25.HashTable
在java中有两个类都提供了一个多种用途的hashTable机制,他们都可以将key和value结合起来构成键值对通过put(key,value)方法保存起来,然后通过get(key)方法获取相对应的value值。一个是前面提到的HashMap,还有一个就是马上要讲解的HashTable。对于HashTable而言,它在很大程度上和HashMap的实现差不多,如果我们对HashMap比较了解的话,对HashTable的认知会有很大的帮助。他们两者之间只存在几点的不同,这个后面会阐述。

HashTable在Java中的定义如下:

从中可以看出HashTable继承Dictionary类,实现Map接口。其中Dictionary类是所有可将键映射到相应值的类(如 Hashtable)的抽象父类。每个键和每个值都是一个对象。在任何一个 Dictionary 对象中,每个键至多与一个值相关联。Map是"key-value键值对"接口。
HashTable采用"拉链法"实现哈希表,它定义了几个重要的参数:table、count、threshold、loadFactor、modCount。
HashTable采用"拉链法"实现哈希表,它定义了几个重要的参数:table、count、threshold、loadFactor、modCount。
table:为一个Entry[]数组类型,Entry代表了“拉链”的节点,每一个Entry代表了一个键值对,哈希表的"key-value键值对"都是存储在Entry数组中的。
count:HashTable的大小,注意这个大小并不是HashTable的容器大小,而是他所包含Entry键值对的数量。
threshold:Hashtable的阈值,用于判断是否需要调整Hashtable的容量。threshold的值="容量*加载因子"。
loadFactor:加载因子。
modCount:用来实现“fail-fast”机制的(也就是快速失败)。所谓快速失败就是在并发集合中,其进行迭代操作时,若有其他线程对其进行结构性的修改,这时迭代器会立马感知到,并且立即抛出ConcurrentModificationException异常,而不是等到迭代完成之后才告诉你(你已经出错了)。

在HashTabel中存在5个构造函数。通过这5个构造函数我们构建出一个我想要的HashTable。
1.默认构造函数,容量为11,加载因子为0.75。

2.用指定初始容量和默认的加载因子 (0.75) 构造一个新的空哈希表。

3.用指定初始容量和指定加载因子构造一个新的空哈希表。其中initHashSeedAsNeeded方法用于初始化hashSeed参数,其中hashSeed用于计算key的hash值,它与key的hashCode进行按位异或运算。这个hashSeed是一个与实例相关的随机值,主要用于解决hash冲突。
public Hashtable(int initialCapacity, float loadFactor) {
//验证初始容量
if (initialCapacity < 0) {
throw new IllegalArgumentException("Illegal Capacity: "+ initialCapacity);
}
//验证加载因子
if (loadFactor <= 0 || Float.isNaN(loadFactor)) {
throw new IllegalArgumentException("Illegal Load: "+loadFactor);
}
if (initialCapacity==0){
initialCapacity = 1;
}
this.loadFactor = loadFactor;
//初始化table,获得大小为initialCapacity的table数组
table = new Entry[initialCapacity];
//计算阀值
threshold = (int)Math.min(initialCapacity * loadFactor, MAX_ARRAY_SIZE + 1);
//初始化HashSeed值
initHashSeedAsNeeded(initialCapacity);
}
4.构造一个与给定的 Map 具有相同映射关系的新哈希表。

public Hashtable(Map<? extends K, ? extends V> t) {
//设置table容器大小,其值==t.size * 2 + 1
this(Math.max(2*t.size(), 11), 0.75f);
putAll(t);
}

HashTable的API对外提供了许多方法,这些方法能够很好帮助我们操作HashTable,但是这里我只介绍两个最根本的方法:put、get。
首先我们先看put方法:将指定 key 映射到此哈希表中的指定 value。注意这里键key和值value都不可为空。
public synchronized V put(K key, V value) {
// 确保value不为null
if (value == null) {
throw new NullPointerException();
}
/* * 确保key在table[]是不重复的
* 处理过程:
* 1、计算key的hash值,确认在table[]中的索引位置
* 2、迭代index索引位置,如果该位置处的链表中存在一个一样的key,则替换其value,返回旧值
*/
Entry tab[] = table;
int hash = hash(key);
//计算key的hash值
int index = (hash & 0x7FFFFFFF) % tab.length;
//确认该key的索引位置
//迭代,寻找该key,替换
for (Entry<K,V> e = tab[index] ; e != null ; e = e.next) {
if ((e.hash == hash) && e.key.equals(key)) {
V old = e.value;
e.value = value;
return old;
}
}
modCount++;
if (count >= threshold) {
//如果容器中的元素数量已经达到阀值,则进行扩容操作
rehash();
tab = table;
hash = hash(key);
index = (hash & 0x7FFFFFFF) % tab.length;
}
// 在索引位置处插入一个新的节点
Entry<K,V> e = tab[index];
tab[index] = new Entry<>(hash, key, value, e);
//容器中元素+1
count++;
return null;
}
put方法的整个处理流程是:计算key的hash值,根据hash值获得key在table数组中的索引位置,然后迭代该key处的Entry链表(我们暂且理解为链表)
,若该链表中存在这个key的对象,那么就直接替换其value值即可,否则在将改key-value节点插入该index索引位置处。如下:
首先我们假设一个容量为5的table,存在8、10、13、16、17、21。他们在table中位置如下:
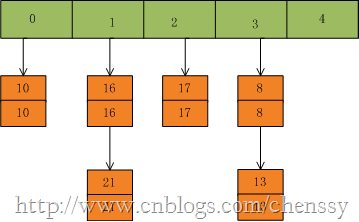
然后我们插入一个数:put(16,22),key=16在table的索引位置为1,同时在1索引位置有两个数,程序对该“链表”进行迭代,发现存在一个key=16,这时要做的工作就是用newValue=22替换oldValue16,并将oldValue=16返回。
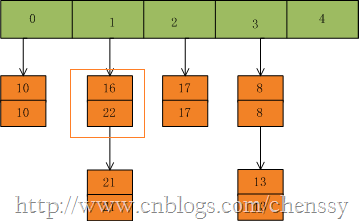
在put(33,33),key=33所在的索引位置为3,并且在该链表中也没有存在某个key=33的节点,所以就将该节点插入该链表的第一个位置。

1、HashTable的扩容操作,在put方法中,如果需要向table[]中添加Entry元素,会首先进行容量校验,如果容量已经达到了阀值,
HashTable就会进行扩容处理rehash(),如下:
protected void rehash() {
int oldCapacity = table.length;
//元素
Entry<K,V>[] oldMap = table;
//新容量=旧容量 * 2 + 1
int newCapacity = (oldCapacity << 1) + 1;
if (newCapacity - MAX_ARRAY_SIZE > 0) {
if (oldCapacity == MAX_ARRAY_SIZE) {
return;
}
newCapacity = MAX_ARRAY_SIZE;
}
//新建一个size = newCapacity 的HashTable
Entry<K,V>[] newMap = new Entry[];
modCount++;
//重新计算阀值
threshold = (int)Math.min(newCapacity * loadFactor, MAX_ARRAY_SIZE + 1);
//重新计算hashSeed
boolean rehash = initHashSeedAsNeeded(newCapacity);
table = newMap;
//将原来的元素拷贝到新的HashTable中
for (int i = oldCapacity ; i-- > 0 ;) {
for (Entry<K,V> old = oldMap[i] ; old != null ; ) {
Entry<K,V> e = old; old = old.next;
if (rehash) {
e.hash = hash(e.key);
}
int index = (e.hash & 0x7FFFFFFF) % newCapacity;
e.next = newMap[index]; newMap[index] = e;
}
}
}
在这个rehash()方法中我们可以看到容量扩大两倍+1,同时需要将原来HashTable中的元素一一复制到新的HashTable中,这个过程是比较消耗时间的,同时还需要重新计算hashSeed的,
毕竟容量已经变了。这里对阀值啰嗦一下:比如初始值11、加载因子默认0.75,那么这个时候阀值threshold=8,当容器中的元素达到8时,HashTable进行一次扩容操作,容量 = 8 * 2 + 1 =17,
而阀值threshold=17*0.75 = 13,当容器元素再一次达到阀值时,HashTable还会进行扩容操作,一次类推。
2、其实这里是我的一个疑问,在计算索引位置index时,HashTable进行了一个与运算过程(hash & 0x7FFFFFFF),为什么需要做一步操作,
这么做有什么好处?如果哪位知道,望指导,LZ不胜感激!!下面是计算key的hash值,这里hashSeed发挥了作用。

相对于put方法,get方法就会比较简单,处理过程就是计算key的hash值,判断在table数组中的索引位置,然后迭代链表,匹配直到找到相对应key的value,若没有找到返回null。
public synchronized V get(Object key) {
Entry tab[] = table;
int hash = hash(key);
int index = (hash & 0x7FFFFFFF) % tab.length;
for (Entry<K,V> e = tab[index] ; e != null ; e = e.next) {
if ((e.hash == hash) && e.key.equals(key)) {
return e.value;
}
}
return null;
}

HashTable和HashMap存在很多的相同点,但是他们还是有几个比较重要的不同点。
第一:我们从他们的定义就可以看出他们的不同,HashTable基于Dictionary类,而HashMap是基于AbstractMap。Dictionary是什么?它是任何可将键映射到相应值的类的抽象父类,而AbstractMap是基于Map接口的骨干实现,它以最大限度地减少实现此接口所需的工作。
第二:HashMap可以允许存在一个为null的key和任意个为null的value,但是HashTable中的key和value都不允许为null。如下:
当HashMap遇到为null的key时,它会调用putForNullKey方法来进行处理。对于value没有进行任何处理,只要是对象都可以。

而当HashTable遇到null时,他会直接抛出NullPointerException异常信息。

第三:Hashtable的方法是同步的,而HashMap的方法不是。所以有人一般都建议如果是涉及到多线程同步时采用HashTable,没有涉及就采用HashMap,但是在Collections类中存在一个静态方法:synchronizedMap(),该方法创建了一个线程安全的Map对象,并把它作为一个封装的对象来返回,所以通过Collections类的synchronizedMap方法是可以我们你同步访问潜在的HashMap。这样君该如何选择呢???
以上内容均来自http://www.cnblogs.com/chenssy/博客,此博客为本人学习笔记
25.HashTable的更多相关文章
- 在webservice中传递Hashtable
webservice中不支持hashtable的数据类型,那么如何在webservice中传递hashtable呢?我们可以通过将hashtable转化为webservice中支持的数组的类型来进行传 ...
- Java:Hashtable
概要 前一章,我们学习了HashMap.这一章,我们对Hashtable进行学习.我们先对Hashtable有个整体认识,然后再学习它的源码,最后再通过实例来学会使用Hashtable.第1部分 Ha ...
- 通过jQuery或ScriptManager以Ajax方式访问服务
1.客户端和服务端 服务端对外提供服务时,可以通过handler或者webservice.handler比较轻便,但是难以对外公开,只有程序员自己知道它到底做了些什么工作.webservice可以将服 ...
- c#动态调用WEBSERVICE接口
C#动态webservice调用接口 1 using System; 2 using System.Collections; 3 using System.IO; 4 using System.Net ...
- Java集合专题总结(1):HashMap 和 HashTable 源码学习和面试总结
2017年的秋招彻底结束了,感觉Java上面的最常见的集合相关的问题就是hash--系列和一些常用并发集合和队列,堆等结合算法一起考察,不完全统计,本人经历:先后百度.唯品会.58同城.新浪微博.趣分 ...
- HashTable(散列表)
最近都在研究数据结构,关于hashtable,或者叫做散列表,过去一直不了解是什么东西,现在终于明白了. 所谓hashtable,就是某组key,通过某个关系(函数),得到一个与之对应的映射值(在计算 ...
- 数据结构和算法 – 7.散列和 Hashtable 类
7.1.散列函数 散列是一种常见的存储数据的技术,按照这种方式可以非常迅速地插入和取回数据.散列所采用的数据结构被称为是散列表.尽管散列表提供了快速地插入.删除.以及取回数据的操作,但是诸如查找最大值 ...
- C#中HashTable和快速排序的用法
题目主要是写一个程序,分析一个文本文件(英文文章)中各个词出现的频率,并且把频率最高的10个词打印出来. 自从周四拿到题目以后,发现又要用到万恶的数据结构了,不得不说这是我的短板,所有上周20号到 ...
- HashTable和HashSet中的类型陷阱
HashTable和HashSet中的类型陷阱 发现这个陷阱的起因是这样的:我现在有上百万字符串,我准备用TopK算法统计出出现次数做多的前100个字符串. 首先我用Hashtable统计出了每个字符 ...
随机推荐
- selenium调用webdriver异常
使用selenium调用webdriver的时候报错. from selenium import webdriver browser = webdriver.Chrome() browser.get( ...
- vim高级工能入门
一.多文件编辑 1.vim 1.txt 2.txt 3.txt同时打开3个文件在vim缓冲区, 命令模式下输入:n 切换到下一个文件,可以加!:n! 强制切换,之前那个没有保存,仅仅是切换. ...
- Ubuntu 增加swap空间大小
1. create a 1G file for the swap. sudo fallocate -l 1G /swapfile we can verify that the correct amou ...
- 连接HTTP服务器
一.前提 Android 系统上面默认所有Http的请求都被阻止了. 需要在androidmanifest.xml的 application标签上加入 android:usesCleartextTra ...
- python requests库爬取网页小实例:ip地址查询
ip地址查询的全代码: 智力使用ip183网站进行ip地址归属地的查询,我们在查询的过程是通过构造url进行查询的,将要查询的ip地址以参数的形式添加在ip183url后面即可. #ip地址查询的全代 ...
- gk888t打印机安装
https://jingyan.baidu.com/article/948f5924090c7ad80ff5f9c5.html
- java之servlet学习基础(一)
这一阵子在学java三大框架.却在学习过程中发现前面的知识已经忘记了.所以决定写一篇博客来总结回顾之前的学习. 1.Servlet是什么? servlet是一个运行在服务器端的小应用程序.通过HTTP ...
- HDU1060
#include <bits/stdc++.h> using namespace std; int main() { int n; long long x; double t,ans; c ...
- 面试简单整理之zookeeper
157.zookeeper 是什么? ZooKeeper 是一个开源的分布式协调服务,由雅虎创建,是 Google Chubby 的开源实现. 分布式应用程序可以基于 ZooKeeper 实现诸如数据 ...
- Flip String to Monotone Increasing LT926
A string of '0's and '1's is monotone increasing if it consists of some number of '0's (possibly 0), ...