WOE和IV
woe全称是“Weight of Evidence”,即证据权重,是对原始自变量的一种编码形式。
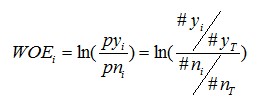
进行WOE编码前,需要先把这个变量进行分组处理(离散化)
其中,pyi是这个组中响应客户(即模型中预测变量取值为“是”或1的个体,也叫坏样本)占所有样本中所有响应客户的比例,pni是这个组中未响应客户(也叫好样本)占样本中所有未响应客户的比例;
#yi是这个组中响应客户的数量,#ni是这个组中未响应客户的数量,#yT是样本中所有响应客户的数量,#nT是样本中所有未响应客户的数量。
从这个公式中我们可以体会到,WOE表示的实际上是“当前分组中响应客户占所有响应客户的比例”和“当前分组中没有响应的客户占所有没有响应的客户的比例”的差异。
为了更简单明了一点,我们来做个简单变换,得:
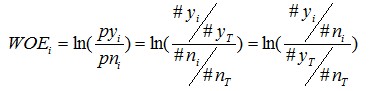
不难看出,woe表示的是当前这个组中响应客户和未响应客户的比值,和所有样本中这个比值的差异。这个差异是用这两个比值的比值,再取对数来表示的。例子如下:
| Age | #bad | #good | Woe |
|---|---|---|---|
| 0-10 | 50 | 200 | =ln((50/100)/(200/1000))=ln((50/200)/(100/1000)) |
| 10-18 | 20 | 200 | =ln((20/100)/(200/1000))=ln((20/200)/(100/1000)) |
| 18-35 | 5 | 200 | =ln((5/100)/(200/1000))=ln((5/200)/(100/1000)) |
| 35-50 | 15 | 200 | =ln((15/100)/(200/1000))=ln((15/200)/(100/1000)) |
| 50以上 | 10 | 200 | =ln((10/100)/(200/1000))=ln((10/200)/(100/1000)) |
| 汇总 | 100 | 1000 |
WOE越大,这种差异越大,这个分组里的样本响应的可能性就越大,WOE越小,差异越小,这个分组里的样本响应的可能性就越小。woe反映的是在自变量每个分组下违约用户对正常用户占比和总体中违约用户对正常用户占比之间的差异;从而可以直观的认为woe蕴含了自变量取值对于目标变量(违约概率)的影响。再加上woe计算形式与logistic回归中目标变量的logistic转换(logist_p=ln(p/1-p))如此相似,因而可以将自变量woe值替代原先的自变量值。
那woe编码有什么意义呢?
很明显,它可以提升模型的预测效果,提高模型的可理解性。
标准化的功能。
WOE编码之后,自变量其实具备了某种标准化的性质,也就是说,自变量内部的各个取值之间都可以直接进行比较(WOE之间的比较)
异常值处理。
一些极值变量,可以通过分组的WOE,变为非异常值
- 检查变量WOE后与违约概率的关系
一般筛选的变量WOE与违约概率都是单调的,如果出现U型,或者其他曲线形状,则需要重新看下变量是否有问题。
核查WOE变量模型的变量系数出现负值。
如果最终模型的出来的系数出现负值,需要考虑是否出现了多重共线性的影响,或者变量计算逻辑问题。
woe的意义,大家可以再体会一下。下面附上一段woe自编Code:
## 证据权重函数
def total_response(data,label):
value_count = data[label].value_counts()
return value_count
def woe(data,feature,label,label_value):
'''
data:传入需要做woe的特征和标签两列数据
feature:特征名
label:标签名
label_value:接收字典,key为1,0,表示为响应和未响应,value为对应的值
'''
import pandas as pd
import numpy as np
idx = pd.IndexSlice # 创建一个对象以更轻松地执行多索引切片
data['woe'] = 1
groups = data.groupby([label,feature]).count().sort_index()
## 使用上述函数
value_counts = total_response(data,label)
resp_col = label_value[1]
not_resp_col = label_value[0]
resp = groups.loc[idx[resp_col,:]]/value_counts[resp_col]
not_resp = groups.loc[idx[not_resp_col,:]]/value_counts[not_resp_col]
Woe = np.log(resp/not_resp).fillna(0)
return Woe
既然讲到这了,就再讲讲IV吧。
公式如下:

有了一个变量各分组的IV值,我们就可以计算整个变量的IV值,方法很简单,就是把各分组的IV相加:

其中,n为变量分组个数。
WOE和IV的更多相关文章
- 评分卡模型剖析之一(woe、IV、ROC、信息熵)
信用评分卡模型在国外是一种成熟的预测方法,尤其在信用风险评估以及金融风险控制领域更是得到了比较广泛的使用,其原理是将模型变量WOE编码方式离散化之后运用logistic回归模型进行的一种二分类变量的广 ...
- 数据分箱:等频分箱,等距分箱,卡方分箱,计算WOE、IV
转载:https://zhuanlan.zhihu.com/p/38440477 转载:https://blog.csdn.net/starzhou/article/details/78930490 ...
- 信息熵、信息增益、信息增益率、gini、woe、iv、VIF
整理一下这几个量的计算公式,便于记忆 采用信息增益率可以解决ID3算法中存在的问题,因此将采用信息增益率作为判定划分属性好坏的方法称为C4.5.需要注意的是,增益率准则对属性取值较少的时候会有偏好,为 ...
- 【风控算法】一、变量分箱、WOE和IV值计算
一.变量分箱 变量分箱常见于逻辑回归评分卡的制作中,在入模前,需要对原始变量值通过分箱映射成woe值.举例来说,如"年龄"这一变量,我们需要找到合适的切分点,将连续的年龄打散到不同 ...
- 特征重要度 WoE、IV、BadRate
1.IV的用途 IV的全称是Information Value,中文意思是信息价值,或者信息量. 我们在用逻辑回归.决策树等模型方法构建分类模型时,经常需要对自变量进行筛选.比如我们有200个候选自变 ...
- 转载:数据挖掘模型中的IV和WOE详解
1.IV的用途 IV的全称是Information Value,中文意思是信息价值,或者信息量. 我们在用逻辑回归.决策树等模型方法构建分类模型时,经常需要对自变量进行筛选.比如我们有200个候选自变 ...
- 评分卡模型中的IV和WOE详解
1.IV的用途 IV的全称是Information Value,中文意思是信息价值,或者信息量. 我们在用逻辑回归.决策树等模型方法构建分类模型时,经常需要对自变量进行筛选.比如我们有200个候选 ...
- 数据挖掘模型中的IV和WOE详解
IV: 某个特征中 某个小分组的 响应比例与未响应比例之差 乘以 响应比例与未响应比例的比值取对数 数据挖掘模型中的IV和WOE详解 http://blog.csdn.net/kevin7658/ar ...
- 特征工程中的IV和WOE详解
1.IV的用途 IV的全称是Information Value,中文意思是信息价值,或者信息量. 我们在用逻辑回归.决策树等模型方法构建分类模型时,经常需要对自变量进行筛选.比如我们有200个候选自变 ...
随机推荐
- translate和position的比较
有很多css属性可以影响元素定位,比如float,margin,padding,position,translate().表面上来看,position:relatative和transform:tra ...
- 一口一口吃掉Hexo(五)
如果你想得到更好的阅读效果,请访问我的个人网站 ,版权所有,未经许可不得转载! 通过前四节的内容,相信你已经能够在你的虚拟主机上成功部署网站,并且能够通过你自己的域名访问你的网站了,接下来要做的就是日 ...
- C语言使用hiredis访问redis
Hiredis 是Redis数据库的简约C客户端库.它是简约的,因为它只是增加了对协议的最小支持,但是同时它使用了一个高级别的 printf-like API,所以对于习惯了 printf 风格的C编 ...
- mysql 解决 timestamp 的2038问题
当 timestamp 存储的时间大于 '2038-01-19 03:14:07' UTC,mysql就会报错,因为这是 mysql自身的问题,也就是说 timestamp是有上限的,超过了,自然会报 ...
- js设计模式总结1
js设计模式有很多种,知道不代表会用,更不代表理解,为了更好的理解每个设计模式,对每个设计模式进行总结,以后只要看到总结,就能知道该设计模式的作用,以及模式存在的优缺点,使用范围. 本文主要参考张容铭 ...
- [转][MVC4]ASP.NET MVC4+EF5(Lambda/Linq)读取数据
本文转自:https://blog.csdn.net/dingxiaowei2013/article/details/29405687 继续上一节初始ASP.NET MVC4,继续深入学习,感受了一下 ...
- 乐字节-Java8新特性-Lambda表达式
上一篇文章我们了解了Java8新特性-接口默认方法,接下来我们聊一聊Java8新特性之Lambda表达式. Lambda表达式(也称为闭包),它允许我们将函数当成参数传递给某个方法,或者把代码本身当作 ...
- ThreadLocal的用法
阿里巴巴 java 开发手册中推荐的 ThreadLocal 的用法: public class DateUtil { public static final ThreadLocal<DateF ...
- Java - List总结
Java提高篇(三二)-----List总结 前面LZ已经充分介绍了有关于List接口的大部分知识,如ArrayList.LinkedList.Vector.Stack,通过这几个知识点可以对List ...
- visual studio 2013 下ef6 CodeFirst 使用SQL Lite 数据库
今天系统的来记录一下再vs2013下,使用ef6 codefirst功能,来操作SQL lite数据库 本来我以为sqlite数据库用的这么多,ef6肯定支持,结果,使用过程中很多坑,现在我把具体的配 ...