机器学习笔记簿 降维篇 PCA 01
降维是机器学习中十分重要的部分,降维就是通过一个特定的映射(可以是线性的或非线性的)将高维数据转换为低维数据,从而达到一些特定的效果,所以降维算法最重要的就是找到这一个映射。主成分分析(Principal Component Analysis, PCA)是一种最经典,也是最简单的降维算法。PCA可以保证降维之后,重构回原数据的效果最好,因此广泛用于对高维数据的预处理。
1. 一个投影的PCA求解
设样本矩阵为\(X=[x_1,x_2,\cdots,x_n]\in \mathbb R^{m\times n}\),其中样本向量\(x_i\in\mathbb R^m\),样本均值为
\]
我们现在要找到一个投影向量\(p\in\mathbb R^m\),且\(\|p\|_2=1\),将各样本映射到一个\(1\)维空间中,
\]
在这里,\(p^Tx\)称为一个主成分。
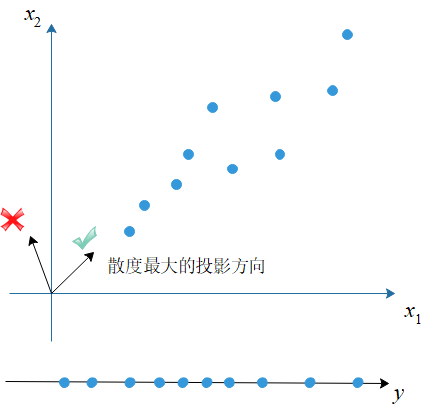
PCA的目标是最大化投影后的样本方差,方差也可以称为样本的散度,方差越大则样本的散度越大(样本点在空间中的分布越散乱),相反,如果散度越小,样本投影之后越聚集,就越难以重构(可以结合信息熵来理解,熵值越大信息越多)。最大化散度的方案可以保证投影产生的信息丢失最少,因此PCA总可以保证降维之后的数据是最接近原数据的。在当前情形下,PCA的优化问题是:
&&\max_{p^Tp=1} \sum_{i=1}^n{(y-\bar y)^2}\\
=&&\max_{p^Tp=1} \sum_{i=1}^n{(p^Tx-p^T\bar x)^2}\\
=&&\max_{p^Tp=1} \sum_{i=1}^n{(p^Tx-p^T\bar x)(p^Tx-p^T\bar x)^T}\\
=&&\max_{p^Tp=1} \sum_{i=1}^n{p^T(x-\bar x)(x-\bar x)^Tp}\\
=&&\max_{p^Tp=1} p^T\left[\sum_{i=1}^n{(x-\bar x)(x-\bar x)^T}\right]p\\
=&&\max_{p^Tp=1} p^TSp\tag{1}
\end{eqnarray*}
\]
其中,定义散度矩阵(亦称作协方差矩阵)为
\]
这里\(\hat X\)是去中心化后的样本矩阵,即\(\hat X=[x_1-\bar x,x_2-\bar x,\cdots,x_n-\bar x]\),考虑到\((1)\)中含有等式约束,我们可以用使用拉格朗日乘数法解优化问题\((1)\),首先定义拉格朗日函数为
\]
令\(L\)对\(p\)的偏导为\(0\)得到:
\frac{\partial L}{\partial p}&=&Sp-\lambda p=0\\
\Rightarrow Sp&=&\lambda p\tag{2}
\end{eqnarray*}
\]
将\((2)\)代回\((1)\)中得到
&&\max_{p^Tp=1}{p^TSp}\\=&&\max_{p^Tp=1}{p^T\lambda p}\\=&&\max_{p^Tp=1}{\lambda}\tag{3}
\end{eqnarray*}
\]
显然\((2)\)是一个特征值问题,根据\((3)\)可以知道,最大的特征值对应的特征向量就是我们所需的投影向量\(p\)。
2. 多个投影的PCA求解
在前面我们获得了一个投影向量,可以将样本投影到一维空间,在一般情况下我们需要指定降维维数\(d\),这样就需要\(d\)个投影向量。这样我们的目标就是一个投影矩阵\(P=[p_1,p_2,\cdots,p_d]\in\mathbb{R}^{m\times d}\),并且\(P\)的各个投影\(p_i\)都是标准正交的(正交性可以保证每一个主成分之间都互不相关),也即\(P^TP=I\)。样本可以通过\(P\)投影到\(d\)维空间:
\]
\(y\)中的每一个元素都是一个主成分,此处它包含了个\(d\)个互不相关的主成分。
PCA的优化目标仍然是最大化样本的散度,同理,它的优化目标是:
&&\max_{P^TP=I} \sum_{i=1}^n{\|y-\bar y\|^2_2}\\
=&&\max_{P^TP=I} \sum_{i=1}^n{\|P^Tx-P^T\bar x\|^2_2}\\
=&&\max_{P^TP=I} \sum_{i=1}^n{tr\left[(P^Tx-P^T\bar x)(P^Tx-P^T\bar x)^T\right]}\\
=&&\max_{P^TP=I} \sum_{i=1}^n{tr\left[P^T(x-\bar x)(x-\bar x)^TP\right]}\\
=&&\max_{P^TP=I} tr\left\{P^T\left[\sum_{i=1}^n{(x-\bar x)(x-\bar x)^T}\right]P\right\}\\
=&&\max_{P^TP=I} tr(P^TSP)\\
=&&\max_{p_i^Tp_i=1} \sum_{i=1}^n{p_i^TSp_i}\tag{4}
\end{eqnarray*}
\]
这里\((4)\)和\((1)\)具有相同的形式,我们仍然可以通过拉格朗日乘数法来求解,而这里我们获得的投影矩阵是\(S\)的前\(d\)个最大特征值对应的特征向量依次排列组成的。
一般我们定义能量占比来选取\(d\)的大小,设定一个阈值\(\alpha\)(一般取\(0.95,0.98\)等),则\(d\)由下式给出
\]
\(\lambda_i\)是第\(i\)大的特征值,\(E\)是能量占比,这个式子的意义是,选择能够使能量占比达到阈值的最小的\(d\)作为降维维数,这样可以保证主要的信息(也就是特征值大的那些投影)能够被获取,那些特征值很小的投影被丢弃,PCA通过这种方式可以去除散度矩阵的零空间,从而去除了原样本的无用信息。
总结一下,PCA的步骤很简单:
计算去中心化后的样本矩阵矩阵\(\hat X\),求出散度矩阵\(S\)
对散度矩阵\(S\)进行特征分解
最后取它前\(d\)个最大特征值的特征向量作为投影矩阵\(P\)。
3. 基于最小化重构误差的理解
以上我们从最大化散度的角度出发理解了PCA。由于PCA本质上要求降维产生的数据信息的损失最少,因此我们可以从最小化重构误差的角度出发,也能得到相同的结果。
首先我们需要知道投影后的数据是如何重构的,在这里重构就是投影的逆过程,重构数据就因此被定义为
\]
在这里,PCA想要做到重构后的数据可以近似为原始数据,即
\]
这里的\(y_ip_i(i=1,2,\cdots,d)\)其实是数据的每一个投影分量。也就是说我们希望误差\(\|x-x'\|_2\)越小越好,对应的优化问题是
&&\min_{P^TP=I}\sum_{i=1}^n{\|x_i-x_i'\|_2^2}\\
=&&\min_{P^TP=I}\sum_{i=1}^n{\|x_i-PP^Tx_i\|_2^2}\\
=&&\min_{P^TP=I}{\|X-PP^TX\|_F^2}\\
=&&\min_{P^TP=I}tr\left[(X-PP^TX)(X-PP^TX)^T\right]\\
=&&\min_{P^TP=I}tr(XX^T)-2tr(XX^TPP^T)+tr(PP^TXX^TPP^T)\\
=&&\min_{P^TP=I}tr(P^TXX^TPP^TP)-2tr(P^TXX^TP)\\
=&&\min_{P^TP=I}-tr(P^TXX^TP)\\
=&&\max_{P^TP=I}tr(P^TXX^TP)\\
\end{eqnarray*}
\]
如果假设散度矩阵是\(S_0=XX^T\),则原优化问题变为
\]
这个问题我们已经很熟悉了:\(P\)就是\(S_0\)的前\(d\)个最大特征值对应的特征向量组成的。
注意到,在之前我们用到的散度矩阵是\(S=\hat X\hat X^T\),这里的\(\hat X\)是去中心化过的样本矩阵,但根据以上的推导,样本矩阵完全可以不用去中心化,直接计算\(S_0\)进行特征分解依然可以实现PCA,但这不意味着用\(S\)和用\(S_0\)得到的计算结果是相同的:去中心化可以帮助减少样本数据偏移(bias)的影响,不去中心化时可以用更少的投影就达到很好的重构效果,在样本均值为\(0\)的时候,这两种方法没有区别。在实际应用中,使用\(S_0\)或者\(S\)作特征分解都是可行的。
机器学习笔记簿 降维篇 PCA 01的更多相关文章
- 机器学习笔记簿 降维篇 LDA 01
机器学习中包含了两种相对应的学习类型:无监督学习和监督学习.无监督学习指的是让机器只从数据出发,挖掘数据本身的特性,对数据进行处理,PCA就属于无监督学习,因为它只根据数据自身来构造投影矩阵.而监督学 ...
- iOS开发Swift篇(01) 变量&常量&元组
iOS开发Swift篇(01) 变量&常量&元组 说明: 1)终于要写一写swift了.其实早在14年就已经写了swift的部分博客,无奈时过境迁,此时早已不同往昔了.另外,对于14年 ...
- 【机器学习】主成分分析法 PCA (I)
主成分分析算法是最常见的降维算法,在PCA中,我们要做的是找到一个方向向量,然后我们把所有的数都投影到该向量上,使得投影的误差尽可能的小.投影误差就是特征向量到投影向量之间所需要移动的距离. PCA的 ...
- 机器学习算法总结(九)——降维(SVD, PCA)
降维是机器学习中很重要的一种思想.在机器学习中经常会碰到一些高维的数据集,而在高维数据情形下会出现数据样本稀疏,距离计算等困难,这类问题是所有机器学习方法共同面临的严重问题,称之为“ 维度灾难 ”.另 ...
- 机器学习基础与实践(三)----数据降维之PCA
写在前面:本来这篇应该是上周四更新,但是上周四写了一篇深度学习的反向传播法的过程,就推迟更新了.本来想参考PRML来写,但是发现里面涉及到比较多的数学知识,写出来可能不好理解,我决定还是用最通俗的方法 ...
- 机器学习实战基础(二十一):sklearn中的降维算法PCA和SVD(二) PCA与SVD 之 降维究竟是怎样实现
简述 在降维过程中,我们会减少特征的数量,这意味着删除数据,数据量变少则表示模型可以获取的信息会变少,模型的表现可能会因此受影响.同时,在高维数据中,必然有一些特征是不带有有效的信息的(比如噪音),或 ...
- 机器学习之路:python 特征降维 主成分分析 PCA
主成分分析: 降低特征维度的方法. 不会抛弃某一列特征, 而是利用线性代数的计算,将某一维度特征投影到其他维度上去, 尽量小的损失被投影的维度特征 api使用: estimator = PCA(n_c ...
- 吴裕雄 python 机器学习——主成份分析PCA降维
# -*- coding: utf-8 -*- import numpy as np import matplotlib.pyplot as plt from sklearn import datas ...
- 机器学习实战基础(二十七):sklearn中的降维算法PCA和SVD(八)PCA对手写数字数据集的降维
PCA对手写数字数据集的降维 1. 导入需要的模块和库 from sklearn.decomposition import PCA from sklearn.ensemble import Rando ...
随机推荐
- Python线程池与进程池
Python线程池与进程池 前言 前面我们已经将线程并发编程与进程并行编程全部摸了个透,其实我第一次学习他们的时候感觉非常困难甚至是吃力.因为概念实在是太多了,各种锁,数据共享同步,各种方法等等让人十 ...
- BUUCTF-BJD(更新V1.0)
CTF-Day1 (PS:第一次写博客,就是想记录自己的一一步一步) Misc: 问卷调查 | SOLVED |题最简单的misc-y1ng | SOLVED |Real_EasyBaBa | SOL ...
- 小程序报错 parameter.content should be String instead of Undefined;
自己遇到了两种情况会导致这个问题 1.参数名写错未定义,然后赋值的时候值为undefined 2.服务端返回的值错误,返回的值为空,导致赋值时报错 解决方法: 1.检查参数名,如不是全局变量的应在da ...
- 【DevCloud · 敏捷智库】两种你必须了解的常见敏捷估算方法
背景 在某开发团队辅导的回顾会议上,团队成员对于优化估计具体方法上达成了一致意见.询问是否有什么具体的估计方法来做估算. 问题分析 回顾意见上大家对本次Sprint的效果做回顾,其中80%的成员对于本 ...
- 萌新计划 PartⅡ
Part Ⅱ web 9-15 这一部分的题,主要是绕过过滤条件,进行命令执行 0x01 web 9 过滤条件: if(preg_match("/system|exec|highlight/ ...
- 数据可视化基础专题(七):Pandas基础(六) 数据增删改以及相关操作
首先第一部还是导入 Pandas 与 NumPy ,并且要生成一个 DataFrame ,这里小编就简单的使用随机数的形式进行生成,代码如下: import numpy as np import pa ...
- python 并发 ThreadPoolExecutor
正文:Executor是一个抽象类,子类: ThreadPoolExecutor和ProcessPoolExecutor ,一个线程池,一个进程池. future对象:在未来的某一时刻完成操作的对象. ...
- python网络编程05 /TCP阻塞机制
python网络编程05 /TCP阻塞机制 目录 python网络编程05 /TCP阻塞机制 1.什么是拥塞控制 2.拥塞控制要考虑的因素 3.拥塞控制的方法: 1.慢开始和拥塞避免 2.快重传和快恢 ...
- Python之爬虫(十七) Scrapy框架中Spiders用法
Spider类定义了如何爬去某个网站,包括爬取的动作以及如何从网页内容中提取结构化的数据,总的来说spider就是定义爬取的动作以及分析某个网页 工作流程分析 以初始的URL初始化Request,并设 ...
- Linux如何用脚本监控Oracle发送警告日志ORA-报错发送邮件
Linux如何用脚本监控Oracle发送警告日志ORA-报错发送邮件 前言 公司有购买的监控软件北塔系统监控,由于购买的版权中只包含了有限台数据库服务器的监控,所以只监控了比较重要的几台服务器. 后边 ...