我的Python成长之路---第四天---Python基础(16)---2016年1月23日(寒风刺骨)
四、正则表达式
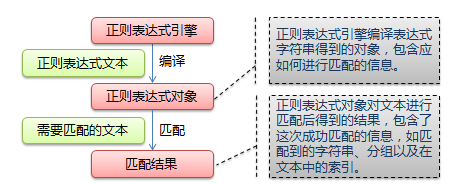
1、Python支持的正则表达式元字符和语法
| 语法 | 说明 | 表达式实例 | 完整匹配的字符串 |
| 字符 | |||
| 一般字符 | 匹配自己 | abc | abc |
| . | 匹配任意字符“\n”除外 DOTALL模式中(re.DOTALL)也能匹配换行符 |
a.b | abc或abc或a1c等 |
| [...] | 字符集[abc]表示a或b或c,也可以-表示一个范围如[a-d]表示a或b或c或d | a[bc]c | abc或adc |
| [^...] | 非字符集,也就是非[]里的之外的字符 | a[^bc]c | adc或aec等 |
| 预定义字符集(也可以系在字符集[...]中) | |||
| \d | 数字:[0-9] | a\dc | a1c等 |
| \D | 非数字:[^0-9]或[^\d] | a\Dc | abc等 |
| \s | 空白字符:[<空格>\t\n\f\v] | a\sc | a b等 |
| \S | 非空白字符:[^s] | a\Sc | abc等 |
| \w | 字母数字(单词字符)[a-zA-Z0-9] | a\wc | abc或a1c等 |
| \W | 非字母数字(非单词字符)[^\w] | a\Wc | a.c或a_c等 |
| 数量词(用在字符或(...)分组之后) | |||
| * | 匹配0个或多个前面的表达式。(注意包括0次) | abc* | ab或abcc等 |
| + | 匹配1个或多个前面的表达式。 | abc+ | abc或abcc等 |
| ? | 匹配0个或1个前面的表达式。(注意包括0次) | abc? | ab或abc |
| {m} | 匹配m个前面表达式(非贪婪) | abc{2} | abcc |
| {m,} | 匹配至少m个前面表达式(m至无限次) | abc{2,} | abcc或abccc等 |
| {m,n} | 匹配m至n个前面的表达式 | abc{1,2} | abc或abcc |
| 边界匹配(不消耗待匹配字符中的字符) | |||
| ^ | 匹配字符串开头,在多行模式中匹配每一行的开头 | ^abc | abc或abcd等 |
| $ | 匹配字符串结尾,在多行模式中匹配每一行的结尾 | abc$ | abc或123abc等 |
| \A | 仅匹配字符串开头 | \Aabc | abc或abcd等 |
| \Z | 仅匹配字符串结尾 | abc\Z | abc或123abc等 |
| \b | 匹配一个单词边界,也就是指单词和空格间的位置。例如, 'er\b' 可以匹配"never" 中的 'er',但不能匹配 "verb" 中的 'er'。 | ||
| \B | 匹配非单词边界。'er\B' 能匹配 "verb" 中的 'er',但不能匹配 "never" 中的 'er'。 | ||
| 逻辑、分组 | |||
| | | 或左右表达式任意一个(短路)如果|没有在()中表示整个正则表达式(注意有括号和没括号的区别) | abc|def ab(c|d)ef |
abc或def abcef或abdef |
| (...) | 分组,可以用来引用,也可以括号内的被当做一组进行数量匹配后接数量词 | (abc){2}a | abcabca |
| (?P<name>...) | 分组别名,给分组起个名字,方便后面调用 | ||
| \<number> | 引用编号为<number>的分组匹配到的字符串(注意是配到的字符串不是分组表达式本身) | (\d)abc\1 | 1ab1或5ab5等 |
| (?=name) | 引用别名为name的分组匹配到的字符串(注意是配到的字符串不是分组表达式本身) | (?P<id>\d)abc(?P=id) | 1ab1或5ab5等 |
2、数量词的贪婪模式与分贪婪模式
3、python的re模块
import re # 将正则表达式编译成Pattern对象
pattern = re.compile(r'hello') # 使用Pattern匹配文本,获得匹配结果,无法匹配时将返回None
match = pattern.match('hello world!') if match:
# 使用Match获得分组信息
print match.group()
hello
macth = re.match('hello', 'hello world')
if match:
print match.group()
4、re模块的常用方法
re.compile(strPattern[, flag])
match(string[, pos[, endpos]]) | re.match(pattern, string[, flags])
search(string[, pos[, endpos]]) | re.search(pattern, string[, flags])
>>> import re
>>> s = 'hello world'
>>> print(re.match('ello', s))
None
>>> print(re.search('ello',s ))
<_sre.SRE_Match object; span=(1, 5), match='ello'>
说明:可以看到macth只匹配开头,开头不匹配,就不算匹配到,search则可以从中间,只要能有匹配到就算匹配
findall(string[, pos[, endpos]]) | re.findall(pattern, string[, flags])
搜索string,以列表形式返回全部能匹配的子串。有点像search的扩展,把所有匹配的子串放到一个列表
参数:同match
返回值:所有匹配的子串,没有匹配则返回空列表
>>> import re
>>> s = 'one1two2three3four4'
>>> re.findall('\d+', s)
['', '', '', '']
split(string[, maxsplit]) | re.split(pattern, string[, maxsplit]):
>>> import re
>>> s = 'one1two2three3four4'
>>> re.split('\d+', s)
['one', 'two', 'three', 'four', '']
sub(repl, string[, count]) | re.sub(pattern, repl, string[, count])
if __name__ == '__main__':
import re
s = '--(1.1+1+1-(-1)-(1+1+(1+1+2.2)))+-----111+--++--3-+++++++---+---1+4+4/2+(1+3)*4.1+(2-1.1)*2/2*3'
def replace_sign(expression):
'''
替换多个连续+-符号的问题,例如+-----,遵循奇数个负号等于正否则为负的原则进行替换
:param expression: 表达式,包括有括号的情况
:return: 返回经过处理的表达式
'''
def re_sign(m):
if m:
if m.group().count('-')%2 == 1:
return '-'
else:
return '+'
else:
return ''
expression = re.sub('[\+\-]{2,}', re_sign, expression)
return expression s = replace_sign(s)
print(s)
执行结果
24 +(1.1+1+1-(-1)-(1+1+(1+1+2.2)))-111+3-1+4+4/2+(1+3)*4.1+(2-1.1)*2/2*3
我的Python成长之路---第四天---Python基础(16)---2016年1月23日(寒风刺骨)的更多相关文章
- 我的Python成长之路---第四天---Python基础(15)---2016年1月23日(寒风刺骨)
二.装饰器 所谓装饰器decorator仅仅是一种语法糖, 可作用的对象可以是函数也可以是类, 装饰器本身是一个函数, 其主要工作方式就是将被装饰的类或者函数当作参数传递给装饰器函数.本质上, ...
- 我的Python成长之路---第四天---Python基础(14)---2016年1月23日(寒风刺骨)
一.生成器和迭代器 1.迭代器 迭代器是访问集合元素的一种方式.迭代器对象从集合的第一个元素开始访问,直到所有的元素被访问完结束.迭代器只能往前不会后退,不过这也没什么,因为人们很少在迭代途中往后退. ...
- 我的Python成长之路---第三天---Python基础(13)---2016年1月16日(雾霾)
五.Python的常用的内置函数 Python为我们准备了大量的内置函数,如下图所示 这里我们只讨论红框内的内置函数 abs(x) 返回一个数的绝对值(模),参数可以是真说或浮点数 >>& ...
- python成长之路——第四天
内置函数: callable:查看对象是否能被调用(对象是函数的话能被调用) #callable def f1(): pass f2="a" print(callable(f1)) ...
- 我的Python成长之路---第七天---Python基础(21)---2016年2月27日(晴)
四.面向对象进阶 1.类方法 普通的方法通过对象调用,至少有一个self参数(调用的时候系统自动传递,不需要手工传递),而类方法由类直接调用,至少有一个cls参数,执行时,自动将调用该方法的类赋值个c ...
- 我的Python成长之路---第三天---Python基础(12)---2016年1月16日(雾霾)
四.函数 日常生活中,要完成一件复杂的功能,我们总是习惯把“大功能”分解为多个“小功能”以实现.在编程的世界里,“功能”可称呼为“函数”,因此“函数”其实就是一段实现了某种功能的代码,并且可以供其它代 ...
- 我的Python成长之路---第三天---Python基础(11)---2016年1月16日(雾霾)
三.深浅拷贝 在Python中将一个变量的值传递给另外一个变量通常有三种:赋值.浅拷贝以及深拷贝 讨论深浅拷贝之前我们把Python的数据类型分为基本数据类型包括数字.字符串.布尔以及None等,还有 ...
- 我的Python成长之路---第三天---Python基础(10)---2016年1月16日(雾霾)
二.collections collections是对Python现有的数据类型的补充,在使用collections中的对象要先导入import collections模块 1.Counter——计数 ...
- Python高手之路【四】python函数装饰器
def outer(func): def inner(): print('hello') print('hello') print('hello') r = func() print('end') p ...
随机推荐
- 这家伙,搞了好多C#excel的操作,学习了
http://www.cnblogs.com/peterzb/archive/2009/07/06/1517395.html
- monkeyrunner环境搭建
对android世界小白白的人儿,弄个monkeyrunner环境吭哧哧的费了大半天的劲,没办法,因为实在是对这方面一窍不通,名词都是一个个百度才略懂一二,既然这么辛苦费劲的才能弄好,怎么也得记录下来 ...
- IOS 特定于设备的开发:Info.plist属性列表的设置
应用程序的Info.plist属性列表使你能够在向iTunes提交应用程序时指定应用程序的要求.这些限制允许告诉iTunes应用程序需要哪些设备特性. 每个IOS单元都会提供一个独特的特性集.一些设备 ...
- w3wp.exe CPU过百问题
w3wp.exe CPU过百问题 最近发布在windows server2012 IIS8.0上的一个WebAPI项目,才几十个人在线,CPU就会出现过百情况,并且CPU一旦过百应用程序池就自动暂 ...
- 在OSX狮子(Lion)上安装MYSQL(Install MySQL on Mac OSX)
这篇文章简述了在Mac OSX狮子(Lion)上安装MySQL Community Server最新版本v10.6.7的过程. MySQL是最流行的开源数据库管理系统.首先,从MySQL的下载页面上下 ...
- Oracle 表空间操作
-- 查询已有表空间 SELECT TABLE_SPACENAME FROM DBA_TABLESPACES; -- 创建表空间 CREATE TABLESPACE SPACE DATAFILE ‘E ...
- _WSAStartup@8,该符号在函数 _main 中被引用
int WSAStartup( __in WORD wVersionRequested, __out LPWSADATA lpWSAData ); WSAStartup 格 式: int PASCA ...
- 集合ArrayList案例
1.添加元素,读取 ArrayList n = new ArrayList(); n.Add();//集合中添加元素用Add,分别添加了1,2 n.Add(); foreach (int a in n ...
- [译]Stairway to Integration Services Level 9 - Control Flow Task Errors
介绍 在本文中,我们会实验 MaximumErrorCount和ForceExecutioResult 故障容差属性,并且还要学习Control Flow task errors, event han ...
- 在一个数组中是否存在两个数A、B的和为M
#include <iostream>#include <algorithm>//#include <vector>using namespace std; int ...