HBase详解(02) - HBase-2.0.5安装
HBase详解(02) - HBase-2.0.5安装
HBase安装环境准备
- Zookeeper安装
Zookeeper安装参考《Zookeeper详解(02) - zookeeper安装部署-单机模式-集群模式》
启动Zookeeper集群
bin/zkServer.sh start
- Hadoop安装
Hadoop安装参考《Hadoop详解(02) - Hadoop3.1.3集群运行环境搭建》
启动Hadoop集群
sbin/start-dfs.sh
sbin/start-yarn.sh
Hbase安装
- 安装包下载
HBase官网:https://hbase.apache.org/
Hbase安装包历史版本下载地址:https://archive.apache.org/dist/hbase/
hbase-2.0.5下载地址:https://archive.apache.org/dist/hbase/2.0.5/hbase-2.0.5-bin.tar.gz
- 上传解压
将Hbase安装包hbase-2.0.5-bin.tar.gz上传到服务器的/opt/software目录
解压:
[hadoop@hadoop102 software]$ tar -zxvf hbase-2.0.5-bin.tar.gz -C /opt/module/
重命名
[hadoop@hadoop102 software]$ cd /opt/module/
[hadoop@hadoop102 module]$ mv hbase-2.0.5/ hbase
- 修改配置文件hbase-env.sh
[hadoop@hadoop102 module]$ cd hbase/conf/
[hadoop@hadoop102 conf]$ vi hbase-env.sh
修改内容:
#使用独立的Zookeeper集群,找到如下内容,放开注释,将值修改为false
export HBASE_MANAGES_ZK=false
- 修改配置文件hbase-site.xml
[hadoop@hadoop102 conf]$ vi hbase-site.xml
添加如下内容:
<configuration>
<property>
<name>hbase.rootdir</name>
<value>hdfs://hadoop102:9820/hbase</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>hadoop102,hadoop103,hadoop104</value>
</property>
</configuration>
注意:hbase.rootdir配置的端口为Hadoop namenode端口,即与hadoop中core-site.xml的fs.defaultFS值配置的端口一致
- 修改regionservers
[hadoop@hadoop102 conf]$ vi regionservers
删除原来的内容,添加如下内容,表示需要启动的Region Server节点
hadoop102
hadoop103
hadoop104
- 分发安装包
将HBase安装包分发到其他集群
[hadoop@hadoop102 module]$ scp -r hbase/ hadoop103:/opt/module/
[hadoop@hadoop102 module]$ scp -r hbase/ hadoop104:/opt/module/
- 配置环境变量
[hadoop@hadoop102 module]$ sudo vi /etc/profile
在文件末尾添加如下内容
#HBASE_HOME
export HBASE_HOME=/opt/module/hbase
export PATH=$PATH:$HBASE_HOME/bin
注意:在hadoop103,hadoop104上也需要配置HBase的环境变量
- 启动Hbase集群
[hadoop@hadoop102 hbase]$ cd /opt/module/hbase/
[hadoop@hadoop102 hbase]$ bin/start-hbase.sh
停止服务:
[hadoop@hadoop102 hbase]$ bin/stop-hbase.sh
- 查看Hbase UI页面
浏览器中访问http://hadoop102:16010
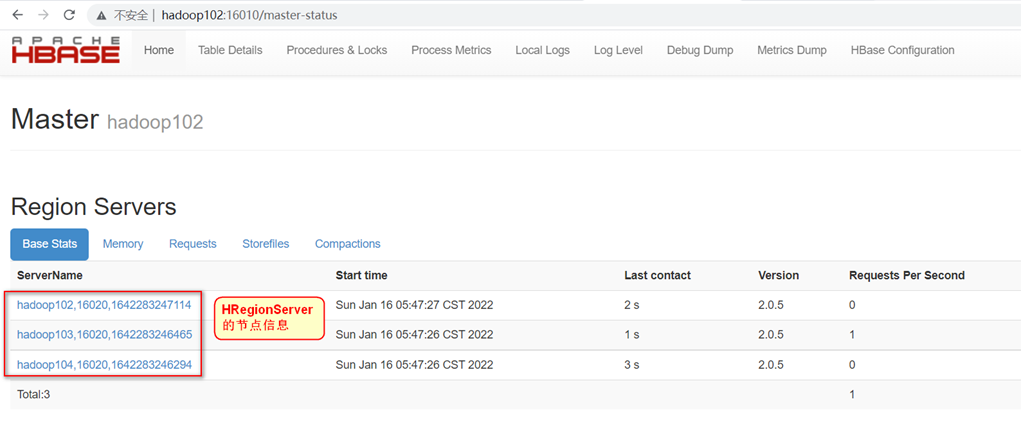
提示:如果集群之间的节点时间不同步,会导致regionserver无法启动,抛出ClockOutOfSyncException异常。
解决方法:
方法一:同步时间服务
方法二:设置属性:hbase.master.maxclockskew设置更大的值
|
<property> <name>hbase.master.maxclockskew</name> <value>180000</value> <description>Time difference of regionserver from master</description> </property> |
- 单点启动命令
bin/hbase-daemon.sh start master
bin/hbase-daemon.sh start regionserver
HMaster高可用(可选)
在HBase中HMaster负责监控HRegionServer的生命周期,均衡RegionServer的负载,如果HMaster挂掉了,那么整个HBase集群将陷入不健康的状态,并且此时的工作状态并不会维持太久。所以HBase支持对HMaster的高可用配置。
- 关闭HBase集群(如果没有启动Hbase集群则跳过此步)
[hadoop@hadoop102 hbase]$ bin/stop-hbase.sh
- 在conf目录下创建backup-masters文件
[hadoop@hadoop102 hbase]$ touch conf/backup-masters
- 在backup-masters文件中配置高可用HMaster节点
[hadoop@hadoop102 hbase]$ echo hadoop103 > conf/backup-masters
- 将conf目录scp到其他节点
[hadoop@hadoop102 hbase]$ scp -r conf/ hadoop103:/opt/module/hbase/
[hadoop@hadoop102 hbase]$ scp -r conf/ hadoop104:/opt/module/hbase/
- 启动HBase集群
[hadoop@hadoop102 hbase]$ bin/start-hbase.sh
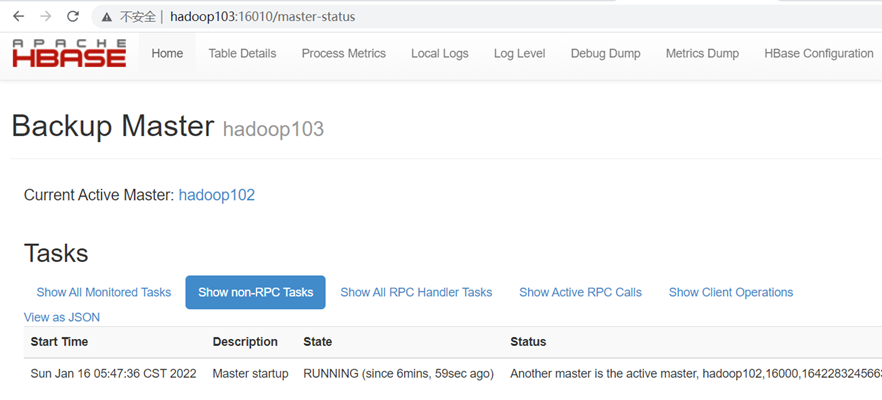
- 打开页面测试查看
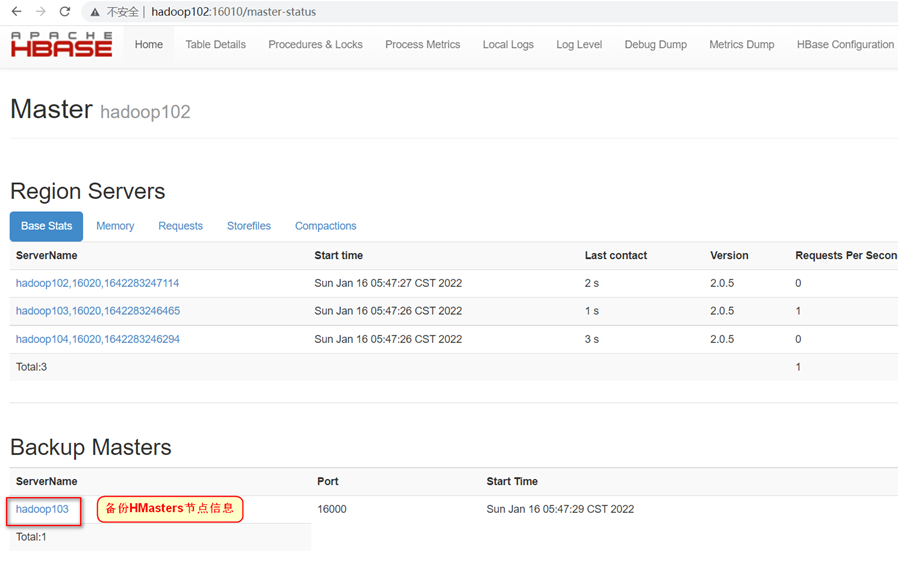
访问备份节点的HMaster:http://hadoop103:16010
HBase Shell操作
基本操作
1.进入HBase客户端命令行
[hadoop@hadoop102 hbase]$ bin/hbase shell
2.查看帮助命令
hbase(main):001:0> help
namespace的操作
1.查看当前Hbase中有哪些namespace
hbase(main):002:0> list_namespace
NAMESPACE
default(创建表时未指定命名空间的话默认在default下)
hbase(系统使用的,用来存放系统相关的元数据信息等,勿随便操作)
2.创建namespace
hbase(main):010:0> create_namespace "test"
hbase(main):010:0> create_namespace "test01", {"author"=>"wyh", "create_time"=>"2020-03-10 08:08:08"}
3.查看namespace
hbase(main):010:0> describe_namespace "test01"
4.修改namespace的信息(添加或者修改属性)
hbase(main):010:0> alter_namespace "test01", {METHOD => 'set', 'author' => 'weiyunhui'}
添加或者修改属性:
alter_namespace 'ns1', {METHOD => 'set', 'PROPERTY_NAME' => 'PROPERTY_VALUE'}
删除属性:
alter_namespace 'ns1', {METHOD => 'unset', NAME => ' PROPERTY_NAME '}
5.删除namespace
hbase(main):010:0> drop_namespace "test01"
注意: 要删除的namespace必须是空的,其下没有表。
表的操作
0.查看当前数据库中有哪些表
hbase(main):002:0> list
1.创建表
hbase(main):002:0> create 'student','info'
2.插入数据到表
hbase(main):003:0> put 'student','1001','info:sex','male'
hbase(main):004:0> put 'student','1001','info:age','18'
hbase(main):005:0> put 'student','1002','info:name','Janna'
hbase(main):006:0> put 'student','1002','info:sex','female'
hbase(main):007:0> put 'student','1002','info:age','20'
3.扫描查看表数据
hbase(main):008:0> scan 'student'
hbase(main):009:0> scan 'student',{STARTROW => '1001', STOPROW => '1001'}
hbase(main):010:0> scan 'student',{STARTROW => '1001'}
4.查看表结构
hbase(main):011:0> describe 'student'
5.更新指定字段的数据
hbase(main):012:0> put 'student','1001','info:name','Nick'
hbase(main):013:0> put 'student','1001','info:age','100'
6.查看"指定行"或"指定列族:列"的数据
hbase(main):014:0> get 'student','1001'
hbase(main):015:0> get 'student','1001','info:name'
7.统计表数据行数
hbase(main):021:0> count 'student'
8.删除数据
删除某rowkey的全部数据:
hbase(main):016:0> deleteall 'student','1001'
删除某rowkey的某一列数据:
hbase(main):017:0> delete 'student','1002','info:sex'
9.清空表数据
hbase(main):018:0> truncate 'student'
提示:清空表的操作顺序为先disable,然后再truncate。
10.删除表
首先需要先让该表为disable状态:
hbase(main):019:0> disable 'student'
然后才能drop这个表:
hbase(main):020:0> drop 'student'
提示:如果直接drop表,会报错:ERROR: Table student is enabled. Disable it first.
11.变更表信息
将info列族中的数据存放3个版本:
hbase(main):022:0> alter 'student',{NAME=>'info',VERSIONS=>3}
hbase(main):022:0> get 'student','1001',{COLUMN=>'info:name',VERSIONS=>3}
HBase详解(02) - HBase-2.0.5安装的更多相关文章
- 大数据入门第十四天——Hbase详解(一)入门与安装配置
一.概述 1.什么是Hbase 根据官网:https://hbase.apache.org/ Apache HBase™ is the Hadoop database, a distributed, ...
- [转帖]HBase详解(很全面)
HBase详解(很全面) very long story 简单看了一遍 很多不明白的地方.. 2018-06-08 16:12:32 卢子墨 阅读数 34857更多 分类专栏: HBase [转自 ...
- 图解大数据 | 海量数据库查询-Hive与HBase详解
作者:韩信子@ShowMeAI 教程地址:http://www.showmeai.tech/tutorials/84 本文地址:http://www.showmeai.tech/article-det ...
- Linux 下Redis集群安装部署及使用详解(在线和离线两种安装+相关错误解决方案)
一.应用场景介绍 本文主要是介绍Redis集群在Linux环境下的安装讲解,其中主要包括在联网的Linux环境和脱机的Linux环境下是如何安装的.因为大多数时候,公司的生产环境是在内网环境下,无外网 ...
- RabbitMQ详解(一)------简介与安装(Docker)
RABBITMQ详解(一)------简介与安装(DOCKER) 刚刚进入实习,在学习过程中没有接触过MQ,RabbitMQ 这个消息中间件,正好公司最近的项目中有用到,学习了解一下. 首先什么是MQ ...
- 大数据学习day11------hbase_day01----1. zk的监控机制,2动态感知服务上下线案例 3.HDFS-HA的高可用基本的工作原理 4. HDFS-HA的配置详解 5. HBASE(简介,安装,shell客户端,java客户端)
1. ZK的监控机制 1.1 监听数据的变化 (1)监听一次 public class ChangeDataWacher { public static void main(String[] arg ...
- HBase详解
1. hbase简介 1.1. 什么是hbase HBASE是一个高可靠性.高性能.面向列.可伸缩的分布式存储系统,利用HBASE技术可在廉价PC Server上搭建起大规模结构化存储集群. H ...
- Hive集成HBase详解
摘要 Hive提供了与HBase的集成,使得能够在HBase表上使用HQL语句进行查询 插入操作以及进行Join和Union等复杂查询 应用场景 1. 将ETL操作的数据存入HBase 2. HB ...
- Linux用户、用户组权限管理详解 --- 02
2,用户.用户组管理操作详解: 2.1 adduser 添加用户: adduser [-u uid][-g group][-d home][-s shell] -u:直接给出userID ...
- 图文详解压力测试工具JMeter的安装与使用
压力测试是目前大型网站系统的设计和开发中不可或缺的环节,通常会和容量预估等工作结合在一起,穿插在系统开发的不同方案.压力测试可以帮助我们及时发现系统的性能短板和瓶颈问题,在这个基础在上再进行针对性的性 ...
随机推荐
- Kafka之工作流程分析
Kafka之工作流程分析 kafka核心组成 一.Kafka生产过程分析 1.1 写入方式 producer采用推(push)模式将消息发布到broker,每条消息都被追加(append)到分区(pa ...
- Linux、Windows下Redis的安装即Redis的基本使用详解
前言 什么是Redis Redis是一个基于内存的key-value结构数据库.Redis 是互联网技术领域使用最为广泛的存储中间件,它是「Remote Dictionary Service」的首字母 ...
- Linux基础_6_文本编辑
vi i #编辑 ESC+:wq #保存退出 ESC+ZZ #保存退出 ESC+:q! #不保存退出 shift+z+q #不保存退出 dd #删除所在行 ESC+u #撤销dd误操作 :/字符串 # ...
- commons-fileupload组件和commons-io组件的详细下载
commons-fileupload组件和commons-io组件的详细下载 1. commons-fileupload组件的下载 下载地址:http://commons.apache.org/fil ...
- iframe的简单使用
看人家写的真的是摸不着头脑.自己写.还是清楚 局部数据的刷新:可以使用ajax.这里只是简单的演示 只作:例子使用.简单演示页面跳转 a标签中target属性和iframe中的name对应.相当于将该 ...
- 【JavaWeb】学习笔记——Ajax、Axios
Ajax Ajax 介绍 AJAX(Asynchronous JavaScript And XML):异步的JavaScript 和 XML AJAX 的作用: 与服务器进行数据交换:通过AJAX可以 ...
- 笔记:Debian下为sublime text建立软链接[像vi一样到处使用]
先查询sublime-text安装路径 :~$ dpkg -L sublime-text /. /opt /opt/sublime_text ... /opt/sublime_text/sublime ...
- Java函数式编程:二、高阶函数,闭包,函数组合以及柯里化
承接上文:Java函数式编程:一.函数式接口,lambda表达式和方法引用 这次来聊聊函数式编程中其他的几个比较重要的概念和技术,从而使得我们能更深刻的掌握Java中的函数式编程. 本篇博客主要聊聊以 ...
- 云原生之旅 - 10)手把手教你安装 Jenkins on Kubernetes
前言 谈到持续集成工具就离不开众所周知的Jenkins,本文带你了解如何在 Kubernetes 上安装 Jenkins,后续文章会带你深入了解如何使用k8s pod 作为 Jenkins的build ...
- 嵌入式-C语言基础:指针是存放变量的地址,那为什么要区分类型?
指针是存放变量的地址,那为什么要区分类型?不能所有类型的变量都用一个类型吗?下面用一个例子来说明这个问题. #include<stdio.h> int main() { int a=0x1 ...