ElasticSearch 7.x 学习
ElasticSearch 7.x
一、前言
ElasticSearch 是一个基于 Lunece 的开源搜索引擎。Lunece 是目前为止最先进、性能最好、功能最全的搜索引擎库。
ElasticSearch 用 RESTful API 来隐藏 Lunece 的复杂性。
ES 创始人:Shay Banon,项目起源是老婆想弄一个搜索菜谱的软件。
Spring 项目的创始人:Rod Jhonson。ES 项目早期的投资人。
doug cutting:是 Apache Lunece 的作者,也是 hadoop 的创始人之一。
Lucene 是一套信息检索工具包! jar 包!不包含搜索引擎系统!
Lucene 和 ElasticSearch 的关系:
ElasticSearch 是基于 Lucune 做了一些封装和增强。
1.1、正向索引和倒排索引
正向索引和倒排索引是在搜索领域中非常重要的名词。
1.txt
我是小明,我喜欢看剧和打球
2.txt
我是小张,我喜欢看剧和玩游戏
正向索引和倒排索引在使用时都会进行分词处理,什么是分词处理呢?
分词处理:将一句话拆成中文语义的一个个词。
1.1.1、正向索引
如果使用的是正向索引,经过分词处理后的两个文件内容是:
1.txt
我 是 小明 我 喜欢 看 看剧 和 打 打球
2.txt
我 是 小张 我 喜欢 看 看剧 和 玩游戏 游戏
然后如果我们查询条件是喜欢,那么会从文章开头开始找喜欢,找到就将文档加入结果集,如果文本内容很多,会耗费大量时间。
1.1.2、倒排索引
如果使用的是倒排索引,经过分词处理后,会按照分词和文档进行映射:
| 关键词 | 文档 |
|---|---|
| 我 | 1.txt, 2.txt |
| 是 | 1.txt, 2.txt |
| 小明 | 1.txt |
| 小张 | 2.txt |
| 喜欢 | 1.txt, 2.txt |
| 看 | 1.txt, 2.txt |
| 看剧 | 1.txt, 2.txt |
| 和 | 1.txt, 2.txt |
| 打 | 1.txt |
| 打球 | 1.txt |
| 玩游戏 | 2.txt |
| 游戏 | 2.txt |
然后搜索时先找关键字,比如搜索喜欢,直接在关键词找到喜欢这个词。然后找到对应的文档。
二、安装
ElasticSearch:分布式搜索引擎
Kibana:ElasticSearch 可视化界面
Logstash:对数据进行采集、过滤、和输出。
movielens 数据集:https://grouplens.org/datasets/movielens/
导入数据:
三、ES 基本概念
3.1、索引
某一类文档的集合,可以类比一个数据库(或者数据库表)
3.2、文档
具体的一条数据。
{
"_index" : "movies", // 索引名
"_type" : "_doc", // 类型
"_id" : "42015", // id
"_score" : 1.0,
"_source" : { // 存放具体的数据
"id" : "42015",
"genre" : [
"Action",
"Adventure",
"Comedy",
"Drama",
"Romance"
],
"title" : "Casanova",
"year" : 2005,
"@version" : "1"
}
}
3.4、mapping
mapping 是 ES 每一个文档的约束信息,例如属性的类型,是否能被索引等。
3.5、DSL
DSL 是 ES 的查询语言。
3.6 传统关系型数据库和 ES 的对比
关系型数据库与 ES 进行对比。
| DBMS | ElasticSearch |
|---|---|
| database | Index |
| table | type(在7.0之后都是固定值_doc) |
| Row | Docment |
| Column | Field |
| Schema | Mapping |
| SQL | DSL |
一个索引想像成一个数据库,一个数据库只有一张表 _doc,一张索引有多个文档(记录),一个文档有多个字段(列)。
四
4.1、基本 CRUD
查看所有索引:
GET _cat/indices
查看某个索引的数据:
# GET 索引名/_search
GET movies/_search
查看某个索引下有多少条数据:
# 语法:GET 索引名/_count
GET movies/_count
查看指定 id 的文档的数据:
# 语法:GET 索引名/_doc/ID
GET movies/_doc/38701
添加一个文档:
POST 索引名/_doc/文档ID
{
"key1": "value1",
"key2": "value2"
...
}
添加一个文档,指定 ID,如果 ID 已经有了会报错,没有会创建一个文档:
POST 索引名/_create/文档ID
{
"key1": "value1",
"key2": "value2"
...
}
修改一个文档结构:
POST 索引名/_update/文档ID
{
"doc": {
"key1": "value1",
"key2": "value2"
...
}
}
删除指定文档 ID 的文档:
DELETE 索引名/_doc/文档ID
删除索引:
DELETE 索引名
批量插入:
POST user/_bulk
{"index": {"_id": "1"}}
{"firstname": "li"}
{"index": {"_id": "2"}}
{"firstname": "ya"}
{"index": {}}
{"firstname": "ya"}
查询,数组返回
GET _mget
{
"docs": [
{"_index": "user", "_id": "1"},
{"_index": "user", "_id": "2"},
{"_index": "user", "_id": "kgu6mHYB-tSK-znPeUte"}
]
}
4.2、ES 的 URI 查询
查询内容有 2012 的文档:
GET movies/_search?q=2012
查询 title 属性有 2012 的文档:
GET movies/_search?q=2012&df=title
上面可以简写为:
GET movies/_search?q=title:2012
包含 beautiful 或 mind 的:
GET movies/_search?q=title:beautiful mind
只包含 beautiful 不包含 mind:
GET movies/_search?q=title:(beautiful -mind)
既包含 beautiful 又包含 mind:
GET movies/_search?q=title:(beautiful AND mind)
AND 必须大写,小写会当成一个条件。
获取一个短语是 beautiful mind 的:
GET movies/_search?q=title:"beautiful mind"
分页,from=从第几条开始,从第一条开始 from=0,size=总共要查出几条数据
GET movies/_search?q=title:2012&from=1&size=3
范围查询:
# 语法:GET 索引名/_search?q=属性名:比较运算符 条件
GET movies/_search?q=year:>=2016
查询电影名字包含 beautiful 或 mind,并且上映的年份在 [1990, 1992] 的所有电影
GET movies/_search?q=year:(>=1990 AND <=1992) AND title:beautiful mind
查询年份大于 2011 小于等于 2013,后边的括号只能是中括号:
GET movies/_search?q=year:{2011 TO 2013]
查看 title 为 min加上一个随机的字符的数据:
GET movies/_search?q=title:min?
?可以代表一个字符。
查看 title 为 min加上一个或多个随机的字符的数据:
GET movies/_search?q=title:mi*
可以代表多个字符。
五、Analysis
Analysis 只是一个概念,就是文本分析,将全文本转换为一系列单词的过程,也叫分词。Analysis 是通过 analyzer(分词器)来实现的,ES 内部有很多定义好的分词器,也可以使用自定义的分词器。
除了在数据写入的时候将词条进行转换,查询的时候也会使用分析器对语句进行分析。
Aynalysis 是由三部分组成:
<p>Hello a World, the world is beautiful</p>
1、Character Filter:将文本中的 html 标签剔除掉。
2、Tokenizer:按照规则进行分词,在英文中按照空格分词。
3、Token Filter:去掉 stop word(停顿词,a an the is are等),然后转换为小写。
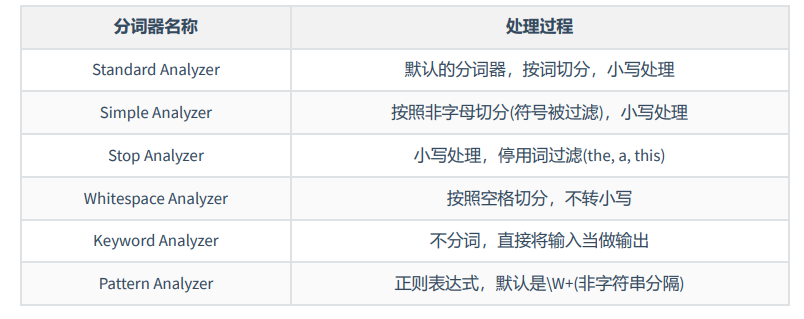
5.1、内置分词器
5.2、内置分词器使用示例
GET _analyze
{
"analyzer":"standard",
"text":"Then I will take care of your life"
}
结果:
{
"tokens" : [
{
"token" : "then",
"start_offset" : 0,
"end_offset" : 4,
"type" : "<ALPHANUM>",
"position" : 0
},
{
"token" : "i",
"start_offset" : 5,
"end_offset" : 6,
"type" : "<ALPHANUM>",
"position" : 1
},
{
"token" : "will",
"start_offset" : 7,
"end_offset" : 11,
"type" : "<ALPHANUM>",
"position" : 2
},
{
"token" : "take",
"start_offset" : 12,
"end_offset" : 16,
"type" : "<ALPHANUM>",
"position" : 3
},
{
"token" : "care",
"start_offset" : 17,
"end_offset" : 21,
"type" : "<ALPHANUM>",
"position" : 4
},
{
"token" : "of",
"start_offset" : 22,
"end_offset" : 24,
"type" : "<ALPHANUM>",
"position" : 5
},
{
"token" : "your",
"start_offset" : 25,
"end_offset" : 29,
"type" : "<ALPHANUM>",
"position" : 6
},
{
"token" : "life",
"start_offset" : 30,
"end_offset" : 34,
"type" : "<ALPHANUM>",
"position" : 7
}
]
}
六、ResquestBody 深入探索
ES 是进行不了复杂的查询的,所以有了 ResquestBody 查询。
GET movies/_search
{
"query": {
"match": {
"title": "beautiful mind"
}
}
}
在说 Analysis 的时候,说不仅仅在输入的时候会做分词处理,查询的时候也会。在查询的时候会将 beautiful mind 按照 Ananlysis 的三步分词处理的方式,最后会拆成``beautiful 和mind,然后进行查询,所以只要结果中包含 beautiful或mind` 就可以。
6.1、term 查询
1、term 和 terms(不进行分词处理,完全匹配)
term 查询不会对输入进行分词处理。match 会做分词处理。
title 包含 beanutiful 的 文档:
GET movies/_search
{
"query": {
"term": {
"title":
"beautiful"
}
}
}
title 包含 beanutiful 或 mind 的文档:
GET movies/_search
{
"query": {
"terms": {
"title": [
"beautiful",
"mind"
]
}
}
}
一个查询的单词用 term,多个用 terms。
2、range (范围查询)
查询上映在 2016 到 2018 年的所有电影,再根据上映的时间倒叙进行排序。
GET movies/_search
{
"query": {
"range": {
"year":{
"gte": 2016,
"lte": 2018
}
}
},
"sort": [
{
"year": {
"order": "desc"
}
}
]
}
查(query)什么,查的是范围(range),查什么范围,年份(year),结果按照顺序(order),按照倒叙(desc)。
gte:大于等于。
lte:小于等于。
复合查询:match 和 range 同时使用。
GET movies/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"title": "beautiful mind"
}
},
{
"range": {
"year": {
"gte": 1990,
"lte": 1992
}
}
}
]
}
}
}
3、Constant Score(不进行相关性算分,查询的结果会进行缓存)
不会进行相关性算分,会节省大量时间。查询的结果会进行缓存。Constant Score 只能用 term 查询。
查询 title 中包含 beautiful 的所有电影
GET movies/_search
{
"query": {
"constant_score": {
"filter": {
"term": {
"title": "beautiful"
}
}
}
}
}
会发现查询结果的 _score:1.0。没有进行相关性算分。
"hits" : [
{
"_index" : "movies",
"_type" : "_doc",
"_id" : "66701",
"_score" : 1.0,
"_source" : {
"id" : "66701",
"genre" : [
"Comedy",
"Drama"
],
"title" : "Beautiful Ohio",
"year" : 2006,
"@version" : "1"
}
},
]
6.2、全文查询
全文查询的种类有: Match Query、Match Phrase Query、Query String Query 等
6.2.1、match(完全匹配)
查询包含输入条件的内容。
查询电影名包含 beautiful 的电影 ,每页 10 条,取第 2 页的数据。
GET movies/_search
{
"query": {
"match": {
"title": "beautiful"
}
},
"from": 10,
"size": 10
}
查询电影名包含 beautiful 的电影,但是查询的结果只显示 id 和 title
GET movies/_search
{
"_source": ["title", "id"],
"query": {
"match": {
"title": "beautiful"
}
}
}
只想查部分属性,使用 _source。
6.2.2、match_phrase(短语完全匹配)
匹配短语,整个输入都做一个整体查询条件。
GET movies/_search
{
"query": {
"match_phrase": {
"title": "beautiful mind"
}
}
}
查出来的结果:
{
"took" : 15,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 13.509613,
"hits" : [
{
"_index" : "movies",
"_type" : "_doc",
"_id" : "4995",
"_score" : 13.509613,
"_source" : {
"id" : "4995",
"genre" : [
"Drama",
"Romance"
],
"title" : "Beautiful Mind, A",
"year" : 2001,
"@version" : "1"
}
}
]
}
}
6.2.3、 multi_match(条件与多结果完全匹配)
查询的条件和多个结果匹配的的结果。
GET movies/_search
{
"query": {
"multi_match": {
"query": "beautiful",
"fields": ["title", "genre"]
}
}
}
6.2.4、match_all(查询所有)
查询所有的数据。
GET movies/_search
{
"query": {
"match_all": {
}
}
}
这个就相当于:
GET movies/_search
6.2.5、query_string(AND 或 OR 条件组合)
条件用 AND 组合时可以用这个, OR 也可以。
GET movies/_search
{
"query": {
"query_string": {
"default_field": "title",
"query": "beautiful OR mind"
}
}
}
GET movies/_search
{
"query": {
"query_string": {
"default_field": "title",
"query": "beautiful AND mind"
}
}
}
AND 和 OR 一定要大写,不然会被当作查询条件进行查询。
6.2.6、simple_query_string
GET movies/_search
{
"query": {
"simple_query_string": {
"query": "beautiful+ -mind",
"fields": ["title"]
}
}
}
6.3、模糊查询-fuzzy
关键字:fuzzy。
GET movies/_search
{
"query": {
"fuzzy": {
"title": {
"value": "neverendogn",
"fuzziness": 2
}
}
}
}
fuzziness 的值只能为大于等于0,小于等于2,有小数点。值为 0 时,必须是完全匹配,值为 1 时,可以有 1 个字母和搜索中的不一样,值 为 2 时,可以有 2 个字母和搜索中的不一样。
6.4、多条件查询
1、must
多个条件同时满足。会进行相关性算分。
GET movies/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"title": "beautiful"
}
},
{
"range": {
"year": {
"gte": 1990,
"lte": 2000
}
}
}
]
}
}
}
语法是:
GET 索引名/_search
{
"query": {
"bool": {
"must": [
{
条件查询1
},
{
条件查询2
}
...
]
}
}
}
2、must_not
多个条件同时不满足。不会进行相关性算分。
GET movies/_search
{
"query": {
"bool": {
"must_not": [
{
"match": {
"title": "mind"
}
}
]
}
}
}
语法是:
GET 索引名/_search
{
"query": {
"bool": {
"must_not": [
{
条件查询1
},
{
条件查询2
}
...
]
}
}
}
{
"took" : 5,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 10000,
"relation" : "gte"
},
"max_score" : 0.0,
"hits" : [
{
"_index" : "movies",
"_type" : "_doc",
"_id" : "42015",
"_score" : 0.0,
"_source" : {
"id" : "42015",
"genre" : [
"Action",
"Adventure",
"Comedy",
"Drama",
"Romance"
],
"title" : "Casanova",
"year" : 2005,
"@version" : "1"
}
},
{
"_index" : "movies",
"_type" : "_doc",
"_id" : "42018",
"_score" : 0.0,
"_source" : {
"id" : "42018",
"genre" : [
"Comedy",
"Drama"
],
"title" : "Mrs. Henderson Presents",
"year" : 2005,
"@version" : "1"
}
}
]
}
}
"_score" : 0.0 都是一样的,没有进行相关性算分。
3、filter
多个条件同时满足。不会进行相关性算分。
GET movies/_search
{
"query": {
"bool": {
"filter": [
{
"match": {
"title": "beautiful"
}
},
{
"range": {
"year": {
"gte": 1990,
"lte": 2000
}
}
}
]
}
}
}
"_score" : 0.0 ,都是一样的,和 must 的功能不一样,都是多条件同时满足,但是不会进行相关性算分。
4、should
或者的关系 ,会对查询的结果进行相关性算分。
GET movies/_search
{
"query": {
"bool": {
"should": [
{
"match": {
"title": "beautiful"
}
},
{
"match": {
"title": "mind"
}
}
]
}
}
}
语法是:
GET 索引名/_search
{
"query": {
"bool": {
"should": [
{
查询条件1
},
{
查询条件2
}
]
}
}
}
七、Mapping
Mapping 的作用:
定义字段的数据类型。
设置该字段是否可以被倒排索引。
7.1、数据类型
| 类型名 | 描述名 |
|---|---|
| Text/Keyword | 字符串,默认的类型 |
| Date | 日期类型 |
| Integer/Float/Long | 数字类型 |
| Boolean | 布尔类型 |
Text 和 KeyWord:是否分词。https://www.cnblogs.com/qlqwjy/p/13462750.html
7.2、定义 Mapping
语法如下:
PUT users
{
"mappings": {
// 在这里定义 mapping
}
}
定义 mapping 的建议方式:推荐导入样本文档到临时索引,ES 会自动生成 mapping 信息,用 api 查询 mapping 的定义,根据自己的需求修改这份 mapping 信息,然后创建索引,删除临时索引。
ES 的 mapping 设置好后,是不可以修改的,所以不像关系型数据库那样,可以直接修改,所以只能这样从左。
示例
添加一个索引一个文档:
PUT users/_doc/1
{
"name": "Jack",
"age": 18,
"height": 180.0,
"isRich": "true"
}
索引的 mapping 会自动生成,我们看一下自动生成的索引,使用命令查询:
GET users/_mapping
查询结果:
{
"users" : {
"mappings" : {
"properties" : {
"age" : {
"type" : "long"
},
"height" : {
"type" : "float"
},
"isRich" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"name" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
}
}
}
}
}
把 mappings 后面内容复制一下:
"mappings" : {
"properties" : {
"age" : {
"type" : "long"
},
"height" : {
"type" : "float"
},
"isRich" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"name" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
}
}
}
去掉 fields 这些:
"mappings" : {
"properties" : {
"age" : {
"type" : "long"
},
"height" : {
"type" : "float"
},
"isRich" : {
"type" : "text"
},
"name" : {
"type" : "text"
}
}
}
将 isRich 的类型改为 boolean,加上 PUT users
PUT users
{
"mappings" : {
"properties" : {
"age" : {
"type" : "long"
},
"height" : {
"type" : "float"
},
"isRich" : {
"type" : "boolean"
},
"name" : {
"type" : "text"
}
}
}
}
然后删除索引
DELETE users
执行上面的创建 mapping 语句,再重新建立索引添加一条文档:
PUT users
{
"mappings" : {
"properties" : {
"age" : {
"type" : "long"
},
"height" : {
"type" : "float"
},
"isRich" : {
"type" : "boolean"
},
"name" : {
"type" : "text"
}
}
}
}
PUT users/_doc/1
{
"name": "Jack",
"age": 18,
"height": 180.0,
"isRich": "true"
}
查看现在的索引 mapping:
GET users/_mapping
查询结果:
{
"users" : {
"mappings" : {
"properties" : {
"age" : {
"type" : "long"
},
"height" : {
"type" : "float"
},
"isRich" : {
"type" : "boolean"
},
"name" : {
"type" : "text"
}
}
}
}
}
发现每个字段所对应的类型是我们提前定义好的类型。
搜索时匹配
7.3、常见参数
7.3.1、index
可以给属性添加一个布尔类型的 index 属性,可以控制属性是否被倒排索引。
PUT test
{
"mappings" : {
"properties" : {
"name" : {
"type" : "text",
"index": false
}
}
}
}
为 false 的时候不可以进行倒排索引。
插入两条数据
POST test/_doc/1
{
"name": "zhangsan"
}
POST test/_doc/2
{
"name": "xiaoqi"
}
查询:
GET test/_search
{
"query": {
"match": {
"name": "zhangsan"
}
}
}
会报错。
{
"error" : {
"root_cause" : [
{
"type" : "query_shard_exception",
"reason" : "failed to create query: Cannot search on field [name] since it is not indexed.",
"index_uuid" : "YCjgmE81QkSHLohZdY2JBw",
"index" : "test"
}
],
"type" : "search_phase_execution_exception",
"reason" : "all shards failed",
"phase" : "query",
"grouped" : true,
"failed_shards" : [
{
"shard" : 0,
"index" : "test",
"node" : "zTWkfiA2RG2GUVGMgRnuhQ",
"reason" : {
"type" : "query_shard_exception",
"reason" : "failed to create query: Cannot search on field [name] since it is not indexed.",
"index_uuid" : "YCjgmE81QkSHLohZdY2JBw",
"index" : "test",
"caused_by" : {
"type" : "illegal_argument_exception",
"reason" : "Cannot search on field [name] since it is not indexed."
}
}
}
]
},
"status" : 400
}
7.3.2、null_value
字段的值如果是 null,是无法进行搜索的,这个时候我们可以使用 null_value,null_value 会将属性转化为 null_value 的值。
使用 null_value 时,只能用 keyword 类型。
示例
添加数据:
POST test/_doc/1
{
"name": "zhangsan"
}
POST test/_doc/2
{
"name": "xiaoqi"
}
POST test/_doc/3
{
"name": null
}
搜索值为 null :
GET test/_search
{
"query": {
"match": {
"name": null
}
}
}
运行结果会报错:
{
"error" : {
"root_cause" : [
{
"type" : "parsing_exception",
"reason" : "No text specified for text query",
"line" : 5,
"col" : 5
}
],
"type" : "parsing_exception",
"reason" : "No text specified for text query",
"line" : 5,
"col" : 5
},
"status" : 400
}
我们可以使用 null_value:
PUT test
{
"mappings" : {
"properties" : {
"name" : {
"type" : "keyword",
"null_value": "null"
}
}
}
}
然后插入数据:
POST test/_doc/1
{
"name": "zhangsan"
}
POST test/_doc/2
{
"name": "xiaoqi"
}
POST test/_doc/3
{
"name": null
}
然后查询:
GET test/_search
{
"query": {
"match": {
"name": "null"
}
}
}
查询结果:
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 0.9808291,
"hits" : [
{
"_index" : "test",
"_type" : "_doc",
"_id" : "3",
"_score" : 0.9808291,
"_source" : {
"name" : null
}
}
]
}
}
八、ES 聚合查询
语法格式:
GET indexName/_search {
"aggs": {
"聚合名称(自定义的)": {
"聚合类型(ES 提供的)": {
"field": "要做聚合的字段名"
}
}
}
创建索引类型,新增文档:
PUT employee
{
"mappings": {
"properties": {
"id": {
"type": "integer" },
"name": {
"type": "keyword" },
"job": {
"type": "keyword" },
"age": {
"type": "integer" },
"gender": {
"type": "keyword" }
}
}
}
PUT employee/_bulk
{"index": {"_id": 1}}
{"id": 1, "name": "Bob", "job": "java", "age": 21, "sal": 8000, "gender": "female"}
{"index": {"_id": 2}}
{"id": 2, "name": "Rod", "job": "html", "age": 31, "sal": 18000, "gender": "female"}
{"index": {"_id": 3}}
{"id": 3, "name": "Gaving", "job": "java", "age": 24, "sal": 12000, "gender": "male"}
{"index": {"_id": 4}}
{"id": 4, "name": "King", "job": "dba", "age": 26, "sal": 15000, "gender": "female"}
{"index": {"_id": 5}}
{"id": 5, "name": "Jonhson", "job": "dba", "age": 29, "sal": 16000, "gender": "male"}
{"index": {"_id": 6}}
{"id": 6, "name": "Douge", "job": "java", "age": 41, "sal": 20000, "gender": "female"}
{"index": {"_id": 7}}
{"id": 7, "name": "cutting", "job": "dba", "age": 27, "sal": 7000, "gender": "male"}
{"index": {"_id": 8}}
{"id": 8, "name": "Bona", "job": "html", "age": 22, "sal": 14000, "gender": "female"}
{"index": {"_id": 9}}
{"id": 9, "name": "Shyon", "job": "dba", "age": 20, "sal": 19000, "gender": "female"}
{"index": {"_id": 10}}
{"id": 10, "name": "James", "job": "html", "age": 18, "sal": 22000, "gender": "male"}
{"index": {"_id": 11}}
{"id": 11, "name": "Golsling", "job": "java", "age": 32, "sal": 23000, "gender": "female"}
{"index": {"_id": 12}}
{"id": 12, "name": "Lily", "job": "java", "age": 24, "sal": 2000, "gender": "male"}
{"index": {"_id": 13}}
{"id": 13, "name": "Jack", "job": "html", "age": 23, "sal": 3000, "gender": "female"}
{"index": {"_id": 14}}
{"id": 14, "name": "Rose", "job": "java", "age": 36, "sal": 6000, "gender": "female"}
{"index": {"_id": 15}}
{"id": 15, "name": "Will", "job": "dba", "age": 38, "sal": 4500, "gender": "male"}
{"index": {"_id": 16}}
{"id": 16, "name": "smith", "job": "java", "age": 32, "sal": 23000, "gender": "male"}
8.1、单值输出
8.1.1、总和
查员工工资的总和
# 查询工资的总和
GET employee/_search
{
"size": 0,
"aggs": {
"sum_sal": {
"sum": {
"field": "sal"
}
}
}
}
8.1.2、平均
查询员工的平均工资
GET employee/_search
{
"size": 0,
"aggs": {
"other_avg": {
"avg": {
"field": "sal"
}
}
}
}
8.1.3、总数
查询总共有多少岗位
# 查询总共有多少岗位
GET employee/_search
{
"size": 0,
"aggs": {
"jon_sum": {
"cardinality": {
"field": "job"
}
}
}
}
8.1.4、最大值最小值
查询工资的最大值、最小值
GET employee/_search
{
"size": 0,
"aggs": {
"sal_max": {
"max": {
"field": "sal"
}
}
}
}
GET employee/_search
{
"size": 0,
"aggs": {
"sal_min": {
"min": {
"field": "sal"
}
}
}
}
8.2、多值的输出
8.2.1、查询信息(stats)
信息包括:总数量、最小值、最大值、平均值、总和。stats 使用时属性只能是类型。
查询员工工资信息
# 查询员工工资信息
GET employee/_search
{
"size": 0,
"aggs": {
"sal_info": {
"stats": {
"field": "sal"
}
}
}
}
运行结果:
{
"took" : 2,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 16,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
},
"aggregations" : {
"sal_info" : {
"count" : 16,
"min" : 2000.0,
"max" : 23000.0,
"avg" : 13281.25,
"sum" : 212500.0
}
}
}
8.2.2、分组查询(terms)
查询到达不同国家的航班数量
GET kibana_sample_data_flights/_search
{
"size": 0,
"aggs": {
"dest_country_info": {
"terms": {
"field": "DestCountry"
}
}
}
}
查询结果:
{
"took" : 3,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 10000,
"relation" : "gte"
},
"max_score" : null,
"hits" : [ ]
},
"aggregations" : {
"dest_country_info" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 3187,
"buckets" : [
{
"key" : "IT",
"doc_count" : 2371
},
{
"key" : "US",
"doc_count" : 1987
},
{
"key" : "CN",
"doc_count" : 1096
},
{
"key" : "CA",
"doc_count" : 944
},
{
"key" : "JP",
"doc_count" : 774
},
{
"key" : "RU",
"doc_count" : 739
},
{
"key" : "CH",
"doc_count" : 691
},
{
"key" : "GB",
"doc_count" : 449
},
{
"key" : "AU",
"doc_count" : 416
},
{
"key" : "PL",
"doc_count" : 405
}
]
}
}
}
8.2.3、子查询
查询不同目的地航班次数以及不同目的地不同天气的统计信息
# 查询不同目的地航班次数以及不同目的地天气的统计信息
GET kibana_sample_data_flights/_search
{
"size": 0,
"aggs": {
"dest_country_info": {
"terms": {
"field": "DestCountry"
},
"aggs": {
"dest_country_weather_info": {
"terms": {
"field": "DestWeather"
}
}
}
}
}
}
运行结果:
{
"took" : 28,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 10000,
"relation" : "gte"
},
"max_score" : null,
"hits" : [ ]
},
"aggregations" : {
"dest_country_info" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 3187,
"buckets" : [
{
"key" : "IT",
"doc_count" : 2371,
"dest_country_weather_info" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : "Clear",
"doc_count" : 428
},
{
"key" : "Sunny",
"doc_count" : 424
},
{
"key" : "Rain",
"doc_count" : 417
},
{
"key" : "Cloudy",
"doc_count" : 414
},
{
"key" : "Heavy Fog",
"doc_count" : 182
},
{
"key" : "Damaging Wind",
"doc_count" : 173
},
{
"key" : "Hail",
"doc_count" : 169
},
{
"key" : "Thunder & Lightning",
"doc_count" : 164
}
]
}
},
{
"key" : "US",
"doc_count" : 1987,
"dest_country_weather_info" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : "Rain",
"doc_count" : 371
},
{
"key" : "Clear",
"doc_count" : 346
},
{
"key" : "Sunny",
"doc_count" : 345
},
{
"key" : "Cloudy",
"doc_count" : 330
},
{
"key" : "Heavy Fog",
"doc_count" : 157
},
{
"key" : "Thunder & Lightning",
"doc_count" : 155
},
{
"key" : "Hail",
"doc_count" : 142
},
{
"key" : "Damaging Wind",
"doc_count" : 141
}
]
}
},
{
"key" : "CN",
"doc_count" : 1096,
"dest_country_weather_info" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : "Sunny",
"doc_count" : 209
},
{
"key" : "Rain",
"doc_count" : 207
},
{
"key" : "Clear",
"doc_count" : 192
},
{
"key" : "Cloudy",
"doc_count" : 173
},
{
"key" : "Thunder & Lightning",
"doc_count" : 86
},
{
"key" : "Hail",
"doc_count" : 81
},
{
"key" : "Heavy Fog",
"doc_count" : 79
},
{
"key" : "Damaging Wind",
"doc_count" : 69
}
]
}
},
{
"key" : "CA",
"doc_count" : 944,
"dest_country_weather_info" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : "Clear",
"doc_count" : 197
},
{
"key" : "Rain",
"doc_count" : 173
},
{
"key" : "Cloudy",
"doc_count" : 156
},
{
"key" : "Sunny",
"doc_count" : 148
},
{
"key" : "Damaging Wind",
"doc_count" : 80
},
{
"key" : "Thunder & Lightning",
"doc_count" : 69
},
{
"key" : "Heavy Fog",
"doc_count" : 62
},
{
"key" : "Hail",
"doc_count" : 59
}
]
}
},
{
"key" : "JP",
"doc_count" : 774,
"dest_country_weather_info" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : "Rain",
"doc_count" : 152
},
{
"key" : "Sunny",
"doc_count" : 138
},
{
"key" : "Clear",
"doc_count" : 130
},
{
"key" : "Cloudy",
"doc_count" : 123
},
{
"key" : "Damaging Wind",
"doc_count" : 66
},
{
"key" : "Heavy Fog",
"doc_count" : 58
},
{
"key" : "Thunder & Lightning",
"doc_count" : 57
},
{
"key" : "Hail",
"doc_count" : 50
}
]
}
},
{
"key" : "RU",
"doc_count" : 739,
"dest_country_weather_info" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : "Cloudy",
"doc_count" : 149
},
{
"key" : "Rain",
"doc_count" : 128
},
{
"key" : "Clear",
"doc_count" : 122
},
{
"key" : "Sunny",
"doc_count" : 117
},
{
"key" : "Thunder & Lightning",
"doc_count" : 62
},
{
"key" : "Hail",
"doc_count" : 56
},
{
"key" : "Damaging Wind",
"doc_count" : 55
},
{
"key" : "Heavy Fog",
"doc_count" : 50
}
]
}
},
{
"key" : "CH",
"doc_count" : 691,
"dest_country_weather_info" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : "Cloudy",
"doc_count" : 135
},
{
"key" : "Sunny",
"doc_count" : 134
},
{
"key" : "Clear",
"doc_count" : 128
},
{
"key" : "Rain",
"doc_count" : 115
},
{
"key" : "Heavy Fog",
"doc_count" : 51
},
{
"key" : "Hail",
"doc_count" : 46
},
{
"key" : "Damaging Wind",
"doc_count" : 41
},
{
"key" : "Thunder & Lightning",
"doc_count" : 41
}
]
}
},
{
"key" : "GB",
"doc_count" : 449,
"dest_country_weather_info" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : "Rain",
"doc_count" : 93
},
{
"key" : "Sunny",
"doc_count" : 81
},
{
"key" : "Clear",
"doc_count" : 77
},
{
"key" : "Cloudy",
"doc_count" : 71
},
{
"key" : "Heavy Fog",
"doc_count" : 34
},
{
"key" : "Hail",
"doc_count" : 32
},
{
"key" : "Damaging Wind",
"doc_count" : 31
},
{
"key" : "Thunder & Lightning",
"doc_count" : 30
}
]
}
},
{
"key" : "AU",
"doc_count" : 416,
"dest_country_weather_info" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : "Rain",
"doc_count" : 80
},
{
"key" : "Cloudy",
"doc_count" : 75
},
{
"key" : "Clear",
"doc_count" : 73
},
{
"key" : "Sunny",
"doc_count" : 57
},
{
"key" : "Hail",
"doc_count" : 38
},
{
"key" : "Thunder & Lightning",
"doc_count" : 34
},
{
"key" : "Heavy Fog",
"doc_count" : 32
},
{
"key" : "Damaging Wind",
"doc_count" : 27
}
]
}
},
{
"key" : "PL",
"doc_count" : 405,
"dest_country_weather_info" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : "Clear",
"doc_count" : 74
},
{
"key" : "Rain",
"doc_count" : 71
},
{
"key" : "Cloudy",
"doc_count" : 67
},
{
"key" : "Sunny",
"doc_count" : 66
},
{
"key" : "Thunder & Lightning",
"doc_count" : 37
},
{
"key" : "Damaging Wind",
"doc_count" : 30
},
{
"key" : "Hail",
"doc_count" : 30
},
{
"key" : "Heavy Fog",
"doc_count" : 30
}
]
}
}
]
}
}
}
一个查询中只能直接嵌套一个查询。但是可以间接嵌套多个。
嵌套查询练习
# 查询每个岗位下工资的信息(平均工资、最高工资、最少工资)
GET employee/_search
{
"size": 0,
"aggs": {
"every_job": {
"terms": {
"field": "job"
}
, "aggs": {
"sal_info": {
"stats": {
"field": "sal"
}
}
}
}
}
}
# 查询不同工种男女员工的数量,然后统计不同工种下的男女员工的工资信息。
GET employee/_search
{
"size": 0,
"aggs": {
"diff_job": {
"terms": {
"field": "job"
}, "aggs": {
"gender_cnt": {
"terms": {
"field": "gender"
}, "aggs": {
"employee_info": {
"stats": {
"field": "sal"
}
}
}
}
}
}
}
}
8.2.4、限制查询(top_hits)
查询年龄最大的两位员工的信息
GET employee/_search
{
"size": 0,
"aggs": {
"older_two_emp": {
"top_hits": {
"size": 2,
"sort": [
{
"age": {
"order": "desc"
}
}
]
}
}
}
}
在一个查询结果中前几个,就用 top_hits。
8.2.5、范围查询-range
range 的区间是前闭后开的。
# 查询不同工资区间员工工资的统计信息
GET employee/_search
{
"size": 0,
"aggs": {
"range_sal_info": {
"range": {
"field": "sal",
"ranges": [
{
"key": "0 <= sal < 10001",
"to": 10001
},
{
"key": "10001 <= sal < 20001",
"from": 10001,
"to": 20001
},
{
"key": "20001 <= sal < 30001",
"from": 20001,
"to": 30001
}
]
}
}
}
}
程序结果:
{
"took" : 4,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 16,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
},
"aggregations" : {
"range_sal_info" : {
"buckets" : [
{
"key" : "0 <= sal < 10001",
"to" : 10001.0,
"doc_count" : 6
},
{
"key" : "10001 <= sal < 20001",
"from" : 10001.0,
"to" : 20001.0,
"doc_count" : 7
},
{
"key" : "20001 <= sal < 30001",
"from" : 20001.0,
"to" : 30001.0,
"doc_count" : 3
}
]
}
}
}
{
"key": "20001 <= sal < 30001",
"from": 20001,
"to": 30001
}
范围就是 [20001, 30001),range 是前开后闭区间
8.2.6、查询的结果直方图显示出来-histogram
# 以直方图的方式,每 3000 元为一个区间查询员工信息
GET employee/_search
{
"size": 0,
"aggs": {
"range_sal_info": {
"histogram": {
"field": "sal",
"interval": 3000,
"extended_bounds": {
"min": 0,
"max": 15000
}
}
}
}
}
field:字段名
interval:指定多少为一个区间
extended_bounds:有属性 max,指定最大的区间,不够会补。
运行结果:
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 16,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
},
"aggregations" : {
"range_sal_info" : {
"buckets" : [
{
"key" : 0.0,
"doc_count" : 1
},
{
"key" : 3000.0,
"doc_count" : 2
},
{
"key" : 6000.0,
"doc_count" : 3
},
{
"key" : 9000.0,
"doc_count" : 0
},
{
"key" : 12000.0,
"doc_count" : 2
},
{
"key" : 15000.0,
"doc_count" : 2
},
{
"key" : 18000.0,
"doc_count" : 3
},
{
"key" : 21000.0,
"doc_count" : 3
}
]
}
}
}
8.2.7、结果中找最低的-min_bucket
查询平均工资最低的工种
# 查询平均工资最低的工种
GET employee/_search
{
"size": 0,
"aggs": {
"job_info": {
"terms": {
"field": "job"
},
"aggs": {
"diff_job_avg_sal": {
"avg": {
"field": "sal"
}
}
}
},
"min_avg_sal_job": {
"min_bucket": {
"buckets_path": "job_info>diff_job_avg_sal"
}
}
}
}
buckets_path:是聚合的路径,聚合名字 a>聚合名字 b...
运行结果:
{
"took" : 3,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 16,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
},
"aggregations" : {
"job_info" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : "java",
"doc_count" : 7,
"diff_job_avg_sal" : {
"value" : 13428.57142857143
}
},
{
"key" : "dba",
"doc_count" : 5,
"diff_job_avg_sal" : {
"value" : 12300.0
}
},
{
"key" : "html",
"doc_count" : 4,
"diff_job_avg_sal" : {
"value" : 14250.0
}
}
]
},
"min_avg_sal_job" : {
"value" : 12300.0,
"keys" : [
"dba"
]
}
}
}
8.3、聚合之全局过滤与局部过滤-filter
上面用的都是全局过滤。做一个局部过滤
求 30 岁以上的员工的平均工资和所有员工的平均工资
# 求 30 岁以上的员工的平均工资和所有员工的平均工资
GET employee/_search
{
"size": 0,
"aggs": {
"all_emp_avg_sal": {
"avg": {
"field": "sal"
}
},
"gt_30_emp_avg_info":{
"filter": {
"range": {
"age": {
"gte": 30
}
}
},
"aggs": {
"gt_30_emp_avg_sal": {
"avg": {
"field": "sal"
}
}
}
}
}
}
查询结果:
{
"took" : 13,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 16,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
},
"aggregations" : {
"all_emp_avg_sal" : {
"value" : 13281.25
},
"gt_30_emp_avg_info" : {
"doc_count" : 6,
"gt_30_emp_avg_sal" : {
"value" : 15750.0
}
}
}
}
ES 建议搜索
语法
GET 索引名/_search
{
"suggest": {
"自定义的名字": {
"text": "想要查询建议搜索值",
"term": {
"FIELD": "字段名"
}
}
}
}
查询电影中名字为 beauti 的建议搜索
GET movies/_search
{
"suggest": {
"title_suggest": {
"text": "beauti",
"term": {
"field": "title"
}
}
}
}
查询结果:
{
"took" : 7,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 0,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
},
"suggest" : {
"title_suggest" : [
{
"text" : "beauti",
"offset" : 0,
"length" : 6,
"options" : [
{
"text" : "beauty",
"score" : 0.8333333,
"freq" : 66
},
{
"text" : "beati",
"score" : 0.8,
"freq" : 1
},
{
"text" : "beasts",
"score" : 0.6666666,
"freq" : 9
},
{
"text" : "beauties",
"score" : 0.6666666,
"freq" : 5
},
{
"text" : "beastie",
"score" : 0.6666666,
"freq" : 2
}
]
}
]
}
}
options 后跟的是建议的结果。注意,用上面的查询,只有在值在数据中没有时,ES 才会给出建议搜索值,否则是无法给出的。比如将 beauti 换成 beauty,结果集中有,options 中就不会显示。
GET movies/_search
{
"suggest": {
"title_suggest": {
"text": "beauty",
"term": {
"field": "title"
}
}
}
}
查询结果:
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 0,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
},
"suggest" : {
"title_suggest" : [
{
"text" : "beauty",
"offset" : 0,
"length" : 6,
"options" : [ ]
}
]
}
}
此时 ES 就没有给出建议搜索。可以使用 suggest_mode 来控制。
GET movies/_search
{
"suggest": {
"title_suggest": {
"text": "beauty",
"term": {
"field": "title",
"suggest_mode": "always"
}
}
}
}
suggest_mode 代表 ES 的建议模式,有 3 个值:
missing:倒排索引没有的时候才给建议always:无论倒排索引中有没有都给建议popular:搜索建议中比较流行常用的单词
ES 的自动补全功能
我们在浏览器搜索引擎中经常见到 ES 的自动补全功能:
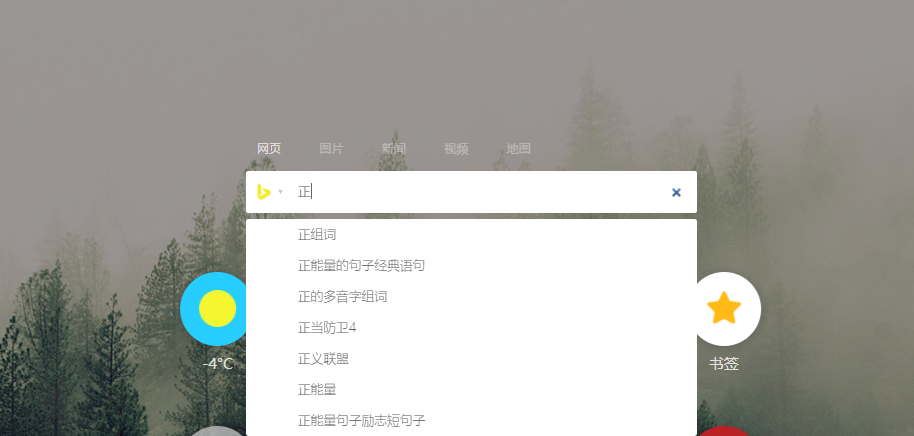
我们输入一个词,就会从数据中匹配。所以自动补全功能对性能要求很高。针对这个,ES 没有采取倒排索引的方式,数据类型要改为 completion
定义 mapping
PUT movies
{
"mappings" : {
"properties" : {
"@version" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"genre" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"id" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"title" : {
"type" : "completion"
},
"year" : {
"type" : "long"
}
}
}
}
将 title 的数据类型设置为 completion。这样才可以使用 ES 的自动补全功能。
前缀搜索
GET movies/_search
{
"_source": [""],
"suggest": {
"title_prefix_suggest": {
"prefix": "bea",
"completion": {
"field" : "title",
"skip_duplicates": true,
"size":10
}
}
}
}
prefix:前缀,ES 会自动补全。
completion:
- field:需要自动补全的值对应的的字段。
- skip_duplicates:去掉重复内容。
- size:查出的结果数量,默认值是 5。
ES 高亮显示-highlight
平时在使用浏览器搜索时就会看到查询的内容高亮显示
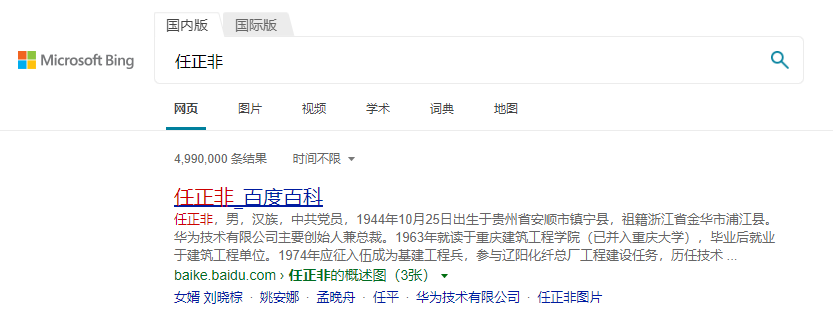
将 title 和 genere 中的所有 romance 进行一个高亮显示
GET movies/_search
{
"query": {
"multi_match": {
"query": "romance",
"fields": ["title", "genre"]
}
},
"highlight": {
"pre_tags": "<span>",
"post_tags": "</span>",
"fields": {
"title": {},
"genre": {
"pre_tags": "<em>",
"post_tags": "</em>"
}
}
}
}
先用了 query 查询,然后使用 highlight 高亮显示。
pre_tags:默认值是 <em>,会加在高亮词的前面。
post_tags:默认值是 </em>,会加在高亮词的后面。
{
"took" : 4,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 7734,
"relation" : "eq"
},
"max_score" : 9.840833,
"hits" : [
{
"_index" : "movies",
"_type" : "_doc",
"_id" : "2894",
"_score" : 9.840833,
"_source" : {
"year" : 1999,
"id" : "2894",
"title" : "Romance",
"@version" : "1",
"genre" : [
"Drama",
"Romance"
]
},
"highlight" : {
"genre" : [
"<em>Romance</em>"
],
"title" : [
"<span>Romance</span>"
]
}
},
{
"_index" : "movies",
"_type" : "_doc",
"_id" : "116867",
"_score" : 9.840833,
"_source" : {
"year" : 1930,
"id" : "116867",
"title" : "Romance",
"@version" : "1",
"genre" : [
"Drama",
"Romance"
]
},
"highlight" : {
"genre" : [
"<em>Romance</em>"
],
"title" : [
"<span>Romance</span>"
]
}
},
{
"_index" : "movies",
"_type" : "_doc",
"_id" : "124991",
"_score" : 9.840833,
"_source" : {
"year" : 2008,
"id" : "124991",
"title" : "Romance",
"@version" : "1",
"genre" : [
"Romance"
]
},
"highlight" : {
"genre" : [
"<em>Romance</em>"
],
"title" : [
"<span>Romance</span>"
]
}
},
{
"_index" : "movies",
"_type" : "_doc",
"_id" : "555",
"_score" : 8.284594,
"_source" : {
"year" : 1993,
"id" : "555",
"title" : "True Romance",
"@version" : "1",
"genre" : [
"Crime",
"Thriller"
]
},
"highlight" : {
"title" : [
"True <span>Romance</span>"
]
}
},
{
"_index" : "movies",
"_type" : "_doc",
"_id" : "3501",
"_score" : 8.284594,
"_source" : {
"year" : 1985,
"id" : "3501",
"title" : "Murphy's Romance",
"@version" : "1",
"genre" : [
"Comedy",
"Romance"
]
},
"highlight" : {
"genre" : [
"<em>Romance</em>"
],
"title" : [
"Murphy's <span>Romance</span>"
]
}
},
{
"_index" : "movies",
"_type" : "_doc",
"_id" : "5769",
"_score" : 8.284594,
"_source" : {
"year" : 1981,
"id" : "5769",
"title" : "Modern Romance",
"@version" : "1",
"genre" : [
"Comedy",
"Romance"
]
},
"highlight" : {
"genre" : [
"<em>Romance</em>"
],
"title" : [
"Modern <span>Romance</span>"
]
}
},
{
"_index" : "movies",
"_type" : "_doc",
"_id" : "40342",
"_score" : 8.284594,
"_source" : {
"year" : 2005,
"id" : "40342",
"title" : "Romance & Cigarettes",
"@version" : "1",
"genre" : [
"Comedy",
"Drama",
"Musical",
"Romance"
]
},
"highlight" : {
"genre" : [
"<em>Romance</em>"
],
"title" : [
"<span>Romance</span> & Cigarettes"
]
}
},
{
"_index" : "movies",
"_type" : "_doc",
"_id" : "133712",
"_score" : 8.284594,
"_source" : {
"year" : 1977,
"id" : "133712",
"title" : "Office Romance",
"@version" : "1",
"genre" : [
"Comedy",
"Romance"
]
},
"highlight" : {
"genre" : [
"<em>Romance</em>"
],
"title" : [
"Office <span>Romance</span>"
]
}
},
{
"_index" : "movies",
"_type" : "_doc",
"_id" : "149446",
"_score" : 8.284594,
"_source" : {
"year" : 2010,
"id" : "149446",
"title" : "Petty Romance",
"@version" : "1",
"genre" : [
"Comedy",
"Drama"
]
},
"highlight" : {
"title" : [
"Petty <span>Romance</span>"
]
}
},
{
"_index" : "movies",
"_type" : "_doc",
"_id" : "150016",
"_score" : 8.284594,
"_source" : {
"year" : 2012,
"id" : "150016",
"title" : "Brasserie Romance",
"@version" : "1",
"genre" : [
"Comedy",
"Drama"
]
},
"highlight" : {
"title" : [
"Brasserie <span>Romance</span>"
]
}
}
]
}
}
将 2012 年电影的名字中包含 romance 的电影,将 title 中 romance 进行高亮显示,同时将这些电影中 genre 包含 children 的单词进行高亮显示。
# 将 2012 年电影的名字中包含 romance 的电影,将 title 中 romance 进行高亮显示,同时将这些电影中 genre 包含 children 的单词进行高亮显示。
GET movies/_search
{
"query": {
"bool": {
"must": [
{
"term": {
"year": "2012"
}
},
{
"match": {
"title": "romance"
}
}
]
}
},
"highlight": {
"fields": {
"title": {},
"genre": {
"pre_tags": "<sapn>",
"post_tags": "</span>",
"highlight_query":{
"match": {
"genre": "children"
}
}
}
}
}
}
九、ES springboot 结合
springboot 官网 ES 相关:https://docs.spring.io/spring-data/elasticsearch/docs/4.1.2/reference/html/#reference
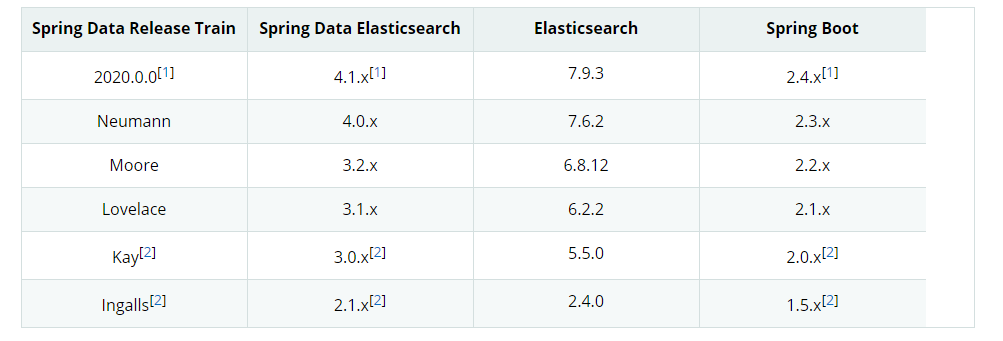
版本 4.0 以来已弃用类TransportClient``TransportClient
版本对应关系:
普通查询
引入依赖
sprigboot 2.4.1 + jdk8 + spring-boot-starter-data-elasticsearch 4.1.0
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.4.1</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<groupId>com.passerbywl</groupId>
<artifactId>esspringboot</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>esspringboot</name>
<description>Demo project for Spring Boot</description>
<properties>
<java.version>1.8</java.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<!-- 引入 elasticsearch springboot start-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
<configuration>
<excludes>
<exclude>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</exclude>
</excludes>
</configuration>
</plugin>
</plugins>
</build>
</project>
Client
package com.passerbywl.esspringboot.config;
import org.elasticsearch.client.RestHighLevelClient;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.data.elasticsearch.client.ClientConfiguration;
import org.springframework.data.elasticsearch.client.RestClients;
import org.springframework.data.elasticsearch.config.AbstractElasticsearchConfiguration;
/**
* @author liyanan
* @create 2021-01-04 17:45
*/
@Configuration
public class RestClientConfig extends AbstractElasticsearchConfiguration {
@Override
@Bean
public RestHighLevelClient elasticsearchClient() {
final ClientConfiguration clientConfiguration = ClientConfiguration.builder()
.connectedTo("localhost:9200")
.build();
return RestClients.create(clientConfiguration).rest();
}
}
实体类
package com.passerbywl.esspringboot.entity;
import lombok.Builder;
import lombok.Data;
import org.springframework.data.annotation.Id;
import org.springframework.data.elasticsearch.annotations.Document;
import java.util.List;
/**
* @author liyanan
* @create 2020-12-28 19:36
*/
@Data
@Builder
@Document(indexName = "movies")
public class Movies {
@Id
private String id;
private String title;
private List<String> genre;
private long year;
}
Controller
package com.passerbywl.esspringboot.controller;
import com.passerbywl.esspringboot.entity.Movies;
import com.passerbywl.esspringboot.repository.MoviesRepository;
import org.springframework.data.domain.Page;
import org.springframework.data.domain.PageRequest;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
import java.util.List;
/**
* @author liyanan
* @create 2020-12-28 20:01
*/
@RestController
@RequestMapping("/movies")
public class MoviesController {
private MoviesRepository moviesRepository;
public MoviesController(MoviesRepository moviesRepository) {
this.moviesRepository = moviesRepository;
}
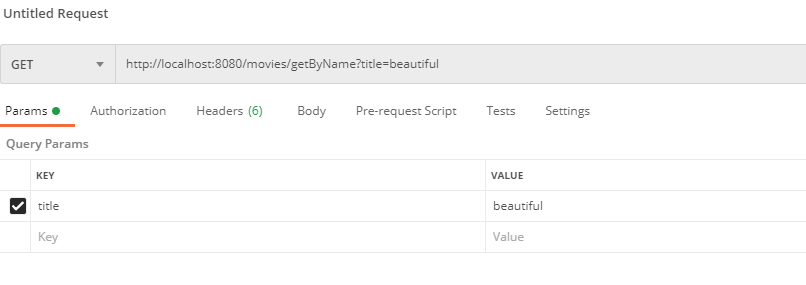
@GetMapping("/getByName")
public List<Movies> getPageData(@RequestParam String title,
@RequestParam(defaultValue = "0") Integer page,
@RequestParam(defaultValue = "10") Integer size) {
PageRequest pageable = PageRequest.of(page, size);
Page<Movies> pageData = moviesRepository.findByTitle(title, pageable);
return pageData.getContent();
}
}
运行 springboot 程序,然后测试:
Repository
package com.passerbywl.esspringboot.repository;
import com.passerbywl.esspringboot.entity.Movies;
import org.springframework.data.domain.Page;
import org.springframework.data.domain.Pageable;
import org.springframework.data.elasticsearch.repository.ElasticsearchRepository;
/**
* @author liyanan
* @create 2020-12-28 19:39
* ElasticsearchRepository<实体类型, id类型>
*/
public interface MoviesRepository extends ElasticsearchRepository<Movies, String> {
Page<Movies> findByTitle(String title, Pageable pageable);
}
ElasticsearchRepository<实体类型, id 类型>
关于这些方法,官网有相关介绍:https://docs.spring.io/spring-data/elasticsearch/docs/4.1.2/reference/html/#elasticsearch.query-methods.criterions
ES + SpringBoot 实现自动补全简单实现
ES 语句:
GET movies/_search
{
"_source": [""],
"suggest": {
"title_prefix_suggest": {
"prefix": "bea",
"completion": {
"field" : "title",
"skip_duplicates": true,
"size":10
}
}
}
}
对应的建议语句:
package com.passerbywl.esspringboot.controller;
import org.elasticsearch.search.suggest.Suggest;
import org.elasticsearch.search.suggest.SuggestBuilder;
import org.elasticsearch.search.suggest.completion.CompletionSuggestionBuilder;
import org.springframework.data.elasticsearch.core.ElasticsearchOperations;
import org.springframework.data.elasticsearch.core.mapping.IndexCoordinates;
import org.springframework.web.bind.annotation.CrossOrigin;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
import java.util.ArrayList;
import java.util.List;
/**
* @author liyanan
* @create 2021-01-07 10:30
*/
@RestController
@CrossOrigin("*")
public class MoviesSuggestController {
private ElasticsearchOperations elasticsearchOperations;
public MoviesSuggestController(ElasticsearchOperations elasticsearchOperations) {
this.elasticsearchOperations = elasticsearchOperations;
}
@GetMapping("/movie/suggest")
public List<String> suggest(@RequestParam String prefix) {
List<String> result = new ArrayList<>();
CompletionSuggestionBuilder completionSuggestionBuilder =
new CompletionSuggestionBuilder("title")
.skipDuplicates(true)
.prefix(prefix)
.size(10);
SuggestBuilder suggestBuilder = new SuggestBuilder().addSuggestion("title_suggest", completionSuggestionBuilder);
// 获取 Suggest
Suggest suggest = elasticsearchOperations.suggest(suggestBuilder, IndexCoordinates.of("movies")).getSuggest();
List<? extends Suggest.Suggestion.Entry<? extends Suggest.Suggestion.Entry.Option>> entries = suggest.getSuggestion("title_suggest").getEntries();
entries.forEach(entry -> {
List<? extends Suggest.Suggestion.Entry.Option> options = entry.getOptions();
options.forEach(op -> {
result.add(op.getText().toString());
});
});
return result;
}
}
Controller 上面要配置跨域,否则下面的 html 无法访问到 SpringBoot 服务。
index.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
<style>
* {
margin: 0;
padding: 0;
}
input {
width: 400px;
height: 24px;
margin-left: 100px;
}
div {
width: 400px;
height: 500px;
margin-left: 100px;
background: bisque;
}
</style>
</head>
<body>
<input type="text" oninput="getAutoCompletedHints(this)">
<div id="content"></div>
</body>
<script src="https://cdn.bootcdn.net/ajax/libs/jquery/2.2.1/jquery.js"></script>
<script>
var content = document.getElementById("content");
function getAutoCompletedHints(inputDom) {
let prefix = inputDom.value;
if (prefix.trim()) {
content.innerHTML = '';
$.getJSON("http://localhost:8080/movie/suggest/?prefix=" + prefix.trim(), {},
function (_data) {
for (let i = 0; i < _data.length; i++) {
let pTag = document.createElement('p');
pTag.innerText = _data[i];
content.appendChild(pTag);
}
});
}
}
</script>
</html>
ElasticSearch 7.x 学习的更多相关文章
- ElasticSearch权威指南学习(索引管理)
创建索引 当我们需要确保索引被创建在适当数量的分片上,在索引数据之前设置好分析器和类型映射. 手动创建索引,在请求中加入所有设置和类型映射,如下所示: PUT /my_index { "se ...
- 搜索引擎Elasticsearch REST API学习
Elasticsearch为开发者提供了一套基于Http协议的Restful接口,只需要构造rest请求并解析请求返回的json即可实现访问Elasticsearch服务器.Elasticsearch ...
- ElasticSearch基础入门学习笔记
前言 本笔记的内容主要是在从0开始学习ElasticSearch中,按照官方文档以及自己的一些测试的过程. 安装 由于是初学者,按照官方文档安装即可.前面ELK入门使用主要就是讲述了安装过程,这里不再 ...
- Elasticsearch的配置学习笔记
文/朱季谦 Elasticsearch是一个基于Lucene的搜索服务器.它提供一个分布式多用户能力的全文搜索引擎,基于RESTful web接口,Elasticsearch是用Java语言开发的. ...
- Elasticsearch基础知识学习
概要 ElasticSearch是一个基于Lucene的搜索服务器.它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口.Elasticsearch是用Java开发的,并作为Ap ...
- ElasticSearch权威指南学习(分布式搜索)
查询阶段 在初始化查询阶段(query phase),查询被向索引中的每个分片副本(原本或副本)广播. 每个分片在本地执行搜索并且建立了匹配document的优先队列(priority queue). ...
- ElasticSearch权威指南学习(排序)
排序方式 相关性排序 默认情况下,结果集会按照相关性进行排序 -- 相关性越高,排名越靠前. 相关性分值会用_score字段来给出一个浮点型的数值,所以默认情况下,结果集以_score进行倒序排列. ...
- ElasticSearch权威指南学习(结构化查询)
请求体查询 简单查询语句(lite)是一种有效的命令行adhoc查询.但是,如果你想要善用搜索,你必须使用请求体查询(request body search)API. 空查询 我们以最简单的 sear ...
- ElasticSearch权威指南学习(映射和分析)
概念 映射(mapping)机制用于进行字段类型确认,将每个字段匹配为一种确定的数据类型(string, number, booleans, date等).+ 分析(analysis)机制用于进行全文 ...
- ElasticSearch权威指南学习(分布式文档存储)
路由文档到分片 当你索引一个文档,它被存储在单独一个主分片上.Elasticsearch是如何知道文档属于哪个分片的呢?当你创建一个新文档,它是如何知道是应该存储在分片1还是分片2上的呢? 进程不能是 ...
随机推荐
- ctfhub技能树—文件上传—无验证
打开靶机 查看页面信息 编写一句话木马 <?php echo "123"; @eval(@$_POST['a']); ?> 上传木马 上传成功,并拿到相对路径地址 查看 ...
- 【葵花宝典】All-in-One模式安装KubeSphere
1.准备 Linux 机器 2.google api受限下载 KubeKey export KKZONE=cn curl -sfL https://get-kk.kubesphere.io | VER ...
- 参数模型检验过滤器 .NetCore版
最近学习 .NETCore3.1,发现过滤器的命名空间有变化. 除此以外一些方法的名称和使用方式也有变动,正好重写一下. 过滤器的命名空间的变化 原先:System.Web.Http.Filters; ...
- JavaScript中的迭代器和生成器[未排版]
JavaScript中的迭代器 在软件开发领域,"迭代"的意思是按照顺序反复多次执行一段程序,通常会有明确的终止条件. ECMAScript 6规范新增了两个高级特性:迭代器和生成 ...
- 提取当前文件夹下的所有文件名.bat(Windows批处理文件)
@echo off dir /s/b *.* > 文件名.txt exit
- 研发流程 接口定义&开发&前后端联调 线上日志观察 模型变动
阿里等大厂的研发流程,进去前先了解一下_我们一起进大厂 - SegmentFault 思否 https://segmentfault.com/a/1190000021831640 接口定义 测试用例评 ...
- 排查golang的性能问题 go pprof 实践
小结: 1.内存消耗分析 list peek 定位到函数 https://mp.weixin.qq.com/s/_LovnIqJYAuDpTm2QmUgrA 使用pprof和go-torch排查 ...
- 【题解】 CF767E Change-free
洛谷链接 这个题翻译忘了输入,我看的英语原文...... 首先,这是一道贪心题 我的大致方法:pair+堆优 题目分析: 从第一天开始,到最后一天,每天可以选择找钱或者不找钱. 如果不找钱,则零钱数m ...
- Mapper查询技巧
Sql字段动态比较判断 <sql id="getUserInfoList_body"> SELECT * from userinfo <dynamic prepe ...
- 静默安装Oracle也没那么恐怖
几种必须静默安装的情况 服务器为了减少资源占用,没安装图形组件 不能进入机房,只能远程SSH 想炫(Z)耀(B),静默安装显得有技术含量 磁盘分区要求 如没有特别要求,装机时可按如下分区比较好管理 / ...