face detection[HR]
该模型hybrid-resolution model (HR),来自《finding tiny faces》,时间线为2016年12月
0 引言
虽然大家在目标识别上有了较好的进步,可是检测小物体仍然是一个极具挑战的事情。对于几乎所有当前的识别和目标检测系统而言,尺度不变性是一个必须的特性。但是从实际角度来说,尺度不变性也只是一定程度的不变性,因为对于一个3像素的和300像素的缩放来说,的确相差太大了。
而现在大多数的目标检测任务使用的无外乎2种形式来解决尺度不变性问题:
- 基于一个图像金字塔进行窗口滑动的方式,如MTCNN;
- 基于ROI-pooling方式进行区域分类,如fast-rcnn。
其实,我们主要是希望有一个小模板能够检测小模型,大模板能够检测大模型,那么这时候就涉及到需要针对不同尺度训练不同的检测器,而且在预测的时候也得处理多次,并且也缺少对应的数据集。所以作者这里为了权衡之间的问题,通过训练一个CNN,并基于不同的网络层提取对应的feature map(就和ssd一样)。不过这样虽然对大目标有较好效果,对于小的人脸,还需要其他考虑。
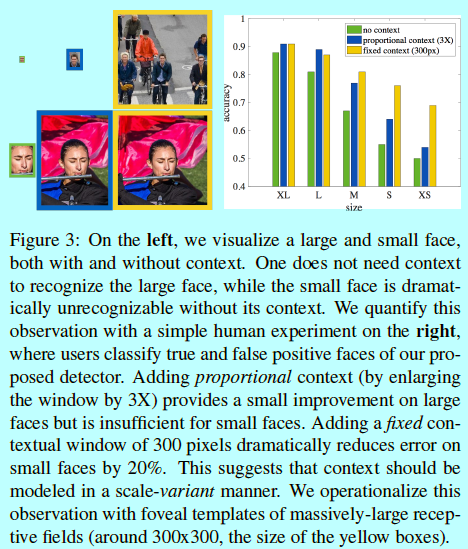
如上图所示,这是一个简单的人类实验,其中用户需要试图基于模型给出的结果基础上,区分真人脸(真阳性)和假人脸(假阳性)。从这个实验中可以看出,人类需要上下文信息去准确的判别小脸。

如图所示:
- 图像金字塔方法:如(a),传统的方法是建立一个单尺度模板,将其用在图像金字塔上面;
- 不同尺度采用不同检测器:如(b),而如果想要利用到不同分辨率上的信息,那么需要基于不同的对象尺度构建不同的检测器(如在一张图片上,检测小脸的一个检测器,检测大脸的一个检测器),而这样的方法在极端对象尺度上还是会失败,因为可能这个尺度的根本没出现过在训练集中;
- 本文方法:如(c)作者先用粗略的图像金字塔去抓取极端的尺度变化。然后为了提升关于小脸的检测,增加了额外的上下文信息,即通过一个固定大小的感受野在所有特定尺度上进行抓取,如(d)。然后如(e),基于同一个深度模型,在网络不同层上提取的特征来定义模板。
ps:在一个网络模型中,采用同样大小的划框在多个feature map上进行局部采样,这样形成的特征叫“超级列(hypercolumns)”,被用在语义分割中《Hypercolumns for object segmentation and fine-grained localization》。
1 尺度分析(上下文、分辨率等信息利用)
要说到尺度不变性,还得追述到SIFT模型,不过随着fast-rcnn等提出的ROI pooing等深度网络的兴起,还有近来基于不同网络层提取多种尺度信息的SSD(其实就是将图像金字塔转换成特征层金字塔)。作者也有了一些想法和灵感。
作者这里基于ResNet-50作为基底模型,并提取每个残差快最后一层的feature map作为特征,即(res2cx,res3dx,res4fx,res5cx),这里简写成(res2,res3,res4,res5)。通过对不同层进行超级列(中央凹)等操作,并基于提取的特征做二值热力图预测(即结果也是一个map,其中每个值表示以其为中心的人脸出现的置信度)
1.1 上下文信息
固定大小的划框在多层map下的变化
首先设计了一个实验,首先设计一个固定大小的划窗,然后不断的增加层上的区域,从而达到增加感受野的目的:

如图所示,划窗大小都为25×20,在不同feature map上面,得到的感受野却是不同的,比如res4上可以得到291x291的感受野。可以看出,基于多层通道获取的特征可以提供丰富的上下文信息,从而有助于人脸的检测。在小脸检测上,最开始就能提供较为准确的检测,并随着感受野的增大和信息的增多,准确度也在增大(最后有所下降,估计是最开始最小的划框刚好框住人脸,然后随着感受野增大,输入了太多噪音导致过拟合了);而对于大人脸,只有不断上升的效果(是因为随着感受野的增大,当前小划框终于能够看到完整的人脸了,最初只能看到鼻子而已)。

这里仍是基于固定大小的划框,然后是否采用中央凹(多层通道)的结果,可以看出如果采用了中央凹,那么就可以提供更多信息,从而检测效果上升;如果没有采用,只是考虑感受野的增大,发现对大人脸效果是有上升,不过对小人脸却有过拟合的风险。
总结:通过感受野的增大,且保证划框刚好框住对象,此时得到的效果最好,然而固定划框如果框多了,或者少了,会造成过拟合或者欠拟合。如果此时增加多通道的特征,可以起到正则效果,并降低框住太多背景噪音而造成的过拟合,这样就解决了划框大小选择的问题,从而不需要不同尺度目标都去设计不同的检测模型了
1.2 模板分辨率
作者还做了实验,如何让模板去对应不同尺度的目标,
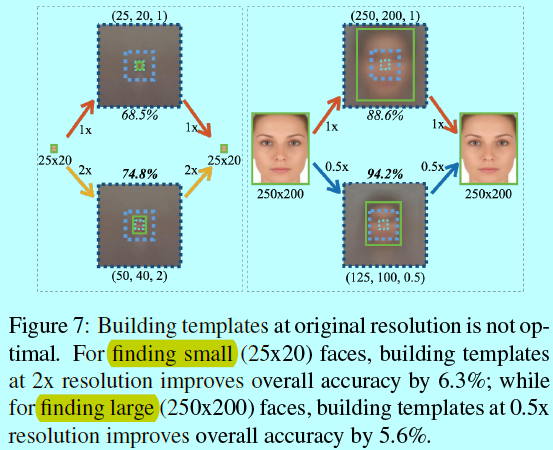
如图所示:
- 他假设采用了一个中等尺寸的模板(50x40),然后去找小的人脸(25x20),如果进行放大两倍,那么结果就从原来的69%上升到75%;
- 反过来,如果当前中等尺寸模板大小为125x100,去找大的人脸(250x200),将这张图片缩小两倍,结果也从原来的89%上升到94%。
可以看出,如果如果模板的大小和人脸大小基本一致,那么就能提升检测结果。
作者猜测,这主要就是基于不同的尺度目标下,训练数据不充分的缘故。
如图,比如在wider face 和coco数据集中,小人脸的量大于大人脸的量。不平衡的数据导致采用中等模板检测大人脸要比检测小人脸容易(因为相对在训练阶段有更多中等人脸),虽然这并没有解释小人脸问题。
接着从预训练数据集Imagenet上进行分析
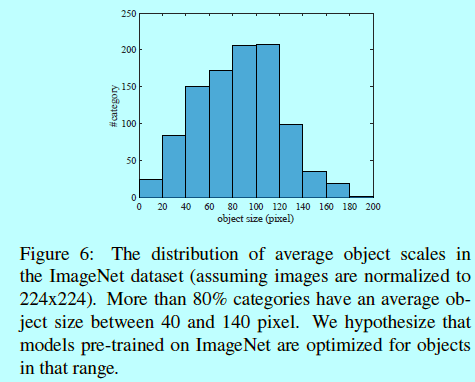
如图所示,80%的训练样本都包含中等尺寸的目标(从40到140像素之间)。
此时作者也假设,如果用基于Imagenet预训练的模型在自己的数据上微调,最好的部分也就是这部分
2 结构
那么现在问题来了,如何实现多个目标尺度上采用不同的模板呢?
- 如图7所示,假设我们定义模板为\(t(h,w,\sigma)\);并假设是用来检测分辨率为\(\sigma\)的目标尺度为\((h/\sigma,w/\sigma)\),比如图7中,用\(t(250,200,1)\)和\((t(125,100,0.5))\)可以同时去检测\(250 \times 200\)的人脸。
那么问题又来了,怎么设定模板大小?
- 假设我们的训练集有图像和对应的边界框,那么先采用聚类的方式去获取其中的对象尺度,这里采用的距离测度是:
\[d(s_i,s_j)=1-J(s_i,s_j)\]
这里\(s_i=(h_i,w_i)\)和\(s_j=(h_j,w_j)\)是一对边界框,\(J\)表示标准的jaccrad相似度(IOU)。
现在,对于每个对象尺度\(s_i=(h_i,w_i)\),我们想知道\(\sigma_i\)设多大合适呢?
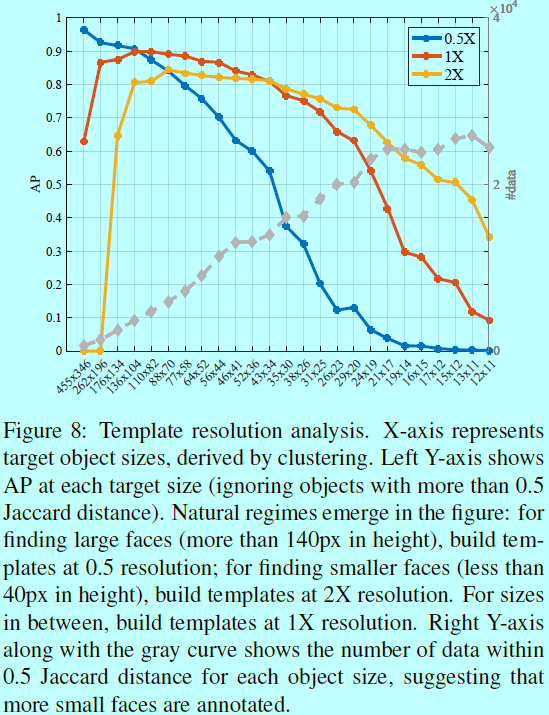
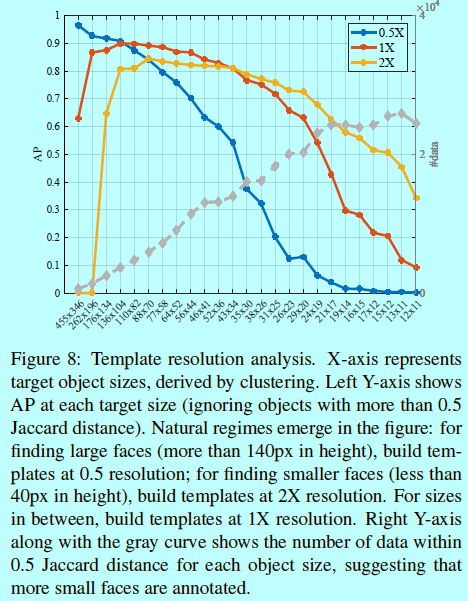
- 通过多任务模型方法,直接将每个\(\sigma \in \Sigma\)一起做目标函数;并对每个对象尺度提取最大的,如图8所示
如图8所示,对于每个\((h_i,w_i)\)的最优\(\sigma_i\),我们用一个多任务模型去训练一个混合分辨率(HR),在实测中也符合所以曲线的上限。有趣的是,的确存在不同策略下的自然惩罚:- 为了找到大目标(高度超过140像素),使用2X进行缩小;
- 为了找到小目标(小于40像素),使用2X进行放大;
- 否则就是用1X的分辨率。
我们的结果也证明了之前关于Imagenet统计的猜测。
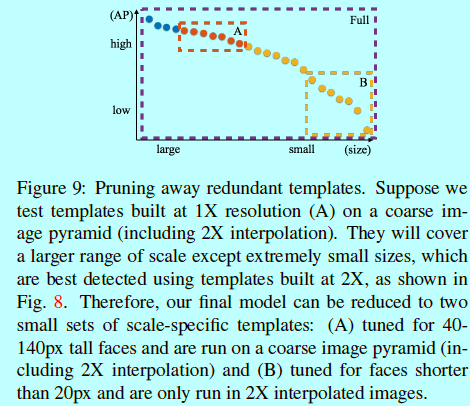
剪枝
上面提到的(hybrid-resolution,HR)中还是有一些冗余的。例如:模板(62,50,2)可以用来寻找31x25的人脸,可是他同时也和寻找64x50的人脸的模板(64,50,1)相冲突了。如图9,冗余删除之后,甚至有点小提升。本质来说,我们的模型可以进一步减少到只包含几个具体尺度模板的集合,并在一个粗粒度的图像金字塔上做计算。
这里我们给出本论文的模型结构:
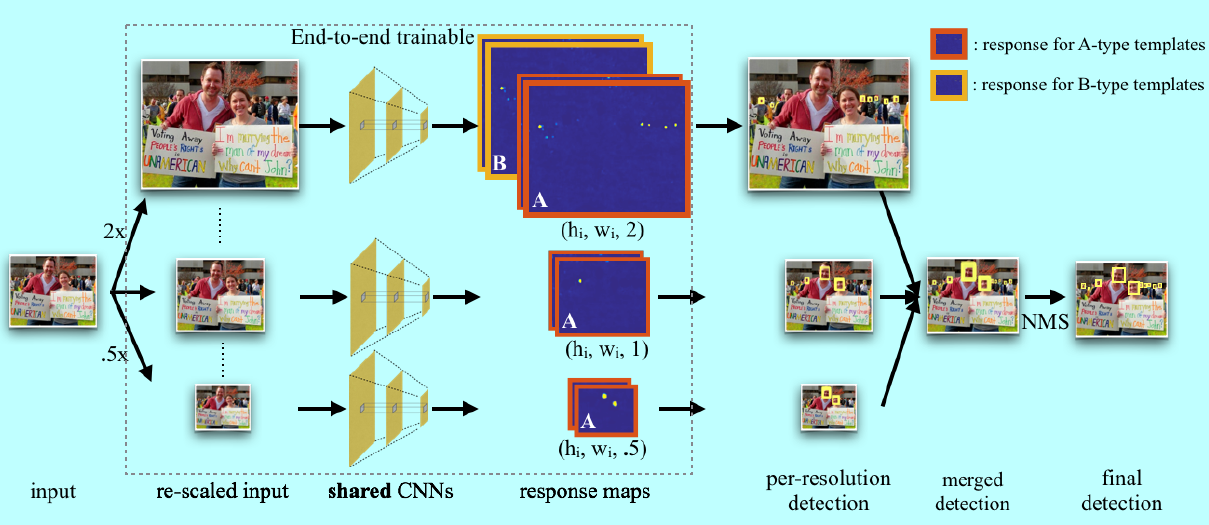

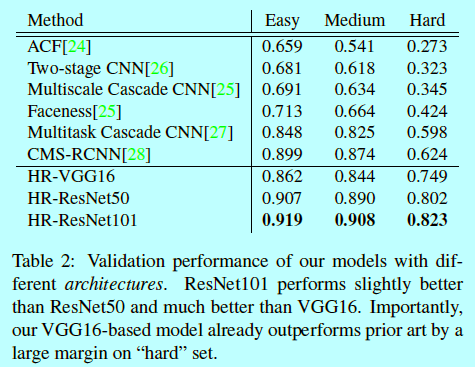
如图所示,通过训练二值多通道热力图,预一个范围人脸尺度(40-140像素)之间的对象置信度。然后基于特定分辨率下得到的热力图,通过图像金字塔寻找更大或者更小的人脸;对于共享的CNN部分,我们测试过ResNet101,ResNet50,VGG16,结果显示ResNet101最好。
face detection[HR]的更多相关文章
- Saliency Detection: A Spectral Residual Approach
Saliency Detection: A Spectral Residual Approach 题目:Saliency Detection: A Spectral Residual Approach ...
- 记2016腾讯 TST 校招面试经历,电面、笔试写代码、技术面、hr面,共5轮
(出处:http://www.cnblogs.com/linguanh/) 前序: 距离 2016 腾讯 TST 校招面试结束已经5天了,3月27日至今,目前还在等待消息.从投简历到两轮电面,再到被 ...
- Html --用简单的<hr>实现多样化分割效果
最基本的:<hr width=300 size=1 color=#5151A2 align=center noshade>. <!--其中 width 规定线条的长度,还可以是百分比 ...
- <hr>标签不止创建html水平线也可以画圆噢
看到上面这张图,第一反应是用photoshop类似作图软件画出来的,但那是华丽丽的错觉.一个简单的<hr>标签就能完成漂亮的效果,而不仅仅是创建html水平线.想知道怎么实现吗?Let's ...
- Oracle Database 创建HR模式
其实Oracle是自带演示模式的,我还一直在跪舔外面的培训机构的sql文件 首先以system 用户登陆SQL 输入: alter user hr account unlock identified ...
- Oracle解锁与加锁(HR用户为例)
SQL*Plus: Release 9.2.0.4.0 - Production on Tue Jul 14 18:12:38 2009 Copyright (c) 1982, 2002, Ora ...
- Clash Detection
Clash Detection eryar@163.com Abstract. Clash detection is used for the model collision check. The p ...
- YOLO: Real-Time Object Detection
YOLO detection darknet框架使用 YOLO 训练自己的数据步骤,宁广涵详细步骤说明
- 腾讯WEB前端开发面试经历,一面二面HR面,面面不到!
[一面]~=110分钟 2014/09/24 11:20 星期三 进门静坐30分钟做题. 填空题+大题+问答题 >>填空题何时接触电脑 何时接触前端运算符 字符串处理 延 ...
随机推荐
- 解决在TP5中无法使用快递鸟的即时查询API
快递鸟的接口对接其实很简单,先去官网注册账号,登陆把基本信息填好,然后在产品管理中订购一下“物流查询”,免费,不过其他产品是收费,免费的有对接口调用频率限制,结合自己的应用流量够用就可以. 使用前复制 ...
- 17.Odoo产品分析 (二) – 商业板块(10) – 电子商务(1)
查看Odoo产品分析系列--目录 安装电子商务模块 1. 主页 点击"商店"菜单: 2. 添加商品 在odoo中,你不用进入"销售"模块,再进入产品列表添加产 ...
- iOS ----------要学习的地方(链接整理)
1.http://www.cocoachina.com/special/xcode/ 2.http://blog.csdn.net/a416863220/article/details/4111387 ...
- python+selenium+PhantomJS爬取网页动态加载内容
一般我们使用python的第三方库requests及框架scrapy来爬取网上的资源,但是设计javascript渲染的页面却不能抓取,此时,我们使用web自动化测试化工具Selenium+无界面浏览 ...
- Python 一键commit文件、目录到SVN服务器
一键commit文件.目录到SVN服务器 by:授客 QQ:1033553122 实现功能 1 测试环境 1 代码show 1 实现功能 一键提交文件.目录到svn 测试环境 Win7 64位 ...
- Javac编译原理 《深入分析java web 技术内幕》第四章
javac编译的四个主要的流程: 词法分析器:将源码转换为Token流 将源代码划分成一个个Token(找出java语言中的关键字) 语法分析器:将Token流转化为语法树 将上述的一个个Token组 ...
- Android平台下利用zxing实现二维码开发
Android平台下利用zxing实现二维码开发 现在走在大街小巷都能看到二维码,而且最近由于项目需要,所以研究了下二维码开发的东西,开源的二维码扫描库主要有zxing和zbar,zbar在iPos平 ...
- 对display主要属性的探究,以及vertical-aligin
display 首先要简单说明一下display的主要3个主要属性,分别为block,inline-block,inline,这里只提及主要,关于其他的inherit,none等可以自行了解 inli ...
- Solr5.5高级应用(基于tomcat9)
一.配置solr 1.配置 注意:要是想放到其它路径下,可以修改此路径下的web.xml配置文件 修改内容如下: <!-- 将solrhome的绝对路径写入env-entry-value --& ...
- [20180810]exadata--豆腐渣系统的保护神.txt
[20180810]exadata--豆腐渣系统的保护神.txt --//最近一段时间,一直在看exdata方面的书籍,我个人的感觉exadata并非善长oltp系统,能通过OLTP获得好处的就算ex ...