Netty(二)Netty 与 NIO 之前世今生
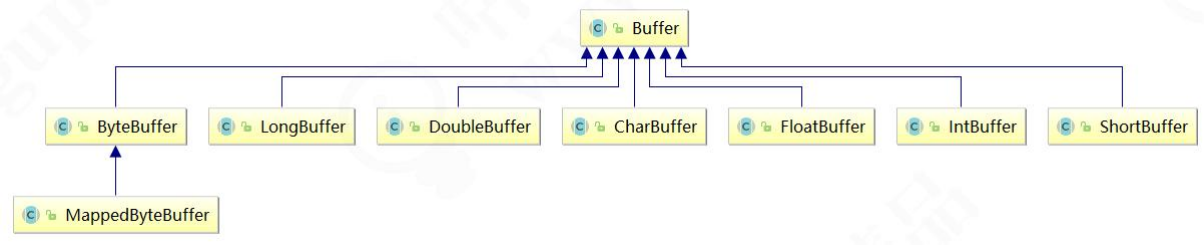
package com.lf.io;
import java.nio.IntBuffer;
public class IntBufferDemo {
public static void main(String[] args) {
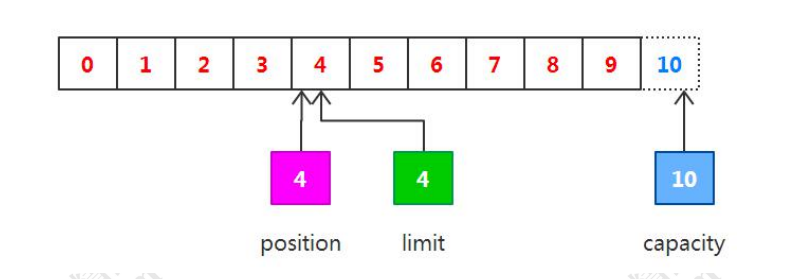
// 分配新的 int 缓冲区,参数为缓冲区容量
// 新缓冲区的当前位置将为零,其界限(限制位置)将为其容量。它将具有一个底层实现数组,其数组偏移量将为零。
IntBuffer buffer = IntBuffer.allocate(8);
for (int i = 0; i < buffer.capacity(); ++i) {
int j = 2 * (i + 1);
// 将给定整数写入此缓冲区的当前位置,当前位置递增
buffer.put(j);
}
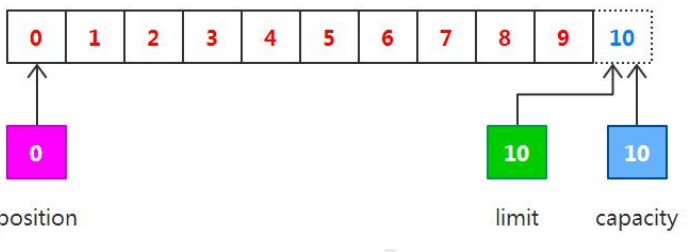
// 重设此缓冲区,将限制设置为当前位置,然后将当前位置设置为 0
buffer.flip();
// 查看在当前位置和限制位置之间是否有元素
while (buffer.hasRemaining()) {
// 读取此缓冲区当前位置的整数,然后当前位置递增
int j = buffer.get();
System.out.print(j + " ");
}
}
}
输出:2 4 6 8 10 12 14 16
package com.lf.io; import java.io.FileInputStream;
import java.nio.Buffer;
import java.nio.ByteBuffer;
import java.nio.channels.FileChannel; public class BufferDemo {
public static void main(String args[]) throws Exception {
//这用用的是文件 IO 处理
FileInputStream fin = new FileInputStream("E://test.txt");
//创建文件的操作管道
FileChannel fc = fin.getChannel();
//分配一个 10 个大小缓冲区,说白了就是分配一个 10 个大小的 byte 数组
ByteBuffer buffer = ByteBuffer.allocate(10);
output("初始化", buffer);
//先读一下
fc.read(buffer);
output("调用 read()", buffer);
//准备操作之前,先锁定操作范围
buffer.flip();
output("调用 flip()", buffer);
//判断有没有可读数据
while (buffer.remaining() > 0) {
byte b = buffer.get();
System.out.print(((char) b));
}
output("调用 get()", buffer);
//可以理解为解锁
buffer.clear();
output("调用 clear()", buffer);
//最后把管道关闭
fin.close();
} //把这个缓冲里面实时状态给答应出来
public static void output(String step, Buffer buffer) {
System.out.println(step + " : ");
//容量,数组大小
System.out.print("capacity: " + buffer.capacity() + ", ");
//当前操作数据所在的位置,也可以叫做游标
System.out.print("position: " + buffer.position() + ", ");
//锁定值,flip,数据操作范围索引只能在 position - limit 之间
System.out.println("limit: " + buffer.limit());
System.out.println();
}
}
输出:
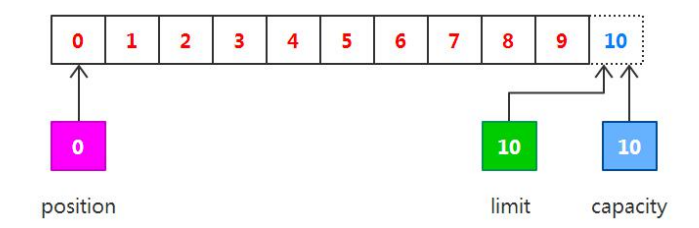
初始化 :
capacity: 10, position: 0, limit: 10 调用 read() :
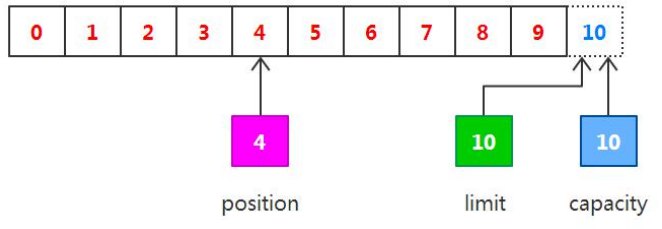
capacity: 10, position: 4, limit: 10 调用 flip() :
capacity: 10, position: 0, limit: 4 LFGB调用 get() :
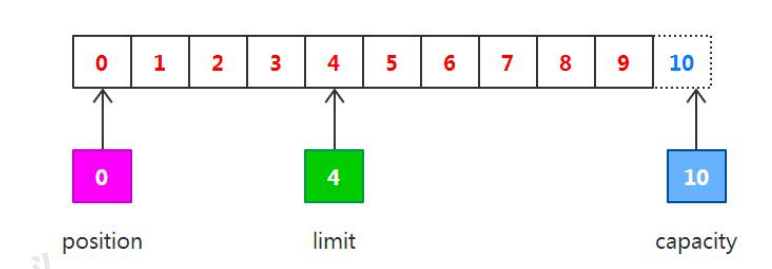
capacity: 10, position: 4, limit: 4 调用 clear() :
capacity: 10, position: 0, limit: 10 Process finished with exit code 0
/**
* 手动分配缓冲区
*/
public class BufferWrap {
public void myMethod() {
// 分配指定大小的缓冲区
ByteBuffer buffer1 = ByteBuffer.allocate(10);
// 包装一个现有的数组
byte array[] = new byte[10];
ByteBuffer buffer2 = ByteBuffer.wrap(array);
}
}
package com.lf.io; import java.nio.ByteBuffer; /*** 缓冲区分片 */
public class BufferSlice {
static public void main(String args[]) throws Exception {
ByteBuffer buffer = ByteBuffer.allocate(10);
// 缓冲区中的数据 0-9
for (int i = 0; i < buffer.capacity(); ++i) {
buffer.put((byte) i);
}
// 创建子缓冲区
buffer.position(3);
buffer.limit(7);
ByteBuffer slice = buffer.slice();
// 改变子缓冲区的内容
for (int i = 0; i < slice.capacity(); ++i) {
byte b = slice.get(i);
b *= 10;
slice.put(i, b);
}
buffer.position(0);
buffer.limit(buffer.capacity());
while (buffer.remaining() > 0) {
System.out.println(buffer.get());
}
}
}
输出:
0
1
2
30
40
50
60
7
8
9
package com.lf.io;
import java.nio.ByteBuffer;
public class ReadOnlyBuffer {
static public void main(String args[]) throws Exception {
ByteBuffer buffer = ByteBuffer.allocate(10);
// 缓冲区中的数据 0-9
for (int i = 0; i < buffer.capacity(); ++i) {
buffer.put((byte) i);
}
// 创建只读缓冲区
ByteBuffer readonly = buffer.asReadOnlyBuffer();
// 改变原缓冲区的内容
for (int i = 0; i < buffer.capacity(); ++i) {
byte b = buffer.get(i);
b *= 10;
buffer.put(i, b);
}
readonly.position(0);
readonly.limit(buffer.capacity());
// 只读缓冲区的内容也随之改变
while (readonly.remaining() > 0) {
System.out.println(readonly.get());
}
}
}
package com.lf.io; import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.nio.ByteBuffer;
import java.nio.channels.FileChannel; public class DirectBuffer {
static public void main(String args[]) throws Exception {
//首先我们从磁盘上读取刚才我们写出的文件内容
String infile = "E://test.txt";
FileInputStream fin = new FileInputStream(infile);
FileChannel fcin = fin.getChannel();
//把刚刚读取的内容写入到一个新的文件中
String outfile = String.format("E://testcopy.txt");
FileOutputStream fout = new FileOutputStream(outfile);
FileChannel fcout = fout.getChannel();
// 使用 allocateDirect,而不是 allocate
ByteBuffer buffer = ByteBuffer.allocateDirect(1024);
while (true) {
buffer.clear();
int r = fcin.read(buffer);
if (r == -1) {
break;
}
buffer.flip();
fcout.write(buffer);
}
}
}
package com.lf.io; import java.io.RandomAccessFile;
import java.nio.MappedByteBuffer;
import java.nio.channels.FileChannel; /**
* IO 映射缓冲区
*/
public class MappedBuffer {
static private final int start = 0;
static private final int size = 1024; static public void main(String args[]) throws Exception {
RandomAccessFile raf = new RandomAccessFile("E://test.txt", "rw");
FileChannel fc = raf.getChannel();
//把缓冲区跟文件系统进行一个映射关联
// 只要操作缓冲区里面的内容,文件内容也会跟着改变
MappedByteBuffer mbb = fc.map(FileChannel.MapMode.READ_WRITE, start, size);
mbb.put(0, (byte) 97);
mbb.put(1023, (byte) 122);
raf.close();
}
}


package com.lf.io; import java.io.FileInputStream;
import java.nio.ByteBuffer;
import java.nio.channels.FileChannel; public class FileInputDemo {
static public void main(String args[]) throws Exception {
FileInputStream fin = new FileInputStream("E://test.txt");
// 获取通道
FileChannel fc = fin.getChannel();
// 创建缓冲区
ByteBuffer buffer = ByteBuffer.allocate(1024);
// 读取数据到缓冲区
fc.read(buffer);
buffer.flip();
while (buffer.remaining() > 0) {
byte b = buffer.get();
System.out.print(((char) b));
}
fin.close();
}
}
package com.lf.io; import java.io.FileOutputStream;
import java.nio.ByteBuffer;
import java.nio.channels.FileChannel; public class FileOutputDemo {
static private final byte message[] = {83, 111, 109, 101, 32, 98, 121, 116, 101, 115, 46}; static public void main(String args[]) throws Exception {
FileOutputStream fout = new FileOutputStream("E://test.txt");
FileChannel fc = fout.getChannel();
ByteBuffer buffer = ByteBuffer.allocate(1024);
for (int i = 0; i < message.length; ++i) {
buffer.put(message[i]);
}
buffer.flip();
fc.write(buffer);
fout.close();
}
}


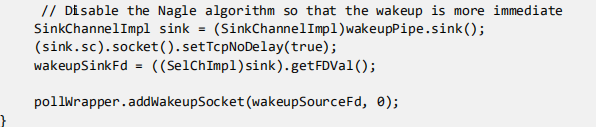
看看 SelectorProvider.provider()做了什么:





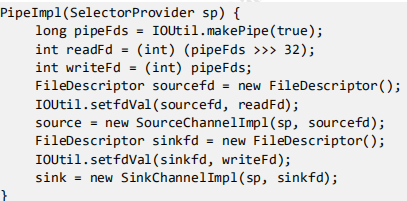
再看看怎么 new PipeImpl()的:
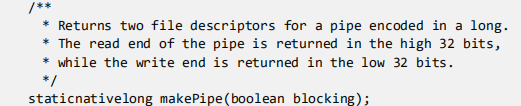
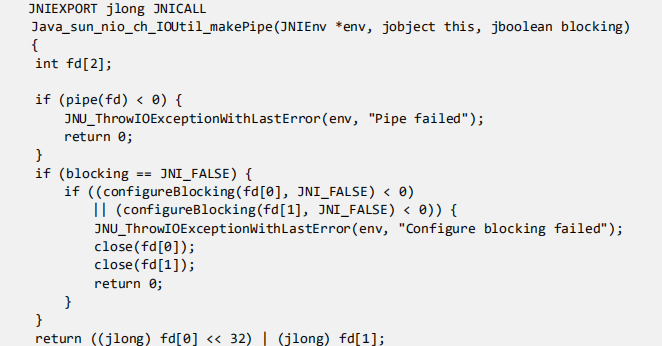

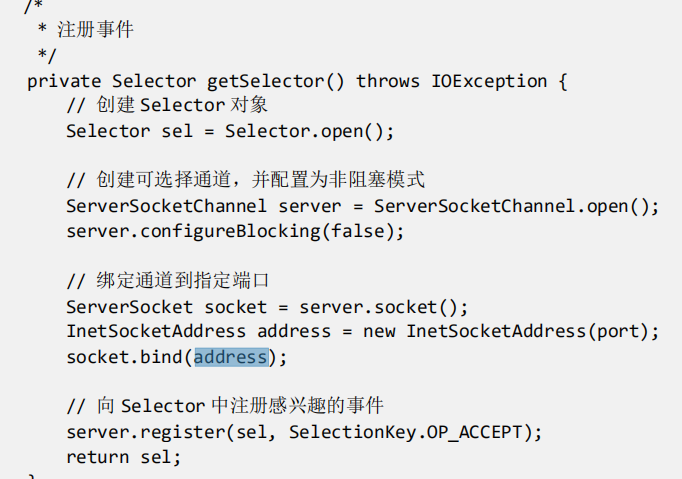
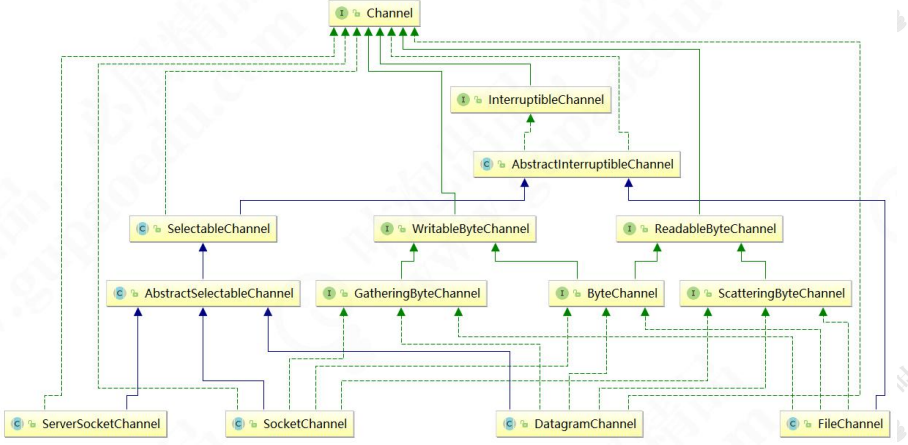
正如这段注释所描述的:





然后通过 serverChannel1.register(selector, SelectionKey.OP_ACCEPT);把 selector 和 channel 绑定在一起,也就是把 new



这个 poll0()会监听 pollWrapper 中的 FD 有没有数据进出,这会造成 IO 阻塞,直到有数据读写事件发生。比如,由于

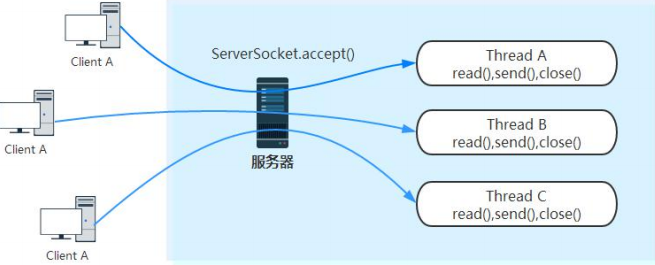
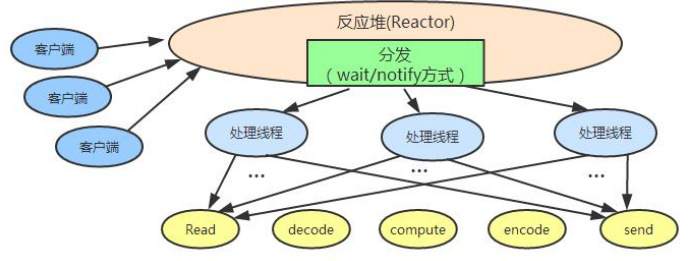
Netty(二)Netty 与 NIO 之前世今生的更多相关文章
- 2.Netty 与 NIO 之前世今生
2.Netty 与 NIO 之前世今生 本文围绕一下几点阐述: 1. NIO 的核心组件 Buffer.Selector.Channel. 2.何谓多路复用? 3.Netty 支持的功能与特性. ...
- Netty学习笔记(一)——nio基础
Netty简单认识: 1) Netty 是由JBOSS 提供的一个Java 开源框架. 2) Netty 是一个异步的.基于事件驱动的网络应用框架,用以快速开发高性能.高可靠性的网络I0 程序. 3) ...
- Netty学习——Netty和Protobuf的整合(二)
Netty学习——Netty和Protobuf的整合(二) 这程序是有瑕疵的,解码器那里不通用,耦合性太强,有两个很明显的问题,但是要怎么解决呢?如:再加一个内部类型 Person2,之前的代码就不能 ...
- 【Netty】Netty传输
一.前言 在简单学习了Netty中的组件后,接着学习Netty中数据的传输细节. 二.传输 2.1 传输示例 Netty中的数据传输都是使用的字节类型,下面通过一个实例进行说明,该实例中服务器接受请求 ...
- Netty学习——Netty和Protobuf的整合(一)
Netty学习——Netty和Protobuf的整合 Protobuf作为序列化的工具,将序列化后的数据,通过Netty来进行在网络上的传输 1.将proto文件里的java包的位置修改一下,然后再执 ...
- 【Netty】Netty入门之WebSocket小例子
服务端: 引入Netty依赖 <!-- netty --> <dependency> <groupId>io.netty</groupId> <a ...
- 002——Netty之Netty介绍
Netty出现背景 Java NIO难用 据说存在bug 业界其他NIO框架不成熟 Netty主要解决两个相应关注领域 (1)异步和事件驱动的实现. (2)一组设计模式,将应用逻辑与网络层解耦. 特性 ...
- JAVA I/O(二)文件NIO
一.Unix五种I/O模型 读取和写入文件I/O操作都是调用操作系统提高的接口,对磁盘I/O来说,一般是将数据从磁盘拷贝到内核空间,然后从内核空间拷贝到用户空间.为了减小I/O时间,一般内核空间存在高 ...
- 【netty】(1)---BIO NIO AIO演变
BIO NIO AIO演变 Netty是一个提供异步事件驱动的网络应用框架,用以快速开发高性能.高可靠的网络服务器和客户端程序.Netty简化了网络程序的开发,是很多框架和公司都在使用的技术. Net ...
随机推荐
- Jmeter接口自动化测试系列之函数使用及扩展
介绍一下Jmeter自带函数的使用和 函数扩展,来满足测试工作中的各种需求! Jmeter自带函数 点击函数帮助助手图标,弹出函数助手框,可以选择各种各样的函数 举例: _Random 获取随机数,可 ...
- git branch --set-upstream-to=
test@uat:/usr/server/app_server# git config --local -lcore.repositoryformatversion=0core.filemode=tr ...
- 键相同,比较两个map中的值是否相同
获取.排序.比较两个Map中相同key对应value值 /** * * @param hashMap 原数据 * @param hashMap2 需要比较的数据 * @return */ privat ...
- C++ Primer Plus读书笔记(六)分支语句和逻辑运算符
1. 以上均包含在cctype中 1 #include<cctype> 2 //#include<ctype.h> 2.文件操作 (1)头文件 1 #include<fs ...
- 济南学校D1T3_hahaha
[问题描述] 小Q对计算几何有着浓厚的兴趣.他经常对着平面直角坐标系发呆,思考一些有趣的问题.今天,他想到了一个十分有意思的题目: 首先,小Q会在轴正半轴和轴正半轴分别挑选个点.随后,他将轴的点与轴的 ...
- java小技巧
String 转 Date String classCode = RequestHandler.getString(request, "classCode"); SimpleDat ...
- 数据分析中常用的Excel函数
数据分析中excel是一个常见且基础的数据分析工具,要想掌握好它,学会使用其中的常用函数是一个绕不过去的坎.从网上搜集的资料来说,基本上确定了数据分析中Excel的常用函数有以下这六类 数学函数:SU ...
- MySQL按照(windows)及常用命令
MySQL语法规则 关键字与函数名称全部大写 数据库名称.表名称.字段名称全部小写 SQL 语句必须以分号结尾 MySQL安装 MySQL配置: 在cmd中输入 mysql,提示['mysql' 不是 ...
- Hadoop优势,组成的相关架构,大数据生态体系下的模式
Hadoop优势,组成的相关架构,大数据生态体系下的模式 一.Hadoop的优势 二.Hadoop的组成 2.1 HDFS架构 2.2 Yarn架构 2.3 MapReduce架构 三.大数据生态体系 ...
- redis防止重复提交
public interface DistributedLock { boolean getLock(String var1, String var2, int var3);//加锁 void unL ...