Azure Databricks 第一篇:创建工作区、集群和Notebook
Azure Databricks是一个可扩展的数据分析平台,基于Apache Spark。Azure Databricks 工作区(Workspace)是一个交互式的环境,工作区把对象(notebook、library、dashboards、experiments)组织成文件夹,用于数据集成和数据分析。
一,Azure Databricks的基本概念
1,工作区是一个交互式的环境
工作区是一个交互式的环境,可以管理Databricks的集群、Notebook、Job等对象。
2,集群是运行Notebook和job的资源
在使用工作区中,要进行数据集成和数据分析,必须创建集群(Cluster),Cluser代表运行notebook和job的计算资源,并用于存储相应的配置信息。
Cluster有两种类型:通用(All-purpose)和job,all-purpose集群是交互式的,用于通用的数据集成和数据分析任务,而job类型的集群用于定时运行job。
job是一个非交互式的机制,用于立即或按照计划来运行notebook或library。job类型的集群在job开始时创建,在job完成时结束。
根据cluster的类型,把Azure Databricks的工作负载(workload)分为两个类型:data engineering (job) 和 data analytics (all-purpose)。
- 数据工程:(自动)工作负载在Job群集上运行,Azure Databricks作业计划程序为每个工作负载创建了一个工作群集。
- 数据分析:(交互式)工作负载在all-purpose集群上运行,交互式工作负载通常在Azure Databricks笔记本中运行命令,但是在现有的通用集群上运行作业也被视为交互式工作负载。
3,Notebook是一个基于Web的记事本
Notebook是一个包含可执行命令的记事本,用户可以在Notebook中编写Python命令,编辑命令,并执行命令,获得输出的结果,并可以对结果进行可视化处理,Notebook的功能和UI类似于Jupyter Notebook。
二,创建Workspace
通过Azure UI来创建工作区,从Azure Services中找到Azure Databricks。

创建工作区,选择订阅用于管理资源和成本,需要设置订阅(Subscription)和资源组(Resource group),选择定价策略(Pricing Tier)。

选择“Review + Create”,点击Create 按钮来创建工作区。等到工作区部署完成之后,打开Azure Databricks Service,点击“Launch Workspace”登录到工作区门户。

三,创建Spark Cluster
Spark Cluster可以看作是Databricks的计算资源,因此必须创建集群。
1,登录到工作区门户
登录(Launch)到新建的工作区门户中,从“Common Tasks”列表中点击“New Cluster”。
2,配置集群
Cluster Mode:集群的模式共有三种,High concurrency(高并发)、Standard(标准)和Single Node(单节点)。标准模式是推荐模式,通常用于单用户的集群。
Pool:Pool是一组空闲的随时可用的实例,可减少集群启动和自动缩放的时间。当连接到Pool的集群需要一个实例时,它首先尝试分配Pool的中一个实例,如果该Pool没有空闲的实例,那么该Pool将通过从实例提供者分配有ige新的实例来扩展,以满足集群的需求。集群释放实例后,它将返回到Pool中,并可以提供给其他集群使用。只有连接到Pool的集群才能使用该Pool的空闲实例。实例在Pool中处于空闲状态时是免费的。
Databricks Runtime:运行时版本配置,选择用于创建集群的image,运行时是在集群上运行的一组核心组件。
Enable autoscaling:勾选自动缩放,根据工作负载的不同,集群在最大节点数量和最小节点数量之间自动缩放。
Terminate after xx minutes of inactivity:当集群不活动时,延迟一定时间后,结束集群。
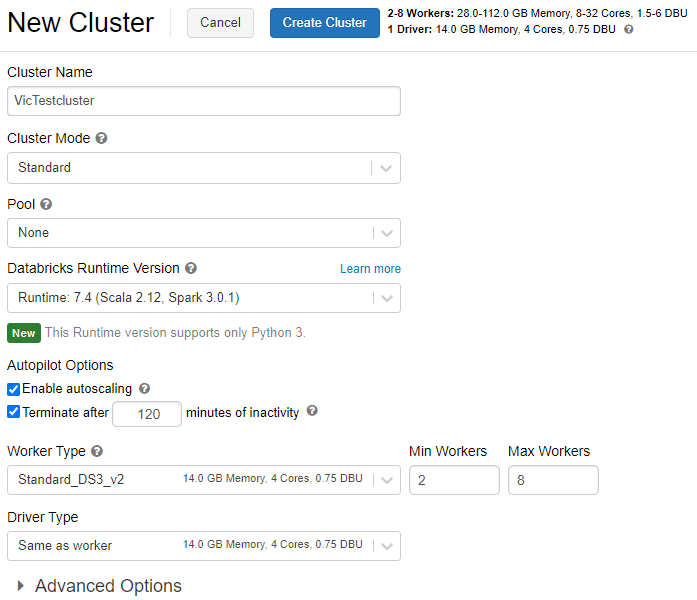
配置完成之后,点击顶部的“Create Clustere” 按钮创建集群。
四,创建Notebook
Notebook是一个包含可执行命令的记事本,用户可以在Notebook中编写Python命令,编辑命令,并执行命令,获得输出的结果,并可以对结果进行可视化处理。
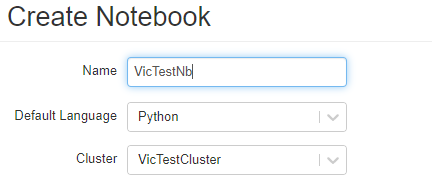
从Common Tasks中选择“New Notebook”,输入Notebook的Name,选择编程语言Python、选择集群,点击对话框底部的“Create”按钮创建Notebook。
在新建的Notebook中输入命令,打印"hello world",点击"Shift+Enter",执行命令

参考文档:
Azure Databricks 第一篇:创建工作区、集群和Notebook的更多相关文章
- Kafka【第一篇】Kafka集群搭建
Kafka初识 1.Kafka使用背景 在我们大量使用分布式数据库.分布式计算集群的时候,是否会遇到这样的一些问题: 我们想分析下用户行为(pageviews),以便我们设计出更好的广告位 我想对用户 ...
- 大数据之ES系列——第一篇 ElasticSearch2.2 集群安装部署
第一部分 安装准备 准备三台主机节点: hc11.spads 192.168.160.181 hc12.spads 192.168.160.182 hc13.spads 192.168.160 ...
- C#码农的大数据之路 - 使用Azure Management API创建HDInsight集群
Azure平台提供了几乎全线产品的API,可以使用第三方工具来进行管理.对于.NET更是提供封装好了的库方便使用C#等语言实现Azure的管理. 我们使用创建HDInsight集群为例来介绍使用C#管 ...
- 如何在CentOS上创建Kubernetes集群
欢迎大家前往腾讯云+社区,获取更多腾讯海量技术实践干货哦~ 本文由编程男孩 发表于云+社区专栏 介绍 Kubernetes(常简称为K8s)是用于自动部署.扩展和管理容器化(containerized ...
- 5 秒创建 k8s 集群 - 每天5分钟玩转 Docker 容器技术(115)
据说 Google 的数据中心里运行着超过 20 亿个容器,而且 Google 十年前就开始使用容器技术. 最初,Google 开发了一个叫 Borg 的系统(现在命令为 Omega)来调度如此庞大数 ...
- docker创建ceph集群
背景 Ceph官方现在提供两类镜像来创建集群,一种是常规的,每一种Ceph组件是单独的一个镜像,如ceph/daemon.ceph/radosgw.ceph/mon.ceph/osd等:另外一种是最新 ...
- 在 Azure 虚拟机上快速搭建 MongoDB 集群
MongoDB 是目前在 NoSQL 市场上非常受欢迎的一个数据库,本文介绍如何使用 Azure PowerShell 和 Azure CLI 在 Azure 虚拟机上搭建单节点 MongoDB(测试 ...
- 5 秒创建 k8s 集群[转]
据说 Google 的数据中心里运行着超过 20 亿个容器,而且 Google 十年前就开始使用容器技术. 最初,Google 开发了一个叫 Borg 的系统(现在命令为 Omega)来调度如此庞大数 ...
- 使用Kubeadm创建k8s集群之部署规划(三十)
前言 上一篇我们讲述了使用Kubectl管理k8s集群,那么接下来,我们将使用kubeadm来启动k8s集群. 部署k8s集群存在一定的挑战,尤其是部署高可用的k8s集群更是颇为复杂(后续会讲).因此 ...
随机推荐
- docker和k8s的概念-IaaS、PaaS、SaaS 的区别
docker和k8s 参考: 什么是Docker? Kubernetes概述 openstack,docker,mesos,k8s什么关系? IaaS.PaaS.SaaS的概念 SaaS:软件服务,S ...
- JVM(二)-内存区域之线程私有区
概述: 对于从事C.C++开发的程序员来说,在内存管理领域,他们既是拥有最高权力的"皇帝",又是从事最基础工作的劳动人民--既拥有每个对象的"所有权", 又担负 ...
- 蚂蚁上市员工人均一套大 House,阿里程序员身价和这匹配吗?
作者 | 硬核云顶宫 责编 | 伍杏玲 出品 | CSDN(ID:CSDNnews) 上周,蚂蚁集团迎来IPO,其发行价格将达到68.8元,总市值将突破2万亿元.市场对蚂蚁的成长性有着充分的信心,为了 ...
- 分享:经常说你精通C语言,看看这十道题你会不会解!
今天给大家分享我们在日常工作中可能遇到的疑问,不看答案,你是否有把握都能答对?让我们来试试吧~ 一.会输出"hello-std-out"? 参考答案: stdout和stder ...
- MySQL制作具有千万条测试数据的测试库
有时候需要制造一些测试的数据,以mysql官方给的测试库为基础,插入十万,百万或者千万条数据.利用一些函数和存储过程来完成. 官方给的测试库地址:https://github.com/datachar ...
- 7-1 Hashing
The task of this problem is simple: insert a sequence of distinct positive integers into a hash tabl ...
- UML第二次作业(代码互评)
博客班级 https://edu.cnblogs.com/campus/fzzcxy/2018SE2/ 作业要求 https://edu.cnblogs.com/campus/fzzcxy/2018S ...
- iptables SNAT 和DNAT的转化配置实验
原文链接:http://www.jb51.net/LINUXjishu/402441.html DNAT(Destination Network Address Translation,目的地址转换) ...
- springboot多模块项目搭建遇到的问题记录
废话不多说,直接上问题报错与解决方法. 问题报错一:(报错信息看下方代码) 问题原因:'com.company.logistics.service.company.CompanyService' 未找 ...
- 转:HTTP协议简介与在python中的使用详解
1. 使用谷歌/火狐浏览器分析 在Web应用中,服务器把网页传给浏览器,实际上就是把网页的HTML代码发送给浏览器,让浏览器显示出来.而浏览器和服务器之间的传输协议是HTTP,所以: HTML是一种用 ...