Flink资料(1)-- Flink基础概念(Basic Concept)
Flink基础概念
本文描述Flink的基础概念,翻译自https://ci.apache.org/projects/flink/flink-docs-release-1.0/concepts/concepts.html
一、程序(Progrram)和数据流(Dataflows)
Flink程序的构建基础为Streams和Transformations。其中Streams为中间结果,而Transformations是将一到多个Streams作为输入,计算产生一到多个Streams作为输出的操作(Operation)
当执行时,Flink程序将被映射成为一个流式数据流图(Streaming Dataflow),以Transformation operator作为结点,以streams作为边。该Streaming Dataflow类似一个DAG(有向无环图)。
一般情况下,Program中的Transformation与数据流图中的Operator是一对一关系,但有时一个Transformation也可能对应包括了多个Operator

图1 Program & Streaming Dataflow
1.1 数据流图的并行
Flink开发的程序本质上就是并行且分布的。Streams被分割为stream partitions,Operator被分割为Operator subtask。这些subtask在执行时互相独立,运行在不同线程甚至不同硬件或容器(containers)中。
1.1.1 并行度
一个Operator的并行度(parallelism)即为该Operator的subtask数量。
一个Stream的并行度与产生它的Operator统一。

图2 Parallelism
1.1.2 数据流传输模式
在Flink中,以两种模式在Operator之间传输Stream
· 一对一(One-to-One / Forwarding):stream保留原有的分割和元素的顺序。
o 如map()的Subtask[1]接收到的Stream与Source的Subtask[1]中产生的子Stream保持一致。
o 图2中Source和Map之间即以此种模式传输。
· 重分发(Redistributing):发送端将会改变Stream的分割。每个Subtask根据其Transformation的方式,将数据发送给不同的Target-Subtask。
o 如keyBy(根据HashCode进行重分割)、broadcast(广播分发)、rebalance(随机重分发)。
o 在重分发模式中,只在连接的两个Operator之间保留Stream中元素的顺序。
o 图2中Map和KeyBy/Window之间、KeyBy/Window和Sink之间即为此种模式
1.2 任务以及操作链(Task & Operator Chains)
为了分布式运行的优化,Flink将Operator的Subtasks链接(Chain)起来形成Tasks,而每个Task独立由一个线程执行。
· 将Subtasks链接为Task可以减少线程之间的通信和缓冲的开销,提高总体吞吐量(throughput)并降低延迟(latency)
· Chain操作方式可由API进行配置。
· 图2的程序需要7个线程运行,经过Chain操作(图3),线程被降低到了5个

图3 Tasks & Operator Chains
二、分布式执行
2.1 Master、Worker、Client
2.1.1 Master & Worker
Flink运行时的进程分为两种,Master进程和Worker进程
· Master进程(JobManager)负责协调分布式执行:调度Task、协调检查点、协调失效恢复等等
o Flink应用至少有一个Master进程,一个高可用性的运行配置可能包含多个Master进程,其中一个是Leader,其他的是Standby
· Worker进程(TaskManager)负责执行一个Dataflow的Task,缓存并交换streams
o Flink应用至少有一个Worker进程
Master和Worker进程可以多种方式部署:直接部署在机器上、通过container或者如YARN等资源框架。Worker进程向Master进程声明其可用,而后Master进程将任务发放给Worker
2.1.2 Client
Client不属于Flink的runtime和程序的执行过程,它的作用是准备并发送Dataflow给Master进程。在这之后,Client可以断开连接,也可以保持连接以接收运行进度报告。
Client的运行触发程序的执行,以命令行"flink run …"调用
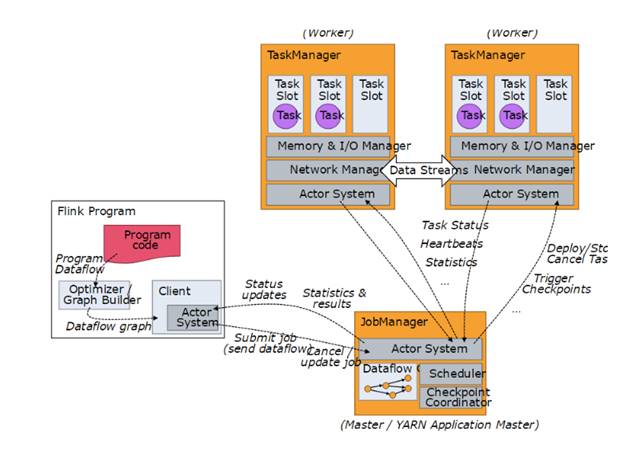
图4 Master, Worker, Client
2.2 Worker, Slots, Resource
2.2.1 Flink资源分割
每个Worker(TaskManager)都是一个JVM进程,且在不同的线程上运行一个或多个Subtask。为了控制一个Worker接受task的数量,引入任务槽(Task slot)
每个task slot代表了TaskManager的固定比例的一部分资源。例如,一个有三个task slot的TaskManager,会将其1/3的内存给每个Task slot。
o 将资源分槽使得subtask不会与其他job的subtask争抢资源,而是会拥有一部分专用的资源。
o Flink当前仅将内存作为可分槽的资源,CPU没有分槽
调整task slot的数量可以让用户定义subtask之间如何互相隔离。
o 每个TaskManager仅有一个task slot意味着每个任务组都运行在分割的JVM中,所以也就可以在不同的Container中运行
o 拥有多个Task slot则意味着多subtask共享JVM,同JVM的task将通过多路复用(Multiplexing)共享TCP连接和心跳消息(Heatbeat Message),它们之间也可以共享Dataset和数据结构,所以可以减少单任务的开销
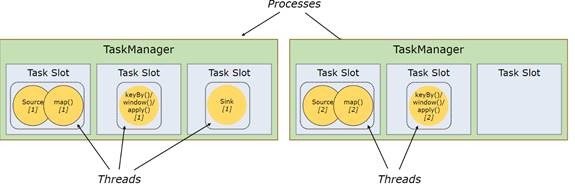
图5 TaskSlot,资源
2.2.2 任务槽共享(Slot Sharing)
默认情况下,Flink允许来自同一个Job的subtask共享task slot(不同Task的subtask也可以,只要来自同一个Job)。这样产生的结果可能是一个task slot运行着job的整个运行流水线(pipeline),允许task slot共享具有以下优势:
o Flink集群需要Job中最高并行度(parallelism)的task slot。而使用任务槽共享则不必计算一个任务中具体有多少task(这些task可能还有不同的并行度)
o 使得提升资源利用率更加方便。若没有任务槽共享,负载不高的Source/Map等subtask将会占据许多资源,而负载较高的窗口subtask则会缺乏资源;而有了任务槽共享,可以将基本并行度(base parallelism)从2提升到6,以增加分槽资源的利用率的同时,仍可以保证每个TaskManager得到的高负载subtask的分配方案的公平性
任务槽共享可以通过API控制,以防止不理想地分配情况,控制任务槽分享的机制是资源组(resource group),用以定义哪些任务可以共享任务槽。
经验上来说,Task Slot的数量设置为CPU核心的数量为好。考虑到超线程,每个slot可以得到2个或更多的硬件线程上下文

图6 任务槽共享(Slot Sharing)
三、时间和窗口
由于流数据的无限等特点,流处理中的聚合事件(counts、sums等)和批处理模式下是有所不同的,在stream上的聚合使用窗口(window)来确定范围,如“最近5分钟的总数”、“最近100个元素的和”等。
窗口可以是时间驱动(time driven)或数据驱动(data driven)的。我们可以将窗口分为三类:(1)滚动窗口(tumbling window),窗口之间不重叠;(2)滑动窗口(Sliding Window),窗口之间有重叠;(3)会话窗口(session window),活动之间有间隔

图7 Windows
3.1 时间
流处理程序中对于时间的定义有三种:
o 事件时间(Event Time):是事件被创建的时间,一般由事件中的Timestamp描述,如在产生数据的传感器或是生产服务上中,使用event time来标记时间。Flink通过timestamp assigner来访问timestamp。
o 提取时间(Ingestion time):是一个事件由source operator进入Flink的数据流图时的时间。
o 处理时间(Processing time):是单个Operator执行一个基于时间的操作的时间,是一个本地时间(local time)
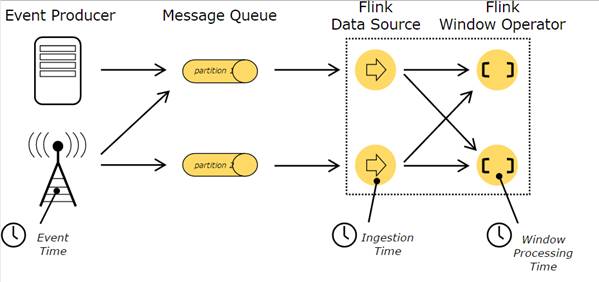
图8 Time
四、状态和容错
有些Operation仅仅需要当前的Event(如事件复制操作)、而有些Operation需要不同的事件的信息(如窗口操作),我们称这些Operation是有状态(stateful)的
这些Operation的状态在Flink中以key-value的形式维护,这些状态与那些被有状态的operator所读取的stream的分割、分布存储在一起。所以,我们只能在经过keyby()方法分割后的stream上访问key-value的状态,而且仅限于当前事件的key的值。
这种将stream的key和状态联系在一起的方式,保证了对状态的更新是本地操作(local operation),从而可以不通过事务(Transaction)也可以保持一致性,避免了事务的开销。这种联系方式还使得Flink可以方便地重分布(redistribute)状态,并调整stream对应分割。

图9 状态
4.1 检查点
Flink使用stream reply和检查点的组合来实现容错。一个检查点定义了一个Dataflow可以恢复的stream的一致的状态点,并且维护了整个应用的一致性(exactly-once processing semantics)。事件和状态的在上一个检查点被输入stream回复后才更新
检查点间隔是一个衡量执行时容错开销的方式,此外还有恢复时间(recovery time),即需要回复的事件数量。
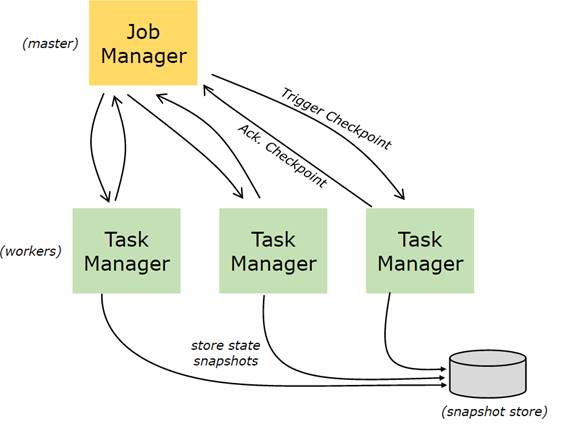
图10 检查点 & 容错
4.2 状态后端
存储key-value索引的数据结构由选择的状态后端(state backend)决定。一种状态后端将数据存储在内存中的哈希映射中,另一种状态后端使用RocksDB存储key-value索引。此外,为了定义维护状态的数据结构,状态后端同样实现了记录在某时间点上维护key-value状态的快照,并存储该快照为检查点的一部分。
五、在流处理上的批处理
Flink以流处理程序的特殊形式来执行批处理,即Stream是有界的(有限的元素)。DataSet本质上依然以数据流处理,所以批处理情景依然可以使用上述的概念,仅仅有一些小区别
o DataSet API中不使用检查点。Recovery happens by fully replaying the streams. That is possible, because inputs are bounded. This pushes the cost more towards the recovery, but makes the regular processing cheaper, because it avoids checkpoints.
o DataSet API的有状态Operation使用简化的内存中分散化(in-memory/out-of-core)的数据结构,而不是key-value索引结构。
o DataSet API使用特殊的同步迭代(superstep-based),这种迭代只适用于有界流的情况。更多信息查看iteration docs
Flink资料(1)-- Flink基础概念(Basic Concept)的更多相关文章
- 转-nRF5 SDK for Mesh(六) BLE MESH 的 基础概念
nRF5 SDK for Mesh(六) BLE MESH 的 基础概念 Basic Bluetooth Mesh concepts The Bluetooth Mesh is a profile s ...
- Flink入门-第一篇:Flink基础概念以及竞品对比
Flink入门-第一篇:Flink基础概念以及竞品对比 Flink介绍 截止2021年10月Flink最新的稳定版本已经发展到1.14.0 Flink起源于一个名为Stratosphere的研究项目主 ...
- Flink基础概念入门
Flink 概述 什么是 Flink Apache Apache Flink 是一个开源的流处理框架,应用于分布式.高性能.高可用的数据流应用程序.可以处理有限数据流和无限数据,即能够处理有边界和无边 ...
- 《从0到1学习Flink》—— 介绍Flink中的Stream Windows
前言 目前有许多数据分析的场景从批处理到流处理的演变, 虽然可以将批处理作为流处理的特殊情况来处理,但是分析无穷集的流数据通常需要思维方式的转变并且具有其自己的术语(例如,"windowin ...
- 《从0到1学习Flink》—— Apache Flink 介绍
前言 Flink 是一种流式计算框架,为什么我会接触到 Flink 呢?因为我目前在负责的是监控平台的告警部分,负责采集到的监控数据会直接往 kafka 里塞,然后告警这边需要从 kafka topi ...
- Flink初探-为什么选择Flink
本文主要记录一些关于Flink与storm,spark的区别, 优势, 劣势, 以及为什么这么多公司都转向Flink. What Is Flink 一个通俗易懂的概念: Apache Flink 是近 ...
- 【Machine Learning】机器学习及其基础概念简介
机器学习及其基础概念简介 作者:白宁超 2016年12月23日21:24:51 摘要:随着机器学习和深度学习的热潮,各种图书层出不穷.然而多数是基础理论知识介绍,缺乏实现的深入理解.本系列文章是作者结 ...
- hadoop之Spark强有力竞争者Flink,Spark与Flink:对比与分析
hadoop之Spark强有力竞争者Flink,Spark与Flink:对比与分析 Spark是一种快速.通用的计算集群系统,Spark提出的最主要抽象概念是弹性分布式数据集(RDD),它是一个元素集 ...
- JavaWeb开发技术基础概念回顾篇
JavaWeb开发技术基础概念回顾篇 第一章 动态网页开发技术概述 1.JSP技术:JSP是Java Server Page的缩写,指的是基于Java服务器端动态网页. 2.JSP的运行原理:当用户第 ...
随机推荐
- css3系列教程--animation
Animation:动画animationshi css的动画效果.需要定义keyframe动画对象来实现.为了兼容苹果/chrome,firefox,ie每次定义需要添加-webkit-,-moz- ...
- js 记忆函数
使用js记忆函数来计算菲波那切数列.阶乘等,可以极大减少我们必须要做的工作,加速程序计算. 1.编写记忆函数memoizer var memoizer = function(memo, fundame ...
- 替换Gravatar头像默认服务器
这几天Gravatar头像服务器应该集体被墙了,头像无法显示.兵来将挡,水来土掩,上有政策,下有对策,和谐社会靠大家,哈. 利用多说Gravatar头像中转服务器替代头像默认服务器. 将下面代码添加到 ...
- C# 运算符 if
运算符: 一.算术运算符: + - * / % ——取余运算 取余运算的应用场景: 1.奇偶数的区分. 2.把数变化到某个范围之内.——彩票生成. 3.判断能否整除.——闰年.平年. int a = ...
- HOOK钩子 - 钩子函数说明
翻译参考自MaybeHelios的blog: http://blog.csdn.net/maybehelios/ 通过SetWindowsHookEx方法安装钩子,该函数指定处理拦截消息的钩子函数(回 ...
- mysql学习(五)-字段属性
字段属性: unsigned: 无符号类型,只能修饰数值类型: create table if not exists t1(id int unsigned); zerofill:前端填0 //只能修饰 ...
- zend guard loader
1 .是zendoptimizer的前身, 在php 5.3 (含)之前使用更新到6 ,5.4 之后不再使用.是代码优化的一种,7中opcache 类似功效. 2 .php版本的变量 phpversi ...
- 关于ThinkPHP下使用Uploadify插件 仅有火狐提示HTTP Error (302)错误的解决办法
'VAR_SESSION_ID' => 'session_id', //修复uploadify插件无法传递session_id的bug 首先在项目目录中的Common/Conf/config.p ...
- 最长增长子序列 DP
#include<iostream> using namespace std; #define INF 0x7fffffff #define N 10000 // O(n^2) int l ...
- vs2005 测试 lua环境
(1)添加文件核路径 (2)库文件路径 (3)main.cpp #include <stdio.h>#include <string.h> extern "C&quo ...