基础算法-查找:线性索引查找(I)
前面介绍的几种查找的算法都是基于数据有序的基础上进行的。但是在实际的应用中,很多数据集可能有惊人的数据量,面对这些海量的数据,要保证记录全部按照当中的某个关键字有序,其时间代价是非常昂贵的,所以这种数据通常都是按先后顺序存储的。
那么如何能够快速的查找到需要的数据呢?办法就是--索引。
索引就是把一个关键字与它对应的记录相关联的过程。一个索引有若干个索引项构成,每个索引项至少应包括关键字和对应的记录在存储器中的位置等信息。
在索引表中的每个索引项对应多条记录,则称为稀疏索引,若每个索引项唯一对应一条记录,则称为稠密索引。
索引按照结构可以分为线性索引、树形索引和多级索引。所谓的线性索引就是将索引项集合组织为线性结构,也称为索引表。
稠密索引
稠密索引是指在线性索引表中,将数据集中的每个记录对应一个索引项。并且索引项一定是按照关键码有序的排列。
索引项有序也就意味着,在查找关键字时,可以用到折半、插值、斐波那契等有序的查找算法。
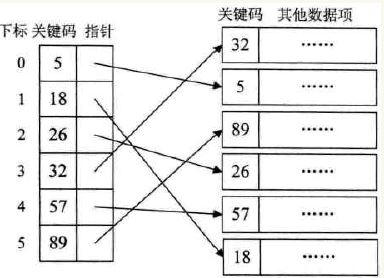
稠密索引的改进的地方在于:它简化了庞大的原数据集,使原本不能装入内存的庞大的数据集,能一次性的装入内存,并且能够在内存中实现关键字码的排序,并且每一个索引项能够指向磁盘中它代表的原数据记录。
能利用高级的查找算法,这显然是稠密索引的优点,但是如果数据集非常的大,那么索引表也是非常的大,对于内存有限的计算机来说,不得不把索引表也放到磁盘中,这样就大大的降低了效率。
分块索引
稠密索引因为索引项与数据集的记录个数相同,所以空间代价很大。为了减少索引项的个数,对数据集进行分块,使其分块有序,然后在对每一块建立一个索引项,从而减少索引项的个数。
分块有序,就是把数据集的记录分成了若干块,这些块需要满足的条件是:
块内无序,块间有序。

上图中定义的索引项的结构分为三个数据项:
(1)最大关键码,它存储了每一块中的最大关键字,这样的好处是可以使得在它之后的下一块中的最小关键字也能比这一块最大的关键字要大。当然这个索引关键字码可以是任何能够唯一标识一个块的任何数据。
(2)存储了块中记录的个数,以便于循环时使用。
(3)用于指向块首数据元素的指针,便于开始对这一块中记录遍历
分块索引如果在索引表和每个块内的记录都采用顺序表查找,那么时间复杂度分析就如下:
分块索引表的平均查找长度分析
设有n个记录,被分成了m块,每块有t条记录。显然n=mxt。在索引表和块中的平均查找长度分别是Lb和Lw。

上面的分析中,在块间使用的也是顺序查找,因为块间是有序的,所以可以使用折半查找等快速的算法来提高效率。

#define ILMSize 60;
#define MaxSize 3600;
//建立索引项结构
struct IndexItem
{
int index;
int start;
int length;
};
//建立索引表
typedef struct IndexItem indexList[ILMSize]; //ILMSize为事先定义好的整型常量,大于等于索引项数目m
//建立原始数据的主表
int mainList[MaxSize]; //MaxSize为事先定义好的整型常量,大于等于主表中的记录的个数n /*
* 输入:主表A,索引表B,索引表中索引项数目m,要搜索的元素elem
* 输出:找到的元素的下标
*/
int blockSearch(mainList A, indexList B, int m, int elem)
{
for(int i = 0; i < m; i++)
{
if(B[i].index >= elem)
{
break;
}
}//for
if(i == m)
{
return -1; //查找失败
} int endNum = B[i].start + B[i].length;
for(int j = B[i].start; j < num; j++)
{
if(A[j] == elem)
{
break;
}
}//for
if(j < num)
{
return j;
}
if(j == num)
{
return -1;
} }
若 IndexKeyType 被定义为字符串类型,则算法中相应的条件改为 strcmp (K1, B[i].index) == 0; 同理,若KeyType 被定义为字符串类型
则算法中相应的条件也应该改为 strcmp (K2, A[j].key) == 0 若每个子表在主表A中采用的是链接存储,则只要把上面算法中的while循环
和其后的if语句进行如下修改即可: while (j != -1)//用-1作为空指针标记
{
if (K2 == A[j].key)
break;
else
j = A[j].next;
}
return j;
在索引表中折半查找的伪代码
//在索引表中折半查找伪代码
while low <= high
mid = (low + high)/2
if A[mid-1]<elem<A[mid]
i = mid
break
else if A[mid-1]>elem
high = mid - 1
else if elem > A[mid]
low = mid + 1
if low > high
i = low
在索引表中折半查找的代码实现
//在索引表中折半查找代码实现
while(low <= high)
{
mid = (low + high) / 2;
if(B[mid -1].index < elem && B[mid].index > elem)
{
i = mid;
break;
}
else if(B[mid - 1].index > elem)
{
high = mid - 1;
}
else
{
low = mid + 1;
}
}//while
if(low > high)
{
i = low;
}
分块索引表的建立
这样就能很好的实现,大的数据块存储在磁盘上,索引表存储于内存中了。这种模型是不需要对原始数据集进行排序操作的,因为块与块之间是可以不连续的存放的。在原始数据产生前确定分多少块,以及每个块的存储位置(块间位置不连续,块内位置连续),这时每个块内的存储数据的范围也要确定,当新的数据到来的时候,就能确定要把这个数据放到哪个块中。
举个例子:
我想设计一个分块索引来查找数据,大体估算有3600个数据,所以根据能使算法效率最高的分块数目等于每一块的记录数目。设置60个块,每个块有60个记录。60个块就对应磁盘上的60个文件夹目录用来存储数据,这60个块的块间位置不连续。同时假设这3600个记录的关键字大小范围是1-3000,那么第一块就存储1-50的记录。来一个新纪录,如果关键字在1-50之间,就直接把它追加到第一块中。同时如果这个记录的关键字值大于索引表中的最大关键码,就对索引表中的最大关键字码更新。
参考文章链接
http://blog.csdn.net/wtfmonking/article/details/17337703
http://blog.csdn.net/xiaoping8411/article/details/7706381
http://blog.csdn.net/xiaoping8411/article/details/7706376
http://blog.csdn.net/wangyunyun00/article/details/23464359
http://blog.csdn.net/fovwin/article/details/9077017
基础算法-查找:线性索引查找(I)的更多相关文章
- 基础算法-查找:线性索引查找(II)
索引查找是在索引表和主表(即线性表的索引存储结构)上进行的查找. 索引查找的过程是: 1)首先根据给定的索引值K1,在索引表上查找出索引值等于K1的索引项,以确定对应子表在主表中的开始位置和长度. 2 ...
- Python 基础算法
递归 时间&空间复杂度 常见列表查找 算法排序 数据结构 递归 在调用一个函数的过程中,直接或间接地调用了函数本身这就叫做递归. 注:python在递归中没用像别的语言对递归进行优化,所以每一 ...
- Python <算法思想集结>之初窥基础算法
1. 前言 数据结构和算法是程序的 2 大基础结构,如果说数据是程序的汽油,算法则就是程序的发动机. 什么是数据结构? 指数据在计算机中的存储方式,数据的存储方式会影响到获取数据的便利性. 现实生活中 ...
- PHP基础算法
1.首先来画个菱形玩玩,很多人学C时在书上都画过,咱们用PHP画下,画了一半. 思路:多少行for一次,然后在里面空格和星号for一次. <?php for($i=0;$i<=3;$i++ ...
- c/c++面试总结---c语言基础算法总结2
c/c++面试总结---c语言基础算法总结2 算法是程序设计的灵魂,好的程序一定是根据合适的算法编程完成的.所有面试过程中重点在考察应聘者基础算法的掌握程度. 上一篇讲解了5中基础的算法,需要在面试之 ...
- c/c++面试指导---c语言基础算法总结1
c语言基础算法总结 1 初学者学习任何一门编程语言都必须要明确,重点是学习编程方法和编程思路,不是学习语法规则,语法规则是为编程实现提供服务和支持.所以只要认真的掌握了c语言编程方法,在学习其它的语 ...
- ACM基础算法入门及题目列表
对于刚进入大学的计算机类同学来说,算法与程序设计竞赛算是不错的选择,因为我们每天都在解决问题,锻炼着解决问题的能力. 这里以TZOJ题目为例,如果为其他平台题目我会标注出来,同时我的主页也欢迎大家去访 ...
- 基础算法(java版本)
Practice Author: Dorae Date: 2018年10月11日13:57:44 转载请注明出处 具体代码请移步git 基础算法 图 Prim Kruskal Dijkstra Flo ...
- Java基础算法
i++;++i; i--;--i; int a=5;int b=a++;++放在后面,表示先使用a的值,a再加1b=5,a=a+1,a=6 int c=5;int d=++c;++放在前面,表示先将c ...
随机推荐
- python基础学习笔记5--对象
对象(object) 1.对象(object): 面向对象程序设计重要术语. 对象的特性:多态性.封装性.继承性 >>def add(x,y): return x+y 对于很多类型的参数都 ...
- 一段关于 Unix、Linux 和 Windows 的暗黑史
“SCO 在言语上变得越来越好斗,而且还拒绝展示有关诉讼的任何证据,一切都似乎在表明,SCO只不过是在那里拉虎皮做大旗地狂言乱语.但是,微软 决不会轻易放弃这么可以一个利用这些狂言乱语的好机会.”20 ...
- 利用svg技术实现在线动画演示
搜索MDCC的论文,发现了这个站点,里面有演示动画,居然是通过svg来实现的. 分享给大家看看: 有空研究下,做一个类似的演示,展示一下OceanBase内部的常见操作. 展示一个svg做的游戏: h ...
- 动态子类化CComboBox以得到子控件EDIT及LISTBOX
动态子类化CComboBox以得到子控件EDIT及LISTBOX Joise.LI写于2004-4-6 ComboBox是比较常用的一个控件,有三种样式:CBS_SIMPLE(简单),CBS_DROP ...
- Android Studio 代码混淆
新建一个项目,Android Studio默认关闭代码混淆开关,在build.gradle文件中,如下图所示的minifyEnabled 开关,因此如果需要混淆代码,需将false改为true,然后在 ...
- jquery阻止默认滑动
$(".swiper-slide").click(function(){ var index = imgarr[$(this).index()]; var content = &q ...
- 【deep learning学习笔记】Recommending music on Spotify with deep learning
主要内容: Spotify是个类似酷我音乐的音乐站点.做个性化音乐推荐和音乐消费.作者利用deep learning结合协同过滤来做音乐推荐. 详细内容: 1. 协同过滤 基本原理:某两个用户听的歌曲 ...
- hdu 4741 Save Labman No.004(2013杭州网络赛)
http://blog.sina.com.cn/s/blog_a401a1ea0101ij9z.html 空间两直线上最近点对. 这个博客上给出了很好的点法式公式了...其实没有那么多的tricky. ...
- 《Effective C++》:条款48:理解力template
元编程
Template metaprogramming(TMP,模板元编程)这是写template-based C++规划.编译过程.template metaprogramming随着C++写模板程序,化 ...
- matlab画甘特图
近期为发小论文一直在研究作业调度问题,好不easy把数据搞出来了,结果又被画甘特图给难住了,查了各种资料.anygantt,highchart.Jfree chart等都试了,效果都不咋好.无意中留意 ...