2.9:数据交换-csv、Excel、json、爬虫、Tushare获取数据
〇、任务
1、 使用Python基础文件读写函数完成CSV文件的处理;
2、 使用标准CSV库完成CSV文件的处理;
3、 使用Excel库完成Excel文件的处理;
4、 Python数据结构和Json格式的相互转换;
5、 使用第三方封装库直接获取格式化数据;
6、 使用Requests库获取Json格式数据和Html格式数据
一、CSV和Excel数据交换
1、读取CSV文件

注意:csvdemo.csv文件中内容如下:
id,name,age
1,Diego,12
2,Eugene,30
3,Sunny,24
结果输出:[ ['1', 'Diego', '12'], ['2', 'Eugene', '30'], ['3', 'Sunny', '24']]。通过调用strip方法,为每行去掉尾部的回车换行。通过split方法,按逗号切割成一个列表,然后存放在一个嵌套列表中。访问的时候,可以使用ls[1:]获取不包括表头的数据。
2、生成CSV文件

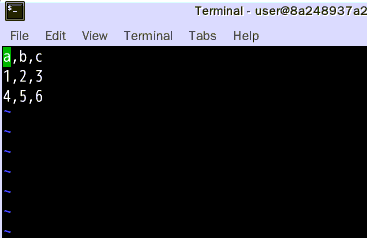
3、使用CSV库读取CSV文件
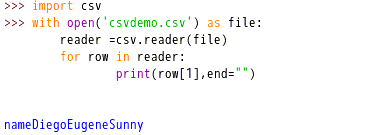
结果输出:nameDiegoEugeneSunny。通过csv的包装器reader,把文件对象包装为一个reader对象,这个对象为可迭代对象,因此可以直接用for in语句来获取其中的各行数据,并按索引获取每行中的对应元素。最后通过end=””,把print语句默认的回车换行换掉,从而让各行输出链接在一行中。
4、使用CSV库写入CSV文件

结果输出:输出一个data.csv文件,内容为四列数据。当然也可以用writer.writerows(data) ,一次写入多行。我们对比上面的例子可以看出,使用python的write时,要求输入str类型而不能直接输入int,而csv库则方便多了,也不需要处理逗号和每行的回车换行符。
5、从CSV文件读取数据并转换为字典类型
import csv
data=[]
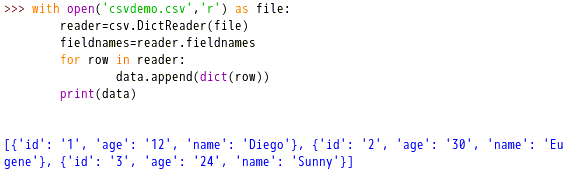
结果输出:[{'id': '1', 'name': 'Diego', 'age': '12'}, {'id': '2', 'name': 'Eugene', 'age': '30'}, {'id': '3', 'name': 'Sunny', 'age': '24'}]。csv库中还有一个DictReader,这个包装器可以直接给用户提供fieldname,获取csv的表头;每行数据通过dict()方法强制转换之后,可以直接输出字典类型的数据(默认row是OrderedDict)。用户就不需要手工拼接成字典类型的对象了,提高了处理速度。
6、从CSV中提取特定行数据
import csv
data=[]
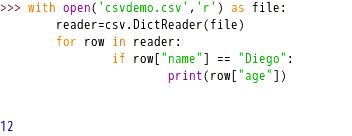
结果输出:12。通过if语句,来找到数据中符合姓名是“Diego”的记录,然后获取其年龄信息。
7、读取Excel文件


结果输出:a,b,c1.0,2.0,3.04.0,5.0,6.0
导入读取Excel库:import xlrd; 打开文件:data = xlrd.open_workbook('excel.xls’)
获取工作表有3种方法:分别是:如table = data.sheets()[0] ,通过索引顺序获取;如table = data.sheet_by_index(0) ,通过索引顺序获取;如table = data.sheet_by_name(u'Sheet1’) ,通过名称获取。获取行列数据使用 table.row_values(i)或table.col_values(i);获取行数和列数,使用table.nrows和table.ncols;获取单元格:使用able.cell(2,3).value。
8、写入Excel文件


结果输出:为一个info.xls的文件。
顺序是:加载模块:import xlwt,创建workbook:workbook = xlwt.Workbook(encoding = “utf-8”),创建表:worksheet = workbook.add_sheet('My Worksheet’);在单元格写入数据:worksheet.write(0, 0,’53.6’);保存数据:workbook.save('Excel_Workbook.xls’)。一般处理数据时不建议直接操作excel,可以通过pandas的excel读取写入函数进行处理。
二、Json数据交换
1、将Python数据结构转换为Json串
import json
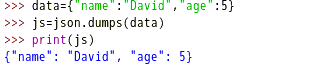
结果输出:'{"name": "David", "age": 5}'。注意,输出是一个字符串。在Python中,可以通过单引号和双引号交叉的方式表达字符串中的字符串。这里,最外层是单引号,内层是双引号。最后的输出结果是一个Json格式的字符串。方法dumps()的作用就是把一个对象(字典对象或列表对象、元组对象等)转换为Json格式的字符串。如s=json.dumps(list("hello"))的输出结果是:'["h", "e", "l", "l", "o"]'。可以直观的理解为dumps方法把对象加上引号,和eval()相反。s=json.dumps(56+36)的结果是字符串“92”。
2、将Json串转换为Python数据结构


结果输出:{'employees': [{'firstName': 'Bill', 'lastName': 'Gates'}, {'firstName': 'George', 'lastName': 'Bush'}, {'firstName': 'Thomas', 'lastName': 'Carter'}]}。这个输出是一个标准的Python字典结构,最外层是大括号,不是引号。字典的第一个key是“Employees”,它的值是一个列表list,里面有3个嵌套字典。每个字典里有两个keys:firstName和lastName,分别有对应的值。
3、读取Json格式文件


结果输出:George。json库的load方法直接将一个json格式的文件直接转换为python字典对象。然后可以按照字典的方式进行访问。如通过data["employees"]返回对应的value值,是一个列表,然后通过索引访问列表的第二个元素,还是一个字典。获取该字典元素的“firstName”键值对应的value值。
4、写入Json格式文件


结果输出:当前目录下生成一个json文件,内容为:{"name": "David", "age": 5}。dump方法通过两个参数完成数据的写入,第一个是要写入的字典格式(或其他格式的对象),第二个参数为要写入的文件对象(已经打开)。
三、Web数据交换
1、使用Tushare获取数据

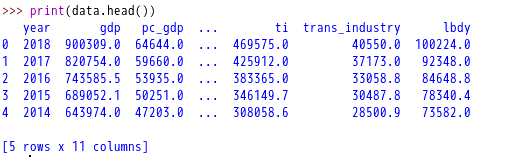
结果输出:当前目录下输出一个tsout.csv文件,里面包含了得到的所有数据,同时屏幕打印出前5行数据。tushare 是一个提供免费的财经数据三方库。通过良好的封装,它提供了方便快捷的接入方式。可以通过导入之后,通过dir函数查看这个库所支持的查询功能。通过type函数,可以查看data的类型是:<class 'pandas.core.frame.DataFrame'>,是一个pandas的DataFrame类型。这个类型对象提供了很多中保持数据的方法,如to_csv,to_excel等等,用户可以根据需要自由选择。
2、去百词斩查单词

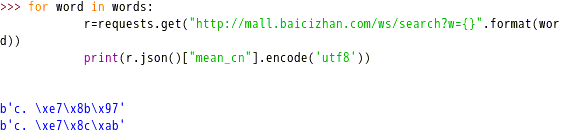
结果输出:b’c. \xe7\x8b\x97’b’c. \xe7\x8c\xab’
Requests库是一个优秀的第三方网络爬虫库。Requests库的json()方法可以直接生成一个字典,而text方法返回的是一个字符串。通过json方法返回的字典,可以直接访问其对应键值获取对应的value值。
3、爬取普通静态页面数据


结果输出:<title>The Dormouse’s story</title> titleThe Dormouse’s storyheadBS4 库是一个解析和处理HTML 和XML 的第三方库。它的作用是能够快速方便简单的提取网页中指定的内容,给我一个网页字符串,然后使用它的接口将网页字符串生成一个对象,然后通过这个对象的方法来提取数据。本次使用模拟的网页来提取数据。
2.9:数据交换-csv、Excel、json、爬虫、Tushare获取数据的更多相关文章
- python#读csv,excel,json数据
#读csv,excel,json数据 with open('E:\\test\\xdd.csv','r') as f: for line in f.readlines(): print(line) i ...
- MySQL数据导出为Excel, json,sql等格式
MySQL数据经常要导出为Excel, json,sql等格式,通过步骤都很多,麻烦,现在通过Treesoft可以方便的导出你要的数据格式. 1.在线执行SQL,在数据列表中有相应按钮,方便的将数据导 ...
- 数据交换格式之 - Json
Json简介: JSON是JavaScript对象表示法,是一种与语言无关的数据交换的格式,是一种完全独立于语言的文本格式. 使用ajax进行前后台数据交换,移动端与服务端的数据交换. web客户端和 ...
- Python使用Scrapy框架爬取数据存入CSV文件(Python爬虫实战4)
1. Scrapy框架 Scrapy是python下实现爬虫功能的框架,能够将数据解析.数据处理.数据存储合为一体功能的爬虫框架. 2. Scrapy安装 1. 安装依赖包 yum install g ...
- 第三章——供机器读取的数据(CSV与JSON)
本书使用的文件.代码:https://github.com/huangtao36/data_wrangling 机器可读(machine readable)文件格式: 1.逗号分隔值(Comma-Se ...
- [数据科学] 从text, json文件中提取数据
文本文件是基本的文件类型,不管是csv, xls, json, 还是xml等等都可以按照文本文件的形式读取. #-*- coding: utf-8 -*- fpath = "data/tex ...
- 轻量级的数据交换语言(JSON)
游戏开发过程中,很多用到JSON的地方:客户端与服务端的网络通信,程序读取客户端的数值表之类的. JSON用于描述数据结构,有以下形式存在. 对象(object):一个对象以“{”开始,并以“}”结束 ...
- Qt编写数据导出到Excel及Pdf和打印数据
一.前言 用Qt开发已经九年了,期间用Qt做过不少的项目,在各种项目中有个功能很常用,尤其是涉及到数据记录存储的项目,那就是需要对查询的数据进行导出到Excel,或者导出到Pdf文件,或者直接打印查询 ...
- c#导出数据到csv文本文档中,数据前面的0不见了解决方法
((char)(9)).ToString() + dataRow["FUserName"].ToString().Trim() + "\t",
- [转]jquery getJSON 数据联动(采用序列化和反序列化获取数据) .
<html xmlns="http://www.w3.org/1999/xhtml"><head runat="server"> ...
随机推荐
- Kibana:在Kibana中对数据进行深入分析
- 采用阿里云 yum的方式安装ceph
首先机器需要联网,并且配置网络yum源,epel源,可从阿里开源镜像站中下载源文件. 注:EPEL (Extra Packages for Enterprise Linux)是基于Fedora的一个项 ...
- centos yum安装docker
cd /etc/yum.repos.d/ mv CentOS-Base.repo CentOS-Base.repo_bak wget -O /etc/yum.repos.d/CentOS-Base.r ...
- 企业使用erp系统的好处及解决了什么问题?
不是所有的企业使用ERP都能带来好处的,尤其是对于一些小微企业,带来的可能是灾难,而实施不适用的系统同样也会带来意想不到的后果,所以在ERP的使用方面得根据自己企业实际做决定.不同规模的企业选用不同的 ...
- (数据科学学习手札144)使用管道操作符高效书写Python代码
本文示例代码已上传至我的Github仓库https://github.com/CNFeffery/DataScienceStudyNotes 1 简介 大家好我是费老师,一些比较熟悉pandas的读者 ...
- java:找不到符号
出现这种情况的原因之一:实体类的字段修改过.实体类中的变量名修改.然而其他地方调用的字段名还是修改之前的变量.
- sql面试50题------(1-10)
文章目录 1.查询课程编号'01'比课程编号'02'成绩高的所有学生学号 2.查询平均成绩大于60分得学生的学号和平均成绩 3.查询所有学生的学号,姓名,选课数,总成绩 4.查询姓"猴&qu ...
- 二进制安装Dokcer
写在前边 考虑到很多生产环境是内网,不允许外网访问的.恰好我司正是这种场景,写一篇二进制方式安装Docker的教程,用来帮助实施同事解决容器部署的第一个难关. 本文将以二进制安装方式,在CentOS7 ...
- 14.api根路由
我们可以通过使用超链接来提高我们APi的内聚力和可发现性 一.为我们的API创建一个根路径 我们的视图有很多个url,但是没有一个入口点,可以使用@api_view创建一个根路径 #views.p ...
- C# 8.0 添加和增强的功能【基础篇】
.NET Core 3.x和.NET Standard 2.1支持C# 8.0. 一.Readonly 成员 可将 readonly 修饰符应用于结构的成员,来限制成员为不可修改状态.这比在C# 7. ...