构建第一个模型:KNN算法(Iris_dataset)
利用鸢尾花数据集完成一个简单的机器学习应用~万丈高楼平地起,虽然很基础,但是还是跟着书敲了一遍代码。
一、模型构建流程
1、获取数据
- 本次实验的Iris数据集来自skicit-learn的datasets模块
from sklearn.datasets import load_iris
iris_dataset = load_iris()
查看一下数据:
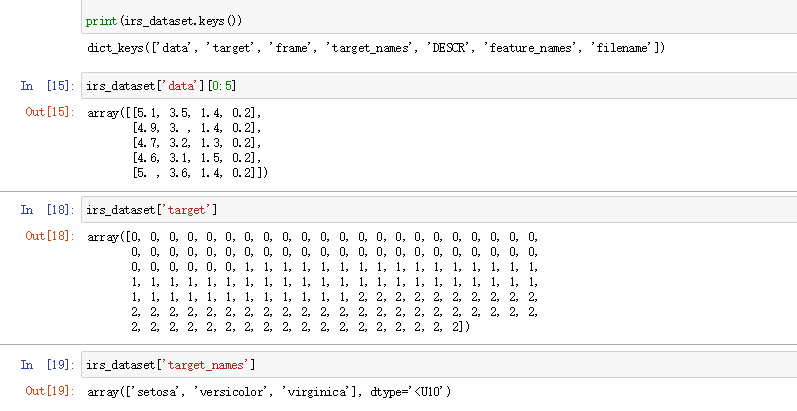
可以发现iris_dataset类似一个字典,里面包含键和值,其中键值对包括数据的简介(DESC)、标签值(target)、数据样本(data),标签名(target name)等
2、数据预处理
- 本次使用的数据无需预处理,已经处理好了,目标值也被表示为0,1,2的数字标签,data和target都是ndarray数组。
3、特征工程
- 本次数据还比较简单,特征也少,无需特征选择,
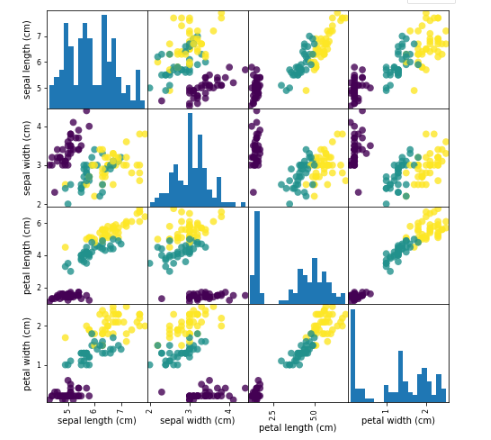
- 这里利用pandas的scatter.metrix将数据进行可视化一下,进行观察各个特征之间的关系,
在此之前先划分一下训练集和测试集
- 这里利用pandas的scatter.metrix将数据进行可视化一下,进行观察各个特征之间的关系,
#划分训练集,测试集
X_train,X_test,y_trian,y_test = train_test_split(irs_dataset['data'],irs_dataset['target'],random_state = 0)
#利用pd,画散点图,观察数据是否有异常值
irs_dataframe = pd.DataFrame(X_train,columns=irs_dataset.feature_names)
grr = pd.plotting.scatter_matrix(irs_dataframe,c=y_trian,figsize=(8,8),marker='o',
hist_kwds={'bins':20},s=60,alpha=.8)
4、(机器学习)构建模型
考虑到这个数据特点,这里使用KNN算法
KNN:在判断一个数据X的标签时,会计算距离它与其他所有样本x1,x2,x3,...,的距离,选择距离它最近的k个样本的标签值,作为该数据X的标签值。
#建立模型:KNN算法
knn = KNeighborsClassifier(n_neighbors=2) #把k值设为2
knn.fit(X_train, y_trian) #基于训练集构建模型,两个参数都是Numpy 数组
5、模型评估
怎么知道该模型在预测新数据时的有效性呢?有很多评估指标,比如说精确率、召回率...
这里使用精确率:正确预测列别的数据,占所有数据的比例
#评估模型
y_pred = knn.predict(X_test)
print(y_pred)
print("precision={:.2f}".format(np.mean(y_pred==y_test)))
print(knn.score(X_test, y_test))
二、遇到的问题
- 按照书上所写使用pandas的scatter.metrix画散点图做相关性分析时遇到’module ‘pandas’ has no attribute ‘scatter_matrix’'这个问题

解决方法:
现在的pandas的scatter_matrix用法已经发生变化了,在使用时需要加上plotting,即:pandas.plotting.scatter_matrix
三、参考文献
《python机器学习基础教程》--【德】Adreas C.Muller
构建第一个模型:KNN算法(Iris_dataset)的更多相关文章
- 机器学习之近邻算法模型(KNN)
1..导引 如何进行电影分类 众所周知,电影可以按照题材分类,然而题材本身是如何定义的?由谁来判定某部电影属于哪 个题材?也就是说同一题材的电影具有哪些公共特征?这些都是在进行电影分类时必须要考虑的问 ...
- [Python] 应用kNN算法预测豆瓣电影用户的性别
应用kNN算法预测豆瓣电影用户的性别 摘要 本文认为不同性别的人偏好的电影类型会有所不同,因此进行了此实验.利用较为活跃的274位豆瓣用户最近观看的100部电影,对其类型进行统计,以得到的37种电影类 ...
- KNN算法的补充
文本自动分类技术是文字管理的基础.通过快速.准确的文本自动分类,可以节省大量的人力财力:提高工作效率:让用户快速获得所需资源,改善用户体验.本文着重对KNN文本分类算法进行介绍并提出改进方法. 一.相 ...
- 【机器学习算法基础+实战系列】KNN算法
k 近邻法(K-nearest neighbor)是一种基本的分类方法 基本思路: 给定一个训练数据集,对于新的输入实例,在训练数据集中找到与该实例最邻近的k个实例,这k个实例多数属于某个类别,就把输 ...
- sklearn学习 第一篇:knn分类
K临近分类是一种监督式的分类方法,首先根据已标记的数据对模型进行训练,然后根据模型对新的数据点进行预测,预测新数据点的标签(label),也就是该数据所属的分类. 一,kNN算法的逻辑 kNN算法的核 ...
- KNN算法和实现
KNN要用到欧氏距离 KNN下面的缺点很容易使分类出错(比如下面黑色的点) 下面是KNN算法的三个例子demo, 第一个例子是根据算法原理实现 import matplotlib.pyplot as ...
- 吴裕雄--天生自然python机器学习实战:K-NN算法约会网站好友喜好预测以及手写数字预测分类实验
实验设备与软件环境 硬件环境:内存ddr3 4G及以上的x86架构主机一部 系统环境:windows 软件环境:Anaconda2(64位),python3.5,jupyter 内核版本:window ...
- 深入浅出KNN算法
概述 K最近邻(kNN,k-NearestNeighbor)分类算法 所谓K最近邻,就是k个最近的邻居的意思,说的是每个样本都可以用它最接近的k个邻居来代表. kNN算法的核心思想是如果一个样本在特征 ...
- 机器学习笔记--KNN算法2-实战部分
本文申明:本系列的所有实验数据都是来自[美]Peter Harrington 写的<Machine Learning in Action>这本书,侵删. 一案例导入:玛利亚小姐最近寂寞了, ...
随机推荐
- 在linux环境下安装VMtools(成功)
想在主机和虚拟机之间互相复制文件吗? 想更加方便的联系主机和虚拟机吗? 就安装VMtools吧 其实,在linux下安装VMtools 是非常的简单,只要简单地几步就行了! 第一步:打开虚拟机,在左 ...
- 在小程序中Tabbar显示和隐藏的秘密
其实对Tabbar 的用法的理解总结下来分这几个阶段: 第一阶段:在 app.json 中配置 "tabBar": { "list": [{ "pag ...
- 【Android开发】富文本
SpannableString spannableString = new SpannableString("设置文字的前景色为淡蓝色"); ForegroundColorSpan ...
- xml中的<![CDATA[]]>和转义字符
被<![CDATA[]]>这个标记所包含的内容将表示为纯文本,比如<![CDATA[<]]>表示文本内容"<". 此标记用于xml文档中,我们先 ...
- 自学java如何快速地达到工作的要求?
自学java如何快速地达到工作的要求,是很多初学者都比较关心的问题,对于初学者来说,盲目自学不但不能快速入门,还会浪费大量的时间. 今天知了堂就来分享自学Java如何快速达到找工作的要求. 1.自学J ...
- Spring-AOP动态代理技术(底层代码)
1.JDK代理:基于接口的动态代理技术 目标对象必须有接口,目标对象有什么方法,目标接口就有什么方法, 运行期间基于接口动态生成代理对象,所以代理对象也就有目标对象同样的方法. 注意:以下代码只是底层 ...
- 【Oracle】EXPDP和IMPDP数据泵进行导出导入的方法
一.expdp/impdp和exp/imp 客户端工具 1.exp和imp是客户端工具程序,它们既可以在客户端使用,也可以在服务端使用. 服务端工具 2.expdp和impdp是服务端的工具程序,他们 ...
- 帝国CMS批量提取正文内容到简介
最近接到一个帝国CMS模板改版项目,自带的数据可能是采集的,以前的简介字段内容只截取了60个字,新模板的简介60字符太少了,不美观,想让简介都截取200个字,怎么批量修改呢,文章太多了手动改肯定不行, ...
- hutool工具类常用API整理
0.官网学习地址 https://www.hutool.cn/ 1.依赖 <dependency> <groupId>cn.hutool</groupId> < ...
- 机器学习实战:用SVD压缩图像
前文我们了解了奇异值分解(SVD)的原理,今天就实战一下,用矩阵的奇异值分解对图片进行压缩. Learn by doing 我做了一个在线的图像压缩应用,大家可以感受一下. https://huggi ...