spark学习之路1--用IDEA编写第一个基于java的程序打包,放standalone集群,client和cluster模式上运行
1,首先确保hadoop和spark已经运行。(如果是基于yarn,hdfs的需要启动hadoop,否则hadoop不需要启动)。
2.打开idea,创建maven工程。编辑pom.xml文件。增加dependency.
<dependency> <!-- Spark dependency -->
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.10</artifactId>
<version>1.6.0</version>
</dependency>
3.编写SimpleApp.java
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.Function; /**
* TODO
*
* @ClassName: SimpleApp
* @author: DingH
* @since: 2019/3/26 11:30
*/
public class SimpleApp {
public static void main(String[] args) {
String textfile = "file:///usr/local/spark/README.md";
SparkConf conf1 = new SparkConf().setAppName("SimpleApp");
JavaSparkContext sc = new JavaSparkContext(conf1);
JavaRDD<String> data = sc.textFile(textfile).cache(); long numAs = data.filter(new Function<String, Boolean>() {
public Boolean call(String s) throws Exception {
return s.contains("a");
}
}).count(); long numBs = data.filter(new Function<String, Boolean>() {
public Boolean call(String s) throws Exception {
return s.contains("b");
}
}).count(); System.out.println("Lines with a: " + numAs + ", lines with b: " + numBs);
}
}
4.执行程序(肯定会有错,因为这个路径是ubuntu上spark的readme文件路径,如果想要在本地实验,修改本地文件系统中的一个文件路径就行,这个同时还有conf.setmaster("local")),打包。
5.将目标路径下的target文件夹拷贝到服务器端。
6.如果是client模式,直接执行:
ubuntu@master:/usr/local/spark$ ./bin/spark-submit --class "SimpleApp" --deploy-mode client --master spark://172.19.57.221:7077 ~/target/SimpleApp-1.0-SNAPSHOT.jar

7.如果是cluster上,则需要把target上传到slave01的用户目录下。然后执行:
ubuntu@master:/usr/local/spark$ ./bin/spark-submit --class "SimpleApp" --deploy-mode cluster --master spark://172.19.57.221:7077 ~/target/SimpleApp-1.0-SNAPSHOT.jar
这个方式执行的结果只能在webUI上看。
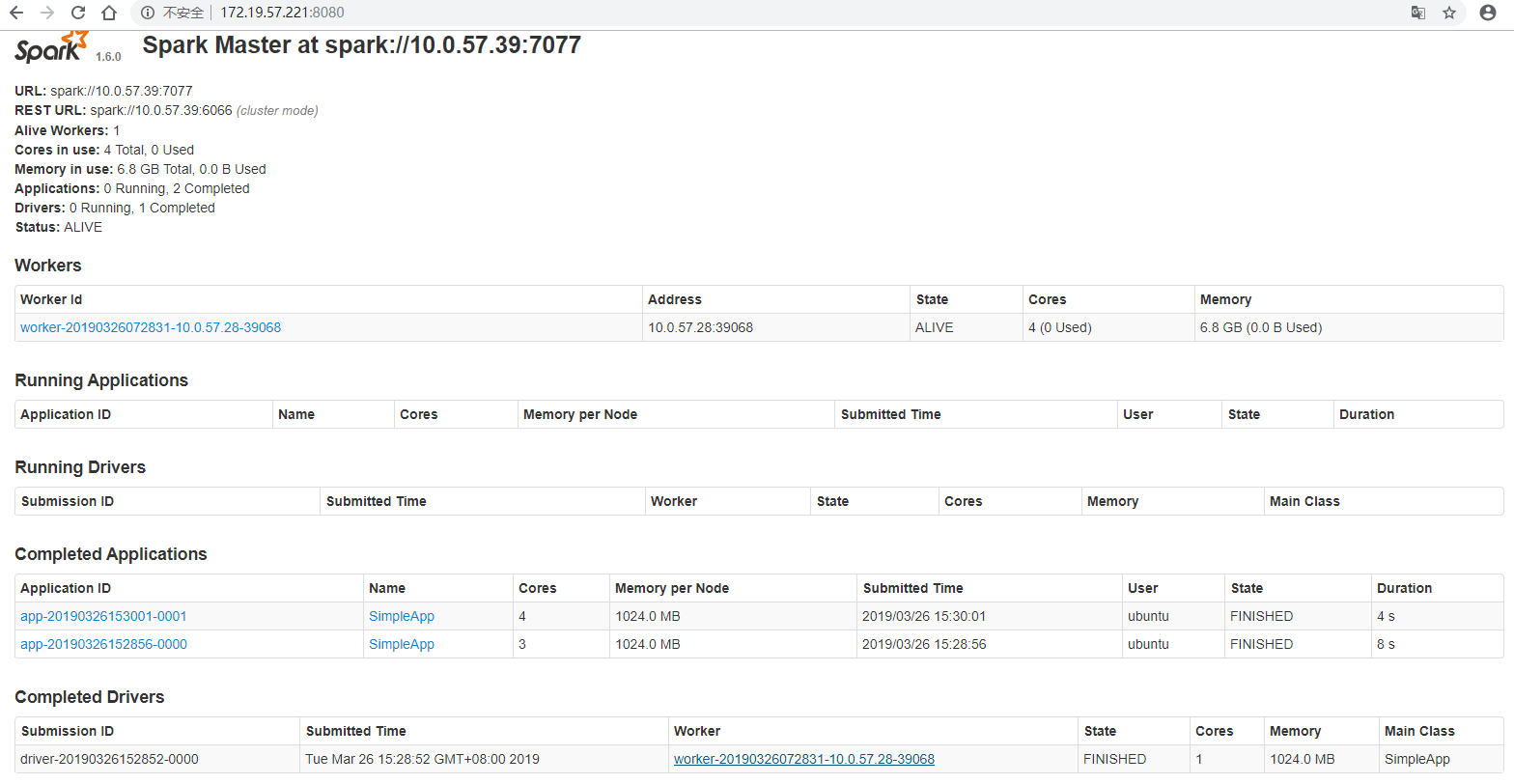
在http://172.19.57.221:8080/上,可以看到spark master。
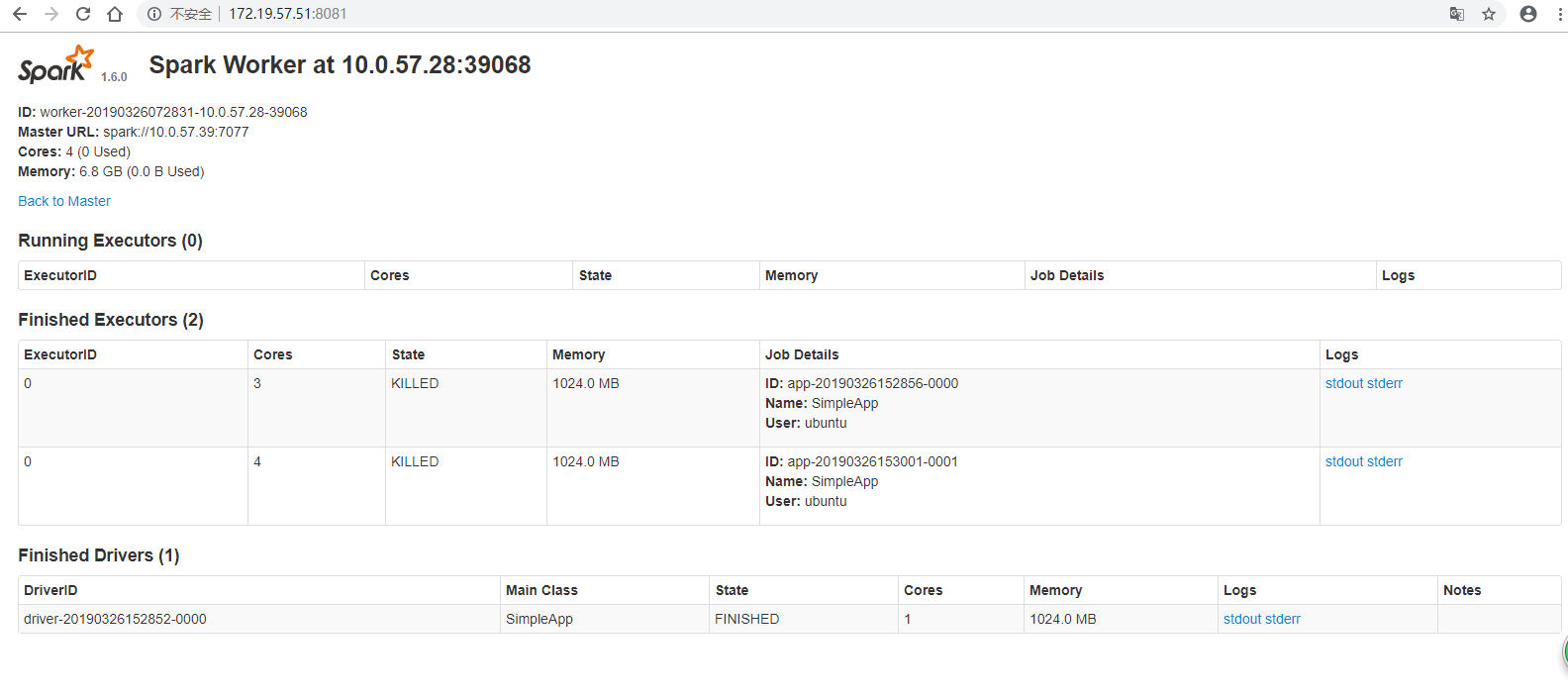
在http://172.19.57.51:8081/上,可以看到spark worker。
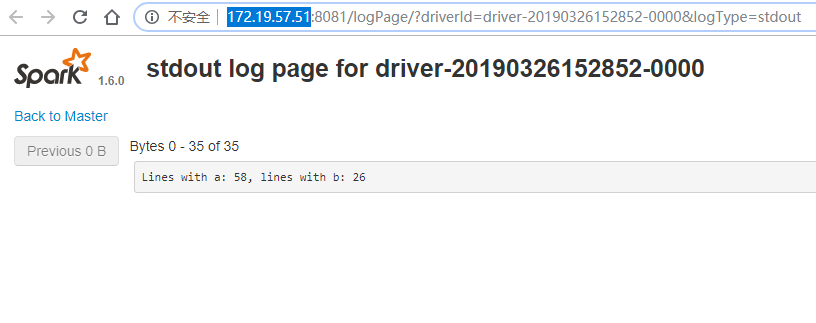
点击Finished Drivers里面的stdout就可以查看执行的结果。
完结~
spark学习之路1--用IDEA编写第一个基于java的程序打包,放standalone集群,client和cluster模式上运行的更多相关文章
- [转]Spark学习之路 (三)Spark之RDD
Spark学习之路 (三)Spark之RDD https://www.cnblogs.com/qingyunzong/p/8899715.html 目录 一.RDD的概述 1.1 什么是RDD? ...
- Spark学习之路 (十二)SparkCore的调优之资源调优
摘抄自:https://tech.meituan.com/spark-tuning-basic.html 一.概述 在开发完Spark作业之后,就该为作业配置合适的资源了.Spark的资源参数,基本都 ...
- Spark学习之路 (十二)SparkCore的调优之资源调优[转]
概述 在开发完Spark作业之后,就该为作业配置合适的资源了.Spark的资源参数,基本都可以在spark-submit命令中作为参数设置.很多Spark初学者,通常不知道该设置哪些必要的参数,以及如 ...
- Spark学习之路 (八)SparkCore的调优之开发调优
摘抄自:https://tech.meituan.com/spark-tuning-basic.html 前言 在大数据计算领域,Spark已经成为了越来越流行.越来越受欢迎的计算平台之一.Spark ...
- Spark学习之路 (七)Spark 运行流程
一.Spark中的基本概念 (1)Application:表示你的应用程序 (2)Driver:表示main()函数,创建SparkContext.由SparkContext负责与ClusterMan ...
- Spark学习之路(七)—— 基于ZooKeeper搭建Spark高可用集群
一.集群规划 这里搭建一个3节点的Spark集群,其中三台主机上均部署Worker服务.同时为了保证高可用,除了在hadoop001上部署主Master服务外,还在hadoop002和hadoop00 ...
- Spark学习之路(五)—— Spark运行模式与作业提交
一.作业提交 1.1 spark-submit Spark所有模式均使用spark-submit命令提交作业,其格式如下: ./bin/spark-submit \ --class <main- ...
- Spark学习之路(四)—— RDD常用算子详解
一.Transformation spark常用的Transformation算子如下表: Transformation算子 Meaning(含义) map(func) 对原RDD中每个元素运用 fu ...
- Spark学习之路 (八)SparkCore的调优之开发调优[转]
前言 在大数据计算领域,Spark已经成为了越来越流行.越来越受欢迎的计算平台之一.Spark的功能涵盖了大数据领域的离线批处理.SQL类处理.流式/实时计算.机器学习.图计算等各种不同类型的计算操作 ...
随机推荐
- simulate events
windows system maintains a msg queue, and any process that supports msg will create an thread that h ...
- Ubuntu升级GCC到gcc4.8
http://www.qtcn.org/bbs/apps.php?q=diary&a=detail&did=1456&uid=139371Ubuntu最新gcc版本在ppa:u ...
- Spring4-@Enable** 注解的实现原理
背景 在前面的工作中使用SpringBoot的时候,我碰到了很多的使用@Enable***注解的地方,使用上也都是加在@Configuration 类注解的类上面,比如: (1)@EnableAuto ...
- linux强制将数据写入磁盘,防止丢失内存的数据
sync命令文件系统管理 sync命令用于强制被改变的内容立刻写入磁盘,更新超块信息. 在Linux/Unix系统中,在文件或数据处理过程中一般先放到内存缓冲区中,等到适当的时候再写入磁盘, 以提高系 ...
- 安装python的pip模块
安装python的pip模块 网址https://pypi.python.org/pypi/pip 选择,点击下载 将文件解压到C:\Users\Administrator\AppData\Local ...
- L1和L2正则
https://blog.csdn.net/jinping_shi/article/details/52433975
- 【转载】 Eclipse注释模板设置详解
Eclipse注释模板设置详解 网站推荐: 金丝燕网(主要内容是 Java 相关) 木秀林网(主要内容是消息队列)
- SpringBoot的yml配置文件
1.在src\main\resources下创建application.yml配置文件 spring: datasource: driver-class-name: com.mysql.jdbc.Dr ...
- checkbox 选中的id拼接长字符串
需求描述:为了做一个批量操作,需要获取到checkbox选中的项的id,并且把选中的id拼接成字符串. 解决思路:先获取到checkbox选中项,然后拼接.(这tm不废话么),问题的关键就是获取che ...
- 使用 declare 语句和strict_types 声明来启用严格模式:
使用 declare 语句和strict_types 声明来启用严格模式: Caution: 启用严格模式同时也会影响返回值类型声明. Note: 严格类型适用于在启用严格模式的文件内的函数调用,而不 ...