Java8线程池ThreadPoolExecutor底层原理及其源码解析
小侃一下
日常开发中, 或许不会直接new线程或线程池, 但这些线程相关的基础或思想是非常重要的, 参考林迪效应;
就算没有直接用到, 可能间接也用到了类似的思想或原理, 例如tomcat, jetty, 数据库连接池, MQ;
本文不会对线程的基础知识进行介绍, 所以最好已"进食"关于线程的基础知识, 再"食用"本文更佳;
由于在下的工作及其它原因, 前后花费了数月的时间才完成这篇博客, 希望能帮助到想要了解ThreadPoolExecutor线程池源码和原理的同学.
1. 使用线程池的好处. 为什么要使用线程池?
避免频繁创建、销毁线程的开销; 复用创建的线程.
及时响应提交的任务; 提交一个任务,不再是每次都需要创建新的线程.
避免每次提交的任务都新建线程, 造成服务器资源耗尽, 线程频繁上下文切换等服务器资源开销.
更容易监控、管理线程; 可以统计出已完成的任务数, 活跃的线程数, 等待的任务数等, 可以重写hook方法
beforeExecute,afterExecute,terminated, 重写之后, 结合具体的业务进行处理.
2. 线程池核心参数介绍
| 参数 | 意义 |
|---|---|
| corePoolSize | 线程池中的核心线程数 |
| workQueue | 存放提交的task |
| maximumPoolSize | 线程池中允许的最大线程数 |
| threadFactory | 线程工厂, 用来创建线程, 由Executors#defaultThreadFactory实现 |
| keepAliveTime | 空闲线程存活时间(默认是临时线程, 也可设置为核心线程) |
| unit | 空闲线程存活时间单位枚举 |
下面将结合线程池中的任务提交流程加深理解.
3. 提交任务到线程池中的流程
3.1 ThreadPoolExecutor#execute方法整体流程
这里以java.util.concurrent.ThreadPoolExecutor#execute方法为例, 画一个简单的图:
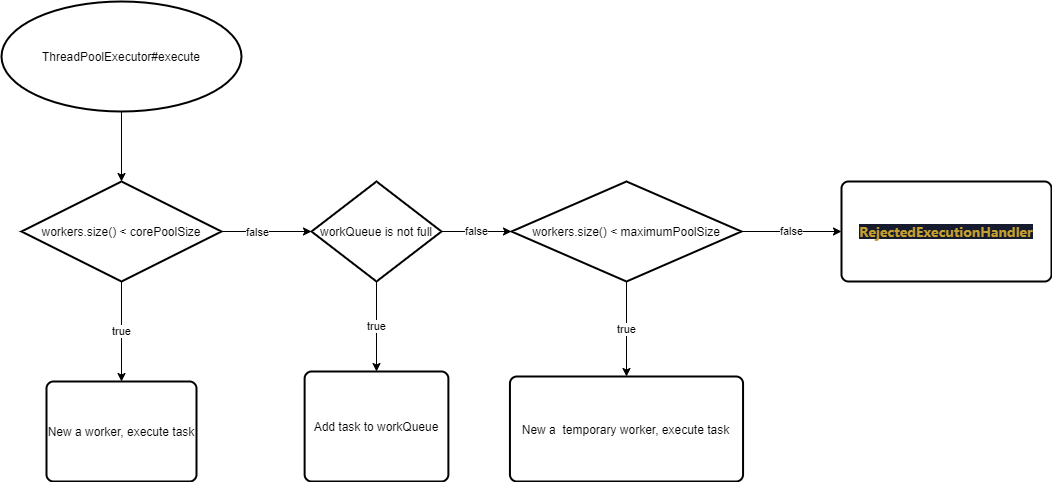
上图中的worker可简单理解为线程池中的一个线程, workers.size()即使线程池中的线程数;
- 当
workers.size()小于corePoolSize时, 创建新的线程执行提交的task. - 当
workers.size()大于corePoolSize时, 并且workQueue没有满, 将task添加到workQueue. - 当
workers.size()大于corePoolSize时, 并且workQueue已经满了, 但是workers.size()<maximumPoolSize, 就创建一个临时线程处理task. - 当
workers.size()大于corePoolSize时, 并且workQueue已经满了, 但是workers.size()>=maximumPoolSize, 执行拒绝策略.
后续会有对ThreadPoolExecutor#execute方法的详细解读: execute方法源码: 提交task到线程池.
4种默认的拒绝策略: ThreadPoolExecutor默认实现的4种拒绝策略.
3.2 排队恰火锅的场景
这里我们可以想像一个场景: 去海底捞吃火锅;
下午4点晚市正式开始排队, 假如店内一共有16张桌子, 陆续光临的16组客人将店内坐满;
店外一共有20组客人座位, 则第17~36组客人坐在店外排队;
第37组客人来了, 启动临时餐桌供客人吃饭.
所以, 这里的店内16张桌子则是corePoolSize, 店外一共有20组座位则为BlockingQueue, 而临时餐桌数量即maximumPoolSize-corePoolSize.
上面的例子并非绝对完美, 仅仅是为了便于我们理解线程池的各个参数, 以及加深印象.
4. ThreadPoolExecutor线程池源码及其原理
有了上面对线程池的总体了解后, 下面结合源码来看看线程池的底层原理吧!
4.1 从创建ThreadPoolExecutor开始: 线程池构造函数的源码
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue) {
this(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue,
Executors.defaultThreadFactory(), defaultHandler);
}
上面是ThreadPoolExecutor参数最少的一个构造方法, 默认的ThreadFactory是Executors.defaultThreadFactory(), 默认的 RejectedExecutionHandler是defaultHandler = new AbortPolicy();
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
if (corePoolSize < 0 ||
maximumPoolSize <= 0 ||
maximumPoolSize < corePoolSize ||
keepAliveTime < 0)
throw new IllegalArgumentException();
if (workQueue == null || threadFactory == null || handler == null)
throw new NullPointerException();
this.acc = System.getSecurityManager() == null ?
null :
AccessController.getContext();
this.corePoolSize = corePoolSize;
this.maximumPoolSize = maximumPoolSize;
this.workQueue = workQueue;
this.keepAliveTime = unit.toNanos(keepAliveTime);
this.threadFactory = threadFactory;
this.handler = handler;
}
上面是ThreadPoolExecutor参数最多的一个构造方法, 其他构造方法都是传入参数调用这个构造方法, 默认的线程工厂见默认的线程工厂Executors#defaultThreadFactory, 各个参数在线程池核心参数介绍已经介绍.
4.2 ThreadPoolExecutor中的一些重要的属性
对一些重要属性有基础的认知, 有助于后面我们更容易看懂源码流程.
4.2.1 线程池的运行状态
private static final int COUNT_BITS = Integer.SIZE - 3;
private static final int CAPACITY = (1 << COUNT_BITS) - 1;
// runState is stored in the high-order bits
private static final int RUNNING = -1 << COUNT_BITS;
private static final int SHUTDOWN = 0 << COUNT_BITS;
private static final int STOP = 1 << COUNT_BITS;
private static final int TIDYING = 2 << COUNT_BITS;
private static final int TERMINATED = 3 << COUNT_BITS;
根据上面源码可知, COUNT_BITS的值为29, CAPACITY的值为2的29次方-1, 二进制表示为: "00011111111111111111111111111111"(明显29个1);
上面的源码中线程池的运行状态的二进制表示:
| 状态 | 二进制 | 意义 |
|---|---|---|
RUNNING |
11100000000000000000000000000000 | 接受新execute的task, 执行已入队的task |
SHUTDOWN |
0 | 不接受新execute的task, 但执行已入队的task, 中断所有空闲的线程 |
STOP |
00100000000000000000000000000000 | 不接受新execute的task, 不执行已入队的task, 中断所有的线程 |
TIDYING |
01000000000000000000000000000000 | 所有线程停止, workerCount数量为0, 将执行hook方法: terminated() |
TERMINATED |
01100000000000000000000000000000 | terminated()方法执行完毕 |
可以看出, 线程池的状态由32位int整型的二进制的前三位表示.
下图根据Javadoc所画:

4.2.2 核心属性ctl源码(线程池状态和有效线程数)
private final AtomicInteger ctl = new AtomicInteger(ctlOf(RUNNING, 0));
核心属性ctl, 数据类型是AtomicInteger, 表示了两个含义:
- 线程池运行状态(
runState) - 线程池中的有效线程数(
workerCount)
那是如何做到一个属性表示两个含义的呢? 那就要看看ctlOf方法
private static int ctlOf(int rs, int wc) { return rs | wc; }
ctlOf方法在线程池内部用来更新线程池的ctl属性,比如ctl初始化的时候: ctl = new AtomicInteger(ctlOf(RUNNING, 0)), 调用ThreadPoolExecutor#shutdown方法等;
rs表示runState, wc表示workerCount;
将 runState和workerCount做按位或运算得到ctl的值;
而runState和workerCount的值由下面两个方法packing和unpacking, 这里的形参c就是ctl.get()的值;
// Packing and unpacking ctl
private static int runStateOf(int c) { return c & ~CAPACITY; }
private static int workerCountOf(int c) { return c & CAPACITY; }
下面用表格更清晰理解:
| 方法 | 方法体 | 带入CAPACITY的值 |
|---|---|---|
runStateOf |
c & ~CAPACITY |
c & 11100000000000000000000000000000 |
workerCountOf |
c & CAPACITY |
c & 00011111111111111111111111111111 |
按位与运算, 相同位置, 同1才为1, 其余为0;
结合表格看, runStateOf方法取ctl前3位表示runState, workerCountOf方法取第4~32位的值表示workerCount;
相信大家已经明白runState和workerCount如何被packing和unpacking, 这就是为什么ctl能即表示runState又能表示wokerCount.
Note: 众所周知, 与2的整数次幂-1进行按位与运算结果等于取余运算的结果, 而位运算效率高于取余运算, 与Java8及其之后的HashMap的散列方式有同曲同工之妙, 见:https://www.cnblogs.com/theRhyme/p/9404082.html#_lab2_1_16.
4.2.3 线程池中的mainLock锁
private final ReentrantLock mainLock = new ReentrantLock();
这把可重入锁, 在线程池的很多地方会被用到;
比如要对workers(线程池中的线程集合)操作的时候(如添加一个worker到工作中), interrupt所有的 workers, 调用shutdown方法等.
4.2.4 线程池中的线程集合
private final HashSet<Worker> workers = new HashSet<Worker>();
用来保存当前线程池中的所有线程;
可通过该集合对线程池中的线程进行中断, 遍历等;
创建新的线程时, 要添加到该集合, 移除线程, 也要从该集合中移除对应的线程;
对该集合操作都需要mainLock锁.
4.2.5 mainLock的Condition()对象
private final Condition termination = mainLock.newCondition();
主要是为了让tryTerminate方法与awaitTermination方法结合使用;
而tryTerminate又被shutdown、shutdownNow、processWorkerExit等方法调用;
Condition对象termination的作用就是当线程池中的状态表示的值小于TERMINATED的值3时, 当前调用了awaitTermination方法的线程就会wait对应的时间;
等到过了指定的wait时间, 或者线程池状态等于或大于TERMINATED, wait的线程被唤醒, 就继续执行;
如果不清楚wait(long)与wait()的区别可参考: Object#wait()与Object#wait(long)的区别.
4.2.6 线程池中曾经达到的最大线程数
private int largestPoolSize;
用作监控, 查看当前线程池, 线程数最多的时候的数量是多少, 见方法ThreadPoolExecutor#getLargestPoolSize;
mainLock保证其可见性和原子性.
4.2.7 线程池中已完成的任务数
private long completedTaskCount;
通过方法ThreadPoolExecutor#getCompletedTaskCount获取.
4.2.8 核心线程池中的空闲线程
private volatile boolean allowCoreThreadTimeOut;
默认情况下, 只有临时线程超过了keepAliveTime的时间会被回收;
allowCoreThreadTimeOut默认为false, 如果设置为true, 则会通过中断或getTask的结果为null的方式停止超过keepAliveTime的核心线程, 具体见getTask方法, 后续会详细介绍.
5. ThreadPoolExecutor一些重要的方法源码及其原理解析
5.1 execute方法源码: 提交task到线程池
public void execute(Runnable command) {
// 如果task为null, 抛出NPE
if (command == null)
throw new NullPointerException();
// 获得ctl的int值
int c = ctl.get();
// workerCount小于corePoolSize
if (workerCountOf(c) < corePoolSize) {
// 添加一个新的worker, 作为核心线程池的线程
if (addWorker(command, true))
// 添加worker作为核心线程成功, execute方法退出
return;
// 添加worker作为核心线程失败, 重新获取ctl的int值
c = ctl.get();
}
// 线程池是RUNNING状态并且task入阻塞队列成功
if (isRunning(c) && workQueue.offer(command)) {
// double-check, 再次获取ctl的值
int recheck = ctl.get();
// 线程池不是RUNNING状态并且当前task从workerQueue被移除成功
if (! isRunning(recheck) && remove(command))
// 执行拒绝策略
reject(command);
// 线程池中的workerCount为0
else if (workerCountOf(recheck) == 0)
// 启动一个非核心线程, 由于这里的task参数为null, 该线程会从workerQueue拉去任务
addWorker(null, false);
}
// 添加一个非核心线程执行提交的task
else if (!addWorker(command, false))
// 添加一个非核心线程失败, 执行拒绝策略
reject(command);
}
结合上面代码中的注释和提交任务到线程池中的流程, 相信我们已经对这个execute方法提交task到线程池的流程的源码更加清晰了.
5.2 addWorker方法源码: 创建线程并启动, 执行提交的task
private boolean addWorker(Runnable firstTask, boolean core) {
retry:
for (;;) {
int c = ctl.get();
// 线程池运行状态
int rs = runStateOf(c);
// 如果线程池运行状态大于等于SHUTDOWN, 提交的firstTask为null, workQueue为null,返回false
if (rs >= SHUTDOWN &&
! (rs == SHUTDOWN &&
firstTask == null &&
! workQueue.isEmpty()))
return false;
for (;;) {
// workerCount
int wc = workerCountOf(c);
// 线程数大于了2的29次方-1, 或者想要添加为核心线程但是核心线程池满, 或者想要添加为临时线程, 但是workerCount等于或大于了最大的线程池线程数maximumPoolSize, 返回false
if (wc >= CAPACITY ||
wc >= (core ? corePoolSize : maximumPoolSize))
return false;
// CAS的方式让workerCount数量增加1,如果成功, 终止循环
if (compareAndIncrementWorkerCount(c))
break retry;
c = ctl.get();
// 再次检查runState, 如果被更改, 重头执行retry代码
if (runStateOf(c) != rs)
continue retry;
// 其他的, 上面的CAS如果由于workerCount被其他线程改变而失败, 继续内部的for循环
}
}
// 标志位workerStarted, workerAdded
boolean workerStarted = false;
boolean workerAdded = false;
Worker w = null;
try {
// 传入task对象, 创建Worker对象
w = new Worker(firstTask);
// 从worker对象中回去Thread对象
final Thread t = w.thread;
if (t != null) {
final ReentrantLock mainLock = this.mainLock;
// 获取mainLock锁
mainLock.lock();
try {
// 获取mainLock锁之后, 再次检查runState
int rs = runStateOf(ctl.get());
// 如果是RUNNING状态, 或者是SHUTDOWN状态并且传入的task为null(执行workQueue中的task)
if (rs < SHUTDOWN ||
(rs == SHUTDOWN && firstTask == null)) {
// 线程已经被启动, 抛出IllegalThreadStateException
if (t.isAlive())
throw new IllegalThreadStateException();
// 将worker对象添加到HashSet
workers.add(w);
int s = workers.size();
// 线程池中曾经达到的最大线程数(上面4.2.6提到过)
if (s > largestPoolSize)
largestPoolSize = s;
// worker被添加成功
workerAdded = true;
}
} finally {
// 释放mainLock锁
mainLock.unlock();
}
// 如果worker被添加成功, 启动线程, 执行对应的task
if (workerAdded) {
t.start();
workerStarted = true;
}
}
} finally {
// 如果线程启动失败, 执行addWorkerFailed方法
if (! workerStarted)
addWorkerFailed(w);
}
return workerStarted;
}
每行代码都有详细的对应的注释, 相信我们已经明白了addWorker方法的过程.
5.3 Worker类源码: 线程是如何执行提交到线程池中的task?
上面的addWorker方法中, 获得Worker对象中的Thread对象(final Thread t = w.thread;), 并调用线程的start方法启动线程执行Worker中的run方法.
5.3.1 Worker 的定义
继承了AQS(AbstractQueuedSynchronizer), 重写了部分方法, 这里的主要作用主要是通过tryLock或isLocked方法判断当前线程是否正在执行Worker中的run方法, 如果返回false, 则线程没有正在执行或没有处于active, 反之, 处于;
结合getActiveCount方法源码理解;
实现了Runnable接口, 是一个线程可执行的任务.
private final class Worker
extends AbstractQueuedSynchronizer
implements Runnable{
...
}
5.3.2 Worker中的属性
| 属性 | 意义 |
|---|---|
final Thread thread |
线程对象, worker会被提交到该线程 |
Runnable firstTask |
提交到线程池中的task, 可能为null, 比如方法ThreadPoolExecutor#prestartCoreThread |
volatile long completedTasks |
每个线程完成的任务数 |
5.3.3 Worker的构造方法
首先设置初始状态state为-1, 这里的setState方法是AQS中的方法;
提交的task赋值给firstTask属性;
利用ThreadFactory, 传入当前Worker对象(为了执行当前Worker中的run方法), 创建Thread对象.
Worker(Runnable firstTask) {
setState(-1); // inhibit interrupts until runWorker
this.firstTask = firstTask;
this.thread = getThreadFactory().newThread(this);
}
5.3.4 Worker中的run方法
Worker对象的run方法, 直接调用了ThreadPoolExecutor的runWorker方法.
public void run() {
runWorker(this);
}
5.3.5 Worker中的重写AQS的方法tryAcquire, tryRelease, isHeldExclusively
5.3.5.1 tryAcquire方法
尝试将state从0设置为1, 成功后把当前持有锁的线程设置为当前线程;
形参unused没有用到.
protected boolean tryAcquire(int unused) {
if (compareAndSetState(0, 1)) {
setExclusiveOwnerThread(Thread.currentThread());
return true;
}
return false;
}
5.3.5.2 tryRelease方法
直接将当前持有锁的线程设置为null, 将state设置为1;
形参unused没有用到.
protected boolean tryRelease(int unused) {
setExclusiveOwnerThread(null);
setState(0);
return true;
}
5.3.5.3 isHeldExclusively方法
判断当前线程是否已经获取了Worker的锁;
如果getState() == 0, 则没有线程获取了该锁, 可以尝试获取锁, 将state设置为1;
如果getState() == 1, 已经有线程获取了该锁, 互斥, 此时无法获取该锁.
protected boolean isHeldExclusively() {
return getState() != 0;
}
5.3.6 lock方法
获取锁, 直到获取到锁为止(具体见AbstractQueuedSynchronizer#acquireQueued方法);
public void lock() { acquire(1); }
5.3.7 tryLock方法
tryLock, 尝试获取锁, 获取到返回true, 否则返回false.
public boolean tryLock() { return tryAcquire(1); }
5.3.8 isLocked方法
isLocked方法, 如果当前有线程持有该锁, 则返回true, 否则返回false.
public boolean isLocked() { return isHeldExclusively(); }
5.3.9 interruptIfStarted方法
线程启动会调用unlock方法(ThreadPoolExecutor.java第1131行), 将state设置为0;
如果线程已经启动, 并且没有被中断, 调用线程的中断方法.
void interruptIfStarted() {
Thread t;
if (getState() >= 0 && (t = thread) != null && !t.isInterrupted()) {
try {
t.interrupt();
} catch (SecurityException ignore) {
}
}
}
5.3.10 unlock方法
底层调用worker的tryRelease方法, 设置state为0.
public void unlock() { release(1); }
5.4 runWorker方法源码: 线程池中线程被复用的关键
执行提交的task或死循环从BlockingQueue获取task.
final void runWorker(Worker w) {
Thread wt = Thread.currentThread();
Runnable task = w.firstTask;
w.firstTask = null;
w.unlock();
boolean completedAbruptly = true;
try {
// 当传入的task不为null, 或者task为null但是从BlockingQueue中获取的task不为null
while (task != null || (task = getTask()) != null) {
// 执行任务之前先获取锁
w.lock();
// 线程池状态如果为STOP, 或者当前线程是被中断并且线程池是STOP状态, 或者当前线程不是被中断;
// 则调用interrupt方法中断当前线程
if ((runStateAtLeast(ctl.get(), STOP) ||
(Thread.interrupted() &&
runStateAtLeast(ctl.get(), STOP))) &&
!wt.isInterrupted())
wt.interrupt();
try {
// beforeExecute hook方法
beforeExecute(wt, task);
Throwable thrown = null;
try {
// 真正执行提交的task的run方法
task.run();
} catch (RuntimeException x) {
thrown = x; throw x;
} catch (Error x) {
thrown = x; throw x;
} catch (Throwable x) {
thrown = x; throw new Error(x);
} finally {
// afterExecute hook方法
afterExecute(task, thrown);
}
} finally {
// task赋值为null, 下次从BlockingQueue中获取task
task = null;
w.completedTasks++;
w.unlock();
}
}
completedAbruptly = false;
} finally {
processWorkerExit(w, completedAbruptly);
}
5.5 getTask方法源码: 从BlockingQueue中获取task
private Runnable getTask() {
// BlockingQueue的poll方法是否已经超时
boolean timedOut = false;
for (;;) {
int c = ctl.get();
int rs = runStateOf(c);
// 如果线程池状态>=SHUTDOWN,并且BlockingQueue为null;
// 或者线程池状态>=STOP
// 以上两种情况都减少工作线程的数量, 返回的task为null
if (rs >= SHUTDOWN && (rs >= STOP || workQueue.isEmpty())) {
decrementWorkerCount();
return null;
}
int wc = workerCountOf(c);
// 当前线程是否需要被淘汰
boolean timed = allowCoreThreadTimeOut || wc > corePoolSize;
if ((wc > maximumPoolSize || (timed && timedOut))
&& (wc > 1 || workQueue.isEmpty())) {
if (compareAndDecrementWorkerCount(c))
return null;
continue;
}
try {
// BlockingQueue的poll方法超时会直接返回null
// BlockingQueue的take方法, 如果队列中没有元素, 当前线程会wait, 直到其他线程提交任务入队唤醒当前线程.
Runnable r = timed ?
workQueue.poll(keepAliveTime, TimeUnit.NANOSECONDS) :
workQueue.take();
if (r != null)
return r;
timedOut = true;
} catch (InterruptedException retry) {
timedOut = false;
}
}
}
5.6 shutdown方法源码: 中断所有空闲的线程
public void shutdown() {
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
checkShutdownAccess();
// 死循环将线程池状态设置为SHUTDOWN
advanceRunState(SHUTDOWN);
// 中断所有空闲的线程
interruptIdleWorkers();
// hook函数, 比如ScheduledThreadPoolExecutor对该方法的重写
onShutdown();
} finally {
mainLock.unlock();
}
tryTerminate();
}
5.7 shutdownNow方法源码: 中断所有空闲的线程, 删除并返回BlockingQueue中所有的task
public List<Runnable> shutdownNow() {
List<Runnable> tasks;
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
checkShutdownAccess();
// 死循环将线程池状态设置为STOP
advanceRunState(STOP);
// 中断所有空闲的线程
interruptWorkers();
// 删除并返回BlockingQueue中所有的task
tasks = drainQueue();
} finally {
mainLock.unlock();
}
tryTerminate();
// 返回BlockingQueue中所有的task
return tasks;
}
6. ThreadPoolExecutor一些其他的方法和属性介绍
6.1 默认的线程工厂Executors#defaultThreadFactory
默认的线程工厂的两个重要作用就是创建线程和初始化线程名前缀.
创建DefaultThreadFactory对象.
public static ThreadFactory defaultThreadFactory() {
return new DefaultThreadFactory();
}
DefaultThreadFactory默认构造方法, 初始化ThreadGroup和创建出的线程名前缀namePrefix.
static class DefaultThreadFactory implements ThreadFactory {
private static final AtomicInteger poolNumber = new AtomicInteger(1);
private final ThreadGroup group;
private final AtomicInteger threadNumber = new AtomicInteger(1);
private final String namePrefix;
DefaultThreadFactory() {
SecurityManager s = System.getSecurityManager();
group = (s != null) ? s.getThreadGroup() :
Thread.currentThread().getThreadGroup();
namePrefix = "pool-" +
poolNumber.getAndIncrement() +
"-thread-";
}
public Thread newThread(Runnable r) {
Thread t = new Thread(group, r,
namePrefix + threadNumber.getAndIncrement(),
0);
if (t.isDaemon())
// 非daemon线程, 不会随父线程的消亡而消亡
t.setDaemon(false);
if (t.getPriority() != Thread.NORM_PRIORITY)
t.setPriority(Thread.NORM_PRIORITY);
return t;
}
}
6.2 ThreadPoolExecutor默认实现的4种拒绝策略
6.2.1 CallerRunsPolicy
如果线程池状态不是SHUTDOWN, 由提交任务到线程池中(如调用ThreadPoolExecutor#execute方法)的线程执行该任务;
如果线程池状态是SHUTDOWN, 则该任务会被直接丢弃掉, 不会再次入队或被任何线程执行.
public static class CallerRunsPolicy implements RejectedExecutionHandler {
public CallerRunsPolicy() { }
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
if (!e.isShutdown()) {
r.run();
}
}
}
6.2.2 AbortPolicy
在调用提交任务到线程池中(如调用ThreadPoolExecutor#execute方法)的线程中直接抛出RejectedExecutionException异常, 当然任务也不会被执行, 提交任务的线程如果未捕获异常会因此停止.
public static class AbortPolicy implements RejectedExecutionHandler {
public AbortPolicy() { }
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
throw new RejectedExecutionException("Task " + r.toString() +
" rejected from " +
e.toString());
}
}
6.2.3 DiscardPolicy
直接丢弃掉这个任务, 不做任何事情.
public static class DiscardPolicy implements RejectedExecutionHandler {
public DiscardPolicy() { }
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
}
}
6.2.4 DiscardOldestPolicy
线程池如果不是SHUTDOWN状态, 丢弃最老的任务, 即workQueue队头的任务, 将当前任务execute提交到线程池;
与CallerRunsPolicy一样, 如果线程池状态是SHUTDOWN, 则该任务会被直接丢弃掉, 不会再次入队或被任何线程执行.
public static class DiscardOldestPolicy implements RejectedExecutionHandler {
public DiscardOldestPolicy() { }
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
if (!e.isShutdown()) {
e.getQueue().poll();
e.execute(r);
}
}
6.3 addWorkerFailed方法源码: 移除启动线程失败的worker
private void addWorkerFailed(Worker w) {
final ReentrantLock mainLock = this.mainLock;
// 获取mainLock锁
mainLock.lock();
try {
// 如果worker不为null, 从HashSet中移除worker
if (w != null)
workers.remove(w);
// 循环执行CAS操作直到让workerCount数量减少1
decrementWorkerCount();
// 执行tryTerminate方法
tryTerminate();
} finally {
mainLock.unlock();
}
}
6.4 tryTerminate方法源码: 尝试更改runState, workerCount, 尝试关闭线程池
final void tryTerminate() {
for (;;) {
// 获取ctl, runState和workerCount
int c = ctl.get();
// 当前线程池状态是否是RUNNING, 或者是否是TIDYING或TERMINATED状态, 或者是否是SHUTDOWN状态并且workQueue不为空(需要被线程执行), return结束方法
if (isRunning(c) ||
runStateAtLeast(c, TIDYING) ||
(runStateOf(c) == SHUTDOWN && ! workQueue.isEmpty()))
return;
// workerCount如果不为0, 随机中断一个空闲的线程, return结束方法
if (workerCount如果不为0,(c) != 0) {
interruptIdleWorkers(ONLY_ONE);
return;
}
final ReentrantLock mainLock = this.mainLock;
// 获取mainLock锁
mainLock.lock();
try {
// CAS方式设置当前线程池状态为TIDYING, workerCount为0
if (ctl.compareAndSet(c, ctlOf(TIDYING, 0))) {
try {
// 执行hook方法terminated
terminated();
} finally {
// 设置当前线程池状态为TERMINATED, workerCount为0
ctl.set(ctlOf(TERMINATED, 0));
// 唤醒调用了awaitTermination方法的线程
termination.signalAll();
}
return;
}
} finally {
mainLock.unlock();
}
// 当CAS失败, 循环重试
}
}
6.5 awaitTermination方法源码: 等待指定时间后, 线程池是否已经关闭
死循环判断, 如果当前线程池状态小于TERMINATED, 则wait对应的时间;
如果过了wait的时间(nanos <= 0), 线程池状态大于等于TERMINATED则循环终止, 函数返回true, 否则返回false.
public boolean awaitTermination(long timeout, TimeUnit unit)
throws InterruptedException {
long nanos = unit.toNanos(timeout);
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
for (;;) {
if (runStateAtLeast(ctl.get(), TERMINATED))
return true;
if (nanos <= 0)
return false;
nanos = termination.awaitNanos(nanos);
}
} finally {
mainLock.unlock();
}
}
6.6 prestartCoreThread方法源码: 预启动一个核心线程
如果当前线程池中的核心线程数小于corePoolSize, 则增加一个核心线程(提交的task为null).
public boolean prestartCoreThread() {
return workerCountOf(ctl.get()) < corePoolSize &&
addWorker(null, true);
}
6.7 prestartAllCoreThreads方法源码: 预先启动线程池中的所有核心线程
启动所有的核心线程.
public int prestartAllCoreThreads() {
int n = 0;
while (addWorker(null, true))
++n;
return n;
}
6.8 getActiveCount方法源码: 获得当前线程池中活跃的线程
获得当前线程池中活跃的线程(即正在执行task没有wait的线程, [runWorker](#5.4 runWorker方法源码: 线程池中线程被复用的关键)方法中的同步代码块).
public int getActiveCount() {
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
int n = 0;
for (Worker w : workers)
if (w.isLocked())
++n;
return n;
} finally {
mainLock.unlock();
}
}
总结
通过介绍ThreadPoolExecutor的构造方法, 重要属性, execute方法, 引出Worker类, 以及真正的线程处理提交到线程池中的task的源码和流程, 对ThreadPoolExecutor整体结构有了清晰的认知;
线程池ThreadPoolExecutor使用BlockingQueue实现线程间的等待-通知机制, 当然也可以自己手动实现;
复用线程体现在runWorker方法中, 死循环+BlockingQueue的特性.
Java8线程池ThreadPoolExecutor底层原理及其源码解析的更多相关文章
- jdk线程池ThreadPoolExecutor工作原理解析(自己动手实现线程池)(一)
jdk线程池ThreadPoolExecutor工作原理解析(自己动手实现线程池)(一) 线程池介绍 在日常开发中经常会遇到需要使用其它线程将大量任务异步处理的场景(异步化以及提升系统的吞吐量),而在 ...
- 21.线程池ThreadPoolExecutor实现原理
1. 为什么要使用线程池 在实际使用中,线程是很占用系统资源的,如果对线程管理不善很容易导致系统问题.因此,在大多数并发框架中都会使用线程池来管理线程,使用线程池管理线程主要有如下好处: 降低资源消耗 ...
- 线程池ThreadPoolExecutor使用原理
本文来源于翁舒航的博客,点击即可跳转原文观看!!!(被转载或者拷贝走的内容可能缺失图片.视频等原文的内容) 若网站将链接屏蔽,可直接拷贝原文链接到地址栏跳转观看,原文链接:https://www.cn ...
- 线程池ThreadPoolExecutor实现原理
线程属于稀缺资源,对于线程的创建规则,引用<阿里巴巴 Java 手册>中的一条进行说明. 本篇从源码方面介绍ThreadPoolExecutor对象,并简要解析线程池工作原理. 首先Thr ...
- 线程池ThreadPoolExecutor工作原理
前言 工作原理 如果使用过线程池,细心的同学肯定会注意到,new一个线程池,但是如果不往里面提交任何任务的话,main方法执行完之后程序会退出,但是如果向线程池中提交了任务的话,main方法执行完毕之 ...
- 从源码角度来分析线程池-ThreadPoolExecutor实现原理
作为一名Java开发工程师,想必性能问题是不可避免的.通常,在遇到性能瓶颈时第一时间肯定会想到利用缓存来解决问题,然而缓存虽好用,但也并非万能,某些场景依然无法覆盖.比如:需要实时.多次调用第三方AP ...
- 底层原理Hashmap源码解析实例
Map.java package com.collection; public interface Map<K, V> { public V put(K k, V v); public V ...
- 线程池续:你必须要知道的线程池submit()实现原理之FutureTask!
前言 上一篇内容写了Java中线程池的实现原理及源码分析,说好的是实实在在的大满足,想通过一篇文章让大家对线程池有个透彻的了解,但是文章写完总觉得还缺点什么? 上篇文章只提到线程提交的execute( ...
- 硬核干货:4W字从源码上分析JUC线程池ThreadPoolExecutor的实现原理
前提 很早之前就打算看一次JUC线程池ThreadPoolExecutor的源码实现,由于近段时间比较忙,一直没有时间整理出源码分析的文章.之前在分析扩展线程池实现可回调的Future时候曾经提到并发 ...
随机推荐
- 最简单的jQuery轮播图(原理解析)
html: <div class="middle_right"> <div id="lunbobox"> <div id=&quo ...
- em(倍)与px的区别
在国内网站中,包括三大门户,以及“引领”中国网站设计潮流的蓝色理想,ChinaUI等都是使用了px作为字体单位.只有百度好歹做了个可调的表率.而 在大洋彼岸,几乎所有的主流站点都使用em作为字体单位, ...
- 在 XUnit 中使用依赖注入
在 XUnit 中使用依赖注入 Intro 之前写过一篇 xunit 的依赖注入相关的文章,但是实际使用起来不是那么方便 今天介绍一个基于xunit和微软依赖注入框架的"真正"的依 ...
- .gitkeep文件
git 默认不会对空文件夹进行追踪: 但某些项目某些文件夹对整体框架是必不可少的,就算是空也得有: 怎么办呢?在这个文件夹下添加一个[.gitkeep]文件,这样就可以同步该文件夹了. (完)
- 状压DP之愤怒的小鸟
题目 传送们P2831 题目较长,不加以赘述 直接步入正题 首先是数学知识,我们可以先根据给出的任意两只猪构建相应的抛物线,同时再构建完之后应判断抛物线的合法性(比如a小于0啊,等等),公式推演就不在 ...
- POJ 3631 Cow Relays Floyd+矩阵快速幂
题目描述 For their physical fitness program, N (2 ≤ N ≤ 1,000,000) cows have decided to run a relay race ...
- 通过手写服务器的方式,立体学习Http
前言 Http我们都已经耳熟能详了,而关于Http学习的文章网上有很多,各个知识点的讲解也可说是深入浅出.然而,学习过后,我们对Http还是一知半解.问题出在了哪? Http是一个客户机与服务器之间的 ...
- 快讯:asuldb再立功,捕获史前大蛤
蛤蛤日报7月7日讯 (蛤媒体记者 申蛤 戌蛤) 昨日下午,asuldb成功于生物实验室捕获史前大蛤.据考证,史前大蛤是一种名为楠楠的生物.这种生物体型庞大,距今已有至少1e18年的寿命.这种大蛤行为古 ...
- 【GIT】git详解
目录 一.基础使用 二.分支管理 三.提交树操作 四.复杂工作流处理 ----------------------------------------------------------------- ...
- js代码段
1.数组去重 Array.prototype.DuplicateRemoval = function(){ let res = [this[0]]; for(let i = 1; i < thi ...