requests模块之post请求传参json和data区别
post请求参数到底是传data还是json,此时要看请求头里的content-type类型
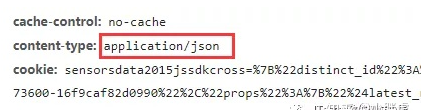
请求头中content-type为application/json, 为json形式,post请求使用json参数
请求头中content-type为application/x-www-form-urlencoded为表单形式,post请求时使用使用data参数
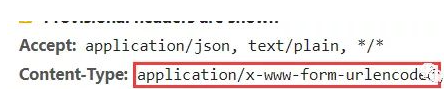
当前接口的请求类型为application/x-www-form-urlencoded,data形式发送post请求
#导入requests模块
import requests
#请求url
url="http://127.0.0.1:8000/user/login"
#请求参数
payload={
"mobilephone":"1530272****",
"pwd":"123456"}
form表单形式,参数用data
res=requests.post(url,data=payload)
print(res.text)
当前接口的请求类型为application/json,json形式发送post请求
import requests
url='http://127.0.0.1:8000/user/login/'
headers={"content-type":"application/json"}
payload={"username":"vivi","password":"123456"}
res=requests.post(url,json=payload,headers=headers)
print(res.text)
当前接口的请求类型为application/json,简单点用json形式发送post请求,但也可通过data发送需将字典类型转化为json字符串
import requests
import json
payload={"username":"vivi","password":"123456"}
header={"content-type":"application/json"}
#字典转化为json串
data=json.dumps(payload)
url='http://127.0.0.1:8000/user/login/'
res=requests.post(url,data=data,headers=header)
print(res.text)
requests模块之post请求传参json和data区别的更多相关文章
- scrapy模块之分页处理,post请求,cookies处理,请求传参
一.scrapy分页处理 1.分页处理 如上篇博客,初步使用了scrapy框架了,但是只能爬取一页,或者手动的把要爬取的网址手动添加到start_url中,太麻烦接下来介绍该如何去处理分页,手动发起分 ...
- 13.scrapy框架的日志等级和请求传参
今日概要 日志等级 请求传参 如何提高scrapy的爬取效率 今日详情 一.Scrapy的日志等级 - 在使用scrapy crawl spiderFileName运行程序时,在终端里打印输出的就是s ...
- requests中get和post传参
get请求 get(url, params=None, **kwargs) requests实现get请求传参的两种方式 方式一: import requests url = 'http://www. ...
- scrapy框架的日志等级和请求传参
日志等级 请求传参 如何提高scrapy的爬取效率 一.Scrapy的日志等级 - 在使用scrapy crawl spiderFileName运行程序时,在终端里打印输出的就是scrapy的日志信息 ...
- scrapy框架的日志等级和请求传参, 优化效率
目录 scrapy框架的日志等级和请求传参, 优化效率 Scrapy的日志等级 请求传参 如何提高scripy的爬取效率 scrapy框架的日志等级和请求传参, 优化效率 Scrapy的日志等级 在使 ...
- 12 Scrapy框架的日志等级和请求传参
一.Scrapy的日志等级 - 在使用scrapy crawl spiderFileName运行程序时,在终端里打印输出的就是scrapy的日志信息. - 日志信息的种类: ERROR : 一般错误 ...
- [转]ASP.NET MVC学习系列(二)-WebAPI请求 传参
[转]ASP.NET MVC学习系列(二)-WebAPI请求 传参 本文转自:http://www.cnblogs.com/babycool/p/3922738.html ASP.NET MVC学习系 ...
- scrapy框架之日志等级和请求传参-cookie-代理
一.Scrapy的日志等级 - 在使用scrapy crawl spiderFileName运行程序时,在终端里打印输出的就是scrapy的日志信息. - 日志信息的种类: ERROR : 一般错误 ...
- Scrapy的日志等级和请求传参
日志等级 日志信息: 使用命令:scrapy crawl 爬虫文件 运行程序时,在终端输出的就是日志信息: 日志信息的种类: ERROR:一般错误: WARNING:警告: INFO:一般的信息: ...
- 爬虫开发10.scrapy框架之日志等级和请求传参
今日概要 日志等级 请求传参 今日详情 一.Scrapy的日志等级 - 在使用scrapy crawl spiderFileName运行程序时,在终端里打印输出的就是scrapy的日志信息. - 日志 ...
随机推荐
- C# 中 SetTimeout 方案
近期项目中需在用户点击按钮后,延时执行代码逻辑,避免频繁操作.网上没找到有关 C# SetTimeout 官方API , 于是通过异步线程,动手实现一个.方案如下,如果同一个DelayedProces ...
- rabbitMQ queue属性
Map<String, Object> args = new HashMap<String, Object>(); args.put("x-message-ttl&q ...
- ubuntu 逻辑卷增加磁盘
使用lv* 相关的命令 lvdisplay lvscan ACTIVE '/dev/ubuntu-vg/ubuntu-lv' [<74.00 GiB] inherit lv ...
- django项目中使用swagger来实现接口文档自动生成
一.Swagger 一般我们在对接前后端的时候,都需要提供相应的接口文档.对于后端来说,编写接口文档即费时费力,还会经常因为没有及时更新,导致前端对接时出现实际接口与文档不一致.而且手写接口文档还容易 ...
- MySQL之Web乱码问题
随笔记录方便自己和同路人查阅. #------------------------------------------------我是可耻的分割线--------------------------- ...
- 打卡node day04--express-get.post.路由
1.基本使用 npm i express 2.请求 get: post: express 不能直接解析请求体,所以需要第三方插件 ---->body-parser 使用 npm install ...
- 面试视频知识点整理1-7(http协议)
http协议类 1)http协议的主要特点 简单快速 统一资源符 灵活 通过http协议,可以修改http头,完成不同数据类型的传输 无连接 ...
- cmd 备份 oracle 数据 dmp文件
语法 : exp 用户名/密码@数据库地址/数据库名 file=文件导出地址/文件名.dmp 实例:exp develop/123@localhost/orcl file=e:/2019-02 ...
- iOS开发之实现自定义浮动操作框效果
今天有个需求是如上图实现类似微信的自定义浮动操作框效果 我自己就写了个demo,大家感兴趣的可以试试,下面是代码 VC代码如下 #import "TestCustomMenuItemVC.h ...
- 网络层-ICMP
为了更有效地转发IP数据报和提高交付成功的机会,在网际层使用了网际控制报文协议ICMP ICMP报文被封闭在IP数据报中发送 封包格式 主机或路由器使用ICMP来发送差错报告报文和询问报文 差错报告报 ...