Vue3源码解析(computed-计算属性)
作者:秦志英
前言
上一篇文章中我们分析了Vue3响应式的整个流程,本篇文章我们将分析Vue3中的computed计算属性是如何实现的。
在Vue2中我们已经对计算属性了解的很清楚了,在Vue3中提供了一个computed的函数作为计算属性的API,下面我们来通过源码的角度去分析计算属性的运行流程。
computed
export function computed<T>(getter: ComputedGetter<T>): ComputedRef<T>
export function computed<T>(
options: WritableComputedOptions<T>
): WritableComputedRef<T>
export function computed<T>(
getterOrOptions: ComputedGetter<T> | WritableComputedOptions<T>
) {
let getter: ComputedGetter<T>
let setter: ComputedSetter<T>
if (isFunction(getterOrOptions)) {
getter = getterOrOptions
setter = NOOP
} else {
getter = getterOrOptions.get
setter = getterOrOptions.set
}
return new ComputedRefImpl(
getter,
setter,
isFunction(getterOrOptions) || !getterOrOptions.set
) as any
}
- 在最开始使用函数重载的方式允许
computed函数接受两种类型的参数:第一种是一个getter函数, 第二种是一个带get和set的对象。 - 接下就是在函数内部根据传入的不同类型的参数初始化函数内部的
getter和setter函数,如果传入的是一个函数类型的参数,那么getter就是这个函数,setter就是一个空的操作,如果传入的参数是一个对象,则getter就等于这个对象的get函数,setter就等于这个对象的set函数。 - 在函数的结尾返回了一个
new ComputedRefImpl,并将前面我们标准化后的参数传递给了这个构造函数。
下面我们就来分析一下ComputedRefImpl这个构造函数。
ComputedRefImpl
class ComputedRefImpl<T> {
// 缓存结果
private _value!: T
// 重新计算开关
private _dirty = true
public readonly effect: ReactiveEffect<T>
public readonly __v_isRef = true;
public readonly [ReactiveFlags.IS_READONLY]: boolean
constructor(
getter: ComputedGetter<T>,
private readonly _setter: ComputedSetter<T>,
isReadonly: boolean
) {
// 对传入的getter函数进行包装
this.effect = effect(getter, {
lazy: true,
// 调度执行
scheduler: () => {
if (!this._dirty) {
this._dirty = true
// 派发通知
trigger(toRaw(this), TriggerOpTypes.SET, 'value')
}
}
})
}
// 访问计算属性的时候 默认调用此时的get函数
get value() {
// 是否需要重新计算
if (this._dirty) {
this._value = this.effect()
this._dirty = false
}
// 访问的时候进行依赖收集 此时收集的是访问这个计算属性的副作用函数
track(toRaw(this), TrackOpTypes.GET, 'value')
return this._value
}
set value(newValue: T) {
this._setter(newValue)
}
}
ComputedRefImpl类在内部维护了_value和_dirty这两个非常重要的私有属性,其中_value使用用来缓存我们计算的结果,_dirty是用来控制是否需要重现计算。接下来我们来看一下这个函数的内部运行机制。
- 首先构造函数在初始化的时候使用了
effect函数对传入getter进行了一层包装(上一篇文章中我们分析过effect函数的作用就是将传入的函数变成可响应式的副作用函数),但是这里我们在effect中传入了一些配置参数,还记得前面我们分析trigger函数的时候有这一段代码:
const run = (effect: ReactiveEffect) => {
if (effect.options.scheduler) {
effect.options.scheduler(effect)
} else {
effect()
}
}
effects.forEach(run)
当属性值发生改变之后,会触发trigger函数进行派发更新,将所有依赖这个属性的effect函数循环遍历,使用run函数执行effect,如果effect的参数中配置了scheduler,则就执行scheduler函数,而不是执行依赖的副作用函数。当计算属性依赖的属性发生变化的时候,回执行包装getter函数的effect, 但是因为配置了scheduler函数,所以真正执行的是scheduler函数,在scheduler函数中并没有执行计算属性的getter函数求取新值,而是将_dirty设置为false,然后通知依赖计算属性的副作用函数进行更新, 当依赖计算属性的副作用函数收到通知的时候就会访问计算属性的get函数,此时会根据_dirty值来确定是否需要重新计算。
回到我们的这个构造函数中,只需要记得我们在构造函数初始化三个重要的点:第一:对传入的getter函数使用effect函数进行包装。第二:在使用effect包装的过程中,我们会执行getter函数,此时getter函数执行过程中对于访问到的属性会将当前的这个计算属性收集到对应的依赖集合中, 第三:传入了配置参数lazy和scheduler,这些配置参数在当前的这个计算属性所订阅的属性发生改变的时候,用来控制计算属性的调度时机。
- 接着我们继续分析
get value,当我们访问计算属性的值时候实际上访问的就是这个函数的返回值, 它会根据_dirty的值来判断是否需要重新计算getter函数,_dirty为true需要重新执行effect函数,并将effect的值置为false,否则就返回之前缓存的_value值。在访问计算属性值的阶段会调用track函数进行依赖收集,此时收集的是访问计算属性值的副作用函数, key始终是vlaue。 - 最后就是当设置计算属性的值的时候会执行set函数,然后调用我们传入的
_setter函数。
示例流程
至此计算属性的执行流程就分析完毕了,我们来结合一个示例来完整的过一遍整个流程:
<template>
<div>
<button @click="addNum">add</button>
<p>计算属性:{{computedData}}</p>
</div>
</template>
<script>
import { ref, watch,reactive, computed } from 'vue'
import { effect } from '@vue/reactivity'
export default {
name: 'App',
setup(){
const testData = ref(1)
const computedData = computed(() => {
return testData.value++
})
function addNum(){
testData.value += 10
}
return {
addNum,
computedData
}
},
}
</script>
下面是一张流程图,当点击页面中的按钮改变testData的value值时,发生的变化流程就是下面的红线部分。
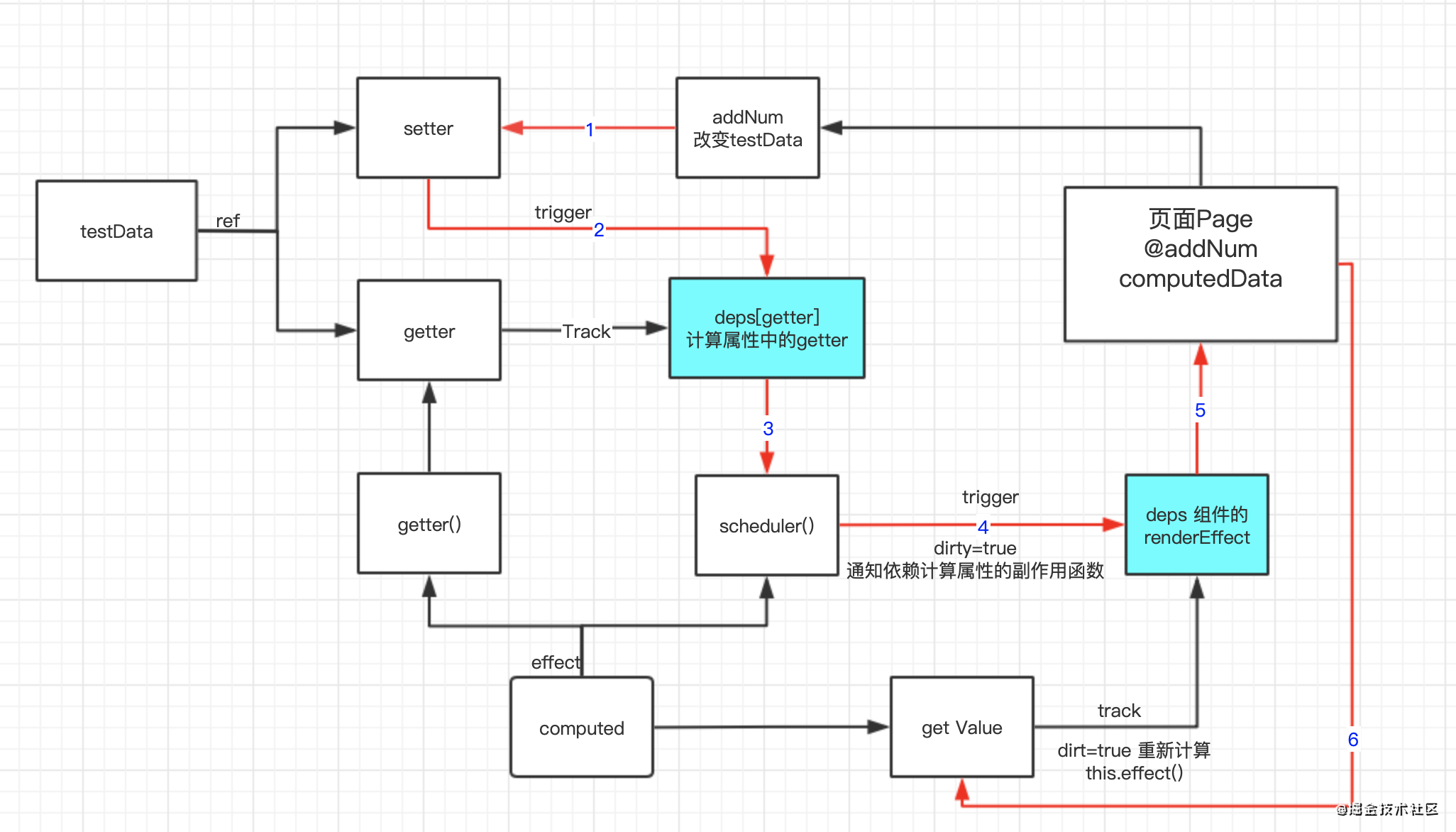
- 首先初始化页面的时候,testData经过ref()之后变成响应式数据,会对访问testData.value的值进行依赖收集,当testData.value的值发生变化的话,会对依赖这个值的依赖集合进行派发更新
- computed中传入了一个getter函数,getter函数内部有对testData.value的访问,此时当前的这个计算属性的副作用函数就订阅了testData.value的值,computed返回了一个值,而页面中的组件有对computed返回值的访问,页面的渲染副作用函数就订阅了computed的返回值,所以这个页面中有两个依赖集合。
- 当我们点击页面中的按钮,会改变testData.value的值,此时会通知订阅计算属性的副作用函数进行更新操作,由于我们在生成计算属性副作用的时候配置了
scheduler,所以执行的是scheduler函数,scheduler函数并没有立即执行getter函数进行重新计算,而是将ComputedRefImpl类内部的私有变量_dirty设置为true,然后通知订阅当前计算属性的副作用函数进行更新操作。 - 组件中的渲染副作用函数执行更新操作的时候会访问到
get value函数,函数内部会根据_dirty值来判断是否需要重新计算,由于前面的scheduler函数将_dirty设置为true所以此时会调用getter函数的副作用函数effect,这个时候才会重新计算并将结果返回,页面数据更新。
总结
计算属性两个最大的特点就是
- 延时计算 计算属性所依赖的值发生改变的时候并不会立即执行getter函数去重新计算新的结果,而是打开重新计算的开关并通知订阅计算属性的副作用函数进行更新。如果当前的计算属性没有依赖集合就不执行重新计算逻辑,如果有依赖触发计算属性的get,这个时候才会调用this.effect()进行重新计算。
- 缓存结果 当依赖的属性没有发生改变的,访问计算属性会返回之前缓存在
_value中的值。
对 Electron 感兴趣?请关注我们的开源项目 Electron Playground,带你极速上手 Electron。
我们每周五会精选一些有意思的文章和消息和大家分享,来掘金关注我们的 晓前端周刊。
我们是好未来 · 晓黑板前端技术团队。
我们会经常与大家分享最新最酷的行业技术知识。
欢迎来 知乎、掘金、Segmentfault、CSDN、简书、开源中国、博客园 关注我们。
Vue3源码解析(computed-计算属性)的更多相关文章
- vuex 源码解析(三) getter属性详解
有时候我们需要从store中的state中派生出一些状态,例如: <div id="app"> <p>{{reverseMessage}}</p> ...
- vue 源码解析computed
计算属性 VS 侦听属性 Vue 的组件对象支持了计算属性 computed 和侦听属性 watch 2 个选项,很多同学不了解什么时候该用 computed 什么时候该用 watch.先不回答这个问 ...
- Netty 出站缓冲区 ChannelOutboundBuffer 源码解析(isWritable 属性的重要性)
目录: 前言 ChannelOutboundBuffer 介绍 addMessage 方法 addFlush 方法 flush0 方法 缓冲区扩展思考 总结 每个 ChannelSocket 的 Un ...
- HashMap 源码解析(一)之使用、构造以及计算容量
目录 简介 集合和映射 HashMap 特点 使用 构造 相关属性 构造方法 tableSizeFor 函数 一般的算法(效率低, 不值得借鉴) tableSizeFor 函数算法 效率比较 tabl ...
- [源码解析] 深度学习流水线并行 GPipe(3) ----重计算
[源码解析] 深度学习流水线并行 GPipe(3) ----重计算 目录 [源码解析] 深度学习流水线并行 GPipe(3) ----重计算 0x00 摘要 0x01 概述 1.1 前文回顾 1.2 ...
- [源码解析] 深度学习流水线并行 PipeDream(2)--- 计算分区
[源码解析] 深度学习流水线并行 PipeDream(2)--- 计算分区 目录 [源码解析] 深度学习流水线并行 PipeDream(2)--- 计算分区 0x00 摘要 0x01 前言 1.1 P ...
- HTK计算mfcc/filter_bank源码解析
HTK计算mfcc/filter_bank源码解析 HTK可以用简单的 HCopy -C config -s scp 求取mfcc或者filter_bank 关于mfcc的原理在 http://my. ...
- [源码解析] PyTorch 流水线并行实现 (4)--前向计算
[源码解析] PyTorch 流水线并行实现 (4)--前向计算 目录 [源码解析] PyTorch 流水线并行实现 (4)--前向计算 0x00 摘要 0x01 论文 1.1 引论 1.1.1 数据 ...
- [源码解析] PyTorch 流水线并行实现 (5)--计算依赖
[源码解析] PyTorch 流水线并行实现 (5)--计算依赖 目录 [源码解析] PyTorch 流水线并行实现 (5)--计算依赖 0x00 摘要 0x01 前文回顾 0x02 计算依赖 0x0 ...
随机推荐
- 学习笔记:[算法分析]数据结构与算法Python版[基本的数据结构-上]
线性结构Linear Structure ❖线性结构是一种有序数据项的集合,其中 每个数据项都有唯一的前驱和后继 除了第一个没有前驱,最后一个没有后继 新的数据项加入到数据集中时,只会加入到原有 某个 ...
- MindManager使用教程:如何导出HTML5交互式导图
Mindmanager思维导图软件有着友好的用户界面以及丰富的思维导图制作功能.再搭配与Microsoft 软件的无缝集成功能,使得这款思维导图软件越来越受到职场人士的喜爱. 不仅是作为制作思维导图的 ...
- JUC并发工具包之Semaphore
目录 Semaphore (JDK) Timed Semaphore (Apache Commons) Semaphore vs. Mutex CodeRepo Semaphore (JDK) 我们使 ...
- Jmeter生成HTML测试报告
jmeter轻便小巧,运行速度快,但是缺少直观的可视化测试报告,并且生成测试报告操作稍微有点麻烦. GUI界面没有生成测试报告的功能,只能使用命令行生成测试报告.这里需要提到一个jtl的文件,它是生成 ...
- Leetcode 周赛#202 题解
本周的周赛题目质量不是很高,因此只给出最后两题题解(懒). 1552 两球之间的磁力 #二分答案 题目链接 题意 有n个空篮子,第i个篮子位置为position[i],现希望将m个球放到这些空篮子,使 ...
- K8ssandra——专为Kubernetes云原生数据而生
DataStax最近发布了K8ssandra--一个开源的.部署于Kubernetes上的Apache Cassandra全新发行版本.K8ssandra一站式集合了在Kubernetes上部署开源版 ...
- 树莓派4b 安装最新wiringpi库
树莓派4自带的wiringPi库默认是2.50,无法映射到gpio,所以需要更新到2.52才能与树莓派映射: 1. 安装自带的wiringPi库 $ Sudo apt-get install wiri ...
- Mysql主从同步机制
1.1 主从同步介绍和优点 *在多台数据服务器中,分为主服务器和从服务器.一台主服务器对应多台从服务器. *主服务器只负责写入数据,从服务器只负责同步主服务器的数据,并让外部程序读取数据 *主服务器写 ...
- JZOJ8月5日提高组反思
JZOJ8月5日提高组反思 再次炸了 虽然不是爆0 但也没差多少-- T1 想的DP 然后就打了 一开始是只能拿60的 后来想到了用前缀和优化 然后打完交了 最后一分钟测了一下空间 爆了 就赶紧把数组 ...
- 使用django的用户表进行登录管理
改写用户基本表 ... AUTH_USER_MODEL = 'appjwt.User' ... setting.py from django.db import models from django. ...