iOS开发--APP性能检测方案汇总
1 . CPU 占用率
CPU作为手机的中央处理器,可以说是手机最关键的组成部分,所有应用程序都需要它来调度运行,资源有限。所以当我们的APP因设计不当,使 CPU 持续以高负载运行,将会出现APP卡顿、手机发热发烫、电量消耗过快等等严重影响用户体验的现象。
因此我们对应用在CPU中占用率的监控,将变得尤为重要。那么我们应该如何来获取CPU的占有率呢?!
我们都知道,我们的APP在运行的时候,会对应一个Mach Task,而Task下可能有多条线程同时执行任务,每个线程都是作为利用CPU的基本单位。所以我们可以通过获取当前Mach Task下,所有线程占用 CPU 的情况,来计算APP的 CPU 占用率。
在《OS X and iOS Kernel Programming》是这样描述 Mach task 的:
任务(task)是一种容器(container)对象,虚拟内存空间和其他资源都是通过这个容器对象管理的,这些资源包括设备和其他句柄。严格地说,Mach 的任务并不是其他操作系统中所谓的进程,因为 Mach 作为一个微内核的操作系统,并没有提供“进程”的逻辑,而只是提供了最基本的实现。不过在 BSD 的模型中,这两个概念有1:1的简单映射,每一个 BSD 进程(也就是 OS X 进程)都在底层关联了一个 Mach 任务对象。
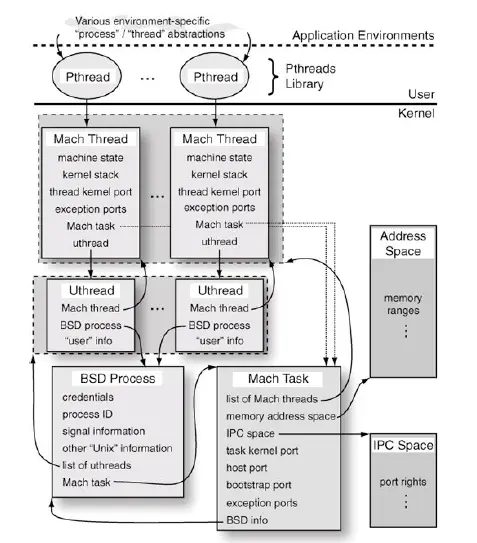

iOS 是基于
Apple Darwin内核,由kernel、XNU和Runtime组成,而XNU是Darwin的内核,它是“X is not UNIX”的缩写,是一个混合内核,由 Mach 微内核和 BSD 组成。Mach 内核是轻量级的平台,只能完成操作系统最基本的职责,比如:进程和线程、虚拟内存管理、任务调度、进程通信和消息传递机制等。其他的工作,例如文件操作和设备访问,都由 BSD 层实现。
iOS 的线程技术与Mac OS X类似,也是基于 Mach 线程技术实现的,在 Mach 层中thread_basic_info 结构体封装了单个线程的基本信息:
struct thread_basic_info {
time_value_t user_time; /* user run time */
time_value_t system_time; /* system run time */
integer_t cpu_usage; /* scaled cpu usage percentage */
policy_t policy; /* scheduling policy in effect */
integer_t run_state; /* run state (see below) */
integer_t flags; /* various flags (see below) */
integer_t suspend_count; /* suspend count for thread */
integer_t sleep_time; /* number of seconds that thread has been sleeping */
}
一个Mach Task包含它的线程列表。内核提供了task_threads API 调用获取指定 task 的线程列表,然后可以通过thread_info API调用来查询指定线程的信息,在 thread_act.h 中有相关定义。
task_threads 将target_task 任务中的所有线程保存在act_list数组中,act_listCnt表示线程个数:
kern_return_t task_threads
(
task_t target_task,
thread_act_array_t *act_list,
mach_msg_type_number_t *act_listCnt
);
thread_info结构如下:
kern_return_t thread_info
(
thread_act_t target_act,
thread_flavor_t flavor, // 传入不同的宏定义获取不同的线程信息
thread_info_t thread_info_out, // 查询到的线程信息
mach_msg_type_number_t *thread_info_outCnt // 信息的大小
);
所以我们如下来获取CPU的占有率:
#import "LSLCpuUsage.h"
#import <mach/task.h>
#import <mach/vm_map.h>
#import <mach/mach_init.h>
#import <mach/thread_act.h>
#import <mach/thread_info.h>
@implementation LSLCpuUsage
+ (double)getCpuUsage {
kern_return_t kr;
thread_array_t threadList; // 保存当前Mach task的线程列表
mach_msg_type_number_t threadCount; // 保存当前Mach task的线程个数
thread_info_data_t threadInfo; // 保存单个线程的信息列表
mach_msg_type_number_t threadInfoCount; // 保存当前线程的信息列表大小
thread_basic_info_t threadBasicInfo; // 线程的基本信息
// 通过“task_threads”API调用获取指定 task 的线程列表
// mach_task_self_,表示获取当前的 Mach task
kr = task_threads(mach_task_self(), &threadList, &threadCount);
if (kr != KERN_SUCCESS) {
return -1;
}
double cpuUsage = 0;
for (int i = 0; i < threadCount; i++) {
threadInfoCount = THREAD_INFO_MAX;
// 通过“thread_info”API调用来查询指定线程的信息
// flavor参数传的是THREAD_BASIC_INFO,使用这个类型会返回线程的基本信息,
// 定义在 thread_basic_info_t 结构体,包含了用户和系统的运行时间、运行状态和调度优先级等
kr = thread_info(threadList[i], THREAD_BASIC_INFO, (thread_info_t)threadInfo, &threadInfoCount);
if (kr != KERN_SUCCESS) {
return -1;
}
threadBasicInfo = (thread_basic_info_t)threadInfo;
if (!(threadBasicInfo->flags & TH_FLAGS_IDLE)) {
cpuUsage += threadBasicInfo->cpu_usage;
}
}
// 回收内存,防止内存泄漏
vm_deallocate(mach_task_self(), (vm_offset_t)threadList, threadCount * sizeof(thread_t));
return cpuUsage / (double)TH_USAGE_SCALE * 100.0;
}
@end
2. 内存
虽然现在的手机内存越来越大,但毕竟是有限的,如果因为我们的应用设计不当造成内存过高,可能面临被系统“干掉”的风险,这对用户来说是毁灭性的体验。
Mach task 的内存使用信息存放在mach_task_basic_info结构体中 ,其中resident_size 为应用使用的物理内存大小,virtual_size为虚拟内存大小,在task_info.h中:
#define MACH_TASK_BASIC_INFO 20 /* always 64-bit basic info */
struct mach_task_basic_info {
mach_vm_size_t virtual_size; /* virtual memory size (bytes) */
mach_vm_size_t resident_size; /* resident memory size (bytes) */
mach_vm_size_t resident_size_max; /* maximum resident memory size (bytes) */
time_value_t user_time; /* total user run time for
terminated threads */
time_value_t system_time; /* total system run time for
terminated threads */
policy_t policy; /* default policy for new threads */
integer_t suspend_count; /* suspend count for task */
};
获取方式是通过task_infoAPI 根据指定的 flavor 类型,返回 target_task 的信息,在task.h中:
kern_return_t task_info
(
task_name_t target_task,
task_flavor_t flavor,
task_info_t task_info_out,
mach_msg_type_number_t *task_info_outCnt
);
笔者尝试过使用如下方式获取内存情况,基本和腾讯的GT的相近,但是和Xcode和Instruments的值有较大差距:
// 获取当前应用的内存占用情况,和Xcode数值相差较大
+ (double)getResidentMemory {
struct mach_task_basic_info info;
mach_msg_type_number_t count = MACH_TASK_BASIC_INFO_COUNT;
if (task_info(mach_task_self(), MACH_TASK_BASIC_INFO, (task_info_t)&info, &count) == KERN_SUCCESS) {
return info.resident_size / (1024 * 1024);
} else {
return -1.0;
}
}
后来看了一篇博主讨论了这个问题,说使用phys_footprint才是正解,博客地址。亲测,基本和Xcode的数值相近。
// 获取当前应用的内存占用情况,和Xcode数值相近
+ (double)getMemoryUsage {
task_vm_info_data_t vmInfo;
mach_msg_type_number_t count = TASK_VM_INFO_COUNT;
if(task_info(mach_task_self(), TASK_VM_INFO, (task_info_t) &vmInfo, &count) == KERN_SUCCESS) {
return (double)vmInfo.phys_footprint / (1024 * 1024);
} else {
return -1.0;
}
}
博主文中提到:关于 phys_footprint 的定义可以在 XNU 源码中,找到 osfmk/kern/task.c 里对于 phys_footprint 的注释,博主认为注释里提到的公式计算的应该才是应用实际使用的物理内存。
/*
* phys_footprint
* Physical footprint: This is the sum of:
* + (internal - alternate_accounting)
* + (internal_compressed - alternate_accounting_compressed)
* + iokit_mapped
* + purgeable_nonvolatile
* + purgeable_nonvolatile_compressed
* + page_table
*
* internal
* The task's anonymous memory, which on iOS is always resident.
*
* internal_compressed
* Amount of this task's internal memory which is held by the compressor.
* Such memory is no longer actually resident for the task [i.e., resident in its pmap],
* and could be either decompressed back into memory, or paged out to storage, depending
* on our implementation.
*
* iokit_mapped
* IOKit mappings: The total size of all IOKit mappings in this task, regardless of
clean/dirty or internal/external state].
*
* alternate_accounting
* The number of internal dirty pages which are part of IOKit mappings. By definition, these pages
* are counted in both internal *and* iokit_mapped, so we must subtract them from the total to avoid
* double counting.
*/
当然我也是赞同这点的>.<。
3. 启动时间
APP的启动时间,直接影响用户对你的APP的第一体验和判断。如果启动时间过长,不单单体验直线下降,而且可能会激发苹果的watch dog机制kill掉你的APP,那就悲剧了,用户会觉得APP怎么一启动就卡死然后崩溃了,不能用,然后长按APP点击删除键。(Xcode在debug模式下是没有开启watch dog的,所以我们一定要连接真机测试我们的APP)
在衡量APP的启动时间之前我们先了解下,APP的启动流程:
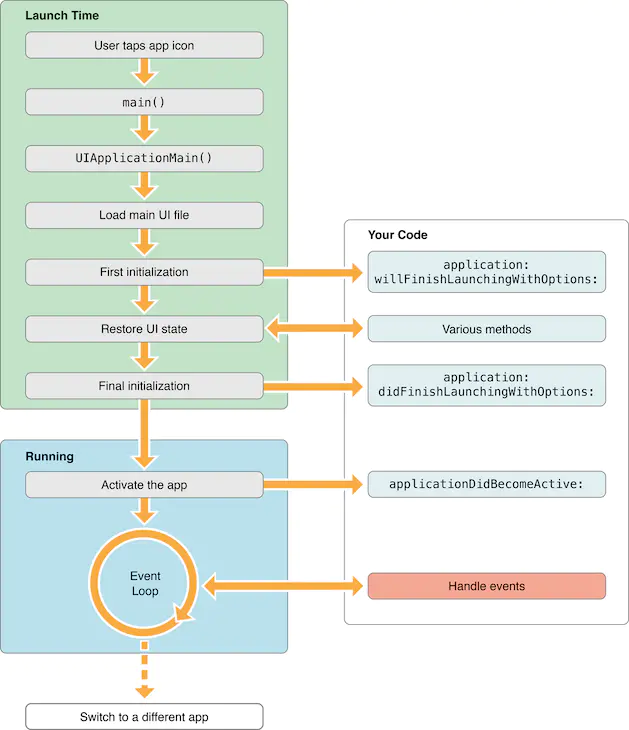

APP的启动可以分为两个阶段,即main()执行之前和main()执行之后。总结如下:
t(App 总启动时间) = t1(
main()之前的加载时间 ) + t2(main()之后的加载时间 )。
- t1 = 系统的 dylib (动态链接库)和 App 可执行文件的加载时间;
- t2 =
main()函数执行之后到AppDelegate类中的applicationDidFinishLaunching:withOptions:方法执行结束前这段时间。
所以我们对APP启动时间的获取和优化都是从这两个阶段着手,下面先看看main()函数执行之前如何获取启动时间。
衡量main()函数执行之前的耗时
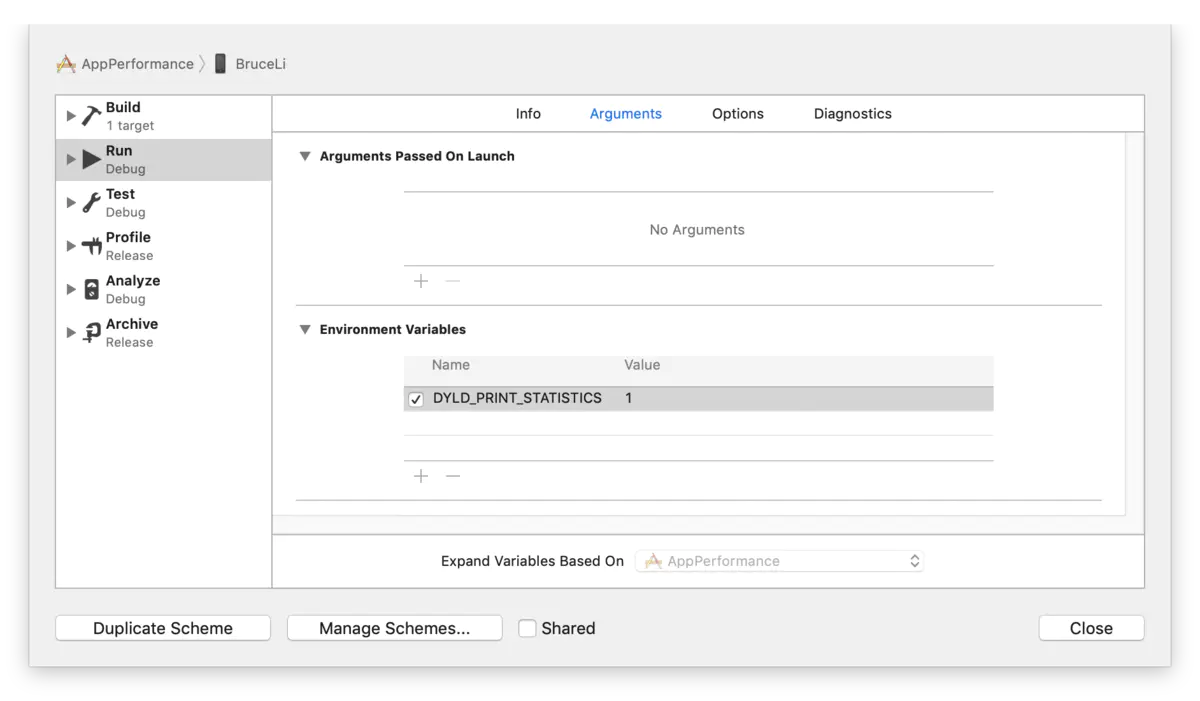
对于衡量main()之前也就是time1的耗时,苹果官方提供了一种方法,即在真机调试的时候,勾选DYLD_PRINT_STATISTICS选项(如果想获取更详细的信息可以使用DYLD_PRINT_STATISTICS_DETAILS),如下图:

输出结果如下:
Total pre-main time: 34.22 milliseconds (100.0%)
dylib loading time: 14.43 milliseconds (42.1%)
rebase/binding time: 1.82 milliseconds (5.3%)
ObjC setup time: 3.89 milliseconds (11.3%)
initializer time: 13.99 milliseconds (40.9%)
slowest intializers :
libSystem.B.dylib : 2.20 milliseconds (6.4%)
libBacktraceRecording.dylib : 2.90 milliseconds (8.4%)
libMainThreadChecker.dylib : 6.55 milliseconds (19.1%)
libswiftCoreImage.dylib : 0.71 milliseconds (2.0%)
系统级别的动态链接库,因为苹果做了优化,所以耗时并不多,而大多数时候,t1的时间大部分会消耗在我们自身App中的代码上和链接第三方库上。
所以我们应如何减少main()调用之前的耗时呢,我们可以优化的点有:
- 减少不必要的
framework,特别是第三方的,因为动态链接比较耗时;check framework应设为optional和required,如果该framework在当前App支持的所有iOS系统版本都存在,那么就设为required,否则就设为optional,因为optional会有些额外的检查;- 合并或者删减一些OC类,关于清理项目中没用到的类,可以借助AppCode代码检查工具:
- 删减一些无用的静态变量
- 删减没有被调用到或者已经废弃的方法
- 将不必须在
+load方法中做的事情延迟到+initialize中- 尽量不要用C++虚函数(创建虚函数表有开销)
衡量main()函数执行之后的耗时
第二阶段的耗时统计,我们认为是从main ()执行之后到applicationDidFinishLaunching:withOptions:方法最后,那么我们可以通过打点的方式进行统计。
Objective-C项目因为有main文件,所以我么直接可以通过添加代码获取:
// 1. 在 main.m 添加如下代码:
CFAbsoluteTime AppStartLaunchTime;
int main(int argc, char * argv[]) {
AppStartLaunchTime = CFAbsoluteTimeGetCurrent();
.....
}
// 2. 在 AppDelegate.m 的开头声明
extern CFAbsoluteTime AppStartLaunchTime;
// 3. 最后在AppDelegate.m 的 didFinishLaunchingWithOptions 中添加
dispatch_async(dispatch_get_main_queue(), ^{
NSLog(@"App启动时间--%f",(CFAbsoluteTimeGetCurrent()-AppStartLaunchTime));
});
大家都知道Swift项目是没有main文件,官方给了如下解释:
In Xcode, Mac templates default to including a “main.swift” file, but for iOS apps the default for new iOS project templates is to add @UIApplicationMain to a regular Swift file. This causes the compiler to synthesize a mainentry point for your iOS app, and eliminates the need for a “main.swift” file.
也就是说,通过添加@UIApplicationMain标志的方式,帮我们添加了mian函数了。所以如果是我们需要在mian函数中做一些其它操作的话,需要我们自己来创建main.swift文件,这个也是苹果允许的。
- 删除
AppDelegate类中的@UIApplicationMain标志;
- 删除
- 自行创建main.swift文件,并添加程序入口:
import UIKit
var appStartLaunchTime: CFAbsoluteTime = CFAbsoluteTimeGetCurrent()
UIApplicationMain(
CommandLine.argc,
UnsafeMutableRawPointer(CommandLine.unsafeArgv)
.bindMemory(
to: UnsafeMutablePointer<Int8>.self,
capacity: Int(CommandLine.argc)),
nil,
NSStringFromClass(AppDelegate.self)
)
- 在AppDelegate的
didFinishLaunchingWithOptions :方法最后添加:
- 在AppDelegate的
// APP启动时间耗时,从mian函数开始到didFinishLaunchingWithOptions方法结束
DispatchQueue.main.async {
print("APP启动时间耗时,从mian函数开始到didFinishLaunchingWithOptions方法:\(CFAbsoluteTimeGetCurrent() - appStartLaunchTime)。")
}
main函数之后的优化:
- 尽量使用纯代码编写,减少xib的使用;
- 启动阶段的网络请求,是否都放到异步请求;
- 一些耗时的操作是否可以放到后面去执行,或异步执行等。
4. FPS
通过维基百科我们知道,FPS是Frames Per Second 的简称缩写,意思是每秒传输帧数,也就是我们常说的“刷新率(单位为Hz)。
FPS是测量用于保存、显示动态视频的信息数量。每秒钟帧数愈多,所显示的画面就会愈流畅,FPS值越低就越卡顿,所以这个值在一定程度上可以衡量应用在图像绘制渲染处理时的性能。一般我们的APP的FPS只要保持在 50-60之间,用户体验都是比较流畅的。
苹果手机屏幕的正常刷新频率是每秒60次,即可以理解为FPS值为60。我们都知道CADisplayLink是和屏幕刷新频率保存一致,所以我们是否可以通过它来监控我们的FPS呢?!
首先CADisplayLink是什么
CADisplayLink是CoreAnimation提供的另一个类似于NSTimer的类,它总是在屏幕完成一次更新之前启动,它的接口设计的和NSTimer很类似,所以它实际上就是一个内置实现的替代,但是和timeInterval以秒为单位不同,CADisplayLink有一个整型的frameInterval属性,指定了间隔多少帧之后才执行。默认值是1,意味着每次屏幕更新之前都会执行一次。但是如果动画的代码执行起来超过了六十分之一秒,你可以指定frameInterval为2,就是说动画每隔一帧执行一次(一秒钟30帧)。
使用CADisplayLink监控界面的FPS值,参考自YYFPSLabel:
import UIKit
class LSLFPSMonitor: UILabel {
private var link: CADisplayLink = CADisplayLink.init()
private var count: NSInteger = 0
private var lastTime: TimeInterval = 0.0
private var fpsColor: UIColor = UIColor.green
public var fps: Double = 0.0
// MARK: - init
override init(frame: CGRect) {
var f = frame
if f.size == CGSize.zero {
f.size = CGSize(width: 55.0, height: 22.0)
}
super.init(frame: f)
self.textColor = UIColor.white
self.textAlignment = .center
self.font = UIFont.init(name: "Menlo", size: 12.0)
self.backgroundColor = UIColor.black
link = CADisplayLink.init(target: LSLWeakProxy(target: self), selector: #selector(tick))
link.add(to: RunLoop.current, forMode: RunLoopMode.commonModes)
}
deinit {
link.invalidate()
}
required init?(coder aDecoder: NSCoder) {
fatalError("init(coder:) has not been implemented")
}
// MARK: - actions
@objc func tick(link: CADisplayLink) {
guard lastTime != 0 else {
lastTime = link.timestamp
return
}
count += 1
let delta = link.timestamp - lastTime
guard delta >= 1.0 else {
return
}
lastTime = link.timestamp
fps = Double(count) / delta
let fpsText = "\(String.init(format: "%.3f", fps)) FPS"
count = 0
let attrMStr = NSMutableAttributedString(attributedString: NSAttributedString(string: fpsText))
if fps > 55.0{
fpsColor = UIColor.green
} else if(fps >= 50.0 && fps <= 55.0) {
fpsColor = UIColor.yellow
} else {
fpsColor = UIColor.red
}
attrMStr.setAttributes([NSAttributedStringKey.foregroundColor:fpsColor], range: NSMakeRange(0, attrMStr.length - 3))
attrMStr.setAttributes([NSAttributedStringKey.foregroundColor:UIColor.white], range: NSMakeRange(attrMStr.length - 3, 3))
DispatchQueue.main.async {
self.attributedText = attrMStr
}
}
}
通过CADisplayLink的实现方式,并真机测试之后,确实是可以在很大程度上满足了监控FPS的业务需求和为提高用户体验提供参考,但是和Instruments的值可能会有些出入。下面我们来讨论下使用CADisplayLink的方式,可能存在的问题。
- (1). 和Instruments值对比有出入,原因如下:
CADisplayLink运行在被添加的那个RunLoop之中(一般是在主线程中),因此它只能检测出当前RunLoop下的帧率。RunLoop中所管理的任务的调度时机,受任务所处的RunLoopMode和CPU的繁忙程度所影响。所以想要真正定位到准确的性能问题所在,最好还是通过Instrument来确认。
- (2). 使用
CADisplayLink可能存在的循环引用问题。
例如以下写法:
let link = CADisplayLink.init(target: self, selector: #selector(tick))
let timer = Timer.init(timeInterval: 1.0, target: self, selector: #selector(tick), userInfo: nil, repeats: true)
原因:以上两种用法,都会对 self 强引用,此时 timer持有 self,self 也持有 timer,循环引用导致页面 dismiss 时,双方都无法释放,造成循环引用。此时使用 weak 也不能有效解决:
weak var weakSelf = self
let link = CADisplayLink.init(target: weakSelf, selector: #selector(tick))
那么我们应该怎样解决这个问题,有人会说在deinit(或dealloc)中调用定时器的invalidate方法,但是这是无效的,因为已经造成循环引用了,不会走到这个方法的。
YYKit作者提供的解决方案是使用 YYWeakProxy,这个YYWeakProxy不是继承自NSObject而是继承NSProxy。
NSProxy
An abstract superclass defining an API for objects that act as stand-ins for other objects or for objects that don’t exist yet.
NSProxy是一个为对象定义接口的抽象父类,并且为其它对象或者一些不存在的对象扮演了替身角色。具体的可以看下NSProxy的官方文档
修改后代码如下,亲测定时器如愿释放,LSLWeakProxy的具体实现代码已经同步到github中。
let link = CADisplayLink.init(target: LSLWeakProxy(target: self), selector: #selector(tick))
5. 卡顿
在了解卡顿产生的原因之前,先看下屏幕显示图像的原理。
屏幕显示图像的原理:
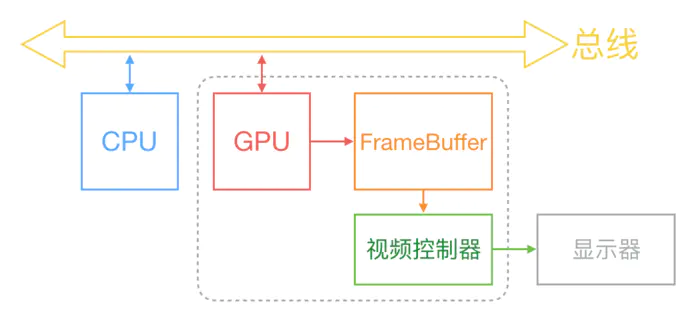

现在的手机设备基本都是采用双缓存+垂直同步(即V-Sync)屏幕显示技术。
如上图所示,系统内CPU、GPU和显示器是协同完成显示工作的。其中CPU负责计算显示的内容,例如视图创建、布局计算、图片解码、文本绘制等等。随后CPU将计算好的内容提交给GPU,由GPU进行变换、合成、渲染。GPU会预先渲染好一帧放入一个缓冲区内,让视频控制器读取,当下一帧渲染好后,GPU会直接将视频控制器的指针指向第二个容器(双缓存原理)。这里,GPU会等待显示器的VSync(即垂直同步)信号发出后,才进行新的一帧渲染和缓冲区更新(这样能解决画面撕裂现象,也增加了画面流畅度,但需要消费更多的计算资源,也会带来部分延迟)。
卡顿的原因:
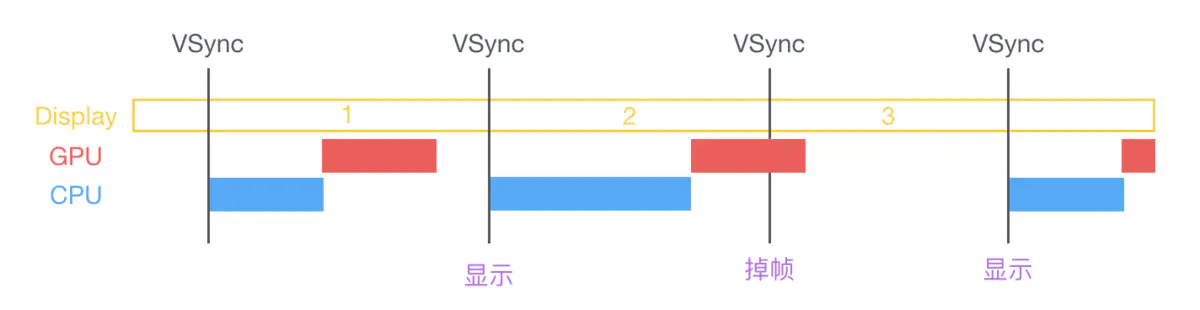

由上面屏幕显示的原理,采用了垂直同步机制的手机设备。如果在一个VSync 时间内,CPU 或GPU 没有完成内容提交,则那一帧就会被丢弃,等待下一次机会再显示,而这时显示屏会保留之前的内容不变。例如在主线程里添加了阻碍主线程去响应点击、滑动事件、以及阻碍主线程的UI绘制等的代码,都是造成卡顿的常见原因。
卡顿监控:
卡顿监控一般有两种实现方案:
(1). 主线程卡顿监控。通过子线程监测主线程的
runLoop,判断两个状态区域之间的耗时是否达到一定阈值。(2).
FPS监控。要保持流畅的UI交互,App 刷新率应该当努力保持在 60fps。FPS的监控实现原理,上面已经探讨过这里略过。
在使用FPS监控性能的实践过程中,发现 FPS 值抖动较大,造成侦测卡顿比较困难。为了解决这个问题,通过采用检测主线程每次执行消息循环的时间,当这一时间大于规定的阈值时,就记为发生了一次卡顿的方式来监控。
这也是美团的移动端采用的性能监控Hertz方案,微信团队也在实践过程中提出来类似的方案--微信读书 iOS 性能优化总结。

方案的提出,是根据滚动引发的Sources事件或其它交互事件总是被快速的执行完成,然后进入到kCFRunLoopBeforeWaiting状态下;假如在滚动过程中发生了卡顿现象,那么RunLoop必然会保持kCFRunLoopAfterWaiting或者kCFRunLoopBeforeSources这两个状态之一。
所以监控主线程卡顿的方案一:
开辟一个子线程,然后实时计算 kCFRunLoopBeforeSources 和 kCFRunLoopAfterWaiting 两个状态区域之间的耗时是否超过某个阀值,来断定主线程的卡顿情况。
但是由于主线程的RunLoop在闲置时基本处于Before Waiting状态,这就导致了即便没有发生任何卡顿,这种检测方式也总能认定主线程处在卡顿状态。
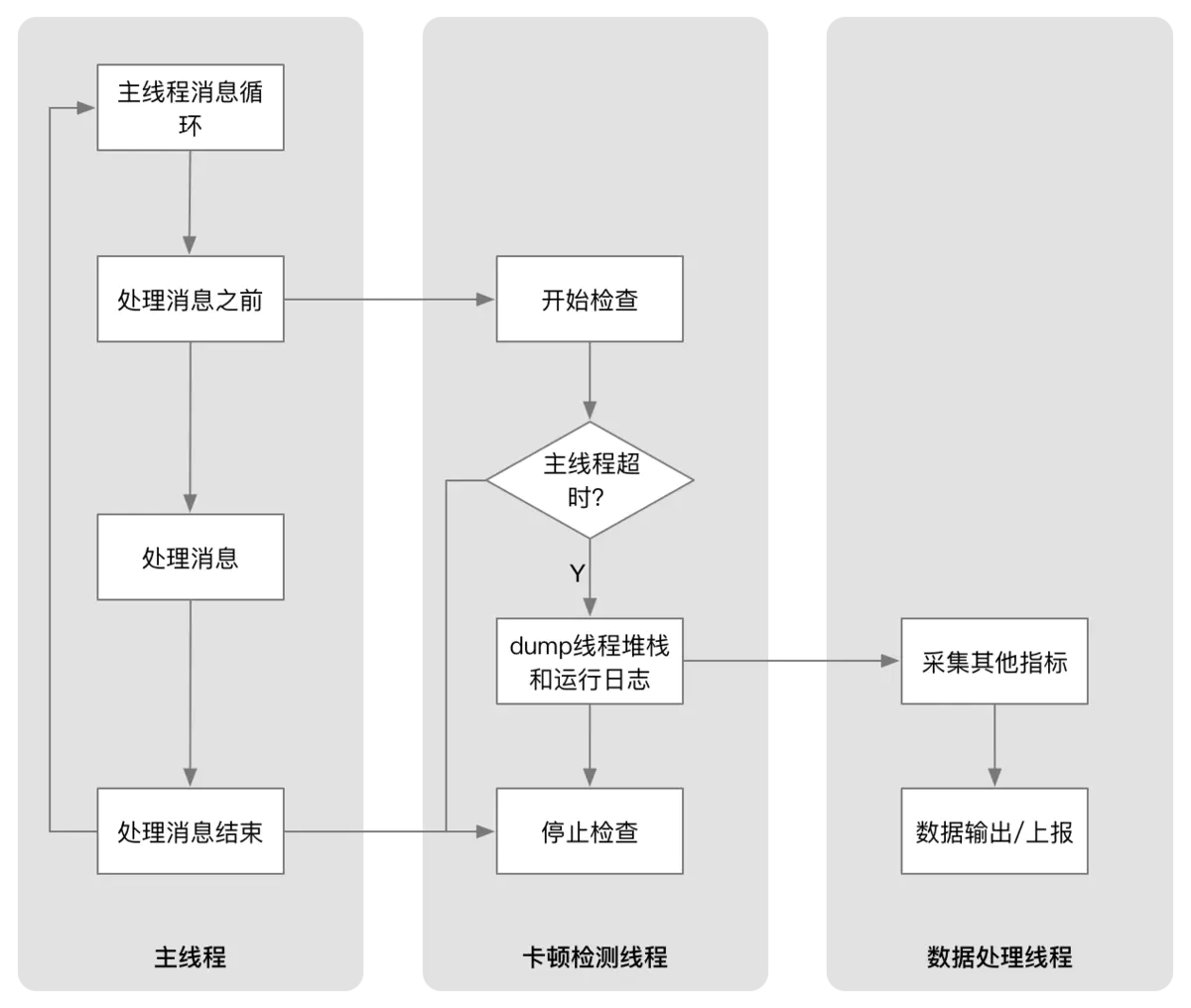
为了解决这个问题寒神(南栀倾寒)给出了自己的解决方案,Swift的卡顿检测第三方ANREye。这套卡顿监控方案大致思路为:创建一个子线程进行循环检测,每次检测时设置标记位为YES,然后派发任务到主线程中将标记位设置为NO。接着子线程沉睡超时阙值时长,判断标志位是否成功设置成NO,如果没有说明主线程发生了卡顿。
结合这套方案,当主线程处在Before Waiting状态的时候,通过派发任务到主线程来设置标记位的方式处理常态下的卡顿检测:
#define lsl_SEMAPHORE_SUCCESS 0
static BOOL lsl_is_monitoring = NO;
static dispatch_semaphore_t lsl_semaphore;
static NSTimeInterval lsl_time_out_interval = 0.05;
@implementation LSLAppFluencyMonitor
static inline dispatch_queue_t __lsl_fluecy_monitor_queue() {
static dispatch_queue_t lsl_fluecy_monitor_queue;
static dispatch_once_t once;
dispatch_once(&once, ^{
lsl_fluecy_monitor_queue = dispatch_queue_create("com.dream.lsl_monitor_queue", NULL);
});
return lsl_fluecy_monitor_queue;
}
static inline void __lsl_monitor_init() {
static dispatch_once_t onceToken;
dispatch_once(&onceToken, ^{
lsl_semaphore = dispatch_semaphore_create(0);
});
}
#pragma mark - Public
+ (instancetype)monitor {
return [LSLAppFluencyMonitor new];
}
- (void)startMonitoring {
if (lsl_is_monitoring) { return; }
lsl_is_monitoring = YES;
__lsl_monitor_init();
dispatch_async(__lsl_fluecy_monitor_queue(), ^{
while (lsl_is_monitoring) {
__block BOOL timeOut = YES;
dispatch_async(dispatch_get_main_queue(), ^{
timeOut = NO;
dispatch_semaphore_signal(lsl_semaphore);
});
[NSThread sleepForTimeInterval: lsl_time_out_interval];
if (timeOut) {
[LSLBacktraceLogger lsl_logMain]; // 打印主线程调用栈
// [LSLBacktraceLogger lsl_logCurrent]; // 打印当前线程的调用栈
// [LSLBacktraceLogger lsl_logAllThread]; // 打印所有线程的调用栈
}
dispatch_wait(lsl_semaphore, DISPATCH_TIME_FOREVER);
}
});
}
- (void)stopMonitoring {
if (!lsl_is_monitoring) { return; }
lsl_is_monitoring = NO;
}
@end
其中LSLBacktraceLogger是获取堆栈信息的类,详情见代码Github。
打印日志如下:
2018-08-16 12:36:33.910491+0800 AppPerformance[4802:171145] Backtrace of Thread 771:
======================================================================================
libsystem_kernel.dylib 0x10d089bce __semwait_signal + 10
libsystem_c.dylib 0x10ce55d10 usleep + 53
AppPerformance 0x108b8b478 $S14AppPerformance25LSLFPSTableViewControllerC05tableD0_12cellForRowAtSo07UITableD4CellCSo0kD0C_10Foundation9IndexPathVtF + 1144
AppPerformance 0x108b8b60b $S14AppPerformance25LSLFPSTableViewControllerC05tableD0_12cellForRowAtSo07UITableD4CellCSo0kD0C_10Foundation9IndexPathVtFTo + 155
UIKitCore 0x1135b104f -[_UIFilteredDataSource tableView:cellForRowAtIndexPath:] + 95
UIKitCore 0x1131ed34d -[UITableView _createPreparedCellForGlobalRow:withIndexPath:willDisplay:] + 765
UIKitCore 0x1131ed8da -[UITableView _createPreparedCellForGlobalRow:willDisplay:] + 73
UIKitCore 0x1131b4b1e -[UITableView _updateVisibleCellsNow:isRecursive:] + 2863
UIKitCore 0x1131d57eb -[UITableView layoutSubviews] + 165
UIKitCore 0x1133921ee -[UIView(CALayerDelegate) layoutSublayersOfLayer:] + 1501
QuartzCore 0x10ab72eb1 -[CALayer layoutSublayers] + 175
QuartzCore 0x10ab77d8b _ZN2CA5Layer16layout_if_neededEPNS_11TransactionE + 395
QuartzCore 0x10aaf3b45 _ZN2CA7Context18commit_transactionEPNS_11TransactionE + 349
QuartzCore 0x10ab285b0 _ZN2CA11Transaction6commitEv + 576
QuartzCore 0x10ab29374 _ZN2CA11Transaction17observer_callbackEP19__CFRunLoopObservermPv + 76
CoreFoundation 0x109dc3757 __CFRUNLOOP_IS_CALLING_OUT_TO_AN_OBSERVER_CALLBACK_FUNCTION__ + 23
CoreFoundation 0x109dbdbde __CFRunLoopDoObservers + 430
CoreFoundation 0x109dbe271 __CFRunLoopRun + 1537
CoreFoundation 0x109dbd931 CFRunLoopRunSpecific + 625
GraphicsServices 0x10f5981b5 GSEventRunModal + 62
UIKitCore 0x112c812ce UIApplicationMain + 140
AppPerformance 0x108b8c1f0 main + 224
libdyld.dylib 0x10cd4dc9d start + 1
======================================================================================
方案二是结合CADisplayLink的方式实现
在检测FPS值的时候,我们就详细介绍了CADisplayLink的使用方式,在这里也可以通过FPS值是否连续低于某个值开进行监控。

iOS开发--APP性能检测方案汇总的更多相关文章
- 100个iOS开发/设计程序员面试题汇总,你将如何作答?
100个iOS开发/设计程序员面试题汇总,你将如何作答? 雪姬 2015-01-25 19:10:49 工作职场 评论(0) 无论是对于公司还是开发者或设计师个人而言,面试都是一项耗时耗钱的项目, ...
- android app性能优化大汇总
这里根据网络上各位大神已经总结的知识内容做一个大汇总,作为记录,方便后续“温故知新”. 性能指标: (1)使用流畅度: 图片处理器每秒刷新的帧数(FPS),可用来指示页面是否平滑的渲染.高的帧率可以 ...
- iOS论App推送方案
1.APNS介绍(原生推送实现原理) 在iOS平台上,大部分应用是不允许在后台运行并连接网络的.在应用没有被运行的时候,只能通过 Apple Push Notification Service (AP ...
- 李洪强iOS开发之性能优化技巧
李洪强iOS开发之性能优化技巧 通过静态 Analyze 工具,以及运行时 Profile 工具分析性能瓶颈,并进行性能优化.结合本人在开发中遇到的问题,可以从以下几个方面进行性能优化. 一.view ...
- iOS开发app启动原理及视图和控制器的函数调用顺序
main()函数是整个程序的入口,在程序启动之前,系统会调用exec()函数.在Unix中exec和system的不同在于,system是用shell来调用程序,相当于fork+exec+waitpi ...
- android app性能优化大汇总(google官方Android性能优化典范 - 第1季)
大多数用户感知到的卡顿等性能问题的最主要根源都是因为渲染性能.从设计师的角度,他们希望App能够有更多的动画,图片等时尚元素来实现流畅的用户体验.但是Android系统很有可能无法及时完成那些复杂的界 ...
- iOS开发——app审核指导方针(官网)
iOS 开发后上传到App Store审核的指导方针 ——苹果官网介绍地址 https://developer.apple.com/app-store/review/guidelines/
- iOS开发 - Swift实现检测网络连接状态及网络类型
一.前言 在移动开发中,检测网络的连接状态尤其检测网络的类型尤为重要.本文将介绍在iOS开发中,如何使用Swift检测网络连接状态及网络类型(移动网络.Wifi). 二.如何实现 Reachabili ...
- 检测iOS的APP性能的一些方法
首先如果遇到应用卡顿或者因为内存占用过多时一般使用Instruments里的来进行检测.但对于复杂情况可能就需要用到子线程监控主线程的方式来了,下面我对这些方法做些介绍: Time Profiler ...
- 检测 iOS 的 APP 性能的一些方法
本文转载于微信公众号:iOS大全 首先如果遇到应用卡顿或者因为内存占用过多时一般使用Instruments里的来进行检测.但对于复杂情况可能就需要用到子线程监控主线程的方式来了,下面我对这些方法做些介 ...
随机推荐
- 【杂项】利用CUDA实现tensorflow的gpu加速——以NXP的eIQ Portal Command line环境为例
这是一个针对于eIQ的解决方案,笔者所用显卡是GTX1650 step1:下载CUDA和CuDnn 2022年3月,eIQ所使用tensorflow版本为2.5.0,因此对应CUDA 11.2.0,C ...
- uni-app学习笔记之----目录认识
新建了一个项目之后,先简单认识目录结构 1.pages 存放项目的所有页面 2.static 存放静态资源 3.unpackage 存放项目打包之后生成的文件 4.App.vue 项目的根组 ...
- Go组件库总结之介入式链表
本篇文章我们用Go封装一个介入式的双向链表,目的是将链表的实现和具体元素解耦.文章参考自:https://github.com/brewlin/net-protocol 1.元素的接口 type El ...
- Jmeter学习:Jmeter函数助手
转载地址:https://www.cnblogs.com/imyalost/p/6802173.html
- openssl常用操作
参考:https://www.golinuxcloud.com/openssl-view-certificate/ 查看证书信息 openssl x509 -in server.crt -text - ...
- gird 布局控制元素都显示在一行
gird 布局控制元素都显示在一行 <ul class="list"> <li v-for="(li, index) in list" :ke ...
- clickhouse-数据副本踩坑
数据副本--失败,看日志 vim /var/log/clickhouse-server/clickhouse-server.err.log select * from system.replicati ...
- 计算机科学导论-第三版-学习笔记-chapter1-绪论
小测验的网站找不到,小程序也找不到,这两个部分的习题就不做了. Cengage Learning - Foundations of Computer Science这上面有部分答案.这里用斜体标出.我 ...
- 基于Antlr的Modelica3.5语言解析
背景 Modelica语言是一种统一面向对象的系统建模语言 官方文档中明确写明了语法规范 在附录的第一章词法,第二章语法都完整的罗列的语言规范,对于Antlr适配特别好 只需要把[]修改为Antlr的 ...
- Keil51单片机解决数字显示不稳的问题
Keil51单片机解决数字显示不稳的问题 数字显示不稳,就是我们人眼的特点决定的,0.1秒的残留现象,低于这个值人眼发现不了其中变化,大于这个值就会出现同一个数字闪烁的现象.解决的方法就是所有数字,第 ...