Nvidia GPU池化-远程GPU
1 背景
2 远程GPU
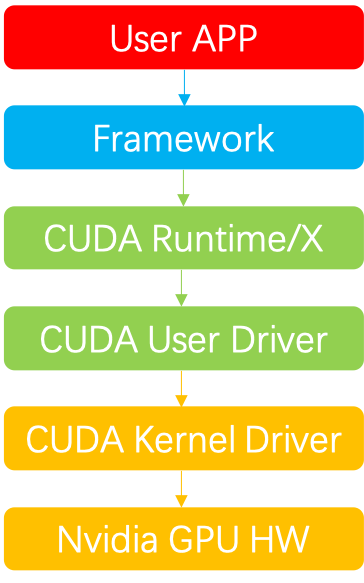
- User APP:业务层,如训练或推理任务等
- Framework:框架层,如tensorflow、pytorch、paddle、megengine等
- CUDA Runtime:CUDA Runtime及周边生态库,如cudart、cublas、cudnn、cufft、cusparse等
- CUDA User Driver:用户态CUDA Driver,如cuda、nvml等
- CUDA Kernel Driver:内核态CUDA Driver,参考官方开源代码,如nvidia.ko等
- Nvidia GPU HW:GPU硬件
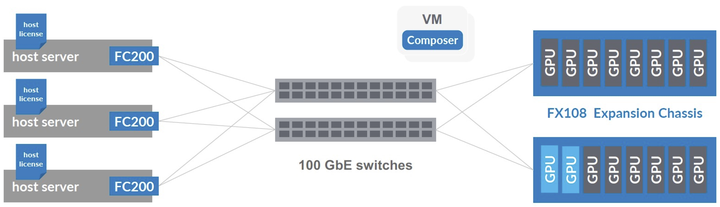
2.1 Fungible
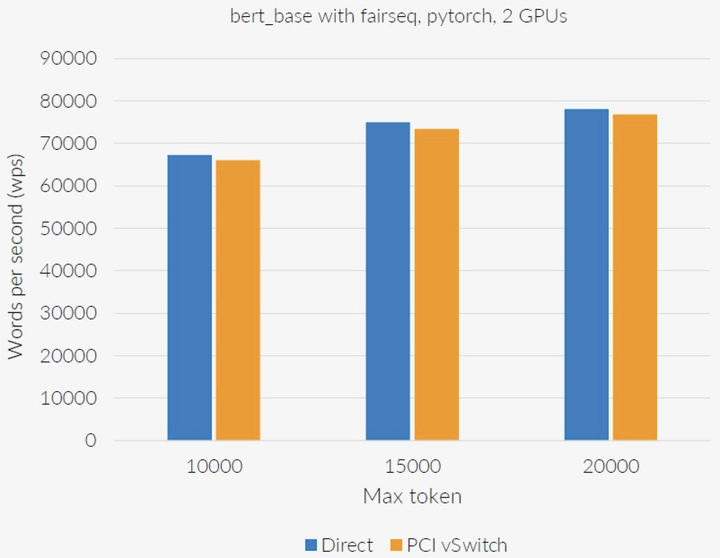
2.2 rCUDA
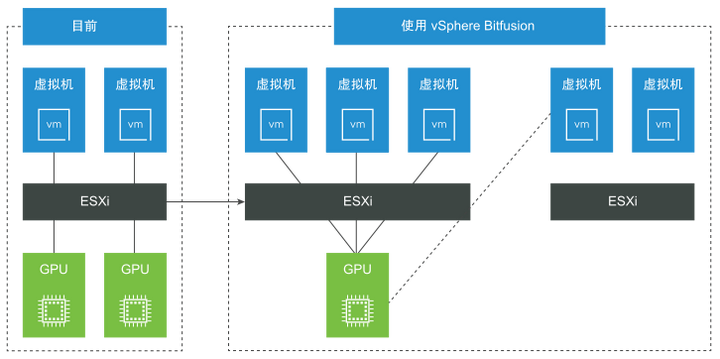
2.3 Bitfusion
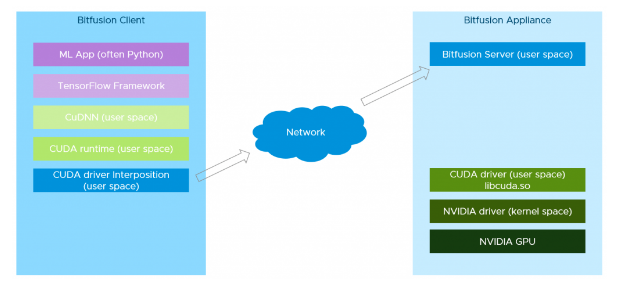
- Bitfusion Server:把GPU安装在vSphere服务器上(要求vSphere 7以上版本),然后在上面运行Bitfusion Server,Bitfusion Server可以把物理GPU资源虚拟化,共享给多个用户使用。
- Bitfusion Client:Bitfusion Client是运行在其他vSphere服务器上的Linux虚机(要求 vSphere 6.7 以上版本),机器学习工作负载运行在这些虚拟机上,Bitfusion会把它们对于GPU的服务请求通过网络传输给Bitfusion Server,计算完成后再返回结果。对于机器学习工作负载来说,远程GPU是完全透明的,它就像是在使用本地的GPU硬件。
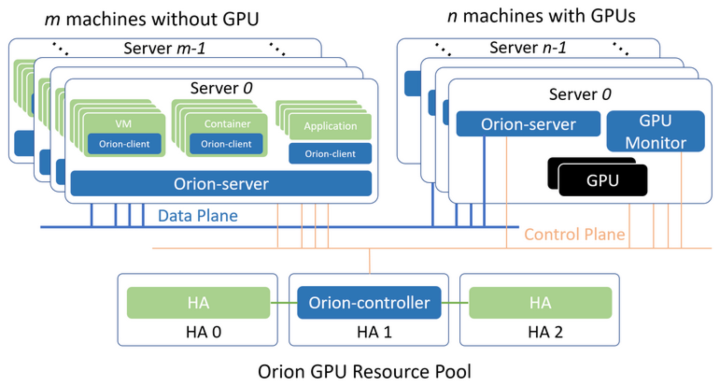
2.4 OrionX
- Orion Controller:负责整个GPU资源池的资源管理。其响应Orion Client的vGPU请求,并从GPU资源池中为Orion Client端的CUDA应用程序分配并返回Orion vGPU资源。
- Orion Server:负责GPU资源化的后端服务程序,部署在每一个CPU以及GPU节点上,接管本机内的所有物理GPU。当Orion Client端应用程序运行时,通过Orion Controller的资源调度,建立和Orion Server的连接。Orion Server为其应用程序的所有CUDA调用提供一个隔离的运行环境以及真实GPU硬件算力。
- Orion Client:模拟了NVidia CUDA的运行库环境,为CUDA程序提供了API接口兼容的全新实现。通过和Orion其他功能组件的配合,为CUDA应用程序虚拟化了一定数量的虚拟GPU(Orion vGPU)。使用CUDA动态链接库的CUDA应用程序可以通过操作系统环境设置,使得一个CUDA应用程序在运行时由操作系统负责链接到Orion Client提供的动态链接库上。由于Orion Client模拟了NVidia CUDA运行环境,因此CUDA应用程序可以透明无修改地直接运行在Orion vGPU之上。
3 其他
3.1 技术难点
3.2 GPU热迁移
Nvidia GPU池化-远程GPU的更多相关文章
- 【转载】 NVIDIA Tesla/Quadro和GeForce GPU比较
原文地址: https://blog.csdn.net/m0_37462765/article/details/74394932 版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议 ...
- 第十四节,TensorFlow中的反卷积,反池化操作以及gradients的使用
反卷积是指,通过测量输出和已知输入重构未知输入的过程.在神经网络中,反卷积过程并不具备学习的能力,仅仅是用于可视化一个已经训练好的卷积神经网络,没有学习训练的过程.反卷积有着许多特别的应用,一般可以用 ...
- tensorflow的卷积和池化层(二):记实践之cifar10
在tensorflow中的卷积和池化层(一)和各种卷积类型Convolution这两篇博客中,主要讲解了卷积神经网络的核心层,同时也结合当下流行的Caffe和tf框架做了介绍,本篇博客将接着tenso ...
- MinkowskiPooling池化(下)
MinkowskiPooling池化(下) MinkowskiPoolingTranspose class MinkowskiEngine.MinkowskiPoolingTranspose(kern ...
- MinkowskiPooling池化(上)
MinkowskiPooling池化(上) 如果内核大小等于跨步大小(例如kernel_size = [2,1],跨步= [2,1]),则引擎将更快地生成与池化函数相对应的输入输出映射. 如果使用U网 ...
- cuSPARSELt开发NVIDIA Ampere结构化稀疏性
cuSPARSELt开发NVIDIA Ampere结构化稀疏性 深度神经网络在各种领域(例如计算机视觉,语音识别和自然语言处理)中均具有出色的性能.处理这些神经网络所需的计算能力正在迅速提高,因此有效 ...
- DL基础补全计划(六)---卷积和池化
PS:要转载请注明出处,本人版权所有. PS: 这个只是基于<我自己>的理解, 如果和你的原则及想法相冲突,请谅解,勿喷. 前置说明 本文作为本人csdn blog的主站的备份.(Bl ...
- 高可用的池化 Thrift Client 实现(源码分享)
本文将分享一个高可用的池化 Thrift Client 及其源码实现,欢迎阅读源码(Github)并使用,同时欢迎提出宝贵的意见和建议,本人将持续完善. 本文的主要目标读者是对 Thrift 有一定了 ...
- 【GPU编解码】GPU硬编码 (转)
一.OpenCV中的硬编码 OpenCV2.4.6中,已实现利用GPU进行写视频,编码过程由cv::gpu::VideoWriter_GPU完成,其示例程序如下. 1 int main(int arg ...
- 测试EntityFramework,Z.EntityFramework.Extensions,原生语句在不同的查询中的表现。原来池化与非池化设定是有巨大的影响的。
Insert测试,只测试1000条的情况,多了在实际的项目中应该就要另行处理了. using System; using System.Collections.Generic; using Syste ...
随机推荐
- ByteArrayInputStream和ByteArrayOutputStream不需要关闭流的原理--博客摘录
---------------- 版权声明:本文为CSDN博主「PSUUGDUFNM」的原创文章,遵循CC 4.0 by-sa版权协议,转载请附上原文出处链接及本声明.原文链接:https://blo ...
- java接口自动化需要的技术
1.testNG需要了解的知识 ITestContext这个类可以直接在方法参数里使用,主要作用是可以通过它的context.getSuite()直接获取suite的相关信息.还可以通过它的 cont ...
- 字符流---->字符过滤流 缓冲流 : -----> printWrite用法:和BufferedReader用法
printWrite用法:1.创建字符节点流FileWriter fw = new FileWriter("Files\\bufchar.txt");2创建字符过滤流 PrintW ...
- 如果遇到This QueryDict instance is immutable错误
添加数据的时候,大家遇到"This QueryDict instance is immutable". 唯一的解决方法是request.data.copy()即可成功实现添加功能
- 纯前端实现后端给数据进行文件导出——angular里面的使用
interface dataList { cmd_cnt: number; risk_name: string; user_cnt: number; risk_type:string; } listO ...
- Java swing图形界面计算器
效果图如下所示 : import java.awt.Color; import java.awt.Container; import java.awt.Font; import java.awt.Gr ...
- How to Apply WebLogic Server (WLS) Patches Using Smart Update
本文目的: 描述weblogic10.3.6及之前的版本,如何通过Smart Update打补丁 先决条件: You should download and apply the enhanced Sm ...
- C#处理JSON类型数据序列化和反序列化的一点心得体会
在处理JSON类型的数据时,定义了很多JSON类型.经常需要用到序列化和反序列化.刚开始接触到这个问题时,我给每个JSON类型都增加了类似下方的代码. using System; using Syst ...
- nginx配置权重,ip_hash....
nginx为后端web服务器(apache,nginx,tomcat,weblogic)等做反向代理 几台后端web服务器需要考虑文件共享,数据库共享,session共享问题.文件共享可以使用nfs, ...
- AWS、谷歌云、Azure:云计算安全功能比较
每个云平台提供给客户用以保护其云资产安全工具和安全功能都不一样. 公有云安全建立在共担责任概念基础之上:大型云服务提供商交付安全超大规模环境,但保护推上云端一切是客户自己责任.对企业而言,这种安全责任 ...