(十) 数据库查询处理之排序(sorting)
1. 为什么我们需要对数据排序
- 可以支持对于重复元素的清除(支持DISTINCT)
- 可以支持GROUP BY 操作
- 对于关系运算中的一些运算能够得到高效的实现
2. 引入外部排序算法
对于不能全部放在内存中的关系的排序。就需要引入外排序,其中最常用的技术就是外部归并排序。
外部排序分为两个阶段
Phase1 - Sorting
对主存中的数据块进行排序,然后将排序后的数据块写回磁盘。
Phase2 - Merging
将已排序的子文件合并成一个较大的文件
2.1 N-way 外部归并排序
从2路归并排序开始。来引出N路归并排序算法
可以见下图


对于简单的二路归并。我们有两个buffer可以用。一个用来放输入进行排序得到归并块。而另一个则用来放输出
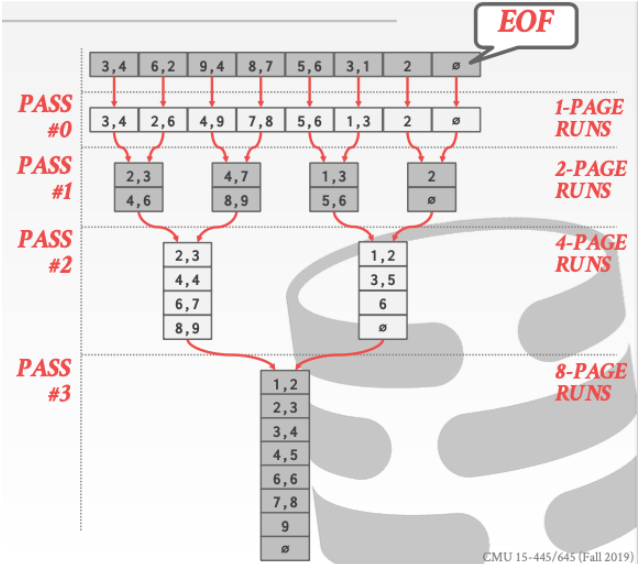
下面来分析一下二路归并的时间复杂度
在每一个阶段我们都需要把归并块从磁盘中读入。然后在写回磁盘因此总共的I/O次数就是阶段数 * 2
阶段数可以很容易的得到为

可以很容易的发现上面的问题主要出现在。由于我们的输入缓冲区只能放一个page。所以这导致了我们不停的进行换入换出导致了io次数变得非常多。优化方法就是加大缓冲区大小。减少阶段数。这就需要我们归并路数增大。
使用B buffer pages 这样我们的输入缓冲区就可以放B - 1个page。这样我们的阶段数就可以减少了。

2.2 利用索引进行加速
如果我们的table中已经有了B+树索引。那么我们可以利用它进行优化。
这里有两种情况需要被考虑
聚簇索引
数据的物理地址顺序和索引的顺序是一致的。
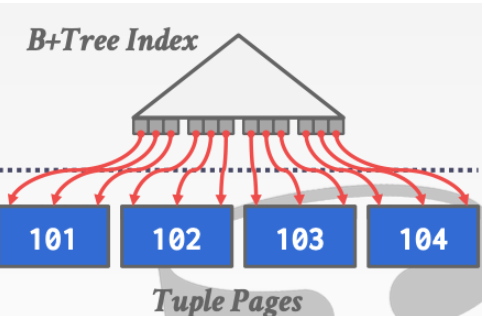
这种方法比外部排序要好,因为它没有额外的计算。比如不需要进行sort。不需要进行归并。而且所有的磁盘访问都是顺序的。
非聚簇索引
数据的物理地址顺序和索引的顺序是不一致的。
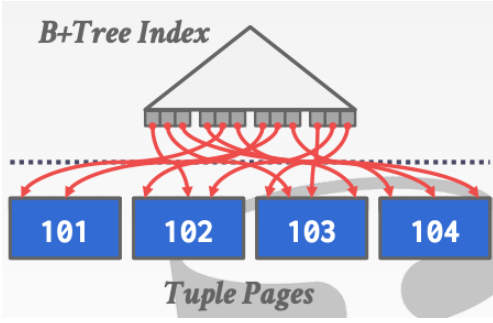
如果是这样的索引。就利用外部排序就好。
2.3 AGGREGATIONS
将多个元组折叠为单个标量值。有两种实现方法
1. 排序
排序之后相同的元素就会在排在一起。这样就可以去除冗余元素

2. hash
但是如果我们不要求数据是有序的。这样我们排序就相当于浪费了时间。因为排序起码要花费nlogn的时间。比如GROUP BY
和DISTINCT操作。在这种情况下。hashing就是一个更好的选择
1. Partition
假设我们有B buffers。其中B - 1个buffer用来partitions而1个buffer用来存储输出data。
第一阶段就是利用一个hash函数。把tuple哈希到不同的桶中。

2. Rehash
由于阶段1之后。拥有相同cid值的tuple都被映射到了相同的桶内。这个阶段我们对不同的桶在进行一次hash。就可以完成我们的去重操作。
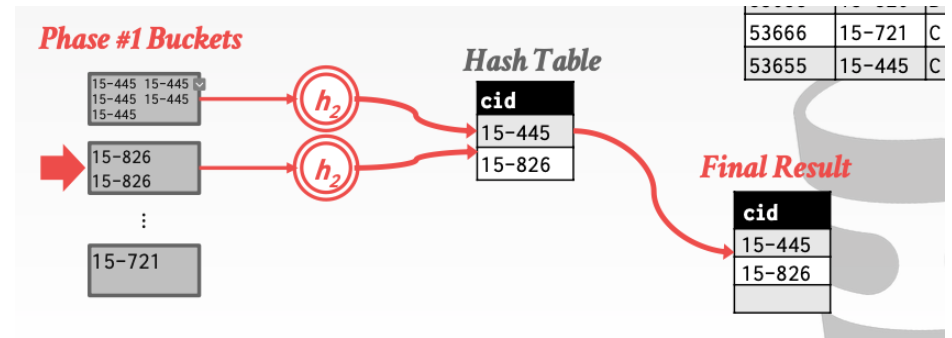
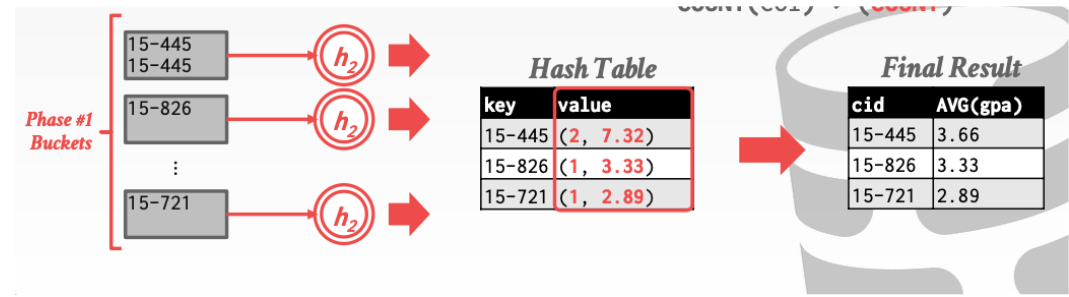
当然利用hash操作不仅可以进行去重还可以进行其他的操作。如MAX、MIN、AVG、COUNT、SUM等
下面这张图演示了count操作和sum操作。
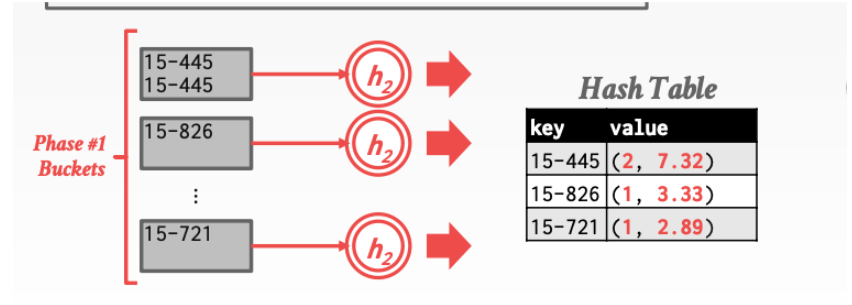
这张图演示了avg操作就是利用 sum / count
这个算是结合cmu15-445课程和对应的教材、ppt进行的总结。顺序从10开始是因为现在正好看到这里。而之前忘了整理了。会在后面所有的都看完之后进行整理的。
(十) 数据库查询处理之排序(sorting)的更多相关文章
- (十二)数据库查询处理之Query Execution(1)
(十二)数据库查询处理之Query Execution(1) 1. 写在前面 这一大部分就是为了Lab3做准备的 每一个query plan都要实现一个next函数和一个init函数 对于next函数 ...
- MySQL 按照数据库表字段动态排序 查询列表信息
MySQL 按照数据库表字段动态排序 查询列表信息 背景描述 项目中数据列表分页展示的时候,前端使用的Table组件,每列自带对当前页的数据进行升序或者降序的排序. 但是客户期望:随机点击某一列的时候 ...
- 第九十九天上课 PHP TP框架 数据库查询和增加
在Model文件夹下创建模型,文件命名规则 : 表名Model.class.php <?php namespace Home\Model; use Think\Model; class yong ...
- mysql数据库查询过程探究和优化建议
查询过程探究 我们先看一下向mysql发送一个查询请求时,mysql做了什么? 如上图所示,查询执行的过程大概可分为6个步骤: 客户端向MySQL服务器发送一条查询请求 服务器首先检查查询缓存,如果命 ...
- 下面介绍一下 Yii2.0 对数据库 查询的一些简单的操作
下面介绍一下 Yii2.0 对数据库 查询的一些简单的操作 User::find()->all(); 此方法返回所有数据: User::findOne($id); 此方法返回 主键 id=1 的 ...
- 50种方法优化SQL Server数据库查询
查询速度慢的原因很多,常见如下几种: 1.没有索引或者没有用到索引(这是查询慢最常见的问题,是程序设计的缺陷) 2.I/O吞吐量小,形成了瓶颈效应. 3.没有创建计算列导致查询不优化. 4.内存不足 ...
- 优化SQL Server数据库查询方法
SQL Server数据库查询速度慢的原因有很多,常见的有以下几种: 1.没有索引或者没有用到索引(这是查询慢最常见的问题,是程序设计的缺陷) 2.I/O吞吐量小,形成了瓶颈效应. 3.没有创建计算列 ...
- mysql 数据库查询与实例。
资料是从教材弄下来的,加上了我的理解.主要内容是练习实例,在写博文中学习命令行,当然也希望这篇博文能帮助其他人学习mysq数据库命令 SELECT 语句可以从一个或多个表中选取特定的行和列 SELEC ...
- 转载 50种方法优化SQL Server数据库查询
原文地址 http://www.cnblogs.com/zhycyq/articles/2636748.html 50种方法优化SQL Server数据库查询 查询速度慢的原因很多,常见如下几种: 1 ...
随机推荐
- C - Door Man(欧拉回路_格式控制)
现在你是一个豪宅的管家,因为你有个粗心的主人,所以需要你来帮忙管理,输入会告诉你现在一共有多少个房间,然后会告诉你从哪个房间出发,你的任务就是从出发的房间通过各个房间之间的通道,来把所有的门都关上,然 ...
- 「SCOI2005」互不侵犯 (状压DP)
题目链接 在\(N\times N\) 的棋盘里面放 \(K\)个国王,使他们互不攻击,共有多少种摆放方案.国王能攻击到它上下左右,以及左上左下右上右下八个方向上附近的各一个格子,共\(8\) 个格子 ...
- 2018-2019 ACM-ICPC, NEERC, Southern Subregional Contest, Qualification Stage(11/12)
2018-2019 ACM-ICPC, NEERC, Southern Subregional Contest, Qualification Stage A. Coffee Break 排序之后优先队 ...
- STL中去重函数unique
一:unique(a.begin(),a.end());去重函数只是去掉连续的重复值,对于不连续的值没有影响,SO,在使用前一般需要进行排序处理: 二: vector<int>::ite ...
- POJ - 2553 tarjan算法+缩点
题意: 给你n个点,和m条单向边,问你有多少点满足(G)={v∈V|∀w∈V:(v→w)⇒(w→v)}关系,并把这些点输出(要注意的是这个关系中是蕴含关系而不是且(&&)关系) 题解: ...
- 【ybt高效进阶2-4-3】【luogu P4551】最长异或路径
最长异或路径 题目链接:ybt高效进阶2-4-3 / luogu P4551 题目大意 给定一棵 n 个点的带权树,结点下标从 1 开始到 N.寻找树中找两个结点,求最长的异或路径. 异或路径指的是指 ...
- OpenStack Train版-10.安装neutron网络服务(网络节点:可选)
可选:安装neutron网络服务节点(neutron01网络节点192.168.0.30)网络配置按照官网文档的租户自助网络 配置系统参数 echo 'net.ipv4.ip_forward = 1' ...
- eclispe中解决OOM问题
-Xms256M -Xmx512M -XX:PermSize=256m -XX:MaxPermSize=512m
- Java RMI 实现一个简单的GFS(谷歌文件系统)——背景与设计篇
目录 背景 系统设计 1. 系统功能 2. Master组件 2.1 命名空间 2.2 心跳机制 2.3 故障恢复和容错机制 3. ChunkServer组件 3.1 本地存储 3.2 内存命中机制 ...
- woj1010 alternate sum 数学 woj1011 Finding Teamates 数学
title: woj1010 alternate sum 数学 date: 2020-03-10 categories: acm tags: [acm,woj,数学] 一道数学题.简单. 题意 给一个 ...