集大量分布在本地学习者之间,每个本地学习者的数据样本数量小于参与训练的学习者总数。
数据集的这些显著特征(即Non-IID、分布式和不平衡的训练数据)将联邦ML框架与其他相关方法区分开来,下文将对此进行讨论。
分布式学习(Distributed Learning)
该方案中,聚合器收集设备本地训练的模型,以提供对所研究参数的整体和更准确的估计,但设备本地并不需要通过聚合器的任何反馈来获取全局模型。
并行学习(Parallel Learning)
并行学习的主要目标是拓展算法规模、加速学习过程,或者二者兼而有之。在这种类型的学习中,中央参数服务器上的可用训练集被划分为子集,分配给一组工作机器,因此分配给每台工作机器的数据集具有相同的底层分布,随后,并行执行训练过程,并将参数反馈给参数服务器。
这种类型的学习是在数据中心执行的,工作机器从共享存储中获取数据,因此,与FL不同,最终将拥有来自同一分布的样本。此外,每个工作者的平均数据样本数远大于参与训练过程的工作者数,这与数据大规模分布的联邦环境不同。
分布式集成学习(Distributed Ensemble Learning)
也被称作Committee-based Learning,是一种多个学习者(例如:分类器、回归器)结合起来协作改善整体表现的学习方式。该方案中,数据集的不同部分被分配去训练不同的模型,然后对这些模型进行汇总,以降低选择不佳模型的可能性。
一般来说,这种学习方法的目标是从模型的混合中学习,而不是通过具有通信约束的本地学习者联邦、使用自然分布的数据集改进全局模型。
3 无线通信中FL应用
3.1 边缘计算与缓存
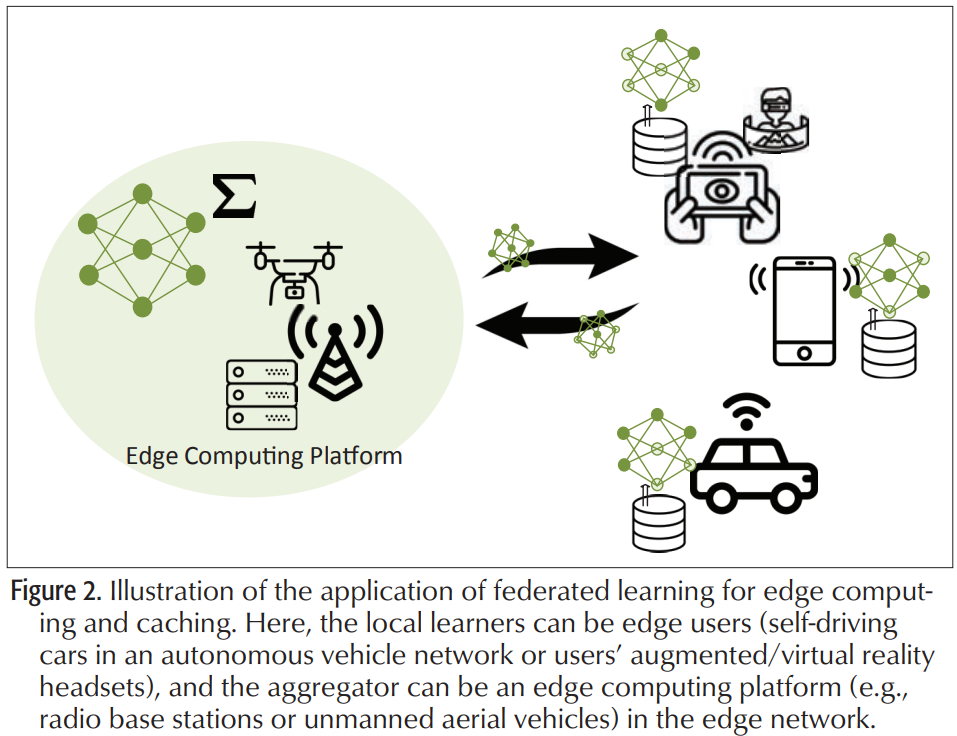
在无线网络边缘进行内容缓存和数据计算是减少回程流量负载的一种很有前途的方法。总体思路是让流行内容更接近边缘终端,即小型基站(SBS)和接入点(基础设施缓存)甚至用户设备(无基础设施缓存),以便可以方便地在本地访问。
这种模式有可能实现具有严格延迟和带宽要求的应用程序,这种体系结构的成功依赖于精确地确定每个缓存中应该放置哪些内容。文献中通常采用的方法是利用静态或动态统计模型进行内容流行度识别。然而,模型驱动的内容流行度识别无法考虑影响内容流行度的众多因素。此外,直接访问对隐私敏感的用户数据以进行内容区分在实践中可能是不可能的。在利用本地训练的模型而不是直接访问用户数据的前提下,联邦学习似乎是无线网络主动缓存中内容流行度预测的绝佳匹配(下图所示)。
- 例如,在AR中,联邦学习可以用于从其他用户那里学习某些流行的增强元素,而无需直接获取他们的隐私敏感数据。然后预取这些流行信息并在本地存储,以减少延迟。
- 此外,在自动驾驶汽车中,可以使用联邦学习通过其他车辆学习与交通有关的信息,并将其预缓存在路边单元中。
3.2 频谱管理
在未来的5G网络中,为了实现关键的5G垂直市场,需要一个低频和高频(即微波和毫米波频段)的混合频谱环境,以及不同类型的许可。混合频谱接入需要协作和更自主的频谱共享策略,以适应5G网络中的环境和应用。然而,以分布式方式动态访问频谱是复杂的。可能需要所有收音机的高分辨率频谱利用率数据,由于隐私问题,这些数据可能不容易共享。事实上,所有无线电设备都需要共享其感知数据,如频谱占用数据、设备非线性信息,以及异常信号(如干扰)的检测。然而,这些数据对隐私敏感,收音机可能不愿意发送与其工作频率相关的信息。此外,在频谱访问数据库中收集频谱使用信息的集中式策略可能并不总是合适的。此外,对如此庞大的数据进行推断需要巨大的处理能力和大规模优化,这在计算上是不允许的。
FL(每个无线电传输其本地频谱利用模型)可以用来解决这些问题。聚合器利用本地频谱利用模型参数来更新全局模型,该模型最终反馈给各个无线电设备,用于频谱接入决策。值得注意的是,同样的策略也可用于促进两个无线系统的共存。
- 当前人们感兴趣的一个特定环境是,专用短程通信(DSRC)和蜂窝连接车辆在同一智能交通系统(ITS)频段内与所有设备(c-V2X)共存,这可以从这种解决方案中受益。
3.3 5G核心网络
网络数据分析功能(NWDAF)是3GPP定义的一种新的网络功能,旨在为支持ML的功能提供更多的数据挖掘能力,即使在核心网络中也是如此。它提供了在网络管理系统中使用智能技术的能力。这使运营商能够自动化网络管理和配置任务,从而通过减少人机交互降低运营支出。通常,NWDAF能够连接到任何网络功能(NF)并利用核心网络中的任何数据(下图所示)。此外,任何NF都可以请求网络分析信息。
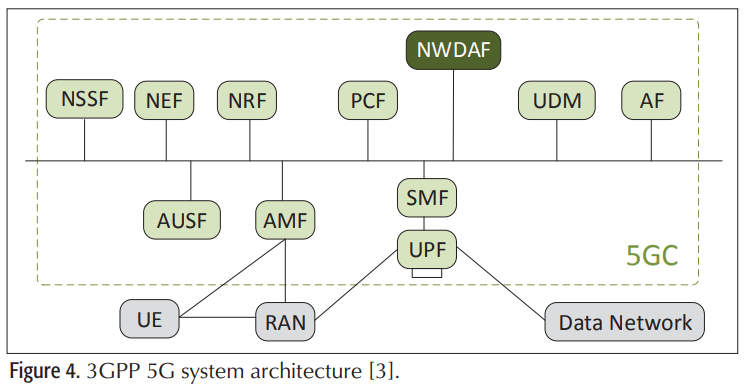
[8]在本地学习者联邦的基础上,为纵向分割的数据集引入了纵向FL,在特征空间中考虑了Non-IID、不平衡和大规模分布的数据集等特性,纵向FL最适合核心网络结构。
例如,访问移动性管理功能(AMF)和会话管理功能(SMF)分别管理移动性和会话建立(IP地址分配、流量路由等)。在这里,NWDAF可以充当处理用户数据聚合的全局节点。用户的数据集在核心网络中的不同实体上垂直分割,每个实体保留与所有用户相关的特定数据特征的记录。通过使用纵向联邦学习,核心网络中的每个实体将其由本地收集的数据特征训练的本地加密模型传输给NWDAF实体,而不是将原始数据发送给NWDAF实体。这可以显著缓解网络功能虚拟化(NFV)引入的网络拓扑中的大规模网络安全漏洞。
4 挑战与未来方向
4.1 安全与隐私挑战及考虑
- [7]提出了一种安全的聚合算法,无需解密就可以聚合加密的模型。然而,一个特定的本地学习者的参与仍然可以通过分析全局模型被揭露[10]。
- [11]提出了差异私有联合算法,以在本地学习者级别提供隐私,而不是保护单个数据样本。然而,这些算法牺牲了模型的性能,或者需要额外的计算和特定数量的本地学习者来参与模型训练。
- 一些神经网络模型可能会无意中记住训练数据的独特方面[12]。
与其他ML方法类似,在联邦学习中,本地模型通常由新收集的数据重新训练,以反映训练模型上的变化。因此,对手可以通过嵌入精心设计的样本数据毒害联邦学习过程,秘密地影响本地训练数据集,从而操纵模型的结果。它甚至可以通过发送梯度更新来执行模型中毒攻击来威胁模型。联邦学习已经通过对抗的视角进行了分析,以检查学习过程对模型中毒对手的脆弱性[13]。由于主要形式的联邦学习易受此类对抗性攻击的影响,因此迫切需要一种防御机制。此外,好奇的聚合器甚至本地学习者都可以对其他本地学习者执行成员推理攻击。在推理攻击中,攻击者的目标是推断特定数据点是否属于训练数据集[14]。模型参数的重复更新是提高成员身份攻击准确性的关键因素。存在各种类型的推理攻击,例如参数推理、输入推理和属性推理攻击,这些攻击可能会危害本地学习者的隐私。因此,还应该研究联邦学习对这些攻击的脆弱性以及相应的防御机制。
4.2 关于算法的挑战与考虑
与几乎所有分散式算法相似,联邦学习的必要考虑之一是受限的通信与计算资源下算法的收敛。
- [15]对基于梯度下降的凸损失函数联邦学习的收敛范围进行了理论分析。
对算法收敛于非凸损失函数的情况进行分析评估也是有益的,在包括深度神经网络在内的一些模型中,模型的自然目标是学习非凸函数。
此外,参与全局更新的本地学习者的最佳数量、本地学习者的分组、本地更新和全局聚合的频率等因素(这些因素导致模型性能和资源保存之间的权衡)依赖于应用程序,值得研究。此外,对于联邦深度神经网络(federated deep neural Network)等一些模型,即使对于物联网(IoT)节点等低功耗设备,更新的规模也可能很大。因此,稀疏和压缩模型参数的方法在计算上是有效的,并减少了资源消耗。
4.3 无线环境中的挑战与考虑
由于无线信道的容量有限,信息在通过信道发送之前需要进行量化。由于本地学习者和聚合器需要通过无线信道交换模型参数,这将产生参数量化的联合学习范式。在这种范式中,一个重要的考虑因素是模型在存在量化误差时的鲁棒性。除了通信带宽外,噪声和干扰也是加剧信道瓶颈的其他因素,还应考虑对这些通道效应的鲁棒性。
另一个重要的考虑因素是收敛时间。聚合时间联邦学习不仅包括本地学习者和聚合器的计算时间,还包括它们之间的通信时间,这取决于无线信道质量。因此,在优化本地更新和全局聚合的频率时,应该考虑无线信道质量。
此外,在学习深层模型时,可以使用模型压缩技术和稀疏训练方法来降低模型的复杂度并缩小模型参数。这些方法对于处理能力有限的设备学习深度模型非常有用。因此,在降低复杂性和保持模型的准确性之间需要权衡。在无线应用的联合深度学习中,模型优化还应考虑无线信道的通信成本和质量。此外,鉴于无线信道的时变特性,可以根据无线信道的质量以自适应方式进行模型压缩。
除了设备的可用性及其参与学习过程的意愿外,全球聚合器和特定本地学习者之间的无线信道的质量也将影响其选择训练,并应与其他因素一起考虑。可能存在这样的情况:特定设备愿意参与,但其相应的无线信道不足以以预定质量传输模型参数,这可能会降低全局模型的准确性。
5 结语
本文讨论了FL在解决主要与5G模式有关的无线通信中的一些挑战方面的作用。我们首先介绍FL的概念及其显著特征,然后,我们介绍了5G网络中FL的几个用例,从边缘到核心网络。还讨论了许多需要在这方面进一步研究的问题和公开挑战。
【论文笔记】Federated Learning for Wireless Communications: Motivation, Opportunities, and Challenges(综述)的更多相关文章
- 【论文笔记】Learning Fashion Compatibility with Bidirectional LSTMs
论文:<Learning Fashion Compatibility with Bidirectional LSTMs> 论文地址:https://arxiv.org/abs/1707.0 ...
- 论文笔记: Deep Learning based Recommender System: A Survey and New Perspectives
(聊两句,突然记起来以前一个学长说的看论文要能够把论文的亮点挖掘出来,合理的进行概括23333) 传统的推荐系统方法获取的user-item关系并不能获取其中非线性以及非平凡的信息,获取非线性以及非平 ...
- 论文笔记:Learning wrapped guidance for blind face restoration
这篇论文主要是讲人脸修复的,所谓人脸修复,其实就是将低清的,或者经过压缩等操作的人脸图像进行高清复原.这可以近似为针对人脸的图像修复工作.在图像修复中,我们都会假设退化的图像是高清图像经过某种函数映射 ...
- 论文笔记: Mutual Learning to Adapt for Joint Human Parsing and Pose Estimation
Mutual Learning to Adapt for Joint Human Parsing and Pose Estimation 2018-11-03 09:58:58 Paper: http ...
- 论文笔记:Learning Dynamic Memory Networks for Object Tracking
Learning Dynamic Memory Networks for Object Tracking ECCV 2018Updated on 2018-08-05 16:36:30 Paper: ...
- SfMLearner论文笔记——Unsupervised Learning of Depth and Ego-Motion from Video
1. Abstract 提出了一种无监督单目深度估计和相机运动估计的框架 利用视觉合成作为监督信息,使用端到端的方式学习 网络分为两部分(严格意义上是三个) 单目深度估计 多视图姿态估计 解释性网络( ...
- 论文笔记 - Active Learning by Acquiring Contrastive Examples
Motivation 最常用来在 Active Learning 中作为样本检索的两个指标分别是: 基于不确定性(给模型上难度): 基于多样性(扩大模型的推理空间). 指标一可能会导致总是选到不提供有 ...
- 深度学习论文笔记-Deep Learning Face Representation from Predicting 10,000 Classes
来自:CVPR 2014 作者:Yi Sun ,Xiaogang Wang,Xiaoao Tang 题目:Deep Learning Face Representation from Predic ...
- 论文笔记:Learning Attribute-Specific Representations for Visual Tracking
Learning Attribute-Specific Representations for Visual Tracking AAAI-2019 Paper:http://faculty.ucmer ...
随机推荐
- 当一个线程进入一个对象的 synchronized 方法 A 之后, 其它线程是否可进入此对象的 synchronized 方法 B?
不能.其它线程只能访问该对象的非同步方法,同步方法则不能进入.因为非静 态方法上的 synchronized 修饰符要求执行方法时要获得对象的锁,如果已经进入 A 方法说明对象锁已经被取走,那么试图进 ...
- H.265
Baseline支持I/P 帧,只支持无交错(Progressive)和CAVLC一般用于低阶或需要额外容错的应用,比如视频通话.手机视频等: Main支持I/P/B 帧,无交错(Progressiv ...
- EDM响应式邮件框架:MJML
概述 新课题研究:响应式邮件框架MJML(MJML官网:https://mjml.io/)姐妹篇: EDM响应式邮件框架:Formerly Ink 介绍 MJML是一种标记语言,设计用于轻松实现一个响 ...
- React系列——websocket群聊系统在react的实现
前奏 这篇文章仅对不熟悉在react中使用socket.io的人.以及websocket入门者有帮助. 下面这个动态图展示的聊天系统是用react+express+websocket搭建的,很模糊吧, ...
- c++实现职责链模式--财务审批
内容: 某物资管理系统中物资采购需要分级审批,主任可以审批1万元及以下的采购单,部门经理可以审批5万元及以下的采购单,副总经理可以审批10万元及以下的采购单,总经理可以审批20万元及以下的采购单,20 ...
- java中StringBuffer的用法
2.StringBuffer StringBuffer:String类同等的类,它允许字符串改变(原因见上一段所说).Overall, this avoids creating many tempor ...
- java中为什么把Checked Exception翻译成受检的异常?
6.Checked Exception(受检的异常) 马克-to-win:为什么我大胆的把Checked Exception翻译成受检的异常?因为这类异常,编译器检查发现到它后会强令你catch它或t ...
- 如何实现多个接口Implementing Multiple Interface
4.实现多个接口Implementing Multiple Interface 接口的优势:马克-to-win:类可以实现多个接口.与之相反,类只能继承一个超类(抽象类或其他类). A class c ...
- 将百度地图Demo抽取出来安到自己的程序中
今日所学: 使用百度地图ADK实现手机定位 [Android]使用百度.高德.腾讯地图SDK获取定位数据与屏幕截图分享到QQ_哔哩哔哩 (゜-゜)つロ 干杯~-bilibili 代码获取SHA1 (2 ...
- JS 实现下拉框去重
JS 实现下拉框去重 学习内容: 需求 总结: 学习内容: 需求 用 JS 下拉框去重 实现代码 <html> <head> <meta http-equiv=" ...