三、hadoop、yarn安装配置
本文hadoop的安装版本为hadoop-2.6.5
关闭防火墙
systemctl stop firewalld
一、安装JDK
1、下载java jdk1.8版本,放在/mnt/sata1目录下,
2、解压:tar -zxvf dk-8u111-linux-x64.tar.gz
3、vim /etc/profile
#在文件最后添加
export JAVA_HOME=/mnt/sata1/jdk1.8.0_111
export PATH=$PATH:$JAVA_HOME/bin
4、刷新配置
source /etc/profile
5、检测是否成功安装:java -version
二、安装Hadoop(单机版)
1、下载hadoop-2.6.5.tar.gz放在/mnt/sata1目录下
2、解压:tar -zxvf hadoop-2.6.5.tar.gz
三、修改配置文件
1、修改hadoop-env.sh,配置java jdk路径
echo $JAVA_HOME
/mnt/sata1/jdk1.8.0_111
#将默认的export JAVA_HOME=${JAVA_HOME}修改为:
export JAVA_HOME=/mnt/sata1/jdk1.8.0_111
2、修改core-site.xml,配置内容如下
<configuration>
<!-- 指定HDFS老大(namenode)的通信地址 -->
<property>
<!-- yang为主机名 -->
<name>fs.defaultFS</name>
<value>hdfs://yang:9000</value>
</property>
<!-- 指定hadoop运行时产生文件的存储路径 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/mnt/sata1/hadoop_data</value>
</property>
</configuration>
3、修改hdfs-site.xml,修改配置如下
<!-- 设置hdfs副本数量 -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
4、将hadoop添加到环境变量,然后更新一下环境变量:source /etc/profile
export HADOOP_HOME=/mnt/sata1/hadoop-2.6.5
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
5、刷新配置
source /etc/profile
6、配置免密(这里以单节点自己对自己免密)
1、创建dsa免密代码:ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
2、将生成的公钥发送给需要做免密的主机:
cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
7、进入/mnt/sata1/hadoop-2.6.5/bin进行格式化
./hdfs nameode -format
8、启动服务
start-dfs.sh
注:
如果没有配置环境变量,到目录/mnt/sata1/hadoop-2.6.5/bin启动(./
start-dfs.sh
)
9、

三、yarn(单机版)
1、修改mapred-site.xml 由于在配置文件目录(/mnt/sata1/hadoop-2.6.5/etc/hadoop)下没有,需要修改名称:mv mapred-site.xml.template mapred-site.xml
<configuration>
<!-- 通知框架MR使用YARN -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
2、修改yarn-site.xml,修改内容如下
<configuration>
<!-- reducer取数据的方式是mapreduce_shuffle -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>localhost</value>
</property>
</configuration>
localhost:主机名
3、启动yarn
cd /mnt/sata1/hadoop-2.6.5/
./start-yarn.sh
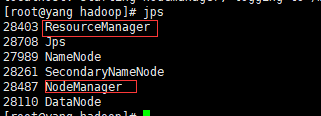
四、Hadoop(集群版)yarn集群版
1、修改hadoop-env.sh,配置java jdk路径
echo $JAVA_HOME
/mnt/sata1/jdk1.8.0_111
#将默认的export JAVA_HOME=${JAVA_HOME}修改为:
export JAVA_HOME=/mnt/sata1/jdk1.8.0_111
2、修改core-site.xml,配置内容如下
<configuration>
<!-- 指定HDFS老大(namenode)的通信地址 -->
<property>
<!-- yang为主机名 -->
<name>fs.defaultFS</name>
<value>hdfs://yang:9000</value>
</property>
<!-- 指定hadoop运行时产生文件的存储路径 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/mnt/sata1/hadoop_data</value>
</property>
</configuration>
3、修改hdfs-site.xml,修改配置如下
<!-- 设置hdfs副本数量 -->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>slave01:50090</value>
</property>
4、SecondaryNameNode与namenode的分开配置,新建一个masters文件,内容为secondnamenode所在节点
/mnt/hadoop/etc/hadoop
[root@master hadoop]# cat masters
slave01
同时在hdfs-site.xml文件加入:
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>slave01:50090</value>
</property>
4、配置yarn
1.修改hadoop配置目录:
复制文件: cp mapred-site.xml.templta mapred-site.xml
mapred-site.xm加入以下配置:
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
2.yarn-site.xml加入以下配置:
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
5、将hadoop的目录文件分发到其他主机
scp -r hadoop root@slave01:/mnt
scp -r hadoop root@slave02:/mnt
6、配置环境变量
export HADOOP_HOME=/mnt/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
7、进入/mnt/hadoop/bin进行格式化(在master所在节点执行)
./hdfs namenode -format
6、启动服务hdfs、yarn
start-dfs.sh start-yarn.sh
注:
如果没有配置环境变量,到目录/mnt/hadoop/bin启动(./
start-dfs.sh
)
三、hadoop、yarn安装配置的更多相关文章
- Hadoop Yarn环境配置
抄一个可行的Hadoop Yarn环境配置.用的官方的2.2.0版本. http://www.jdon.com/bigdata/yarn.html Hadoop 2.2新特性 将Mapreduce框架 ...
- Hadoop 2.x(YARN)安装配置LZO
今天尝试在Hadoop 2.x(YARN)上安装和配置LZO,遇到了很多坑,网上的资料都是基于Hadoop 1.x的,基本没有对于Hadoop 2.x上应用LZO,我在这边记录整个安装配置过程 1. ...
- Hadoop的安装配置(一)
一.Hadoop的安装①Hadoop运行的前提是本机已经安装了JDK,配置JAVA_HOME变量②在Hadoop中启动多种不同类型的进程 例如NN,DN,RM,NM,这些进程需要进行通信 ...
- Storm on Yarn 安装配置
1.背景知识 在不修改Storm任何源代码的情况下,让Storm运行在YARN上,最简单的实现方法是将Storm的各个服务组件(包括Nimbus和Supervisor),作为单独的任务运行在YARN上 ...
- Hadoop Yarn 安装
环境:Linux, 8G 内存.60G 硬盘 , Hadoop 2.2.0 为了构建基于Yarn体系的Spark集群.先要安装Hadoop集群,为了以后查阅方便记录了我本次安装的详细步骤. 事前准备 ...
- Hadoop单机安装配置过程:
1. 首先安装JDK,必须是sun公司的jdk,最好1.6版本以上. 最后java –version 查看成功与否. 注意配置/etc/profile文件,在其后面加上下面几句: export JAV ...
- Hadoop详细安装配置过程
步骤一:基础环境搭建 1.下载并安装ubuntukylin-15.10-desktop-amd64.iso 2.安装ssh sudo apt-get install openssh-server op ...
- 【大数据】Hadoop单机安装配置
1.解压缩hadoop-2.7.6.tar.gz到/home/hadoop/Soft目录中 2.创建软链接,方便hadoop升级 ln -s /home/hadoop/Soft/hadoop-2.7 ...
- Hadoop简单安装配置
Hadoop开始设计以Linux平台为运行目标,所以这里推荐在Linux发行版比如Ubuntu进行安装,目前已经有Hadoop for Windows出来,大家自行搜下文章. Hadoop运行模式分为 ...
随机推荐
- 第11.9节 Python正则表达式的贪婪模式和非贪婪模式
在使用正则表达式时,匹配算法存在贪婪模式和非贪婪模式两种模式,在<第11.8节 Pytho正则表达式的重复匹配模式及元字符"?". "*". " ...
- PyQt学习随笔:重写setData方法截获Model/View中视图数据项编辑的注意事项
根据<PyQt学习随笔:Model/View中视图数据项编辑变动实时获取变动数据的方法>可以重写从PyQt的Model类继承的setData方法来实时截获View中对数据的更改,但需要注意 ...
- PyQt(Python+Qt)学习随笔:Designer中的QDialogButtonBox的StandardButtons标准按钮
在Qt Designer中,可以在界面中使用QDialogButtonBox来配置一组按钮进行操作,Qt中为QDialogButtonBox定义了一组常用的标准按钮,可以在Designer中直接在St ...
- 最简单的Go Dockerfile编写姿势,没有之一!
1. Dockerfile一些额外注意点 选择最简单的镜像 比如alpine,整个镜像5M左右 设置镜像时区 RUN apk add --no-cache tzdata ENV TZ Asia/Sha ...
- 九、git学习之——git基本命令全总结
初始化一个Git仓库,使用git init命令. 添加文件到Git仓库,分两步: git add <file>,注意,可反复多次使用,添加多个文件: 使用命令git commit,完成. ...
- Vue--子组件相互传参
引用了element做按钮组件 父组件 创建子组件公用的空vue变量,为pubVue,并传给需要互相传参/互相调用方法的两个子组件 <template> <div> <b ...
- uniapp-父组件数组变化同步子组件视图渲染
项目中子组件封装的是一个picker,父组件需要传数组到子组件中. 如果父组件的数组出现变更,视图中的子组件或许不能直接刷新渲染,需要反复弹起几下才能看到. 试过深度监听,但都没有用,ref也不知道为 ...
- 【Django Python版本对应】
使用Python36 时应该使用Django版本1.11.4 pip install django==1.11.4 版本对应表: Django version Python versions 1.8 ...
- 前端:css3的过渡与动画
一.css3过渡知识 (一).概述 1.CSS3过渡是元素从一种样式逐渐改变为另一种的效果. 2.实现过渡效果的两个要件: 规定把效果添加到那个css属性上. 规定效果时长 定义 ...
- 一段小代码秒懂C++右值引用和RVO(返回值优化)的误区
关于C++右值引用的参考文档里面有明确提到,右值引用可以延长临时变量的周期.如: std::string&& r3 = s1 + s1; // okay: rvalue referen ...