Dilated Neighborhood Attention Transformer概述
0.前言
发表时间:arxiv2022(2022.9.29)
1.针对的问题
之前的方法通过局部注意力机制来降低计算复杂度,但这削弱了自注意力的两个最理想特性:长程相互依赖建模和全局感受野。
2.主要贡献
•引入DiNA,一个简单、灵活和强大的稀疏全局注意力模式,它允许感受野指数增长,并捕获更长的上下文,而无需任何额外的计算负担。DiNA做到了这一点,同时保持了NA中引入的邻域的对称性。它还可以适应更大的分辨率,而无需扩展到更大的窗口尺寸。
•分析基于卷积,局部注意力和基于DiNA的模型中的理论感受野大小。
•引入DiNAT,一种新的分层视觉transformer,包括邻域注意力的膨胀和非膨胀变种。DiNAT利用了模型的渐进膨胀变化,更优化地扩展了感受野,有助于从细到粗的特征学习。
•使用DiNAT对图像分类、目标检测、实例和语义分割进行了广泛的实验,发现它在下游任务中比基于注意力和卷积的基线有明显的改善。此外,我们研究了各向同性和混合注意力变量,使用ImageNet-22K预训练的缩放实验,以及不同膨胀值的影响。
•通过增加膨胀支持和bfloat16使用能力,扩展NATTEN, 即NA对PyTorch的CUDA扩展,允许该方向的研究扩展到其他任务和应用。
3.方法
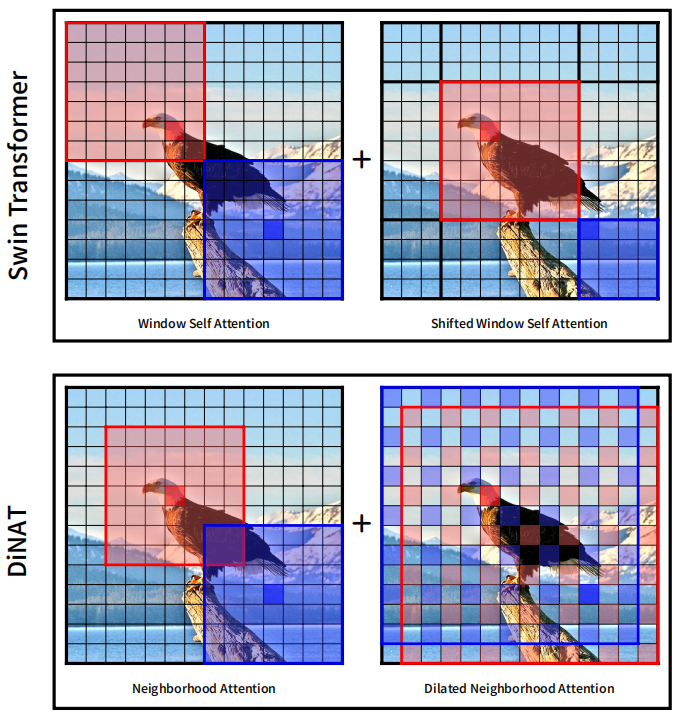
其实就是把膨胀卷积(空洞卷积)与作者之前的工作邻域注意力(NA)相结合,得到DiNA(Dilated Neighborhood attention),这是一种灵活而强大的稀疏全局注意力机制。它存在3个优点:1.捕获了更多的全局上下文。2.允许感受野指数增长。3.没有额外计算成本。Swin与DiNAT对比如下:
公式定义与自注意力类似,就是计算局限于邻域,DiNA的计算与NA类似,在NA中,如果ρj(i)表示token i的第j个最近邻,则在DiNA中,给定一个膨胀值δ,简单地将ρδj(i)定义为token i的第j个最近邻,满足:j mod δ = i mod δ。然后就可以将邻域大小为k的第i个token的δ膨胀率邻域注意力Ai(k,δ)定义为:
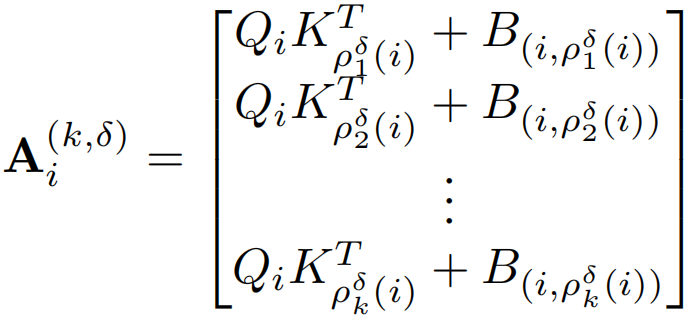
与上面类似得到
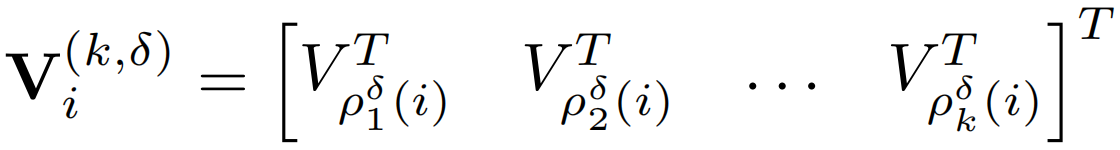
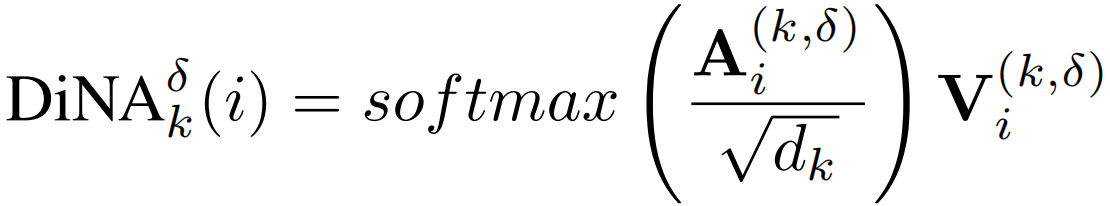
模型结构如下,与NAT模型相同:
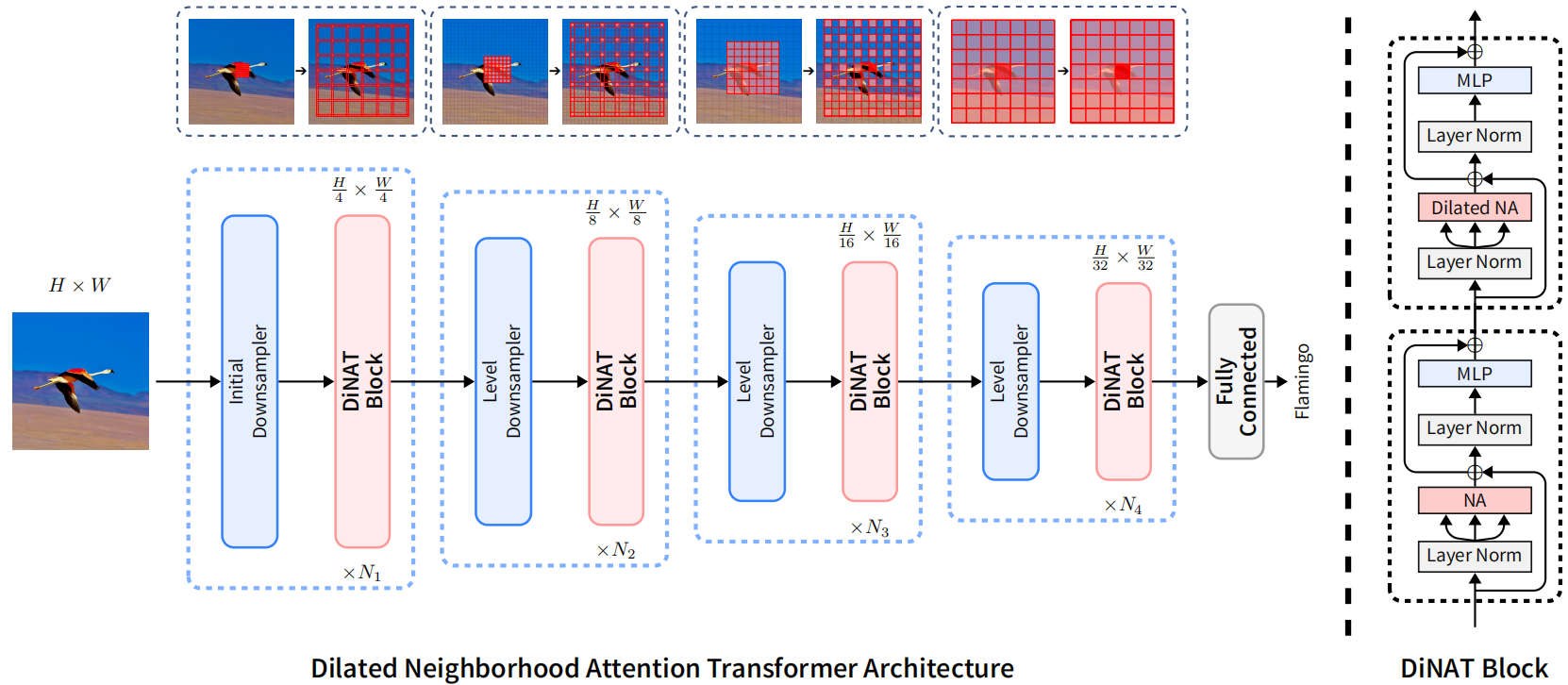
4.补充
1.其实在NA之前就已经有类似卷积的注意力相关工作SASA了,但是效果却并不好,运行速度很慢,之前的观点普遍认为像这种注意力操作被认为效率极低且难以并行化,这也是Window Self Attention背后的动机之一,NA开始也存在同样的限制,即缺乏有效的实现,因为当时的深度学习或CUDA库都没有直接实现这样的操作,也是在NATTEN(邻域注意力CUDA扩展)出现之后在表现出效果。
2.论文中提到Swin由于其特殊的移位窗口设计,相比NAT和ConvNeXt拥有略大的接受域,但它打破了一个重要的属性:对称性。由于Swin的特征映射被划分为不重叠的窗口,同一窗口内的像素只关注彼此,而不考虑它们的位置(无论是在中心还是角落),这导致一些像素在周围看到不对称的上下文。
Dilated Neighborhood Attention Transformer概述的更多相关文章
- Attention & Transformer
Attention & Transformer seq2seq; attention; self-attention; transformer; 1 注意力机制在NLP上的发展 Seq2Seq ...
- 2. Attention Is All You Need(Transformer)算法原理解析
1. 语言模型 2. Attention Is All You Need(Transformer)算法原理解析 3. ELMo算法原理解析 4. OpenAI GPT算法原理解析 5. BERT算法原 ...
- 深度学习之Attention Model(注意力模型)
1.Attention Model 概述 深度学习里的Attention model其实模拟的是人脑的注意力模型,举个例子来说,当我们观赏一幅画时,虽然我们可以看到整幅画的全貌,但是在我们深入仔细地观 ...
- [深度概念]·Attention Model(注意力模型)学习笔记
此文源自一个博客,笔者用黑体做了注释与解读,方便自己和大家深入理解Attention model,写的不对地方欢迎批评指正.. 1.Attention Model 概述 深度学习里的Attention ...
- 深入浅出Transformer
Transformer Transformer是NLP的颠覆者,它创造性地用非序列模型来处理序列化的数据,而且还获得了大成功.更重要的是,NLP真的可以"深度"学习了,各种基于tr ...
- [NLP] REFORMER: THE EFFICIENT TRANSFORMER
1.现状 (1) 模型层数加深 (2) 模型参数量变大 (3) 难以训练 (4) 难以fine-tune 2. 单层参数量和占用内存分析 层 参数设置 参数量与占用内存 1 layer 0.5Bill ...
- 文本建模、文本分类相关开源项目推荐(Pytorch实现)
Awesome-Repositories-for-Text-Modeling repo paper miracleyoo/DPCNN-TextCNN-Pytorch-Inception Deep Py ...
- 关于NLP和深度学习,准备好好看看这个github,还有这篇介绍
这个github感觉很不错,把一些比较新的实现都尝试了: https://github.com/brightmart/text_classification fastText TextCNN Text ...
- BERT解析及文本分类应用
目录 前言 BERT模型概览 Seq2Seq Attention Transformer encoder部分 Decoder部分 BERT Embedding 预训练 文本分类试验 参考文献 前言 在 ...
- ACNet: 特别的想法,腾讯提出结合注意力卷积的二叉神经树进行细粒度分类 | CVPR 2020
论文提出了结合注意力卷积的二叉神经树进行弱监督的细粒度分类,在树结构的边上结合了注意力卷积操作,在每个节点使用路由函数来定义从根节点到叶子节点的计算路径,结合所有叶子节点的预测值进行最终的预测,论文的 ...
随机推荐
- myql数据库新建之后,本地可以访问,远程访问不了
通过如下命令去修改: use mysql; update user set user.Host='%' where user.User='root'; flush privileges;
- c++练习266题:楼层编号
*266题 原题传送门:http://oj.tfls.net/p/266 题解: #include<bits/stdc++.h>using namespace std; int t;//高 ...
- 【面试题】ES6语法五之箭头函数
ES6特性=>. function foo(x, y){ return x + y } var foo = (x, y) => x + y 包括一个参数列表(零个或多个参数,如果参数不是一 ...
- 批量创建xshell会话
import re import os import openpyxl from openpyxl import Workbook,workbook from concurrent.futures i ...
- CI2454 低成本高性能SOC产品 遥控产品的绝佳选择
Ci2454 是一款集成无线收发器和 8 位 RISC(精简指令集)MCU 的 SOC 芯 片. 无线收发器特性: 工作在 2.4GHz ISM 频段. 调制方式:GFSK/FSK. 数据 ...
- js-防抖(简易版)
/** * 节流函数 */ var count = 1; var container = document.getElementById('container'); function getUse ...
- MongoDB 6.0.4 安装记录
须知:版本号x.y.z,看y:偶数版为稳定版,奇数版为开发版 (1)下载zip,解压 1 https://fastdl.mongodb.org/windows/mongodb-windows-x86_ ...
- 发送QQ消息
#include <iostream>#include <windows.h>#include <vector> using namespace std;int m ...
- Laravel ORM 常用方法
1. 数据查询 ->find($id); //需要一个主键$id并返回一个模型对象.若不存在则返回null ->findOrFail($id); //需要一个主键$id并返回一个模型对 ...
- HelloWorld (用记事本写,在dos窗口里运行)
编写HelloWorld (用记事本写,在dos窗口里运行) 首先在任何一个盘中创建一个文件夹 在文件夹里新建一个HelloWorld.java文件,注意后缀名是.java(将文件拓展名打开) 打开这 ...