spark sql优化
1、内存优化
1.1、RDD
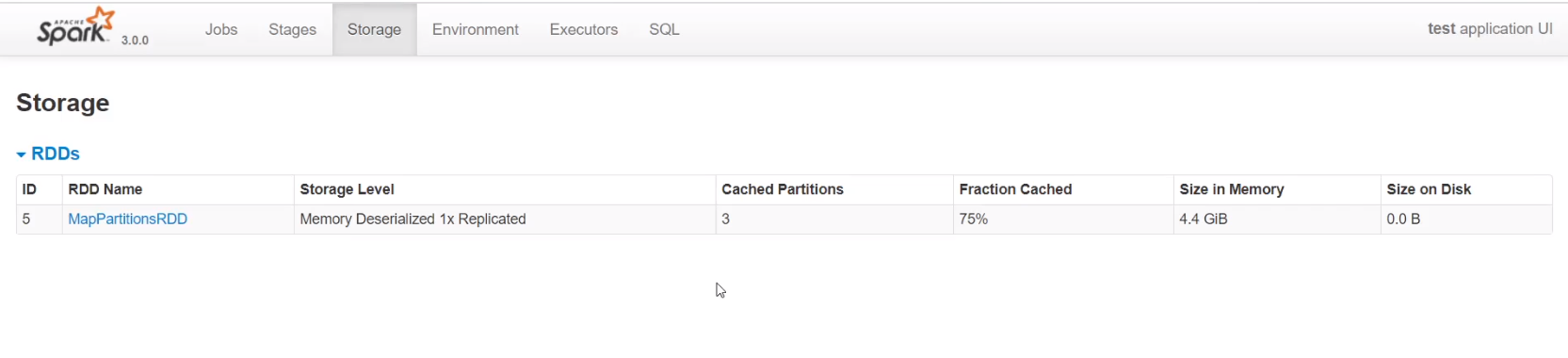
RDD默认cache仅使用内存


可以看到使用默认cache时,四个分区只在内存中缓存了3个分区,4.4G的数据
使用kryo序列化+MEMORY_ONLY_SER


可以看到缓存了四个分区的全部数据,且只缓存了1445.8M

所以这两种缓存方式如何选择,官网建议

也就是说集群资源足够使用默认cache,资源紧张使用kryo序列化+MEMORY_ONLY_SER
1.2、DataFrame与DataSet
DataSet不使用Java和Kryo序列化,它使用特殊的编码器序列化
使用默认cache,保存在内存和磁盘


同样多的数据也是全部缓存,只使用了内存612.3M
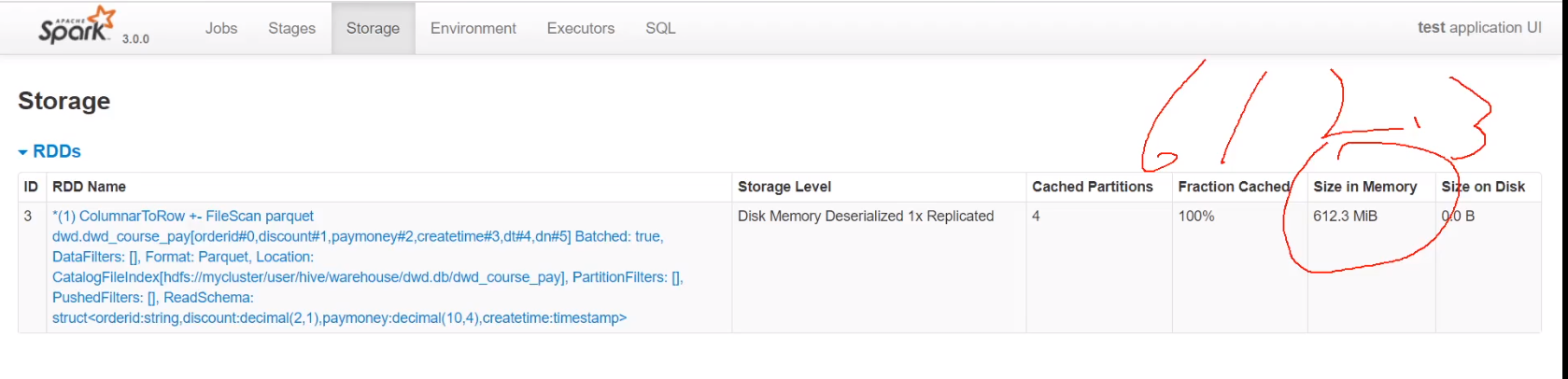
使用序列化缓存时比使用默认缓存还多缓存了30M,共646.2M
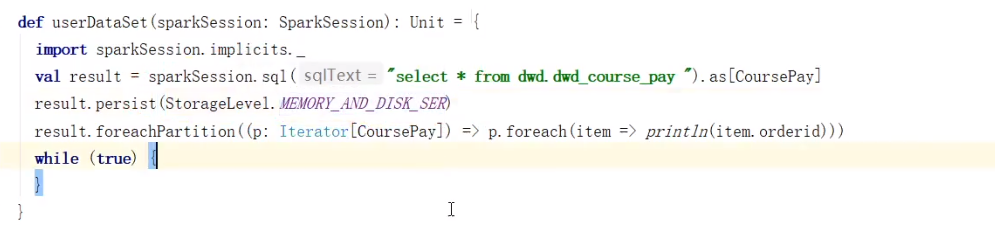

df和ds直接使用默认cache即可
2、小文件过多问题
2.1、RDD中并行度设置
spark.default.parallelism
For distributed shuffle operations like reduceByKey and join, the largest number of partitions in a parent RDD. For operations like parallelize with no parent RDDs, it depends on the cluster manager:
Local mode: number of cores on the local machine
Mesos fine grained mode: 8
Others: total number of cores on all executor nodes or 2, whichever is larger
Default number of partitions in RDDs returned by transformations like join, reduceByKey, and parallelize when not set by user.
2.2、spark sql
Spark SQL can cache tables using an in-memory columnar format by calling sqlContext.cacheTable("tableName") or dataFrame.cache(). Then Spark SQL will scan only required columns and will automatically tune compression to minimize memory usage and GC pressure. You can call sqlContext.uncacheTable("tableName") to remove the table from memory.
建议如果下面无其它任务,缓存可以不释放,有其它任务要释放
算子方式
result.unpersist
spark.sql.shuffle.partitions Configures the number of partitions to use when shuffling data for joins or aggregations.
默认200
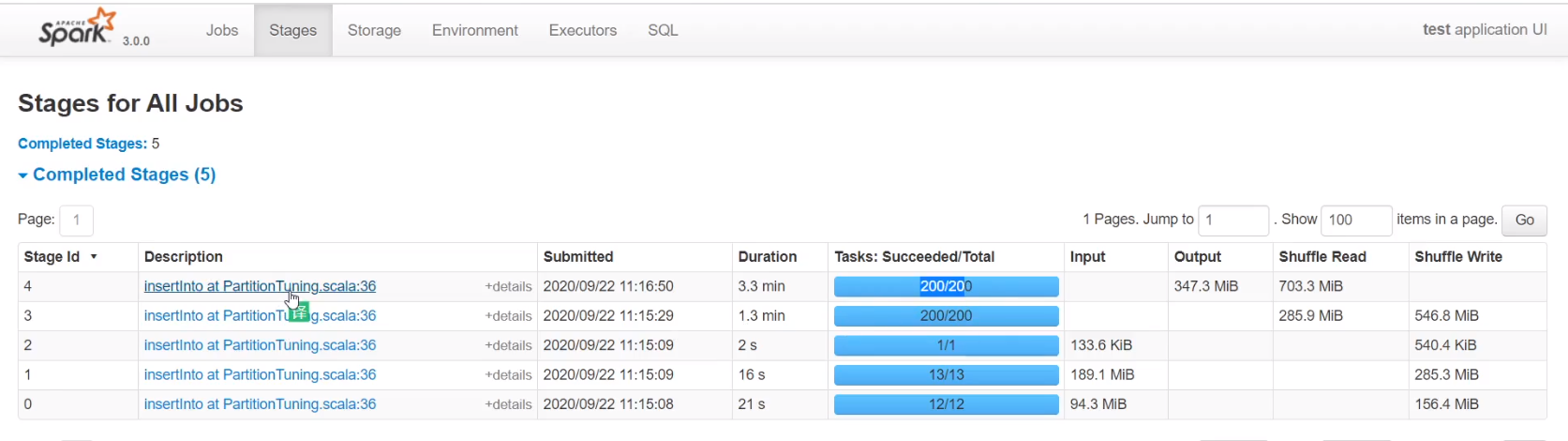
如不减少分区,join后hadoop上会有200个小文件

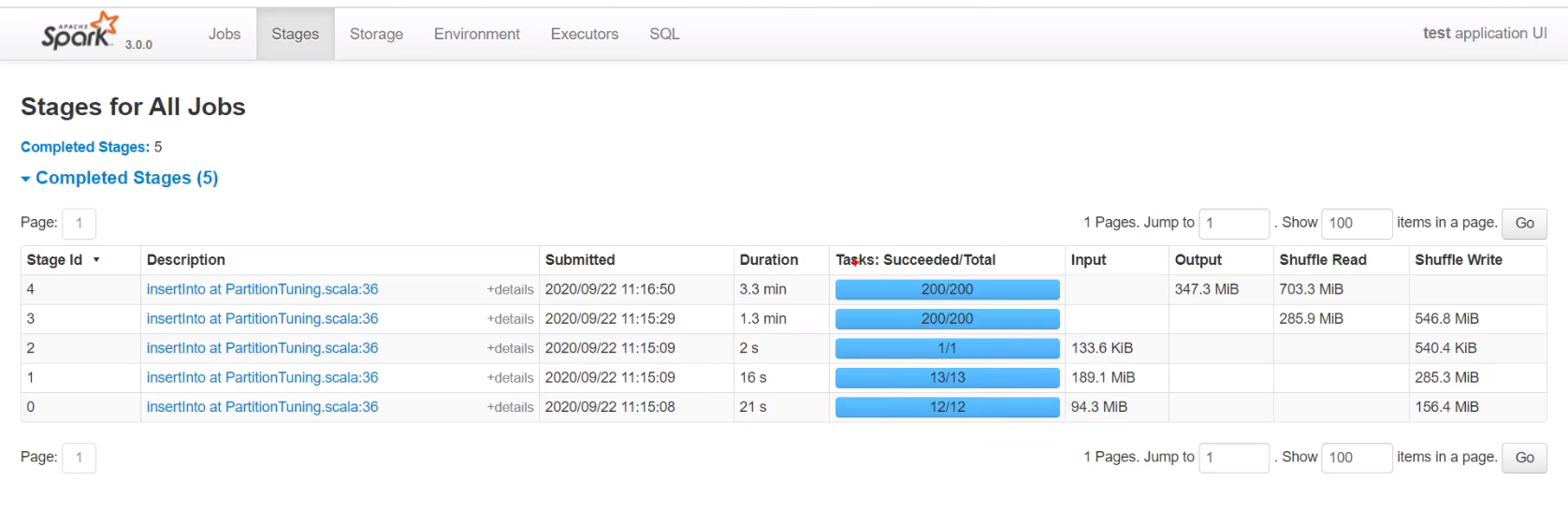
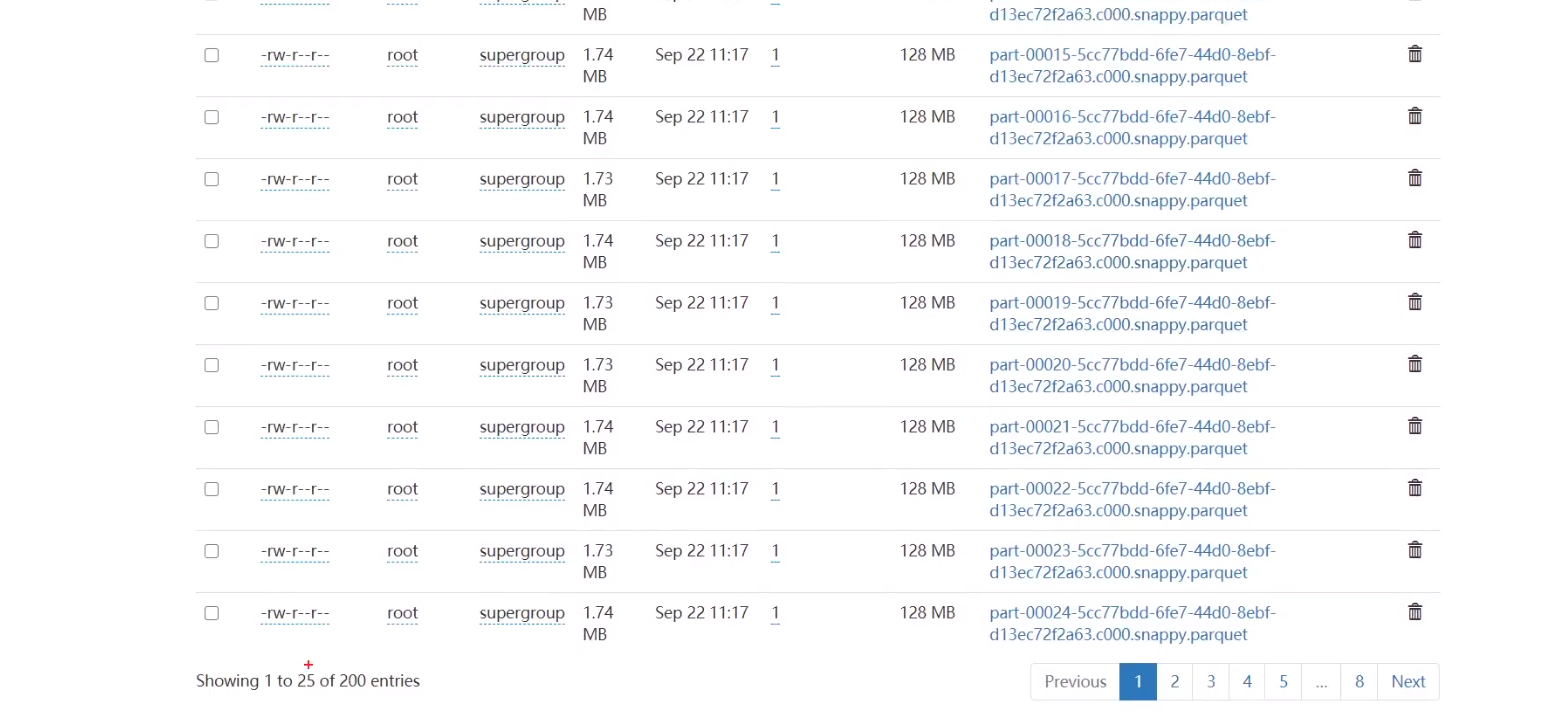
前三个stage为读文件(控制不了),后两个stage为join并行度,为200
1、使用coalesce算子缩小分区,不能大于原有分区数值
2、如果数值小于vcore,有些vcore就不会工作,速度会慢
如压缩成1,并行度就是1只有一个vcore在工作,不会shuffle,如果数据量很大且参数很小,可能会产生oom

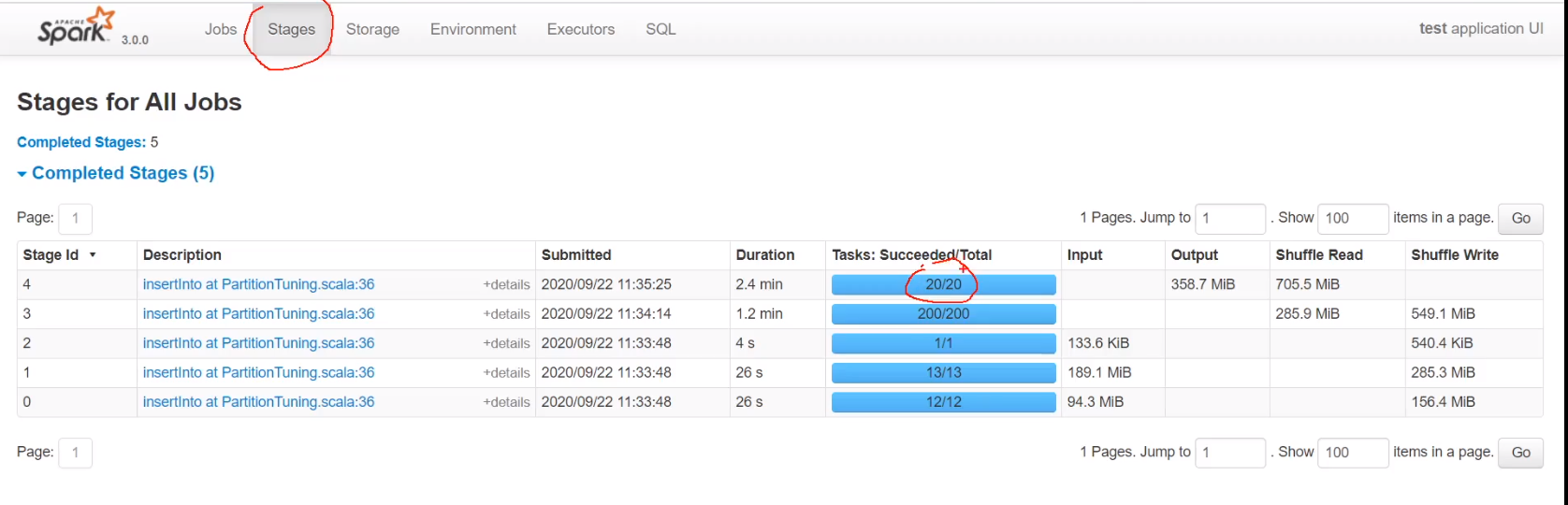
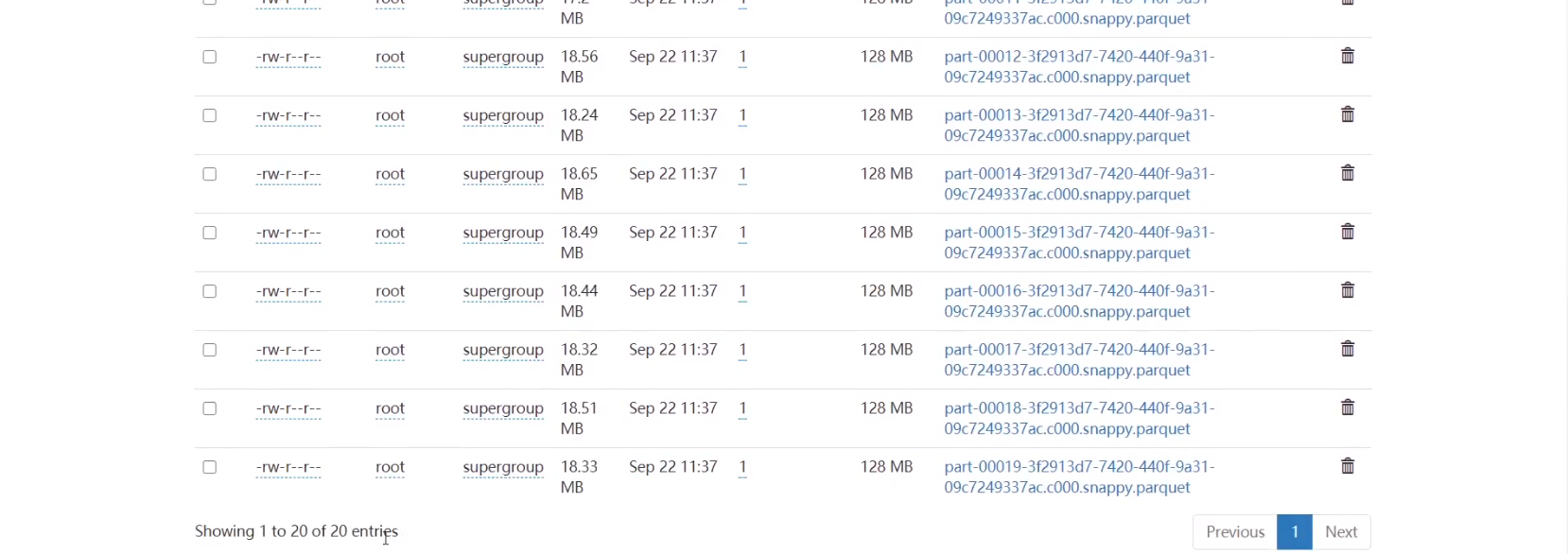
可以看到将分区减少到20,hadoop上只有20个文件
3、合理利用cpu资源
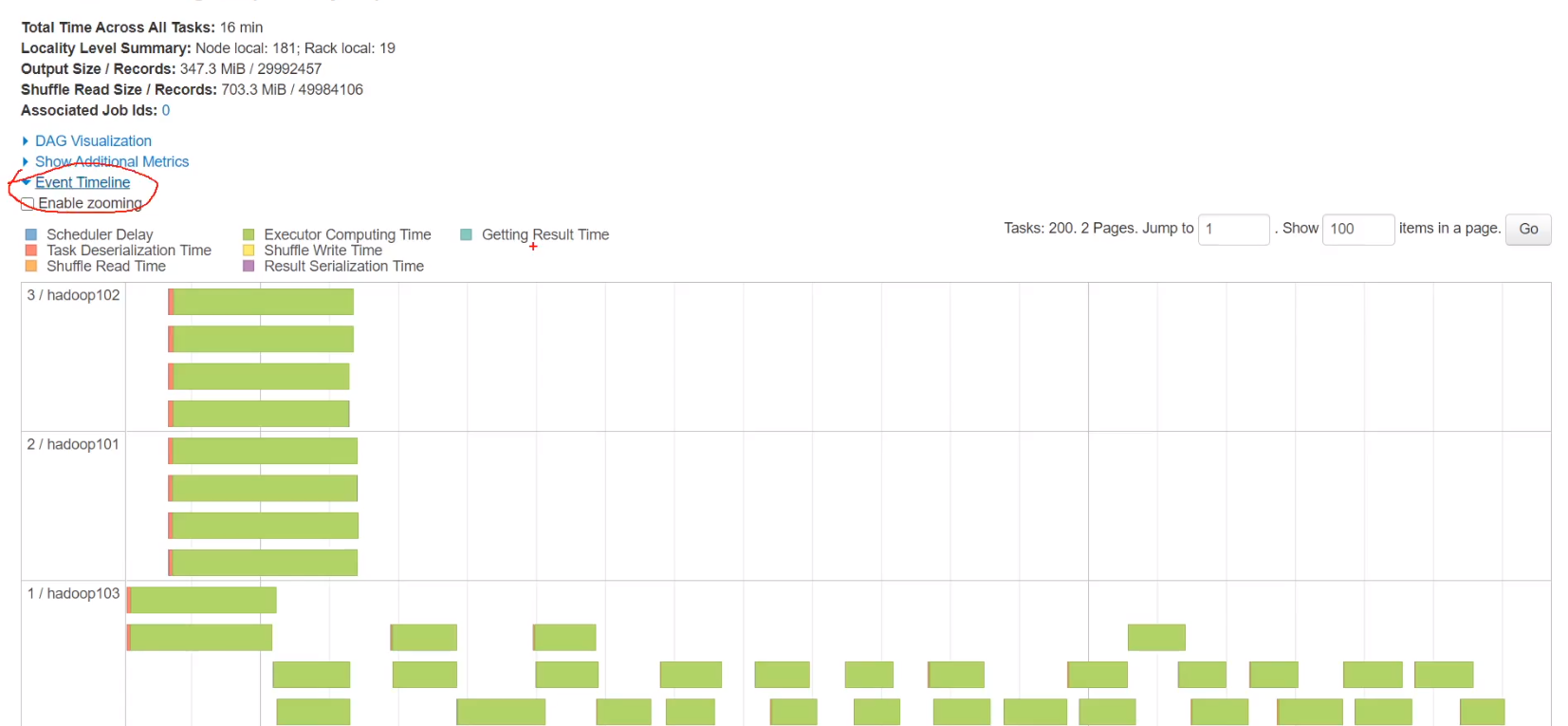
未优化时任务可以看到最后200个任务没有平均分到每台机器上,压力全在hadoop103上,如果数据量很少,hadoop103上有些vcore可能没数据在空转,没有合理利用cpu资源
将·spark.sql.shuffle.partitions设置为总vcore的2到3倍可以达到最优效果




不添加缩小分区coalesce可以看到有36个任务
任务分配也很平均,达到优化效果,避免空转情况,合理利用cpu资源,任务时间缩短到2.5分钟
4、广播join
将小表聚合到driver端,分发到每个executor,规避shuffle,避免此stage
只适合小表join大表
正常大表join大表走SortMergeJoin
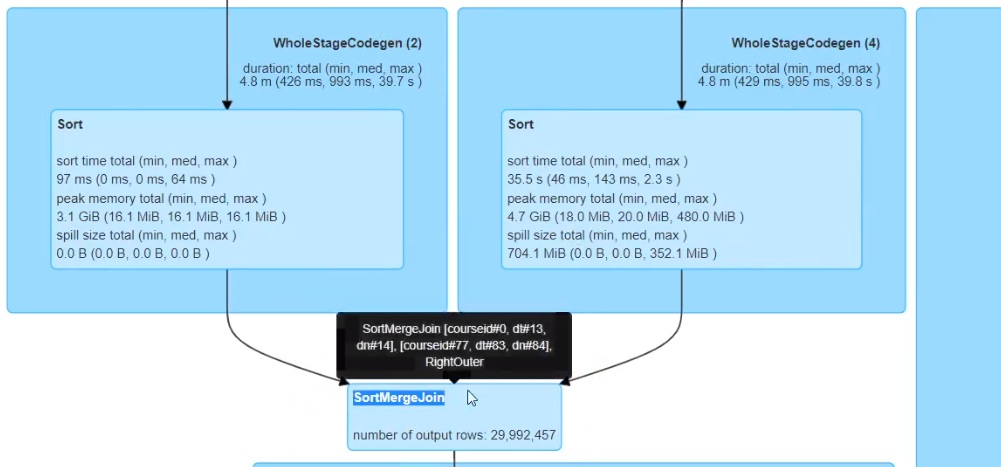
小于等于10M,自动进行广播join
spark.sql.autoBroadcastJoinThreshold 10485760 (10 MB)
Configures the maximum size in bytes for a table that will be broadcast to all worker nodes when performing a join. By setting this value to -1 broadcasting can be disabled. Note that currently statistics are only supported for Hive Metastore tables where the command ANALYZE TABLE <tableName> COMPUTE STATISTICS noscan has been run.
4.1 API
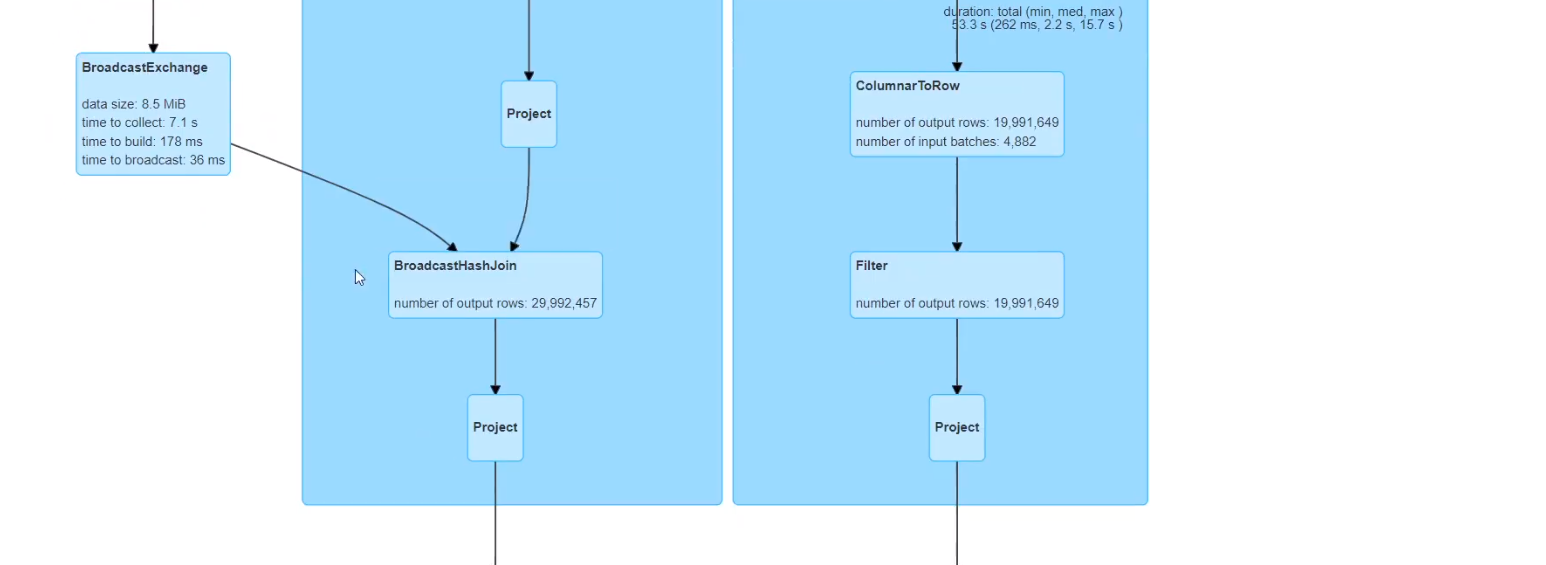
禁用掉广播join ,设置参数为-1

可以看到只剩下一个36task的join stage,多出来一步broadcast exchange,
变成BroadcastHashJoin 耗时变成2分钟

4.2 参数
单位不能是M,10485760
默认10M,实际生产可调大参数,如改成20MB,可以避免小表join大表时数据倾斜
set("spark.sql.autoBroadcastJoinThreshold","20971520")

5、数据倾斜


并不只是500万,因为一个分区里不只一个key,包含多个key,如分区1 101 102 分区2 103 104
本质将相同key的数据聚集到一个task
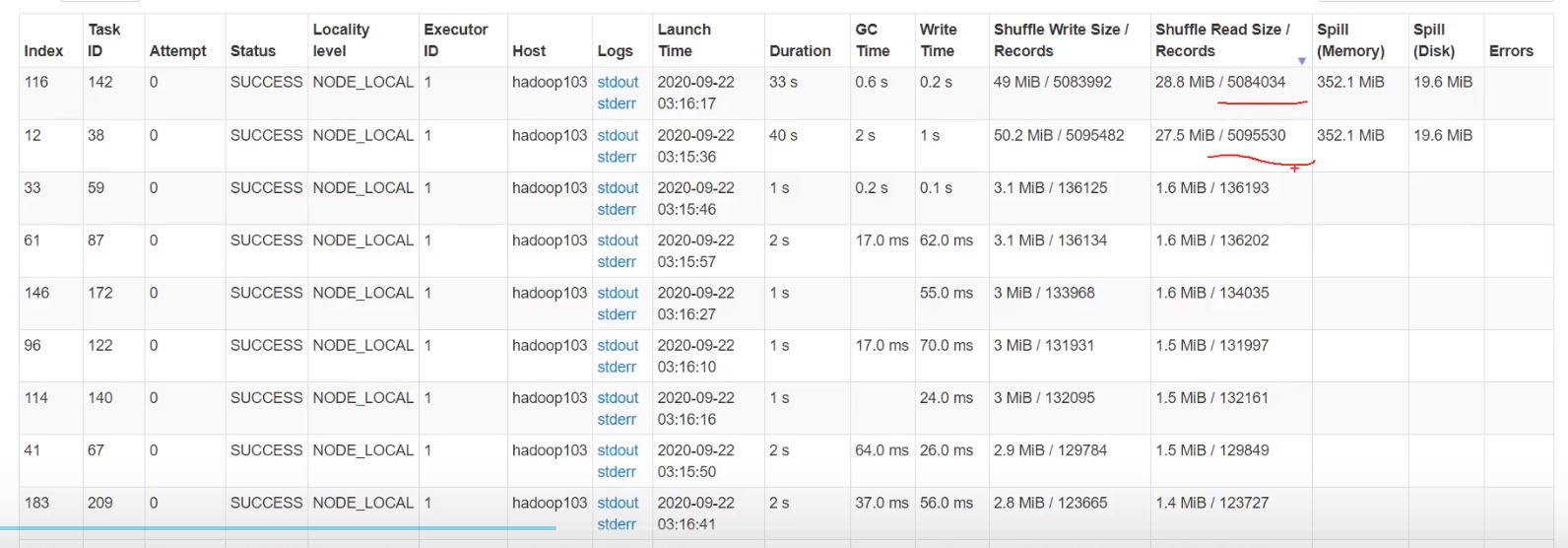
5.1 解决数据倾斜错误方法
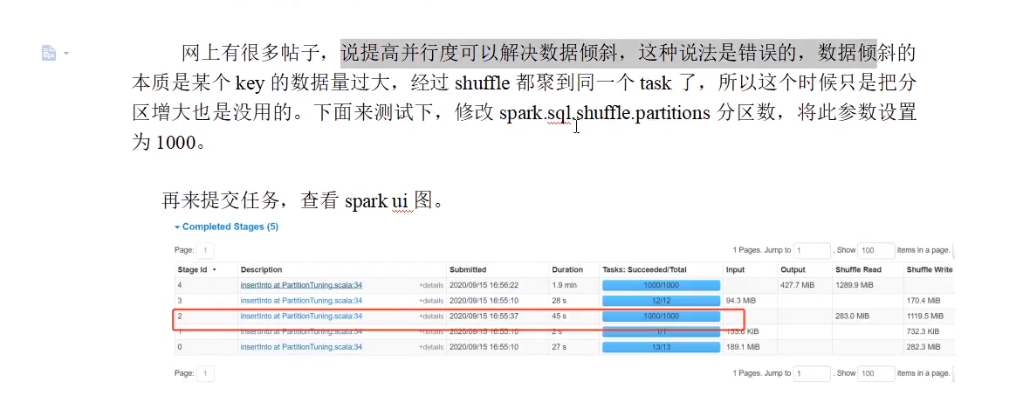

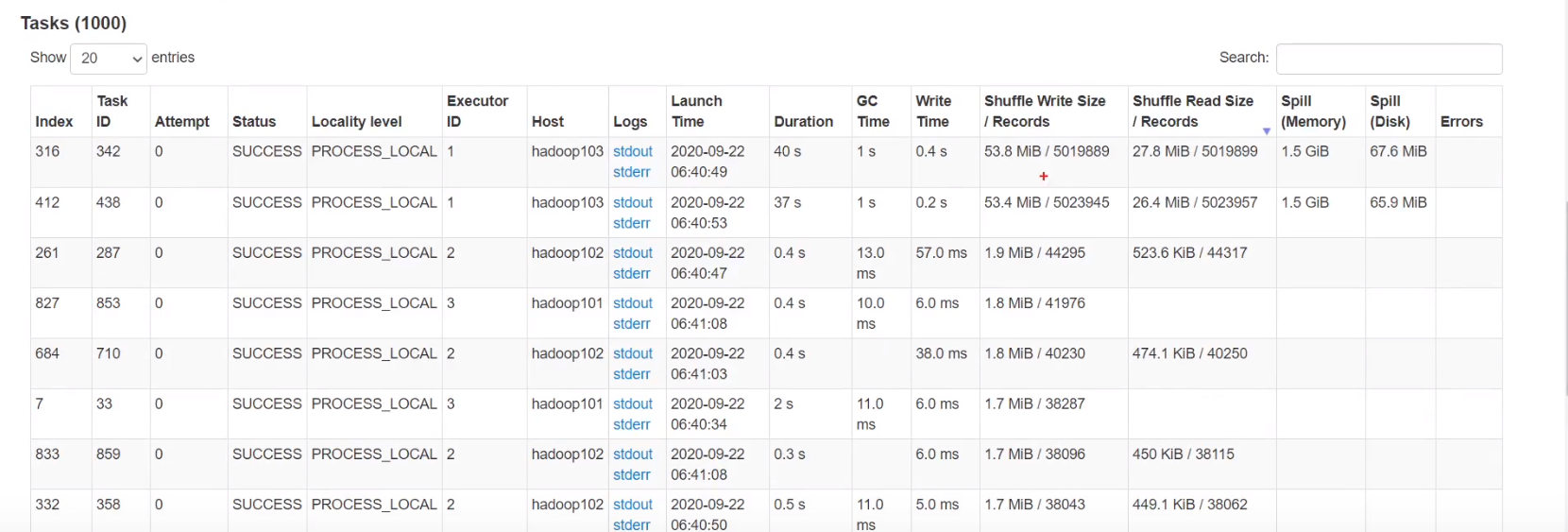
5.2 解决数据倾斜
1、广播join
2、打散大表,扩容小表 能解决,但可能更加耗时,因为小表数据量增加了
除非情况非常严重,结果出不来


拿打散后的courseId进行join

可以看到dataframe.map后变成dataset


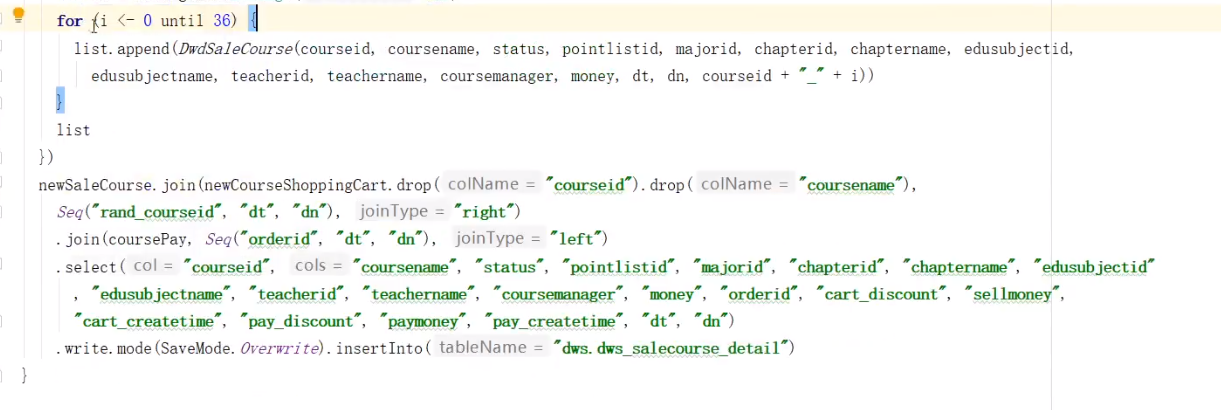
循环里面为i+"_"+courseid,写错了
可以看到已经得到优化
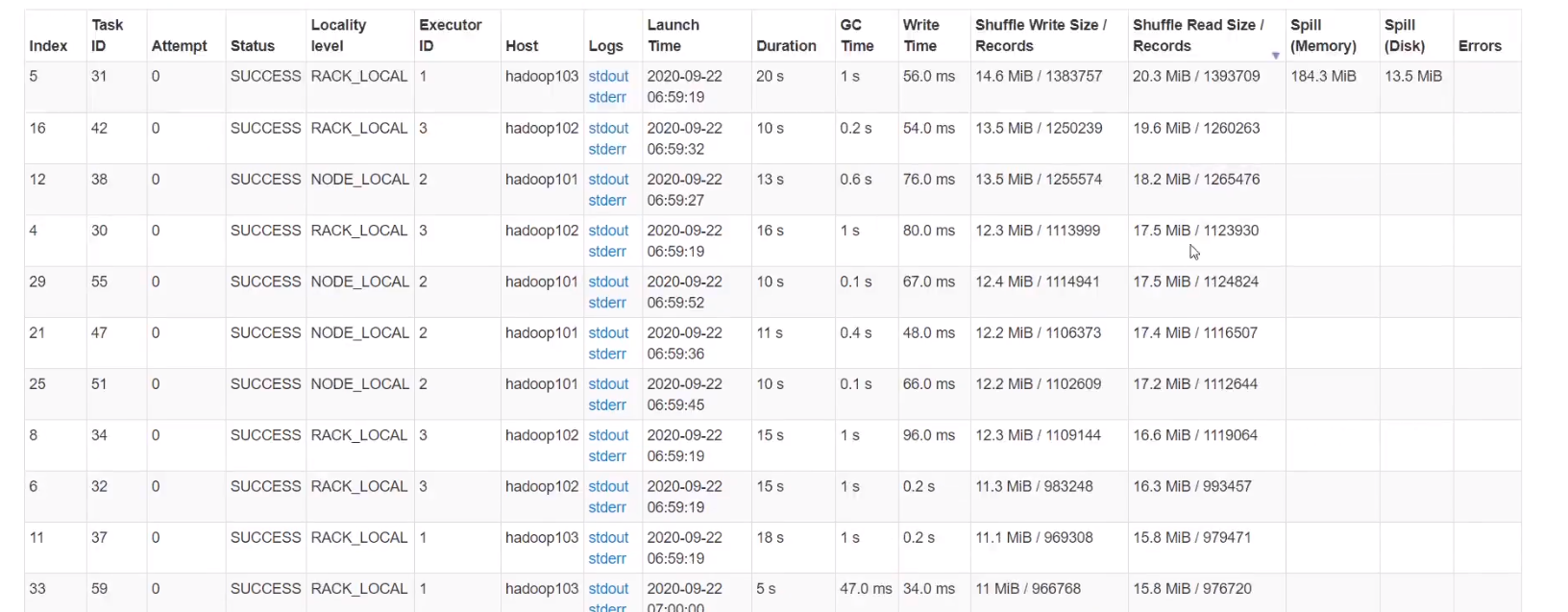
但是时间由变成50秒
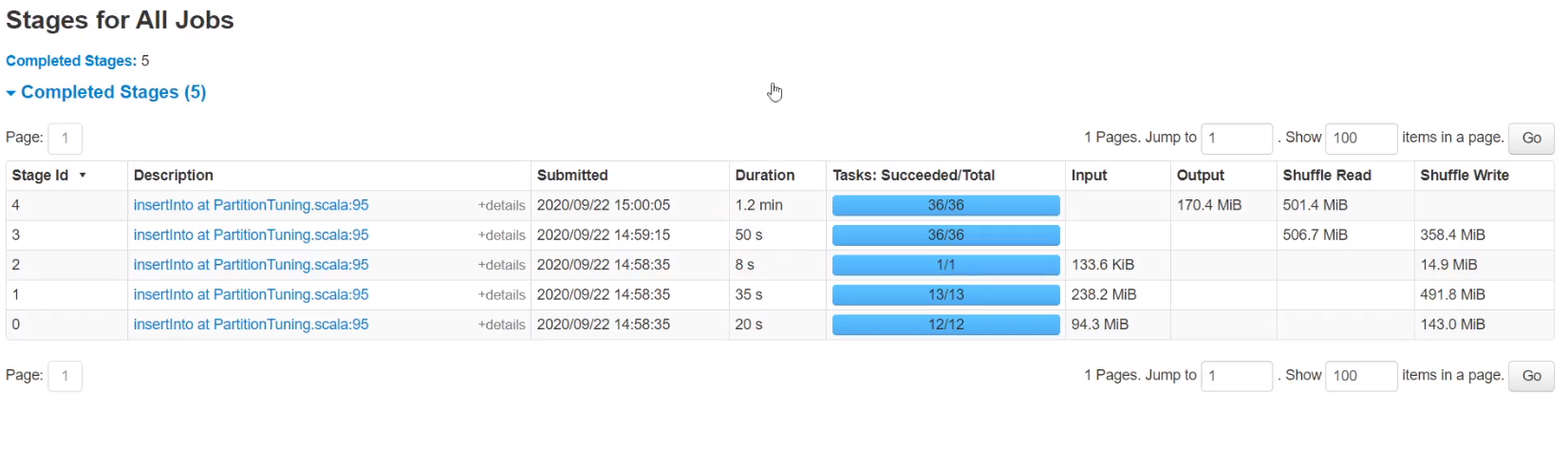
和3中只缩小分区34秒时间增加,虽然3中有数据倾斜
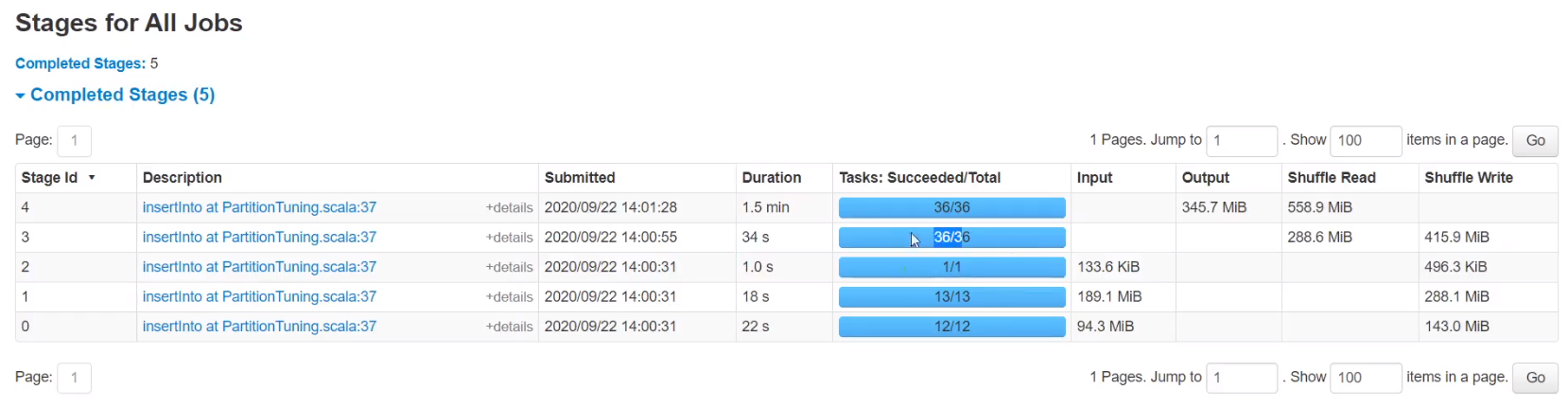

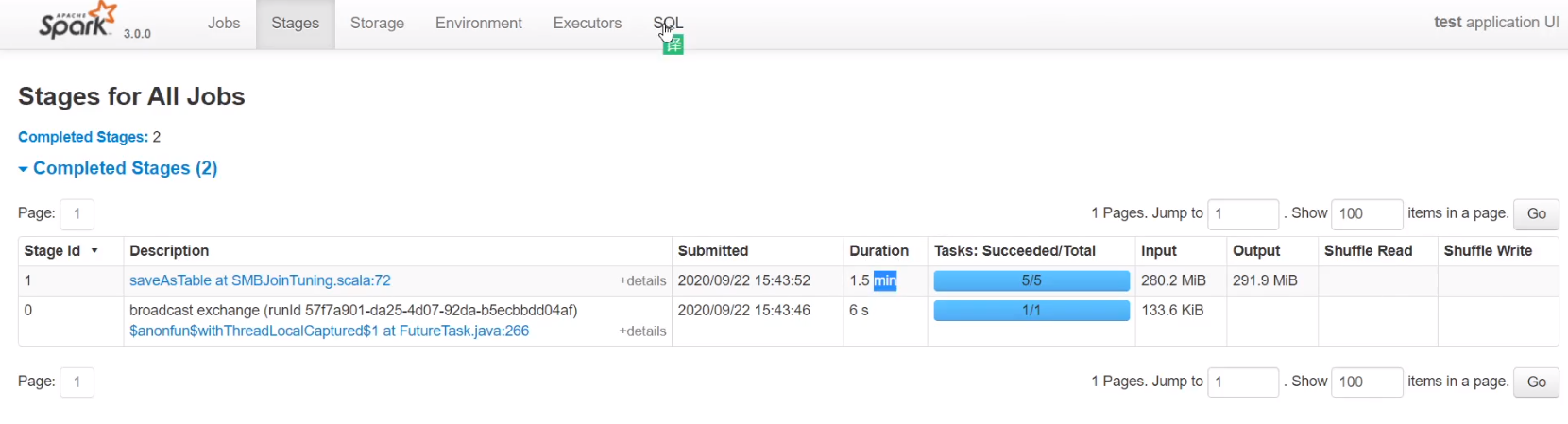
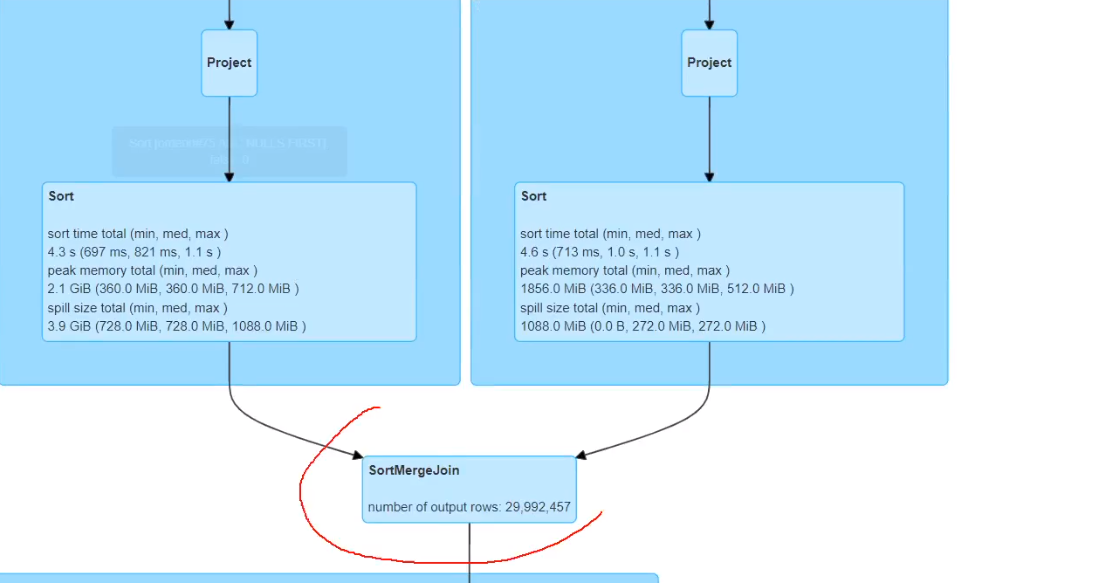
6、SMB join
排序时间优化,数据量大的时候效果很明显


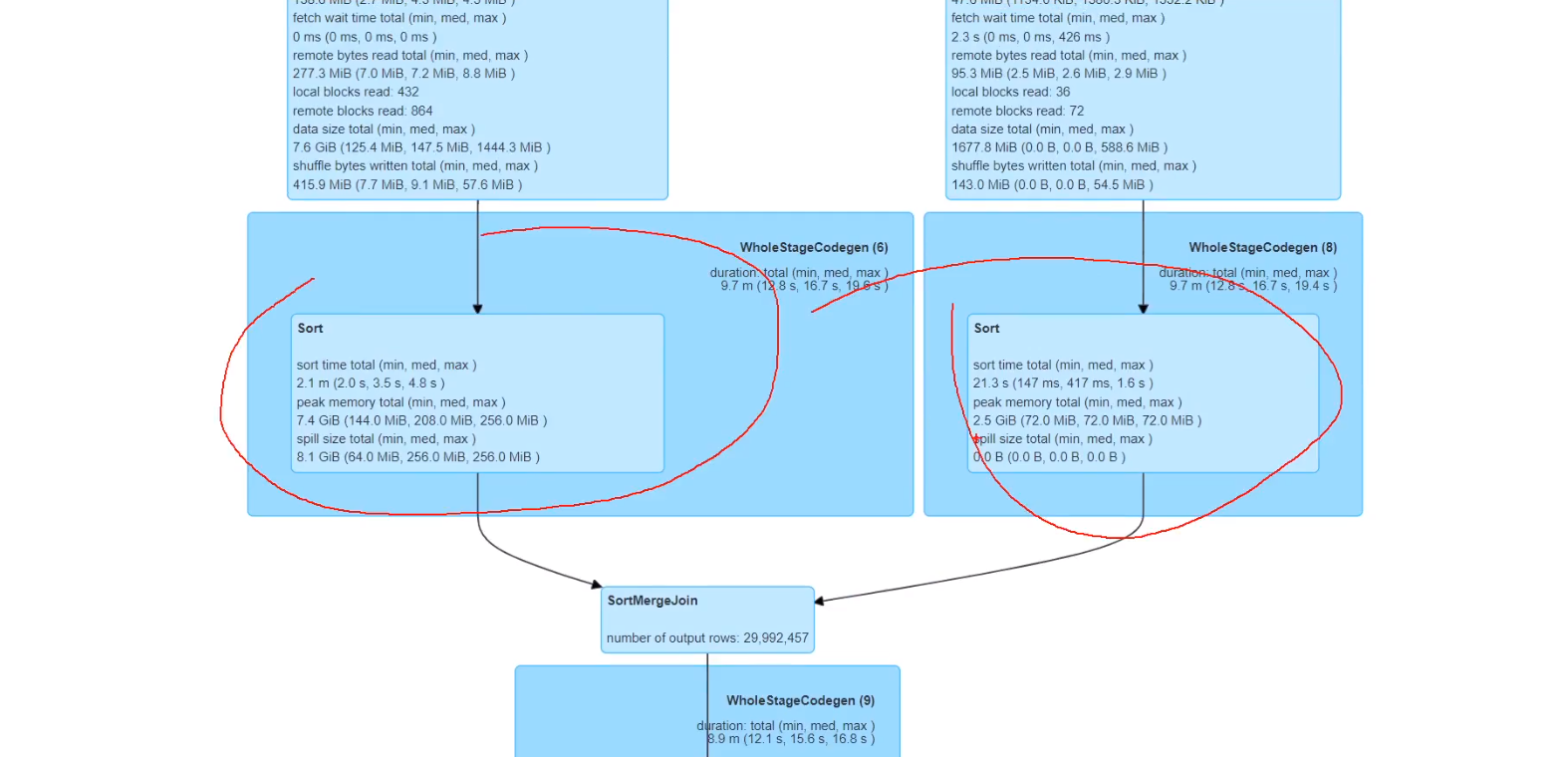
spark中支持分桶必须用saveastable,insertinto不支持分桶

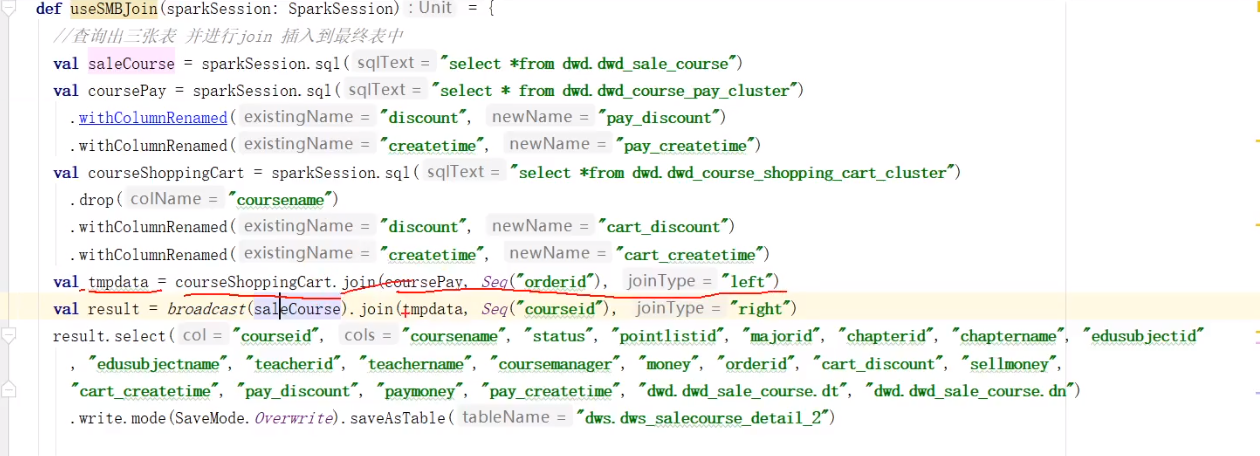
先拿两张分桶表做join
分桶后task数就和分桶数一样
7、使用堆外内存



3.0之前
3.0之后

修改内存测试

max(2G*0.1 384)
2G+2G+384>4G
实际申请4个G,申请会大于4个G

堆外内存使用
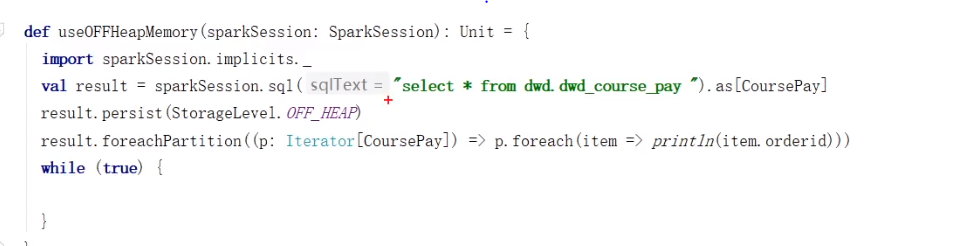



堆内堆外会互相借用
什么情况下使用堆外内存

spark sql优化的更多相关文章
- Spark SQL概念学习系列之Spark SQL 优化策略(五)
查询优化是传统数据库中最为重要的一环,这项技术在传统数据库中已经很成熟.除了查询优化, Spark SQL 在存储上也进行了优化,从以下几点查看 Spark SQL 的一些优化策略. (1)内存列式存 ...
- spark sql 优化心得
本篇文章主要记录最近在使用spark sql 时遇到的问题已经使用心得. 1 spark 2.0.1 中,启动thriftserver 或者是spark-sql时,如果希望spark-sql run ...
- spark第七篇:Spark SQL, DataFrame and Dataset Guide
预览 Spark SQL是用来处理结构化数据的Spark模块.有几种与Spark SQL进行交互的方式,包括SQL和Dataset API. 本指南中的所有例子都可以在spark-shell,pysp ...
- spark SQL (一)初识 ,简介
一, 简介 Spark SQL是用于结构化数据处理的Spark模块.与基本的Spark RDD API不同,Spark SQL提供的接口为Spark提供了关于数据结构和正在执行的计算的更多信息.在内部 ...
- Spark SQL知识点大全与实战
Spark SQL概述 1.什么是Spark SQL Spark SQL是Spark用于结构化数据(structured data)处理的Spark模块. 与基本的Spark RDD API不同,Sp ...
- Spark SQL知识点与实战
Spark SQL概述 1.什么是Spark SQL Spark SQL是Spark用于结构化数据(structured data)处理的Spark模块. 与基本的Spark RDD API不同,Sp ...
- 深入研究Spark SQL的Catalyst优化器(原创翻译)
Spark SQL是Spark最新和技术最为复杂的组件之一.它支持SQL查询和新的DataFrame API.Spark SQL的核心是Catalyst优化器,它以一种新颖的方式利用高级编程语言特性( ...
- Spark SQL 性能优化再进一步:CBO 基于代价的优化
摘要: 本文将介绍 CBO,它充分考虑了数据本身的特点(如大小.分布)以及操作算子的特点(中间结果集的分布及大小)及代价,从而更好的选择执行代价最小的物理执行计划,即 SparkPlan. Spark ...
- 47、Spark SQL核心源码深度剖析(DataFrame lazy特性、Optimizer优化策略等)
一.源码分析 1. ###入口org.apache.spark.sql/SQLContext.scala sql()方法: /** * 使用Spark执行一条SQL查询语句,将结果作为DataFram ...
随机推荐
- ElasticSearch- 单节点 unassigned_shards 故障排查
故障现象 在部署ELK的单机环境,当连接Kibana时候提示下面错误,即使重启整个服务也是提示Kibana server is not ready. {"message":&quo ...
- 【C++】《Effective C++》第八章
第八章 定制new和delete 对于程序开发来说,了解C++内存管理例程的行为是非常重要的.其中两个主角是分配例程和归还例程(operator new和operator delete),配角是new ...
- 【排序基础】5、插入排序法 - Insertion Sort
插入排序法 - Insertion Sort 文章目录 插入排序法 - Insertion Sort 插入排序设计思想 插入排序代码实现 操作:插入排序与选择排序的比较 简单记录-bobo老师的玩转算 ...
- 《Go 语言并发之道》读后感 - 第四章
<Go 语言并发之道>读后感-第四章 约束 约束可以减轻开发者的认知负担以便写出有更小临界区的并发代码.确保某一信息再并发过程中仅能被其中之一的进程进行访问.程序中通常存在两种可能的约束: ...
- js中常用追加元素的几种方法
<!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <title> ...
- kettle数据质量统计
1.利用Kettle的"分组","JavaScript代码","字段选择"组件,实现数据质量统计.2.熟练掌握"JavaScrip ...
- Py集合,字符串的格式化,函数,便利
可变与不可变 不可变指的是:重新赋值时,内存中的id值会变得 其中有:字符串,数字,元组 name="sb" v=id(name) print(v) name ="ale ...
- selenium浏览器弹出框alert 操作
1.简介 在WebDriver中要处理JS生成的alert.confirm以及prompt,需要 switch_to.alert() 来选取(定位)警告弹窗,在对弹窗进行关闭.输入等信息操作. 2.操 ...
- Soul API 网关源码解析 02
如何读开源项目:对着文档跑demo,对着demo看代码,懂一点就开始试,有问题了问社区. 今日目标: 1.运行examples下面的 http服务 2.学习文档,结合divde插件,发起http请求s ...
- MySQL的双主配置
配置MySQL双主配置,需要先配置MySQL的主从复制,传送门: 0.集群规划 hadoop105 hadoop106 hadoop107 MySQL(master,slave) MySQL(slav ...