Python3爬取小说并保存到文件
问题
python课上,老师给同学们布置了一个问题,因为这节课上学的是正则表达式,所以要求利用python爬取小说网的任意小说并保存到文件。
我选的网站的URL是‘https://www.biqukan.com/0_159/’
解决方法
首先先思考解决方式。
- 先获取到网页源码,从源码中找出小说的名字和目录结构
- 创建文件保存的目录,目录名是小说名
- 从网页代码中获取小说的目录列表
- 循环遍历目录,获取目录中每篇的超链接和文章标题
- 如果是超链接就继续发请求访问从而获取这章小说的正文
- 将正文写入创建好的目录,文件名是这章小说的标题名
使用之前需要导入相关的模块,requests模块,re正则的模块,os模块
导入有好几种,这里介绍的是在命令窗口中导入
以管理员的身份打开命令窗口。
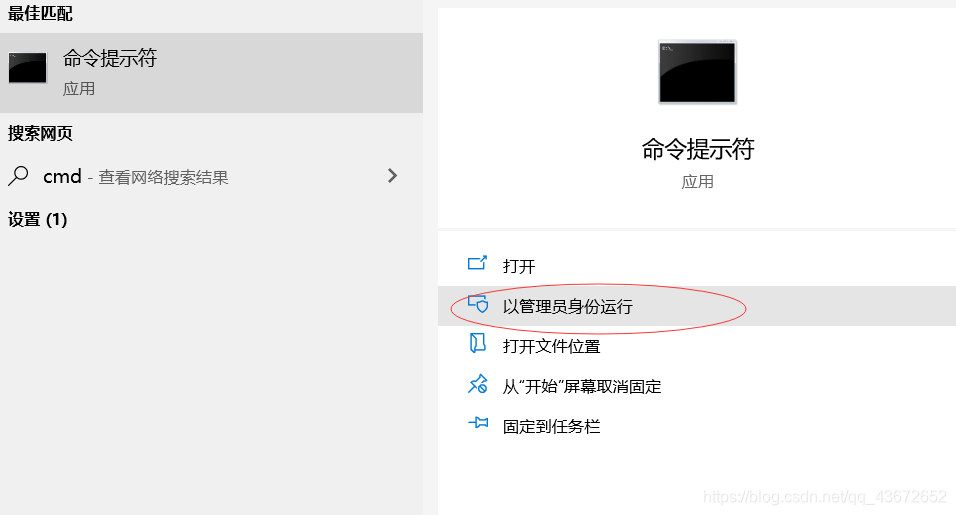
2、输入pip install requests 下载安装requests模块,同样的方式安装剩余模块。
r = requests.get(url)
# 向URL发起get请求,r是返回的对象
r.text就是响应的网页源代码
r.encoding=r.apparent_encoding
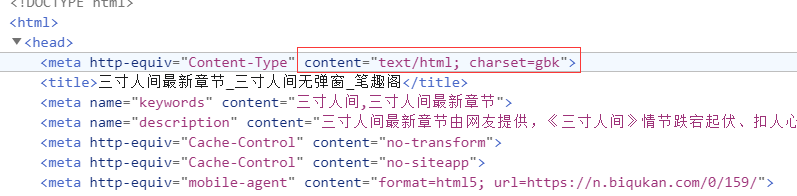
- 这里的encoding指的是对响应结果的编码格式,如果head中没有charset指明编码格式,那么默认是ISO-8859-1,r.text根据encoding编码响应内容;
- apparent_encding是 响应头的编码格式。从网页源代码中可以找出编码方式。
字符编码方式
r.raise_for_status()
如果status_code不是200,产生异常requests.HTTPError;这是HTTP错误。
该语句便于利用try-except进行异常处理。
正则表达式re.findall()方法返回的是一个list集合,关于正则表达式的一些字符。
.代表匹配除换行外的任意字符,*代表匹配一次到N次,?代表采用非贪婪模式匹配,不加?默认是贪婪模式进行匹配。
输入小说的链接,按下F12,查看源代码,检查元素,或是点
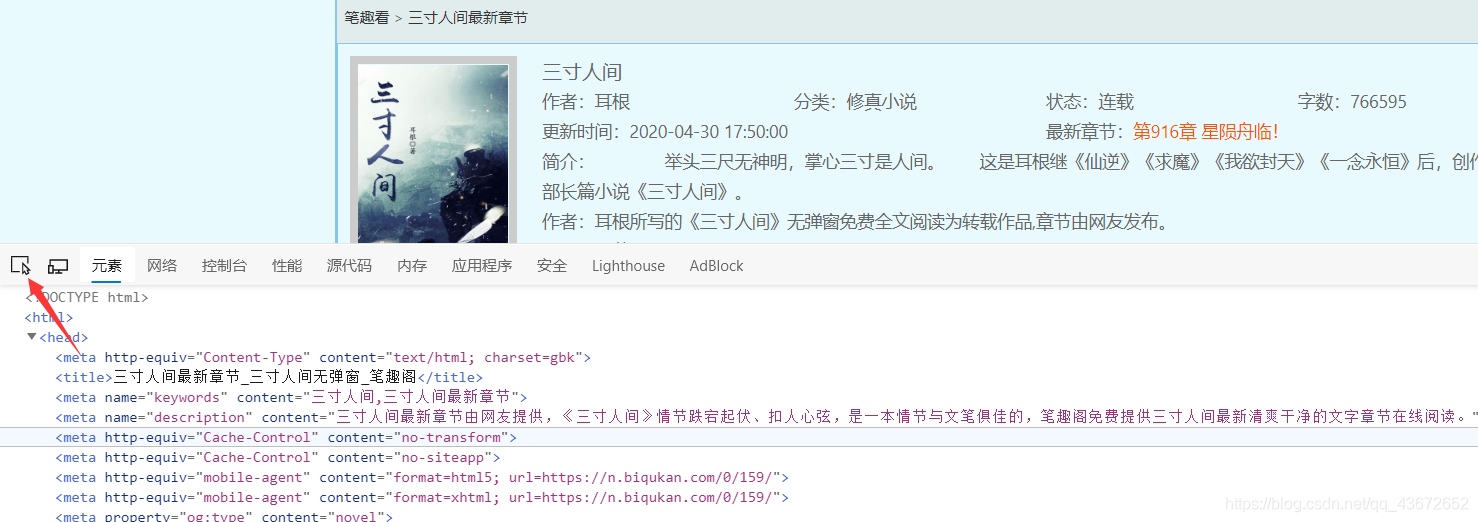
最左边的按钮,找到小说的名字,这时他在h2标签体中;
因此
name = re.findall(r'<h2>(.*?)</h2>',r.text)[0]
因为findall返回的是一个list集合,但是匹配到的只有小说名字一个元素,所以[0]就直接获取了小说名字 ‘三寸人间’
然后创建目录,先判断保存小说的目录存不存在,如果已存在不用创建,如果不存在再创建。这里目录名字就是小说名。
创建完目录后,继续获取小说的目录列表。
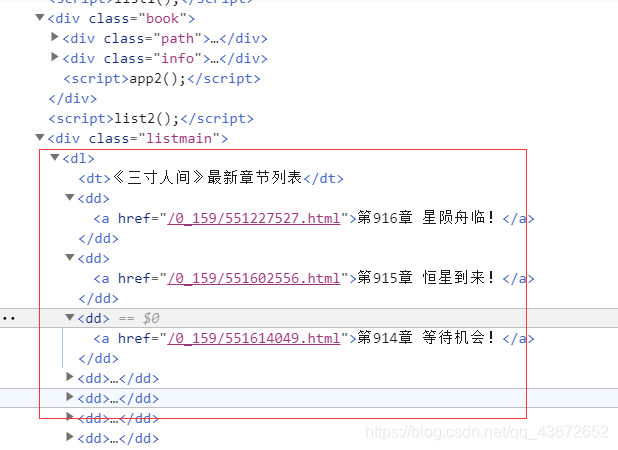
由上图可知,目录都在标签<dl></dl>中,
因此
novleList = re.findall(r'<dl>(.*?)</dl>',html,re.S)[0]
获取目录列表集合,

然后我们要的是a标签找连接里面的内容和href属性值。
在对他进行匹配。得到如下

剩下的就是遍历集合,取出超链接的href和标题,进而访问href,访问的时候需要加上网站的前缀,https://www.biqukan.com/。然后得到正文的返回结果。


想要获取小说内容采用正则匹配,以</script>开头,以<script>结尾。取中间内容。
content = re.findall(r'<script>app2.*?</script>(.*?)<script>',chapterHtml.text,re.S)
最后在保存前需要注意的是,小说中有空格和换行等HTML代码,需要将其替换成相应的格式,保存的时候一定不要忘了编码格式!!!
完整代码如下
import re
import requests
import os
# 将要爬取的url
url = 'https://www.biqukan.com/0_159/'
"""
1. 获取小说名字
2. 创建保存小说的目录
3. 从网页代码中获取小说的目录列表
4. 循环遍历目录,获取每篇的标题,每篇的超链接,如果是超链接就继续请求,进而获取文章内容,最后创建文件将章节写入
"""
# 1.获取小说名
def getNovelName(url):
r = requests.get(url)
# 打印状态码
print(r.status_code)
try:
r.raise_for_status()
r.encoding = r.apparent_encoding
html = r.text
name = re.findall(r'<h2>(.*?)</h2>', html)[0]
except:
return '获取失败'
return name
dirName = getNovelName(url)
#2. 保存小说的路径
path = 'D://workspace//python//reptile//work9_regular/'+dirName
#. 创建一个保存小说的目录
def createDir(path):
try:
if not os.path.exists(path):
os.mkdir(dirName)
else:
print('该文件夹已存在')
except:
print('创建文件失败!')
#3. 创建目录
createDir(path)
def getHtml(url):
r = requests.get(url)
r.encoding=r.apparent_encoding
if r.status_code==200:
return r.text
# 获取小说主页源代码
html = getHtml(url)
#4. 获取目录列表
novleList = re.findall(r'<dl>(.*?)</dl>',html,re.S)[0]
#5. 获取目录中的链接和标题
alls = re.findall(r'<a href ="(.*?)">(.*?)</a>',novleList,re.S)
def writeToFile(alls,path):
# 遍历目录下的标题和链接,继续访问链接获取内容
for item in alls:
hrefs = item[0] # 超链接地址
title = item[1] # 标题
chapterHtml = requests.get('https://www.biqukan.com/'+hrefs)
chapterHtml.encoding=chapterHtml.apparent_encoding
content = re.findall(r'<script>app2.*?</script>(.*?)<script>',chapterHtml.text,re.S)[0]
content = content.replace('<br />','\n') # 替换换行
content = content.replace('\u3000','\t') # 替换制表
content = content.replace(' ',' ') # 替换空格
f = open(path+'/'+title+'.txt','w',encoding='utf-8') # 注意编码方式
f.write(content)
# 6.写入文件
writeToFile(alls,path)
本人初学者,以上有错误的地方欢迎批评指正,有更好的想法的欢迎评论交流!
最后成功保存下来的截图!

Python3爬取小说并保存到文件的更多相关文章
- python3下BeautifulSoup练习一(爬取小说)
上次写博客还是两个月以前的事,今天闲来无事,决定把以前刚接触python爬虫时的一个想法付诸行动:就是从网站上爬取小说,这样可以省下好多流量(^_^). 因为只是闲暇之余写的,还望各位看官海涵:不足之 ...
- python3爬取女神图片,破解盗链问题
title: python3爬取女神图片,破解盗链问题 date: 2018-04-22 08:26:00 tags: [python3,美女,图片抓取,爬虫, 盗链] comments: true ...
- Python3 爬取微信好友基本信息,并进行数据清洗
Python3 爬取微信好友基本信息,并进行数据清洗 1,登录获取好友基础信息: 好友的获取方法为get_friends,将会返回完整的好友列表. 其中每个好友为一个字典 列表的第一项为本人的账号信息 ...
- Python实战项目网络爬虫 之 爬取小说吧小说正文
本次实战项目适合,有一定Python语法知识的小白学员.本人也是根据一些网上的资料,自己摸索编写的内容.有不明白的童鞋,欢迎提问. 目的:爬取百度小说吧中的原创小说<猎奇师>部分小说内容 ...
- python3爬取网页
爬虫 python3爬取网页资源方式(1.最简单: import'http://www.baidu.com/'print2.通过request import'http://www.baidu.com' ...
- python爬虫——爬取小说 | 探索白子画和花千骨的爱恨情仇(转载)
转载出处:药少敏 ,感谢原作者清晰的讲解思路! 下述代码是我通过自己互联网搜索和拜读完此篇文章之后写出的具有同样效果的爬虫代码: from bs4 import BeautifulSoup imp ...
- Python3爬取人人网(校内网)个人照片及朋友照片,并一键下载到本地~~~附源代码
题记: 11月14日早晨8点,人人网发布公告,宣布人人公司将人人网社交平台业务相关资产以2000万美元的现金加4000万美元的股票对价出售予北京多牛传媒,自此,人人公司将专注于境内的二手车业务和在美国 ...
- python3爬取微博评论并存为xlsx
python3爬取微博评论并存为xlsx**由于微博电脑端的网页版页面比较复杂,我们可以访问手机端的微博网站,网址为:https://m.weibo.cn/一.访问微博网站,找到热门推荐链接我们打开微 ...
- python3爬取全民K歌
Python3爬取全民k歌 环境 python3.5 + requests 1.通过歌曲主页链接爬取 首先打开歌曲主页,打开开发者工具(F12). 选择Network,点击播放,会发现有一个请求返回的 ...
随机推荐
- CSP-S2020 DP专项训练
前言 \(\text{CPS-S2020}\) 已然临近,而 \(\text{DP}\) 作为联赛中的常考内容,是必不可少的复习要点,现根据教练和个人刷题,整理部分好题如下(其实基本上是直接搬--). ...
- Angular:管道和自定义管道
①管道的使用,更多管道在angular官网上有 <p>全部转为大写:{{'hahahah' | uppercase}}</p> <p>保留两位小数:{{1.4555 ...
- Jmeter(4)断言
Jmeter添加断言,检查测试中得到的响应数据是否符合预期.以下介绍下响应断言,JSON断言 一.响应断言 1.创建测试计划: 添加线程组->添加取样器->添加察看结果树,运行后可查看接口 ...
- 多个HDFS集群的fs.defaultFS配置一样,造成应用一直连接同一个集群的问题分析
背景 应用需要对两个集群中的同一目录下的HDFS文件个数和文件总大小进行比对,在测试环境中发现,即使两边HDFS目录下的数据不一样,应用日志显示两边始终比对一致,分下下来发现,应用连的一直是同一个集群 ...
- Flink内存溢出
Flink内存模型 此图是基于flink1.12版本. 一个taskmanager给了6g内存,可以有很清楚的看到各个部分占用的内存,还是实时变化的. 名词解释 组件 配置项 描述 Framework ...
- 基于Layuimini的自己封装后台模板
基于Layui的后台模板,正在开发中 交流qq群:1062635741 邮箱:zhangqueque.foxmail.com GitHub:https://github.com/ZhangQueque ...
- VSCode---REST Client接口测试辅助工具
我们一般都会用 PostMan 来完成接口测试的工作,因为用起来十分简单快捷,但是一直以来我也在寻找更好的方案,一个不用切换窗口多开一个 app 的方案 -- 终于在使用 VSCode 一段时版本间, ...
- 程序运行慢?你怕是写的假 Python
Python程序运行太慢的一个可能的原因是没有尽可能的调用内置方法,下面通过5个例子来演示如何用内置方法提升Python程序的性能. 1. 数组求平方和 输入一个列表,要求计算出该列表中数字的的平方和 ...
- python归并排序
由于某人问我要个归并排序,就凑合写了一个,AA = raw_input().split(' ') A = []; for num in AA: A.append(int(num)) def Merge ...
- fiddler抓APP的https接口
吐槽一下,fiddler这工具很蛋疼,用的时候很好用,出bug的时候死活抓不了: ①为了少踩坑,我们在官网下最新的fiddler,官网:Fiddler - Free Web Debugging Pro ...