各种查找算法的选用分析(顺序查找、二分查找、二叉平衡树、B树、红黑树、B+树)
顺序查找
给你一组数,最自然的效率最低的查找算法是顺序查找——从头到尾挨个挨个遍历查找,它的时间复杂度为O(n)。
二分查找
而另一个大家都知道的,效率很高经典查找算法——二分查找法,它的时间复杂度是O(logn)。但二分法的数据结构是数组,这样才能通过公式(low+height)/2=middle计算出中间位置的元素。而数组的修改效率很低,最坏的情况下,插入一个元素,要移动n个元素。
二叉平衡树
通过模拟二分查找法的插入、查找过程,会发现和二叉平衡树很相似,那我们分析一下二叉平衡树。简单的二叉树无法保证能保证查找的每一步节点是二分法中的中间位置,最坏情况会蜕变为顺序查找。所以需要对二叉树进行调整,让它变成二叉平衡树,这样查找的效率就能保证了,二叉平衡树的查找时间复杂度也是O(logn)。但是二叉平衡树的缺点在于,调整的消耗很大。它的每次插入,都要一层一层往上确认、调整。
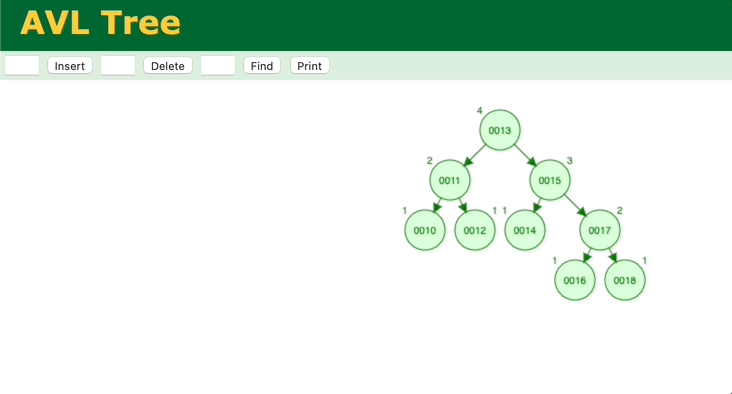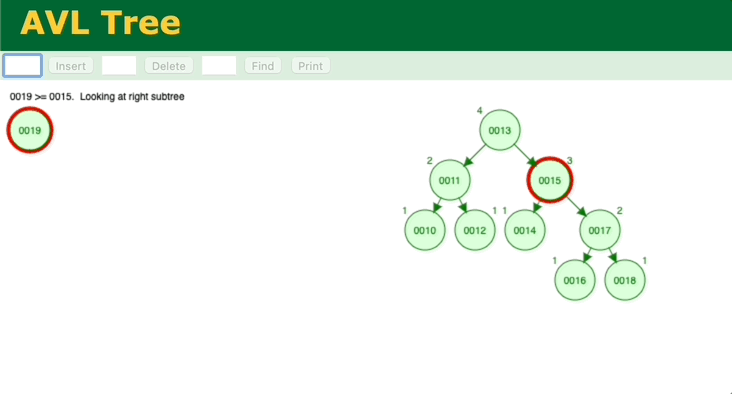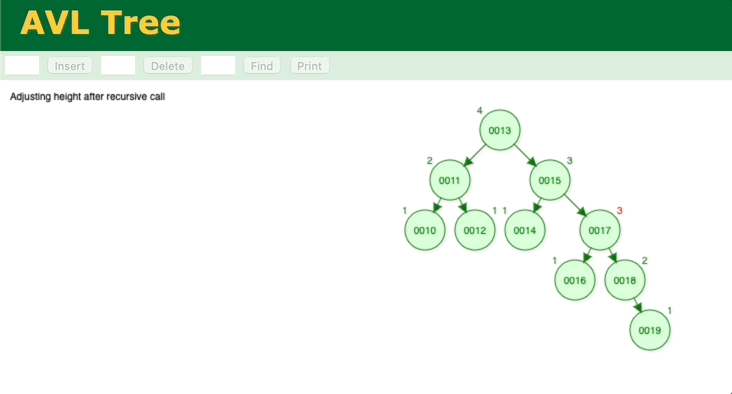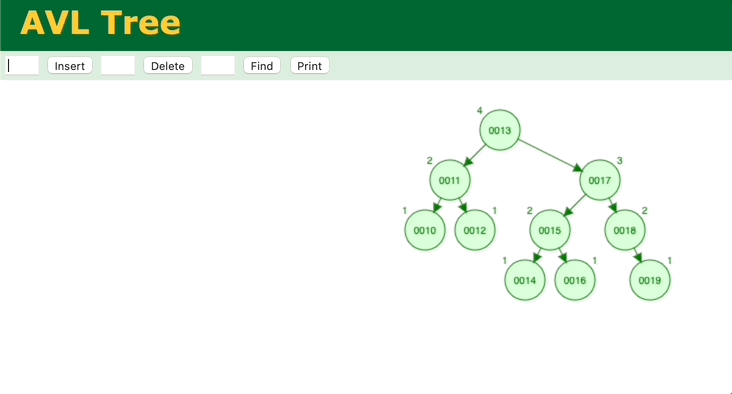
图 二叉树的插入、调整过程
B树
我们再来看另外一个二叉查找树——B树。观察一下B树的插入过程。
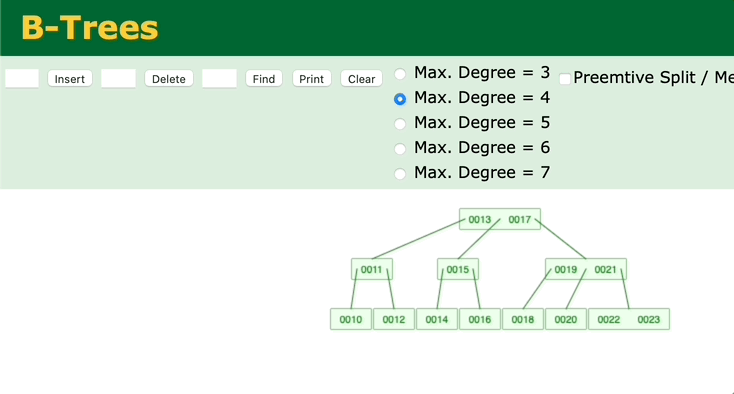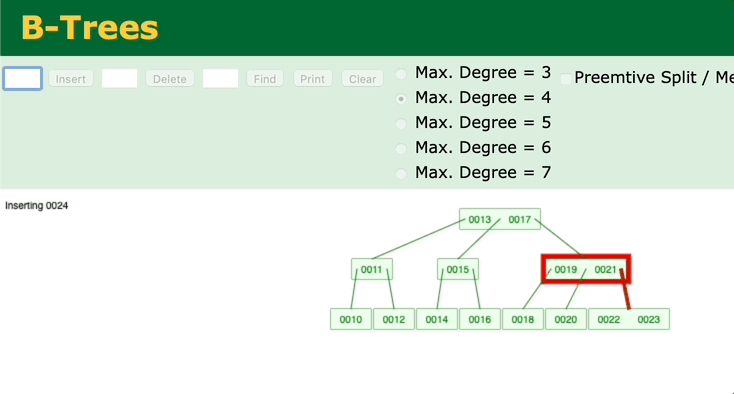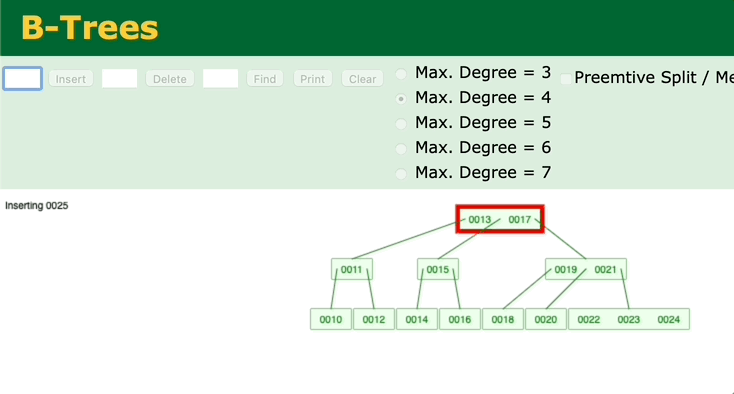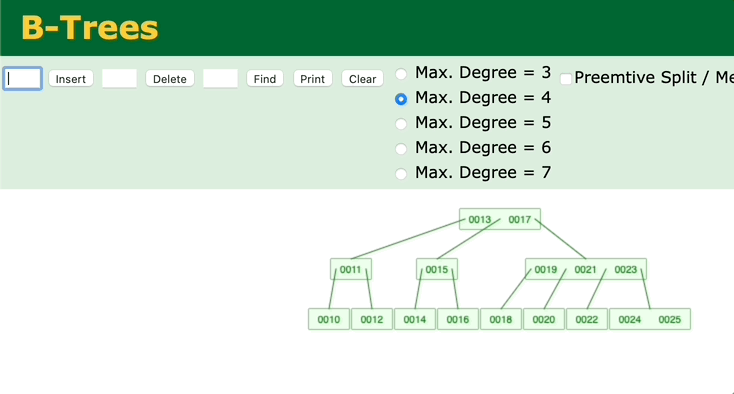
图 B树的插入、调整过程
可以看到,只有在插入后键值数超过最大键值数时,才会去修改父节点。如果父节点的中的键值数没有超过最大键值的话,就不会去动祖父节点了。所以B树的调整效率比二叉平衡树更高。
B树的另一个很大的应用是查找放在磁盘中的数据,比如数据库中数据的查找。假设现在有1G的数据,这么大的数据肯定不可能放在内存中,必须持久化到硬盘中。假设有100W条数据,使用二叉平衡树的话树高为20,即最坏情况下要进行20次I/O。如果使用64阶B树,即最坏情况下也只需要进行4次I/O就能完成查找。这就是为什么涉及到硬盘I/O的查找数据结构一般都会考虑B树。
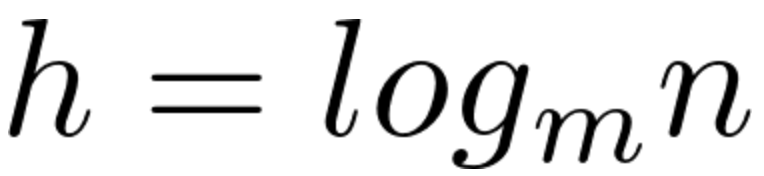
图 树高计算公式(m:树的分支树 n:节点数)
红黑树
我们常听到的红黑树,它的本质其实就是对概念模型:阶数为4的B树——“2-3-4树”的一种实现。由于直接进行不同节点间的转化会造成较大的开销,所以选择以二叉树为基础,在二叉树的属性中加入一个颜色属性来表示2-3-4树中不同的节点。
B+树
B+树是B树的一种变形形式,和B树的区别在于:
- B+树的非叶子节点只保存索引不保存数据,叶子结点存储关键字以及相应记录的地址;
- B+树的叶子节点之间会有指针

图 B+树
MySQL的存储引擎InnoDB就采用B+Tree的数据结构存储索引。B+树相比于B树的优点是:
- 磁盘读写代价更低
B+树的内部结点并没有指向关键字具体信息的指针。因此其内部结点相对B树更小。如果把所有同一内部结点的关键字存放在同一盘块中,那么盘块所能容纳的关键字数量也越多。一次性读入内存中的需要查找的关键字也就越多。相对来说IO读写次数也就降低了; - 查询效率更加稳定
由于非终结点并不是最终指向文件内容的结点,而只是叶子结点中关键字的索引。所以任何关键字的查找必须走一条从根结点到叶子结点的路。所有关键字查询的路径长度相同,导致每一个数据的查询效率相当; - B+树便于范围查询(最重要的原因,范围查找是数据库的常态)
B树在提高了IO性能的同时并没有解决元素遍历的我效率低下的问题,正是为了解决这个问题,B+树应用而生。B+树只需要去遍历叶子节点就可以实现整棵树的遍历。而且在数据库中基于范围的查询是非常频繁的,而B树不支持这样的操作或者说效率太低(B树的范围查找用的是中序遍历,而B+树用的是在链表上遍历)。
三层B+树就可以存储千万级别的数据,详细分析过程见:B+树能存多少数据?。
参考文档
各种查找算法的选用分析(顺序查找、二分查找、二叉平衡树、B树、红黑树、B+树)的更多相关文章
- 算法进阶面试题04——平衡二叉搜索树、AVL/红黑/SB树、删除和调整平衡的方法、输出大楼轮廓、累加和等于num的最长数组、滴滴Xor
接着第三课的内容和讲了第四课的部分内容 1.介绍二叉搜索树 在二叉树上,何为一个节点的后继节点? 何为搜索二叉树? 如何实现搜索二叉树的查找?插入?删除? 二叉树的概念上衍生出的. 任何一个节点,左比 ...
- cb16a_c++_顺序容器的选用_排序_二分查找
/*cb16a_c++_顺序容器的选用_排序_二分查找顺序容器: 1.vector的优点与缺点 vector优点:排序利用下标,快速排序,做二分查找非常快 2.list的优点与缺点 list优点:插入 ...
- 从零开始学算法---二叉平衡树(AVL树)
先来了解一些基本概念: 1)什么是二叉平衡树? 之前我们了解过二叉查找树,我们说通常来讲, 对于一棵有n个节点的二叉查找树,查询一个节点的时间复杂度为log以2为底的N的对数. 通常来讲是这样的, 但 ...
- 算法题 19 二叉平衡树检查 牛客网 CC150
算法题 19 二叉平衡树检查 牛客网 CC150 实现一个函数,检查二叉树是否平衡,平衡的定义如下,对于树中的任意一个结点,其两颗子树的高度差不超过1. 给定指向树根结点的指针TreeNode* ro ...
- 笔试算法题(58):二分查找树性能分析(Binary Search Tree Performance Analysis)
议题:二分查找树性能分析(Binary Search Tree Performance Analysis) 分析: 二叉搜索树(Binary Search Tree,BST)是一颗典型的二叉树,同时任 ...
- 查找算法(I) 顺序查找 二分查找 索引查找
查找 本文为查找算法的第一部分内容,包括了基本概念,顺序查找.二分查找和索引查找.关于散列表和B树查找的内容,待有空更新吧. 基本概念 查找(search)又称检索,在计算机上对数据表进行查找,就是根 ...
- 算法图解学习笔记01:二分查找&大O表示法
二分查找 二分查找又称折半查找,其输入的必须是有序的元素列表.二分查找的基本思想是将n个元素分成大致相等的两部分,取a[n/2]与x做比较,如果x=a[n/2],则找到x,算法中止:如果x<a[ ...
- 查找算法(4)--Fibonacci search--斐波那契查找
1.斐波那契查找 (1)说明 在介绍斐波那契查找算法之前,我们先介绍一下很它紧密相连并且大家都熟知的一个概念——黄金分割. 黄金比例又称黄金分割,是指事物各部分间一定的数学比例关系,即将整体一分为二, ...
- 算法学习:我终于明白二分查找的时间复杂度为什么是O(logn)了
最近发现了个好东西,就是一个学算法的好东西,是网易公开课的一个视频. 直通车 这是麻省理工学院的公开课,有中英字幕,感谢网易.. 也可以在App把视频缓存下来之后再放到电脑上面看,因为我这样可以倍速, ...
随机推荐
- 什么是Ribbon?
ribbon是一个负载均衡客户端,可以很好的控制htt和tcp的一些行为.feign默认集成了ribbon.
- 如何在自定义端口上运行 Spring Boot 应用程序?
为了在自定义端口上运行 Spring Boot 应用程序,您可以在 application.properties 中指定端口. server.port = 8090
- 事务的 ACID 是指什么?
原子性(Atomic):事务中各项操作,要么全做要么全不做,任何一项操作 的失败都会导致整个事务的失败: 一致性(Consistent):事务结束后系统状态是一致的: 隔离性(Isolated):并发 ...
- 利用Properties类关联相关配置文件
文件目录 代码: package Lianxi;import java.io.FileInputStream;import java.io.FileNotFoundException;import j ...
- 【动态规划】洛谷P1802 5 倍经验日(01背包问题)
一个洛谷普及-的题目,也是我刚刚入门学习动态规划的练习题. 下面发一下我的思路和代码题解: 我的思路及伪代码: 我的AC图: 接下来上代码: 1 //动态规划 洛谷P1802 五倍经验日 2 #inc ...
- 【网易云信】H5 容器技术方案
Native 开发原生应用是手机操作系统厂商(目前主要是苹果的 iOS 和 Google 的 Android)对外界提供的标准化的开发模式,他们对于 Native 开发提供了一套标准化实现和优化方案. ...
- h5 在全屏iphonex中的适配
iphonex 已经上线有一段时间了,作为业界刘海屏幕第一款机型,导致全屏不能正常的全屏显示了,,所以需要对iphonx 适配,下面就详细说说如何适配 先看一张适配前后的图: iphonex 提供的 ...
- CCF201604-2俄罗斯方块
问题描述 俄罗斯方块是俄罗斯人阿列克谢·帕基特诺夫发明的一款休闲游戏. 游戏在一个15行10列的方格图上进行,方格图上的每一个格子可能已经放置了方块,或者没有放置方块.每一轮,都会有一个新的由4个小方 ...
- CSS简单样式练习(五)
运行效果: 源代码: 1 <!DOCTYPE html> 2 <html lang="zh"> 3 <head> 4 <meta char ...
- git clone 遇到的问题
经常遇到这个问题, 所以今天决定把它记录下来 当使用git clone时,会报Please make sure you have the correct access rights and the r ...