基于云服务MRS构建DolphinScheduler2调度系统
摘要:本文介绍如何搭建DolphinScheduler并运行MRS作业。
本文分享自华为云社区《基于云服务MRS构建DolphinScheduler2调度系统》,作者: 啊喔YeYe 。
为什么写这篇文章?
- 网上关于DolphinScheduler的介绍很多但是都缺少了与实际大数据平台结合的案例指导。
- DolphinScheduler1.x版本,2.x重构了内核实现,性能提升20倍!但是因为重构导致2.x与1.x部署过程存在差异,按照1.x部署2.x版本存在不少坑。
- 选择轻量化、免运维、低成本的大数据云服务是业界趋势,如果搭建DolphinScheduler再同步自建一套Hadoop生态成本太高!因此我们通过结合华为云MRS服务构建数据中台。
环境准备
- dolphinscheduler2.0.3安装包
- MRS 3.1.0普通集群
- Mysql安装包 5.7.35
- ECS centos7.6
安装MRS 客户端
MRS客户端提供java、python开发环境,也提供开通集群中各组件的环境变量:Hadoop、hive、hbase、flink等。
参见登录ECS安装集群外客户端
安装MySQL服务
1. 创建ECS用户
为了方便数据库管理,对于安装的MySQL数据库,生产上建立了一个mysql用户和mysql用户组:
# 添加mysql用户组
groupadd mysql
# 添加mysql用户
useradd -g mysql mysql -d /home/mysql
# 修改mysql用户的登陆密码
passwd ****
2.解压安装包
```
cd /usr/local/
tar -xzvf mysql-5.7.13-linux-glibc2.5-x86_64.tar.gz
# 改名为mysql
mv mysql-5.7.13-linux-glibc2.5-x86_64 mysql
```
赋予用户读写权限
chown -R mysql:mysql mysql/
3. 配置文件初始化
1. 创建配置文件my.cnf
```
vim /etc/my.cnf [client]
port = 3306
socket = /tmp/mysql.sock [mysqld]
character_set_server=utf8
init_connect='SET NAMES utf8'
basedir=/usr/local/mysql
datadir=/usr/local/mysql/data
socket=/tmp/mysql.sock
log-error=/var/log/mysqld.log
pid-file=/var/run/mysqld/mysqld.pid
#不区分大小写
lower_case_table_names = 1 sql_mode=STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION max_connections=5000 default-time_zone = '+8:00'
```
2. 初始化log文件,防止没有权限
```
#手动编辑一下日志文件,什么也不用写,直接保存退出
cd /var/log/
vim mysqld.log
:wq 退出保存
chmod 777 mysqld.log
chown mysql:mysql mysqld.log
```
3. 初始化pid文件,防止没有权限
```
cd /var/run/
mkdir mysqld
cd mysqld
vi mysqld.pid
:wq保存退出
# 赋权
cd ..
chmod 777 mysqld
chown -R mysql:mysql /mysqld
```
4. 初始化数据库
初始化数据库,并指定启动mysql的用户,否则就会在启动MySQL时出现权限不足的问题
/usr/local/mysql/bin/mysqld --initialize --user=mysql --basedir=/usr/local/mysql --datadir=/usr/local/mysql/data --lc_messages_dir=/usr/local/mysql/share --lc_messages=en_US
初始化完成后,在my.cnf中配置的datadir目录(/var/log/mysqld.log)下生成一个error.log文件,里面记录了root用户的随机密码。
cat /var/log/mysqld.log
执行后记录最后一行:root@localhost: xxxxx 。 这里的xxxxx就是初始密码。后面登入数据库要用到。
4. 启动数据库
#源目录启动:
/usr/local/mysql/support-files/mysql.server start
设置开机自启动服务
# 复制启动脚本到资源目录
cp /usr/local/mysql/support-files/mysql.server /etc/rc.d/init.d/mysqld # 增加mysqld服务控制脚本执行权限
chmod +x /etc/rc.d/init.d/mysqld # 将mysqld服务加入到系统服务
chkconfig --add mysqld # 检查mysqld服务是否已经生效
chkconfig --list mysqld # 切换至mysql用户,启动mysql,或者稍后下一步再启动。
service mysqld start
# 从此就可以使用service mysqld命令启动/停止服务
su mysql
service mysqld start
service mysqld stop
service mysqld restart
5.登陆,修改密码,预置dolphinscheduler的用户
1. 修改密码
```
# 系统默认会查找/usr/bin下的命令;建立一个链接文件。
ln -s /usr/local/mysql/bin/mysql /usr/bin
# 登陆mysql的root用户
mysql -uroot -p
# 输入上面的默认初始密码(root@localhost: xxxxx)
# 修改root用户密码为XXXXXX
set password for root@localhost=password("XXXXXX");
```
2. 预置dolphinscheduler的用户
```
mysql -uroot -p
mysql>CREATE DATABASE dolphinscheduler DEFAULT CHARACTER SET utf8 DEFAULT COLLATE utf8_general_ci;
# 修改 {user} 和 {password} 为你希望的用户名和密码,192.168.56.201是我的主机ID
mysql> GRANT ALL PRIVILEGES ON dolphinscheduler.* TO 'dolphinscheduler'@'%' IDENTIFIED BY 'dolphinscheduler';
mysql> GRANT ALL PRIVILEGES ON dolphinscheduler.* TO 'dolphinscheduler'@'localhost' IDENTIFIED BY 'dolphinscheduler';
mysql> GRANT ALL PRIVILEGES ON dolphinscheduler.* TO 'dolphinscheduler'@'192.168.56.201' IDENTIFIED BY 'dolphinscheduler';
#刷新权限
mysql> flush privileges;
#检查是否创建用户成功
mysql> show databases;
#出现dolphinscheduler,查看创建的用户
mysql> use mysql;
mysql> select User,authentication_string,Host from user;
```
安装dolphinscheduler服务
1. 建立本机id免密
在任意文件夹下进行这一步均可,为防止误会,我在dolphinscheduler203进行这一步,创建用户dolphinscheduler,后面所有操作都是再这个用户下做的。设置root免密登录该用户:
# 创建用户需使用 root 登录
useradd dolphinscheduler
# 添加密码
echo "dolphinscheduler" | passwd --stdin dolphinscheduler
# 配置 sudo 免密
sed -i '$adolphinscheduler ALL=(ALL) NOPASSWD: NOPASSWD: ALL' /etc/sudoers
sed -i 's/Defaults requirett/#Defaults requirett/g' /etc/sudoers
# 修改目录权限,在这一步前将jdbcDriver(我的mysql版本5.6.1,driver版本8.0.16)放入lib里,一并修改权限
chown -R dolphinscheduler:dolphinscheduler dolphinscheduler203
#进入新用户
su dolphinscheduler ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
chmod 600 ~/.ssh/authorized_keys
2. 修改配置参数
- 修改install-config.conf文件
[dolphinscheduler@km1 dolphinscheduler203]$ vi conf/config/install-config.conf
修改:
ips="192.168.56.201"
masters="192.168.56.201"
workers="192.168.56.201:default"
alertServer="192.168.56.201"
apiServers="192.168.56.201"
pythonGatewayServers="192.168.56.201"
# DolphinScheduler安装路径,如果不存在会创建,这里不能放你解压后的ds路径,放置后在运行代码时同名文件、文件夹会冲突导致消失
installPath="/opt/dolphinscheduler203"
# 部署用户,填写在 **配置用户免密及权限** 中创建的用户
deployUser="dolphinscheduler"
# ---------------------------------------------------------
# DolphinScheduler ENV
# ---------------------------------------------------------
# 安装的JDK中 JAVA_HOME 所在的位置
javaHome="/opt/hadoopclient/JDK/jdk1.8.0_272"
# ---------------------------------------------------------
# Database
# ---------------------------------------------------------
# 数据库的类型,用户名,密码,IP,端口,元数据库db。其中 DATABASE_TYPE 目前支持 mysql, postgresql, H2
# 请确保配置的值使用双引号引用,否则配置可能不生效
DATABASE_TYPE="mysql"
SPRING_DATASOURCE_URL="jdbc:mysql://192.168.56.201:3306/dolphinscheduler?useUnicode=true&characterEncoding=UTF-8"
# 如果你不是以 dolphinscheduler/dolphinscheduler 作为用户名和密码的,需要进行修改
SPRING_DATASOURCE_USERNAME="dolphinscheduler"
SPRING_DATASOURCE_PASSWORD="dolphinscheduler"
# ---------------------------------------------------------
# Registry Server
# ---------------------------------------------------------
# 注册中心地址,zookeeper服务的地址
registryServers="192.168.56.201:2181"
zk地址获取方式:
登录manager,访问zookeeper服务,copy管理ip即可(前提ECS与MRS集群网络已打通):
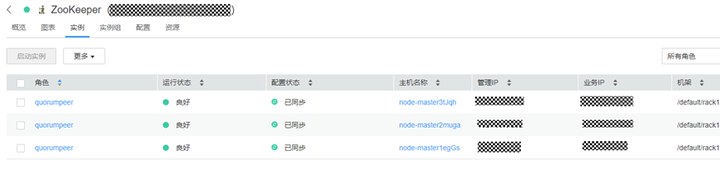
2. 修改 conf/env 目录下的 dolphinscheduler_env.sh
以相关用到的软件都安装在/opt/Bigdata/client下为例:
• export HADOOP_HOME=/opt/Bigdata/client/HDFS/Hadoop
• export HADOOP_CONF_DIR=/opt/Bigdata/client/HDFS/Hadoop
• export SPARK_HOME2=/opt/Bigdata/client/Spark2x/spark
• export PYTHON_HOME=/usr/bin/pytho
• export JAVA_HOME=/opt/Bigdata/client/JDK/jdk1.8.0_272
• export HIVE_HOME=/opt/Bigdata/client/Hive/Beeline
• export FLINK_HOME=/opt/Bigdata/client/Flink/flink
• export DATAX_HOME=/xxx/datax/bin/datax.py
• export PATH=$HADOOP_HOME/bin:$SPARK_HOME2/bin:$PYTHON_HOME:$JAVA_HOME/bin:$HIVE_HOME/bin:$PATH:$FLINK_HOME/bin:$DATAX_HOME:$PATH
说明
- 这一步非常重要,例如 JAVA_HOME 和 PATH 是必须要配置的,没有用到的可以忽略或者注释掉
- 环境变量查找方式说明:假设MRS客户端安装在/opt/Bigdata/client
source /opt/client/bigdata_env
HADOOP_HOME环境地址:通过echo $HADOOP_HOME获得 /opt/Bigdata/client/HDFS/Hadoop
HADOOP_CONF_DIR:/opt/Bigdata/client/HDFS/Hadoop
SPARK_HOME: 通过echo $SPARK_HOME获得/opt/Bigdata/client/Spark2x/spark
JAVA_HOME: 通过echo $JAVA_HOME获得/opt/Bigdata/client/JDK/jdk1.8.0_272
HIVE_HOME:通过echo $HIVE_HOME获得/opt/Bigdata/client/Hive/Beeline
FLINK_HOME:通过echo $FLINK_HOME 获得/opt/Bigdata/client/Flink/flink
3. 将mysql 驱动包放入lib下

tar -zxvf mysql-connector-java-5.1.47.tar.gz

cp mysql-connector-java-5.1.47.jar /opt/dolphinscheduler203/lib/
4.创建元数据库数据表
执行sh script/create-dolphinscheduler.sh
5. 服务安装、启停
每次启停都可以重新部署一次:sh install.sh
启停命令
# 一键停止集群所有服务
sh ./bin/stop-all.sh # 一键开启集群所有服务
sh ./bin/start-all.sh # 启停 Master
sh ./bin/dolphinscheduler-daemon.sh stop master-server
sh ./bin/dolphinscheduler-daemon.sh start master-server # 启停 Worker
sh ./bin/dolphinscheduler-daemon.sh start worker-server
sh ./bin/dolphinscheduler-daemon.sh stop worker-server # 启停 Api
sh ./bin/dolphinscheduler-daemon.sh start api-server
sh ./bin/dolphinscheduler-daemon.sh stop api-server # 启停 Logger
sh ./bin/dolphinscheduler-daemon.sh start logger-server
sh ./bin/dolphinscheduler-daemon.sh stop logger-server # 启停 Alert
sh ./bin/dolphinscheduler-daemon.sh start alert-server
sh ./bin/dolphinscheduler-daemon.sh stop alert-server # 启停 Python Gateway
sh ./bin/dolphinscheduler-daemon.sh start python-gateway-server
sh ./bin/dolphinscheduler-daemon.sh stop python-gateway-server
6. 登录系统
访问前端页面地址:http://xxx:12345/dolphinscheduler
用户名密码:admin/dolphinscheduler123

提交MRS任务
1.登录进入dolphinscheduler webui
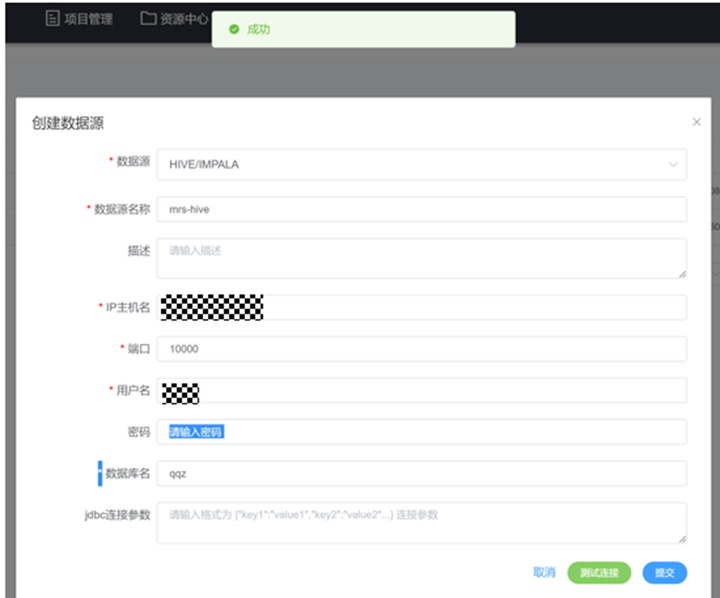
2. 配置MRS-hive连接
登录mrs manager查看hiveserver ip:

创建Hive数据连接,普通集群没有权限可以使用默认用户hive,如有需要可以使用在MRS里面已经创建的用户:
3. 创建任务
1、创建项目
2、创建工作流
3、在工作流编辑任务
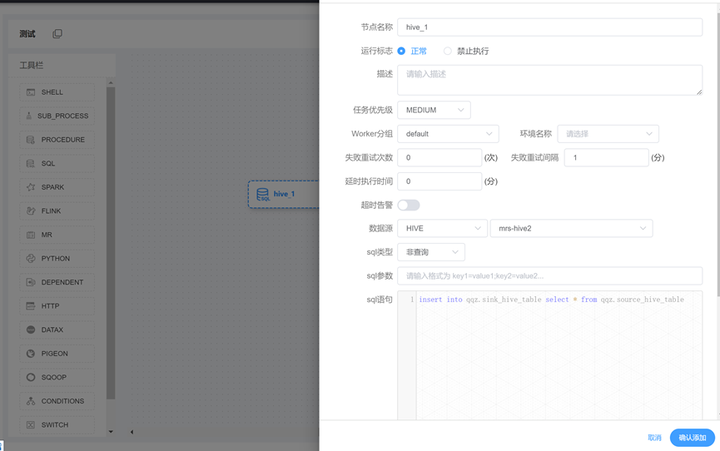
4、任务上线
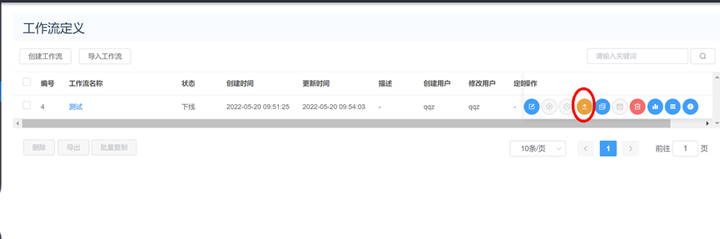
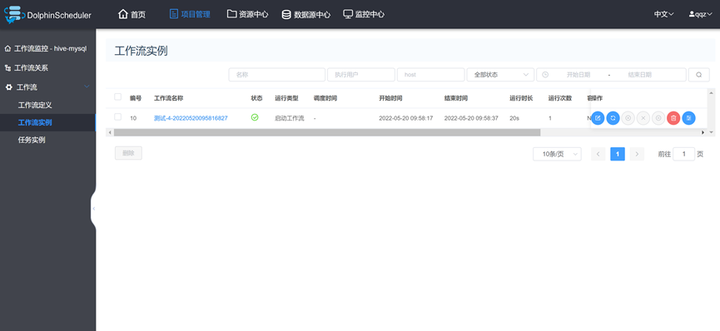
5、启动任务流之后可以查询工作流实例和任务实例
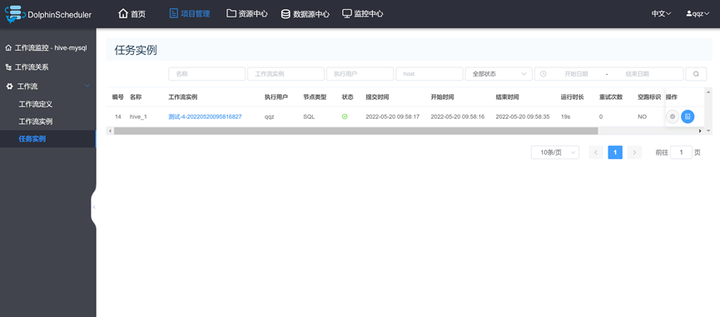
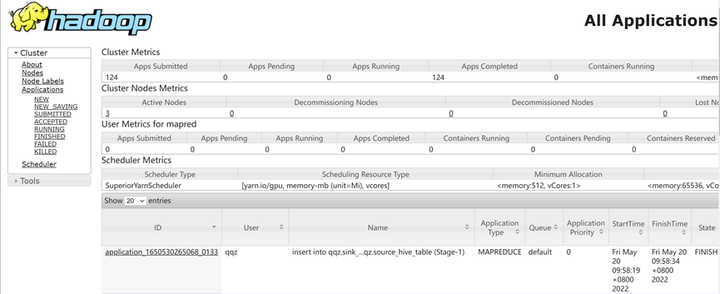
6、登录Manager页面,选择“集群 > 服务 > Yarn > 概览”
7、单击“ResourceManager WebUI”后面对应的链接,进入Yarn的WebUI页面,查看Spark任务是否运行
华为伙伴暨开发者大会2022火热来袭,重磅内容不容错过!
【精彩活动】
勇往直前·做全能开发者→12场技术直播前瞻,8大技术宝典高能输出,还有代码密室、知识竞赛等多轮神秘任务等你来挑战。即刻闯关,开启终极大奖!点击踏上全能开发者晋级之路吧!
【技术专题】
未来已来,2022技术探秘→华为各领域的前沿技术、重磅开源项目、创新的应用实践,站在智能世界的入口,探索未来如何照进现实,干货满满点击了解
基于云服务MRS构建DolphinScheduler2调度系统的更多相关文章
- Kubernetes 降本增效标准指南 | 基于K8s 扩展机制构建云上成本控制系统
作者 王玉君,腾讯云后台高级开发工程师,负责腾讯云原生系统开发及建设. 晏子怡,腾讯云容器产品经理,在K8s弹性伸缩.资源管理领域有丰富的实战经验. 导语 Kubernetes 作为 IaaS 和 P ...
- Windows Azure案例分析: 选择虚拟机或云服务?
作者 王枫 发布于2013年6月27日 随着云计算技术和市场的日渐成熟,企业在考虑IT管理和运维时的选择也更加多样化,应用也从传统部署方式,发展为私有云.公有云.和混合云等部署方式.作为微软核心的公有 ...
- [转]在 Azure 云服务上设计大规模服务的最佳实践
本文转自:http://technet.microsoft.com/zh-cn/magazine/jj717232.aspx 英文版:http://msdn.microsoft.com/library ...
- 华为云FusionInsight MRS:助力企业构建“一企一湖,一城一湖”
摘要:华为云FusionInsight MRS新一代的数据湖,让大数据越用越快.越用越易.越用越稳.越用越省!让数据价值近在眼前! 10月30日,以"携手共赢·数创未来"为主题的第 ...
- 基于云原生DevOps服务自动化部署前端项目学习总结
本文主要以部署前端Vue项目为例,讲述了如何基于云原生DevOps服务自动化部署前端项目~从开发完成到线上环境,我们只需提交代码即可~ 一.引言 作为一名开发人员,日常工作中我们除了需要负责代码的开发 ...
- 基于MRS-ClickHouse构建用户画像系统方案介绍
业务场景 用户画像是对用户信息的标签化.用户画像系统通过对收集的各维度数据,进行深度的分析和挖掘,给不同的用户打上不同的标签,从而刻画出客户的全貌.通过用户画像系统,可以对各个用户进行精准定位,从而将 ...
- 基于AWS的云服务架构最佳实践
ZZ from: http://blog.csdn.net/wireless_com/article/details/43305701 近年来,对于打造高度可扩展的应用程序,软件架构师们挖掘了若干相关 ...
- 微服务架构:基于微服务和Docker容器技术的PaaS云平台架构设计(微服务架构实施原理)
版权声明:本文为博主原创文章,转载请注明出处,欢迎交流学习! 基于微服务架构和Docker容器技术的PaaS云平台建设目标是给我们的开发人员提供一套服务快速开发.部署.运维管理.持续开发持续集成的流程 ...
- 整合SPRING CLOUD云服务架构 - 企业分布式微服务云架构构建
整合SPRING CLOUD云服务架构 - 企业分布式微服务云架构构建 1. 介绍 Commonservice-system是一个大型分布式.微服务.面向企业的JavaEE体系快速研发平台,基于模 ...
随机推荐
- java中如果我老是少捕获什么异常,如何处理?
马克-to-win:程序又一次在出现问题的情况下,优雅结束了.上例中蓝色部分是多重捕获catch.马克-to-win:观察上面三个例子,结论就是即使你已经捕获了很多异常,但是假如你还是少捕获了什么异常 ...
- HTTP长连接和短连接及应用情景
HTTP短连接 HTTP/1.0中默认使用短连接, 客户端和服务器进行一次HTTP操作, 就需要建立一次连接, 任务结束连接也关闭. 当客户端浏览器访问的web网页中包含其他的web资源时, 每遇到一 ...
- Spring Boot-自动配置之底层原理
一.SpringBoot启动的时候加载主配置类,开启了自动配置的功能 @SpringBootApplication public class SpringBoot02Application { pub ...
- Eureka Server 的 Instance Status 一直显示主机名问题
Eureka Server 的 Instance Status 一直显示主机名问题 注册中心启动后,访问 http://localhost:8761/ 后: 如何调整为具体所在的服务器 IP 呢? 解 ...
- Java之万年历
@(文章目录) 二.Java之万年历 2.1 要求 输入年份: 输入月份: 输出某年某月的日历. 2.2 思路 实现从控制台接收年和月,判断是否是闰年(判断是否是闰年:能被4整除但不能被100整除:或 ...
- 简单的js提示框,仅仅用jq和css就可以
首先定义一个盒子 1 .pop { 2 position: fixed; 3 top: 20%; 4 left: 50%; 5 transform: translate(-50%); 6 width: ...
- 微信小程序一些标签
wxml标签 一.视图容器(View Container): 二.基础内容(Basic Content) 标签名 说明 标签名 说明 view 视图容器 icon 图标 scroll-view ...
- 你能知道的或者不知道的shell变量都在这里
第2章 shell变量讲解 2.1 shell中的变量讲解 2.1.1 什么是shell变量 变量的本质就是内存中的一块区域 变量名 位置 变量是脚本中经常会使用的内容信息 变量可以在脚本中直接使用 ...
- Spark SQL底层执行流程详解
本文目录 一.Apache Spark 二.Spark SQL发展历程 三.Spark SQL底层执行原理 四.Catalyst 的两大优化 一.Apache Spark Apache Spark是用 ...
- MySQL进阶之常用函数
我的小站 有时候,除了简单的数据查询,我们还有一些高级的函数. MySQL 包含了大量并且丰富的函数,这套 MySQL 函数大全只收集了几十个常用的,剩下的比较罕见的函数我们就不再整理了,读者可以到M ...