#Python 文本包含函数,pandas库 Series.str.contains 函数
一:基础的函数组成
’’‘Series.str.contains(pat,case = True,flags = 0,na = nan,regex = True)’’'
测试pattern或regex是否包含在Series或Index的字符串中。
返回布尔值系列或索引,具体取决于给定模式或正则表达式是否包含在系列或索引的字符串中。
pat : str类型
字符序列或正则表达式。
case : bool,默认为True
如果为True,区分大小写。
flags : int,默认为0(无标志)
标志传递到re模块,例如re.IGNORECASE。
na : 默认NaN
填写缺失值的值。
regex : bool,默认为True
如果为True,则假定pat是正则表达式。
如果为False,则将pat视为文字字符串。
二:示例应用
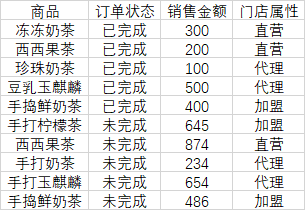
2.1 数据源展示
模拟一个奶茶销售表,包含商品名称,订单状态,销售金额,门店属性四个维度。
2.2 条件筛选(多列)
假设需求:目前需要直营门店、已完成状态的销售表
#模块导入
import pandas as pd
import numpy as np
#路径设置
source_data = r"E:/360MoveData/Users/B/Desktop/pandas_test.xlsx"
out_put = r"E:/360MoveData/Users/B/Desktop/output_data.xlsx"
#筛选条件设置
t1 = data1["门店属性"].str.contains("直营")
t2 = data1["订单状态"].str.contains("已完成")
#根据筛选条件返回成表
result = data1[t1&t2]
#输出成表
print(result)
#导出
result.to_excel(out_put)
输出结果,如下。

通过函数我们可以同时控制多个列的筛选条件,并输出成表。
2.3 文本筛选(同一列)
仍旧使用前文的数据源
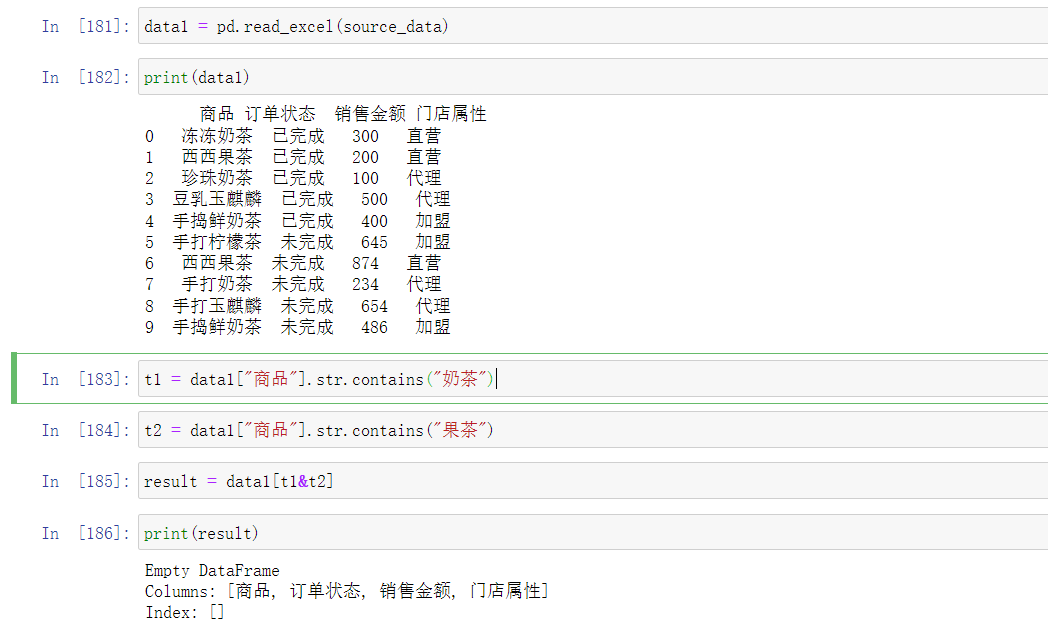
现在我们假设需求:商品品名中含有"奶茶",或者"果茶"的商品销售表
首先,我们来试试上一种方式,可以看到,这里的输出并不是我们想要的表
这里,我们换一个方式来实现。
data1.loc[data1["商品"].str.contains("奶茶|果茶",na = False),"订单判断"] = "目标订单"
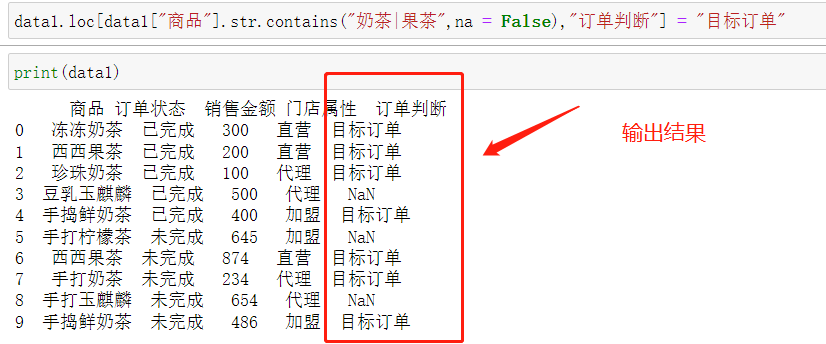
可以看到,商品这一列中含有奶茶、果茶的商品被标记了。
3:总结
利用str.contains,我们可以筛选同一列,不同列的数据,对于活动清洗、订单清洗等数据清洗环节,可以更快的标记对应的订单。
我是simone,期待下次的分享。
#Python 文本包含函数,pandas库 Series.str.contains 函数的更多相关文章
- Python数据分析工具:Pandas之Series
Python数据分析工具:Pandas之Series Pandas概述Pandas是Python的一个数据分析包,该工具为解决数据分析任务而创建.Pandas纳入大量库和标准数据模型,提供高效的操作数 ...
- 利用Python进行数据分析(7) pandas基础: Series和DataFrame的简单介绍
一.pandas 是什么 pandas 是基于 NumPy 的一个 Python 数据分析包,主要目的是为了数据分析.它提供了大量高级的数据结构和对数据处理的方法. pandas 有两个主要的数据结构 ...
- 利用Python进行数据分析(8) pandas基础: Series和DataFrame的基本操作
一.reindex() 方法:重新索引 针对 Series 重新索引指的是根据index参数重新进行排序. 如果传入的索引值在数据里不存在,则不会报错,而是添加缺失值的新行. 不想用缺失值,可以用 ...
- 利用python进行数据分析之pandas库的应用(二)
本节介绍Series和DataFrame中的数据的基本手段 重新索引 pandas对象的一个重要方法就是reindex,作用是创建一个适应新索引的新对象 >>> from panda ...
- 【Python学习笔记】Pandas库之DataFrame
1 简介 DataFrame是Python中Pandas库中的一种数据结构,它类似excel,是一种二维表. 或许说它可能有点像matlab的矩阵,但是matlab的矩阵只能放数值型值(当然matla ...
- 用python做数据分析4|pandas库介绍之DataFrame基本操作
原文地址 怎样删除list中空字符? 最简单的方法:new_list = [ x for x in li if x != '' ] 今天是5.1号. 这一部分主要学习pandas中基于前面两种数据结构 ...
- pandas库Series类型与基本操作
pandas读取excel的类型是dataFrame,然后提取每一列是一个Series类型 Series类型包括index和values两部分 a = pd.Series({'a':1,'b':5}) ...
- 利用python进行数据分析之pandas库的应用(一)
一.pandas的数据结构介绍 Series Series是由一种类似于一维数组的对象,它由一组数据以及一组与之相关的数据索引构成.仅由一组数据可产生最简单的Series. obj=Series([4 ...
- 数据分析之pandas库--series对象
1.Series属性及方法 Series是Pandas中最基本的对象,Series类似一种一维数组. 1.生成对象.创建索引并赋值. s1=pd.Series() 2.查看索引和值. s1=Serie ...
- 【转】Pandas的Apply函数——Pandas中最好用的函数
转自:https://blog.csdn.net/qq_19528953/article/details/79348929 import pandas as pd import datetime #用 ...
随机推荐
- loadrunner之录制脚本
LoadRunner是一款性能测试软件,通过模拟真实的用户行为,通过负载.并发和性能实时监控以及完成后的测试报告,分析系统可能存在的瓶颈,LoadRunner最为有效的手段之一应该就是并发控制,通过在 ...
- python练习--1
ID_CARD = input("Input your ID Card: ") length = len(ID_CARD) if length < 5: NEW_ID_CAR ...
- 9. 实现包括前端后台的预约洗狗功能 - 使用Power Automate发送预约邮件 - 使用Power Automate发送带选择按钮(option)的邮件
除了发送普通的电子邮件外,我们还可以选择发送带选项的电子邮件来得到客户的反馈,下面我们就一起来创建带有选择功能的电子邮件吧. 1. 打开我们的Power Portal,在左侧导航栏选择流,点击左上 ...
- 认识流媒体协议,从 RTSP 协议解析开始!
RTSP 是 Internet 协议规范,是 TCP/IP 协议体系中的一个应用层协议级网络通信系统.专为娱乐(如音频和视频)和通信系统的使用,以控制流媒体服务器.该协议用于在端点之间建立和控制媒体会 ...
- EF Code 如何应对高并发
1.高并发的情况,时常会发生数据不稳定的情况 在看本节内容之前,请先看上一章SqlServer 高并发的情况下,如何利用锁保证数据的稳定性 本节内容,也是具体讨论如何在EF中实现这些操作 2.场景模拟 ...
- 自己动手从零写桌面操作系统GrapeOS系列教程——21.汇编语言写硬盘实战
学习操作系统原理最好的方法是自己写一个简单的操作系统. 在上一讲中我们学习了用汇编语言读硬盘,本讲我们来学习用汇编语言写硬盘.同样也是设计一个简单的实验,实验内容为: 在内存中准备一段有特征的512字 ...
- 易基因:PIWI/piRNA在人癌症中的表观遗传调控机制(DNA甲基化+m6A+组蛋白修饰)|综述
大家好,这里是专注表观组学十余年,领跑多组学科研服务的易基因. 2023年03月07日,南华大学衡阳医学院李二毛团队在<Molecular Cancer>杂志发表了题为"The ...
- MySQL与Java常用数据类型的对应关系
一.字符串数据类型: MySQL类型名 大小 用途 对应Java类名 char 0-255 bytes 定长字符串 (姓名.性别.学号) String varchar 0-65535 bytes 变长 ...
- 人工智能NVIDIA显卡计算(CUDA+CUDNN)平台搭建
NVIDIA是GPU(图形处理器)的发明者,也是人工智能计算的引领者.我们创建了世界上最大的游戏平台和世界上最快的超级计算机. 第一步,首先安装N卡驱动. cby@cby-Inspiron-7577: ...
- pandas之使用自定义函数
如果想要应用自定义的函数,或者把其他库中的函数应用到 Pandas 对象中,有以下三种方法: 1) 操作整个 DataFrame 的函数:pipe() 2) 操作行或者列的函数:apply() 3) ...