ElasticSearch文档及分布式文档存储
1、什么是文档?
文档由索引(_index),类型(_type),唯一标识(_id) 组成,我们为 _index(索引) 分配相关逻辑地址分片,该索引下的数据会根据索引以及类型计算哈希来分配数据存储的分片,文档内容为Json格式的文档体,注意文档中的字段名称不能包含英文的句号,实际处理过程中这里最好不要包含符号,索引名称要用小写
规则:
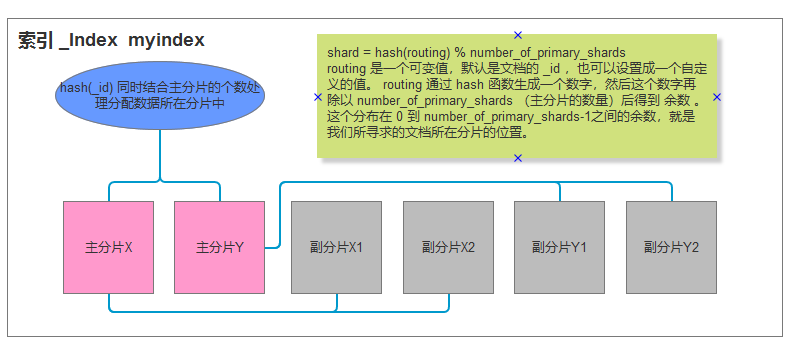
值得注意的是:
我们要在创建索引的时候就确定好主分片的数量 并且永远不会改变这个数量:因为如果数量变化了,那么所有之前路由的值都会无效,文档也再也找不到了
2、主分片与副分片之前的数据怎么同步呢?
如下 定义三个节点,我们有2个主分片,每个分片有2个副分片,为了保证数据完整性,ES会进行如下分布,这里我们用绿色标识主分片,矩形标识副分片,那么会出现如下分布,保证每个节点上都有完成的分片(主1 和主2 )数据.
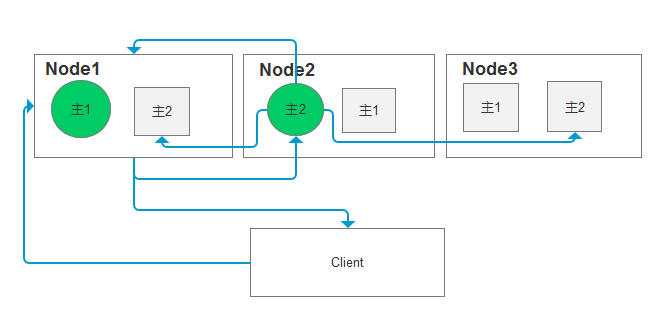
1、Client 发送写操作到Node1
问题:为什么要发到Node1,比如新加入了一个节点,这节点间的有编排编号吗?,如果是访问带有主节点的,也可以访问Node2也可以,这之间有什么关联吗?
答:每个节点都有能力处理任意请求。 每个节点都知道集群中任一文档位置,所以可以直接将请求转发到需要的节点上,一开始进来都是任意一个节点,这个节点知道位置后,会作为协调节点转发请求到对应的节点上。这里请求Node1是随机节点,知道文档存储在主分片2上转发到Node2,如果一开始就是Node2节点就不需转发了,然后协调数据同步后,返回Node1再返回客户端,写操作都会直接找主分区所在的节点,我有点怀疑直接进入Node3呢?
2、根据_id发现数据应该存在存在主分片2上,于是转到Node2,写入数据
问题:新建、索引和删除 请求都是 写 操作, 必须在主分片上面完成之后才能被复制到相关的副本分片,ES应该每个节点上有应该有一个记录主分片分布的节点记录,如果设置的自动生成_id的情况,那么怎么去判断位置?
3、数据同步,写入Node2中的主分片2成功后,并行写入2个副分片,等待两个副分片都应答成功后,然后通知客户端,防止网络或者其他问题带来的数据不一致
那么在数据一致性上Elasticsearch是怎么去处理的?
ES会要求有一定的副分片数量才会执行写操作,结合上面的 同步副分区,可以设置
int( (primary + number_of_replicas) / 2 ) + 1 ,consistency 参数也可以设置 one(主分区ok即可写入) 、all(所有主、副分区全部ok才执行写入)、quorum 默认(大多数的主、副分区没问题即可写入,及上面的公式)
出现分布式就需要注意大数据一致性的问题以及,多修改数据丢失的问题?虽然上面的同步能处理数据最终一致性的问题,但是如果出现多个人修改,会导致数据掉丢失的情况。在实际过程我们又怎么来避免这种情况呢?如又这么一组数据
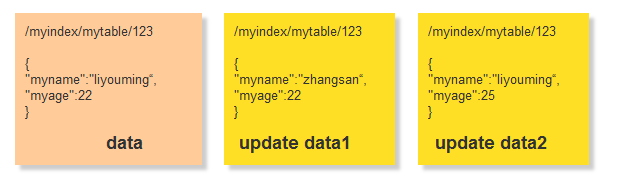
数据data 在 update data1 update data2 2个同时操作的时候会导致数据丢失,加入先get到数据 都是data
但是在update1 update2无论哪个先那个后实际上都会存在数据丢失 如果update1先,update2后,最后数据是 update2的
/myindex/mytable/
{
"myname":"liyouming“,
"myage":
}
如果update2先,update1后,最后数据是 update1的
/myindex/mytable/
{
"myname":"zhangsan“,
"myage":
} 但是实际上我们需要的数据应该是这样
/myindex/mytable/
{
"myname":"zhangsan“,
"myage":
} 其实仔细想想在我们的实际业务管理系统中也会有这样的问题,如果两个人同时打开一个编辑界面同时修改,操作1 在不知道 操作2 修改内容的情况下直接修改,其中会覆盖一部分的数据丢失掉了
那么ElasticSearch是怎么来处理这个问题的呢?
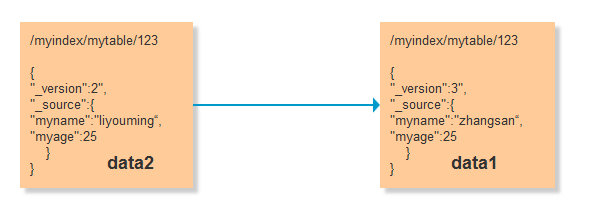
每个文档都有一个 _version (版本)号,当文档被修改时版本号递增。 Elasticsearch 使用这个 _version 号来确保变更以正确顺序得到执行。如果旧版本的文档在新版本之后到达,它可以被简单的忽略,我们可以利用 _version 号来确保 应用中相互冲突的变更不会导致数据丢失。
那么我们在来看下上面的demo
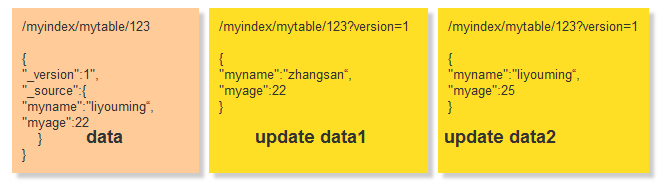
在我们查询出来的时候获取到版本号 _version 为1,在进行update1 或update2的时候带上我们的版本号,那么其中后面执行的那个会出现修改失败,这么就能保证数据丢失的情况了,假定数据update2修改成功了,那么我们得到的数据会是这样 data2 ,upate1失败后再次获取信息 得到版本为2 再次修改成功得到data1最终修改
ElasticSearch文档及分布式文档存储的更多相关文章
- ElasticSearch 学习记录之 分布式文档存储往ES中存数据和取数据的原理
分布式文档存储 ES分布式特性 屏蔽了分布式系统的复杂性 集群内的原理 垂直扩容和水平扩容 真正的扩容能力是来自于水平扩容–为集群添加更多的节点,并且将负载压力和稳定性分散到这些节点中 ES集群特点 ...
- ElasticSearch 5学习(8)——分布式文档存储(wait_for_active_shards新参数分析)
学完ES分布式集群的工作原理以及一些基本的将数据放入索引然后检索它们的所有方法,我们可以继续学习在分布式系统中,每个分片的文档是被如何索引和查询的. 路由 首先,我们需要明白,文档和分片之间是如何匹配 ...
- elasticsearch 基础 —— 分布式文档存储原理
路由一个文档到一个分片中 当索引一个文档的时候,文档会被存储到一个主分片中. Elasticsearch 如何知道一个文档应该存放到哪个分片中呢?当我们创建文档时,它如何决定这个文档应当被存储在分片 ...
- elasticsearch的store属性跟_source字段——如果你的文档长度很长,存储了_source,从_source中获取field的代价很大,你可以显式的将某些field的store属性设置为yes,否则设置为no
转自:http://kangrui.iteye.com/blog/2262860 众所周知_source字段存储的是索引的原始内容,那store属性的设置是为何呢?es为什么要把store的默认取值设 ...
- 分布式文档存储数据库之MongoDB索引管理
前文我们聊到了MongoDB的简介.安装和对collection的CRUD操作,回顾请参考https://www.cnblogs.com/qiuhom-1874/p/13941797.html:今天我 ...
- Elasticsearch配置详解、文档元数据
目录 返回目录:http://www.cnblogs.com/hanyinglong/p/5464604.html 1.Elasticsearch配置文件详解 a. 在上面博客中,我们已经安装并且成功 ...
- ElasticSearch查询 第二篇:文档更新
<ElasticSearch查询>目录导航: ElasticSearch查询 第一篇:搜索API ElasticSearch查询 第二篇:文档更新 ElasticSearch查询 第三篇: ...
- ElasticSearch权威指南学习(文档)
什么是文档 在Elasticsearch中,文档(document)这个术语有着特殊含义.它特指最顶层结构或者根对象(root object)序列化成的JSON数据(以唯一ID标识并存储于Elasti ...
- elasticsearch 基础 —— 索引、更新文档
索引文档 通过使用 index API ,文档可以被 索引 -- 存储和使文档可被搜索 . 但是首先,我们要确定文档的位置.正如我们刚刚讨论的,一个文档的 _index . _type 和 _id 唯 ...
随机推荐
- 【VMware vSphere】vCenter添加主机失败:无法访问指定主机
背景 前一段时间,给一台服务器安装ESXi系统,安装成功之后,通过vCenter在上面安装了一台VDP系统.结果前几天发现服务器掉线,重新连接时出现问题.问题描述如下: 其中错误堆栈具体内容为:在 v ...
- 2018牛客暑期ACM多校训练营第一场(有坑未填)
(重新组队后的第一场组队赛 也是和自己队友的一次磨合吧 这场比赛真的算是一个下马威吧……队友上手一看 啊这不是莫队嘛 然后开敲 敲完提交发现t了 在改完了若干个坑点后还是依然t(真是一个悲伤的故事)然 ...
- python进程.线程和协程的总结
I.进程: II.多线程threading总结 threading用于提供线程相关的操作,线程是应用系统中工作的最小单位(cpu调用的最小单位). Python当前版本的多线程没有实现优先级,线程组, ...
- asyncio Queue的使用例子
import aiohttp import asyncio import async_timeout from urllib.parse import urljoin, urldefrag root_ ...
- requests库入门14-Cookie
因为http是没有状态的协议,上一个请求和下一个请求是没有关联.但是现实中又需要有关联,比如一个页面某个操作需要登陆之后才能进行,没有登陆就提示你登陆.为了实现这样的效果,所以出现了Cookie和Se ...
- Mysql数据库远程链接、权限修改、导入导出等基本操作
一.连接MySQL 格式: mysql -h主机地址 -u用户名 -p用户密码 1.例1:连接到本机上的MYSQL. 首先在打开DOS窗口,然后进入目录 mysqlbin,再键入命令mysql -ur ...
- P3203 [HNOI2010]弹飞绵羊 —— 懒标记?分块?
好久没写博客了哈,今天来水一篇._(:з」∠)_ 题目 :弹飞绵羊(一道省选题) 题目描述 某天,Lostmonkey发明了一种超级弹力装置,为了在他的绵羊朋友面前显摆,他邀请小绵羊一起玩个游戏.游戏 ...
- ROS入门学习
ROS学习笔记 ROS入门网站; ROS入门书籍 ROS主要包含包括功能包.节点.话题.消息类型和服务; ROS功能包/软件包(Packages) ROS软件包是一组用于实现特定功能的相关文件的集合, ...
- spring3.1 profile 配置不同的环境
<?xml version="1.0" encoding="UTF-8"?><beans xmlns="http://www.spr ...
- less个人学习笔记
less中文官网:http://lesscss.cn/ . http://www.bootcss.com/p/lesscss/ Busy 视频教程:http://www.imooc.com/learn ...