Android 12(S) 图形显示系统 - BufferQueue的工作流程(九)
题外话
Covid-19疫情的强烈反弹,小区里检测出了无症状感染者。小区封闭管理,我也不得不居家办公了。既然这么大把的时间可以光明正大的宅家里,自然要好好利用,八个字 == 努力工作,好好学习

一、前言
这篇文章中,将详细讲解 生产者 -- 图形缓冲队列 -- 消费者 这个模型的的具体工作流程。我们还是从我们的demo运行流程着手。
可以再回头看看 Android 12(S) 图形显示系统 - 示例应用(二)
在demo示例中,我们获取buffer --> 填充数据 --> 送出显示的代码如下所示(做了简化):
// 9. dequeue a buffer
ANativeWindowBuffer *nativeBuffer = nullptr;
int hwcFD = -1;
err = nativeWindow->dequeueBuffer(nativeWindow, &nativeBuffer, &hwcFD);
// 10. make sure really control the dequeued buffer
sp<Fence> hwcFence(new Fence(hwcFD));
int waitResult = hwcFence->waitForever("dequeueBuffer_EmptyNative");
// 11. fill buffer
sp<GraphicBuffer> buf(GraphicBuffer::from(nativeBuffer));
uint8_t* img = nullptr;
err = buf->lock(GRALLOC_USAGE_SW_WRITE_OFTEN, (void**)(&img));
fillRGBA8Buffer(img);
err = buf->unlock();
// 13. queue the buffer to display
int gpuFD = -1;
err = nativeWindow->queueBuffer(nativeWindow, buf->getNativeBuffer(), gpuFD);获取图形缓冲区调用流程:
==> ANativeWindow::dequeueBuffer
==> Surface::hook_dequeueBuffer
==> Surface::dequeueBuffer
==> BufferQueueProducer::dequeueBuffer
填充数据后返还图形缓冲区的调用流程:
==> ANativeWindow::queueBuffer
==> Surface::hook_queueBuffer
==> Surface::queueBuffer
==> BufferQueueProducer::queueBuffer
前面文章讲解中提到,BLASTBufferQueue中创建Surface对象时,初始化其成员mGraphicBufferProducer,这个就是指向了一个GraphicBufferProducer对象。
当然,demo作为客户端仅仅是展示了生产者的工作,那消费者的工作又是如何的呢?
先用一张流程图概述一下:
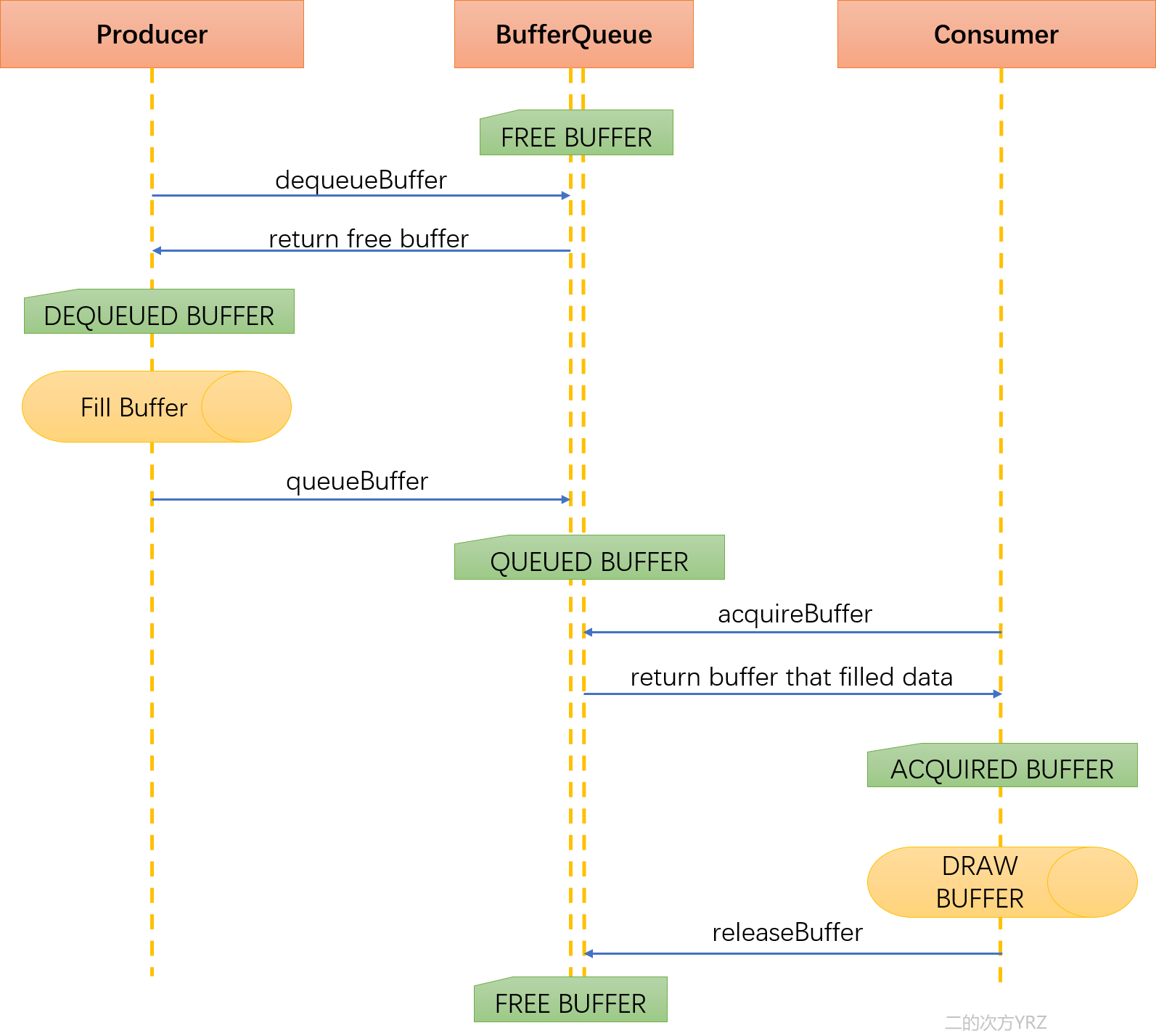
上图基本展示了BufferQueue的工作逻辑以及Buffer的流转过程和状态变化情况。
上图描述的流程我再重复唠叨一遍:
- Producer准备绘图时,调用dequeueBuffer向BufferQueue请求一块buffer;
- BufferQueue收到dequeueBuffer的请求后会去自己的BufferSlot队列中寻找一个FREE状态的,然后返回它的index;
- Producer拿到可用的buffer后就可以准备填充数据了;
- Producer填充数据完毕,调用queueBuffer将bffer再返还给BufferQueue;
- BufferQueue收到queueBuffer请求后,将指定的buffer包装为BufferItem对象,放入mQueue,并通知Consumer来消费;
- Consumer收到 frame available的通知后,调用acquireBuffer,获取一个buffer;
- Consumer拿到buffer进行消费,一般是指SurfaceFlinger做渲染显示;
- Consumer完成处理,调用releaseBuffer把buffer返还给BufferQueue,这个buffer之后就可以再次在新的循环中使用了。
另外一点请留意各个函数调用后,对应的BufferSlot(GraphicBuffer)的状态变化。一般是这样的:
FREE -> DEQUEUED -> QUEUED -> ACQUIRED -> FREE
二、生产者-Producer的相关逻辑
代码位置 :/frameworks/native/libs/gui/BufferQueueProducer.cpp
2.1 申请图形缓冲区
申请图形缓冲区,是从队列中取出一个可用的graphic buffer ,所以函数名叫dequeueBuffer ,它的作用是在应用程序一端准备绘制图像时,向BufferQueue申请一块可用的GraphicBuffer,有了这个buffer就可以把图像数据写入送去做处理和显示。
BufferQueueCore中mSlots数组管理缓冲区,最大容量是64,这个mSlots一开始静态分配了64个BufferSlot大小的空间,但是其中的数据缓冲区GraphicBuffer的分配是动态的,在需要时分配或重新分配。
dequeueBuffer流程
status_t BufferQueueProducer::dequeueBuffer(int* outSlot, sp<android::Fence>* outFence,
uint32_t width, uint32_t height, PixelFormat format,
uint64_t usage, uint64_t* outBufferAge,
FrameEventHistoryDelta* outTimestamps) {
ATRACE_CALL();
{ // Autolock scope
std::lock_guard<std::mutex> lock(mCore->mMutex);
mConsumerName = mCore->mConsumerName;
// BufferQueue已经被废弃,就直接返回了
if (mCore->mIsAbandoned) {
BQ_LOGE("dequeueBuffer: BufferQueue has been abandoned");
return NO_INIT;
}
// 没有producer与BufferQueue建立连接,直接返回了
if (mCore->mConnectedApi == BufferQueueCore::NO_CONNECTED_API) {
BQ_LOGE("dequeueBuffer: BufferQueue has no connected producer");
return NO_INIT;
}
} // Autolock scope
BQ_LOGV("dequeueBuffer: w=%u h=%u format=%#x, usage=%#" PRIx64, width, height, format, usage);
// 宽高信息不正常,直接返回
if ((width && !height) || (!width && height)) {
BQ_LOGE("dequeueBuffer: invalid size: w=%u h=%u", width, height);
return BAD_VALUE;
}
// 定义返回值并初始化
status_t returnFlags = NO_ERROR;
EGLDisplay eglDisplay = EGL_NO_DISPLAY;
EGLSyncKHR eglFence = EGL_NO_SYNC_KHR;
bool attachedByConsumer = false;
{ // Autolock scope
std::unique_lock<std::mutex> lock(mCore->mMutex);
// If we don't have a free buffer, but we are currently allocating, we wait until allocation
// is finished such that we don't allocate in parallel.
// mFreeBuffers中存储的是绑定了GraphicBuffer且状态为FREE的BufferSlot;
// mFreeBuffers为空,且正在分配GraphicBuffer内存时,需等待分配完成
if (mCore->mFreeBuffers.empty() && mCore->mIsAllocating) {
mDequeueWaitingForAllocation = true;
mCore->waitWhileAllocatingLocked(lock); // 等待
mDequeueWaitingForAllocation = false;
mDequeueWaitingForAllocationCondition.notify_all();
}
if (format == 0) {
format = mCore->mDefaultBufferFormat;
}
// Enable the usage bits the consumer requested
usage |= mCore->mConsumerUsageBits;
const bool useDefaultSize = !width && !height;
if (useDefaultSize) {
width = mCore->mDefaultWidth;
height = mCore->mDefaultHeight;
if (mCore->mAutoPrerotation &&
(mCore->mTransformHintInUse & NATIVE_WINDOW_TRANSFORM_ROT_90)) {
std::swap(width, height);
}
}
// 寻找BufferSlot
int found = BufferItem::INVALID_BUFFER_SLOT;
while (found == BufferItem::INVALID_BUFFER_SLOT) {
// 获取到可用的BufferSlot,它在mSlots的下标保存在found中,下面有讲解这个方法
status_t status = waitForFreeSlotThenRelock(FreeSlotCaller::Dequeue, lock, &found);
if (status != NO_ERROR) {
return status;
}
// This should not happen 没有找到可用的
if (found == BufferQueueCore::INVALID_BUFFER_SLOT) {
BQ_LOGE("dequeueBuffer: no available buffer slots");
return -EBUSY;
}
//获取found索引对应的BufferSlot及对应的GraphicBuffer。后面需要为该GraphicBuffer分配空间
const sp<GraphicBuffer>& buffer(mSlots[found].mGraphicBuffer);
// If we are not allowed to allocate new buffers,
// waitForFreeSlotThenRelock must have returned a slot containing a
// buffer. If this buffer would require reallocation to meet the
// requested attributes, we free it and attempt to get another one.
// 在不允许分配新的buffer时,waitForFreeSlotThenRelock必须返回一个绑定GraphicBuffer的slot.
// 如果这个buffer需要重新分配来满足新要求的属性,我们必须释放它然后再重新请求一个。
if (!mCore->mAllowAllocation) {
if (buffer->needsReallocation(width, height, format, BQ_LAYER_COUNT, usage)) {
if (mCore->mSharedBufferSlot == found) {
BQ_LOGE("dequeueBuffer: cannot re-allocate a sharedbuffer");
return BAD_VALUE;
}
mCore->mFreeSlots.insert(found);
mCore->clearBufferSlotLocked(found);
found = BufferItem::INVALID_BUFFER_SLOT;
continue;
}
}
}
//到此,说明已经找到了一个BufferSlot
const sp<GraphicBuffer>& buffer(mSlots[found].mGraphicBuffer);
if (mCore->mSharedBufferSlot == found &&
buffer->needsReallocation(width, height, format, BQ_LAYER_COUNT, usage)) {
BQ_LOGE("dequeueBuffer: cannot re-allocate a shared"
"buffer");
return BAD_VALUE;
}
//如果不是共享buffer,就把这个BufferSlot对应的下标,加入到mActiveBuffers中
if (mCore->mSharedBufferSlot != found) {
mCore->mActiveBuffers.insert(found);
}
*outSlot = found; // outSlot是最终返回给Surface
ATRACE_BUFFER_INDEX(found);
attachedByConsumer = mSlots[found].mNeedsReallocation;
mSlots[found].mNeedsReallocation = false; //表示不需要重新分配空间
mSlots[found].mBufferState.dequeue(); // BufferSlot(BufferState)状态设置为dequeue
// 这里再次判断buffer是否为空,或者是否需要重新分配空间
// needsReallocation方法判断buffer属性和请求的是否匹配,不匹配需要重新分配
if ((buffer == nullptr) ||
buffer->needsReallocation(width, height, format, BQ_LAYER_COUNT, usage))
{ // 重置BufferSlot的变量值,
mSlots[found].mAcquireCalled = false;
mSlots[found].mGraphicBuffer = nullptr;
mSlots[found].mRequestBufferCalled = false;
mSlots[found].mEglDisplay = EGL_NO_DISPLAY;
mSlots[found].mEglFence = EGL_NO_SYNC_KHR;
mSlots[found].mFence = Fence::NO_FENCE;
mCore->mBufferAge = 0;
mCore->mIsAllocating = true;
returnFlags |= BUFFER_NEEDS_REALLOCATION;
} else {
// We add 1 because that will be the frame number when this buffer
// is queued
mCore->mBufferAge = mCore->mFrameCounter + 1 - mSlots[found].mFrameNumber;
}
BQ_LOGV("dequeueBuffer: setting buffer age to %" PRIu64,
mCore->mBufferAge);
if (CC_UNLIKELY(mSlots[found].mFence == nullptr)) {
BQ_LOGE("dequeueBuffer: about to return a NULL fence - "
"slot=%d w=%d h=%d format=%u",
found, buffer->width, buffer->height, buffer->format);
}
eglDisplay = mSlots[found].mEglDisplay;
// 因为GraphicBuffer 最终是要到Gpu去消费,而当前的操作都是在cpu,
// 为了同步cpu和Gpu对同一数据的使用,产生了这中Fence机制
eglFence = mSlots[found].mEglFence;
// Don't return a fence in shared buffer mode, except for the first
// frame.
*outFence = (mCore->mSharedBufferMode &&
mCore->mSharedBufferSlot == found) ?
Fence::NO_FENCE : mSlots[found].mFence;
mSlots[found].mEglFence = EGL_NO_SYNC_KHR;
mSlots[found].mFence = Fence::NO_FENCE;
// If shared buffer mode has just been enabled, cache the slot of the
// first buffer that is dequeued and mark it as the shared buffer.
if (mCore->mSharedBufferMode && mCore->mSharedBufferSlot ==
BufferQueueCore::INVALID_BUFFER_SLOT) {
mCore->mSharedBufferSlot = found;
mSlots[found].mBufferState.mShared = true;
}
if (!(returnFlags & BUFFER_NEEDS_REALLOCATION)) {
if (mCore->mConsumerListener != nullptr) {
mCore->mConsumerListener->onFrameDequeued(mSlots[*outSlot].mGraphicBuffer->getId());
}
}
} // Autolock scope
// //当前BufferSlot 是否需要分配空间
if (returnFlags & BUFFER_NEEDS_REALLOCATION) {
BQ_LOGV("dequeueBuffer: allocating a new buffer for slot %d", *outSlot);
// 使用Gralloc HAL进行内存分配,是在匿名内存中分配空间
sp<GraphicBuffer> graphicBuffer = new GraphicBuffer(
width, height, format, BQ_LAYER_COUNT, usage,
{mConsumerName.string(), mConsumerName.size()});
status_t error = graphicBuffer->initCheck();
{ // Autolock scope
std::lock_guard<std::mutex> lock(mCore->mMutex);
if (error == NO_ERROR && !mCore->mIsAbandoned) {
graphicBuffer->setGenerationNumber(mCore->mGenerationNumber);
// 分配成功,把GraphicBuffer与对应的BufferSlot进行绑定
mSlots[*outSlot].mGraphicBuffer = graphicBuffer;
if (mCore->mConsumerListener != nullptr) {
mCore->mConsumerListener->onFrameDequeued(
mSlots[*outSlot].mGraphicBuffer->getId());
}
}
// 分配完成,唤醒等待的线程
mCore->mIsAllocating = false;
mCore->mIsAllocatingCondition.notify_all();
// 分配graphicBuffer 出错,把BufferSlot插入到mFreeSlots 等操作
if (error != NO_ERROR) {
mCore->mFreeSlots.insert(*outSlot);
mCore->clearBufferSlotLocked(*outSlot);
BQ_LOGE("dequeueBuffer: createGraphicBuffer failed");
return error;
}
if (mCore->mIsAbandoned) {
mCore->mFreeSlots.insert(*outSlot);
mCore->clearBufferSlotLocked(*outSlot);
BQ_LOGE("dequeueBuffer: BufferQueue has been abandoned");
return NO_INIT;
}
VALIDATE_CONSISTENCY();
} // Autolock scope
}
if (attachedByConsumer) {
returnFlags |= BUFFER_NEEDS_REALLOCATION;
}
if (eglFence != EGL_NO_SYNC_KHR) {
// 等待Buffer状态就绪,,然后fence围栏放行
EGLint result = eglClientWaitSyncKHR(eglDisplay, eglFence, 0,
1000000000);
// If something goes wrong, log the error, but return the buffer without
// synchronizing access to it. It's too late at this point to abort the
// dequeue operation.
if (result == EGL_FALSE) {
BQ_LOGE("dequeueBuffer: error %#x waiting for fence",
eglGetError());
} else if (result == EGL_TIMEOUT_EXPIRED_KHR) {
BQ_LOGE("dequeueBuffer: timeout waiting for fence");
}
eglDestroySyncKHR(eglDisplay, eglFence);
}
BQ_LOGV("dequeueBuffer: returning slot=%d/%" PRIu64 " buf=%p flags=%#x",
*outSlot,
mSlots[*outSlot].mFrameNumber,
mSlots[*outSlot].mGraphicBuffer->handle, returnFlags);
if (outBufferAge) {
*outBufferAge = mCore->mBufferAge;
}
addAndGetFrameTimestamps(nullptr, outTimestamps);
return returnFlags;
}代码中都有做了注释,dequeue的主要逻辑基本展现了出来。
下面我们了看看其中的函数 waitForFreeSlotThenRelock,它的作用是在mSlot数组中查找FREE状态的slot,如果找到了就返回这个slot中的index
status_t BufferQueueProducer::waitForFreeSlotThenRelock(FreeSlotCaller caller,
std::unique_lock<std::mutex>& lock, int* found) const {
// // 标记 dequeueBuffer 还是attachBuffer 调用了它
auto callerString = (caller == FreeSlotCaller::Dequeue) ?
"dequeueBuffer" : "attachBuffer";
bool tryAgain = true;
// 在这个while循环,寻找可用的BufferSlot或发生错误退出
while (tryAgain) {
if (mCore->mIsAbandoned) {
BQ_LOGE("%s: BufferQueue has been abandoned", callerString);
return NO_INIT;
}
int dequeuedCount = 0; // 统计mActiveBuffers中状态为DEQUEUED的BufferSlot数量
int acquiredCount = 0; // 统计mActiveBuffers中状态为ACQUIRED的BufferSlot数量
// mActiveBuffers表示已经绑定了GraphicBuffer且状态为非FREE的BufferSlot集合
for (int s : mCore->mActiveBuffers) {
if (mSlots[s].mBufferState.isDequeued()) {
++dequeuedCount;
}
if (mSlots[s].mBufferState.isAcquired()) {
++acquiredCount;
}
}
// Producers are not allowed to dequeue more than
// mMaxDequeuedBufferCount buffers.
// This check is only done if a buffer has already been queued
// 判断是否超出了可以dequeue的buffer的最大数量
if (mCore->mBufferHasBeenQueued &&
dequeuedCount >= mCore->mMaxDequeuedBufferCount) {
// Supress error logs when timeout is non-negative.
if (mDequeueTimeout < 0) {
BQ_LOGE("%s: attempting to exceed the max dequeued buffer "
"count (%d)", callerString,
mCore->mMaxDequeuedBufferCount);
}
return INVALID_OPERATION;
}
*found = BufferQueueCore::INVALID_BUFFER_SLOT;
// If we disconnect and reconnect quickly, we can be in a state where
// our slots are empty but we have many buffers in the queue. This can
// cause us to run out of memory if we outrun the consumer. Wait here if
// it looks like we have too many buffers queued up.
// 获取BufferQueue最大buffer数量
const int maxBufferCount = mCore->getMaxBufferCountLocked();
// 当前mQueue中的Buffer 数量,是否大于maxBufferCount
bool tooManyBuffers = mCore->mQueue.size()
> static_cast<size_t>(maxBufferCount);
if (tooManyBuffers) {
BQ_LOGV("%s: queue size is %zu, waiting", callerString,
mCore->mQueue.size());
} else {
// If in shared buffer mode and a shared buffer exists, always
// return it.
// 共享buffer模式且有共享buffer存在,返回它
if (mCore->mSharedBufferMode && mCore->mSharedBufferSlot !=
BufferQueueCore::INVALID_BUFFER_SLOT) {
*found = mCore->mSharedBufferSlot;
} else {
if (caller == FreeSlotCaller::Dequeue) {
// 1. 从dequeueBuffer 中调用当前函数的
// 2. 优先从mFreeBuffers中寻找BufferSlot,getFreeBufferLocked获取mFreeBuffers队头的item
// 3. mFreeBuffers找不到,再从mFreeSlots寻找BufferSlot,getFreeSlotLocked获取mFreeSlots队头的item
// If we're calling this from dequeue, prefer free buffers
int slot = getFreeBufferLocked();
if (slot != BufferQueueCore::INVALID_BUFFER_SLOT) {
*found = slot;
} else if (mCore->mAllowAllocation) {
*found = getFreeSlotLocked();
}
} else {
//从attachBuffer 中调用当前函数的
// If we're calling this from attach, prefer free slots
int slot = getFreeSlotLocked();
if (slot != BufferQueueCore::INVALID_BUFFER_SLOT) {
*found = slot;
} else {
*found = getFreeBufferLocked();
}
}
}
}
// If no buffer is found, or if the queue has too many buffers
// outstanding, wait for a buffer to be acquired or released, or for the
// max buffer count to change.
tryAgain = (*found == BufferQueueCore::INVALID_BUFFER_SLOT) ||
tooManyBuffers;
// 获取失败,或者当前的Buffer 已经到达最大值,则重试
if (tryAgain) {
// Return an error if we're in non-blocking mode (producer and
// consumer are controlled by the application).
// However, the consumer is allowed to briefly acquire an extra
// buffer (which could cause us to have to wait here), which is
// okay, since it is only used to implement an atomic acquire +
// release (e.g., in GLConsumer::updateTexImage())
if ((mCore->mDequeueBufferCannotBlock || mCore->mAsyncMode) &&
(acquiredCount <= mCore->mMaxAcquiredBufferCount)) {
return WOULD_BLOCK;
}
if (mDequeueTimeout >= 0) {
std::cv_status result = mCore->mDequeueCondition.wait_for(lock,
std::chrono::nanoseconds(mDequeueTimeout));
if (result == std::cv_status::timeout) {
return TIMED_OUT;
}
} else {
// 等待有buffer可以返回
mCore->mDequeueCondition.wait(lock);
}
}
} // while (tryAgain)
return NO_ERROR;
}
上述代码中也做了注释,可以直接阅读源码理解。
dequeueBuffer函数做的事情简单概括如下:
- 寻找状态为FREE的可用的BufferSlot,主要是调用waitForFreeSlotThenRelock,去mFreeBuffers和mFreeSlots中查找;
- 找到可用的BufferSlot后,先把其对应的index添加到mActiveBuffer集合中,标示为活跃状态,并且设置为DEQUEUED状态;
- 如果找到的BufferSlot的GraphicBuffer 为空或者需要重新申请,则把BufferSlot的参数初始化;
- 如果需要重新创建 GraphicBuffer,则创建一个新的GraphicBuffer,并绑定到对应的BufferSlot;
- 其它操作,比如唤醒等待buffer分配完成的线程;
注:在查找可用的BufferSlot时,先去mFreeBuffers中找,找不到再去mFreeSlots中找。
@二的次方 写bug小能手

2.2 填充数据后返还图形缓冲区
客户端/应用通过调用dequeueBuffer获取到一个可用的buffer后,就可以往这个buffer中填充数据了,在我们的demo中这一过程是在fillRGBA8Buffer函数内完成的,具体可见代码。
填充好数据后,就要把这个buffer再返还给BufferQueue,调用的方法是queueBuffer。
直接看源码
status_t BufferQueueProducer::queueBuffer(int slot,
const QueueBufferInput &input, QueueBufferOutput *output) {
ATRACE_CALL();
ATRACE_BUFFER_INDEX(slot);
int64_t requestedPresentTimestamp;
bool isAutoTimestamp;
android_dataspace dataSpace;
Rect crop(Rect::EMPTY_RECT);
int scalingMode;
uint32_t transform;
uint32_t stickyTransform;
sp<Fence> acquireFence;
bool getFrameTimestamps = false;
// 保存Surface传递过来的input里面封装的buffer信息
input.deflate(&requestedPresentTimestamp, &isAutoTimestamp, &dataSpace,
&crop, &scalingMode, &transform, &acquireFence, &stickyTransform,
&getFrameTimestamps);
const Region& surfaceDamage = input.getSurfaceDamage();
const HdrMetadata& hdrMetadata = input.getHdrMetadata();
if (acquireFence == nullptr) {
BQ_LOGE("queueBuffer: fence is NULL");
return BAD_VALUE;
}
auto acquireFenceTime = std::make_shared<FenceTime>(acquireFence);
switch (scalingMode) {
case NATIVE_WINDOW_SCALING_MODE_FREEZE:
case NATIVE_WINDOW_SCALING_MODE_SCALE_TO_WINDOW:
case NATIVE_WINDOW_SCALING_MODE_SCALE_CROP:
case NATIVE_WINDOW_SCALING_MODE_NO_SCALE_CROP:
break;
default:
BQ_LOGE("queueBuffer: unknown scaling mode %d", scalingMode);
return BAD_VALUE;
}
// 回调接口,用于通知consumer
sp<IConsumerListener> frameAvailableListener;
sp<IConsumerListener> frameReplacedListener;
int callbackTicket = 0;
uint64_t currentFrameNumber = 0;
BufferItem item;
{ // Autolock scope
std::lock_guard<std::mutex> lock(mCore->mMutex);
// BufferQueue是否被弃用
if (mCore->mIsAbandoned) {
BQ_LOGE("queueBuffer: BufferQueue has been abandoned");
return NO_INIT;
}
// BufferQueue是否没有连的producer
if (mCore->mConnectedApi == BufferQueueCore::NO_CONNECTED_API) {
BQ_LOGE("queueBuffer: BufferQueue has no connected producer");
return NO_INIT;
}
// BufferSlot对应的slot序号是否合法,状态是否为DEQUEUE
if (slot < 0 || slot >= BufferQueueDefs::NUM_BUFFER_SLOTS) {
BQ_LOGE("queueBuffer: slot index %d out of range [0, %d)",
slot, BufferQueueDefs::NUM_BUFFER_SLOTS);
return BAD_VALUE;
} else if (!mSlots[slot].mBufferState.isDequeued()) {
BQ_LOGE("queueBuffer: slot %d is not owned by the producer "
"(state = %s)", slot, mSlots[slot].mBufferState.string());
return BAD_VALUE;
} else if (!mSlots[slot].mRequestBufferCalled) { // 是否调用了requestBuffer 函数
BQ_LOGE("queueBuffer: slot %d was queued without requesting "
"a buffer", slot);
return BAD_VALUE;
}
// If shared buffer mode has just been enabled, cache the slot of the
// first buffer that is queued and mark it as the shared buffer.
if (mCore->mSharedBufferMode && mCore->mSharedBufferSlot ==
BufferQueueCore::INVALID_BUFFER_SLOT) {
mCore->mSharedBufferSlot = slot;
mSlots[slot].mBufferState.mShared = true;
}
BQ_LOGV("queueBuffer: slot=%d/%" PRIu64 " time=%" PRIu64 " dataSpace=%d"
" validHdrMetadataTypes=0x%x crop=[%d,%d,%d,%d] transform=%#x scale=%s",
slot, mCore->mFrameCounter + 1, requestedPresentTimestamp, dataSpace,
hdrMetadata.validTypes, crop.left, crop.top, crop.right, crop.bottom,
transform,
BufferItem::scalingModeName(static_cast<uint32_t>(scalingMode)));
// 当前queue的具体GraphicBuffer
const sp<GraphicBuffer>& graphicBuffer(mSlots[slot].mGraphicBuffer);
// 根据当前的GraphicBufferd的宽高创建矩形区域
Rect bufferRect(graphicBuffer->getWidth(), graphicBuffer->getHeight());
// 创建裁剪区域
Rect croppedRect(Rect::EMPTY_RECT);
// 裁剪区域 赋值为crop和bufferRect相交部分
crop.intersect(bufferRect, &croppedRect);
if (croppedRect != crop) {
BQ_LOGE("queueBuffer: crop rect is not contained within the "
"buffer in slot %d", slot);
return BAD_VALUE;
}
// Override UNKNOWN dataspace with consumer default
if (dataSpace == HAL_DATASPACE_UNKNOWN) {
dataSpace = mCore->mDefaultBufferDataSpace;
}
mSlots[slot].mFence = acquireFence;
// 改变入队的BufferSlot的状态为QUEUED
mSlots[slot].mBufferState.queue();
// Increment the frame counter and store a local version of it
// for use outside the lock on mCore->mMutex.
++mCore->mFrameCounter;
currentFrameNumber = mCore->mFrameCounter;
mSlots[slot].mFrameNumber = currentFrameNumber;
// 把BufferSlot中的信息封装为BufferItem,后续会把这个BufferItem加入到队列中
item.mAcquireCalled = mSlots[slot].mAcquireCalled;
item.mGraphicBuffer = mSlots[slot].mGraphicBuffer;
item.mCrop = crop;
item.mTransform = transform &
~static_cast<uint32_t>(NATIVE_WINDOW_TRANSFORM_INVERSE_DISPLAY);
item.mTransformToDisplayInverse =
(transform & NATIVE_WINDOW_TRANSFORM_INVERSE_DISPLAY) != 0;
item.mScalingMode = static_cast<uint32_t>(scalingMode);
item.mTimestamp = requestedPresentTimestamp;
item.mIsAutoTimestamp = isAutoTimestamp;
item.mDataSpace = dataSpace;
item.mHdrMetadata = hdrMetadata;
item.mFrameNumber = currentFrameNumber;
item.mSlot = slot;
item.mFence = acquireFence;
item.mFenceTime = acquireFenceTime;
item.mIsDroppable = mCore->mAsyncMode ||
(mConsumerIsSurfaceFlinger && mCore->mQueueBufferCanDrop) ||
(mCore->mLegacyBufferDrop && mCore->mQueueBufferCanDrop) ||
(mCore->mSharedBufferMode && mCore->mSharedBufferSlot == slot);
item.mSurfaceDamage = surfaceDamage;
item.mQueuedBuffer = true;
item.mAutoRefresh = mCore->mSharedBufferMode && mCore->mAutoRefresh;
item.mApi = mCore->mConnectedApi;
mStickyTransform = stickyTransform;
// Cache the shared buffer data so that the BufferItem can be recreated.
if (mCore->mSharedBufferMode) {
mCore->mSharedBufferCache.crop = crop;
mCore->mSharedBufferCache.transform = transform;
mCore->mSharedBufferCache.scalingMode = static_cast<uint32_t>(
scalingMode);
mCore->mSharedBufferCache.dataspace = dataSpace;
}
output->bufferReplaced = false;
if (mCore->mQueue.empty()) {
// 如果mQueue队列为空,则直接push进入这个mQueue,不用考虑阻塞
// When the queue is empty, we can ignore mDequeueBufferCannotBlock
// and simply queue this buffer
mCore->mQueue.push_back(item);
//取出BufferQueueCore的回调接口,下面调用这个接口的onFrameAvailable函数来通知Consumer
frameAvailableListener = mCore->mConsumerListener;
} else {
// When the queue is not empty, we need to look at the last buffer
// in the queue to see if we need to replace it
const BufferItem& last = mCore->mQueue.itemAt(
mCore->mQueue.size() - 1);
if (last.mIsDroppable) {
// 判断最后一个BufferItem是否可以丢弃
if (!last.mIsStale) {
mSlots[last.mSlot].mBufferState.freeQueued();
// After leaving shared buffer mode, the shared buffer will
// still be around. Mark it as no longer shared if this
// operation causes it to be free.
if (!mCore->mSharedBufferMode &&
mSlots[last.mSlot].mBufferState.isFree()) {
mSlots[last.mSlot].mBufferState.mShared = false;
}
// Don't put the shared buffer on the free list.
if (!mSlots[last.mSlot].mBufferState.isShared()) {
mCore->mActiveBuffers.erase(last.mSlot);
mCore->mFreeBuffers.push_back(last.mSlot);
output->bufferReplaced = true;
}
}
// Make sure to merge the damage rect from the frame we're about
// to drop into the new frame's damage rect.
if (last.mSurfaceDamage.bounds() == Rect::INVALID_RECT ||
item.mSurfaceDamage.bounds() == Rect::INVALID_RECT) {
item.mSurfaceDamage = Region::INVALID_REGION;
} else {
item.mSurfaceDamage |= last.mSurfaceDamage;
}
// 用当前BufferItem,替换了队列最后一个BufferItem
// Overwrite the droppable buffer with the incoming one
mCore->mQueue.editItemAt(mCore->mQueue.size() - 1) = item;
//取出回调接口,因为是替换,所以后续调用接口的函数 onFrameReplaced
frameReplacedListener = mCore->mConsumerListener;
} else {
// 直接push进入这个mQueue
mCore->mQueue.push_back(item);
frameAvailableListener = mCore->mConsumerListener;
}
}
// 表示 buffer已经queued,此时入队完成
mCore->mBufferHasBeenQueued = true;
// mDequeueCondition是C++条件变量用作等待/唤醒,这里调用notify_all会唤醒调用了wait的线程
mCore->mDequeueCondition.notify_all();
mCore->mLastQueuedSlot = slot;
//output 参数,会在Surface中继续使用
output->width = mCore->mDefaultWidth;
output->height = mCore->mDefaultHeight;
output->transformHint = mCore->mTransformHintInUse = mCore->mTransformHint;
output->numPendingBuffers = static_cast<uint32_t>(mCore->mQueue.size());
output->nextFrameNumber = mCore->mFrameCounter + 1;
ATRACE_INT(mCore->mConsumerName.string(),
static_cast<int32_t>(mCore->mQueue.size()));
#ifndef NO_BINDER
mCore->mOccupancyTracker.registerOccupancyChange(mCore->mQueue.size());
#endif
// Take a ticket for the callback functions
callbackTicket = mNextCallbackTicket++;
VALIDATE_CONSISTENCY();
} // Autolock scope
// It is okay not to clear the GraphicBuffer when the consumer is SurfaceFlinger because
// it is guaranteed that the BufferQueue is inside SurfaceFlinger's process and
// there will be no Binder call
if (!mConsumerIsSurfaceFlinger) {
item.mGraphicBuffer.clear();
}
// Update and get FrameEventHistory.
nsecs_t postedTime = systemTime(SYSTEM_TIME_MONOTONIC);
NewFrameEventsEntry newFrameEventsEntry = {
currentFrameNumber,
postedTime,
requestedPresentTimestamp,
std::move(acquireFenceTime)
};
addAndGetFrameTimestamps(&newFrameEventsEntry,
getFrameTimestamps ? &output->frameTimestamps : nullptr);
// Call back without the main BufferQueue lock held, but with the callback
// lock held so we can ensure that callbacks occur in order
int connectedApi;
sp<Fence> lastQueuedFence;
{ // scope for the lock
std::unique_lock<std::mutex> lock(mCallbackMutex);
while (callbackTicket != mCurrentCallbackTicket) {
mCallbackCondition.wait(lock);
}
//通知consumer,此处调用接口的不同,是有上面,是否替换最后一个BufferItem 决定的
if (frameAvailableListener != nullptr) {
frameAvailableListener->onFrameAvailable(item);
} else if (frameReplacedListener != nullptr) {
frameReplacedListener->onFrameReplaced(item);
}
connectedApi = mCore->mConnectedApi;
lastQueuedFence = std::move(mLastQueueBufferFence);
mLastQueueBufferFence = std::move(acquireFence);
mLastQueuedCrop = item.mCrop;
mLastQueuedTransform = item.mTransform;
++mCurrentCallbackTicket;
mCallbackCondition.notify_all();
}
// Wait without lock held
if (connectedApi == NATIVE_WINDOW_API_EGL) {
// Waiting here allows for two full buffers to be queued but not a
// third. In the event that frames take varying time, this makes a
// small trade-off in favor of latency rather than throughput.
lastQueuedFence->waitForever("Throttling EGL Production");
}
return NO_ERROR;
}queueBuffer 的流程主要做了这两件事情:
- 将对应 BufferSlot 状态设置成 QUEUED
- 创建 BufferItem 对象,并将 GraphicBuffer 的数据复制给 BufferItem,并入队到 BufferQueueCore 的 mQueue 队列中,这样可以方便图像消费者直接按先进先出的顺序从 mQueue 队列取出 GraphicBuffer 使用
到此queueBuffer 就分析完了。其中会调用了 mCore->mConsumerListener; 的回调接口,来通知consumer消费数据,那么这个回调接口是在何时被传入的,接口的是什么?
这个疑问留到下一篇单独讲解。
三、小结
本文主要聚焦生产者一端的处理逻辑,分析了如何获取buffer以及填充数据后返还buffer的流程。
对照文章开头的那张图片,也只是讲了左半部分的逻辑,下一篇中我们就会涉足consumer的处理流程了。
必读:
Android 12(S) 图形显示系统 - 开篇

Android 12(S) 图形显示系统 - BufferQueue的工作流程(九)的更多相关文章
- Android 12(S) 图形显示系统 - BufferQueue的工作流程(八)
题外话 最近总有一个感觉:在不断学习中,越发的感觉自己的无知,自己是不是要从"愚昧之巅"掉到"绝望之谷"了,哈哈哈 邓宁-克鲁格效应 一.前言 前面的文章中已经 ...
- Android 12(S) 图形显示系统 - BufferQueue的工作流程(十)
题外话 疫情隔离在家,周末还在努力学习的我 ..... 一.前言 上一篇文章中,有基本讲清楚Producer一端的处理逻辑,最后也留下了一个疑问: Consumer是什么时候来消费数据的?他是自己主 ...
- Android 12(S) 图形显示系统 - BufferQueue的工作流程(十一)
题外话 我竟然已经写了这个系列的十一篇文章了,虽然内容很浅显,虽然内容很枯燥,虽然内容也许没营养,但我为自己的坚持点赞! 一.前言 前面的两篇文章,分别讲解了Producer的处理逻辑和queue b ...
- Android 12(S) 图形显示系统 - BufferQueue/BLASTBufferQueue之初识(六)
题外话 你有没有听见,心里有一声咆哮,那一声咆哮,它好像在说:我就是要从后面追上去! 写文章真的好痛苦,特别是自己对这方面的知识也一知半解就更加痛苦了.这已经是这个系列的第六篇了,很多次都想放弃了,但 ...
- Android 12(S) 图形显示系统 - 解读Gralloc架构及GraphicBuffer创建/传递/释放(十四)
必读: Android 12(S) 图形显示系统 - 开篇 一.前言 在前面的文章中,已经出现过 GraphicBuffer 的身影,GraphicBuffer 是Android图形显示系统中的一个重 ...
- Android 12(S) 图形显示系统 - 简单聊聊 SurfaceView 与 BufferQueue的关联(十三)
必读: Android 12(S) 图形显示系统 - 开篇 一.前言 前面的文章中,讲解的内容基本都是从我们提供的一个 native demo Android 12(S) 图形显示系统 - 示例应用( ...
- Android 12(S) 图形显示系统 - 初识ANativeWindow/Surface/SurfaceControl(七)
题外话 "行百里者半九十",是说步行一百里路,走过九十里,只能算是走了一半.因为步行越接近目的地,走起来越困难.借指凡事到了接近成功,往往是最吃力.最艰难的时段.劝人做事贵在坚持, ...
- Android 12(S) 图形显示系统 - 示例应用(二)
1 前言 为了更深刻的理解Android图形系统抽象的概念和BufferQueue的工作机制,这篇文章我们将从Native Level入手,基于Android图形系统API写作一个简单的图形处理小程序 ...
- Android 12(S) 图形显示系统 - 基本概念(一)
1 前言 Android图形系统是系统框架中一个非常重要的子系统,与其它子系统一样,Android 框架提供了各种用于 2D 和 3D 图形渲染的 API供开发者使用来创建绚丽多彩的应用APP.图形渲 ...
随机推荐
- redis集群升级,数据迁移及校验
本次由于安全漏洞原因,需要降redis3升级为redis6,涉及到数据迁移及校验等,用阿里redis-shake迁移工具迁移,并用阿里RedisFullCheck工具进行数据比对 一.新redis安装 ...
- 实现基于MYSQL验证的vsftpd虚拟用户访问
一.配置mysql服务器 1.1 安装mysql # yum -y install mariadb-server # systemctl enable --now mariadb.service &a ...
- spring5+Struts2+hibernate5
一,加jar包 加入顺序,个人推荐,spring->struts2->hibernate spring的jar包:基本包共21个+用到的aspectj注解的包2个+日志包1个 ------ ...
- 最好的Java开发工具---IDEA
IntelliJ IDEA工具的使用 1. 常见的Java集成开发工具 Eclipse IBM团队研发的一个开源的非常好用的集成开发环境.寓意:吞并Sun公司.不过Sun最终被Oracle公司收购了. ...
- 联邦学习:按Dirichlet分布划分Non-IID样本
我们在<Python中的随机采样和概率分布(二)>介绍了如何用Python现有的库对一个概率分布进行采样,其中的dirichlet分布大家一定不会感到陌生.该分布的概率密度函数为 \[P( ...
- 5道面试题,拿捏String底层原理!
原创:微信公众号 码农参上,欢迎分享,转载请保留出处. String字符串是我们日常工作中常用的一个类,在面试中也是高频考点,这里Hydra精心总结了一波常见但也有点烧脑的String面试题,一共5道 ...
- kubernetes之数据管理
volume emptyDir [machangwei@mcwk8s-master ~]$ kubectl apply -f mcwVolume1.yml #部署emptydir pod/produc ...
- 通过shell脚本统计elasticsearch indices每天的数量以及大小
前情提要: 最近elasticsearch集群总出问题,之前虽然修复了,现在又出现新的问题,于是PM要求拉取elasticsearch每天建立的索引有多少,索引有多大,需要对机器进行评估 客户现场无法 ...
- 在线pdf请你谨慎打开
本篇其实算之前安全整改话题的一点补充,对之前内容感兴趣的可以走以下快捷通道: 安全漏洞整改系列(二) 安全漏洞整改系列(一) 背景 前不久某家客户对我们提供的系统又进行了一轮安全测试,其中有一条我觉得 ...
- 关于 share 音乐分享官方文档补充
例子 音乐分享 /*--------微信朋友圈--------*/ [shareParams SSDKSetupWeChatParamsByText:@"内容" title:@&q ...