C++温故补缺(十九):atomic类
atomic
参考:c++11 多线程(3)atomic 总结 - 简书.c++11 atomic Npgw的博客.C++11 并发指南系列 - Haippy - 博客园.
atomic_flag
atomic_flag看名字就能知道是一种flag类型,它是一种简单的原子布尔类型,只支持两种操作:test-and-set和clear。
创建atomic_flag对象时,如果不初始化,那么该对象的状态就是unspecified,未指定的。(C++11的,C++20后未初始化时为clear)
atomic_flag flag;
可以使用ATOMIC_FLAG_INIT标志初始化对象, 表示对象处于clear状态。转到定义,可以看到该tag的值为0

atomic_flag对象只有两种操作,test_and_set就是把atomic_flag的_M_i域置为1,clear则是置零。
功能
test_and_set()的作用是先test测试返回atomic_flag对象的状态,接着set,把对象设置为true。
clear()是直接设置为false,返回类型为void。
原子类型
原子类型需要引用头文件<atomic>,一个原子类型就是原有类型加上atomic_表示。如int对应的原子类型atomic_int,也可以使用原始格式,是类模板实现的:atomic<int> 。
其他原子类型还有:
| Typedefs | |
|---|---|
| std::atomic_bool | std::atomic |
| std::atomic_char | std::atomic |
| std::atomic_schar | std::atomic |
| std::atomic_uchar | std::atomic |
| std::atomic_short | std::atomic |
| std::atomic_ushort | std::atomic |
| std::atomic_int | std::atomic |
| std::atomic_uint | std::atomic |
| std::atomic_long | std::atomic |
| std::atomic_ulong | std::atomic |
| std::atomic_llong | std::atomic |
| std::atomic_ullong | std::atomic |
| std::atomic_char16_t | std::atomic<char16_t> |
| std::atomic_char32_t | std::atomic<char32_t> |
| std::atomic_wchar_t | std::atomic<wchar_t> |
| std::atomic_int_least8_t | std::atomic<int_least8_t> |
| std::atomic_uint_least8_t | std::atomic<uint_least8_t> |
| std::atomic_int_least16_t | std::atomic<int_least16_t> |
| std::atomic_uint_least16_t | std::atomic<uint_least16_t> |
| std::atomic_int_least32_t | std::atomic<int_least32_t> |
| std::atomic_uint_least32_t | std::atomic<uint_least32_t> |
| std::atomic_int_least64_t | std::atomic<int_least64_t> |
| std::atomic_int_fast8_t | std::atomic<int_fast8_t> |
| std::atomic_uint_fast8_t | std::atomic<uint_fast8_t> |
| std::atomic_int_fast16_t | std::atomic<int_fast16_t> |
| std::atomic_uint_fast16_t | std::atomic<uint_fast16_t> |
| std::atomic_int_fast32_t | std::atomic<int_fast32_t> |
| std::atomic_uint_fast32_t | std::atomic<uint_fast32_t> |
| std::atomic_int_fast64_t | std::atomic<int_fast64_t> |
| std::atomic_uint_fast64_t | std::atomic<uint_fast64_t> |
| std::atomic_intptr_t | std::atomic<intptr_t> |
| std::atomic_uintptr_t | std::atomic<uintptr_t> |
| std::atomic_size_t | std::atomic<size_t> |
| std::atomic_ptrdiff_t | std::atomic<ptrdiff_t> |
| std::atomic_intmax_t | std::atomic<intmax_t> |
| std::atomic_uintmax_t | std::atomic<uintmax_t> |
可以看到主要是一些关于int,short,long,char等在内存中以整数存储的类型,没有float,double等浮点型的。
- 原子类型实现同步的例子:
多线程做累加,如果没有做同步,得到的结果可能是正确的,也可能小于预测值。
- 无同步,直接++计算
#include<iostream>
#include<thread>
#include<atomic>
using namespace std;
int count;
void counter(){
for(int i=1;i<200000;i++)
count++;
}
int main(){
thread th1(counter);
thread th2(counter);
thread th3(counter);
thread th4(counter);
thread th5(counter);
th1.join();
th2.join();
th3.join();
th4.join();
th5.join();
cout<<count<<endl;
}
得到的结果:
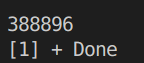
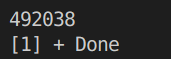
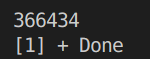
每次结果都不同。
- 使用锁进行同步:
#include<iostream>
#include<thread>
#include<atomic>
#include<mutex>
using namespace std;
int count;
mutex l;
void counter(){
lock_guard<mutex> locker(l);
for(int i=0;i<200000;i++)
count++;
}
int main(){
thread th1(counter);
thread th2(counter);
thread th3(counter);
thread th4(counter);
thread th5(counter);
th1.join();
th2.join();
th3.join();
th4.join();
th5.join();
cout<<count<<endl;
}
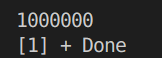
- 使用原子类型:
#include<iostream>
#include<thread>
#include<atomic>
#include<mutex>
using namespace std;
atomic_int count;
void counter(){
for(int i=0;i<200000;i++)
count++;
}
int main(){
thread th1(counter);
thread th2(counter);
thread th3(counter);
thread th4(counter);
thread th5(counter);
th1.join();
th2.join();
th3.join();
th4.join();
th5.join();
cout<<count<<endl;
}
原子类型的实现原理
原子类型实现的原理是直接翻译成CPU指令,而对原子类型的操作,像+,-,*,,++等直接重载了运算符,编译时也直接翻译成CPU指令。每一个原子操作都是一条独立的CPU指令来完成,在其指令周期内,其他CPU无法对原子类型操作。
举例:
#include<iostream>
#include<thread>
#include<atomic>
#include<mutex>
using namespace std;
atomic_int count;
void counter(){
for(int i=0;i<200000;i++)
count++;
}
int main(){
thread th1(counter);
th1.join();
cout<<count<<endl;
}
调试该程序,断点打在count++,
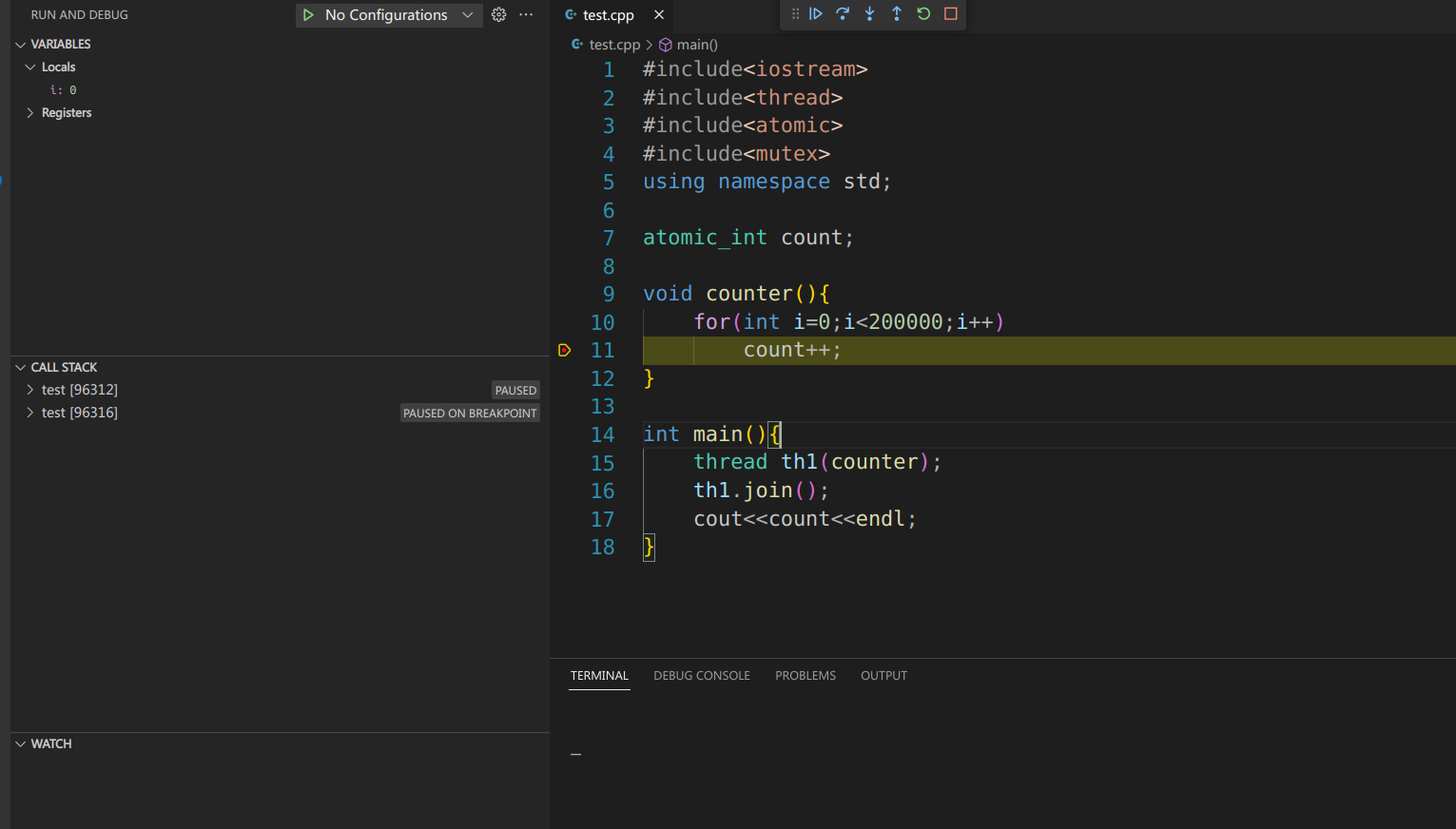
首先可以看到调用栈有两个test,也就是两个线程,main和th1。
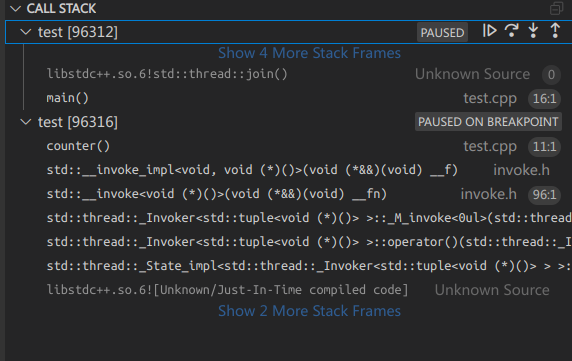
接着进入counter()的反汇编视图,open disassembly view:

call atomic_baseIiEppEi就是这条CPU指令用来给count++,它是原子性的,保证了不会被其他CPU操作。
并且在step into中也能看到跳转到了运算符重载的头文件:
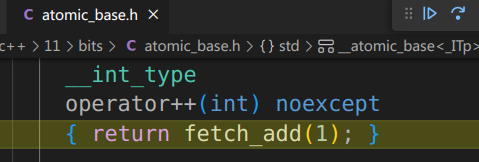

这就是atomic的实现机制
第二条add [rbp-0x4],0x1就是i++对应的CPU指令,i就存在bp基址寄存器的前面四个字节的位置。我们step over几次让i的值有变化,看寄存器相对寻址的值:就是0x7


第三条指令是CPU优化了for循环,本来应该先把i mov到寄存器,现在优化后直接比较i和19999的值,0x30d3f就是十进制的19999,也就是循环结束的条件。
如果给i加上volatile,就可以防止cpu优化
....
volatile int i;
for(i=0;i<200000;i++)
count++;
....

原子类型的操作
上面的count++例子中,step into 跳转到了atomic类型的运算符重载定义中,实际上所有能够对原子类型的操作,都是重载了普通的意思,或添加了新的函数。
所有的原子操作:atomic<> a;
纵列 triv :针对std::atomic以及“其他普通类型之atomic”提供的操作
纵列 int type :针对std::atomic<> 且使用整型类型而提供的操作;
纵列 ptr type :针对std::atomic<> 且使用pointer类型 而提供的操作
| 操作 | triv | int type | ptr type | 效果 |
|---|---|---|---|---|
| atomic a = val | yes | yes | yes | 以val为a的初值(这个不是atomic 的操作) |
| atomic a; atomic_init(&a,val) | yes | yes | yes | 同上 (若无后面的atomic_init(),则a的初始化不完整) |
| a.is_lock_free() | yes | yes | yes | 如果内部不使用lock则返回true 用来检测atomic类型内部是否由于使用lock才成为atomic。如果不是,则硬件本身就拥有对atomic操作的固有支持 |
| a.store(val) | yes | yes | yes | 赋值 val (返回void) |
| a.load() | yes | yes | yes | 返回数值a的copy |
| a.exchange(val) | yes | yes | yes | 赋值val并返回旧值a的拷贝 |
| a.compare_exchange_strong(exp,des) | yes | yes | yes | cas操作 |
| a.compare_exchange_weak(exp,des) | yes | yes | yes | weak cas操作 |
| a = val | yes | yes | yes | 赋值并返回val的拷贝(copy) |
| a.operator atomic() | yes | yes | yes | 返回数值a的拷贝 |
| a.fetch_sub(val) | no | yes | yes | 不可切割值 a -= val 并返回新值得拷贝 |
| a += val | no | yes | yes | 等同于 t.fetch_add(val) |
| a -= val | no | yes | yes | 等同于 t.fetch_sub(val) |
| ++a a++ | no | yes | yes | 等同于 t.fetch_add(1) 并返回 a 或者a+1的拷贝 |
| –a a– | no | yes | yes | 等同于 t.fetch_sub(1) 并返回 a 或者a+1的拷贝 |
| a.fetch_and(val) | no | yes | no | 不可切割值 a &= val 并返回新值得拷贝 |
| a.fetch_or(val) | no | yes | no | 不可切割值 a |
| a.fetch_and(val) | no | yes | no | 不可切割值 a ^= val 并返回新值得拷贝 |
| a &= val | no | yes | no | 等同于 t.fetch_and(val) |
| a | = val | no | yes | no |
| a | = val | no | yes | no |
atomic<>中的模板除了整型,还可以是其他如浮点型,指针,但是他们可能没有+,-,*,/等运算符的重载或位运算重载。
CAS操作
a.compare_exchange_strong/weak是CAS操作(compare and swap),CPU提供这个操作用来比较“某内存的值”和“某给定的值”,当他们相同时,则把“该内存值”更新为”另一个给定的值“。如果不相同,则更新“某给定的值”为“某内存值”。
伪代码:
bool compare_exchange_strong(T & expected ,T desired)
{
if(this->load() == expected )
{
this->strore(desired)
return true;
}
else
{
expected = this->load();
return false;
}
}
this就是内存值的指针,expected是第一个给定的值,desired是另一个给定的值。
memory_order和内存模型
参考:C++11 内存模型。知乎:C++ memory_order.详解c++ atomic原子编程中的Memory Order.
C++11 中的原子类型的API大都需要提供一个std::memory_order(内存序,访存顺序)的枚举类型作为参数,如atomic_store, atomic_load, atomic_exchange, atomic_compare_exchange, atomic_flag, 以及还有test_and_set和clear等API都可以设置一个std::memory_order参数。在没有指定时,默认的参数是std::memory_order_seq_cst(顺序一致性)。
研究内存序,首先要研究C++的内存模型。
C++的内存模型一般可以分为静态内存模型和动态内存模型。静态内存模型主要涉及类的对象的在内存中是如何存放的,即从结构上来看一个对象在内存中的布局。和之前研究的内存对齐和排序(C温故补缺(九):字节对齐与排序)类似。
而动态内存模型,可以理解为存储一致性模型。主要是从行为上来看多个线程对同一个对象同时操作时所做的约束。和我们做线程同步的意义相似的:都是为了程序执行的正确性,避免未知结果。
std::memory_orderspecifies how memory accesses, including regular, non-atomic memory accesses, are to be ordered around an atomic operation. Absent any constraints on a multi-core system, when multiple threads simultaneously read and write to several variables, one thread can observe the values change in an order different from the order another thread wrote them. Indeed, the apparent order of changes can even differ among multiple reader threads. Some similar effects can occur even on uniprocessor systems due to compiler transformations allowed by the memory model.from cppreference
在cppreference.com中的简单解释中也说了:多核系统在没有任何约束的条件下,在多个线程同时读取和写入多个变量时,因为执行顺序的不同可能导致不同的值。在没有规定时,多线程并发执行时,指令是可能被CPU重排的,所以就有可能出现不同的结果。比如:
a,b两个共享变量,初始值都是0,通过两个改变值
线程 1 线程 2 a = 1; b = 2; R1 = b; R2 = a;
虽然对于每个线程每一步都是原子的,但是两个线程之前并没有规定先后顺序。就有可能出现6种情况。
| 情况 1 | 情况 2 | 情况 3 | 情况 4 | 情况 5 | 情况 6 |
|---|---|---|---|---|---|
| a = 1; | b = 2; | a = 1; | a = 1; | b = 2; | b = 2; |
| R1 = b; | R2 = a; | b = 2; | b = 2; | a = 1; | a = 1; |
| b = 2; | a = 1; | R1 = b; | R2 = a; | R1 = b; | R2 = b; |
| R2 = a; | R1 = b; | R2 = a; | R1 = b; | R2 = a; | R1 = b; |
| R1 == 0, R2 == 1 | R1 == 2, R2 == 0 | R1 == 2, R2 == 1 | R1 == 2, R2 == 1 | R1 == 2, R2 == 1 | R1 == 2, R2 == 1 |
常见的存储一致性模型包括:顺序一致性模型、处理器一致性模型、弱一致性模型、释放一致性模型、急切更新一致性模型、懒惰更新释放一致性模型、域一致性模型以及单项一致性模型。
因为C++中只有一下6种,所以只研究这几种访存次序。
| memory order | 作用 |
|---|---|
| memory_order_relaxed | 无fencing 作用,cpu和编译器可以重排指令 |
| memory_order_consume | 后面依赖此原子变量的访存指令勿重排至此条指令前 |
| memory_order_acquire | 后面的访存指令勿重排至此指令前 |
| memory_order_release | 前面的访存指令勿重排到此指令后 |
| memory_order_acq_rel | acquire+release |
| memory_order_seq_cst | acq_rel+所有使用seq_cst的指令有严格的全序关系 |
多线程编程时,通过这些标志位,来读写原子变量,可以组合成4种同步模型:
Relaxed ordering
在这种模型下,std::atomic的load和store都要带上memory_order_relaxed参数,Relaxed ordering仅仅保证load和store是原子的,除此之外无任何跨线程同步。
Release_Acquire ordering
这个模型下,store()使用memory_order_release,而load()使用memory_order_acquire。这个模型限制指令的重排:
在store()之前的读写操作,不允许重排到store()的后面。一般对应写操作
在load()之后的读写操作,不允许重排到load()前面,一般对应读操作
也就是store总是排在load前面,保证不会读到修改前的数据。
如一个打印机有两个模块,一个负责装载打印数据,一个用来打印。如果未装载新的数据,会直接打印上一次的信息:
如果没有规定线程之间的执行顺序,则可能会读到上一此的信息:
#include<iostream>
#include<thread>
#include<atomic>
using namespace std;
string printstr="old data";//上一此的信息
void load(string str){//装载
printstr=str;
}
void print(){//打印
cout<<printstr<<endl;
}
int main(){
thread th1(load,"Hello");
thread th2(print);
th1.join();
th2.join();
}
因为程序会被cpu优化,所以手动编译取消优化-O0
g++ test.cpp -O0 -o test;./test
每次的运行都是随机排序的,所以可能会出现old data

使用Release_acquire模型来规定线程间的执行顺序:
#include<iostream>
#include<thread>
#include<atomic>
using namespace std;
atomic<bool> ready{false};
string printstr="old data";//上一此的信息
void load(string str){//装载
printstr=str;
ready.store(true,memory_order_release);
}
void print(){//打印
while(!ready.load(memory_order_acquire))
;//循环等待
cout<<printstr<<endl;
}
int main(){
thread th1(load,"Hello");
thread th2(print);
th1.join();
th2.join();
}
 就得到了准确的结果
就得到了准确的结果
Release_Consume ordering
这个模型下 store()使用memory_order_release,而load()使用memory_order_consume。
在store前的所有读写,不允许被移动到store()后面
在load之后所有依赖此原子变量的读写,不允许被移动到load前面。
和上面Release-acquire模型的差别是load前可以出现不依赖该原子变量的读写
C++温故补缺(十九):atomic类的更多相关文章
- Java多线程系列九——Atomic类
参考资料:https://fangjian0423.github.io/2016/03/16/java-AtomicInteger-analysis/http://www.cnblogs.com/54 ...
- Python学习第十九课——类的装饰器
类的装饰器 # def deco(func): # print('==========') # return func # # # @deco #test=deco(test) # # def tes ...
- C温故补缺(十六):未定义行为
未定义行为 在计算机程序设计中,未定义行为是指执行某种计算机代码 所产生的结果,这种代码在当前程序状态下的行为在其所使用的语言标准中没有规定. 以C语言为例,未定义行为指C语言标准未作规定的行为,同时 ...
- C温故补缺(十五):栈帧
栈帧 概念 栈帧:也叫过程活动记录,是编译器用来实现过程/函数调用的一种数据结构,每次函数的调用,都会在调用栈(call stack)上维护一个独立的栈帧(stack frame) 栈帧的内容 函数的 ...
- C温故补缺(十四):内存管理
内存管理 stdlib库中有几个内存管理相关的函数 序号 函数和描述 1 void *calloc(int num, int size);在内存中动态地分配 num 个长度为size 个字节 的连续空 ...
- C温故补缺(十二):预编译器与头文件
预编译器 预编译器就是之前学的预编译指令的执行者 gcc -E test.c -o test.i 生成预编译文件就是翻译#指令 比如#include<stdio.h>就是把整个stdio. ...
- C温故补缺(十):输入输出
输入输出 printf()和scanf() 用来格式化输入输出,它们都是有返回值的 int printf()返回输出的内容的长度 #include<stdio.h> int main(){ ...
- 设计模式 ( 十九 ) 模板方法模式Template method(类行为型)
设计模式 ( 十九 ) 模板方法模式Template method(类行为型) 1.概述 在面向对象开发过程中,通常我们会遇到这样的一个问题:我们知道一个算法所需的关键步骤,并确定了这些步骤的执行 ...
- “全栈2019”Java第七十九章:类中可以嵌套接口吗?
难度 初级 学习时间 10分钟 适合人群 零基础 开发语言 Java 开发环境 JDK v11 IntelliJ IDEA v2018.3 文章原文链接 "全栈2019"Java第 ...
- 无废话ExtJs 入门教程十九[API的使用]
无废话ExtJs 入门教程十九[API的使用] extjs技术交流,欢迎加群(201926085) 首先解释什么是 API 来自百度百科的官方解释:API(Application Programmin ...
随机推荐
- c# HttpServer 的使用
在很多的时候,我们写的应用程序需要提供一个信息说明或者告示功能,希望借助于HttpServer来发布一个简单的网站功能,但是又不想架一个臃肿的Http服务器功能, 这时候,标准框架提供的HttpSer ...
- 【RTOS】《基于嵌入式实时操作系统的程序设计技术》——任务的划分与封装
任务的划分与封装 关键任务的划分处理 对于某些对于系统的正常运作至关重要,少执行一次会对系统产生较大影响的功能,我们倾向于将它从原有任务中剥离出来,称为关键任务,用一个独立任务或者ISR(如外部中断) ...
- redis统计用户活跃数量
1.说明,redis 位图存储节省内存,用户id:156,1333; 如果用户登录,根据日期存储为1 setbit 20209001 156 1 ;//id为156的用户在1月1号登录了 setbit ...
- 题目集4~6的总结性Blog
题目集4~6的总结性Blog (1)前言 在这三次作业中,主要考察了正则表达式以及类间的关系.在这三次作业中,相比之下,第四次以及第五次作业的难度明显高于第六次作业,题量与难度相较于以往的作业也有明显 ...
- Java中Math类常用方法
在编写程序时,可能需要计算一个数的平方根.绝对值或获取一个随机数等.java.lang包中的Math类包含许多用来进行科学计算的static方法,这些方法可以直接通过类名调用.另外,Math类还有两 ...
- 处理时间转换不正确-Springboot、springclound、feign、http请求
SpringBoot.SpringCloud.feign.前后端时间解析不正确时,我们可以自定义HttpMessageConverters,以达到我们希望的结果 参考链接:https://www.cn ...
- 服务器性能测试工具ab
ab指令 ab -n 1000 -c 20 http://127.0.0.1/
- pyechart画图(1)安装和基本操作
安装 pip install pyecharts==0.1.9.4 https://blog.csdn.net/weixin_43735353/article/details/89328048 Lin ...
- miou
1. 前言 本文学习记录了机器学习中的分类常见评价指标以及分割中的MIoU. 主要有以下概念:Accuracy, Precision, Recall, Fscore,混淆矩阵,IoU及MIoU. 2. ...
- Windows下安装多个Redis实例
1.在Redis 目录下复制redis.windows-service.conf文件,建议命名规则redis.windows-service-port.conf,我们以6380端口为例. 2.打开re ...