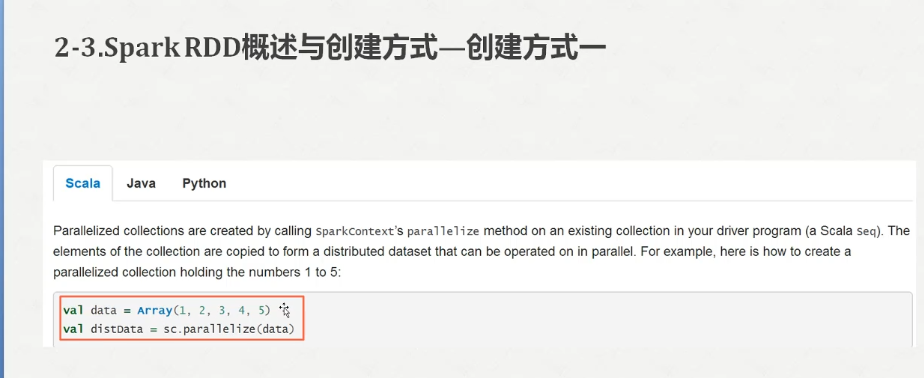
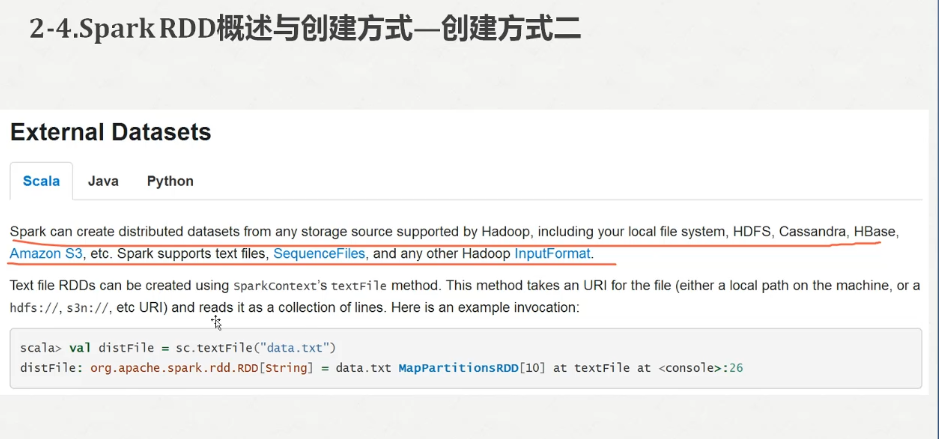
Spark2.X分布式弹性数据集



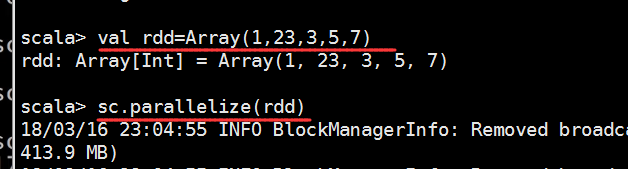
跑一下这个结果
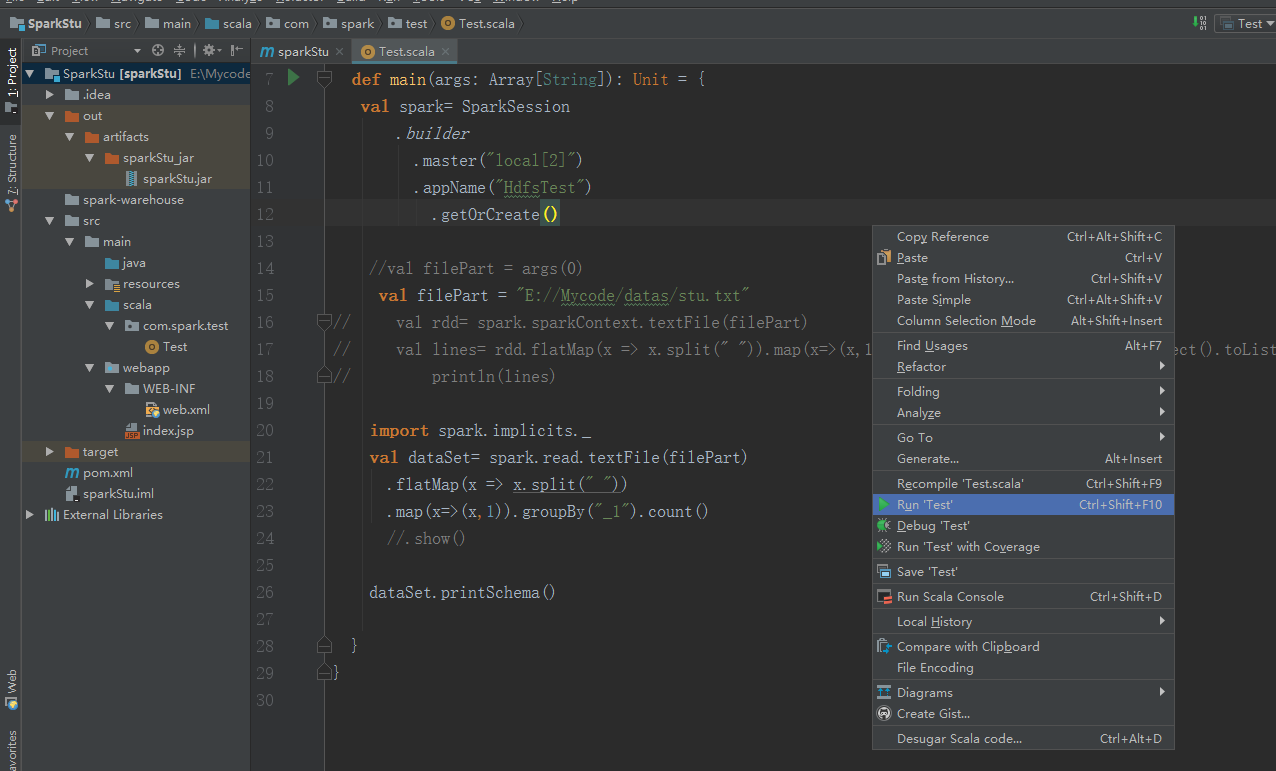
参考代码
package com.spark.test import org.apache.spark.sql.SparkSession
import org.apache.spark.{SparkConf, SparkContext}
object Test { def main(args: Array[String]): Unit = {
val spark= SparkSession
.builder
.master("local[2]")
.appName("HdfsTest")
.getOrCreate() //val filePart = args(0)
val filePart = "E://Mycode/datas/stu.txt"
// val rdd= spark.sparkContext.textFile(filePart)
// val lines= rdd.flatMap(x => x.split(" ")).map(x=>(x,1)).reduceByKey((a,b)=>(a+b)).collect().toList
// println(lines) import spark.implicits._
val dataSet= spark.read.textFile(filePart)
.flatMap(x => x.split(" "))
.map(x=>(x,)).groupBy("_1").count()
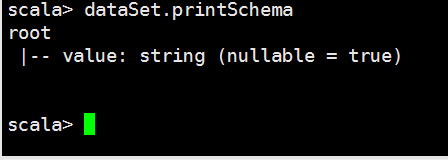
//.show() dataSet.printSchema() }
}
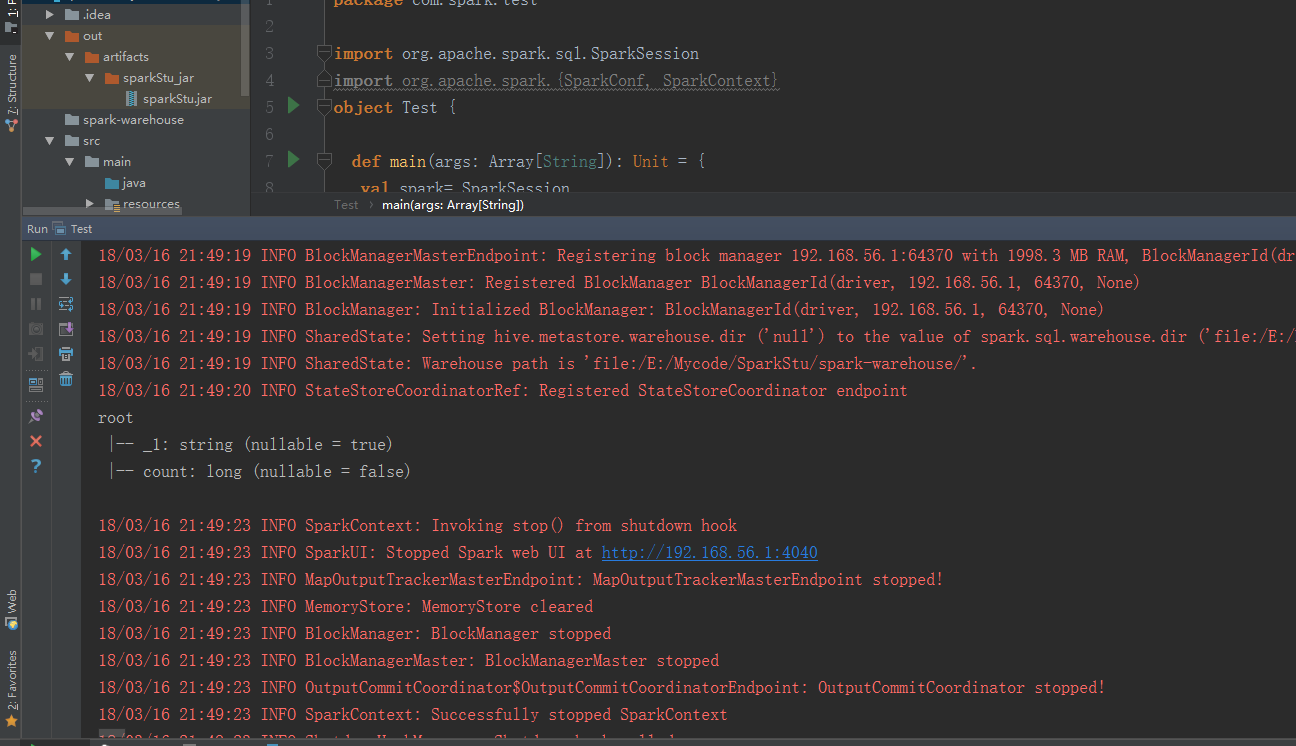
运行结果
E:\software\jdk1.\bin\java "-javaagent:E:\software\IDEA\IntelliJ IDEA 2017.2.6\lib\idea_rt.jar=64316:E:\software\IDEA\IntelliJ IDEA 2017.2.6\bin" -Dfile.encoding=UTF- -classpath E:\software\jdk1.\jre\lib\charsets.jar;E:\software\jdk1.\jre\lib\deploy.jar;E:\software\jdk1.\jre\lib\ext\access-bridge-.jar;E:\software\jdk1.\jre\lib\ext\cldrdata.jar;E:\software\jdk1.\jre\lib\ext\dnsns.jar;E:\software\jdk1.\jre\lib\ext\jaccess.jar;E:\software\jdk1.\jre\lib\ext\jfxrt.jar;E:\software\jdk1.\jre\lib\ext\localedata.jar;E:\software\jdk1.\jre\lib\ext\nashorn.jar;E:\software\jdk1.\jre\lib\ext\sunec.jar;E:\software\jdk1.\jre\lib\ext\sunjce_provider.jar;E:\software\jdk1.\jre\lib\ext\sunmscapi.jar;E:\software\jdk1.\jre\lib\ext\sunpkcs11.jar;E:\software\jdk1.\jre\lib\ext\zipfs.jar;E:\software\jdk1.\jre\lib\javaws.jar;E:\software\jdk1.\jre\lib\jce.jar;E:\software\jdk1.\jre\lib\jfr.jar;E:\software\jdk1.\jre\lib\jfxswt.jar;E:\software\jdk1.\jre\lib\jsse.jar;E:\software\jdk1.\jre\lib\management-agent.jar;E:\software\jdk1.\jre\lib\plugin.jar;E:\software\jdk1.\jre\lib\resources.jar;E:\software\jdk1.\jre\lib\rt.jar;E:\Mycode\SparkStu\target\classes;E:\software\Scala\lib\scala-actors-2.11..jar;E:\software\Scala\lib\scala-actors-migration_2.-1.1..jar;E:\software\Scala\lib\scala-library.jar;E:\software\Scala\lib\scala-parser-combinators_2.-1.0..jar;E:\software\Scala\lib\scala-reflect.jar;E:\software\Scala\lib\scala-swing_2.-1.0..jar;E:\software\Scala\lib\scala-xml_2.-1.0..jar;E:\software\maven3.3.9\repository\org\apache\spark\spark-core_2.\2.2.\spark-core_2.-2.2..jar;E:\software\maven3.3.9\repository\org\apache\avro\avro\1.7.\avro-1.7..jar;E:\software\maven3.3.9\repository\org\codehaus\jackson\jackson-core-asl\1.9.\jackson-core-asl-1.9..jar;E:\software\maven3.3.9\repository\com\thoughtworks\paranamer\paranamer\2.3\paranamer-2.3.jar;E:\software\maven3.3.9\repository\org\apache\commons\commons-compress\1.4.\commons-compress-1.4..jar;E:\software\maven3.3.9\repository\org\tukaani\xz\1.0\xz-1.0.jar;E:\software\maven3.3.9\repository\org\apache\avro\avro-mapred\1.7.\avro-mapred-1.7.-hadoop2.jar;E:\software\maven3.3.9\repository\org\apache\avro\avro-ipc\1.7.\avro-ipc-1.7..jar;E:\software\maven3.3.9\repository\org\apache\avro\avro-ipc\1.7.\avro-ipc-1.7.-tests.jar;E:\software\maven3.3.9\repository\com\twitter\chill_2.\0.8.\chill_2.-0.8..jar;E:\software\maven3.3.9\repository\com\esotericsoftware\kryo-shaded\3.0.\kryo-shaded-3.0..jar;E:\software\maven3.3.9\repository\com\esotericsoftware\minlog\1.3.\minlog-1.3..jar;E:\software\maven3.3.9\repository\org\objenesis\objenesis\2.1\objenesis-2.1.jar;E:\software\maven3.3.9\repository\com\twitter\chill-java\0.8.\chill-java-0.8..jar;E:\software\maven3.3.9\repository\org\apache\xbean\xbean-asm5-shaded\4.4\xbean-asm5-shaded-4.4.jar;E:\software\maven3.3.9\repository\org\apache\spark\spark-launcher_2.\2.2.\spark-launcher_2.-2.2..jar;E:\software\maven3.3.9\repository\org\apache\spark\spark-network-common_2.\2.2.\spark-network-common_2.-2.2..jar;E:\software\maven3.3.9\repository\org\fusesource\leveldbjni\leveldbjni-all\1.8\leveldbjni-all-1.8.jar;E:\software\maven3.3.9\repository\com\fasterxml\jackson\core\jackson-annotations\2.6.\jackson-annotations-2.6..jar;E:\software\maven3.3.9\repository\org\apache\spark\spark-network-shuffle_2.\2.2.\spark-network-shuffle_2.-2.2..jar;E:\software\maven3.3.9\repository\org\apache\spark\spark-unsafe_2.\2.2.\spark-unsafe_2.-2.2..jar;E:\software\maven3.3.9\repository\net\java\dev\jets3t\jets3t\0.9.\jets3t-0.9..jar;E:\software\maven3.3.9\repository\org\apache\httpcomponents\httpcore\4.3.\httpcore-4.3..jar;E:\software\maven3.3.9\repository\javax\activation\activation\1.1.\activation-1.1..jar;E:\software\maven3.3.9\repository\mx4j\mx4j\3.0.\mx4j-3.0..jar;E:\software\maven3.3.9\repository\javax\mail\mail\1.4.\mail-1.4..jar;E:\software\maven3.3.9\repository\org\bouncycastle\bcprov-jdk15on\1.51\bcprov-jdk15on-1.51.jar;E:\software\maven3.3.9\repository\com\jamesmurty\utils\java-xmlbuilder\1.0\java-xmlbuilder-1.0.jar;E:\software\maven3.3.9\repository\net\iharder\base64\2.3.\base64-2.3..jar;E:\software\maven3.3.9\repository\org\apache\curator\curator-recipes\2.6.\curator-recipes-2.6..jar;E:\software\maven3.3.9\repository\org\apache\curator\curator-framework\2.6.\curator-framework-2.6..jar;E:\software\maven3.3.9\repository\org\apache\zookeeper\zookeeper\3.4.\zookeeper-3.4..jar;E:\software\maven3.3.9\repository\com\google\guava\guava\16.0.\guava-16.0..jar;E:\software\maven3.3.9\repository\javax\servlet\javax.servlet-api\3.1.\javax.servlet-api-3.1..jar;E:\software\maven3.3.9\repository\org\apache\commons\commons-lang3\3.5\commons-lang3-3.5.jar;E:\software\maven3.3.9\repository\org\apache\commons\commons-math3\3.4.\commons-math3-3.4..jar;E:\software\maven3.3.9\repository\com\google\code\findbugs\jsr305\1.3.\jsr305-1.3..jar;E:\software\maven3.3.9\repository\org\slf4j\slf4j-api\1.7.\slf4j-api-1.7..jar;E:\software\maven3.3.9\repository\org\slf4j\jul-to-slf4j\1.7.\jul-to-slf4j-1.7..jar;E:\software\maven3.3.9\repository\org\slf4j\jcl-over-slf4j\1.7.\jcl-over-slf4j-1.7..jar;E:\software\maven3.3.9\repository\log4j\log4j\1.2.\log4j-1.2..jar;E:\software\maven3.3.9\repository\org\slf4j\slf4j-log4j12\1.7.\slf4j-log4j12-1.7..jar;E:\software\maven3.3.9\repository\com\ning\compress-lzf\1.0.\compress-lzf-1.0..jar;E:\software\maven3.3.9\repository\org\xerial\snappy\snappy-java\1.1.2.6\snappy-java-1.1.2.6.jar;E:\software\maven3.3.9\repository\net\jpountz\lz4\lz4\1.3.\lz4-1.3..jar;E:\software\maven3.3.9\repository\org\roaringbitmap\RoaringBitmap\0.5.\RoaringBitmap-0.5..jar;E:\software\maven3.3.9\repository\commons-net\commons-net\2.2\commons-net-2.2.jar;E:\software\maven3.3.9\repository\org\scala-lang\scala-library\2.11.\scala-library-2.11..jar;E:\software\maven3.3.9\repository\org\json4s\json4s-jackson_2.\3.2.\json4s-jackson_2.-3.2..jar;E:\software\maven3.3.9\repository\org\json4s\json4s-core_2.\3.2.\json4s-core_2.-3.2..jar;E:\software\maven3.3.9\repository\org\json4s\json4s-ast_2.\3.2.\json4s-ast_2.-3.2..jar;E:\software\maven3.3.9\repository\org\scala-lang\scalap\2.11.\scalap-2.11..jar;E:\software\maven3.3.9\repository\org\scala-lang\scala-compiler\2.11.\scala-compiler-2.11..jar;E:\software\maven3.3.9\repository\org\scala-lang\modules\scala-xml_2.\1.0.\scala-xml_2.-1.0..jar;E:\software\maven3.3.9\repository\org\glassfish\jersey\core\jersey-client\2.22.\jersey-client-2.22..jar;E:\software\maven3.3.9\repository\javax\ws\rs\javax.ws.rs-api\2.0.\javax.ws.rs-api-2.0..jar;E:\software\maven3.3.9\repository\org\glassfish\hk2\hk2-api\2.4.-b34\hk2-api-2.4.-b34.jar;E:\software\maven3.3.9\repository\org\glassfish\hk2\hk2-utils\2.4.-b34\hk2-utils-2.4.-b34.jar;E:\software\maven3.3.9\repository\org\glassfish\hk2\external\aopalliance-repackaged\2.4.-b34\aopalliance-repackaged-2.4.-b34.jar;E:\software\maven3.3.9\repository\org\glassfish\hk2\external\javax.inject\2.4.-b34\javax.inject-2.4.-b34.jar;E:\software\maven3.3.9\repository\org\glassfish\hk2\hk2-locator\2.4.-b34\hk2-locator-2.4.-b34.jar;E:\software\maven3.3.9\repository\org\javassist\javassist\3.18.-GA\javassist-3.18.-GA.jar;E:\software\maven3.3.9\repository\org\glassfish\jersey\core\jersey-common\2.22.\jersey-common-2.22..jar;E:\software\maven3.3.9\repository\javax\annotation\javax.annotation-api\1.2\javax.annotation-api-1.2.jar;E:\software\maven3.3.9\repository\org\glassfish\jersey\bundles\repackaged\jersey-guava\2.22.\jersey-guava-2.22..jar;E:\software\maven3.3.9\repository\org\glassfish\hk2\osgi-resource-locator\1.0.\osgi-resource-locator-1.0..jar;E:\software\maven3.3.9\repository\org\glassfish\jersey\core\jersey-server\2.22.\jersey-server-2.22..jar;E:\software\maven3.3.9\repository\org\glassfish\jersey\media\jersey-media-jaxb\2.22.\jersey-media-jaxb-2.22..jar;E:\software\maven3.3.9\repository\javax\validation\validation-api\1.1..Final\validation-api-1.1..Final.jar;E:\software\maven3.3.9\repository\org\glassfish\jersey\containers\jersey-container-servlet\2.22.\jersey-container-servlet-2.22..jar;E:\software\maven3.3.9\repository\org\glassfish\jersey\containers\jersey-container-servlet-core\2.22.\jersey-container-servlet-core-2.22..jar;E:\software\maven3.3.9\repository\io\netty\netty-all\4.0..Final\netty-all-4.0..Final.jar;E:\software\maven3.3.9\repository\io\netty\netty\3.9..Final\netty-3.9..Final.jar;E:\software\maven3.3.9\repository\com\clearspring\analytics\stream\2.7.\stream-2.7..jar;E:\software\maven3.3.9\repository\io\dropwizard\metrics\metrics-core\3.1.\metrics-core-3.1..jar;E:\software\maven3.3.9\repository\io\dropwizard\metrics\metrics-jvm\3.1.\metrics-jvm-3.1..jar;E:\software\maven3.3.9\repository\io\dropwizard\metrics\metrics-json\3.1.\metrics-json-3.1..jar;E:\software\maven3.3.9\repository\io\dropwizard\metrics\metrics-graphite\3.1.\metrics-graphite-3.1..jar;E:\software\maven3.3.9\repository\com\fasterxml\jackson\core\jackson-databind\2.6.\jackson-databind-2.6..jar;E:\software\maven3.3.9\repository\com\fasterxml\jackson\core\jackson-core\2.6.\jackson-core-2.6..jar;E:\software\maven3.3.9\repository\com\fasterxml\jackson\module\jackson-module-scala_2.\2.6.\jackson-module-scala_2.-2.6..jar;E:\software\maven3.3.9\repository\org\scala-lang\scala-reflect\2.11.\scala-reflect-2.11..jar;E:\software\maven3.3.9\repository\com\fasterxml\jackson\module\jackson-module-paranamer\2.6.\jackson-module-paranamer-2.6..jar;E:\software\maven3.3.9\repository\org\apache\ivy\ivy\2.4.\ivy-2.4..jar;E:\software\maven3.3.9\repository\oro\oro\2.0.\oro-2.0..jar;E:\software\maven3.3.9\repository\net\razorvine\pyrolite\4.13\pyrolite-4.13.jar;E:\software\maven3.3.9\repository\net\sf\py4j\py4j\0.10.\py4j-0.10..jar;E:\software\maven3.3.9\repository\org\apache\spark\spark-tags_2.\2.2.\spark-tags_2.-2.2..jar;E:\software\maven3.3.9\repository\org\apache\commons\commons-crypto\1.0.\commons-crypto-1.0..jar;E:\software\maven3.3.9\repository\org\spark-project\spark\unused\1.0.\unused-1.0..jar;E:\software\maven3.3.9\repository\org\apache\spark\spark-sql_2.\2.2.\spark-sql_2.-2.2..jar;E:\software\maven3.3.9\repository\com\univocity\univocity-parsers\2.2.\univocity-parsers-2.2..jar;E:\software\maven3.3.9\repository\org\apache\spark\spark-sketch_2.\2.2.\spark-sketch_2.-2.2..jar;E:\software\maven3.3.9\repository\org\apache\spark\spark-catalyst_2.\2.2.\spark-catalyst_2.-2.2..jar;E:\software\maven3.3.9\repository\org\codehaus\janino\janino\3.0.\janino-3.0..jar;E:\software\maven3.3.9\repository\org\codehaus\janino\commons-compiler\3.0.\commons-compiler-3.0..jar;E:\software\maven3.3.9\repository\org\antlr\antlr4-runtime\4.5.\antlr4-runtime-4.5..jar;E:\software\maven3.3.9\repository\org\apache\parquet\parquet-column\1.8.\parquet-column-1.8..jar;E:\software\maven3.3.9\repository\org\apache\parquet\parquet-common\1.8.\parquet-common-1.8..jar;E:\software\maven3.3.9\repository\org\apache\parquet\parquet-encoding\1.8.\parquet-encoding-1.8..jar;E:\software\maven3.3.9\repository\org\apache\parquet\parquet-hadoop\1.8.\parquet-hadoop-1.8..jar;E:\software\maven3.3.9\repository\org\apache\parquet\parquet-format\2.3.\parquet-format-2.3..jar;E:\software\maven3.3.9\repository\org\apache\parquet\parquet-jackson\1.8.\parquet-jackson-1.8..jar;E:\software\maven3.3.9\repository\org\apache\spark\spark-streaming_2.\2.2.\spark-streaming_2.-2.2..jar;E:\software\maven3.3.9\repository\org\apache\spark\spark-hive_2.\2.2.\spark-hive_2.-2.2..jar;E:\software\maven3.3.9\repository\com\twitter\parquet-hadoop-bundle\1.6.\parquet-hadoop-bundle-1.6..jar;E:\software\maven3.3.9\repository\org\spark-project\hive\hive-exec\1.2..spark2\hive-exec-1.2..spark2.jar;E:\software\maven3.3.9\repository\commons-io\commons-io\2.4\commons-io-2.4.jar;E:\software\maven3.3.9\repository\commons-lang\commons-lang\2.6\commons-lang-2.6.jar;E:\software\maven3.3.9\repository\javolution\javolution\5.5.\javolution-5.5..jar;E:\software\maven3.3.9\repository\log4j\apache-log4j-extras\1.2.\apache-log4j-extras-1.2..jar;E:\software\maven3.3.9\repository\org\antlr\antlr-runtime\3.4\antlr-runtime-3.4.jar;E:\software\maven3.3.9\repository\org\antlr\stringtemplate\3.2.\stringtemplate-3.2..jar;E:\software\maven3.3.9\repository\antlr\antlr\2.7.\antlr-2.7..jar;E:\software\maven3.3.9\repository\org\antlr\ST4\4.0.\ST4-4.0..jar;E:\software\maven3.3.9\repository\com\googlecode\javaewah\JavaEWAH\0.3.\JavaEWAH-0.3..jar;E:\software\maven3.3.9\repository\org\iq80\snappy\snappy\0.2\snappy-0.2.jar;E:\software\maven3.3.9\repository\stax\stax-api\1.0.\stax-api-1.0..jar;E:\software\maven3.3.9\repository\net\sf\opencsv\opencsv\2.3\opencsv-2.3.jar;E:\software\maven3.3.9\repository\org\spark-project\hive\hive-metastore\1.2..spark2\hive-metastore-1.2..spark2.jar;E:\software\maven3.3.9\repository\com\jolbox\bonecp\0.8..RELEASE\bonecp-0.8..RELEASE.jar;E:\software\maven3.3.9\repository\commons-cli\commons-cli\1.2\commons-cli-1.2.jar;E:\software\maven3.3.9\repository\commons-logging\commons-logging\1.1.\commons-logging-1.1..jar;E:\software\maven3.3.9\repository\org\apache\derby\derby\10.10.2.0\derby-10.10.2.0.jar;E:\software\maven3.3.9\repository\org\datanucleus\datanucleus-api-jdo\3.2.\datanucleus-api-jdo-3.2..jar;E:\software\maven3.3.9\repository\org\datanucleus\datanucleus-rdbms\3.2.\datanucleus-rdbms-3.2..jar;E:\software\maven3.3.9\repository\commons-pool\commons-pool\1.5.\commons-pool-1.5..jar;E:\software\maven3.3.9\repository\commons-dbcp\commons-dbcp\1.4\commons-dbcp-1.4.jar;E:\software\maven3.3.9\repository\javax\jdo\jdo-api\3.0.\jdo-api-3.0..jar;E:\software\maven3.3.9\repository\javax\transaction\jta\1.1\jta-1.1.jar;E:\software\maven3.3.9\repository\commons-httpclient\commons-httpclient\3.1\commons-httpclient-3.1.jar;E:\software\maven3.3.9\repository\org\apache\calcite\calcite-avatica\1.2.-incubating\calcite-avatica-1.2.-incubating.jar;E:\software\maven3.3.9\repository\org\apache\calcite\calcite-core\1.2.-incubating\calcite-core-1.2.-incubating.jar;E:\software\maven3.3.9\repository\org\apache\calcite\calcite-linq4j\1.2.-incubating\calcite-linq4j-1.2.-incubating.jar;E:\software\maven3.3.9\repository\net\hydromatic\eigenbase-properties\1.1.\eigenbase-properties-1.1..jar;E:\software\maven3.3.9\repository\org\apache\httpcomponents\httpclient\4.5.\httpclient-4.5..jar;E:\software\maven3.3.9\repository\org\codehaus\jackson\jackson-mapper-asl\1.9.\jackson-mapper-asl-1.9..jar;E:\software\maven3.3.9\repository\commons-codec\commons-codec\1.10\commons-codec-1.10.jar;E:\software\maven3.3.9\repository\joda-time\joda-time\2.9.\joda-time-2.9..jar;E:\software\maven3.3.9\repository\org\jodd\jodd-core\3.5.\jodd-core-3.5..jar;E:\software\maven3.3.9\repository\org\datanucleus\datanucleus-core\3.2.\datanucleus-core-3.2..jar;E:\software\maven3.3.9\repository\org\apache\thrift\libthrift\0.9.\libthrift-0.9..jar;E:\software\maven3.3.9\repository\org\apache\thrift\libfb303\0.9.\libfb303-0.9..jar;E:\software\maven3.3.9\repository\org\apache\spark\spark-streaming-kafka--10_2.\2.2.\spark-streaming-kafka--10_2.-2.2..jar;E:\software\maven3.3.9\repository\org\apache\kafka\kafka_2.\0.10.0.1\kafka_2.-0.10.0.1.jar;E:\software\maven3.3.9\repository\com\101tec\zkclient\0.8\zkclient-0.8.jar;E:\software\maven3.3.9\repository\com\yammer\metrics\metrics-core\2.2.\metrics-core-2.2..jar;E:\software\maven3.3.9\repository\org\scala-lang\modules\scala-parser-combinators_2.\1.0.\scala-parser-combinators_2.-1.0..jar;E:\software\maven3.3.9\repository\org\apache\spark\spark-sql-kafka--10_2.\2.2.\spark-sql-kafka--10_2.-2.2..jar;E:\software\maven3.3.9\repository\org\apache\kafka\kafka-clients\0.10.0.1\kafka-clients-0.10.0.1.jar;E:\software\maven3.3.9\repository\org\apache\hadoop\hadoop-client\2.6.\hadoop-client-2.6..jar;E:\software\maven3.3.9\repository\org\apache\hadoop\hadoop-common\2.6.\hadoop-common-2.6..jar;E:\software\maven3.3.9\repository\xmlenc\xmlenc\0.52\xmlenc-0.52.jar;E:\software\maven3.3.9\repository\commons-collections\commons-collections\3.2.\commons-collections-3.2..jar;E:\software\maven3.3.9\repository\commons-configuration\commons-configuration\1.6\commons-configuration-1.6.jar;E:\software\maven3.3.9\repository\commons-digester\commons-digester\1.8\commons-digester-1.8.jar;E:\software\maven3.3.9\repository\commons-beanutils\commons-beanutils\1.7.\commons-beanutils-1.7..jar;E:\software\maven3.3.9\repository\commons-beanutils\commons-beanutils-core\1.8.\commons-beanutils-core-1.8..jar;E:\software\maven3.3.9\repository\com\google\protobuf\protobuf-java\2.5.\protobuf-java-2.5..jar;E:\software\maven3.3.9\repository\com\google\code\gson\gson\2.2.\gson-2.2..jar;E:\software\maven3.3.9\repository\org\apache\hadoop\hadoop-auth\2.6.\hadoop-auth-2.6..jar;E:\software\maven3.3.9\repository\org\apache\directory\server\apacheds-kerberos-codec\2.0.-M15\apacheds-kerberos-codec-2.0.-M15.jar;E:\software\maven3.3.9\repository\org\apache\directory\server\apacheds-i18n\2.0.-M15\apacheds-i18n-2.0.-M15.jar;E:\software\maven3.3.9\repository\org\apache\directory\api\api-asn1-api\1.0.-M20\api-asn1-api-1.0.-M20.jar;E:\software\maven3.3.9\repository\org\apache\directory\api\api-util\1.0.-M20\api-util-1.0.-M20.jar;E:\software\maven3.3.9\repository\org\apache\curator\curator-client\2.6.\curator-client-2.6..jar;E:\software\maven3.3.9\repository\org\htrace\htrace-core\3.0.\htrace-core-3.0..jar;E:\software\maven3.3.9\repository\org\apache\hadoop\hadoop-hdfs\2.6.\hadoop-hdfs-2.6..jar;E:\software\maven3.3.9\repository\org\mortbay\jetty\jetty-util\6.1.\jetty-util-6.1..jar;E:\software\maven3.3.9\repository\xerces\xercesImpl\2.9.\xercesImpl-2.9..jar;E:\software\maven3.3.9\repository\xml-apis\xml-apis\1.3.\xml-apis-1.3..jar;E:\software\maven3.3.9\repository\org\apache\hadoop\hadoop-mapreduce-client-app\2.6.\hadoop-mapreduce-client-app-2.6..jar;E:\software\maven3.3.9\repository\org\apache\hadoop\hadoop-mapreduce-client-common\2.6.\hadoop-mapreduce-client-common-2.6..jar;E:\software\maven3.3.9\repository\org\apache\hadoop\hadoop-yarn-client\2.6.\hadoop-yarn-client-2.6..jar;E:\software\maven3.3.9\repository\org\apache\hadoop\hadoop-yarn-server-common\2.6.\hadoop-yarn-server-common-2.6..jar;E:\software\maven3.3.9\repository\org\apache\hadoop\hadoop-mapreduce-client-shuffle\2.6.\hadoop-mapreduce-client-shuffle-2.6..jar;E:\software\maven3.3.9\repository\org\apache\hadoop\hadoop-yarn-api\2.6.\hadoop-yarn-api-2.6..jar;E:\software\maven3.3.9\repository\org\apache\hadoop\hadoop-mapreduce-client-core\2.6.\hadoop-mapreduce-client-core-2.6..jar;E:\software\maven3.3.9\repository\org\apache\hadoop\hadoop-yarn-common\2.6.\hadoop-yarn-common-2.6..jar;E:\software\maven3.3.9\repository\javax\xml\bind\jaxb-api\2.2.\jaxb-api-2.2..jar;E:\software\maven3.3.9\repository\javax\xml\stream\stax-api\1.0-\stax-api-1.0-.jar;E:\software\maven3.3.9\repository\javax\servlet\servlet-api\2.5\servlet-api-2.5.jar;E:\software\maven3.3.9\repository\com\sun\jersey\jersey-core\1.9\jersey-core-1.9.jar;E:\software\maven3.3.9\repository\com\sun\jersey\jersey-client\1.9\jersey-client-1.9.jar;E:\software\maven3.3.9\repository\org\codehaus\jackson\jackson-jaxrs\1.9.\jackson-jaxrs-1.9..jar;E:\software\maven3.3.9\repository\org\codehaus\jackson\jackson-xc\1.9.\jackson-xc-1.9..jar;E:\software\maven3.3.9\repository\org\apache\hadoop\hadoop-mapreduce-client-jobclient\2.6.\hadoop-mapreduce-client-jobclient-2.6..jar;E:\software\maven3.3.9\repository\org\apache\hadoop\hadoop-annotations\2.6.\hadoop-annotations-2.6..jar com.spark.test.Test
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
// :: INFO SparkContext: Running Spark version 2.2.
// :: INFO SparkContext: Submitted application: HdfsTest
// :: INFO SecurityManager: Changing view acls to: Brave
// :: INFO SecurityManager: Changing modify acls to: Brave
// :: INFO SecurityManager: Changing view acls groups to:
// :: INFO SecurityManager: Changing modify acls groups to:
// :: INFO SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(Brave); groups with view permissions: Set(); users with modify permissions: Set(Brave); groups with modify permissions: Set()
// :: INFO Utils: Successfully started service 'sparkDriver' on port .
// :: INFO SparkEnv: Registering MapOutputTracker
// :: INFO SparkEnv: Registering BlockManagerMaster
// :: INFO BlockManagerMasterEndpoint: Using org.apache.spark.storage.DefaultTopologyMapper for getting topology information
// :: INFO BlockManagerMasterEndpoint: BlockManagerMasterEndpoint up
// :: INFO DiskBlockManager: Created local directory at C:\Users\Brave\AppData\Local\Temp\blockmgr-8a40eb8b-fed0-42b1-a1a6-f8f4e58d2f9a
// :: INFO MemoryStore: MemoryStore started with capacity 1998.3 MB
// :: INFO SparkEnv: Registering OutputCommitCoordinator
// :: INFO Utils: Successfully started service 'SparkUI' on port .
// :: INFO SparkUI: Bound SparkUI to 0.0.0.0, and started at http://192.168.56.1:4040
// :: INFO Executor: Starting executor ID driver on host localhost
// :: INFO Utils: Successfully started service 'org.apache.spark.network.netty.NettyBlockTransferService' on port .
// :: INFO NettyBlockTransferService: Server created on 192.168.56.1:
// :: INFO BlockManager: Using org.apache.spark.storage.RandomBlockReplicationPolicy for block replication policy
// :: INFO BlockManagerMaster: Registering BlockManager BlockManagerId(driver, 192.168.56.1, , None)
// :: INFO BlockManagerMasterEndpoint: Registering block manager 192.168.56.1: with 1998.3 MB RAM, BlockManagerId(driver, 192.168.56.1, , None)
// :: INFO BlockManagerMaster: Registered BlockManager BlockManagerId(driver, 192.168.56.1, , None)
// :: INFO BlockManager: Initialized BlockManager: BlockManagerId(driver, 192.168.56.1, , None)
// :: INFO SharedState: Setting hive.metastore.warehouse.dir ('null') to the value of spark.sql.warehouse.dir ('file:/E:/Mycode/SparkStu/spark-warehouse/').
// :: INFO SharedState: Warehouse path is 'file:/E:/Mycode/SparkStu/spark-warehouse/'.
// :: INFO StateStoreCoordinatorRef: Registered StateStoreCoordinator endpoint
root
|-- _1: string (nullable = true)
|-- count: long (nullable = false) // :: INFO SparkContext: Invoking stop() from shutdown hook
// :: INFO SparkUI: Stopped Spark web UI at http://192.168.56.1:4040
// :: INFO MapOutputTrackerMasterEndpoint: MapOutputTrackerMasterEndpoint stopped!
// :: INFO MemoryStore: MemoryStore cleared
// :: INFO BlockManager: BlockManager stopped
// :: INFO BlockManagerMaster: BlockManagerMaster stopped
// :: INFO OutputCommitCoordinator$OutputCommitCoordinatorEndpoint: OutputCommitCoordinator stopped!
// :: INFO SparkContext: Successfully stopped SparkContext
// :: INFO ShutdownHookManager: Shutdown hook called
// :: INFO ShutdownHookManager: Deleting directory C:\Users\Brave\AppData\Local\Temp\spark-f360cd01--4aad-a1db-56f167e10d42 Process finished with exit code
改一下这里
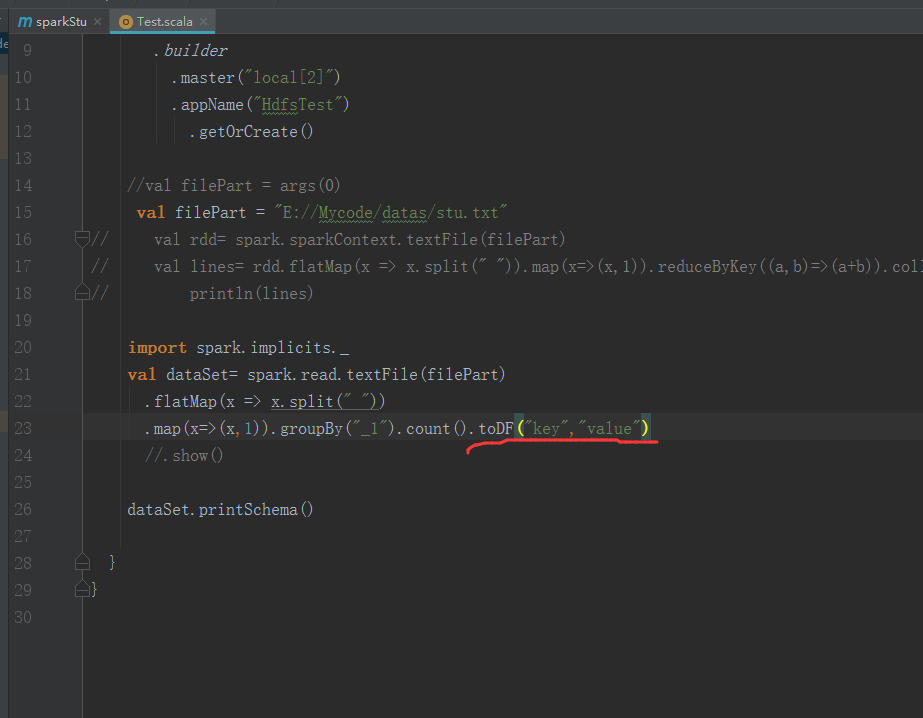
下面是运行结果
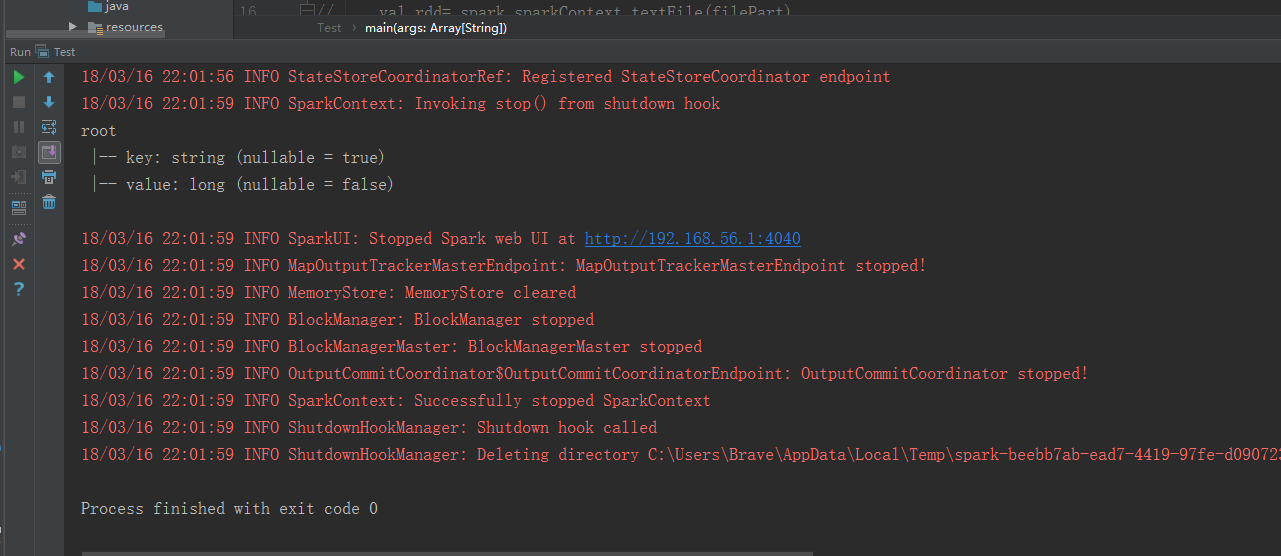


打开这个地址
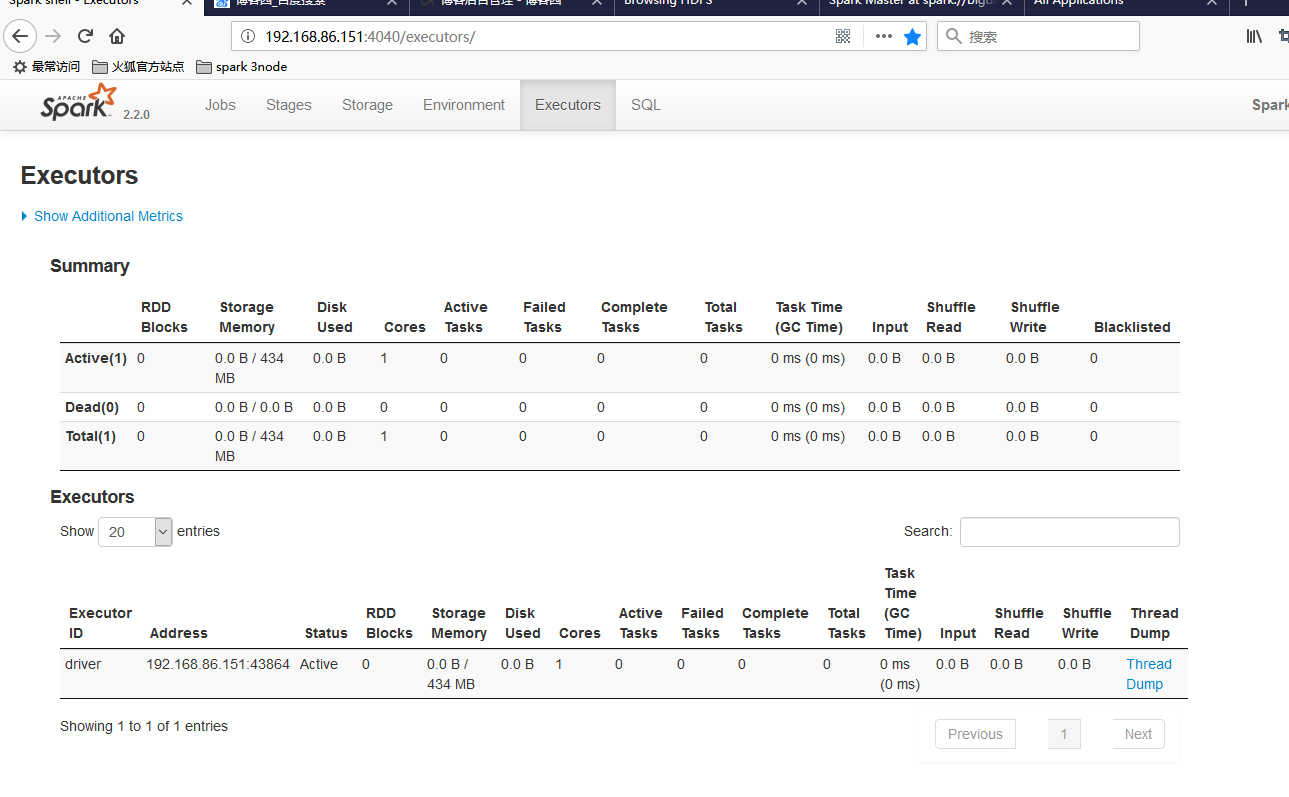
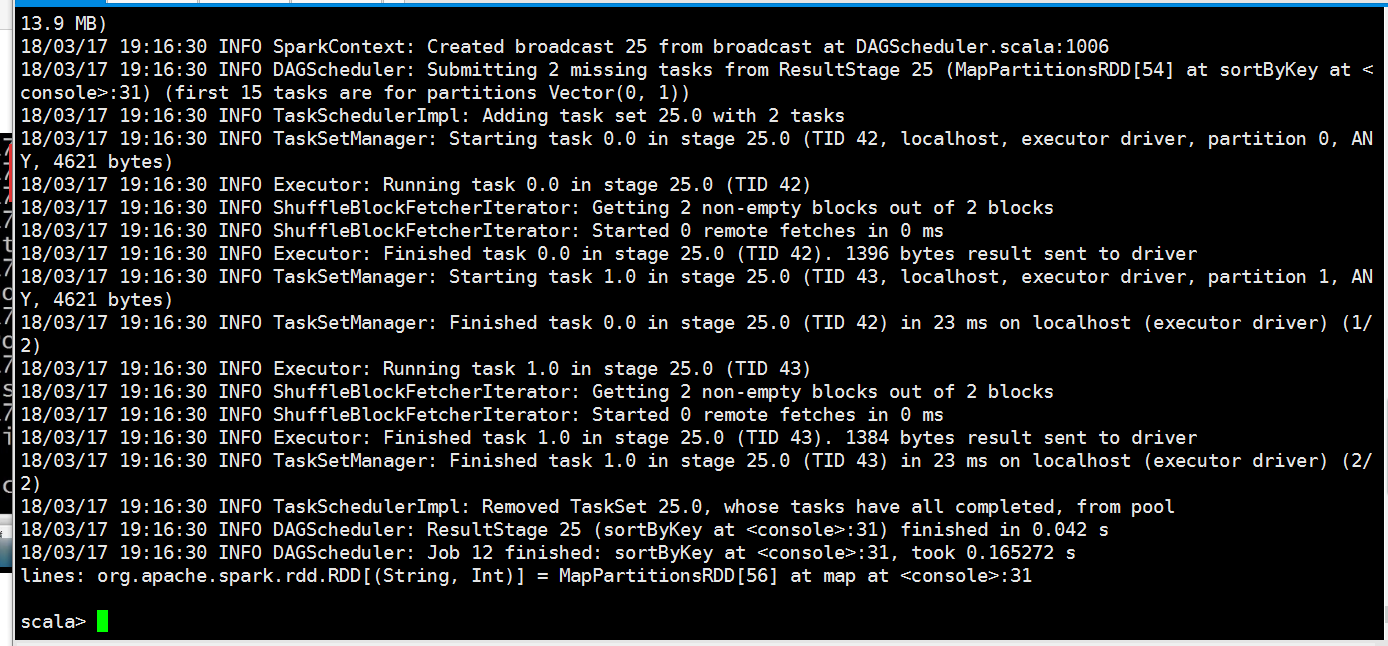
我们来产生一个job


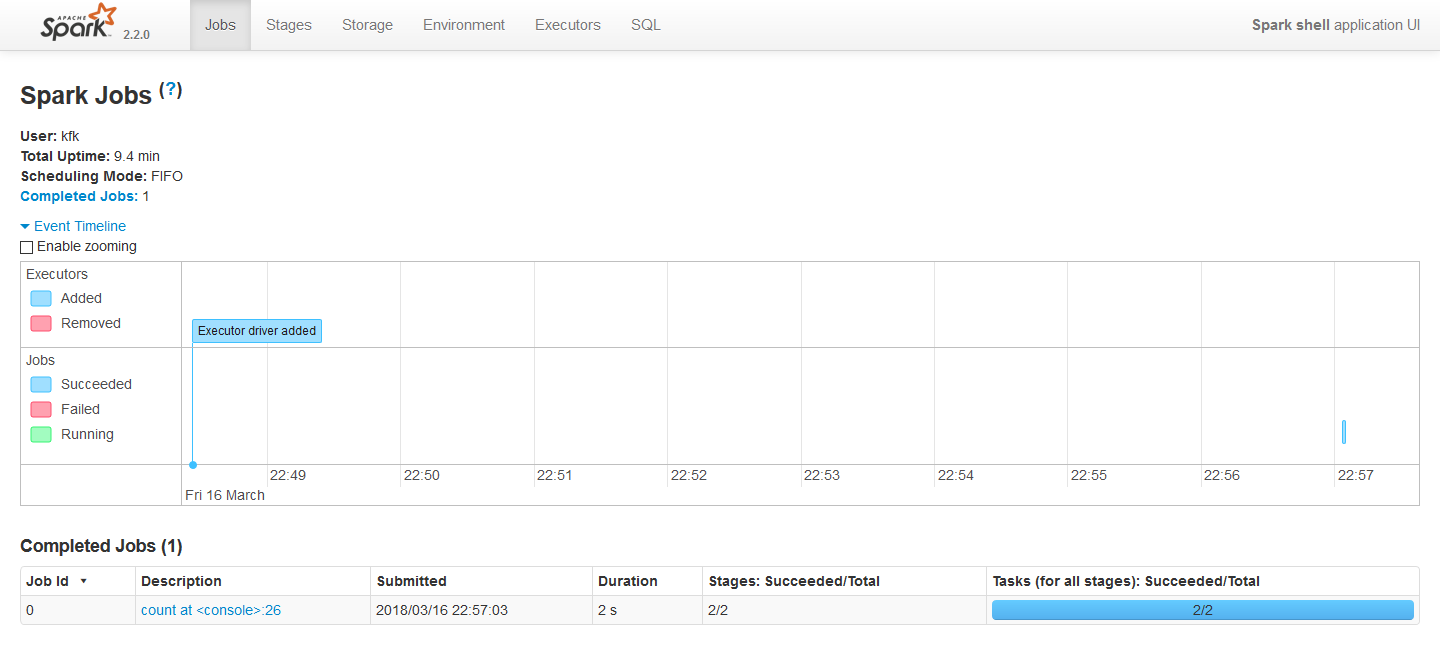

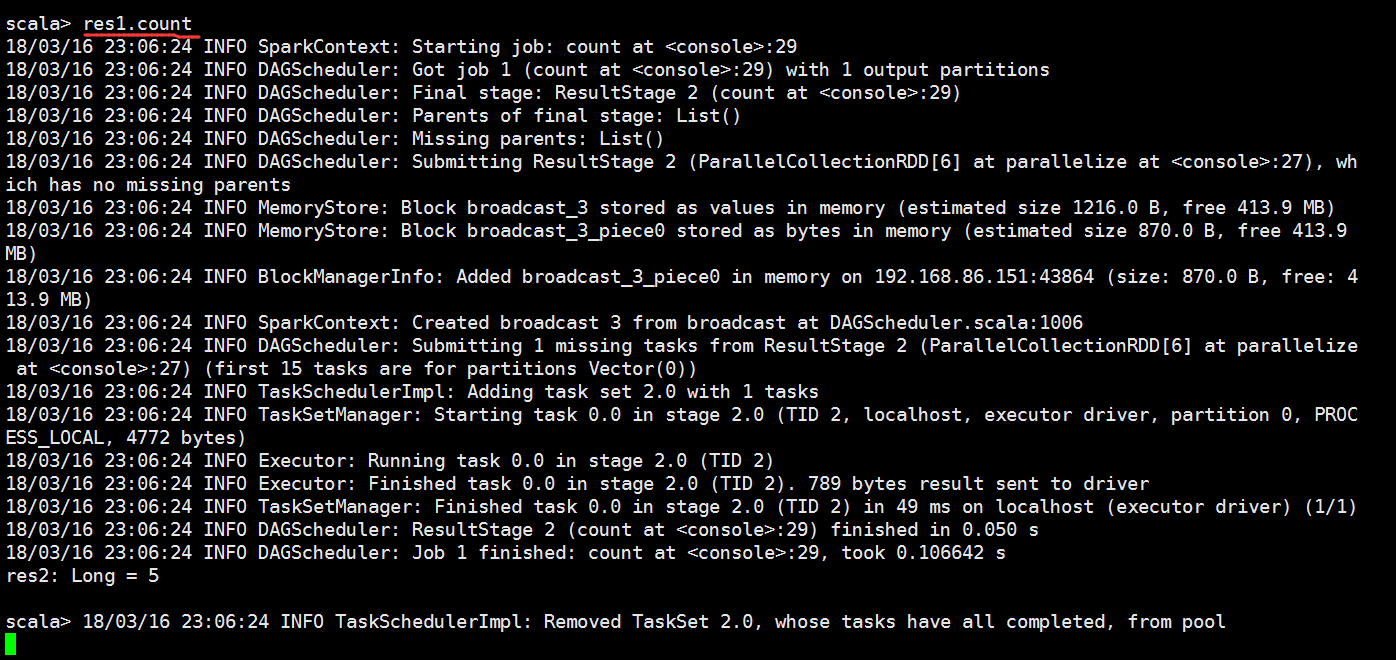



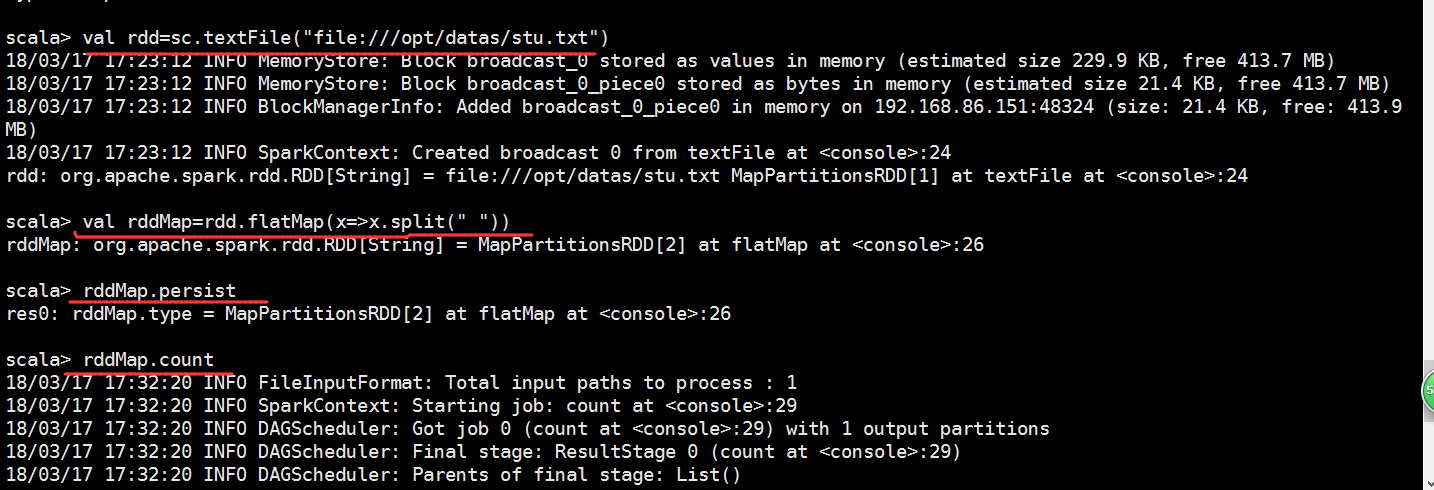
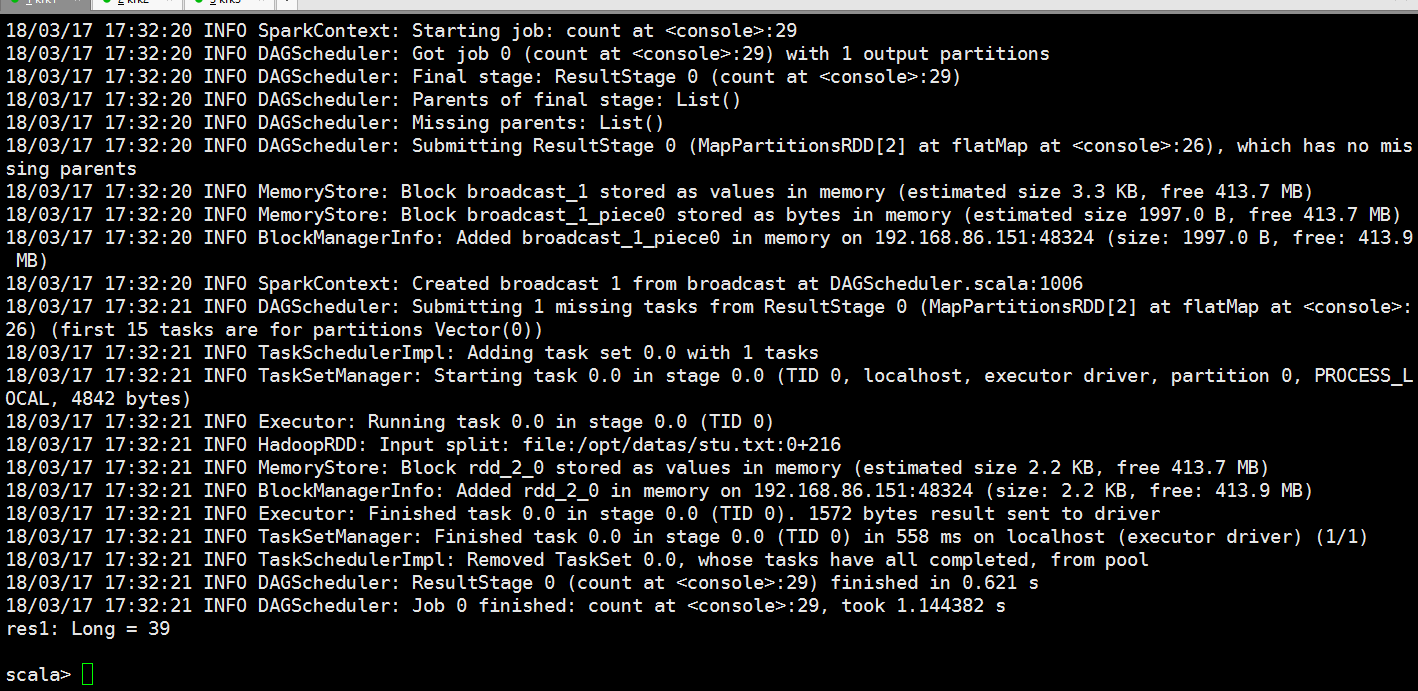
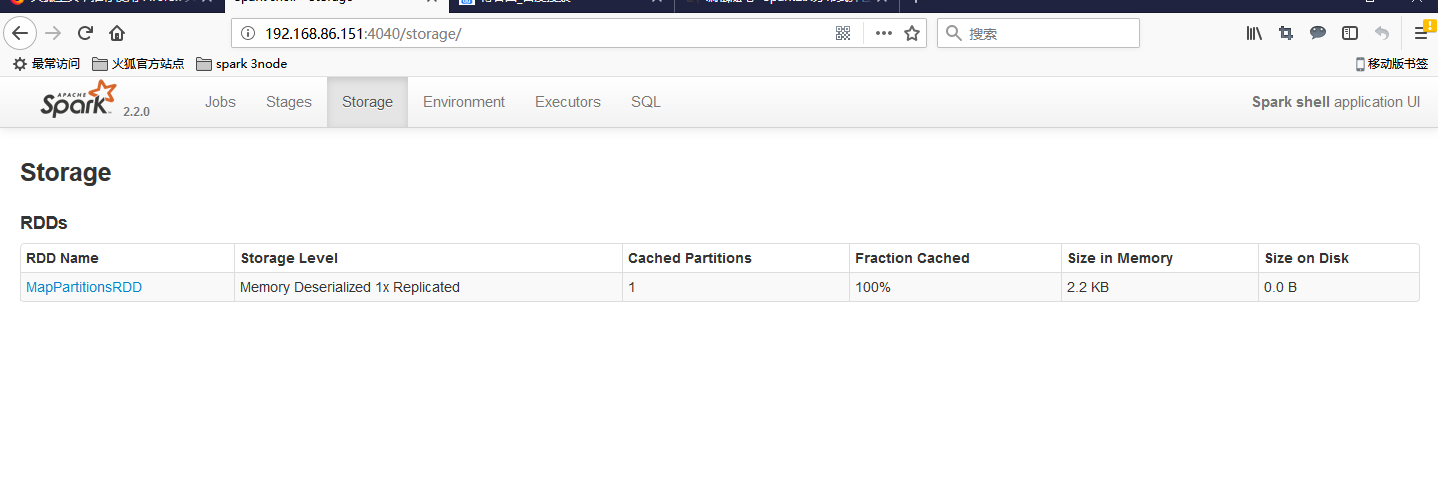
从监控页面我们可以看到
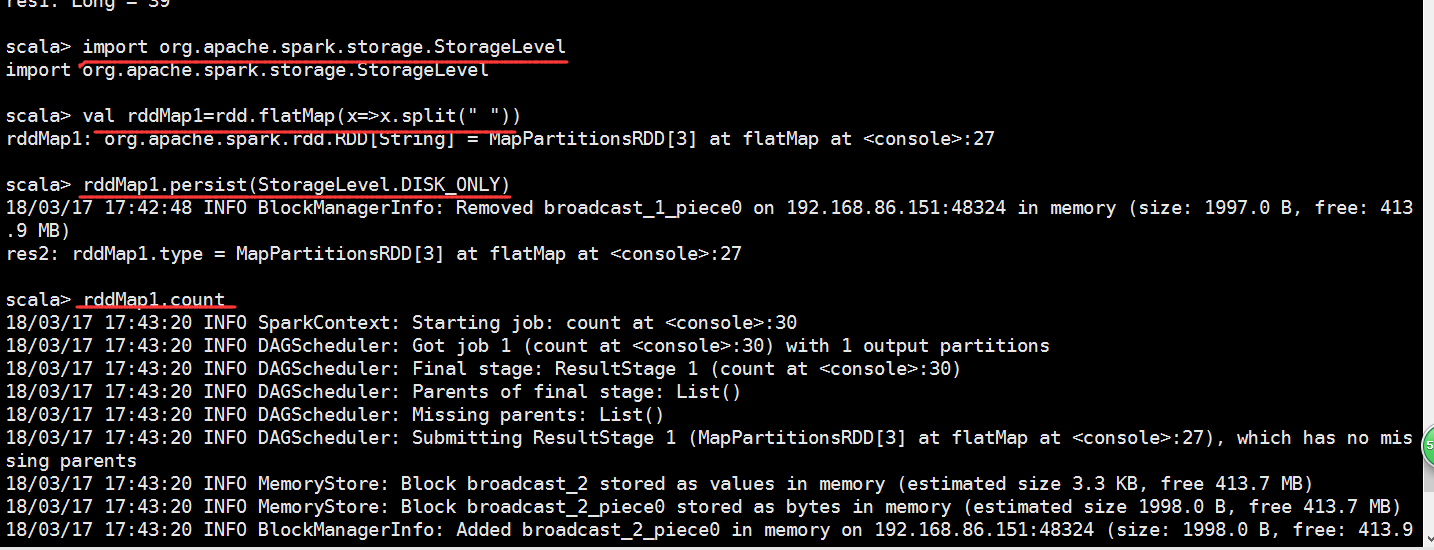
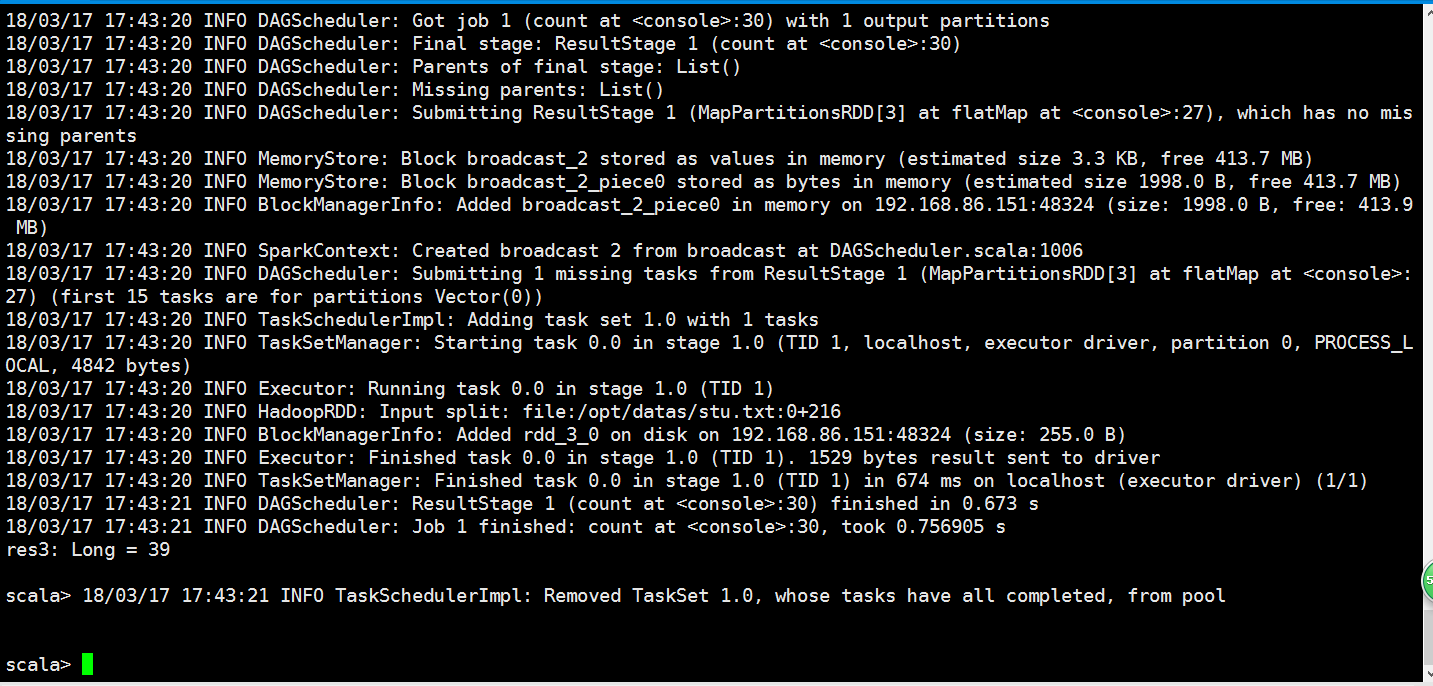






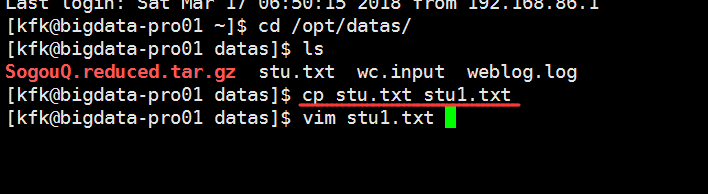
随便敲一些单词用作测试

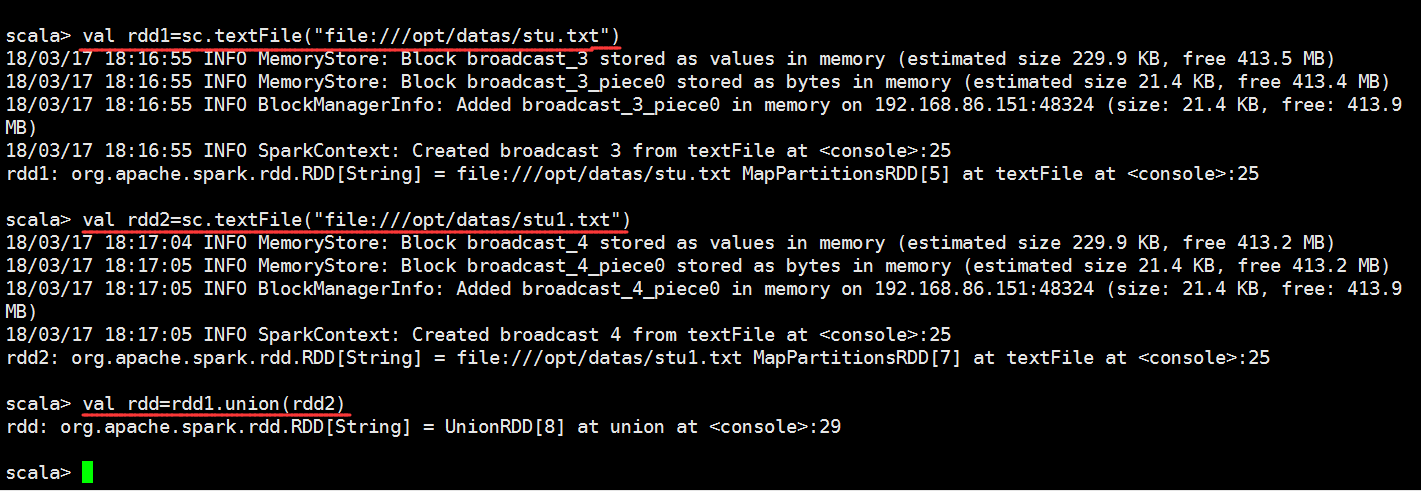
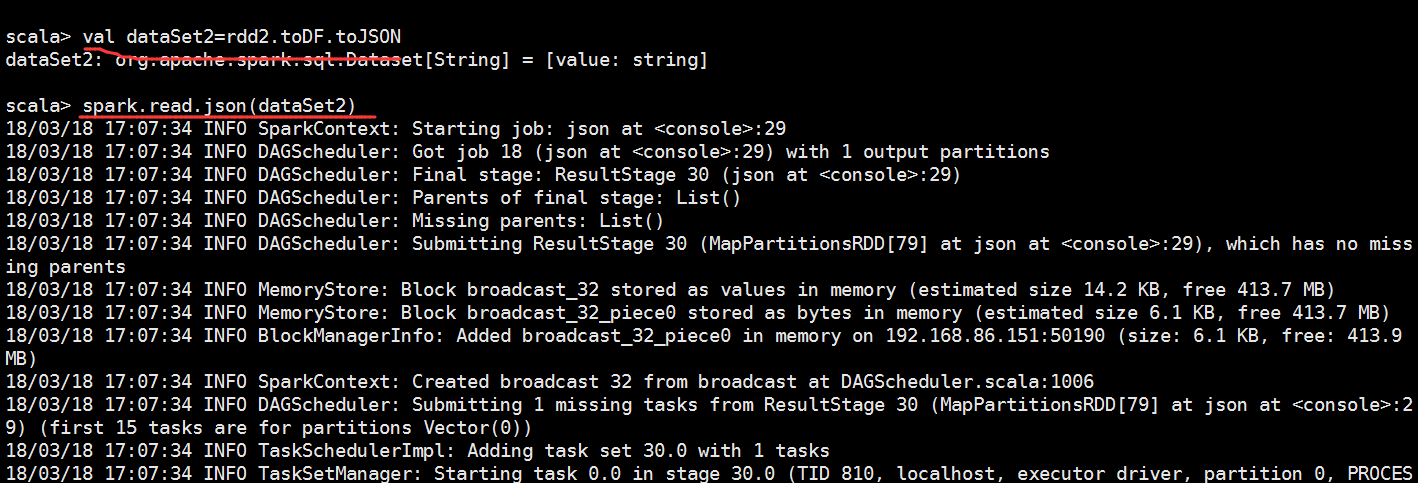
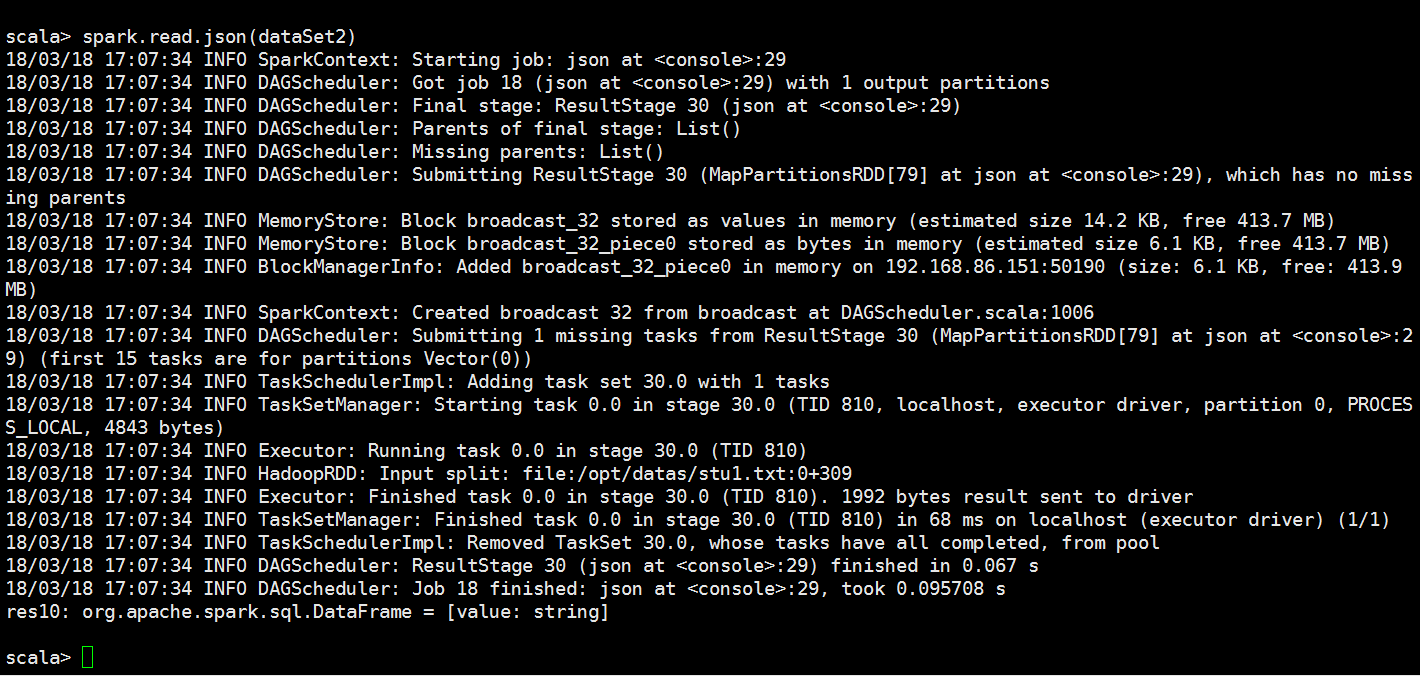
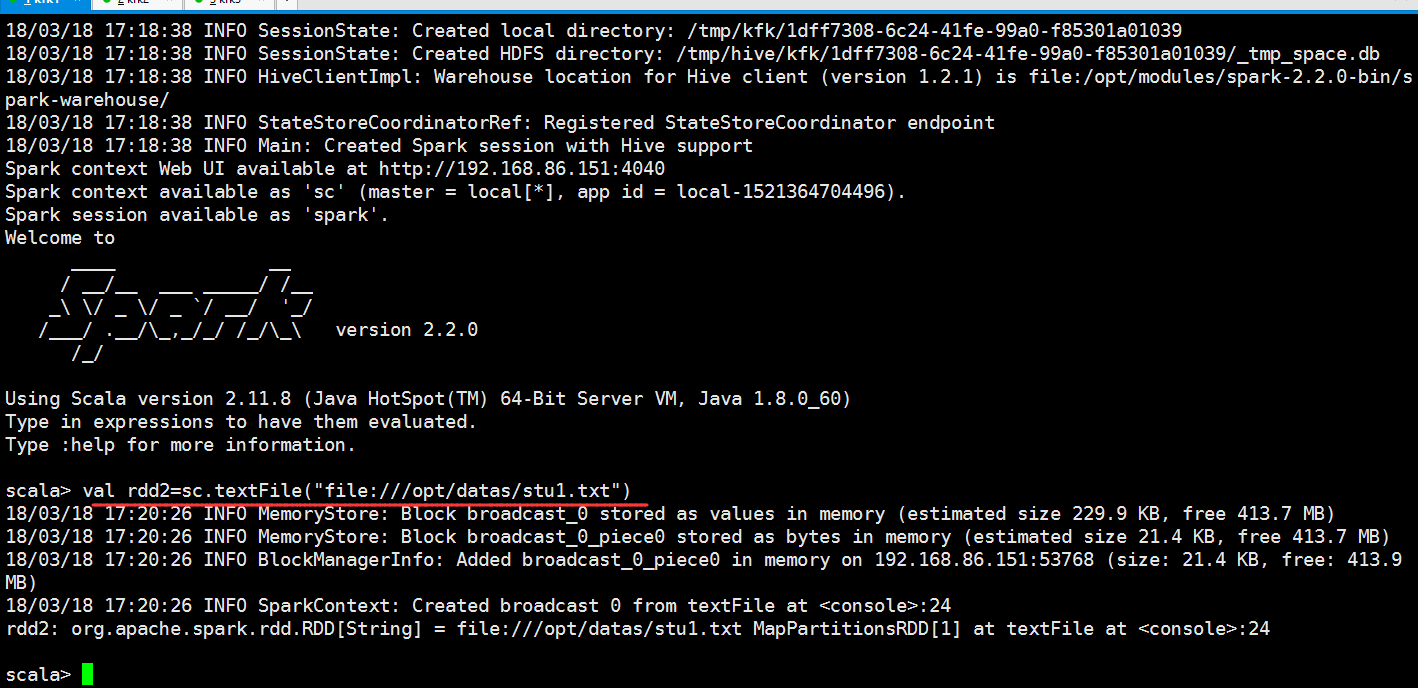
scala> val rdd1=sc.textFile("file:///opt/datas/stu.txt")
// :: INFO MemoryStore: Block broadcast_3 stored as values in memory (estimated size 229.9 KB, free 413.5 MB)
// :: INFO MemoryStore: Block broadcast_3_piece0 stored as bytes in memory (estimated size 21.4 KB, free 413.4 MB)
// :: INFO BlockManagerInfo: Added broadcast_3_piece0 in memory on 192.168.86.151: (size: 21.4 KB, free: 413.9 MB)
// :: INFO SparkContext: Created broadcast from textFile at <console>:
rdd1: org.apache.spark.rdd.RDD[String] = file:///opt/datas/stu.txt MapPartitionsRDD[5] at textFile at <console>:25
scala> val rdd2=sc.textFile("file:///opt/datas/stu1.txt")
// :: INFO MemoryStore: Block broadcast_4 stored as values in memory (estimated size 229.9 KB, free 413.2 MB)
// :: INFO MemoryStore: Block broadcast_4_piece0 stored as bytes in memory (estimated size 21.4 KB, free 413.2 MB)
// :: INFO BlockManagerInfo: Added broadcast_4_piece0 in memory on 192.168.86.151: (size: 21.4 KB, free: 413.9 MB)
// :: INFO SparkContext: Created broadcast from textFile at <console>:
rdd2: org.apache.spark.rdd.RDD[String] = file:///opt/datas/stu1.txt MapPartitionsRDD[7] at textFile at <console>:25
scala> val rdd=rdd1.union(rdd2)
rdd: org.apache.spark.rdd.RDD[String] = UnionRDD[] at union at <console>:
scala>

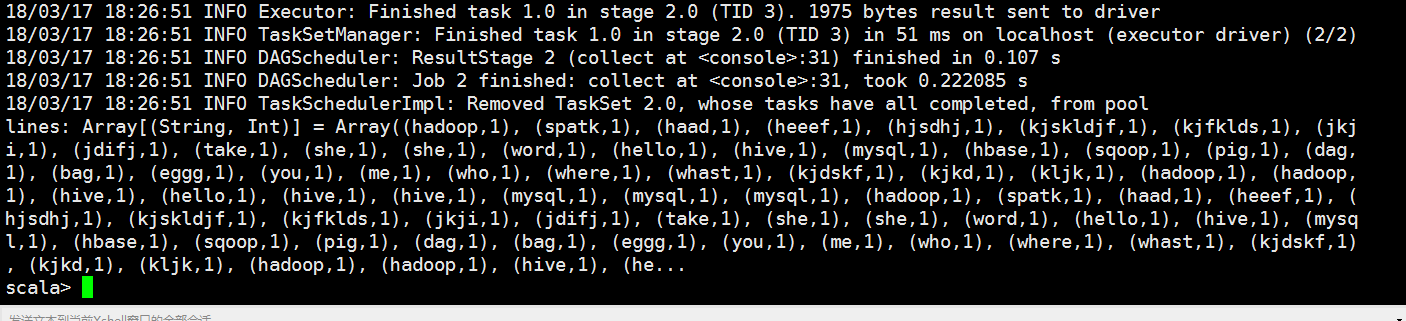
val lines = rdd.flatMap(x=>x.split(" ")).map(x=>(x,)).collect
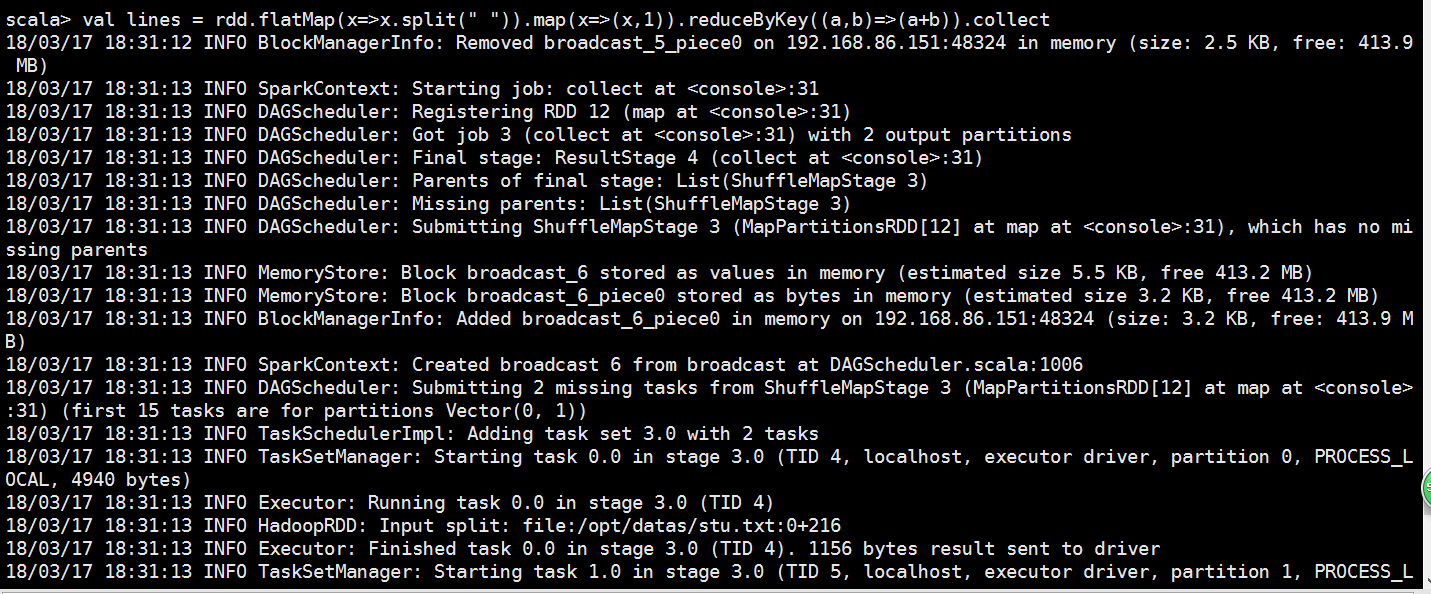
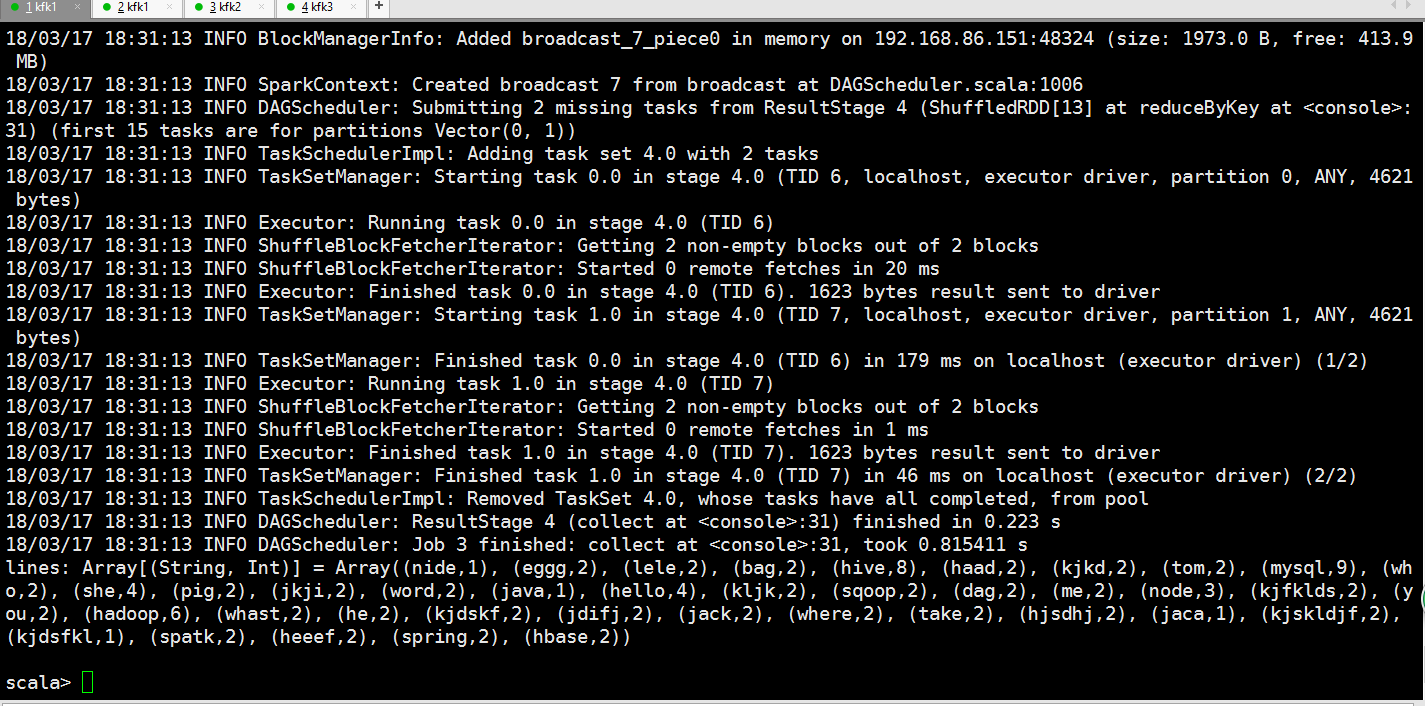
val lines = rdd.flatMap(x=>x.split(" ")).map(x=>(x,)).reduceByKey((a,b)=>(a+b)).collect
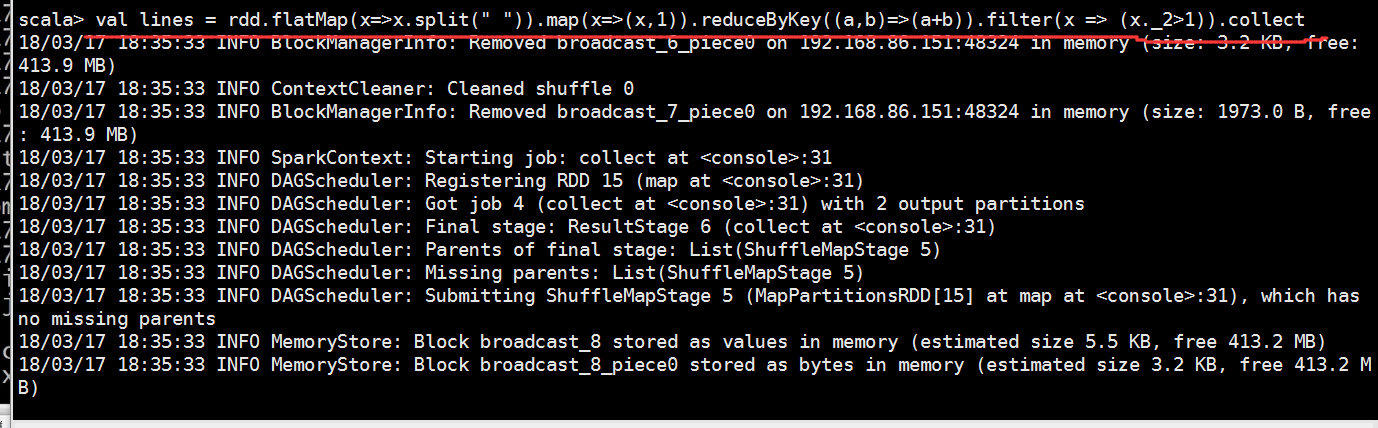
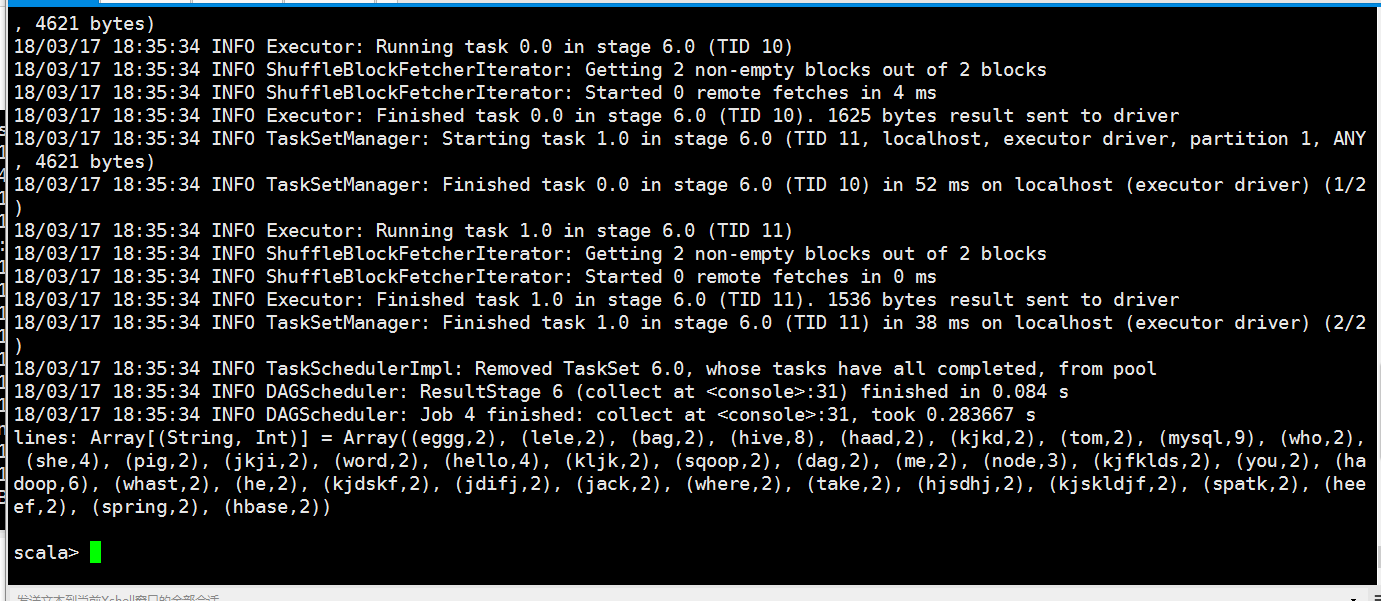
val lines = rdd.flatMap(x=>x.split(" ")).map(x=>(x,)).reduceByKey((a,b)=>(a+b)).filter(x => (x._2>)).collect

val lines = rdd.flatMap(x=>x.split(" ")).map(x=>(x,)).reduceByKey((a,b)=>(a+b)).filter(x => (x._2>)).map(x=>(x._2,x._1)).collect
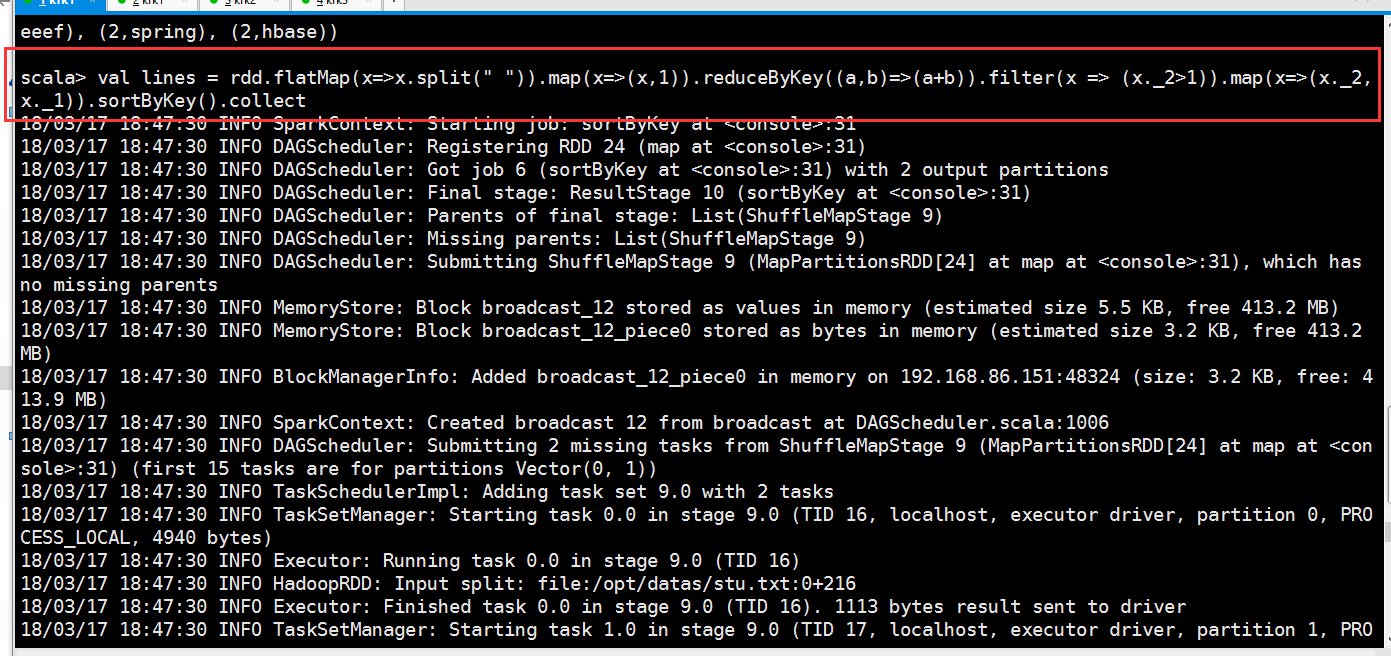
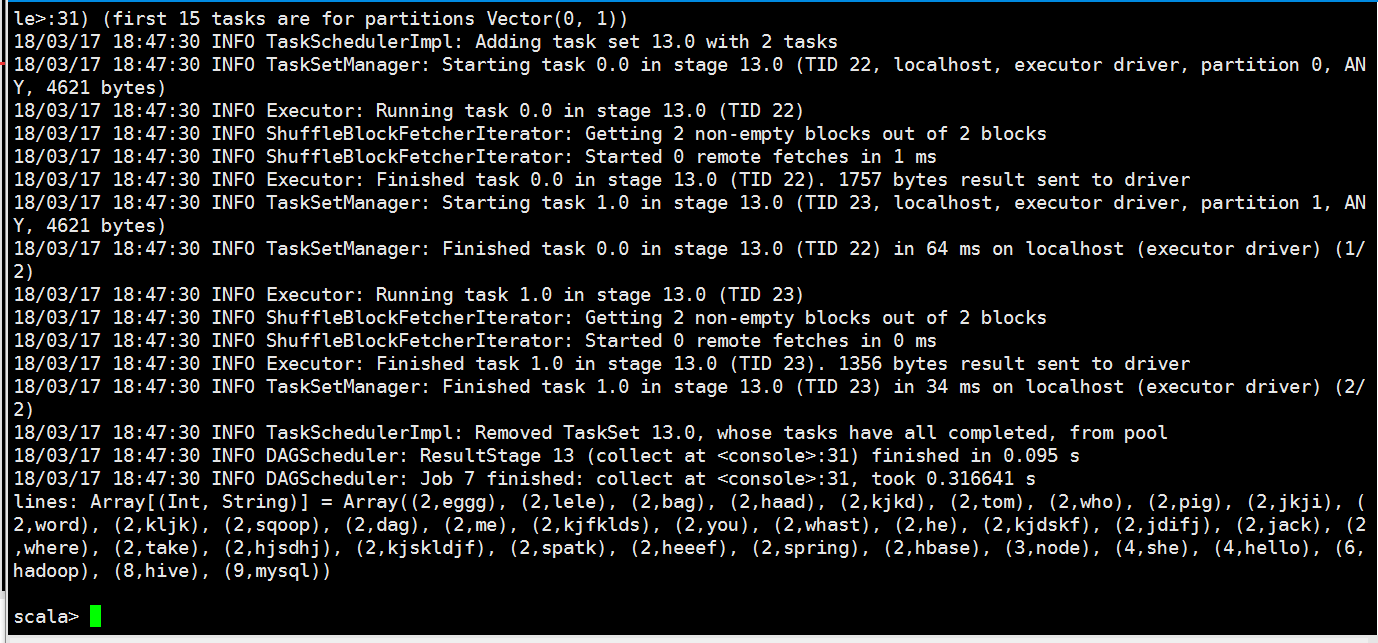
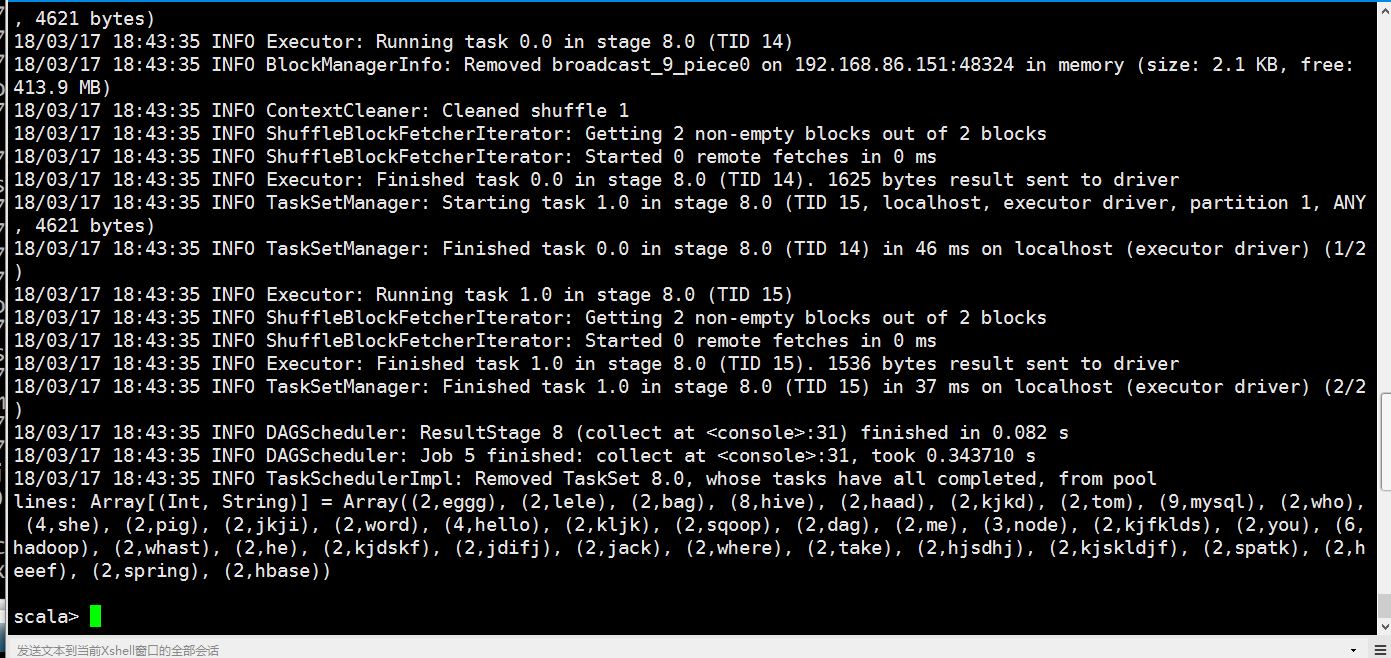
val lines = rdd.flatMap(x=>x.split(" ")).map(x=>(x,)).reduceByKey((a,b)=>(a+b)).filter(x => (x._2>)).map(x=>(x._2,x._1)).sortByKey().collect
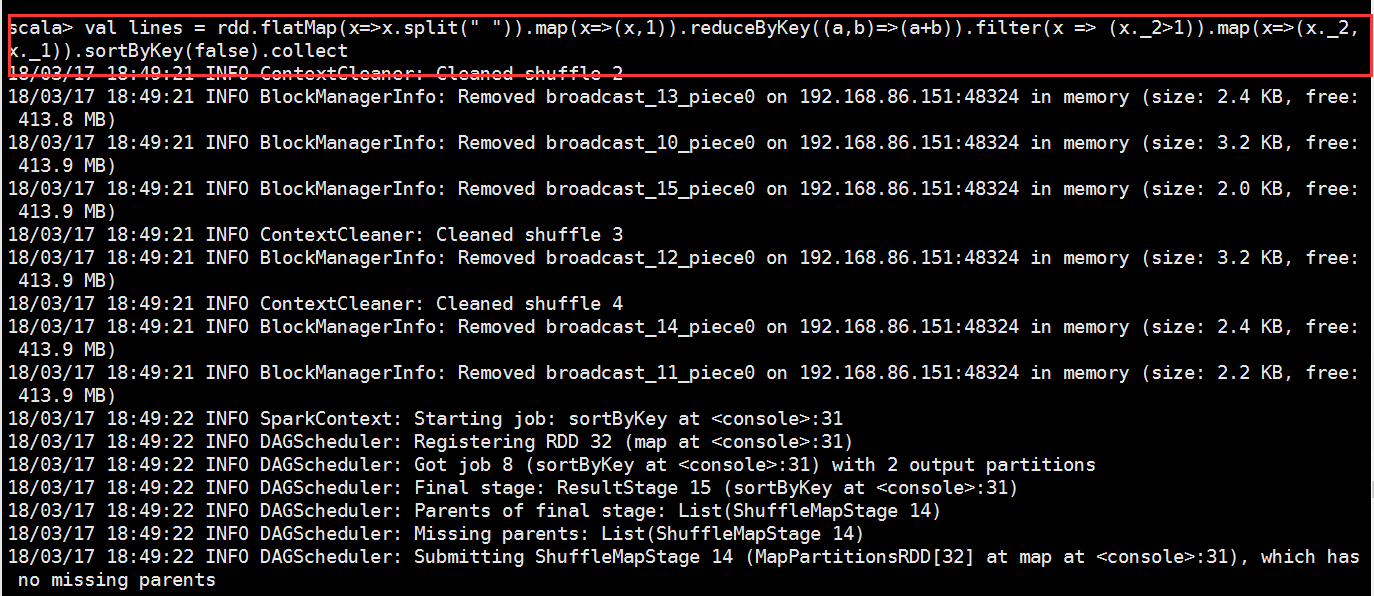
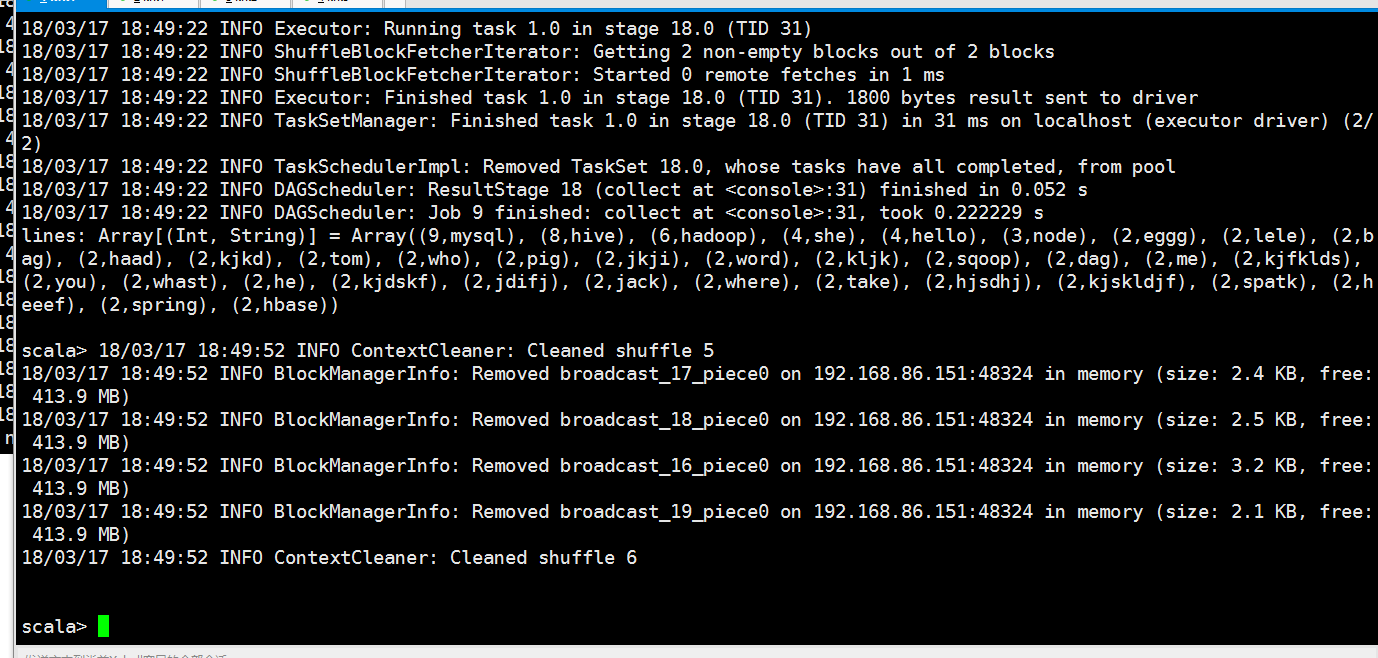
val lines = rdd.flatMap(x=>x.split(" ")).map(x=>(x,)).reduceByKey((a,b)=>(a+b)).filter(x => (x._2>)).map(x=>(x._2,x._1)).sortByKey(false).collect
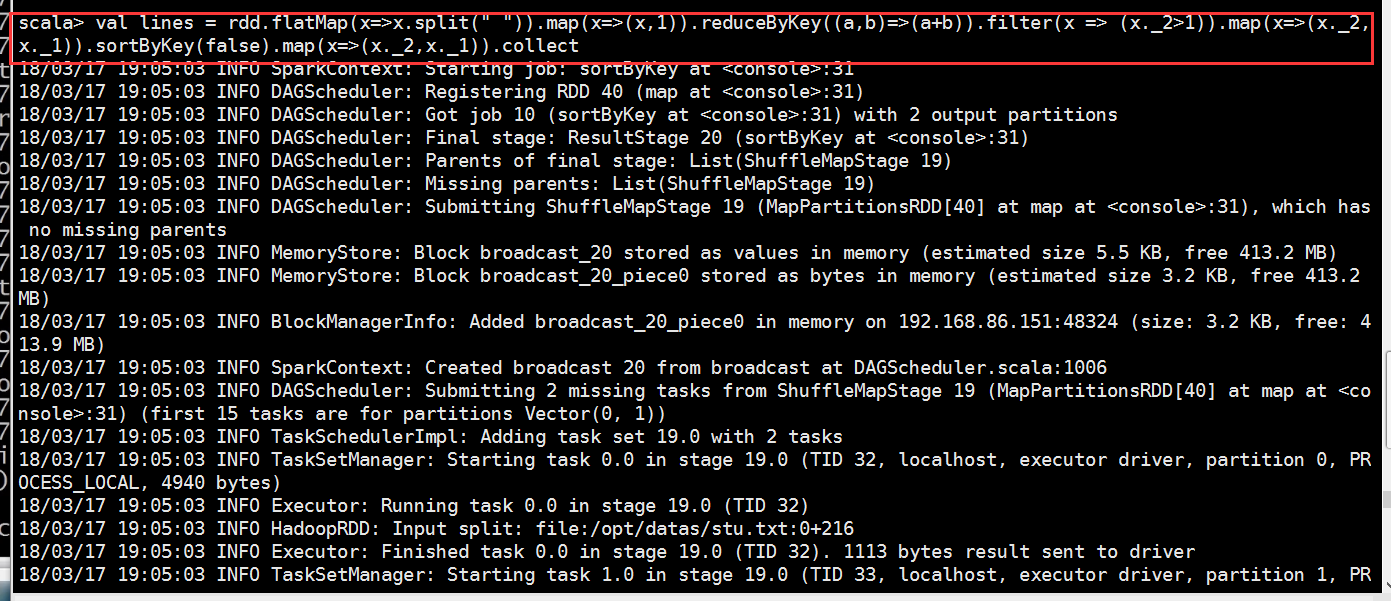
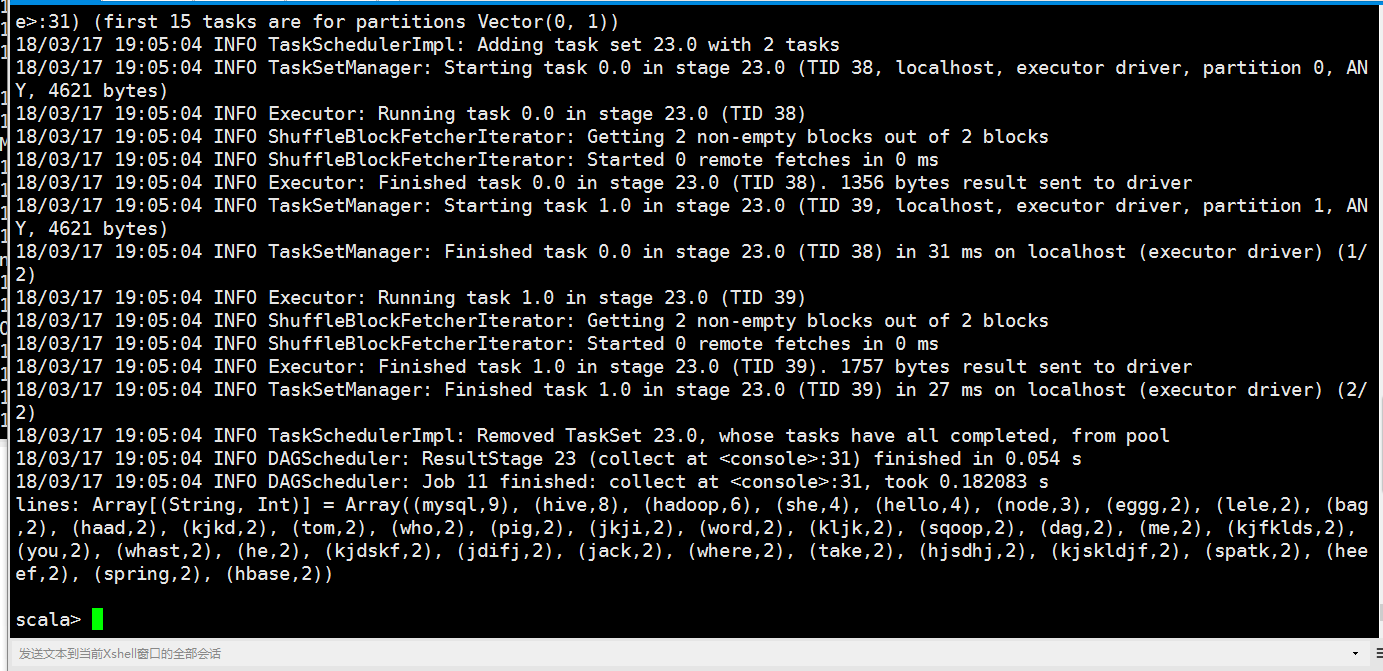
val lines = rdd.flatMap(x=>x.split(" ")).map(x=>(x,)).reduceByKey((a,b)=>(a+b)).filter(x => (x._2>)).map(x=>(x._2,x._1)).sortByKey(false).map(x=>(x._2,x._1)).collect
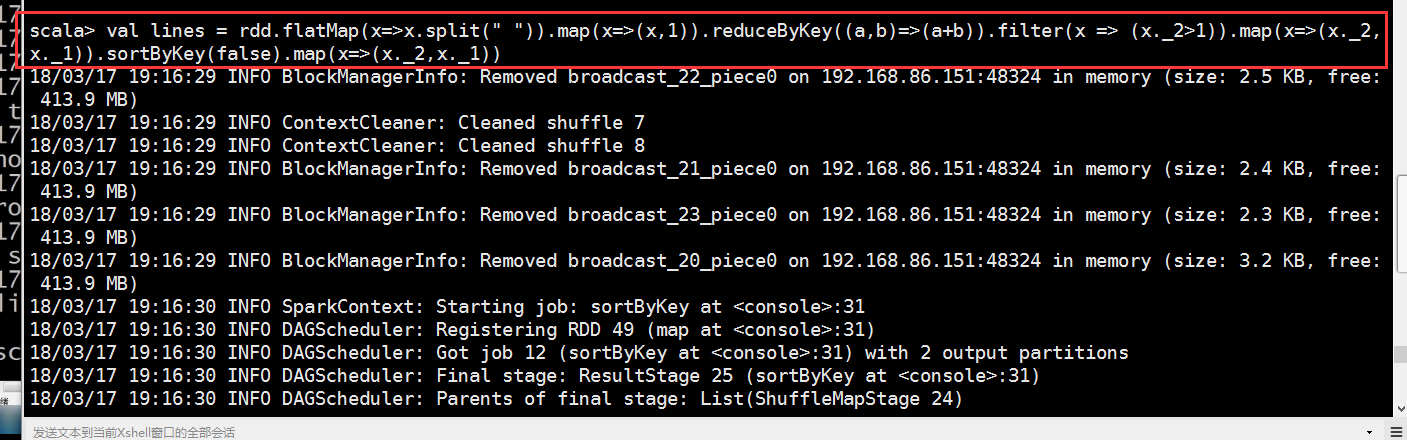

因为我目前的节点2的hdfs是active状态
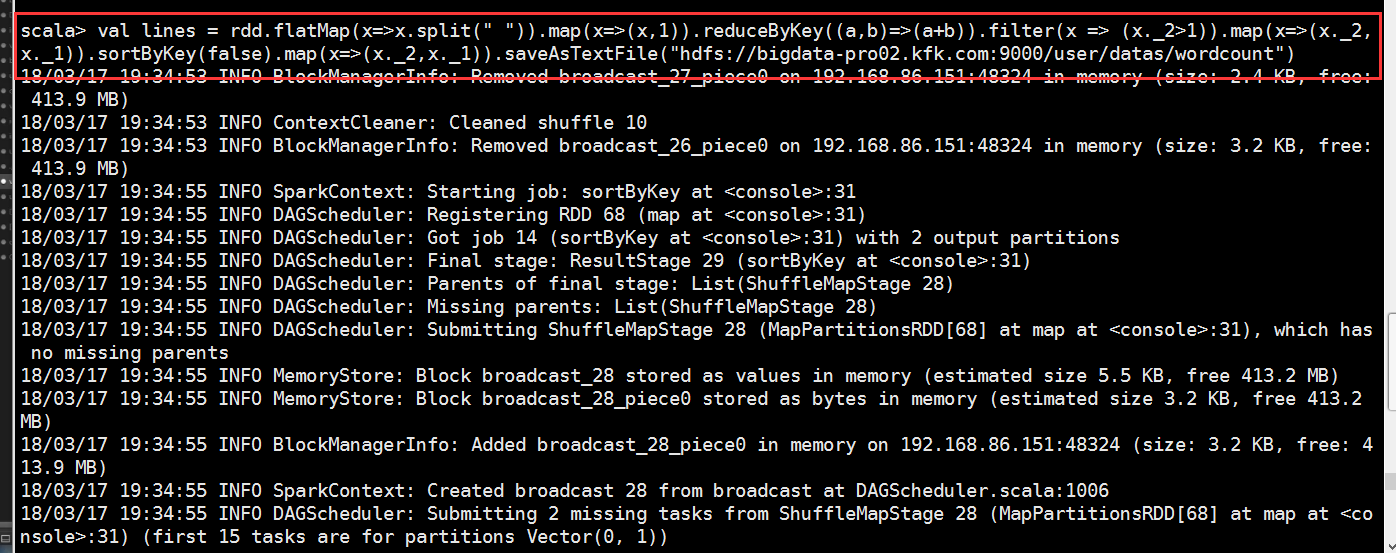
可以看到报错了,文件目录已经存在了,我们必须要是一个不存在的路径才可以
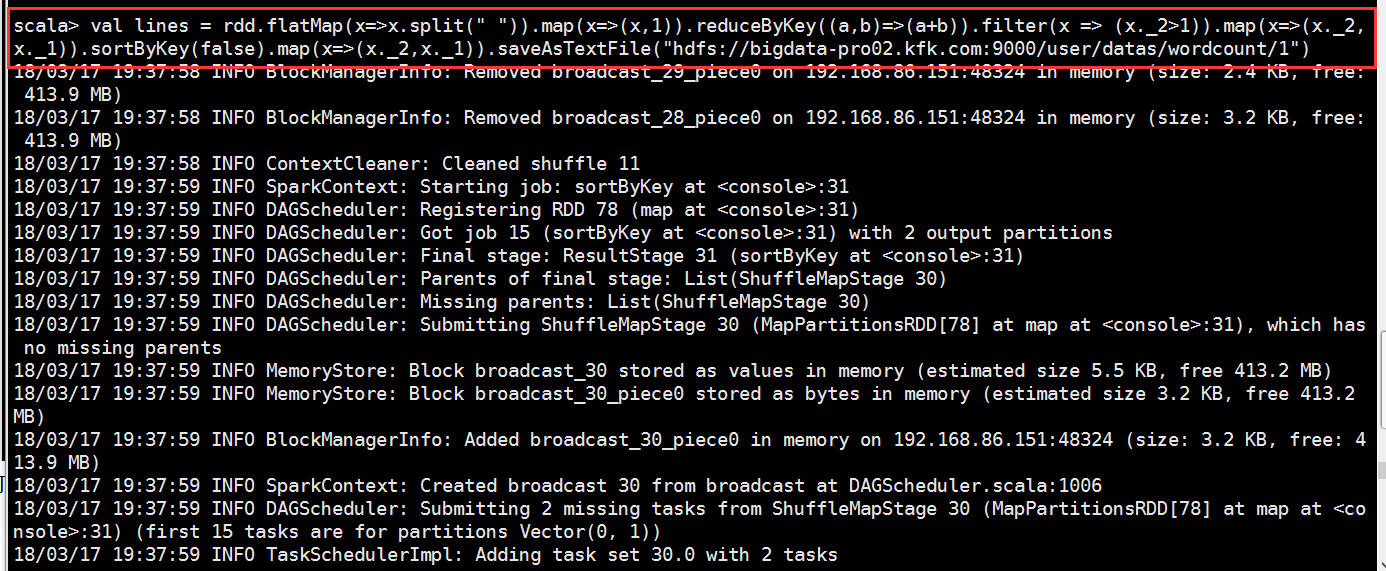
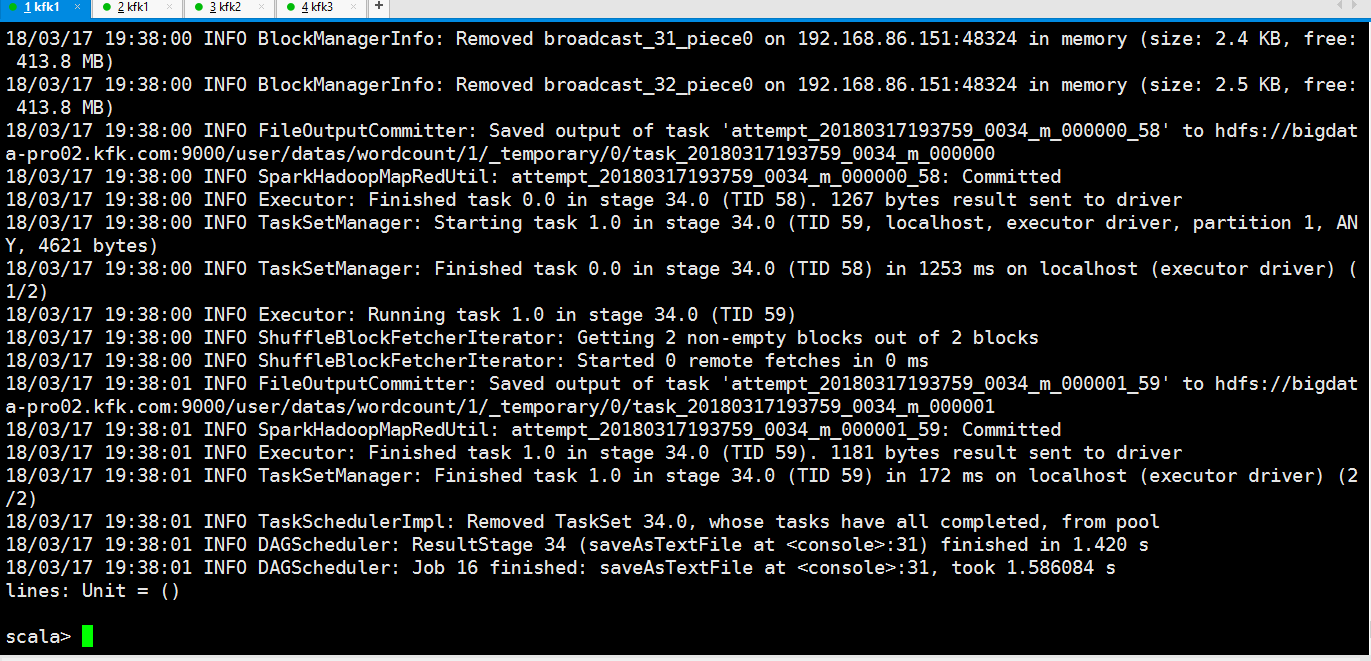
可以看到成功了
我们查看一下hdfs的输出目录
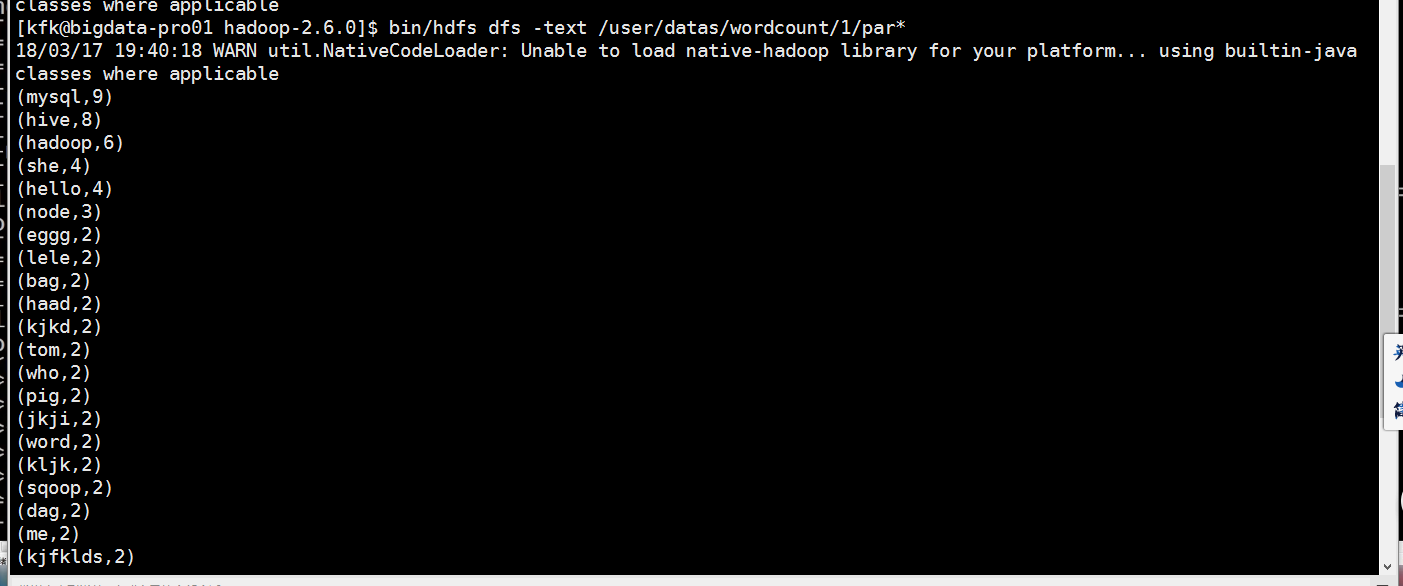
我们退出spark-shell,再重新进入
直接把我们前面的重新执行一次
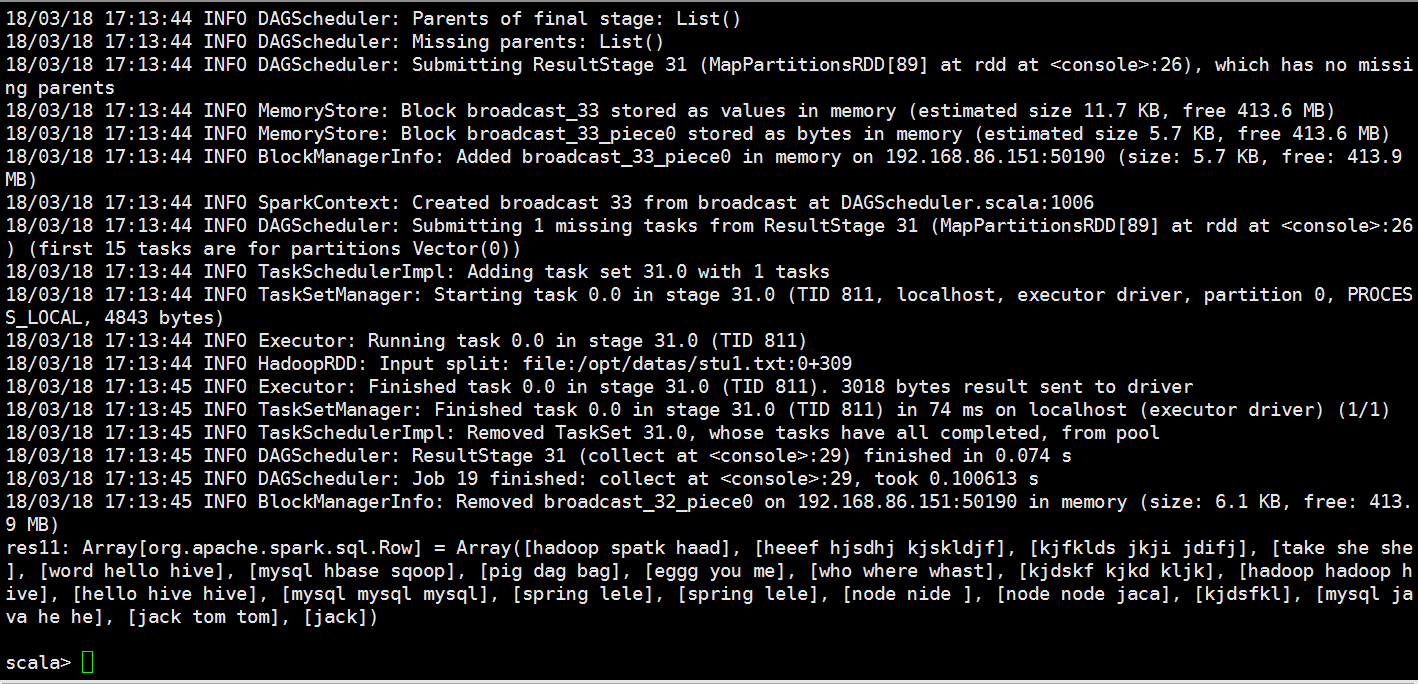
val rdd1=sc.textFile("file:///opt/datas/stu.txt")
val rdd2=sc.textFile("file:///opt/datas/stu1.txt")
val rdd=rdd1.union(rdd2)
val lines = rdd.flatMap(x=>x.split(" ")).map(x=>(x,)).reduceByKey((a,b)=>(a+b)).filter(x => (x._2>)).map(x=>(x._2,x._1)).sortByKey(false).map(x=>(x._2,x._1))
执行完了之后就
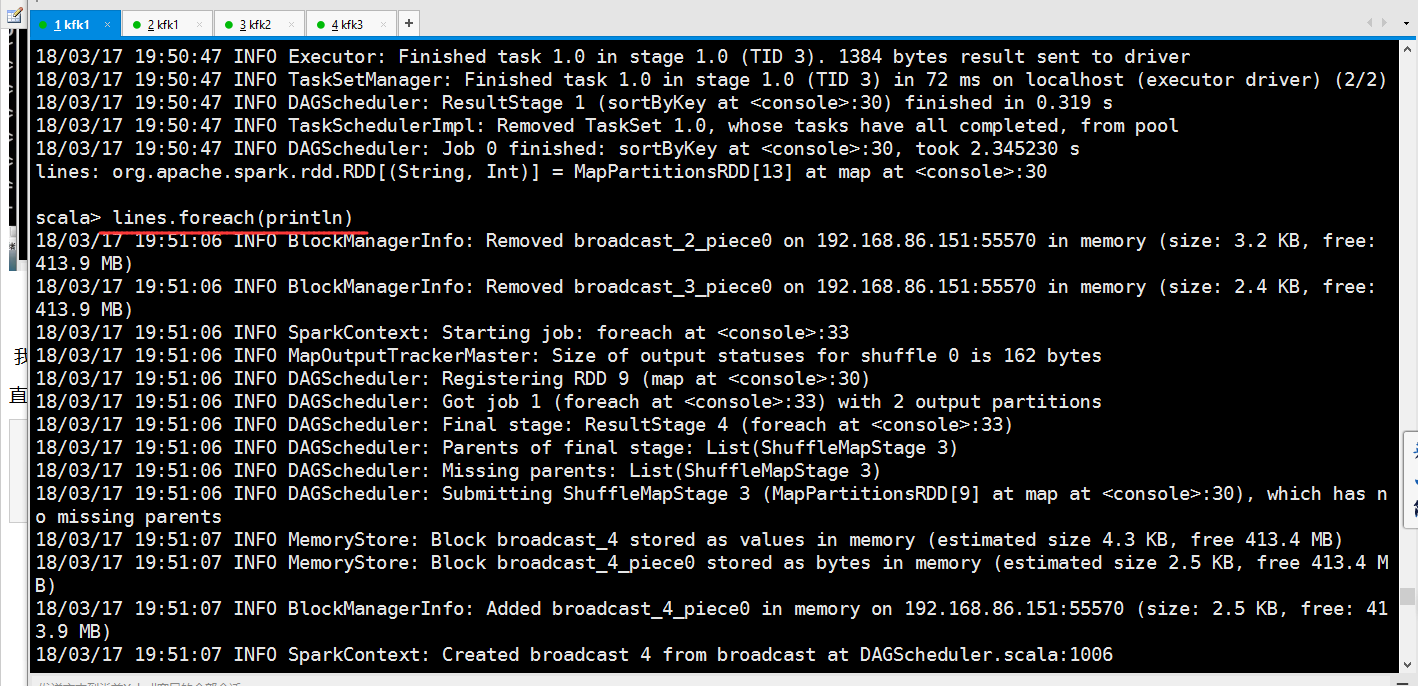

scala> lines.foreach(println)
// :: INFO BlockManagerInfo: Removed broadcast_2_piece0 on 192.168.86.151: in memory (size: 3.2 KB, free: 413.9 MB)
// :: INFO BlockManagerInfo: Removed broadcast_3_piece0 on 192.168.86.151: in memory (size: 2.4 KB, free: 413.9 MB)
// :: INFO SparkContext: Starting job: foreach at <console>:
// :: INFO MapOutputTrackerMaster: Size of output statuses for shuffle is bytes
// :: INFO DAGScheduler: Registering RDD (map at <console>:)
// :: INFO DAGScheduler: Got job (foreach at <console>:) with output partitions
// :: INFO DAGScheduler: Final stage: ResultStage (foreach at <console>:)
// :: INFO DAGScheduler: Parents of final stage: List(ShuffleMapStage )
// :: INFO DAGScheduler: Missing parents: List(ShuffleMapStage )
// :: INFO DAGScheduler: Submitting ShuffleMapStage (MapPartitionsRDD[] at map at <console>:), which has no missing parents
// :: INFO MemoryStore: Block broadcast_4 stored as values in memory (estimated size 4.3 KB, free 413.4 MB)
// :: INFO MemoryStore: Block broadcast_4_piece0 stored as bytes in memory (estimated size 2.5 KB, free 413.4 MB)
// :: INFO BlockManagerInfo: Added broadcast_4_piece0 in memory on 192.168.86.151: (size: 2.5 KB, free: 413.9 MB)
// :: INFO SparkContext: Created broadcast from broadcast at DAGScheduler.scala:
// :: INFO DAGScheduler: Submitting missing tasks from ShuffleMapStage (MapPartitionsRDD[] at map at <console>:) (first tasks are for partitions Vector(, ))
// :: INFO TaskSchedulerImpl: Adding task set 3.0 with tasks
// :: INFO TaskSetManager: Starting task 0.0 in stage 3.0 (TID , localhost, executor driver, partition , ANY, bytes)
// :: INFO Executor: Running task 0.0 in stage 3.0 (TID )
// :: INFO ShuffleBlockFetcherIterator: Getting non-empty blocks out of blocks
// :: INFO ShuffleBlockFetcherIterator: Started remote fetches in ms
// :: INFO Executor: Finished task 0.0 in stage 3.0 (TID ). bytes result sent to driver
// :: INFO TaskSetManager: Starting task 1.0 in stage 3.0 (TID , localhost, executor driver, partition , ANY, bytes)
// :: INFO TaskSetManager: Finished task 0.0 in stage 3.0 (TID ) in ms on localhost (executor driver) (/)
// :: INFO Executor: Running task 1.0 in stage 3.0 (TID )
// :: INFO ShuffleBlockFetcherIterator: Getting non-empty blocks out of blocks
// :: INFO ShuffleBlockFetcherIterator: Started remote fetches in ms
// :: INFO Executor: Finished task 1.0 in stage 3.0 (TID ). bytes result sent to driver
// :: INFO TaskSetManager: Finished task 1.0 in stage 3.0 (TID ) in ms on localhost (executor driver) (/)
// :: INFO TaskSchedulerImpl: Removed TaskSet 3.0, whose tasks have all completed, from pool
// :: INFO DAGScheduler: ShuffleMapStage (map at <console>:) finished in 0.227 s
// :: INFO DAGScheduler: looking for newly runnable stages
// :: INFO DAGScheduler: running: Set()
// :: INFO DAGScheduler: waiting: Set(ResultStage )
// :: INFO DAGScheduler: failed: Set()
// :: INFO DAGScheduler: Submitting ResultStage (MapPartitionsRDD[] at map at <console>:), which has no missing parents
// :: INFO MemoryStore: Block broadcast_5 stored as values in memory (estimated size 3.9 KB, free 413.4 MB)
// :: INFO MemoryStore: Block broadcast_5_piece0 stored as bytes in memory (estimated size 2.3 KB, free 413.4 MB)
// :: INFO BlockManagerInfo: Added broadcast_5_piece0 in memory on 192.168.86.151: (size: 2.3 KB, free: 413.9 MB)
// :: INFO SparkContext: Created broadcast from broadcast at DAGScheduler.scala:
// :: INFO DAGScheduler: Submitting missing tasks from ResultStage (MapPartitionsRDD[] at map at <console>:) (first tasks are for partitions Vector(, ))
// :: INFO TaskSchedulerImpl: Adding task set 4.0 with tasks
// :: INFO TaskSetManager: Starting task 0.0 in stage 4.0 (TID , localhost, executor driver, partition , ANY, bytes)
// :: INFO Executor: Running task 0.0 in stage 4.0 (TID )
// :: INFO ShuffleBlockFetcherIterator: Getting non-empty blocks out of blocks
// :: INFO ShuffleBlockFetcherIterator: Started remote fetches in ms
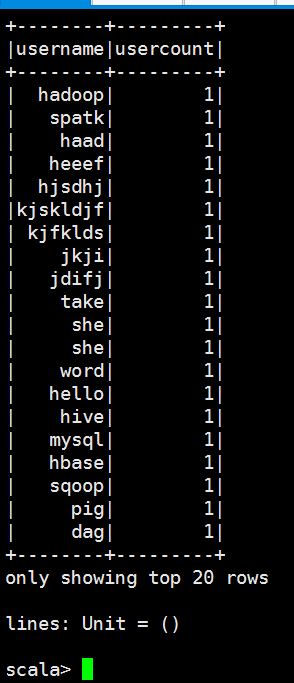
(mysql,)
(hive,)
(hadoop,)
(she,)
(hello,)
(node,)
// :: INFO Executor: Finished task 0.0 in stage 4.0 (TID ). bytes result sent to driver
// :: INFO TaskSetManager: Starting task 1.0 in stage 4.0 (TID , localhost, executor driver, partition , ANY, bytes)
// :: INFO TaskSetManager: Finished task 0.0 in stage 4.0 (TID ) in ms on localhost (executor driver) (/)
// :: INFO Executor: Running task 1.0 in stage 4.0 (TID )
// :: INFO ShuffleBlockFetcherIterator: Getting non-empty blocks out of blocks
// :: INFO ShuffleBlockFetcherIterator: Started remote fetches in ms
(eggg,)
(lele,)
(bag,)
(haad,)
(kjkd,)
(tom,)
(who,)
(pig,)
(jkji,)
(word,)
(kljk,)
(sqoop,)
(dag,)
(me,)
(kjfklds,)
(you,)
(whast,)
(he,)
(kjdskf,)
(jdifj,)
(jack,)
(where,)
(take,)
(hjsdhj,)
(kjskldjf,)
(spatk,)
(heeef,)
(spring,)
(hbase,)
// :: INFO Executor: Finished task 1.0 in stage 4.0 (TID ). bytes result sent to driver
// :: INFO TaskSetManager: Finished task 1.0 in stage 4.0 (TID ) in ms on localhost (executor driver) (/)
// :: INFO DAGScheduler: ResultStage (foreach at <console>:) finished in 0.155 s
// :: INFO TaskSchedulerImpl: Removed TaskSet 4.0, whose tasks have all completed, from pool
// :: INFO DAGScheduler: Job finished: foreach at <console>:, took 0.509656 s scala>
我们可以发现出来的这个结果数据长得很恶心啊

也就是说我们的这个rdd有两个分区
我们来指定分区数目

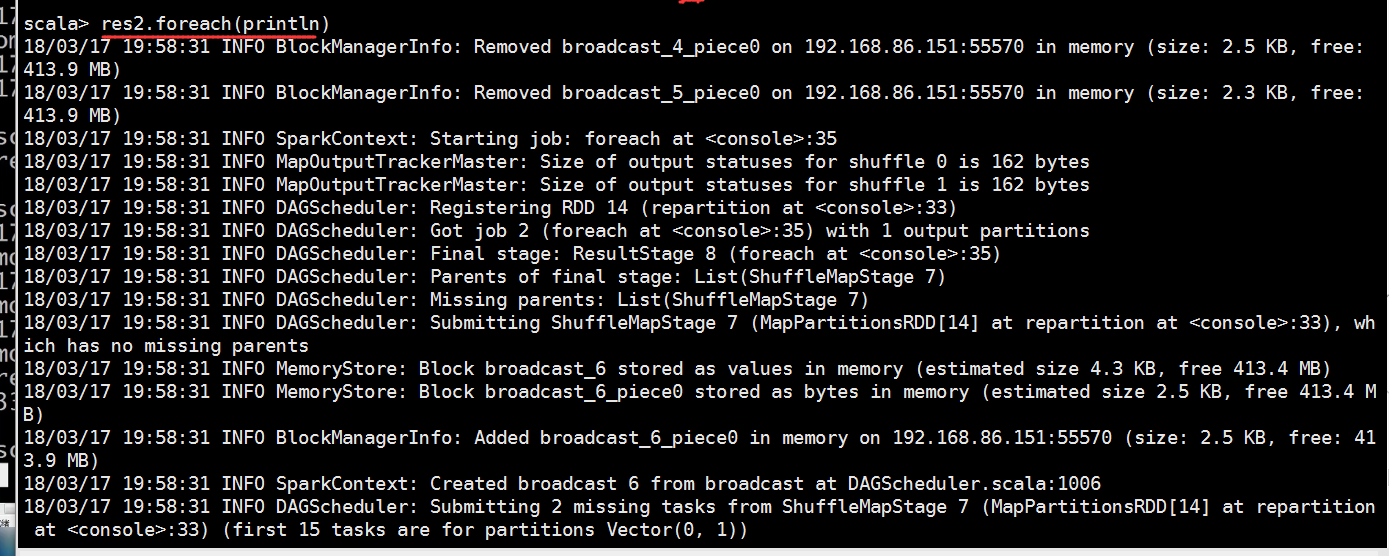

scala> res2.foreach(println)
// :: INFO BlockManagerInfo: Removed broadcast_4_piece0 on 192.168.86.151: in memory (size: 2.5 KB, free: 413.9 MB)
// :: INFO BlockManagerInfo: Removed broadcast_5_piece0 on 192.168.86.151: in memory (size: 2.3 KB, free: 413.9 MB)
// :: INFO SparkContext: Starting job: foreach at <console>:
// :: INFO MapOutputTrackerMaster: Size of output statuses for shuffle is bytes
// :: INFO MapOutputTrackerMaster: Size of output statuses for shuffle is bytes
// :: INFO DAGScheduler: Registering RDD (repartition at <console>:)
// :: INFO DAGScheduler: Got job (foreach at <console>:) with output partitions
// :: INFO DAGScheduler: Final stage: ResultStage (foreach at <console>:)
// :: INFO DAGScheduler: Parents of final stage: List(ShuffleMapStage )
// :: INFO DAGScheduler: Missing parents: List(ShuffleMapStage )
// :: INFO DAGScheduler: Submitting ShuffleMapStage (MapPartitionsRDD[] at repartition at <console>:), which has no missing parents
// :: INFO MemoryStore: Block broadcast_6 stored as values in memory (estimated size 4.3 KB, free 413.4 MB)
// :: INFO MemoryStore: Block broadcast_6_piece0 stored as bytes in memory (estimated size 2.5 KB, free 413.4 MB)
// :: INFO BlockManagerInfo: Added broadcast_6_piece0 in memory on 192.168.86.151: (size: 2.5 KB, free: 413.9 MB)
// :: INFO SparkContext: Created broadcast from broadcast at DAGScheduler.scala:
// :: INFO DAGScheduler: Submitting missing tasks from ShuffleMapStage (MapPartitionsRDD[] at repartition at <console>:) (first tasks are for partitions Vector(, ))
// :: INFO TaskSchedulerImpl: Adding task set 7.0 with tasks
// :: INFO TaskSetManager: Starting task 0.0 in stage 7.0 (TID , localhost, executor driver, partition , ANY, bytes)
// :: INFO Executor: Running task 0.0 in stage 7.0 (TID )
// :: INFO ShuffleBlockFetcherIterator: Getting non-empty blocks out of blocks
// :: INFO ShuffleBlockFetcherIterator: Started remote fetches in ms
// :: INFO Executor: Finished task 0.0 in stage 7.0 (TID ). bytes result sent to driver
// :: INFO TaskSetManager: Starting task 1.0 in stage 7.0 (TID , localhost, executor driver, partition , ANY, bytes)
// :: INFO TaskSetManager: Finished task 0.0 in stage 7.0 (TID ) in ms on localhost (executor driver) (/)
// :: INFO Executor: Running task 1.0 in stage 7.0 (TID )
// :: INFO ShuffleBlockFetcherIterator: Getting non-empty blocks out of blocks
// :: INFO ShuffleBlockFetcherIterator: Started remote fetches in ms
// :: INFO Executor: Finished task 1.0 in stage 7.0 (TID ). bytes result sent to driver
// :: INFO TaskSetManager: Finished task 1.0 in stage 7.0 (TID ) in ms on localhost (executor driver) (/)
// :: INFO TaskSchedulerImpl: Removed TaskSet 7.0, whose tasks have all completed, from pool
// :: INFO DAGScheduler: ShuffleMapStage (repartition at <console>:) finished in 0.157 s
// :: INFO DAGScheduler: looking for newly runnable stages
// :: INFO DAGScheduler: running: Set()
// :: INFO DAGScheduler: waiting: Set(ResultStage )
// :: INFO DAGScheduler: failed: Set()
// :: INFO DAGScheduler: Submitting ResultStage (MapPartitionsRDD[] at repartition at <console>:), which has no missing parents
// :: INFO MemoryStore: Block broadcast_7 stored as values in memory (estimated size 3.3 KB, free 413.4 MB)
// :: INFO MemoryStore: Block broadcast_7_piece0 stored as bytes in memory (estimated size 1934.0 B, free 413.4 MB)
// :: INFO BlockManagerInfo: Added broadcast_7_piece0 in memory on 192.168.86.151: (size: 1934.0 B, free: 413.9 MB)
// :: INFO SparkContext: Created broadcast from broadcast at DAGScheduler.scala:
// :: INFO DAGScheduler: Submitting missing tasks from ResultStage (MapPartitionsRDD[] at repartition at <console>:) (first tasks are for partitions Vector())
// :: INFO TaskSchedulerImpl: Adding task set 8.0 with tasks
// :: INFO TaskSetManager: Starting task 0.0 in stage 8.0 (TID , localhost, executor driver, partition , ANY, bytes)
// :: INFO Executor: Running task 0.0 in stage 8.0 (TID )
// :: INFO ShuffleBlockFetcherIterator: Getting non-empty blocks out of blocks
// :: INFO ShuffleBlockFetcherIterator: Started remote fetches in ms
(mysql,)
(hive,)
(hadoop,)
(she,)
(hello,)
(node,)
(eggg,)
(lele,)
(bag,)
(haad,)
(kjkd,)
(tom,)
(who,)
(pig,)
(jkji,)
(word,)
(kljk,)
(sqoop,)
(dag,)
(me,)
(kjfklds,)
(you,)
(whast,)
(he,)
(kjdskf,)
(jdifj,)
(jack,)
(where,)
(take,)
(hjsdhj,)
(kjskldjf,)
(spatk,)
(heeef,)
(spring,)
(hbase,)
// :: INFO Executor: Finished task 0.0 in stage 8.0 (TID ). bytes result sent to driver
// :: INFO TaskSetManager: Finished task 0.0 in stage 8.0 (TID ) in ms on localhost (executor driver) (/)
// :: INFO TaskSchedulerImpl: Removed TaskSet 8.0, whose tasks have all completed, from pool
// :: INFO DAGScheduler: ResultStage (foreach at <console>:) finished in 0.049 s
// :: INFO DAGScheduler: Job finished: foreach at <console>:, took 0.288514 s scala>
其实我们可以搞多个分区的
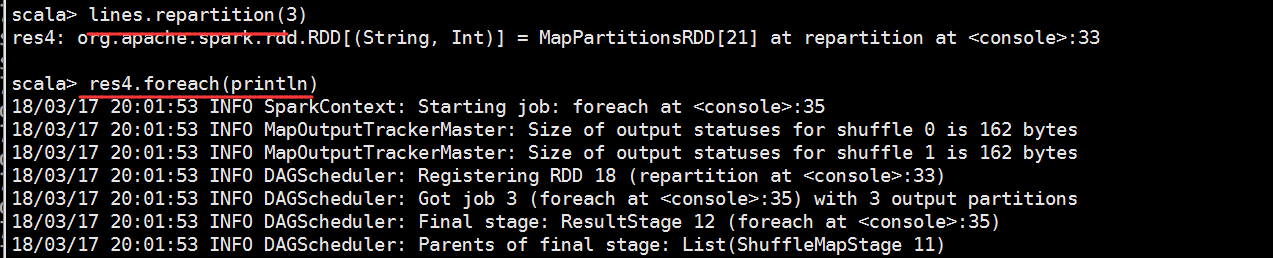
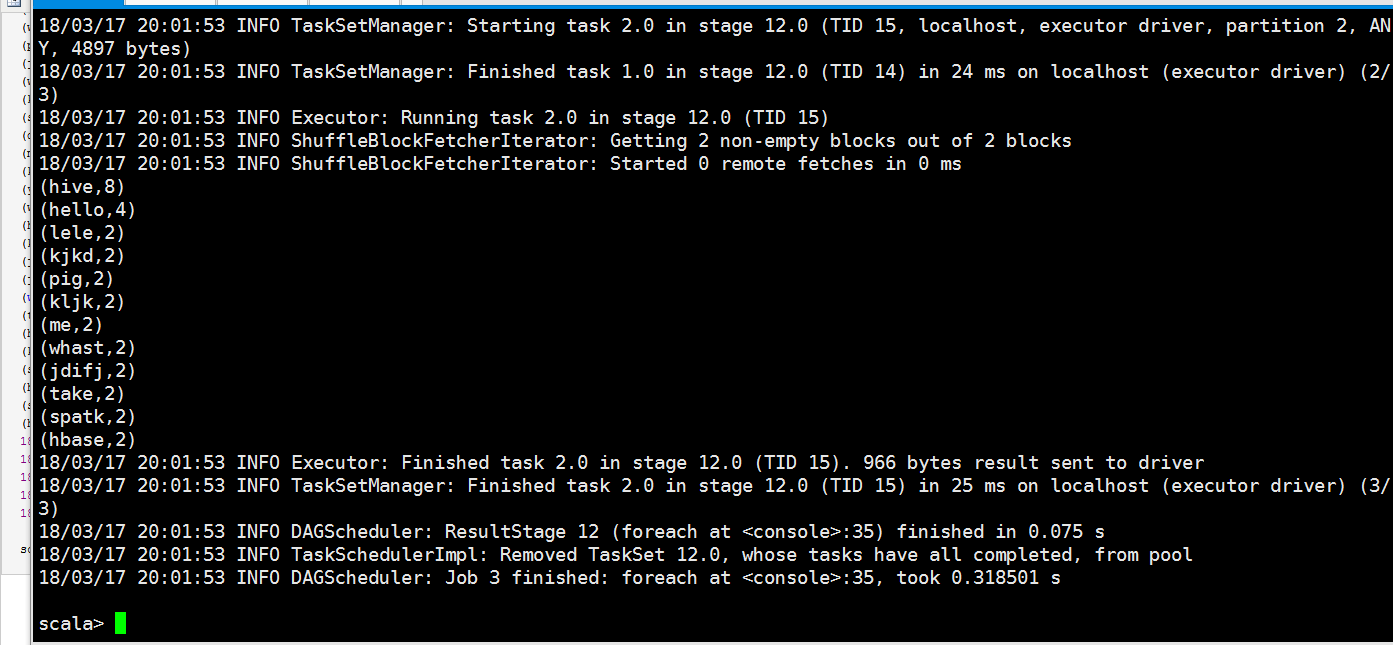
scala> lines.repartition()
res4: org.apache.spark.rdd.RDD[(String, Int)] = MapPartitionsRDD[] at repartition at <console>: scala> res4.foreach(println)
// :: INFO SparkContext: Starting job: foreach at <console>:
// :: INFO MapOutputTrackerMaster: Size of output statuses for shuffle is bytes
// :: INFO MapOutputTrackerMaster: Size of output statuses for shuffle is bytes
// :: INFO DAGScheduler: Registering RDD (repartition at <console>:)
// :: INFO DAGScheduler: Got job (foreach at <console>:) with output partitions
// :: INFO DAGScheduler: Final stage: ResultStage (foreach at <console>:)
// :: INFO DAGScheduler: Parents of final stage: List(ShuffleMapStage )
// :: INFO DAGScheduler: Missing parents: List(ShuffleMapStage )
// :: INFO DAGScheduler: Submitting ShuffleMapStage (MapPartitionsRDD[] at repartition at <console>:), which has no missing parents
// :: INFO MemoryStore: Block broadcast_8 stored as values in memory (estimated size 4.3 KB, free 413.4 MB)
// :: INFO MemoryStore: Block broadcast_8_piece0 stored as bytes in memory (estimated size 2.5 KB, free 413.4 MB)
// :: INFO BlockManagerInfo: Added broadcast_8_piece0 in memory on 192.168.86.151: (size: 2.5 KB, free: 413.9 MB)
// :: INFO SparkContext: Created broadcast from broadcast at DAGScheduler.scala:
// :: INFO DAGScheduler: Submitting missing tasks from ShuffleMapStage (MapPartitionsRDD[] at repartition at <console>:) (first tasks are for partitions Vector(, ))
// :: INFO TaskSchedulerImpl: Adding task set 11.0 with tasks
// :: INFO TaskSetManager: Starting task 0.0 in stage 11.0 (TID , localhost, executor driver, partition , ANY, bytes)
// :: INFO Executor: Running task 0.0 in stage 11.0 (TID )
// :: INFO ShuffleBlockFetcherIterator: Getting non-empty blocks out of blocks
// :: INFO ShuffleBlockFetcherIterator: Started remote fetches in ms
// :: INFO Executor: Finished task 0.0 in stage 11.0 (TID ). bytes result sent to driver
// :: INFO TaskSetManager: Starting task 1.0 in stage 11.0 (TID , localhost, executor driver, partition , ANY, bytes)
// :: INFO TaskSetManager: Finished task 0.0 in stage 11.0 (TID ) in ms on localhost (executor driver) (/)
// :: INFO Executor: Running task 1.0 in stage 11.0 (TID )
// :: INFO ShuffleBlockFetcherIterator: Getting non-empty blocks out of blocks
// :: INFO ShuffleBlockFetcherIterator: Started remote fetches in ms
// :: INFO Executor: Finished task 1.0 in stage 11.0 (TID ). bytes result sent to driver
// :: INFO TaskSetManager: Finished task 1.0 in stage 11.0 (TID ) in ms on localhost (executor driver) (/)
// :: INFO TaskSchedulerImpl: Removed TaskSet 11.0, whose tasks have all completed, from pool
// :: INFO DAGScheduler: ShuffleMapStage (repartition at <console>:) finished in 0.134 s
// :: INFO DAGScheduler: looking for newly runnable stages
// :: INFO DAGScheduler: running: Set()
// :: INFO DAGScheduler: waiting: Set(ResultStage )
// :: INFO DAGScheduler: failed: Set()
// :: INFO DAGScheduler: Submitting ResultStage (MapPartitionsRDD[] at repartition at <console>:), which has no missing parents
// :: INFO MemoryStore: Block broadcast_9 stored as values in memory (estimated size 3.3 KB, free 413.4 MB)
// :: INFO MemoryStore: Block broadcast_9_piece0 stored as bytes in memory (estimated size 1938.0 B, free 413.4 MB)
// :: INFO BlockManagerInfo: Added broadcast_9_piece0 in memory on 192.168.86.151: (size: 1938.0 B, free: 413.9 MB)
// :: INFO SparkContext: Created broadcast from broadcast at DAGScheduler.scala:
// :: INFO DAGScheduler: Submitting missing tasks from ResultStage (MapPartitionsRDD[] at repartition at <console>:) (first tasks are for partitions Vector(, , ))
// :: INFO TaskSchedulerImpl: Adding task set 12.0 with tasks
// :: INFO TaskSetManager: Starting task 0.0 in stage 12.0 (TID , localhost, executor driver, partition , ANY, bytes)
// :: INFO Executor: Running task 0.0 in stage 12.0 (TID )
// :: INFO ShuffleBlockFetcherIterator: Getting non-empty blocks out of blocks
// :: INFO ShuffleBlockFetcherIterator: Started remote fetches in ms
// :: INFO BlockManagerInfo: Removed broadcast_6_piece0 on 192.168.86.151: in memory (size: 2.5 KB, free: 413.9 MB)
(hadoop,)
(node,)
(bag,)
(tom,)
(jkji,)
(sqoop,)
(kjfklds,)
(he,)
(jack,)
(hjsdhj,)
(heeef,)
// :: INFO Executor: Finished task 0.0 in stage 12.0 (TID ). bytes result sent to driver
// :: INFO TaskSetManager: Starting task 1.0 in stage 12.0 (TID , localhost, executor driver, partition , ANY, bytes)
// :: INFO TaskSetManager: Finished task 0.0 in stage 12.0 (TID ) in ms on localhost (executor driver) (/)
// :: INFO Executor: Running task 1.0 in stage 12.0 (TID )
// :: INFO BlockManagerInfo: Removed broadcast_7_piece0 on 192.168.86.151: in memory (size: 1934.0 B, free: 413.9 MB)
// :: INFO ShuffleBlockFetcherIterator: Getting non-empty blocks out of blocks
// :: INFO ShuffleBlockFetcherIterator: Started remote fetches in ms
(mysql,)
(she,)
(eggg,)
(haad,)
(who,)
(word,)
(dag,)
(you,)
(kjdskf,)
(where,)
(kjskldjf,)
(spring,)
// :: INFO Executor: Finished task 1.0 in stage 12.0 (TID ). bytes result sent to driver
// :: INFO TaskSetManager: Starting task 2.0 in stage 12.0 (TID , localhost, executor driver, partition , ANY, bytes)
// :: INFO TaskSetManager: Finished task 1.0 in stage 12.0 (TID ) in ms on localhost (executor driver) (/)
// :: INFO Executor: Running task 2.0 in stage 12.0 (TID )
// :: INFO ShuffleBlockFetcherIterator: Getting non-empty blocks out of blocks
// :: INFO ShuffleBlockFetcherIterator: Started remote fetches in ms
(hive,)
(hello,)
(lele,)
(kjkd,)
(pig,)
(kljk,)
(me,)
(whast,)
(jdifj,)
(take,)
(spatk,)
(hbase,)
// :: INFO Executor: Finished task 2.0 in stage 12.0 (TID ). bytes result sent to driver
// :: INFO TaskSetManager: Finished task 2.0 in stage 12.0 (TID ) in ms on localhost (executor driver) (/)
// :: INFO DAGScheduler: ResultStage (foreach at <console>:) finished in 0.075 s
// :: INFO TaskSchedulerImpl: Removed TaskSet 12.0, whose tasks have all completed, from pool
// :: INFO DAGScheduler: Job finished: foreach at <console>:, took 0.318501 s scala>


老规矩,先启动spark-shell

我们还是把之前的都先执行一次
val rdd1=sc.textFile("file:///opt/datas/stu.txt")
val rdd2=sc.textFile("file:///opt/datas/stu1.txt")
val rdd=rdd1.union(rdd2)
val lines = rdd.flatMap(x=>x.split(" ")).map(x=>(x,)).reduceByKey((a,b)=>(a+b)).filter(x => (x._2>)).map(x=>(x._2,x._1)).sortByKey(false).map(x=>(x._2,x._1)).toDF
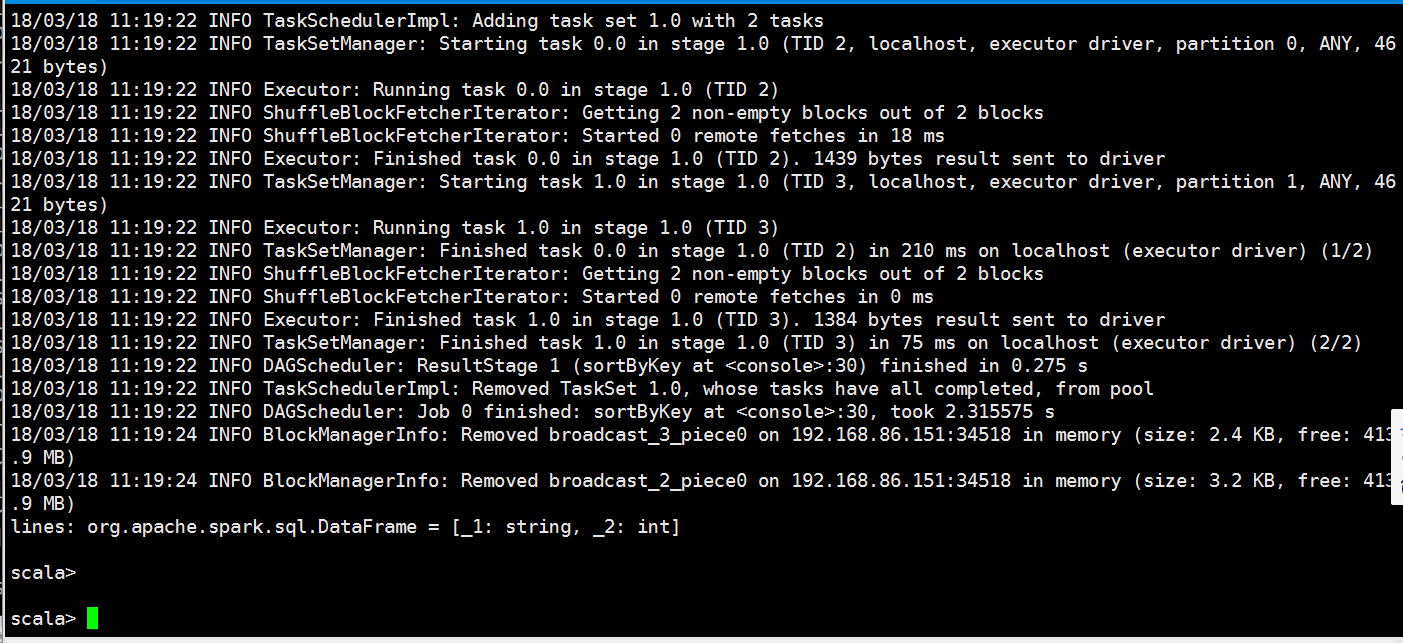
scala> val rdd1=sc.textFile("file:///opt/datas/stu.txt")
// :: INFO MemoryStore: Block broadcast_0 stored as values in memory (estimated size 229.9 KB, free 413.7 MB)
// :: INFO MemoryStore: Block broadcast_0_piece0 stored as bytes in memory (estimated size 21.4 KB, free 413.7 MB)
// :: INFO BlockManagerInfo: Added broadcast_0_piece0 in memory on 192.168.86.151: (size: 21.4 KB, free: 413.9 MB)
// :: INFO SparkContext: Created broadcast from textFile at <console>:
rdd1: org.apache.spark.rdd.RDD[String] = file:///opt/datas/stu.txt MapPartitionsRDD[1] at textFile at <console>:24
scala> val rdd2=sc.textFile("file:///opt/datas/stu1.txt")
// :: INFO MemoryStore: Block broadcast_1 stored as values in memory (estimated size 229.9 KB, free 413.5 MB)
// :: INFO MemoryStore: Block broadcast_1_piece0 stored as bytes in memory (estimated size 21.4 KB, free 413.4 MB)
// :: INFO BlockManagerInfo: Added broadcast_1_piece0 in memory on 192.168.86.151: (size: 21.4 KB, free: 413.9 MB)
// :: INFO SparkContext: Created broadcast from textFile at <console>:
rdd2: org.apache.spark.rdd.RDD[String] = file:///opt/datas/stu1.txt MapPartitionsRDD[3] at textFile at <console>:24
scala> val rdd=rdd1.union(rdd2)
rdd: org.apache.spark.rdd.RDD[String] = UnionRDD[] at union at <console>:
scala> val lines = rdd.flatMap(x=>x.split(" ")).map(x=>(x,)).reduceByKey((a,b)=>(a+b)).filter(x => (x._2>)).map(x=>(x._2,x._1)).sortByKey(false).map(x=>(x._2,x._1)).toDF
// :: INFO FileInputFormat: Total input paths to process :
// :: INFO FileInputFormat: Total input paths to process :
// :: INFO SparkContext: Starting job: sortByKey at <console>:
// :: INFO DAGScheduler: Registering RDD (map at <console>:)
// :: INFO DAGScheduler: Got job (sortByKey at <console>:) with output partitions
// :: INFO DAGScheduler: Final stage: ResultStage (sortByKey at <console>:)
// :: INFO DAGScheduler: Parents of final stage: List(ShuffleMapStage )
// :: INFO DAGScheduler: Missing parents: List(ShuffleMapStage )
// :: INFO DAGScheduler: Submitting ShuffleMapStage (MapPartitionsRDD[] at map at <console>:), which has no missing parents
// :: INFO MemoryStore: Block broadcast_2 stored as values in memory (estimated size 5.5 KB, free 413.4 MB)
// :: INFO MemoryStore: Block broadcast_2_piece0 stored as bytes in memory (estimated size 3.2 KB, free 413.4 MB)
// :: INFO BlockManagerInfo: Added broadcast_2_piece0 in memory on 192.168.86.151: (size: 3.2 KB, free: 413.9 MB)
// :: INFO SparkContext: Created broadcast from broadcast at DAGScheduler.scala:
// :: INFO DAGScheduler: Submitting missing tasks from ShuffleMapStage (MapPartitionsRDD[] at map at <console>:) (first tasks are for partitions Vector(, ))
// :: INFO TaskSchedulerImpl: Adding task set 0.0 with tasks
// :: INFO TaskSetManager: Starting task 0.0 in stage 0.0 (TID , localhost, executor driver, partition , PROCESS_LOCAL, bytes)
// :: INFO Executor: Running task 0.0 in stage 0.0 (TID )
// :: INFO HadoopRDD: Input split: file:/opt/datas/stu.txt:+
// :: INFO Executor: Finished task 0.0 in stage 0.0 (TID ). bytes result sent to driver
// :: INFO TaskSetManager: Starting task 1.0 in stage 0.0 (TID , localhost, executor driver, partition , PROCESS_LOCAL, bytes)
// :: INFO Executor: Running task 1.0 in stage 0.0 (TID )
// :: INFO HadoopRDD: Input split: file:/opt/datas/stu1.txt:+
// :: INFO TaskSetManager: Finished task 0.0 in stage 0.0 (TID ) in ms on localhost (executor driver) (/)
// :: INFO Executor: Finished task 1.0 in stage 0.0 (TID ). bytes result sent to driver
// :: INFO TaskSetManager: Finished task 1.0 in stage 0.0 (TID ) in ms on localhost (executor driver) (/)
// :: INFO DAGScheduler: ShuffleMapStage (map at <console>:) finished in 0.806 s
// :: INFO DAGScheduler: looking for newly runnable stages
// :: INFO DAGScheduler: running: Set()
// :: INFO DAGScheduler: waiting: Set(ResultStage )
// :: INFO TaskSchedulerImpl: Removed TaskSet 0.0, whose tasks have all completed, from pool
// :: INFO DAGScheduler: failed: Set()
// :: INFO DAGScheduler: Submitting ResultStage (MapPartitionsRDD[] at sortByKey at <console>:), which has no missing parents
// :: INFO MemoryStore: Block broadcast_3 stored as values in memory (estimated size 4.3 KB, free 413.4 MB)
// :: INFO MemoryStore: Block broadcast_3_piece0 stored as bytes in memory (estimated size 2.4 KB, free 413.4 MB)
// :: INFO BlockManagerInfo: Added broadcast_3_piece0 in memory on 192.168.86.151: (size: 2.4 KB, free: 413.9 MB)
// :: INFO SparkContext: Created broadcast from broadcast at DAGScheduler.scala:
// :: INFO DAGScheduler: Submitting missing tasks from ResultStage (MapPartitionsRDD[] at sortByKey at <console>:) (first tasks are for partitions Vector(, ))
// :: INFO TaskSchedulerImpl: Adding task set 1.0 with tasks
// :: INFO TaskSetManager: Starting task 0.0 in stage 1.0 (TID , localhost, executor driver, partition , ANY, bytes)
// :: INFO Executor: Running task 0.0 in stage 1.0 (TID )
// :: INFO ShuffleBlockFetcherIterator: Getting non-empty blocks out of blocks
// :: INFO ShuffleBlockFetcherIterator: Started remote fetches in ms
// :: INFO Executor: Finished task 0.0 in stage 1.0 (TID ). bytes result sent to driver
// :: INFO TaskSetManager: Starting task 1.0 in stage 1.0 (TID , localhost, executor driver, partition , ANY, bytes)
// :: INFO Executor: Running task 1.0 in stage 1.0 (TID )
// :: INFO TaskSetManager: Finished task 0.0 in stage 1.0 (TID ) in ms on localhost (executor driver) (/)
// :: INFO ShuffleBlockFetcherIterator: Getting non-empty blocks out of blocks
// :: INFO ShuffleBlockFetcherIterator: Started remote fetches in ms
// :: INFO Executor: Finished task 1.0 in stage 1.0 (TID ). bytes result sent to driver
// :: INFO TaskSetManager: Finished task 1.0 in stage 1.0 (TID ) in ms on localhost (executor driver) (/)
// :: INFO DAGScheduler: ResultStage (sortByKey at <console>:) finished in 0.275 s
// :: INFO TaskSchedulerImpl: Removed TaskSet 1.0, whose tasks have all completed, from pool
// :: INFO DAGScheduler: Job finished: sortByKey at <console>:, took 2.315575 s
// :: INFO BlockManagerInfo: Removed broadcast_3_piece0 on 192.168.86.151: in memory (size: 2.4 KB, free: 413.9 MB)
// :: INFO BlockManagerInfo: Removed broadcast_2_piece0 on 192.168.86.151: in memory (size: 3.2 KB, free: 413.9 MB)
lines: org.apache.spark.sql.DataFrame = [_1: string, _2: int]
scala>

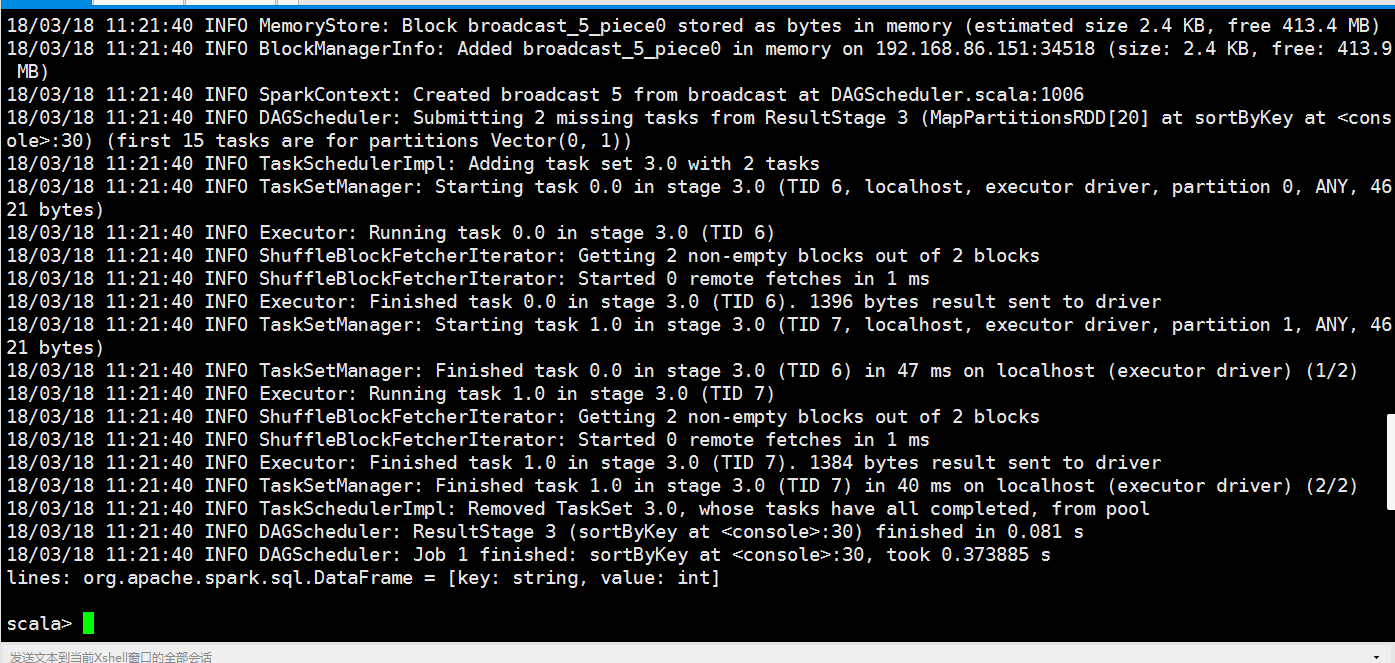
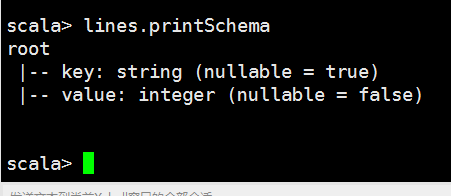



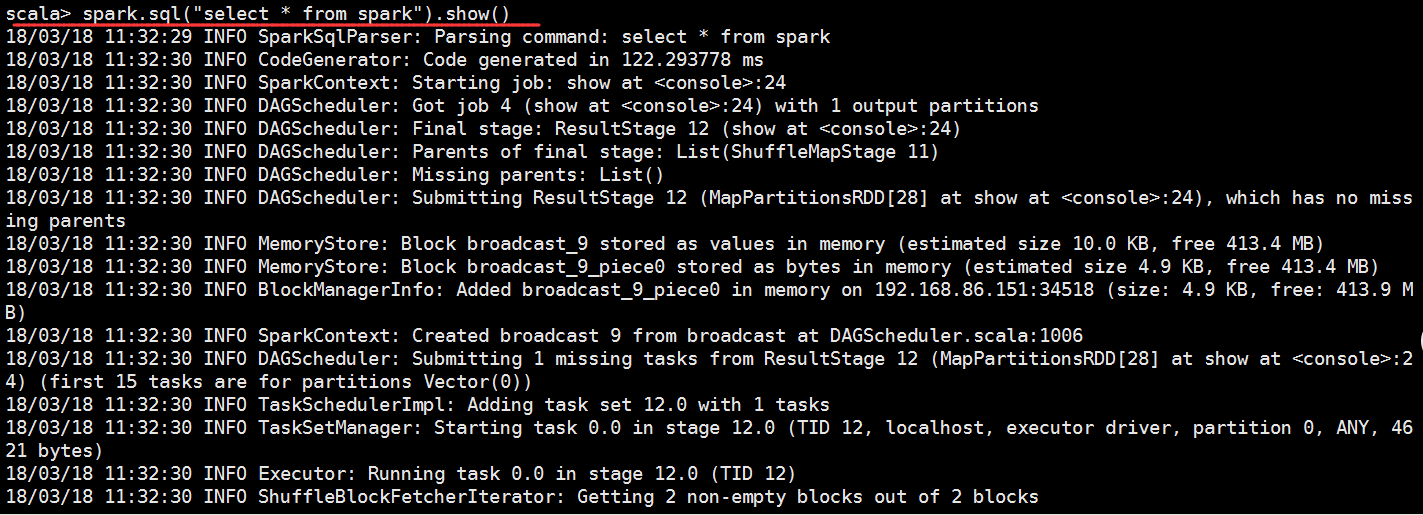
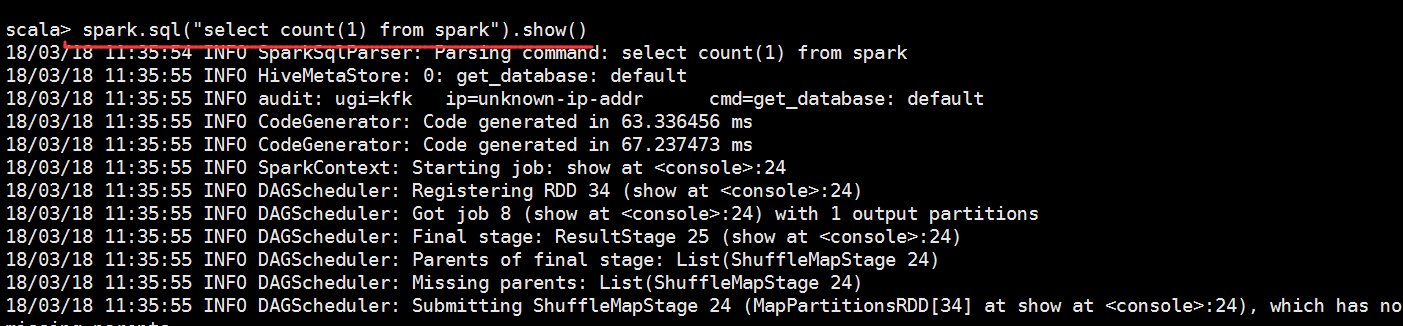
scala> lines.createOrReplaceTempView("spark")
// :: INFO SparkSqlParser: Parsing command: spark
// :: INFO ContextCleaner: Cleaned accumulator
// :: INFO BlockManagerInfo: Removed broadcast_6_piece0 on 192.168.86.151: in memory (size: 2.5 KB, free: 413.9 MB)
// :: INFO ContextCleaner: Cleaned accumulator
// :: INFO BlockManagerInfo: Removed broadcast_7_piece0 on 192.168.86.151: in memory (size: 4.7 KB, free: 413.9 MB)
// :: INFO BlockManagerInfo: Removed broadcast_8_piece0 on 192.168.86.151: in memory (size: 4.7 KB, free: 413.9 MB)
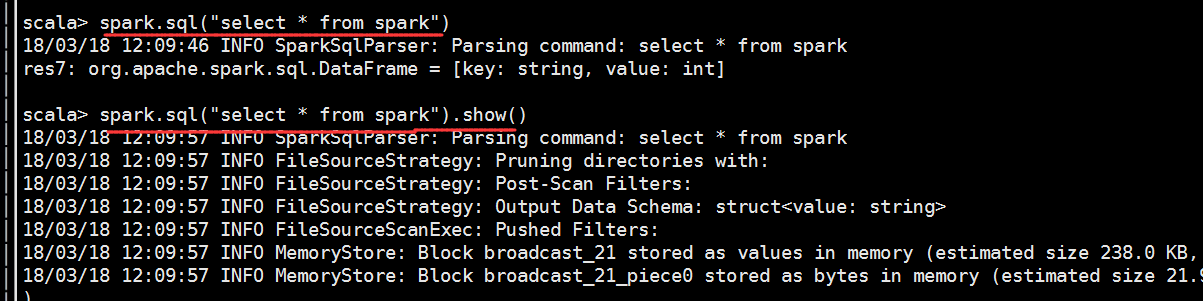
scala> spark.sql("select * from spark")
// :: INFO SparkSqlParser: Parsing command: select * from spark
res3: org.apache.spark.sql.DataFrame = [key: string, value: int]
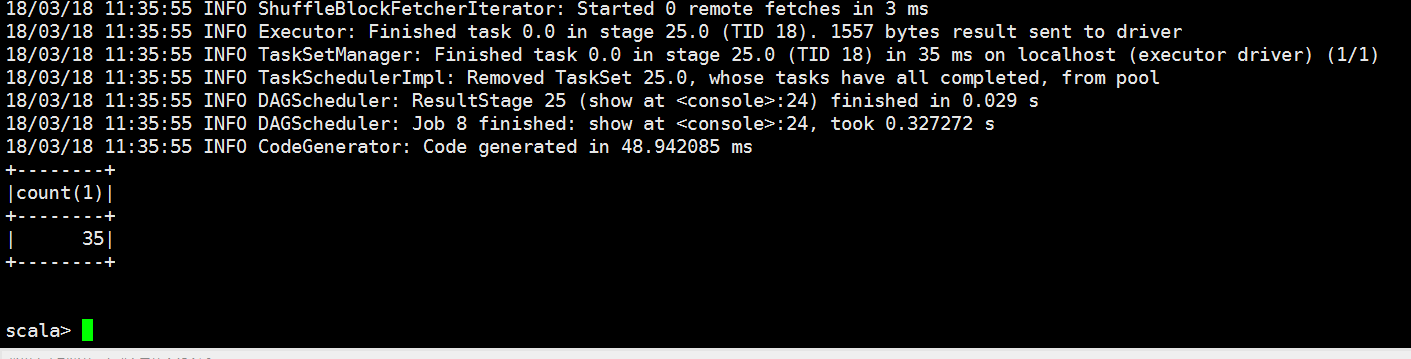
scala> spark.sql("select * from spark").show()
// :: INFO SparkSqlParser: Parsing command: select * from spark
// :: INFO CodeGenerator: Code generated in 122.293778 ms
// :: INFO SparkContext: Starting job: show at <console>:
// :: INFO DAGScheduler: Got job (show at <console>:) with output partitions
// :: INFO DAGScheduler: Final stage: ResultStage (show at <console>:)
// :: INFO DAGScheduler: Parents of final stage: List(ShuffleMapStage )
// :: INFO DAGScheduler: Missing parents: List()
// :: INFO DAGScheduler: Submitting ResultStage (MapPartitionsRDD[] at show at <console>:), which has no missing parents
// :: INFO MemoryStore: Block broadcast_9 stored as values in memory (estimated size 10.0 KB, free 413.4 MB)
// :: INFO MemoryStore: Block broadcast_9_piece0 stored as bytes in memory (estimated size 4.9 KB, free 413.4 MB)
// :: INFO BlockManagerInfo: Added broadcast_9_piece0 in memory on 192.168.86.151: (size: 4.9 KB, free: 413.9 MB)
// :: INFO SparkContext: Created broadcast from broadcast at DAGScheduler.scala:
// :: INFO DAGScheduler: Submitting missing tasks from ResultStage (MapPartitionsRDD[] at show at <console>:) (first tasks are for partitions Vector())
// :: INFO TaskSchedulerImpl: Adding task set 12.0 with tasks
// :: INFO TaskSetManager: Starting task 0.0 in stage 12.0 (TID , localhost, executor driver, partition , ANY, bytes)
// :: INFO Executor: Running task 0.0 in stage 12.0 (TID )
// :: INFO ShuffleBlockFetcherIterator: Getting non-empty blocks out of blocks
// :: INFO ShuffleBlockFetcherIterator: Started remote fetches in ms
// :: INFO Executor: Finished task 0.0 in stage 12.0 (TID ). bytes result sent to driver
// :: INFO TaskSetManager: Finished task 0.0 in stage 12.0 (TID ) in ms on localhost (executor driver) (/)
// :: INFO TaskSchedulerImpl: Removed TaskSet 12.0, whose tasks have all completed, from pool
// :: INFO DAGScheduler: ResultStage (show at <console>:) finished in 0.065 s
// :: INFO DAGScheduler: Job finished: show at <console>:, took 0.108798 s
// :: INFO SparkContext: Starting job: show at <console>:
// :: INFO DAGScheduler: Got job (show at <console>:) with output partitions
// :: INFO DAGScheduler: Final stage: ResultStage (show at <console>:)
// :: INFO DAGScheduler: Parents of final stage: List(ShuffleMapStage )
// :: INFO DAGScheduler: Missing parents: List()
// :: INFO DAGScheduler: Submitting ResultStage (MapPartitionsRDD[] at show at <console>:), which has no missing parents
// :: INFO MemoryStore: Block broadcast_10 stored as values in memory (estimated size 10.0 KB, free 413.4 MB)
// :: INFO MemoryStore: Block broadcast_10_piece0 stored as bytes in memory (estimated size 4.9 KB, free 413.4 MB)
// :: INFO BlockManagerInfo: Added broadcast_10_piece0 in memory on 192.168.86.151: (size: 4.9 KB, free: 413.9 MB)
// :: INFO SparkContext: Created broadcast from broadcast at DAGScheduler.scala:
// :: INFO DAGScheduler: Submitting missing tasks from ResultStage (MapPartitionsRDD[] at show at <console>:) (first tasks are for partitions Vector())
// :: INFO TaskSchedulerImpl: Adding task set 15.0 with tasks
// :: INFO TaskSetManager: Starting task 0.0 in stage 15.0 (TID , localhost, executor driver, partition , ANY, bytes)
// :: INFO Executor: Running task 0.0 in stage 15.0 (TID )
// :: INFO ShuffleBlockFetcherIterator: Getting non-empty blocks out of blocks
// :: INFO ShuffleBlockFetcherIterator: Started remote fetches in ms
// :: INFO Executor: Finished task 0.0 in stage 15.0 (TID ). bytes result sent to driver
// :: INFO TaskSetManager: Finished task 0.0 in stage 15.0 (TID ) in ms on localhost (executor driver) (/)
// :: INFO TaskSchedulerImpl: Removed TaskSet 15.0, whose tasks have all completed, from pool
// :: INFO DAGScheduler: ResultStage (show at <console>:) finished in 0.046 s
// :: INFO DAGScheduler: Job finished: show at <console>:, took 0.084031 s
// :: INFO CodeGenerator: Code generated in 47.514407 ms
+------+-----+
| key|value|
+------+-----+
| mysql| |
| hive| |
|hadoop| |
| she| |
| hello| |
| node| |
| eggg| |
| lele| |
| bag| |
| haad| |
| kjkd| |
| tom| |
| who| |
| pig| |
| jkji| |
| word| |
| kljk| |
| sqoop| |
| dag| |
| me| |
+------+-----+
only showing top rows
scala>


scala> spark.sql("select key from spark").show()
// :: INFO ContextCleaner: Cleaned accumulator
// :: INFO BlockManagerInfo: Removed broadcast_9_piece0 on 192.168.86.151: in memory (size: 4.9 KB, free: 413.9 MB)
// :: INFO SparkSqlParser: Parsing command: select key from spark
// :: INFO ContextCleaner: Cleaned accumulator
// :: INFO BlockManagerInfo: Removed broadcast_10_piece0 on 192.168.86.151: in memory (size: 4.9 KB, free: 413.9 MB)
// :: INFO SparkContext: Starting job: show at <console>:
// :: INFO DAGScheduler: Got job (show at <console>:) with output partitions
// :: INFO DAGScheduler: Final stage: ResultStage (show at <console>:)
// :: INFO DAGScheduler: Parents of final stage: List(ShuffleMapStage )
// :: INFO DAGScheduler: Missing parents: List()
// :: INFO DAGScheduler: Submitting ResultStage (MapPartitionsRDD[] at show at <console>:), which has no missing parents
// :: INFO MemoryStore: Block broadcast_11 stored as values in memory (estimated size 9.4 KB, free 413.4 MB)
// :: INFO MemoryStore: Block broadcast_11_piece0 stored as bytes in memory (estimated size 4.7 KB, free 413.4 MB)
// :: INFO BlockManagerInfo: Added broadcast_11_piece0 in memory on 192.168.86.151: (size: 4.7 KB, free: 413.9 MB)
// :: INFO SparkContext: Created broadcast from broadcast at DAGScheduler.scala:
// :: INFO DAGScheduler: Submitting missing tasks from ResultStage (MapPartitionsRDD[] at show at <console>:) (first tasks are for partitions Vector())
// :: INFO TaskSchedulerImpl: Adding task set 18.0 with tasks
// :: INFO TaskSetManager: Starting task 0.0 in stage 18.0 (TID , localhost, executor driver, partition , ANY, bytes)
// :: INFO Executor: Running task 0.0 in stage 18.0 (TID )
// :: INFO ShuffleBlockFetcherIterator: Getting non-empty blocks out of blocks
// :: INFO ShuffleBlockFetcherIterator: Started remote fetches in ms
// :: INFO Executor: Finished task 0.0 in stage 18.0 (TID ). bytes result sent to driver
// :: INFO TaskSetManager: Finished task 0.0 in stage 18.0 (TID ) in ms on localhost (executor driver) (/)
// :: INFO DAGScheduler: ResultStage (show at <console>:) finished in 0.051 s
// :: INFO DAGScheduler: Job finished: show at <console>:, took 0.080995 s
// :: INFO TaskSchedulerImpl: Removed TaskSet 18.0, whose tasks have all completed, from pool
// :: INFO SparkContext: Starting job: show at <console>:
// :: INFO DAGScheduler: Got job (show at <console>:) with output partitions
// :: INFO DAGScheduler: Final stage: ResultStage (show at <console>:)
// :: INFO DAGScheduler: Parents of final stage: List(ShuffleMapStage )
// :: INFO DAGScheduler: Missing parents: List()
// :: INFO DAGScheduler: Submitting ResultStage (MapPartitionsRDD[] at show at <console>:), which has no missing parents
// :: INFO MemoryStore: Block broadcast_12 stored as values in memory (estimated size 9.4 KB, free 413.4 MB)
// :: INFO MemoryStore: Block broadcast_12_piece0 stored as bytes in memory (estimated size 4.7 KB, free 413.4 MB)
// :: INFO BlockManagerInfo: Added broadcast_12_piece0 in memory on 192.168.86.151: (size: 4.7 KB, free: 413.9 MB)
// :: INFO SparkContext: Created broadcast from broadcast at DAGScheduler.scala:
// :: INFO DAGScheduler: Submitting missing tasks from ResultStage (MapPartitionsRDD[] at show at <console>:) (first tasks are for partitions Vector())
// :: INFO TaskSchedulerImpl: Adding task set 21.0 with tasks
// :: INFO TaskSetManager: Starting task 0.0 in stage 21.0 (TID , localhost, executor driver, partition , ANY, bytes)
// :: INFO Executor: Running task 0.0 in stage 21.0 (TID )
// :: INFO ShuffleBlockFetcherIterator: Getting non-empty blocks out of blocks
// :: INFO ShuffleBlockFetcherIterator: Started remote fetches in ms
// :: INFO Executor: Finished task 0.0 in stage 21.0 (TID ). bytes result sent to driver
// :: INFO TaskSetManager: Finished task 0.0 in stage 21.0 (TID ) in ms on localhost (executor driver) (/)
// :: INFO DAGScheduler: ResultStage (show at <console>:) finished in 0.053 s
// :: INFO DAGScheduler: Job finished: show at <console>:, took 0.096304 s
// :: INFO TaskSchedulerImpl: Removed TaskSet 21.0, whose tasks have all completed, from pool
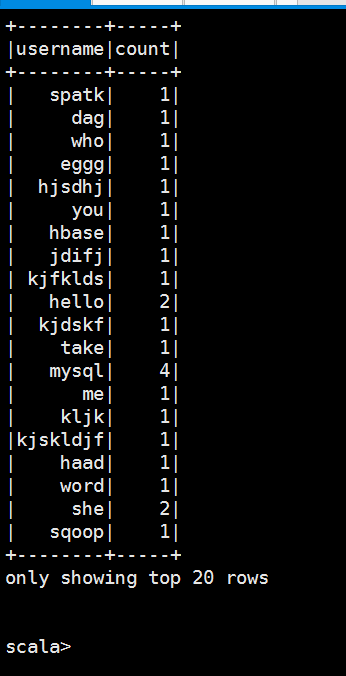
+------+
| key|
+------+
| mysql|
| hive|
|hadoop|
| she|
| hello|
| node|
| eggg|
| lele|
| bag|
| haad|
| kjkd|
| tom|
| who|
| pig|
| jkji|
| word|
| kljk|
| sqoop|
| dag|
| me|
+------+
only showing top rows
scala>

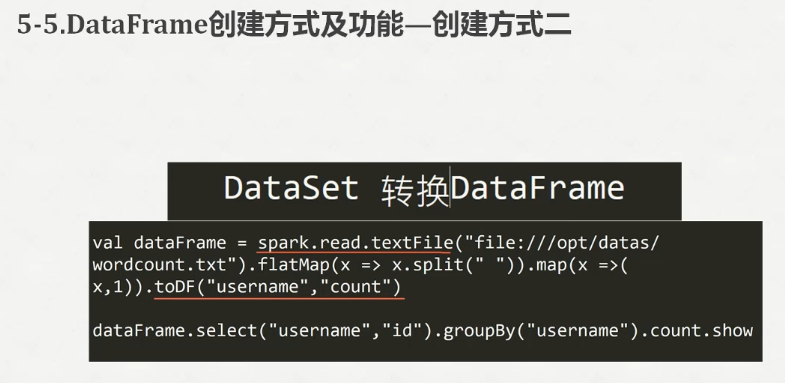

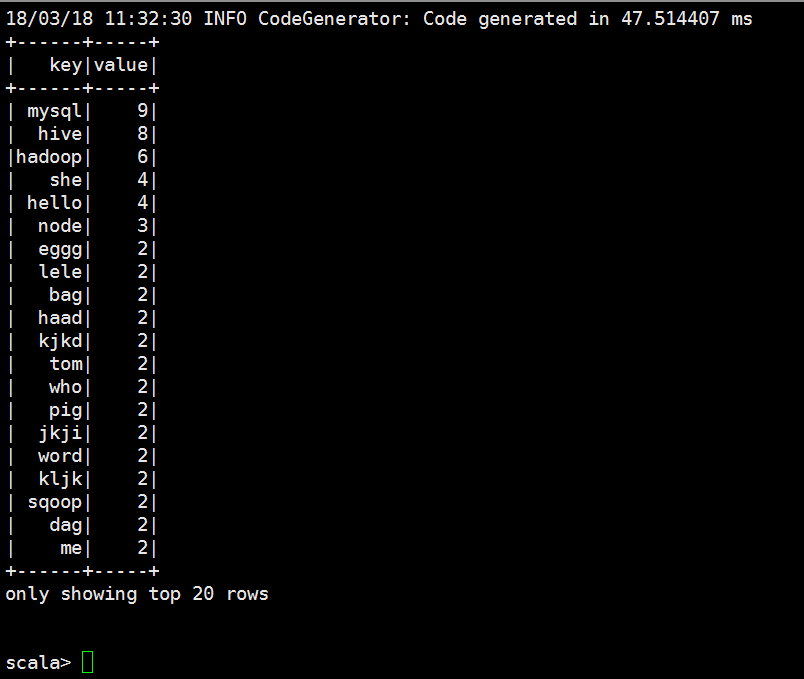
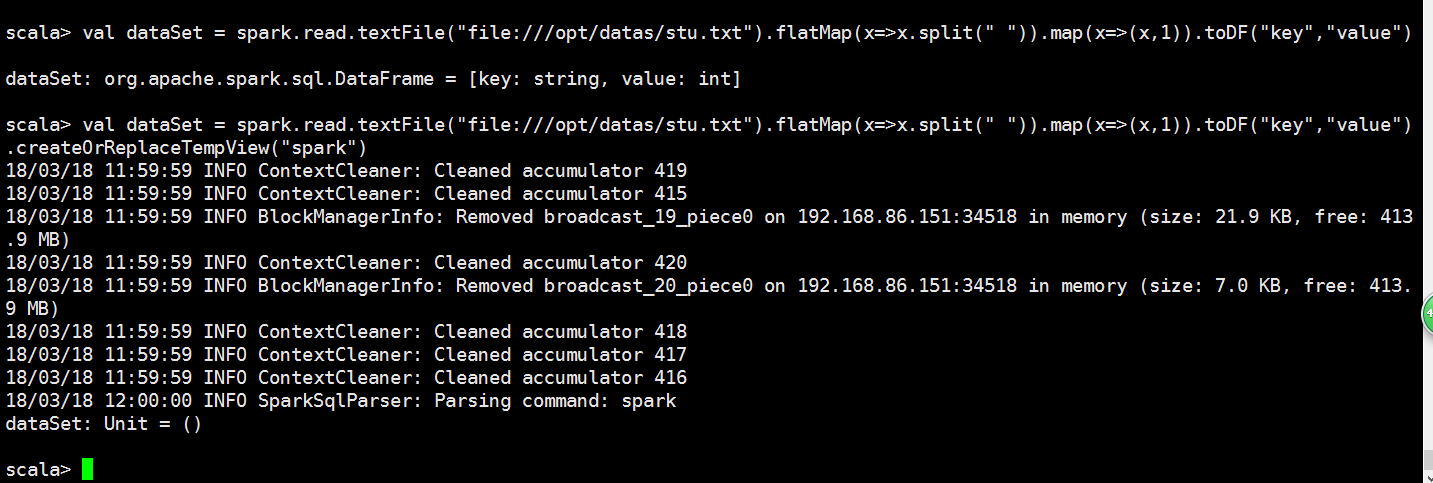
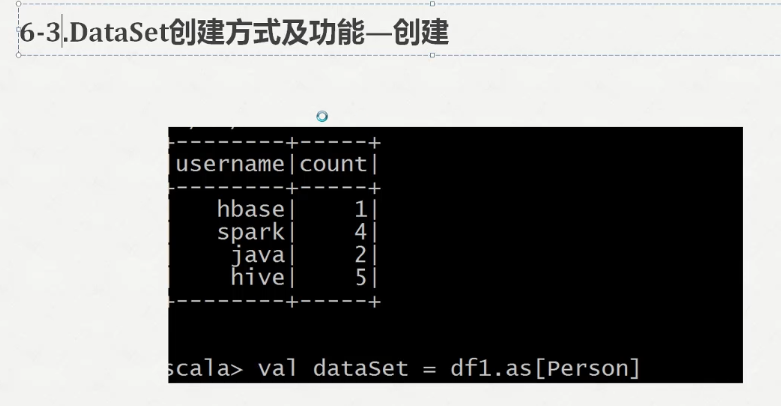
scala> val dataSet = spark.read.textFile("file:///opt/datas/stu.txt")
dataSet: org.apache.spark.sql.Dataset[String] = [value: string]
scala> val dataSet = spark.read.textFile("file:///opt/datas/stu.txt").flatMap(x=>x.split(" ")).map(x=>(x,))
dataSet: org.apache.spark.sql.Dataset[(String, Int)] = [_1: string, _2: int]
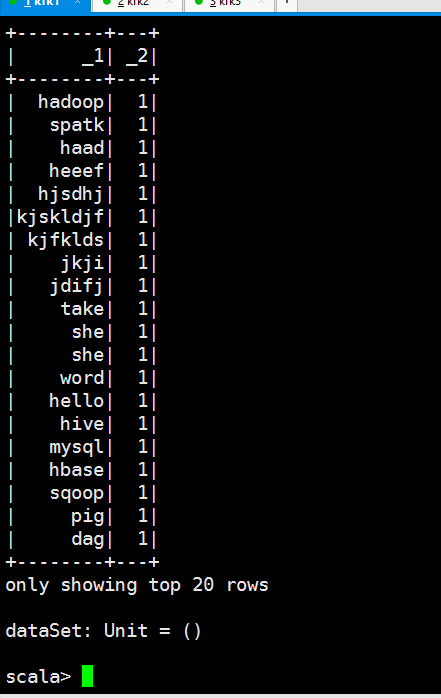




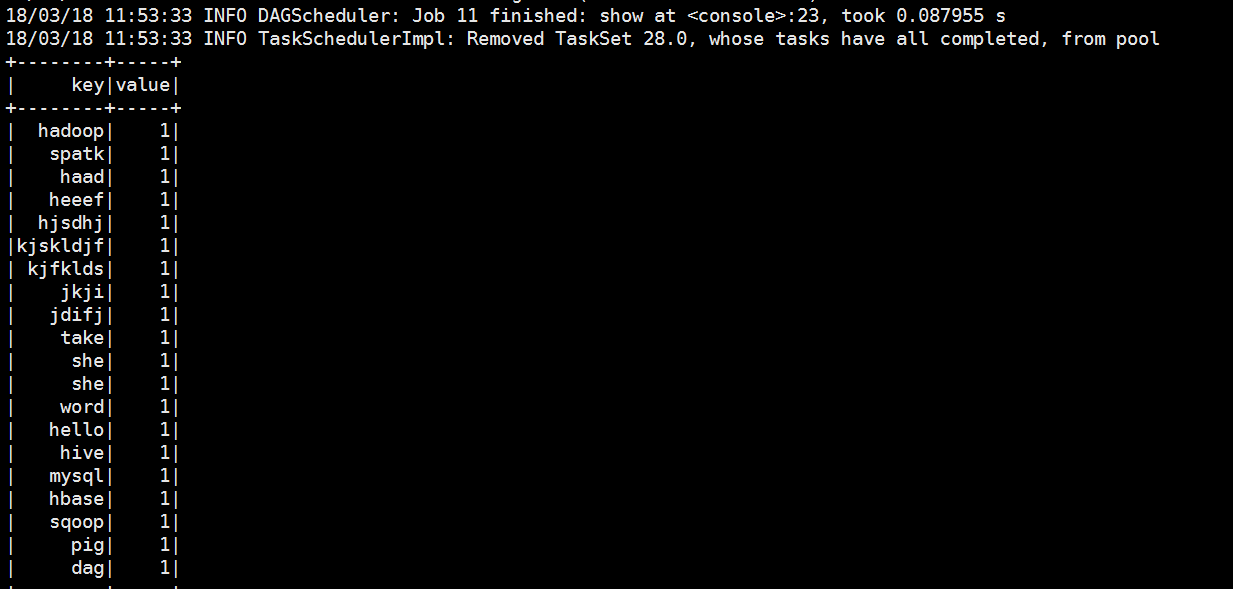
scala> val dataSet = spark.read.textFile("file:///opt/datas/stu.txt").flatMap(x=>x.split(" ")).map(x=>(x,)).toDF("key","value")
dataSet: org.apache.spark.sql.DataFrame = [key: string, value: int]
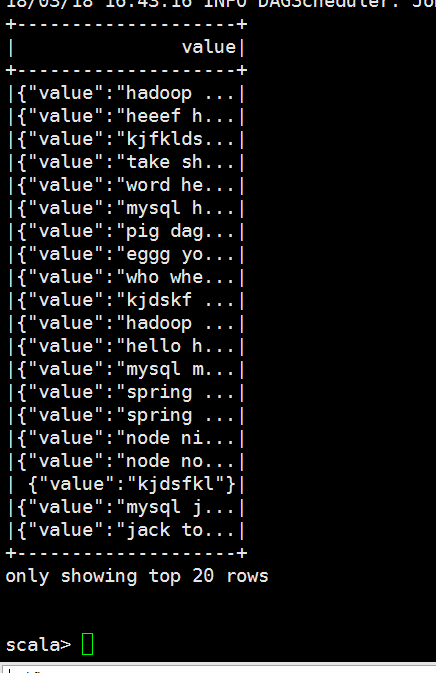
scala> val dataSet = spark.read.textFile("file:///opt/datas/stu.txt").flatMap(x=>x.split(" ")).map(x=>(x,)).toDF("key","value").show()
// :: INFO ContextCleaner: Cleaned accumulator
// :: INFO BlockManagerInfo: Removed broadcast_17_piece0 on 192.168.86.151: in memory (size: 21.9 KB, free: 413.9 MB)
// :: INFO ContextCleaner: Cleaned accumulator
// :: INFO BlockManagerInfo: Removed broadcast_18_piece0 on 192.168.86.151: in memory (size: 7.0 KB, free: 413.9 MB)
// :: INFO ContextCleaner: Cleaned accumulator
// :: INFO ContextCleaner: Cleaned accumulator
// :: INFO ContextCleaner: Cleaned accumulator
// :: INFO ContextCleaner: Cleaned accumulator
// :: INFO FileSourceStrategy: Pruning directories with:
// :: INFO FileSourceStrategy: Post-Scan Filters:
// :: INFO FileSourceStrategy: Output Data Schema: struct<value: string>
// :: INFO FileSourceScanExec: Pushed Filters:
// :: INFO CodeGenerator: Code generated in 108.532527 ms
// :: INFO MemoryStore: Block broadcast_19 stored as values in memory (estimated size 238.0 KB, free 413.2 MB)
// :: INFO MemoryStore: Block broadcast_19_piece0 stored as bytes in memory (estimated size 21.9 KB, free 413.2 MB)
// :: INFO BlockManagerInfo: Added broadcast_19_piece0 in memory on 192.168.86.151: (size: 21.9 KB, free: 413.9 MB)
// :: INFO SparkContext: Created broadcast from show at <console>:
// :: INFO FileSourceScanExec: Planning scan with bin packing, max size: bytes, open cost is considered as scanning bytes.
// :: INFO SparkContext: Starting job: show at <console>:
// :: INFO DAGScheduler: Got job (show at <console>:) with output partitions
// :: INFO DAGScheduler: Final stage: ResultStage (show at <console>:)
// :: INFO DAGScheduler: Parents of final stage: List()
// :: INFO DAGScheduler: Missing parents: List()
// :: INFO DAGScheduler: Submitting ResultStage (MapPartitionsRDD[] at show at <console>:), which has no missing parents
// :: INFO MemoryStore: Block broadcast_20 stored as values in memory (estimated size 16.0 KB, free 413.2 MB)
// :: INFO MemoryStore: Block broadcast_20_piece0 stored as bytes in memory (estimated size 7.0 KB, free 413.2 MB)
// :: INFO BlockManagerInfo: Added broadcast_20_piece0 in memory on 192.168.86.151: (size: 7.0 KB, free: 413.9 MB)
// :: INFO SparkContext: Created broadcast from broadcast at DAGScheduler.scala:
// :: INFO DAGScheduler: Submitting missing tasks from ResultStage (MapPartitionsRDD[] at show at <console>:) (first tasks are for partitions Vector())
// :: INFO TaskSchedulerImpl: Adding task set 28.0 with tasks
// :: INFO TaskSetManager: Starting task 0.0 in stage 28.0 (TID , localhost, executor driver, partition , PROCESS_LOCAL, bytes)
// :: INFO Executor: Running task 0.0 in stage 28.0 (TID )
// :: INFO FileScanRDD: Reading File path: file:///opt/datas/stu.txt, range: 0-216, partition values: [empty row]
// :: INFO Executor: Finished task 0.0 in stage 28.0 (TID ). bytes result sent to driver
// :: INFO TaskSetManager: Finished task 0.0 in stage 28.0 (TID ) in ms on localhost (executor driver) (/)
// :: INFO DAGScheduler: ResultStage (show at <console>:) finished in 0.049 s
// :: INFO DAGScheduler: Job finished: show at <console>:, took 0.087955 s
// :: INFO TaskSchedulerImpl: Removed TaskSet 28.0, whose tasks have all completed, from pool
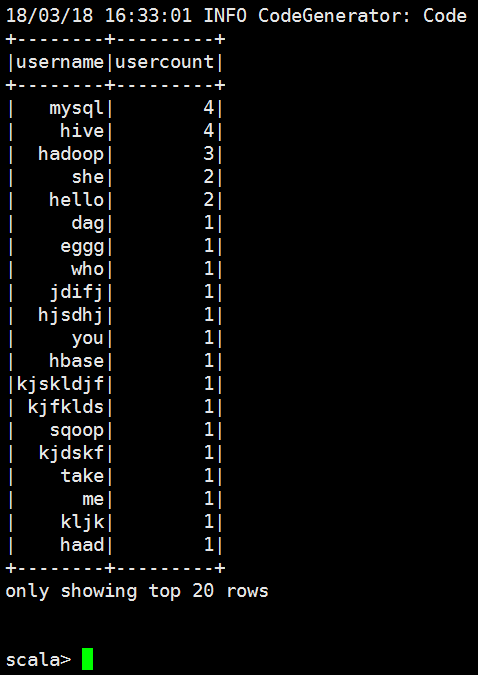
+--------+-----+
| key|value|
+--------+-----+
| hadoop| |
| spatk| |
| haad| |
| heeef| |
| hjsdhj| |
|kjskldjf| |
| kjfklds| |
| jkji| |
| jdifj| |
| take| |
| she| |
| she| |
| word| |
| hello| |
| hive| |
| mysql| |
| hbase| |
| sqoop| |
| pig| |
| dag| |
+--------+-----+
only showing top rows
dataSet: Unit = ()
scala>
scala> val dataSet = spark.read.textFile("file:///opt/datas/stu.txt").flatMap(x=>x.split(" ")).map(x=>(x,)).toDF("key","value")
dataSet: org.apache.spark.sql.DataFrame = [key: string, value: int]
scala> val dataSet = spark.read.textFile("file:///opt/datas/stu.txt").flatMap(x=>x.split(" ")).map(x=>(x,)).toDF("key","value")
.createOrReplaceTempView("spark")
// :: INFO ContextCleaner: Cleaned accumulator
// :: INFO ContextCleaner: Cleaned accumulator
// :: INFO BlockManagerInfo: Removed broadcast_19_piece0 on 192.168.86.151: in memory (size: 21.9 KB, free: 413.9 MB)
// :: INFO ContextCleaner: Cleaned accumulator
// :: INFO BlockManagerInfo: Removed broadcast_20_piece0 on 192.168.86.151: in memory (size: 7.0 KB, free: 413.9 MB)
// :: INFO ContextCleaner: Cleaned accumulator
// :: INFO ContextCleaner: Cleaned accumulator
// :: INFO ContextCleaner: Cleaned accumulator
// :: INFO SparkSqlParser: Parsing command: spark
dataSet: Unit = ()
scala>

scala> spark.sql("select * from spark")
// :: INFO SparkSqlParser: Parsing command: select * from spark
res7: org.apache.spark.sql.DataFrame = [key: string, value: int]
scala> spark.sql("select * from spark").show()
// :: INFO SparkSqlParser: Parsing command: select * from spark
// :: INFO FileSourceStrategy: Pruning directories with:
// :: INFO FileSourceStrategy: Post-Scan Filters:
// :: INFO FileSourceStrategy: Output Data Schema: struct<value: string>
// :: INFO FileSourceScanExec: Pushed Filters:
// :: INFO MemoryStore: Block broadcast_21 stored as values in memory (estimated size 238.0 KB, free 413.2 MB)
// :: INFO MemoryStore: Block broadcast_21_piece0 stored as bytes in memory (estimated size 21.9 KB, free 413.2 MB)
// :: INFO BlockManagerInfo: Added broadcast_21_piece0 in memory on 192.168.86.151: (size: 21.9 KB, free: 413.9 MB)
// :: INFO SparkContext: Created broadcast from show at <console>:
// :: INFO FileSourceScanExec: Planning scan with bin packing, max size: bytes, open cost is considered as scanning bytes.
// :: INFO SparkContext: Starting job: show at <console>:
// :: INFO DAGScheduler: Got job (show at <console>:) with output partitions
// :: INFO DAGScheduler: Final stage: ResultStage (show at <console>:)
// :: INFO DAGScheduler: Parents of final stage: List()
// :: INFO DAGScheduler: Missing parents: List()
// :: INFO DAGScheduler: Submitting ResultStage (MapPartitionsRDD[] at show at <console>:), which has no missing parents
// :: INFO MemoryStore: Block broadcast_22 stored as values in memory (estimated size 16.0 KB, free 413.2 MB)
// :: INFO MemoryStore: Block broadcast_22_piece0 stored as bytes in memory (estimated size 7.0 KB, free 413.2 MB)
// :: INFO BlockManagerInfo: Added broadcast_22_piece0 in memory on 192.168.86.151: (size: 7.0 KB, free: 413.9 MB)
// :: INFO SparkContext: Created broadcast from broadcast at DAGScheduler.scala:
// :: INFO DAGScheduler: Submitting missing tasks from ResultStage (MapPartitionsRDD[] at show at <console>:) (first tasks are for partitions Vector())
// :: INFO TaskSchedulerImpl: Adding task set 29.0 with tasks
// :: INFO TaskSetManager: Starting task 0.0 in stage 29.0 (TID , localhost, executor driver, partition , PROCESS_LOCAL, bytes)
// :: INFO Executor: Running task 0.0 in stage 29.0 (TID )
// :: INFO FileScanRDD: Reading File path: file:///opt/datas/stu.txt, range: 0-216, partition values: [empty row]
// :: INFO Executor: Finished task 0.0 in stage 29.0 (TID ). bytes result sent to driver
// :: INFO TaskSetManager: Finished task 0.0 in stage 29.0 (TID ) in ms on localhost (executor driver) (/)
// :: INFO TaskSchedulerImpl: Removed TaskSet 29.0, whose tasks have all completed, from pool
// :: INFO DAGScheduler: ResultStage (show at <console>:) finished in 0.050 s
// :: INFO DAGScheduler: Job finished: show at <console>:, took 0.083076 s
+--------+-----+
| key|value|
+--------+-----+
| hadoop| |
| spatk| |
| haad| |
| heeef| |
| hjsdhj| |
|kjskldjf| |
| kjfklds| |
| jkji| |
| jdifj| |
| take| |
| she| |
| she| |
| word| |
| hello| |
| hive| |
| mysql| |
| hbase| |
| sqoop| |
| pig| |
| dag| |
+--------+-----+
only showing top rows
scala>

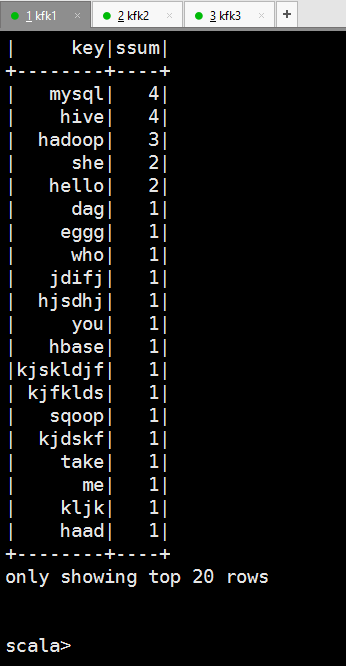

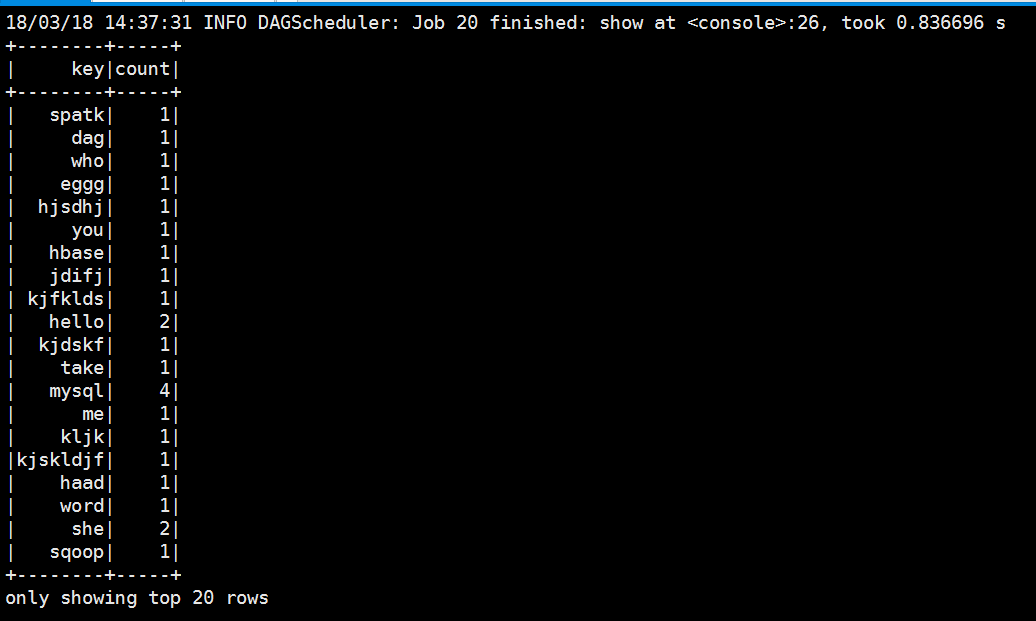



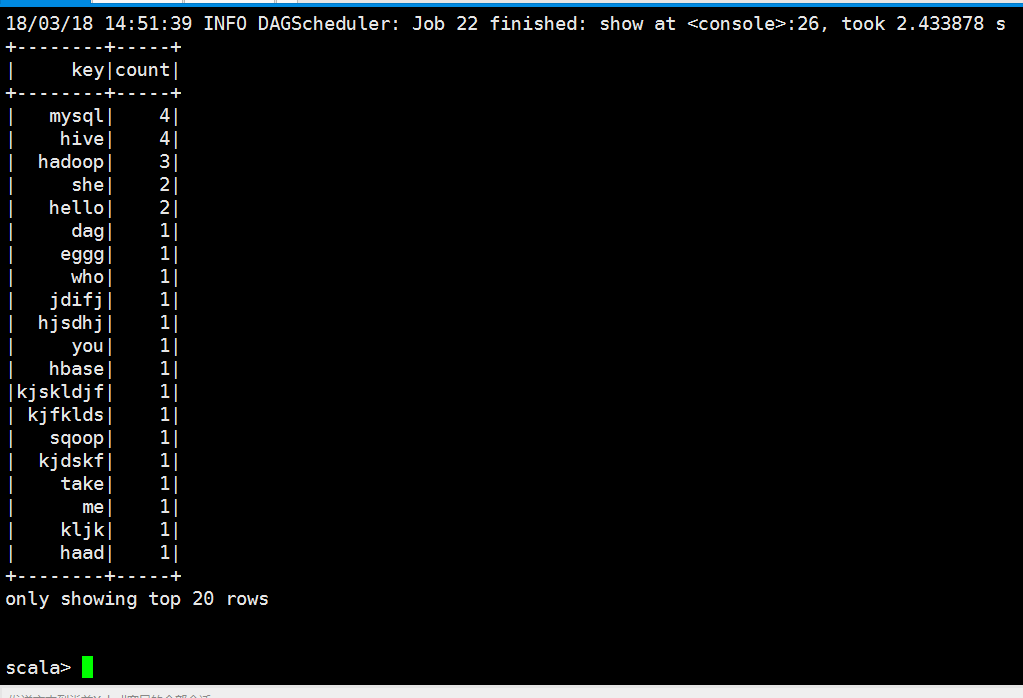

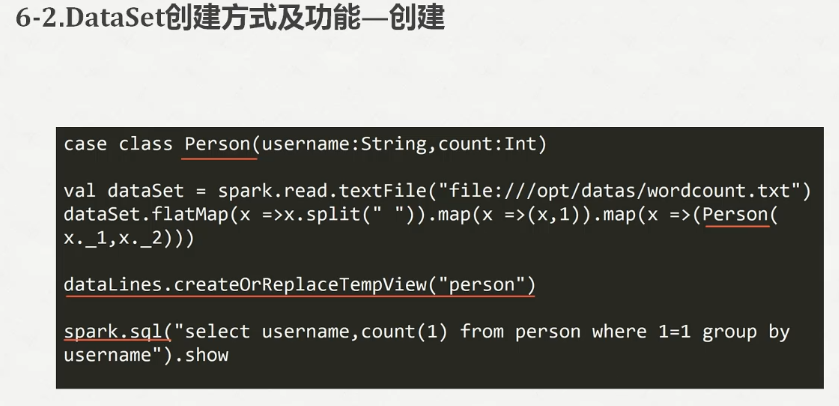
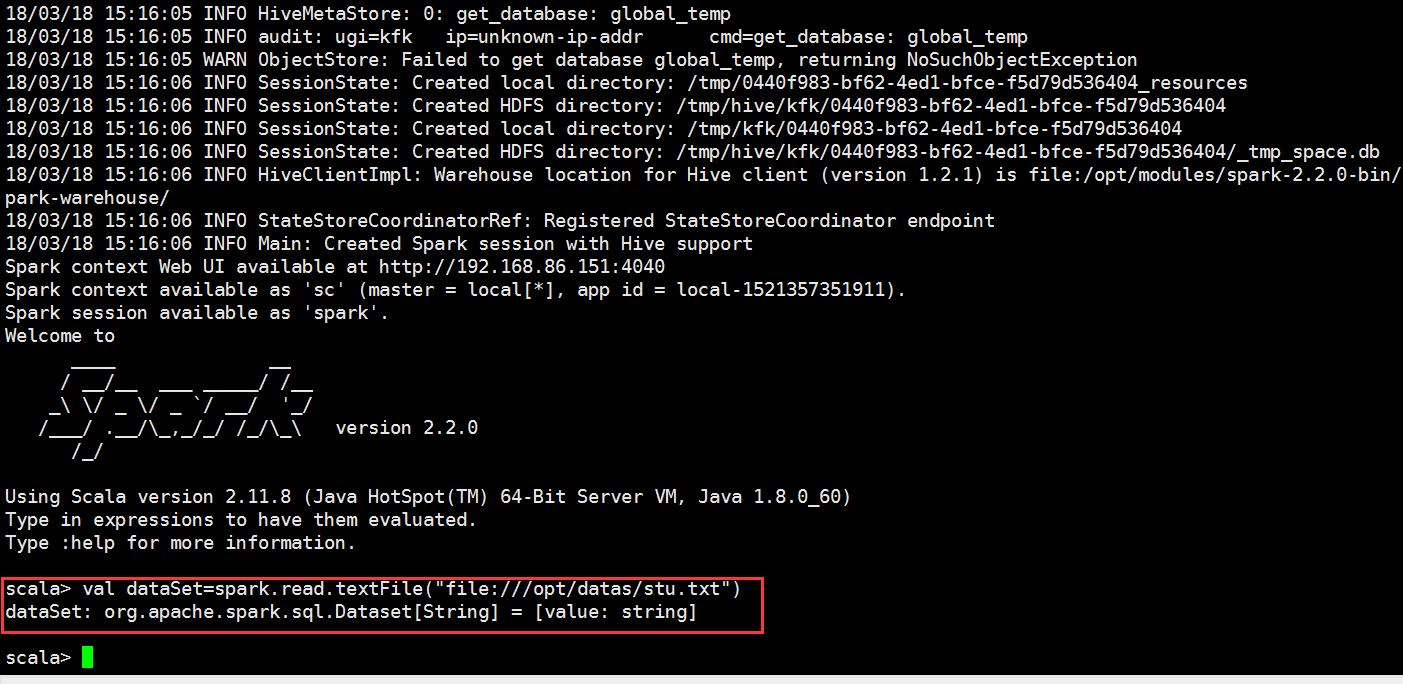



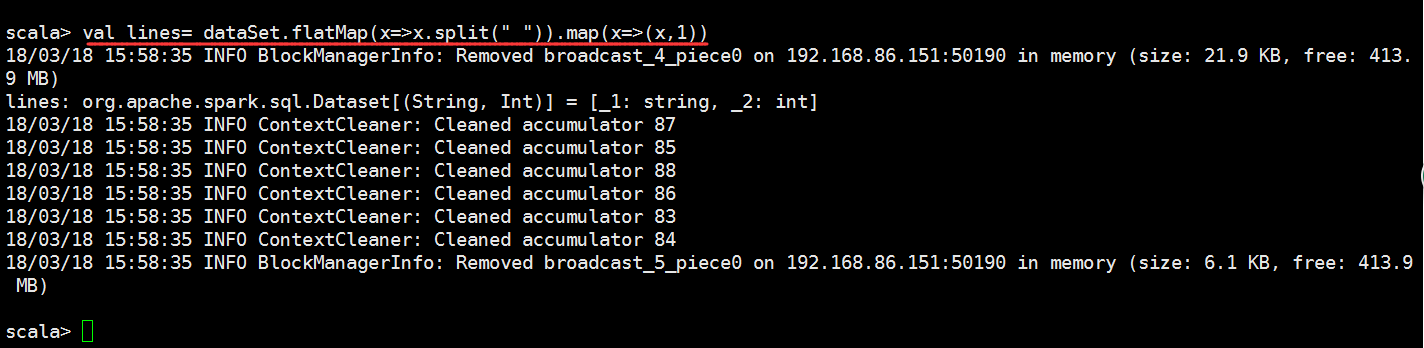

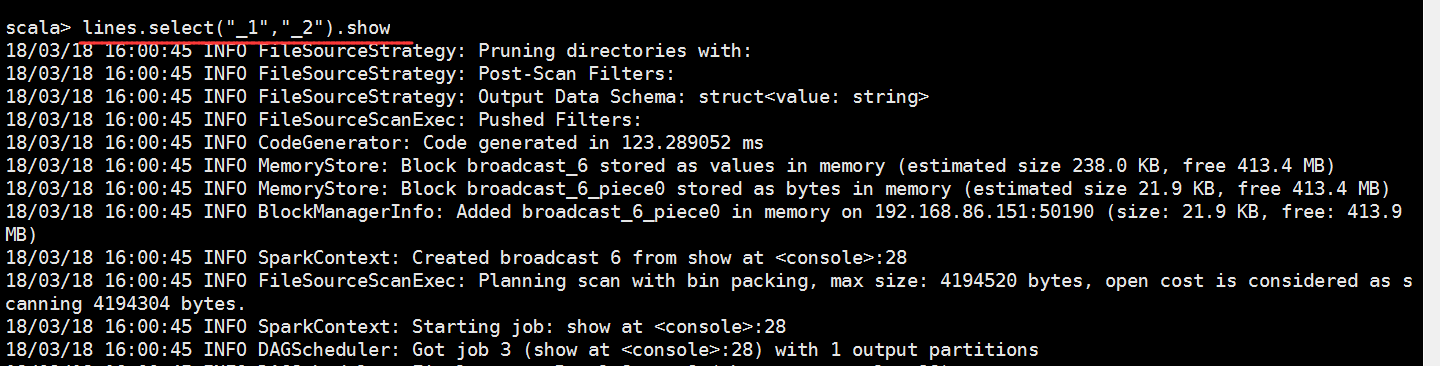
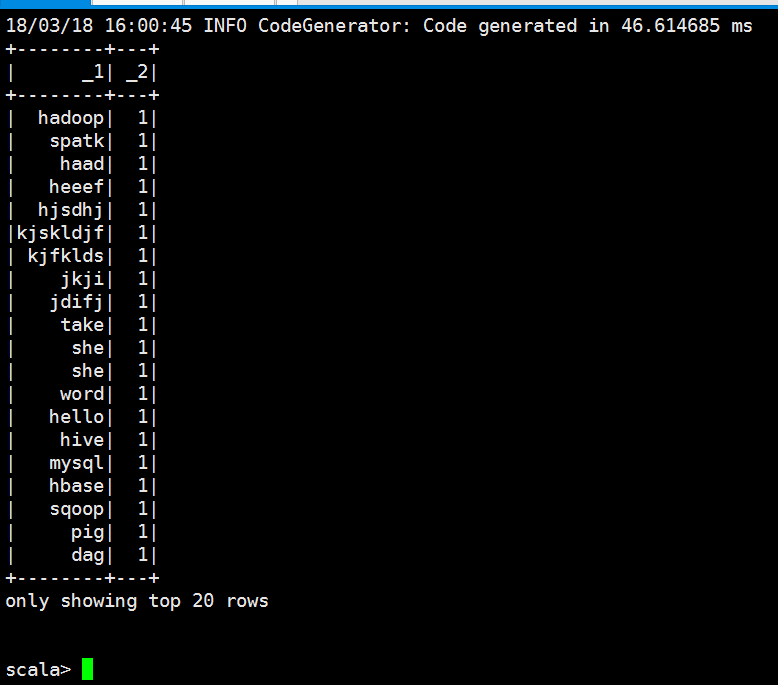
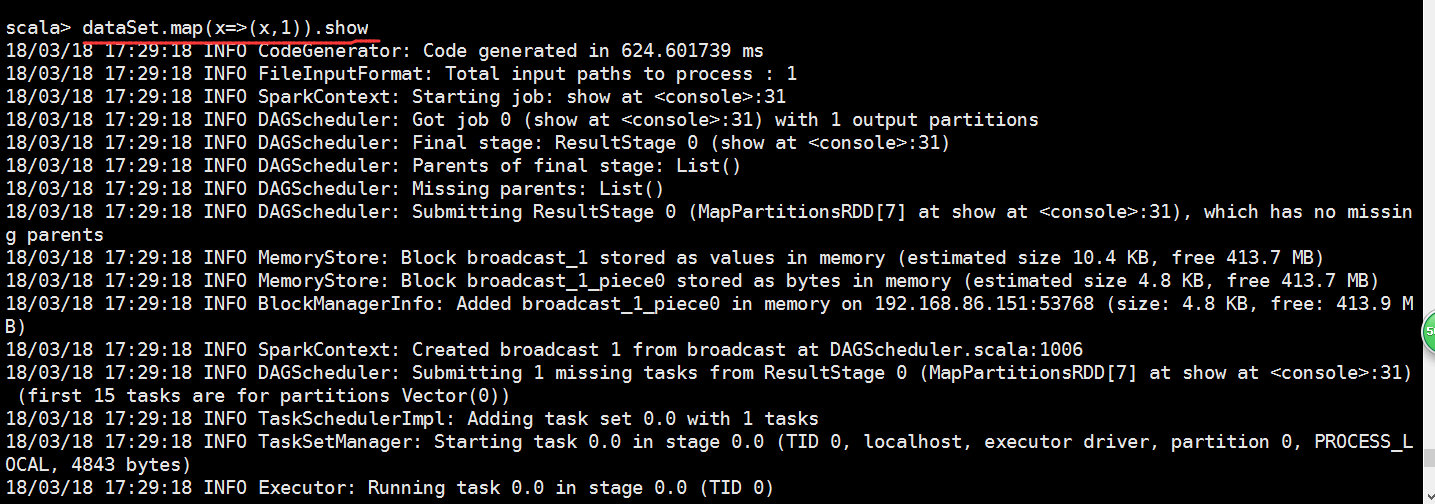
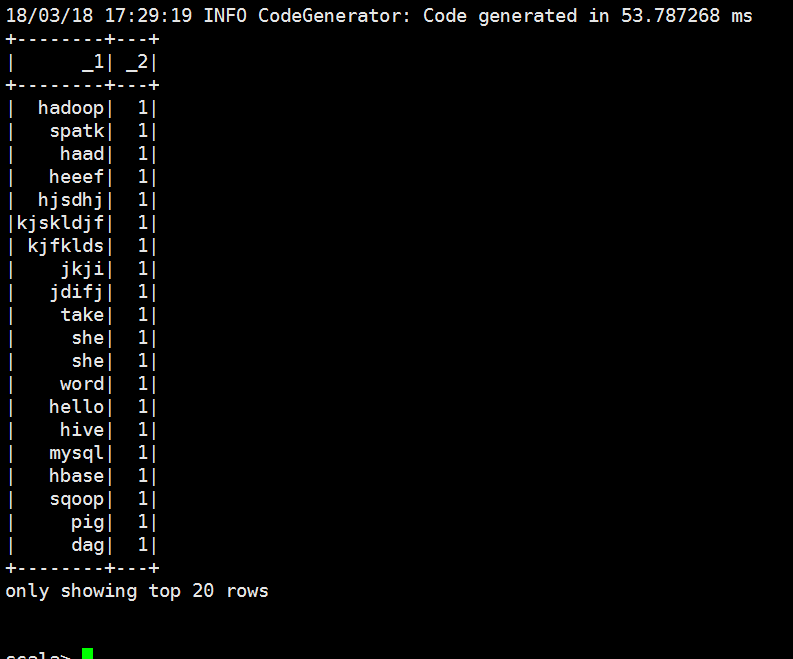
scala> lines.select("_1","_2").show
// :: INFO FileSourceStrategy: Pruning directories with:
// :: INFO FileSourceStrategy: Post-Scan Filters:
// :: INFO FileSourceStrategy: Output Data Schema: struct<value: string>
// :: INFO FileSourceScanExec: Pushed Filters:
// :: INFO CodeGenerator: Code generated in 123.289052 ms
// :: INFO MemoryStore: Block broadcast_6 stored as values in memory (estimated size 238.0 KB, free 413.4 MB)
// :: INFO MemoryStore: Block broadcast_6_piece0 stored as bytes in memory (estimated size 21.9 KB, free 413.4 MB)
// :: INFO BlockManagerInfo: Added broadcast_6_piece0 in memory on 192.168.86.151: (size: 21.9 KB, free: 413.9 MB)
// :: INFO SparkContext: Created broadcast from show at <console>:
// :: INFO FileSourceScanExec: Planning scan with bin packing, max size: bytes, open cost is considered as scanning bytes.
// :: INFO SparkContext: Starting job: show at <console>:
// :: INFO DAGScheduler: Got job (show at <console>:) with output partitions
// :: INFO DAGScheduler: Final stage: ResultStage (show at <console>:)
// :: INFO DAGScheduler: Parents of final stage: List()
// :: INFO DAGScheduler: Missing parents: List()
// :: INFO DAGScheduler: Submitting ResultStage (MapPartitionsRDD[] at show at <console>:), which has no missing parents
// :: INFO MemoryStore: Block broadcast_7 stored as values in memory (estimated size 15.7 KB, free 413.4 MB)
// :: INFO MemoryStore: Block broadcast_7_piece0 stored as bytes in memory (estimated size 7.0 KB, free 413.4 MB)
// :: INFO BlockManagerInfo: Added broadcast_7_piece0 in memory on 192.168.86.151: (size: 7.0 KB, free: 413.9 MB)
// :: INFO SparkContext: Created broadcast from broadcast at DAGScheduler.scala:
// :: INFO DAGScheduler: Submitting missing tasks from ResultStage (MapPartitionsRDD[] at show at <console>:) (first tasks are for partitions Vector())
// :: INFO TaskSchedulerImpl: Adding task set 3.0 with tasks
// :: INFO TaskSetManager: Starting task 0.0 in stage 3.0 (TID , localhost, executor driver, partition , PROCESS_LOCAL, bytes)
// :: INFO Executor: Running task 0.0 in stage 3.0 (TID )
// :: INFO FileScanRDD: Reading File path: file:///opt/datas/stu.txt, range: 0-216, partition values: [empty row]
// :: INFO Executor: Finished task 0.0 in stage 3.0 (TID ). bytes result sent to driver
// :: INFO TaskSetManager: Finished task 0.0 in stage 3.0 (TID ) in ms on localhost (executor driver) (/)
// :: INFO DAGScheduler: ResultStage (show at <console>:) finished in 0.076 s
// :: INFO DAGScheduler: Job finished: show at <console>:, took 0.113333 s
// :: INFO TaskSchedulerImpl: Removed TaskSet 3.0, whose tasks have all completed, from pool
// :: INFO CodeGenerator: Code generated in 46.614685 ms
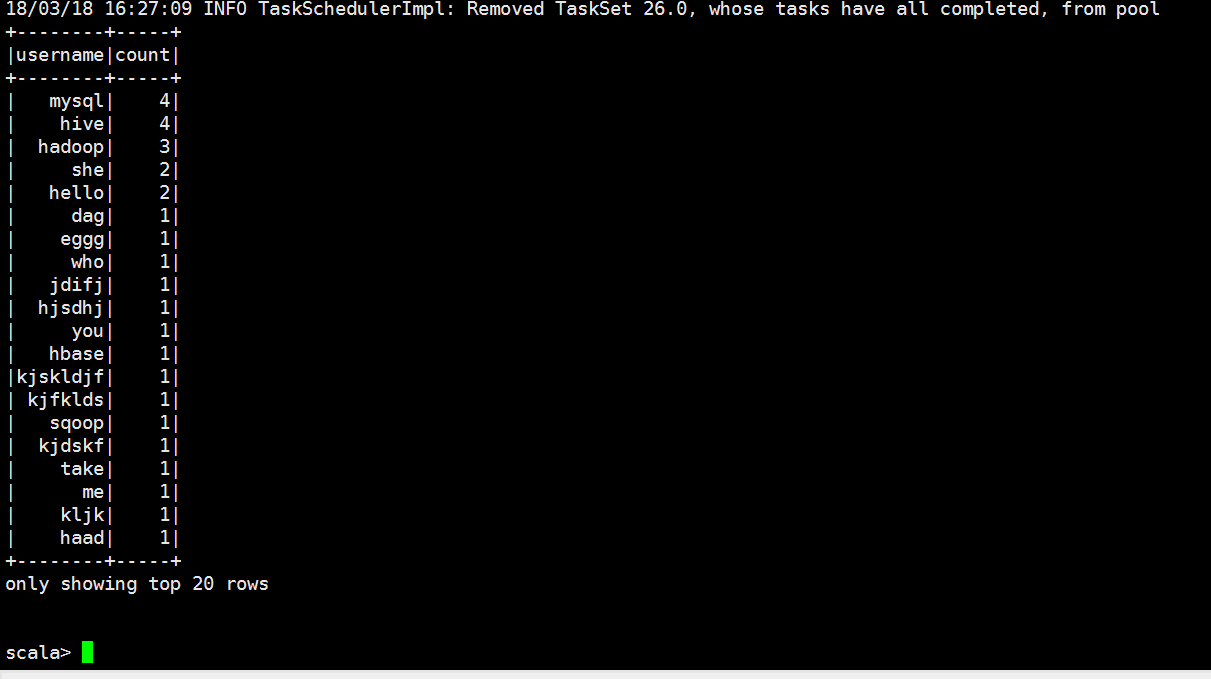
+--------+---+
| _1| _2|
+--------+---+
| hadoop| |
| spatk| |
| haad| |
| heeef| |
| hjsdhj| |
|kjskldjf| |
| kjfklds| |
| jkji| |
| jdifj| |
| take| |
| she| |
| she| |
| word| |
| hello| |
| hive| |
| mysql| |
| hbase| |
| sqoop| |
| pig| |
| dag| |
+--------+---+
only showing top rows
scala>

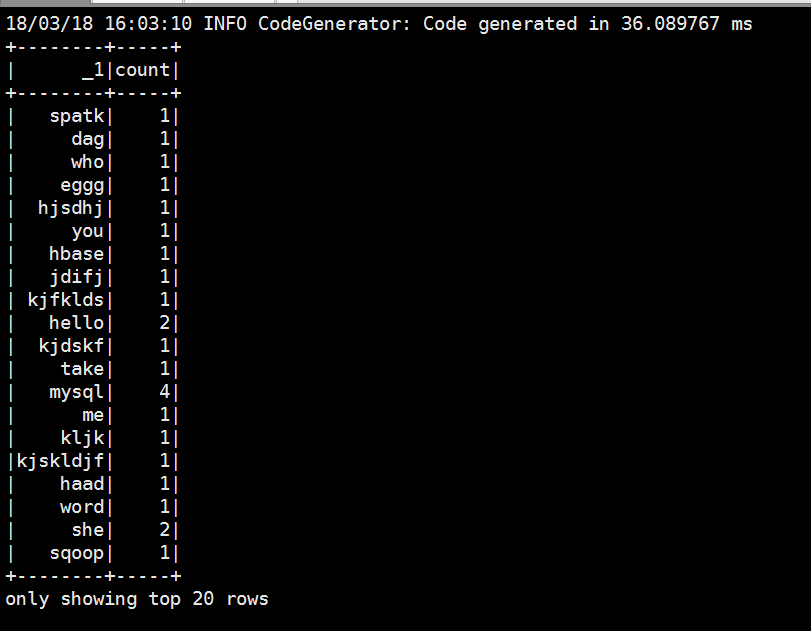

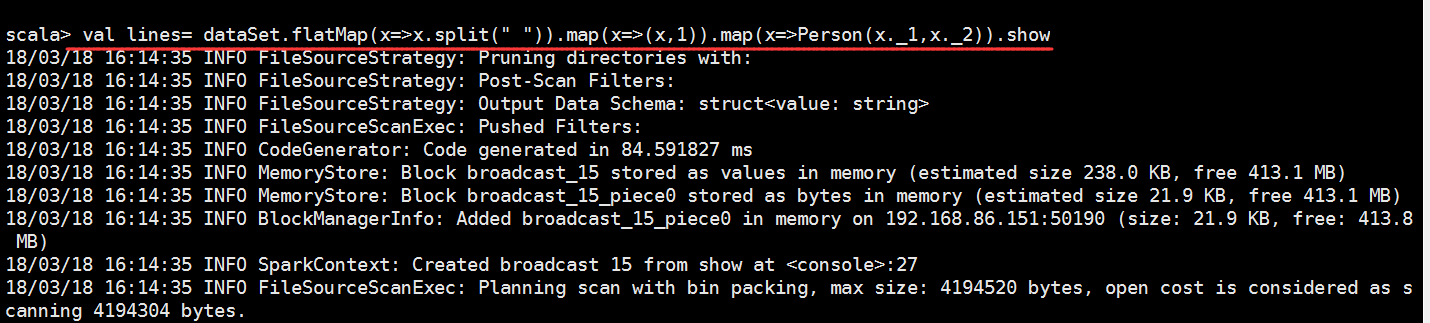


















Spark2.X分布式弹性数据集的更多相关文章
- 新闻实时分析系统 Spark2.X分布式弹性数据集
1.三大弹性数据集介绍 1)概念 2)优缺点对比 2.Spark RDD概述与创建方式 1)概述 在集群背后,有一个非常重要的分布式数据架构,即弹性分布式数据集(resilientdistribute ...
- 新闻网大数据实时分析可视化系统项目——17、Spark2.X分布式弹性数据集
1.三大弹性数据集介绍 1)概念 2)优缺点对比 2.Spark RDD概述与创建方式 1)概述 在集群背后,有一个非常重要的分布式数据架构,即弹性分布式数据集(resilientdistribute ...
- Hive数据分析——Spark是一种基于rdd(弹性数据集)的内存分布式并行处理框架,比于Hadoop将大量的中间结果写入HDFS,Spark避免了中间结果的持久化
转自:http://blog.csdn.net/wh_springer/article/details/51842496 近十年来,随着Hadoop生态系统的不断完善,Hadoop早已成为大数据事实上 ...
- PGXZ-腾讯全功能分布式关系数据集群
PGXZ-腾讯全功能分布式关系数据集群
- ElasticSearch大数据分布式弹性搜索引擎使用
阅读目录: 背景 安装 查找.下载rpm包 .执行rpm包安装 配置elasticsearch专属账户和组 设置elasticsearch文件所有者 切换到elasticsearch专属账户测试能否成 ...
- ElasticSearch大数据分布式弹性搜索引擎使用—从0到1
阅读目录: 背景 安装 查找.下载rpm包 .执行rpm包安装 配置elasticsearch专属账户和组 设置elasticsearch文件所有者 切换到elasticsearch专属账户测试能否成 ...
- spark2.4 分布式安装
一.Spark2.0的新特性Spark让我们引以为豪的一点就是所创建的API简单.直观.便于使用,Spark 2.0延续了这一传统,并在两个方面凸显了优势: 1.标准的SQL支持: 2.数据框(Dat ...
- 大数据技术之_19_Spark学习_03_Spark SQL 应用解析 + Spark SQL 概述、解析 、数据源、实战 + 执行 Spark SQL 查询 + JDBC/ODBC 服务器
第1章 Spark SQL 概述1.1 什么是 Spark SQL1.2 RDD vs DataFrames vs DataSet1.2.1 RDD1.2.2 DataFrame1.2.3 DataS ...
- SparkSQL
Spark SQL Spark SQL是Spark用来处理结构化数据的一个模块,它提供了2个编程抽象:DataFrame和DataSet,并且作为分布式SQL查询引擎的作用. Hive SQL是转换成 ...
随机推荐
- C# 线程:定时器的使用
转载请注明出处:http://www.cnblogs.com/KeenLeung/p/3911556.html Timer类:设置一个定时器,定时执行用户指定的函数. 定时器启动后,系统将自动建立一个 ...
- [转]linux中vim命令
在vi中按u可以撤销一次操作 u 撤销上一步的操作 ctrl+r 恢复上一步被撤销的操作 在vi中移动光标至: 行首:^或0 行尾:$ 页首:1G(或gg) 页尾:G(即shift+g) 显 ...
- mongodb--Profiling慢查询详解
官方查询地址:https://docs.mongodb.com/v3.2/tutorial/manage-the-database-profiler/ 在很多情况下,DBA都要对数据库的性能进行分析处 ...
- python2核心类库:urllib、urllib2的区别和使用
urllib/urllib2都是接受URL请求的相关模块区别:1.urllib2可以接受一个Request类的实例来设置URL请求的headers,urllib仅可以接受URL.这意味着,你不可以伪装 ...
- c#多线程与委托(转)
一:线程在.net中提供了两种启动线程的方式,一种是不带参数的启动方式,另一种是带参数的启动的方式.不带参数的启动方式 如果启动参数时无需其它额外的信息,可以使用ThreadStart来实例化Thre ...
- xilinx AXI相关IP核学习
xilinx AXI相关IP核学习 1.阅读PG044 (1)AXI4‐Stream to Video Out Top‐Level Signaling Interface (2)AXI4‐Stream ...
- <亲测>阿里云centos7 挂载数据盘配置
阿里云centos7 挂载数据盘配置 2018年07月17日 15:13:53 阅读数:235更多 个人分类: linux阿里云ECS数据盘挂载 查看磁盘情况 fdisk -l 其中/dev/v ...
- 【springboot】之常用技术文档
https://www.ibm.com/developerworks/cn/java/j-lo-spring-boot/index.html
- STL基础--算法(已排序数据的算法,数值算法)
已排序数据的算法 Binary search, merge, set operations 每个已排序数据算法都有一个同名的更一般的形式 vector vec = {8,9,9,9,45,87,90} ...
- C#创建自定义Object对象
, B=,J=}; 记录一下,老写成 var obj = new object() { O=0, B=0,J=0};