PowerExchange实时抽取架构介绍
工作原理
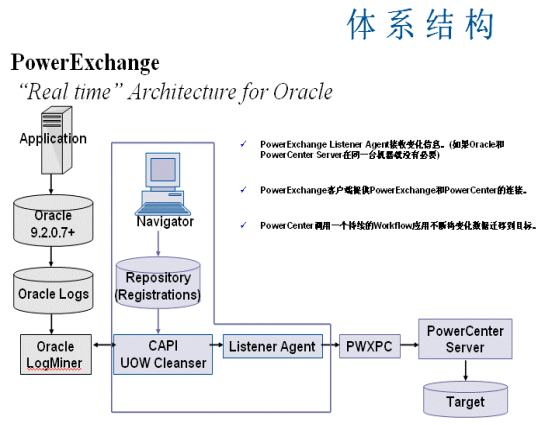
准实时抽取架构图:

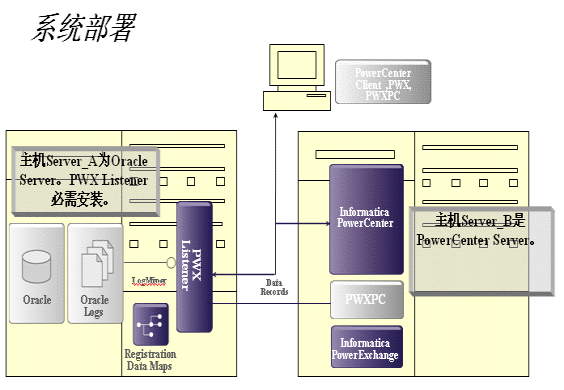
以上共有核心业务系统数据库服务器、ETL服务器、BI数据库服务器〔目标数据库服务器〕,三台服务器和ETL客户端(PowerCenter客户端)。其中核心业务系统上有核心系统产生的Redo Log、安装Oracle Logminer、安装PowerExchange,ETL服务器上安装PowerCenter及PowerExhchange的客户端、BI数据库服务器为目标数据库、ETL客户端安装(PowerCenter客户端)。
核心业务系统数据库服务器在进行业务过程中,会一直写Redo Log;Logminer为Oracle日志分析工具,能够对Redo Log及Achive Log进行解析;PowerExhchange为Oracle Logminer和ETL工具PowerCenter的接口,实现对Logminer的封装,通过他来定义要获取哪些表的增量及增量数据放到哪张对应的增量表中〔增量表结构是自己定义〕。
ETL客户端主要用来定义数据的抽取、转换、加载规则,比如:定义要抽取哪些表的增量、抽取的频率、要将增量数据插入到那个数据库〔可以是任何数据库服务器上的表〕。在获取增量后如何处理这些增量(转换)等。
ETL服务器执行客户端定义好的ETL规则。在执行过程中,通过PowerExchange接口实时抽取核心业务系统产生的增量,并根据规则转换处理或不进行转换插入到BI数据库服务器上相应的目标表中。
具体执行流程是,PowerExchange和Logminer以类似服务的形式,在核心业务系统上执行,当ETL服务器启动抽取时,通过PowerExhchange接口调用在核心业务系统上的PowerExchange,PowerExhchange再调用Logminer,Logminer对核心业务系统产生的Redo Log进行解析。解析完成后将数据返回给PowerExhchange,PowerExhchange将数据返回给ETL服务器,ETL服务器根据ETL客户端指定的规则(经过加工处理或不经过加工处理)处理后将增量数据加工到BI数据库服务器相关的表中。
详细介绍


在Oracle服务器端的详细操作如下:
1、 执行以下脚本
说明:如果数据库已经是归档模式则不需要创建和指定归档日志存放路径。
必须创建针对PowerExchange使用的Oracle用户并赋予指定权限,主要是为了对Logminer解析出数据后,存放数据的视图进行操作。
设置Oracle Supplemental Logging,默认情况下。Oracle记录日志,是没有数据表中的字段数据内容,设置Supplemental Logging完成或。Redo log会记录发生变化的每条记录的前像内容和后像内容。只有这样,才能获取到变化记录内容。
创建Logminer 表空间,Logminer在进行数据解析后。会将解析的结果数据保存到,几个视图中。也就是说需要将数据暂存到数据表空间中。
编译Logminer系统包。
将Oracle Catalog复制到redo logs
Logminer根据对数据字典的使用分为三种模式〔数据字典是将redo log中的对象代码转换成具体表名等对象名的映射文件〕,user online Catalog、Extracting a LogMiner Dictionary to the Redo Log Files、Extracting the LogMiner Dictionary to a Flat File。
PowerExchange在调用Logminer时,使用Extracting the LogMiner Dictionary to a Flat File这种模式。这种模式不需生成数据字典文件,即将数据字典内容写入到redo log中,因此没有额外的对数据库的操作。
2、 在Oracle服务器端安装PowerExchange
PowerExchange主要是实现对Oracle Logminer进行封装的工具,Logminer实现了对数据库日志的解析,但是要达到实时获取增量数据的目的需要涉及以下方面的问题
(1) 如何实时进行解析
Oracle Logminer进行日志解析,需要调用Logminer的命令。每次命令可以解析整个redo log内容,也可以按照时间进行解析。但是,需要手工执行命令。PowerExchange利用自身的触发机制,对logminer进行自动的调用,实现准实时增量数据的获取
(2) 解析出的内容的处理
Logminer在解析出变化数据后,会存放到相关视图中。视图存放所有变化数据表的数据,在应用时,必须对视图进行查询,然后将数据转移到相关的数据表中。操作麻烦,需要变成处理。Logminer提供图形化操作页面,通过Navigator进行对解析数据的定义及处理。
(3) 稳定性及效率问题及和ETL工具的结合
直接调用Logminer会涉及到频率、稳定、效率等诸多考虑因素,PowerExchange做为产品这些问题都有具体的处理。同时PowerExchange做为Informatica的一个组建,非常方便的整合到ETL调度体系中。
PowerExchange在oracle服务器端,做为一个服务贮存,监控数据的产生。通过ETL工具将实时抽取配置成一个Informatica Powercenter的WorkFlow。PowerExchange获取到数据后,自动运行此WorkFlow将获取到的数据抽取到定义好的目标表中。
PowerExchange实时抽取架构介绍的更多相关文章
- 1.8-1.10 大数据仓库的数据收集架构及监控日志目录日志数据,实时抽取之hdfs系统上
一.数据仓库架构 二.flume收集数据存储到hdfs 文档:http://flume.apache.org/releases/content/1.9.0/FlumeUserGuide.html#hd ...
- 利用Flume将MySQL表数据准实时抽取到HDFS
转自:http://blog.csdn.net/wzy0623/article/details/73650053 一.为什么要用到Flume 在以前搭建HAWQ数据仓库实验环境时,我使用Sqoop抽取 ...
- 大型网站技术架构介绍--squid
一.大型网站技术架构介绍 1.pv高 ip高 并发量 2.大型网站架构重点 1. 高性能:响应时间,TPS,系统性能计数器.缓存,消息队列等. 高可用性High Availabilit ...
- 基于Storm 分布式BP神经网络,将神经网络做成实时分布式架构
将神经网络做成实时分布式架构: Storm 分布式BP神经网络: http://bbs.csdn.net/topics/390717623 流式大数据处理的三种框架:Storm,Spark和Sa ...
- Kafka设计解析(一)Kafka背景及架构介绍
转载自 技术世界,原文链接 Kafka设计解析(一)- Kafka背景及架构介绍 本文介绍了Kafka的创建背景,设计目标,使用消息系统的优势以及目前流行的消息系统对比.并介绍了Kafka的架构,Pr ...
- Kafka剖析:Kafka背景及架构介绍
<Kafka剖析:Kafka背景及架构介绍> <Kafka设计解析:Kafka High Availability(上)> <Kafka设计解析:Kafka High A ...
- MySQL高级第一章——架构介绍
一.简介 是一个经典的RDBMS,目前归属于Oracle 高级MySQL包含的内容: MySQL内核 SQL优化工程师 MySQL服务器的优化 各种参数常量设定 查询语句优化 主从复制 软硬件升级 容 ...
- 环信ONE SDK架构介绍
环信ONE SDK架构介绍 摘要 环信即时通讯SDK自2014年6月正式公布2.0版本号至今已走过一个年头.从主要的单聊功能,到群聊功能,再到聊天室的实现.SDK无论是功能.稳定性,还是易集成性都在一 ...
- Flume系列一之架构介绍和安装
Flume架构介绍和安装 写在前面 在学习一门新的技术之前,我们得知道了解这个东西有什么用?我们可以使用它来做些什么呢?简单来说,flume是大数据日志分析中不能缺少的一个组件,既可以使用在流处理中, ...
随机推荐
- day44
今日内容: 1.前端概述 2.前端三剑客 3.页面基本结构 4.常用标签 5.标签分类 1.前端概述与前端三剑客 前端即⽹站前台部分,运⾏在PC端,移动端等浏览器上展现给⽤户浏览的⽹⻚.随着互联⽹技术 ...
- VS 代码段
系统默认代码段 代码段名 描 述 #if 该代码段用#if和#endif命令围绕代码 #region 该代码段用#region和#endregion命令围绕代码 ~ 该代码段插入一个析构函数 a ...
- vi 替换
在vi编辑器中,能够利用 :s命令能够实现字符串的替换.详细的使用方法例如以下: 1.:s/str1/str2/ 用字符串 str2 替换行中首次出现的字符串str1: 2.:s/str1/str2/ ...
- HBase启动报错:ERROR: org.apache.hadoop.hbase.ipc.ServerNotRunningYetException: Server is not running yet
今天进入hbase shell中输入命令报错:ERROR: org.apache.hadoop.hbase.ipc.ServerNotRunningYetException: Server is no ...
- 基于代的垃圾回收机制--《CLR via C#》读书笔记
我们知道,垃圾回收在内存无限大的理想情况下是不需要的,正是因为内存存在的瓶颈,我们才需要垃圾回收.在<垃圾回收算法之引用计数算法>和<垃圾回收算法之引用跟踪算法>两篇文章中,我 ...
- Android开发——RecyclerView特性以及基本使用方法(二)
0. 前言 随着Android的发展,虽然ListView依旧重要,但RecyclerView确实越来越多的被大家使用.但显然并不能说RecyclerView就一定优于ListView,而是应该根据 ...
- MySQL优化:explain using temporary
什么时候会使用临时表:group/order没设计好的时候 1.order没用索引 2.order用了索引, 但不是和where相同的索引 3.order用了两个索引, 但不是联合索引 4.order ...
- 汇编 switch case
知识点: switch case生成的汇编框架 逆向汇编代码还原成C++代码 一.了解switch case结构 .普通情况 |. 83C4 ADD ESP, |. C745 FC >MOV ...
- maven mvn package 打包项目时,出现错误导致失败的解决方法
解决思路:看报错时在maven打包过程中的哪一步,然后看报错内容,解决报错内容即可,如果是实在不好解决的部分,看看能不能设置不检测,能打包出来就行. 这里是因为mybatis逆向工程插件出现异常所以中 ...
- Macaca 基础原理浅析
导语 前面几篇文章介绍了在Macaca实践中的一些实用技巧与解决方案,今天简单分析一下Macaca的基础原理.这篇文章将以前面所分享的UI自动化Macaca-Java版实践心得中的demo为基础,进行 ...