python爬虫学习之Scrapy框架的工作原理
一、Scrapy简介
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。 可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中。 其最初是为了 页面抓取 (更确切来说, 网络抓取 )所设计的, 也可以应用在获取API所返回的数据(例如 Amazon Associates Web Services ) 或者通用的网络爬虫。这里贴出Scrapy框架官方中文文档的链接。
二、Scrapy架构概览
接下来的图展现了Scrapy的架构,包括组件及在系统中发生的数据流的概览(绿色箭头所示)。下面对每个组件都做了简单介绍,数据流如下所描述。
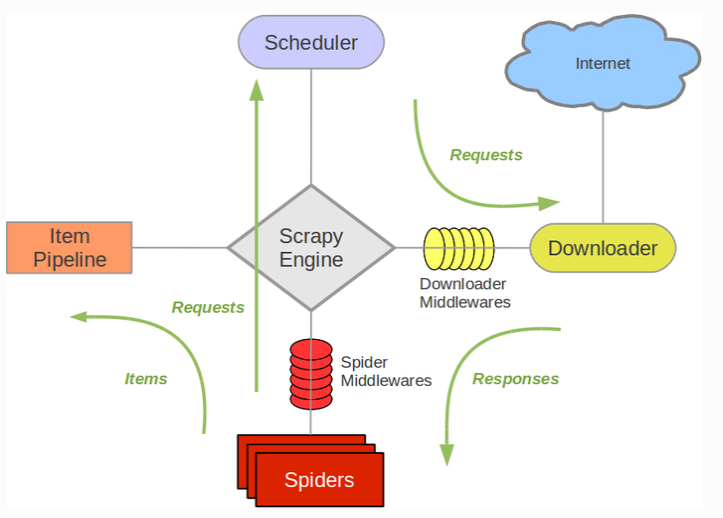
三、组件:
- Scrapy Engine:引擎负责控制数据流在系统中所有组件中流动,并在相应动作发生时触发事件。 详细内容查看下面的数据流(Data Flow)部分。
- 调度器(Scheduler):调度器从引擎接受request并将他们入队,以便之后引擎请求他们时提供给引擎。
- 下载器(Downloader):下载器负责获取页面数据并提供给引擎,而后提供给spider。
- Spiders:Spider是Scrapy用户编写用于分析response并提取item(即获取到的item)或额外跟进的URL的类。 每个spider负责处理一个特定(或一些)网站。
- Item Pipeline:Item Pipeline负责处理被spider提取出来的item。典型的处理有清理、 验证及持久化(例如存取到数据库中)。
- 下载器中间件(Downloader middlewares):下载器中间件是在引擎及下载器之间的特定钩子(specific hook),处理Downloader传递给引擎的response。 其提供了一个简便的机制,通过插入自定义代码来扩展Scrapy功能。
- Spider中间件(Spider middlewares):Spider中间件是在引擎及Spider之间的特定钩子(specific hook),处理spider的输入(response)和输出(items及requests)。 其提供了一个简便的机制,通过插入自定义代码来扩展Scrapy功能
四、数据流(Data flow):
Scrapy中的数据流由执行引擎控制,其过程如下:
1. 引擎打开一个网站(open a domain),找到处理该网站的Spider并向该spider请求第一个要爬取的URL(s)。
2. 引擎从Spider中获取到第一个要爬取的URL并在调度器(Scheduler)以Request调度。
3. 引擎向调度器请求下一个要爬取的URL。
4. 调度器返回下一个要爬取的URL给引擎,引擎将URL通过下载中间件(请求(request)方向)转发给下载器(Downloader)。
5. 一旦页面下载完毕,下载器生成一个该页面的Response,并将其通过下载中间件(返回(response)方向)发送给引擎。
6. 引擎从下载器中接收到Response并通过Spider中间件(输入方向)发送给Spider处理。
7. Spider处理Response并返回爬取到的Item及(跟进的)新的Request给引擎。
8. 引擎将(Spider返回的)爬取到的Item给Item Pipeline,将(Spider返回的)Request给调度器。
9. (从第二步)重复直到调度器中没有更多地request,引擎关闭该网站。
python爬虫学习之Scrapy框架的工作原理的更多相关文章
- Python爬虫进阶之Scrapy框架安装配置
Python爬虫进阶之Scrapy框架安装配置 初级的爬虫我们利用urllib和urllib2库以及正则表达式就可以完成了,不过还有更加强大的工具,爬虫框架Scrapy,这安装过程也是煞费苦心哪,在此 ...
- Python爬虫-Scrapy框架的工作原理
Scrapy框架工作原理 Scrapy框架架构图 Scrapy框架主要由六大组件组成,分别为: 调度器(Scheduler),下载器(Downler),爬虫(Spiders),中间件(Middwa ...
- 零基础写python爬虫之使用Scrapy框架编写爬虫
网络爬虫,是在网上进行数据抓取的程序,使用它能够抓取特定网页的HTML数据.虽然我们利用一些库开发一个爬虫程序,但是使用框架可以大大提高效率,缩短开发时间.Scrapy是一个使用Python编写的,轻 ...
- python爬虫入门(六) Scrapy框架之原理介绍
Scrapy框架 Scrapy简介 Scrapy是用纯Python实现一个为了爬取网站数据.提取结构性数据而编写的应用框架,用途非常广泛. 框架的力量,用户只需要定制开发几个模块就可以轻松的实现一个爬 ...
- PYTHON 爬虫笔记十一:Scrapy框架的基本使用
Scrapy框架详解及其基本使用 scrapy框架原理 Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架. 其可以应用在数据挖掘,信息处理或存储历史数据等一系列的程序中.其最初是为了 ...
- python 爬虫相关含Scrapy框架
1.从酷狗网站爬取 新歌首发的新歌名字.播放时长.链接等 from bs4 import BeautifulSoup as BS import requests import re import js ...
- Python爬虫知识点四--scrapy框架
一.scrapy结构数据 解释: 1.名词解析: o 引擎(Scrapy Engine)o 调度器(Scheduler)o 下载器(Downloader)o 蜘蛛(Spiders)o 项目管 ...
- 芝麻HTTP:Python爬虫进阶之Scrapy框架安装配置
初级的爬虫我们利用urllib和urllib2库以及正则表达式就可以完成了,不过还有更加强大的工具,爬虫框架Scrapy,这安装过程也是煞费苦心哪,在此整理如下. Windows 平台: 我的系统是 ...
- 【Python爬虫实战】Scrapy框架的安装 搬运工亲测有效
windows下亲测有效 http://blog.csdn.net/liuweiyuxiang/article/details/68929999这个我们只是正确操作步骤详解的搬运工
随机推荐
- .net WebApi中使用swagger生成WepApi集成测试工具
我在WebApi中使用swagger的时候发现会出现很多问题,搜索很多地方都没找到完全解决问题的方法,后面自己解决了,希望对于遇到同样问题朋友有帮助.我将先一步一步的演示项目中解决swagger遇到问 ...
- CentOS7 修改静态IP地址
Ip配置文件在/etc/sysconfig/network-scripts文件夹下,查找该文件的方法为: [root@localhost ~]# ll /etc/sysconfig/network-s ...
- Quartz.Net 定时服务
http://www.cnblogs.com/jys509/p/4628926.html https://www.cnblogs.com/AmyLo/p/8125505.html https://bl ...
- weblogic中配置数据源
Weblogic数据源配置 一.配置数据源 1.点击数据源,进入数据源配置页面,点击新建后选择一般数据源 2.输入名称和jndi名称(两个输入一样即可)后点击下一步 3.选择驱动后点击下一步 4.输入 ...
- rtx tiny os
一,简单测试步骤: 1. license management包含两项:artx51 real time os, PK51 2. code #include "rtx51tny.h&quo ...
- [ES]elasticsearch章5 ES的分词(一)
初次接触 Elasticsearch 的同学经常会遇到分词相关的难题,比如如下这些场景: 1.为什么明明有包含搜索关键词的文档,但结果里面就没有相关文档呢? 2.我存进去的文档到底被分成哪些词(ter ...
- laravel-更换语言包
第一步:找语言包 找到比较靠谱的语言包(根据下载量与收藏量综合判断),而且要是laravel的 扩展的链接:https://packagist.org/packages/caouecs/laravel ...
- 使用nginx反向代理实现隐藏端口号
使用nginx反向代理实现隐藏端口号 在服务器上下载安装nginx,主要是修改配置nginx.conf. 用proxy_pass里面配置要转发的域名+端口,相当于这一部分是被域名替换的部分,在http ...
- Shell脚本备份数据库(多库)
#!/bin/bashPATH=/bin:/sbin:/usr/bin:/usr/sbin:/usr/local/bin:/usr/local/sbinexport PATH#数据库用户名dbuser ...
- 【Python】【BugList13】req = requests.get(url=target)报错: (Caused by SSLError(SSLError(1, '[SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed (_ssl.c:777)')
[代码] # -*- coding:UTF-8 -*- import requests if __name__ == '__main__': target = 'https://unsplash.co ...