架构与思维:互联网高性能Web架构
1 什么是高性能Web架构
在互联网业务中,我们经常会面临流量巨大的复杂的分布式场景。这就要求我们在设计系统的时候保证系统具有承载高并发(High Concurrency)的能力,同时能够保证系统的高可用性(High Availability)。
所以,具备高性能Web架构通常是指,通过稳健的系统设计能力,来保证系统能够同时处理复杂的业务场景,并保证性能、稳定性、可用性的架构体系。。
高性能Web常用的一些衡量指标有响应时间(Response Time),吞吐量(Throughput),每秒请求数QPS(Query Per Second),并发用户数等。
响应时间(RT) 响应时间是指系统对请求作出响应的时间,如一个请求从发送request到response的时间是500ms,这就是请求的响应时间。
吞吐量(Throughput) 吞吐量是指系统在单位时间内处理请求的数量。
并发用户数 并发数是指系统同时能处理的请求数量,这个也是反映了系统的负载能力。
与吞吐量相比,并发用户数是一个更直观但也更笼统的性能指标。实际上,并发用户数是一个非常不准确的指标,因为用户不同的使用模式会导致不同用户在单位时间发出不同数量的请求。
QPS每秒查询率(Query Per Second) 每秒查询率QPS是对一个特定的查询服务器在规定时间内所处理流量多少的衡量标准
TPS每秒事务数(Transactions Per Second) 是吞吐量的常用量化指标
2 如何提升系统的性能指标
在互联网分布式架构设计,我们常常用两种方式来提高系统的性能,一种是横向扩展(Scale Out),一种是纵向扩展(Scale Up)。对于横向纵向扩张我们在 微服务系列、MySQL系列、Redis系列 中已经多次 讨论过了。
纵向扩展主要提高单机的性能,让其算力不断提升。横向扩展就是典型的分治思维,单机的内存、CPU、连接数、吞吐量始终是有限的,多实例化的集群支撑才是解决大型分布式场景的保障。
2.1 纵向扩展(Scale Up): 提升单机算力
1、单机硬件水平提升,如 CPU(多线程计算服务消耗大)、内存(缓存等)、GPU(音视频、直播类)、SSD磁盘(数据存储等),升级到更高的配置;
2、提升单机架构性能,很多时候不是服务器硬件水平低,而是架构的不合理。如:
- 服务模块化分层不合理,导致调用互相影响,请求链路过长。
- 未合理地使用缓存,导致系统计算时间过长,IO操作频率过高。
- 存储服务,如数据库可优化空间大,如 索引使用不当,单表容量过大,单表字段过多,查询未优化等。
这些都是在架构设计的时候需要谨慎对待的。
但是正如上面说的,不论是单机硬件性能,还是单机架构性能,优化都有一个极限,互联网分布式架构设计高并发终极解决方案还是横向扩展。
2.2 横向扩展(Scale Out):
典型的分治思维,单机的内存、SSD、CPU、GPU、连接、吞吐量始终是有限的,总不能无限制的扩展。所以我们需要追求横向扩展,在架构的各个层面做水平扩容,增加实例数量,比如Services Cluster、Redis Cluster、MySQL Cluster,并在长期的业务实践中不断优化。
相对于Scale Up,他有哪些优势:
- 理论上的性能无限扩充,单机的扩容总是有限制的,但是集群是可以持续扩张。bat大厂核心服务的成千上万的服务集群就是很好的业内范例。
- 提高可用性,水平扩容最终会把计算能力和数据能力分摊在不同的实例、甚至不同的服务、甚至不同机房。某个分区出问题不会导致整个系统崩塌,这个单体系统是不能保障的,哪怕他硬件再牛。
3 业内常见的系统分层架构如下:

- Client: 包括Web浏览器、App应用、还有第三方请求。
- Reverse Proxy:流量的入口,提供 反向代理、负载均衡 等能力的支持
- Web Services: Web服务层,处理业务逻辑,直接面向用户视觉,返回HTML页面、文档、Json信息等
- Computing Services:提供计算能力,所有繁琐的业务计算、数据存取、缓存存取。
- Cache:缓存层,主要消耗内存,提供高效率数据存取。
- Data:数据层,将数据持久化到硬盘。
如果要保证整个系统的高性能,那不是单纯对缓存层或数据层进行扩容的事情,就要求各层都可以水平扩展,下面我们一一来拆解下。
4 分层水平扩展架构实践
4.1 Reverse Proxy 的Scale Out
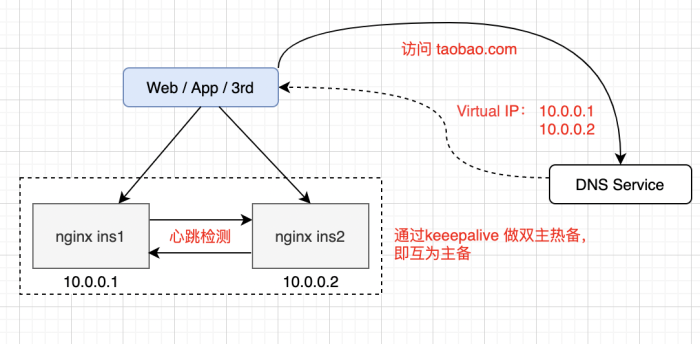
一般情况下,我们使用 Nginx 来实现 Load Balance(Random、Round Robin、Hash等),但是单台Nginx照样存在宕机的风险。这时候我们就使用DNS 轮询
在 Nginx 上层做反向代理,一般会在一个域名上配置多个IP解析。当我们访问 DNS服务的时候,他会轮询的返回IP。而我们增加Nginx实例的时候,同时也在DNS 服务上增配解析IP,这样就达到理论上的无限扩容了。
如图中,当我们有多个Nginx实例的时候,我们还可以配置keepalive做探活,以保证可用性。
4.2 Web Services 的 Scale Out
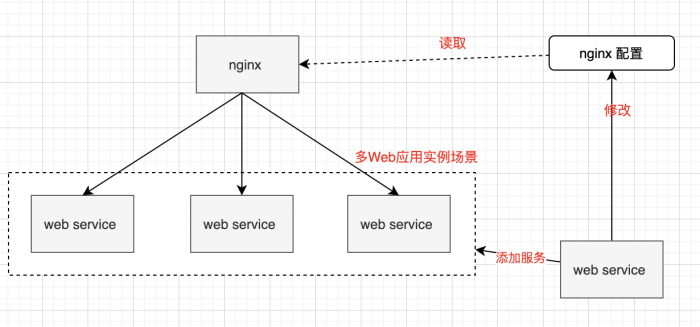
Web Services的上层是Nginx,他本身就是出色的负载均衡利器。当我们有多个服务实例的时候,只要在Nginx上conf文件上进行配置,就可以实现强大而稳定的负载了。而且对服务实例的新增和缩减,可以达到高效配置和快速扩缩的能力。Nginx可以调度足够多的Web Services实例,实现互联网系统高并发运行。
4.3 Computing Services 的 Scale Out
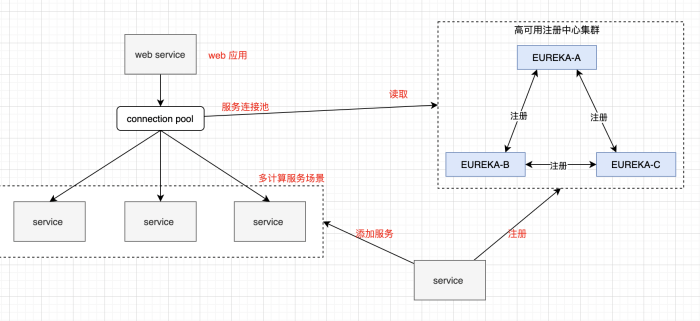
计算服务这一层的横向扩展,可以使用 命名服务(Name Server)模式进行处理。比如我们建立一个高可用的服务注册与发现中心。
Alive的计算服务实例都注册到服务中心去,Web服务层则订阅服务中心,获取可用的计算服务,并执行调用。无论是使用Rest API调用,还是使用RPC调用,当你明显发现计算服务无法支撑逐渐上升的流量的时候(比如用户量暴涨、请求暴增),可以部署新的计算服务实例,并自动地注册到服务中心。实现平滑的动态的计算服务扩容相当优雅。
另外,目前的服务间调用一般是去中心化的,会把订阅到的注册服务实例信息保存在本地(比如 Web 服务 把 计算服务地址 列表保存在本地),哪怕服务中心挂了,短时间内,也不影响请求的正常运转。
4.4 数据层 的 Scale Out
这个算老生长谈了,我们在 MySQL系列 和 Redis系列 中中已经不厌其烦的讨论过 缓存层 和 数据库层水平扩容的方式了。
在互联网高速发展的今天,巨量的数据已经覆盖我们生活的每个角落,我们的衣食住行都是海量的数据进行支撑和管理。当我们的数据过于庞大的时候,一般会通过分库分表,来将数据库拆分到不同的实例,甚至服务器上,来达到存储层系统性能扩展的目的。
《MySQL分库分表》中我们有详细说拆分的原理和方式,以MySQL为例,
这边我们再做一下整理。一般有以下三种拆分方式:
4.4.1 按照Range水平拆分

上面的示例,使用了范围RANGE函数对岗位编号进行分区,共分为3个分区,
岗位编号为1 ~ 25w 的对应在分区P0中,25w+1 ~ 50w 编号在分区P1中,依次类推即可,类别编号大于 50w的数据统一存放在分区P3中即可。
这种模式的优势是:
- 判断简单,只要对值进行判断一下,就能找到对应的存储分区;
- 区间自定义的情况下,可以比较均匀的分布数据。
- 扩展简单,当超过50w的数据比较多的时候,可以再加一个 id(50w,75w) 的分区。
- 可能存在的问题就是,各Range之间的请求压力可能不均衡,比如访问频率最高的用户数据可能都落在第2区间。
4.4.2 按照HASH水平拆分
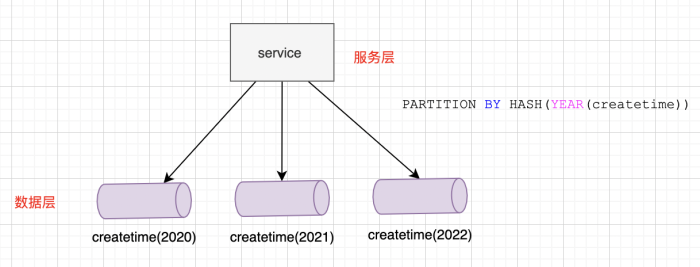
上面的例子,使用HASH函数对createtime日期进行HASH运算,并根据这个日期来分区数据,这里按照 年 为单位共分为3个分区。
建表语句上添加一个“PARTITION BY HASH (expr)”子句,其中“expr”是一个返回整数的表达式,它可以是字段类型为MySQL 整型的一列的名字,也可以是返回非负数的表达式。
这种模式的优势是:
- 同样的,判断简单,只要对相应字段进行hash计算一下就可以了。
- 大部分情况下,数据分布也比较均匀,请求分布都可以比较均匀。比如你使用日期、性别等来hash,得到的结果一般是比较均衡的。
- 缺点是:扩展性不佳,扩增一个数据实例,或者hash属性对应改变的时候,意味着你的数据所属区要重新划定,数据迁移是个不可缺少的成本。
4.4.3 按照LIST(预定义列表)拆分
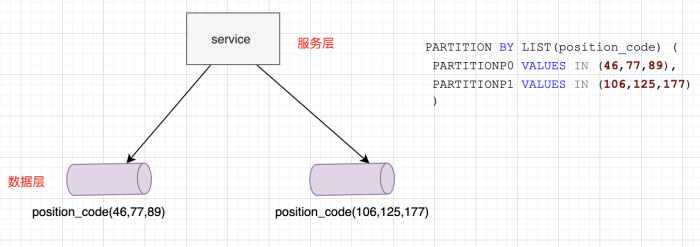
上面的例子,使用了列表匹配LIST函数对位置编号进行分区,共分为2个分区,编号为46,77,89的对应在分区P0中,106,125,177类别在分区P1中。
不同于RANGE的是,LIST分区的数据必须匹配列表中的岗位编号才能进行分区,所以这种方式只是适合比较区间值确定并少量的情况。
不管是哪种模式,我们通过水平扩展,将数据分摊到不同的实例甚至服务器上,以此提升了数据库单实例的性能和稳定性。
5 总结
在大型互联网分布式系统的架构设计中,High Concurrency (高性能)、High Availability(高可用) 是构成的关键因素,我们通过精妙的设计,来保证系统能够同时并行处理足够多的请求、能够提高稳定持久服务的时间(n个9)、能够大幅降低事务处理时间。
提高系统并发能力的方式,方法论上主要有两种:垂直扩展(Scale Up)与水平扩展(Scale Out)。
Scale Up 是指单机硬件水平提升,如 CPU(多线程计算服务消耗大)、内存(缓存等)、GPU(音视频、直播类)、SSD磁盘(数据存储等),升级到更高的配置,来提高并发性和可用性,但单机性能终归是有限的,不可能无限扩展。
在我们上面的讨论中,我们通过对各层逐层的水平扩容来实践互联网系统保持高性能高可用性的可能性。
- Reverse Proxy 通过 DNS轮询 的方式实现IP解析的增配,以保证快速的扩容。
- nginx 通过配置conf 实现对上游 Web Services 的扩容和负载均衡。
- Computing Services 通过服务注册中心实现新增服务实例的自动发现,保证水平扩容的高效和稳定。
- 数据层可以使用 数据库分区 来实现水平扩展。
架构与思维:互联网高性能Web架构的更多相关文章
- 高性能Web架构
高性能Web架构 转自 架构文摘 2017-02-07 王杰 引言 最新中国互联网络信息中心(CNNIC)发布的<第38次中国互联网络发展状况统计报告>,2016年6月,我国网民规模达7 ...
- 2019年最新老男孩高性能Web架构与自动化运维架构视频教程
课程目录L001-老男孩架构15期-Web架构之单机时代L002-老男孩架构15期-Web架构之集群时代L003-老男孩架构15期-Web架构之dnsL004-老男孩架构15期-Web架构之缓存体系L ...
- .NET 需要处理的高性能WEB架构 - .NET架构
1.如果不想被微软包围(其实微软的一套并不贵,是被谣言传高了),数据层依然可以选择SQL Server数据库和存储过程. 2.缓存不再依赖.net自身提供的缓存机制,迁移到部署在Linux平台上的分布 ...
- .NET 高性能WEB架构-比较容易改造方式 - .NET架构
下面列出的一些,是我们常见而且比较容易去优化的方式,当然细节方面非常多,仅供参考: 1.数据库依然选择SQL Server数据库(最新的sqlserver功能是很强大的)和使用订阅发布进行单写多读的读 ...
- 【架构师之路】APP架构师必看:面对爆发流量如何进行架构调整
一.APP架构与WEB架构的最大不同 移动APP的架构和传统PC的WEB架构有三点不同: 1.连接的稳定性.在传统的web端连接成功后就可以认为它是稳定的,但在移动端.无线端,APP连接非常敏感,可能 ...
- 可扩展的 Web 架构与分布式系统
作者:Kate Matsudaira 译者:尹星 本文介绍了分布式架构是如何解决系统扩展性问题的粗略方法,适合刚刚入门分布式系统的同学,我把整篇文章翻译如下,希望给你一些启发. 备注:[idea]标注 ...
- 大型网站技术架构(3):WEB 前端性能优化
上次说到了性能优化策略,根据网站的分层架构,可以大致的分为 web 前端性能优化,应用服务器性能优化,存储服务器性能优化三大类 这次来说一下 web 前端性能优化,一般来说,web 前端就是应用服务器 ...
- 可伸缩Web架构与分布式系统(1)
开源软件近年来已变为构建一些大型网站的基础组件.并且伴随着网站的成长,围绕着它们架构的最佳实践和指导准则已经显露.这篇文章旨在涉及一些在设计大型网站时需要考虑的关键问题和一些为达到这些目标所使用的组件 ...
- 【转载】WEB架构师成长之路
本人也是coding很多年,虽然很失败,但也总算有点失败的心得,不过我在中国,大多数程序员都是像我一样,在一直走着弯路,如果想成为一个架构师,就必须走正确的路,否则离目标越来越远,正在辛苦工作的程序员 ...
随机推荐
- python封装发送邮件类
import smtplib from email.mime.text import MIMEText from email.mime.multipart import MIMEMultipart i ...
- 155_模型_Power BI & Power Pivot 进销存之安全库存
155_模型_Power BI & Power Pivot 进销存之安全库存 一.背景 谈进销存的概念时,我们也需要提及另外一个概念:安全库存. 库存周转在理想的状态下是做到零库存,但是在内部 ...
- wappalyzer 上各种开源框架功能
Underscore.js 官网地址:https://underscorejs.org/ 一个JavaScript实用库,提供了一整套函数式编程的实用功能,但是没有扩展任何JavaScrip ...
- Xilinx DMA的几种方式与架构
DMA是direct memory access,在FPGA系统中,常用的几种DMA需求: 1. 在PL内部无PS(CPU这里统一称为PS)持续干预搬移数据,常见的接口形态为AXIS与AXI,AXI与 ...
- Aeraki Mesh正式成为CNCF沙箱项目,腾讯云携伙伴加速服务网格成熟商用
6月,由腾讯云主导,联合百度.灵雀云.腾讯音乐.滴滴.政采云等多家合作伙伴发起的服务网格开源项目 Aeraki Mesh 通过了全球顶级开源基金会云原生计算基金会(CNCF)技术监督委员会评定,正式成 ...
- SAP 查看在线用户
SM04 可查看服务器全部客户端(Client)的用户的在线状态,并可以结束指定用户的会话状态,也就是强制踢出用户.
- 叮,GitHub 到账 550 美元「GitHub 热点速览 v.22.26」
作者:HelloGitHub-小鱼干 如果你关注 GitHub 官方动态,你会发现它们最近频频点赞世界各地开发者晒出的 GitHub $550 sponsor 截图,有什么比"白嫖" ...
- centos通过日志查入侵
1. Linux查看/var/log/wtmp文件查看可疑IP登陆 last -f /var/log/wtmp 该日志文件永久记录每个用户登录.注销及系统的启动.停机的事件.因此随着系统正常运行时间的 ...
- Python收集这些视频只是单纯的想做做壁纸,大家不要误会
首先澄清一下,我用Python收集这些视频,绝不是想做别的什么,真的只是用来做动态壁纸,大家不要误会!我不是那样的人~ 这样的不过份吧 (这个动图看不看的到就看有没有缘分了 ) 阅读本文你需要准备 1 ...
- NC25136 [USACO 2006 Ope B]Cows on a Leash
NC25136 [USACO 2006 Ope B]Cows on a Leash 题目 题目描述 给定如图所示的若干个长条.你可以在某一行的任意两个数之间作一条竖线,从而把这个长条切开,并可能切开其 ...