python爬虫之PyQuery的基本使用
PyQuery库也是一个非常强大又灵活的网页解析库,如果你有前端开发经验的,都应该接触过jQuery,那么PyQuery就是你非常绝佳的选择,PyQuery 是 Python 仿照 jQuery 的严格实现。语法与 jQuery 几乎完全相同,所以不用再去费心去记一些奇怪的方法了。
官网地址:http://pyquery.readthedocs.io/en/latest/
jQuery参考文档: http://jquery.cuishifeng.cn/
1、字符串的初始化
from pyquery import PyQuery as pq html = '''<div>
<ul>
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul></div>''' doc = pq(html)
print(doc)
print(type(doc))
print(doc('li'))
<div>
<ul>
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul></div>
<class 'pyquery.pyquery.PyQuery'>
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
运行结果
2、打开html文件
注意路劲问题
from pyquery import PyQuery as pq
doc = pq(filename='index.html')
print(doc)
print(doc('head'))
<title>Title</title>
</head>
<body>
<div>
<ul>
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul></div>'''
</body>
</html>
<head>
<meta charset="UTF-8"/>
<title>Title</title>
</head>
运行结果
3、打开某个网站
doc = pq('https://www.baidu.com')
# doc1 = pq(url='https://www.baidu.com')
print(doc)
print(doc('head'))
4、基于CSS选择器查找
from pyquery import PyQuery as pq html = '''<div>
<ul id = 'haha'>
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul></div>''' doc = pq(html)
print(doc)
#id等于haha下面的class等于item-0下的a标签下的span标签(注意层级关系以空格隔开)
print(doc('#haha .item-0 a span'))
<div>
<ul id="haha">
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul></div>
<span class="bold">third item</span>
运行结果
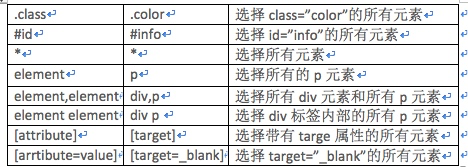
5、可以通过已经查找的标签,查找这个标签下的子标签或者父标签,而不用从头开始查找。
from pyquery import PyQuery as pq html = '''<div class=‘content’>
<ul id = 'haha'>
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul></div>''' doc = pq(html)
item = doc('div ul')
print(item)
#我们可以通过已经查找到的标签,再此查找这个标签下面的标签
print(item.parent())
print(item.children())
<ul id="haha">
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul>
<div class="‘content’">
<ul id="haha">
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul></div>
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
运行结果
from pyquery import PyQuery as pq html = '''<div class=‘content’>
<ul id = 'haha'>
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul></div>''' doc = pq(html)
item = doc('div ul')
print(item)
#注意这里查找ul标签的所有子标签,也就是li标签,下面是查找class属性的标签,如果你把class换成href肯定不行,它指的只是儿子并不是子子孙孙
print(item.children('[class]'))
6、获取属性值
from pyquery import PyQuery as pq html = '''<div class=‘content’>
<ul id = 'haha'>
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul></div>''' doc = pq(html)
#注意class=item-0 active是一个class的属性,但是在pyquery里面要是中间也是空格隔开的话,
#就变成了item-0下的active标签下的a标签了,所以这里空格必须改成点
item = doc(".item-0.active a")
print(type(item))
print(item)
#获取属性值的两种方法
print(item.attr.href)
print(item.attr('href'))
<class 'pyquery.pyquery.PyQuery'>
<a href="link3.html"><span class="bold">third item</span></a>
link3.html
link3.html
运行结果
7、获取标签的内容
from pyquery import PyQuery as pq html = '''<div class=‘content’>
<ul id = 'haha'>
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul></div>''' doc = pq(html)
a = doc("a").text()
print(a)
#结果很有趣,他是找到所有标签的值,然后给连到一起打出来,就像一段话
second item third item fourth item fifth item
运行结果
8、Dom操作
1、属性的增加删除操作
from pyquery import PyQuery as pq html = '''<div class=‘content’>
<ul id = 'haha'>
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul></div>''' doc = pq(html)
li = doc('.item-0.active')
print(li)
#删除classactive
print(li.removeClass('active'))
#增加class属性haha
print(li.addClass('haha'))
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li> <li class="item-0"><a href="link3.html"><span class="bold">third item</span></a></li> <li class="item-0 haha"><a href="link3.html"><span class="bold">third item</span></a></li>
运行结果
2、attrs和css
注意:下列操作有则改之,无则加之。
from pyquery import PyQuery as pq html = '''<div class=‘content’>
<ul id = 'haha'>
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul></div>''' doc = pq(html)
li = doc('.item-0.active')
print(li)
print(li.attr('id','id_test'))
print(li.css('font-size','20px'))
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li> <li class="item-0 active" id="id_test"><a href="link3.html"><span class="bold">third item</span></a></li> <li class="item-0 active" id="id_test" style="font-size: 20px"><a href="link3.html"><span class="bold">third item</span></a></li>
运行结果
3、删除某个标签,在爬去过程中我们通常爬去一下标签或者内容下来的时候总会有些不想要的标签,这个时候我们可以用下面的类似方法删除这个标签。
from pyquery import PyQuery as pq html = '''<div class='content'>
<ul id = 'haha'>
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul></div>''' doc = pq(html)
data = doc('.content')
print(data.text())
#删除所有a标签
data.find('a').remove()
#再次打印
print(data.text())
first item second item third item fourth item fifth item
first item
运行结果
python爬虫之PyQuery的基本使用的更多相关文章
- Python爬虫之PyQuery使用(六)
Python爬虫之PyQuery使用 PyQuery简介 pyquery能够通过选择器精确定位 DOM 树中的目标并进行操作.pyquery相当于jQuery的python实现,可以用于解析HTML网 ...
- python爬虫神器PyQuery的使用方法
你是否觉得 XPath 的用法多少有点晦涩难记呢? 你是否觉得 BeautifulSoup 的语法多少有些悭吝难懂呢? 你是否甚至还在苦苦研究正则表达式却因为少些了一个点而抓狂呢? 你是否已经有了一些 ...
- python爬虫之pyquery学习
相关内容: pyquery的介绍 pyquery的使用 安装模块 导入模块 解析对象初始化 css选择器 在选定元素之后的元素再选取 元素的文本.属性等内容的获取 pyquery执行DOM操作.css ...
- 【Python爬虫】PyQuery解析库
PyQuery解析库 阅读目录 初始化 基本CSS选择器 查找元素 遍历 获取信息 DOM操作 伪类选择器 PyQuery 是 Python 仿照 jQuery 的严格实现.语法与 jQuery 几乎 ...
- Python爬虫之pyquery库的基本使用
# 字符串初始化 html = ''' <div> <ul> <li class = "item-0">first item</li> ...
- Python爬虫系列-PyQuery详解
强大又灵活的网页解析库.如果你觉得正则写起来太麻烦,如果你觉得BeautifulSoup语法太难记,如果你熟悉jQuery的语法,那么PyQuery就是你的最佳选择. 安装 pip3 install ...
- python爬虫之PyQuery
# -*- coding: UTF-8 -*- from pyquery import PyQuery as pq import re from datetime import datetime,ti ...
- Python爬虫利器六之PyQuery的用法
前言 你是否觉得 XPath 的用法多少有点晦涩难记呢? 你是否觉得 BeautifulSoup 的语法多少有些悭吝难懂呢? 你是否甚至还在苦苦研究正则表达式却因为少些了一个点而抓狂呢? 你是否已经有 ...
- 小白学 Python 爬虫(23):解析库 pyquery 入门
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
随机推荐
- 深度学习之Attention Model(注意力模型)
1.Attention Model 概述 深度学习里的Attention model其实模拟的是人脑的注意力模型,举个例子来说,当我们观赏一幅画时,虽然我们可以看到整幅画的全貌,但是在我们深入仔细地观 ...
- 深度学习之从RNN到LSTM
1.循环神经网络概述 循环神经网络(RNN)和DNN,CNN不同,它能处理序列问题.常见的序列有:一段段连续的语音,一段段连续的手写文字,一条句子等等.这些序列长短不一,又比较难拆分成一个个独立的样本 ...
- (predicted == labels).sum().item()作用
⚠️(predicted == labels).sum().item()作用,举个小例子介绍: # -*- coding: utf-8 -*-import torch import numpy as ...
- >/dev/null 2>&1和2>&1 >/dev/null区别
>/dev/null 2>&1和2>&1 >/dev/null区别 >/dev/null 2>&1 //会将标准输出,错误输出都重定向至/d ...
- Spring Security(二十七):Part II. Architecture and Implementation
Once you are familiar with setting up and running some namespace-configuration based applications, y ...
- 初学Python——文件操作
一.文件的打开和关闭 1.常用的打开关闭语句 f=open("yesterday","r",encoding="utf-8") #打开文件 ...
- Pycharm远程调试服务器代码(使用Pipenv管理虚拟环境)
准备工作 1.随便准备一个项目工程,在本地用Pipenv创建一个虚拟环境并生成Pipfile和pipfile.lock文件,如下: 2.准备一台服务器,我这里使用阿里云的ECS SSH连接上 $ ss ...
- JavaScript的基本包装类型说明
一.基本包装类型: 为了便于操作基本类型值,ECMAScript 还提供了3个特殊的引用类型:Boolean.Number和String.这些基本包装类型,具有与各自基本类型相应的特殊行为. 实际上我 ...
- Feature Extractor[DenseNet]
0.背景 随着CNN变得越来越深,人们发现会有梯度消失的现象.这个问题主要是单路径的信息和梯度的传播,其中的激活函数都是非线性的,从而特别是乘法就可以使得随着层数越深,假设将传统的神经网络的每一层看成 ...
- 使用ssh登录kali
SSH为Secure Shell的缩写,SSH为建立在应用层基础上的安全协议.SSH是目前较可靠,专为远程登录会话和其他网络服务提供安全性的协议.利用SSH协议可以有效防止远程管理过程中的信息泄露问题 ...